文章目录
- 背景
- 什么是随机数种子?
- 机器学习中的随机源?
- 尽可能全面的种子固定方案?
-
- 1,Numpy的随机数生成器控制
- 2,Python内置随机
- 3,Pytorch中的可重复性?
-
- 控制随机性来源
-
- pytorch随机数生成器
- python种子
- 其他库中的随机数生成器
- [CUDA convolution benchmarking](#CUDA convolution benchmarking)
- 避免使用非确定性算法
- 填充未初始化的内存
- DataLoader
- 一点思考
- 还有一些问题?
- 参考
背景
在数据分析、统计模拟以及机器学习中,经常需要生成随机数。例如:
• 生成随机样本
• 构造模拟数据
• 初始化模型参数
• 实现随机抽样
我们在数据分析比较常见的,比如说NumPy提供的随机数生成的函数,可以生成多种概率分布的数据。这些函数主要集中在 numpy.random 模块中。
我也在很多机器学习代码中见到过如下代码:
python
import numpy as np
np.random.seed(42) # 42, 神奇的数字, 也是很多AI生成不得不品的一环当然,NumPy最近几个版本开始,官方推荐使用新的随机数生成体系(Generator对象)。
具体参考官网新的更新:https://numpy.org/doc/stable/reference/random/generator.html
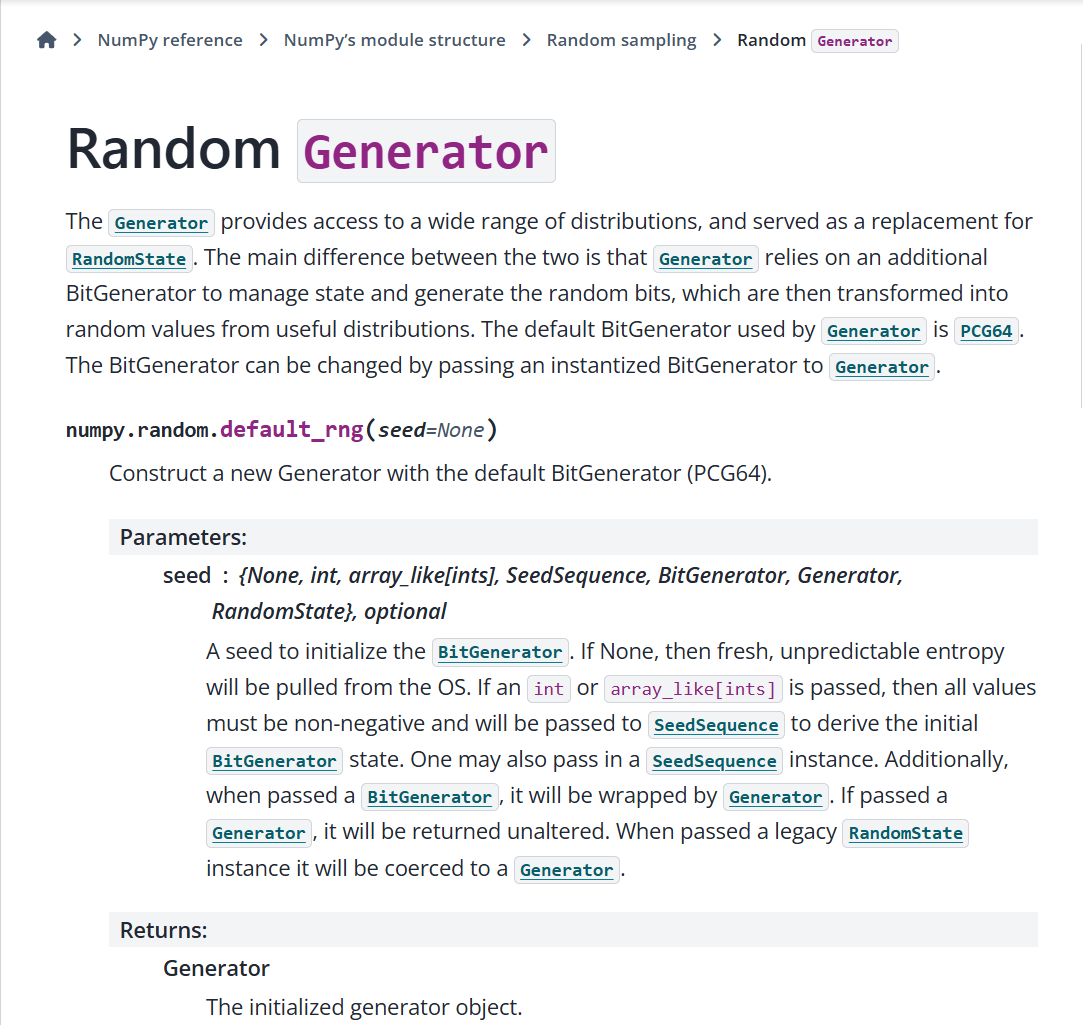
random*函数呢,其实更多的是旧时代的、传统的随机数接口。
在机器学习中,随机种子的设计的一个主要目的就是方便下一次复现,但是需要明确的是,就算我们生成了固定的随机数,结果已经与描述效果相差无几,还是存在难以完全复制效果的情况,这一点不难理解。因为模型训练不只是有随机数这一个随机过程,例如模型使用SGD等优化算法,这些方法本身就带有了随机性,每次迭代更新都是随机采样batch size个样本的平均梯度来更新权值,虽然说随机种子一定程度上降低了随机性,但由于这些方法本身的敏感,结果的细微差别依旧是难以避免的。
本篇博客的初始动机呢,是看到了一些文献仓库写的固定随机数种子的代码,所以想探究一下对于一个常规的机器学习项目,尽可能标准、尽可能使用的可复现随机种子方案应该如何选择,
包括但不限于:种子怎么选,怎么生成,怎么全局固定(这个问题是重点)。
最直接的起因是看到了pytorch官方论坛里讨论的1个古早问题(2018):
https://discuss.pytorch.org/t/how-could-i-fix-the-random-seed-absolutely/45515/6
当面对很多的随机数种子设置方案时,应该如何选择?

最核心的参考资料是这篇pytorch官网文档(2025):
https://docs.pytorch.org/docs/stable/notes/randomness.html#pytorch
注意这篇文档所提到的pytorch版本为
注意,问题是古早的,但是文档是比较新的,另外还有几个类似的问题:
https://github.com/pytorch/pytorch/issues/7068(2018)
https://discuss.pytorch.org/t/setting-seeds-does-not-give-reproducible-code/172792(2023)
https://discuss.pytorch.org/t/is-there-a-way-to-fix-the-random-seed-of-every-workers-in-dataloader/21687(2018,dataloader的随机性)
https://discuss.pytorch.org/t/fix-random-seed-in-training-validation-and-test-generator/137032(2021,多个设置同时尝试)
https://discuss.pytorch.org/t/selectively-applying-random-seed-to-different-parts-of-the-model/131315/2(2021,在model的多个part中能否任意切换随机与非随机1)
什么是随机数种子?
简单来说,种子=伪随机数的"起点值"。
- 相同种子 → 每次运行生成完全一样的随机数(可复现)
- 不同种子 → 生成不同随机数
伪随机不是真随机,所以得靠种子控制结果。
关于伪随机数生成器(PRNG),可以参考维基百科:https://zh.wikipedia.org/wiki/伪随机数生成器



然后还有一个数学定义

机器学习中的随机源?
要1个100%全覆盖的全套固定随机种子方案是不切实际的,毕竟实际工程中方案需求是多种多样的,
不一定要求所有的随机源都固定,即使我们单单从程序代码上溯源锁定了所有的API,
也没有办法轻易地评估固定某个随机种子之后牵一发动全身的连锁后果。
此处只能尽可能全面地罗列机器学习中的随机源可能的场景:
- Python内置随机
- NumPy随机
- 数据加载器打乱(shuffle),数据集划分,数据采样
- 模型初始化(权重)
- 优化器、dropout、batchnorm等
- 多线程/多进程随机性
从理论上来讲,只固定1个种子,结果很大概率依然不可复现,理论上是必须全部锁死
尽可能全面的种子固定方案?
1,Numpy的随机数生成器控制
python
import numpy as np
np.random.seed()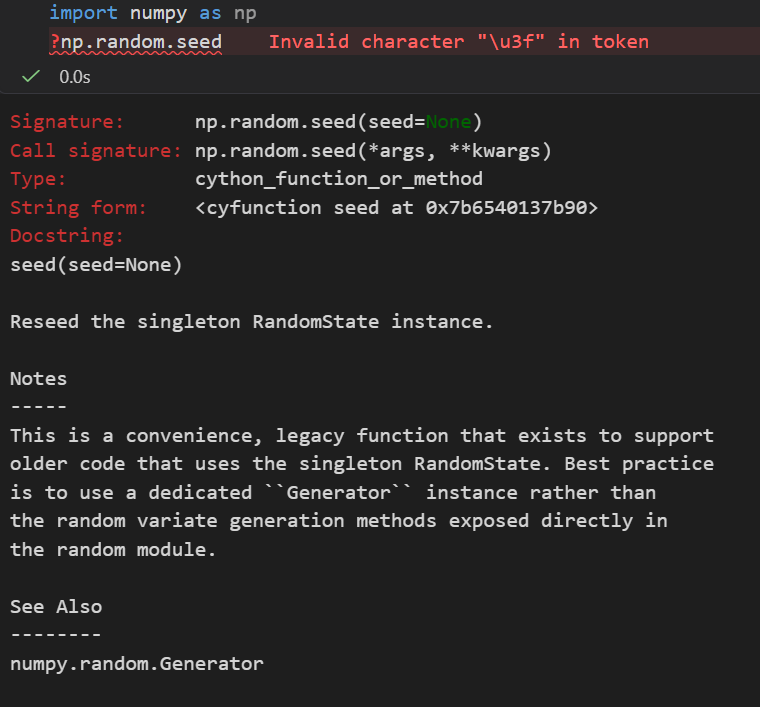
这是一个便捷的遗留函数,其存在是为了支持使用单例 RandomState 的旧代码。最佳实践是使用专用的Generator实例,而非直接使用随机模块中暴露的随机变量生成方法。
可以参考python官方文档:https://docs.python.org/zh-cn/3/library/random.html
随机数生成的算法就是前面维基百科中提到的梅森旋转法:

2,Python内置随机
首先是random模块,可以参考:https://docs.python.org/zh-cn/3/library/random.html
关于和numpy的random模块的比对,可以参考:https://stackoverflow.com/questions/7029993/differences-between-numpy-random-and-random-random-in-python
python
import random
random.seed()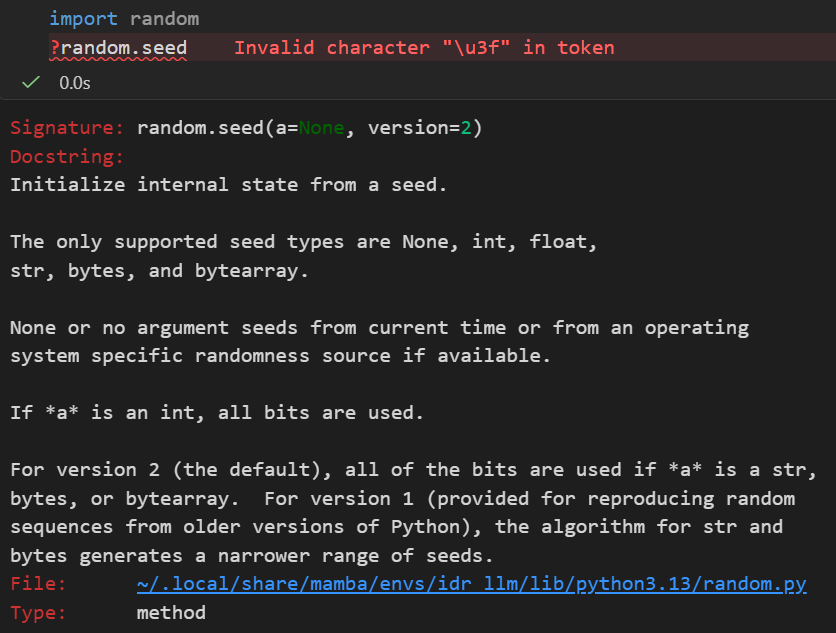
3,Pytorch中的可重复性?
我想这个应该是大家最关心的了,因为普通code以及机器学习code的随机数控制方案是比较简单的,但是深度学习因为体系过于庞大、API过多、过程也更加复杂,所以这个问题会比较难以回答。
我们只参考pytorch官方可重复性文档:
https://docs.pytorch.org/docs/stable/notes/randomness.html#pytorch

我们的标准还是控制非确定性来源,pytorch官方额外提到了一些操作中的使用算法本身是确定性还是非确定性的。

控制随机性来源
pytorch随机数生成器
python
import torch
torch.manual_seed()
python种子
和前面一样
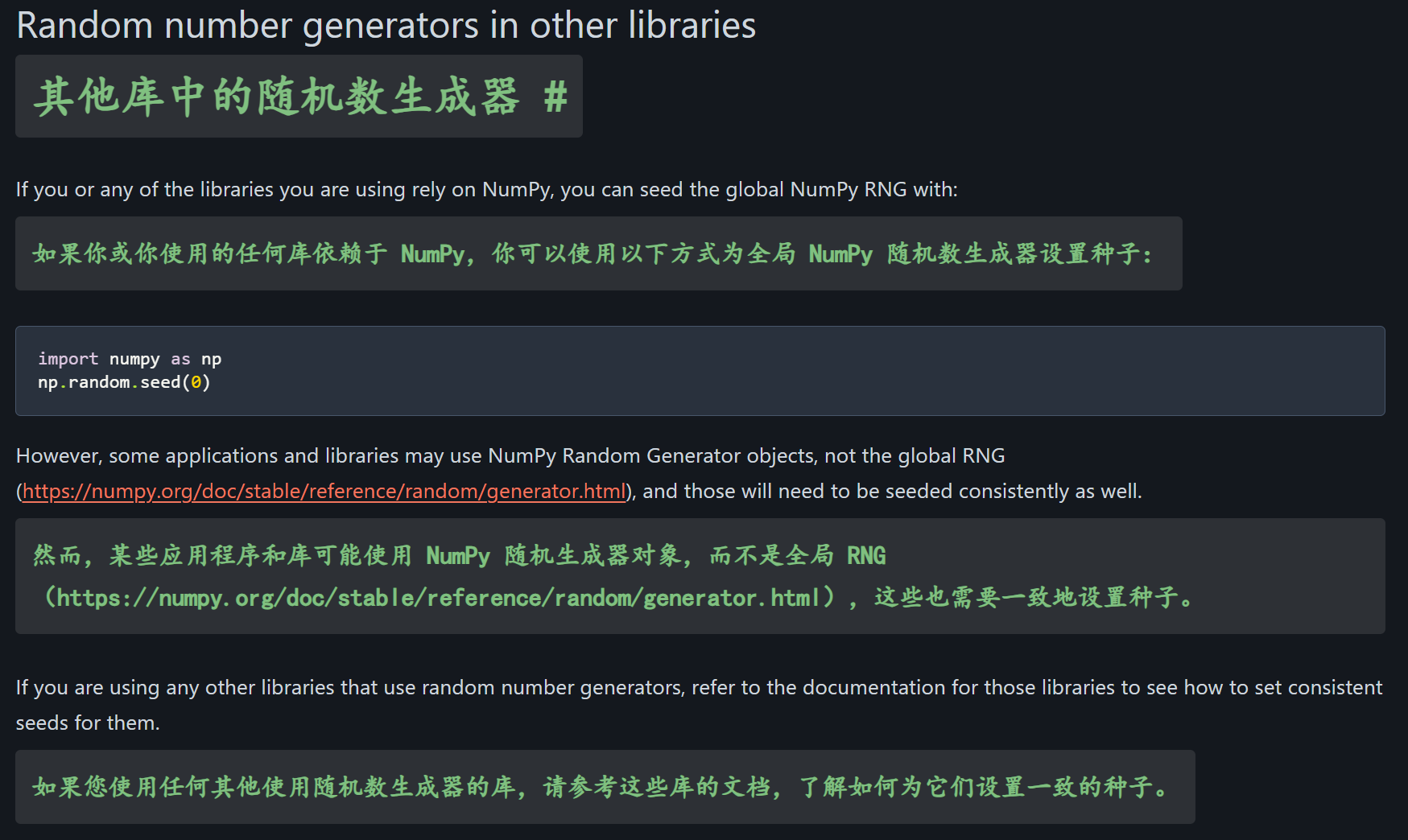
其他库中的随机数生成器
在机器学习语境中,主要是指numpy,当然numpy的随机数生成API以及方案的更新前面也已经提到了,
需要查阅Generator相关API文档,
至于其他的库,也需要具体语境具体分析
CUDA convolution benchmarking
这个词不好翻译,直接叫做卷积基准测试吧。
python
torch.backends.cudnn.benchmark = False
避免使用非确定性算法
python
torch.use_deterministic_algorithms(True)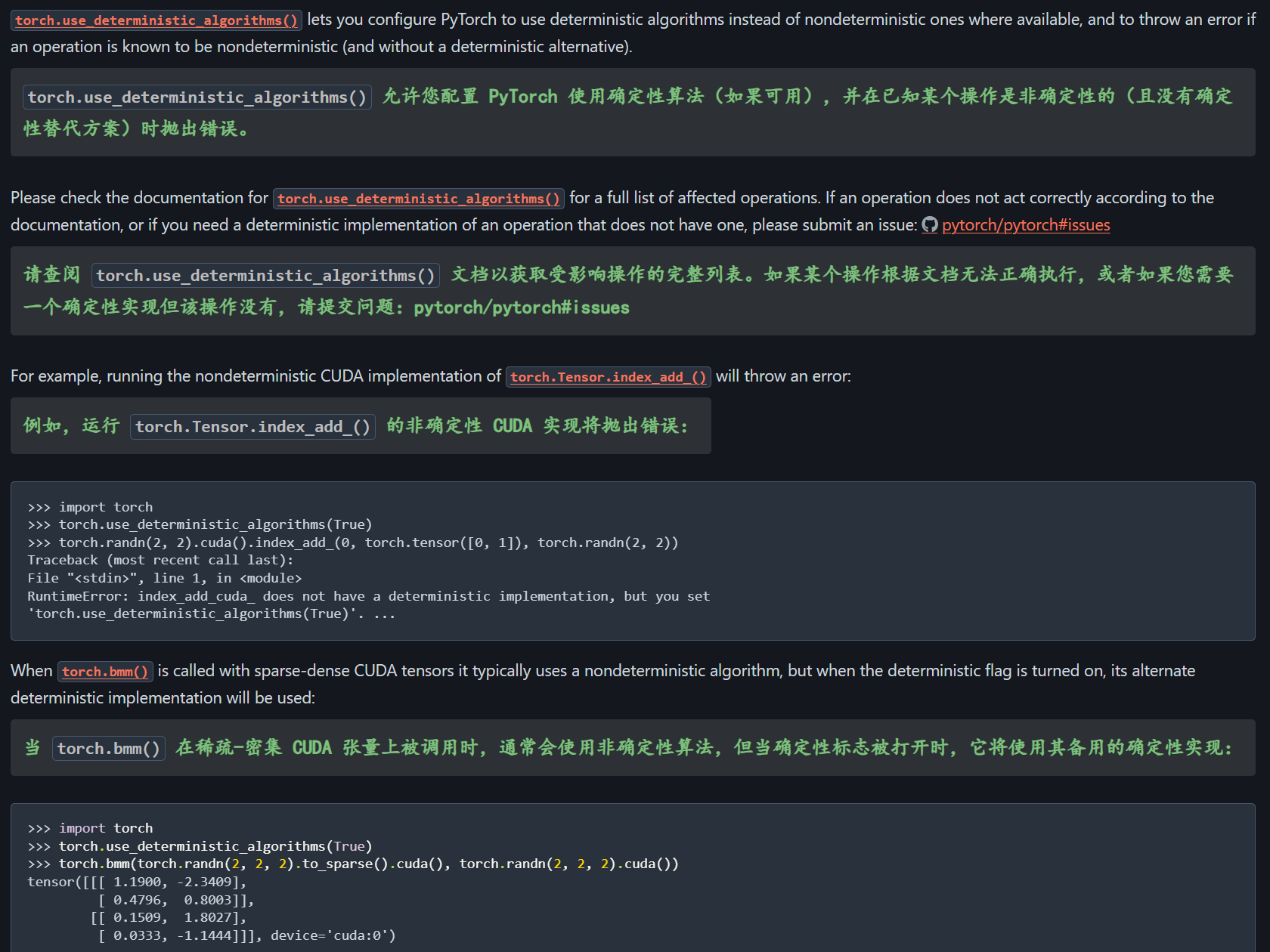
python
# 这两个搭配卷积基准测试确定性, 来选择相同的算法
torch.use_deterministic_algorithms(True)
torch.backends.cudnn.deterministic = True
# 也就是说:搭配使用
torch.use_deterministic_algorithms(True)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# 按照官方说法,第1个的搭配使用方案会更广谱性一点
torch.use_deterministic_algorithms(True)
torch.backends.cudnn.benchmark = False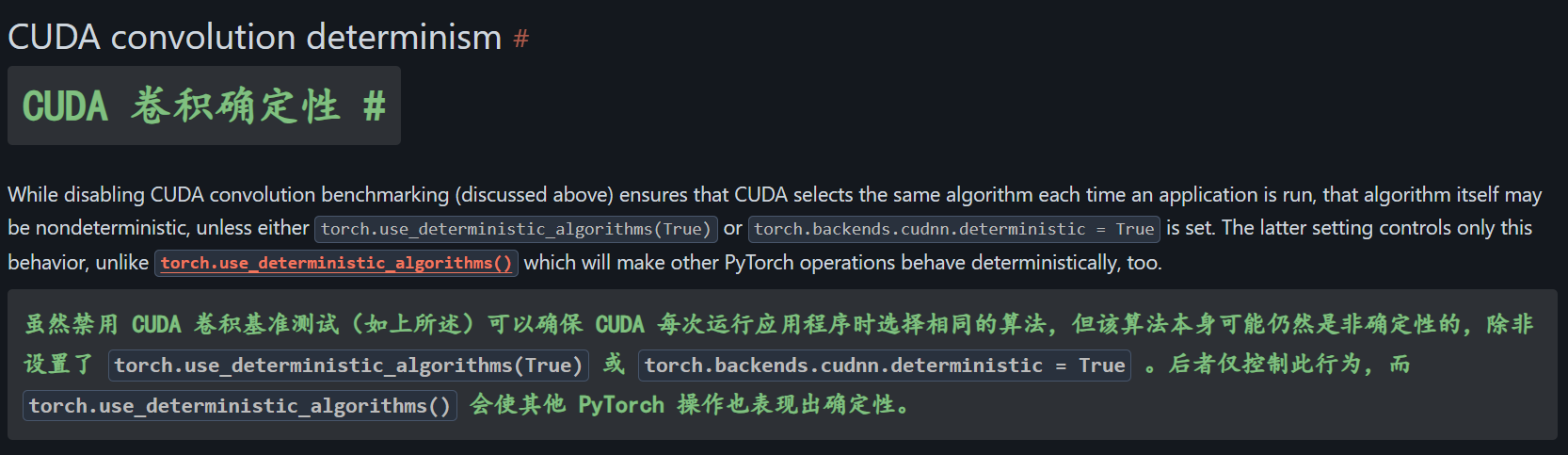
一些特殊的网络架构需要具体情况具体API分析
填充未初始化的内存
python
torch.utils.deterministic.fill_uninitialized_memory = True
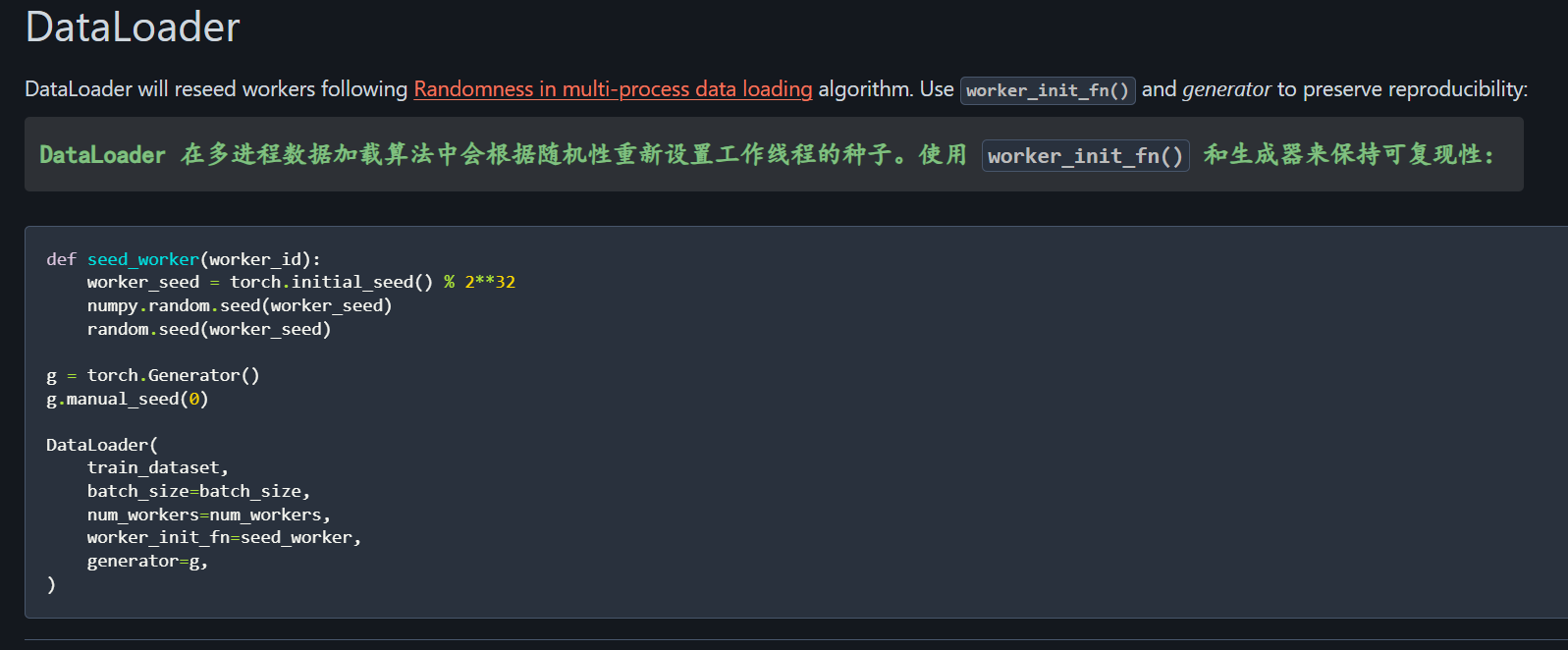
DataLoader
主要是就是多进程的随机性,
PyTorch 的 DataLoader 用多进程(num_workers > 0)加载数据时,每个子进程会自动重新随机种子,导致每次运行读取的数据顺序不一样,训练结果不可复现。
官方给出的代码示例,主要是,每个子进程启动时,都会执行 seed_worker:
- 用 PyTorch 内部初始种子生成一个稳定种子
- 同时固定
numpy和 Python 内置random的种子,这样所有子进程里的随机行为都被固定,每次运行加载的数据顺序完全一致。
python
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
numpy.random.seed(worker_seed)
random.seed(worker_seed)
g = torch.Generator()
g.manual_seed(0)
DataLoader(
train_dataset,
batch_size=batch_size,
num_workers=num_workers,
worker_init_fn=seed_worker,
generator=g,
)
另外关于dataloader这里,有参考讨论:https://discuss.pytorch.org/t/set-seed-doesnt-work/224393
一点思考
一些狂野的尝试:
https://discuss.pytorch.org/t/fix-random-seed-in-training-validation-and-test-generator/137032
如果我们将前面所涉及提到的随机数种子方案都列了个遍(主要的)
python
jj=0
np.random.seed(jj)
random.seed(jj)
torch.manual_seed(jj)
torch.cuda.manual_seed_all(jj)
torch.cuda.manual_seed(jj)
# torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# torch.use_deterministic_algorithms(True)
torch.backends.cudnn.enabled = False
torch.backends.cudnn.benchmark = False
os.environ['PYTHONHASHSEED'] = str(jj)
os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8'
Furthermore,the Dataloader:
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2 ** 32
np.random.seed(worker_seed)
random.seed(worker_seed)
data_loader= DataLoader(train_sample, batch_size=20,num_workers=0,worker_init_fn=seed_worker)
python
seed = 1
def seed_worker(worker_id):
import torch
import random
worker_seed = torch.initial_seed() % 2**32
np.random.seed(worker_seed)
random.seed(worker_seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
params = {'batch_size': batch_size,
'shuffle': shuffle,
'num_workers': num_workers,
'worker_init_fn': seed_worker}
training_set = Dataset(partition['train'], labels)
training_generator = torch.utils.data.DataLoader(training_set, **params)
validation_set = Dataset(partition['validation'], labels)
validation_generator = torch.utils.data.DataLoader(validation_set, **params)会看到一些其他的常见操作:
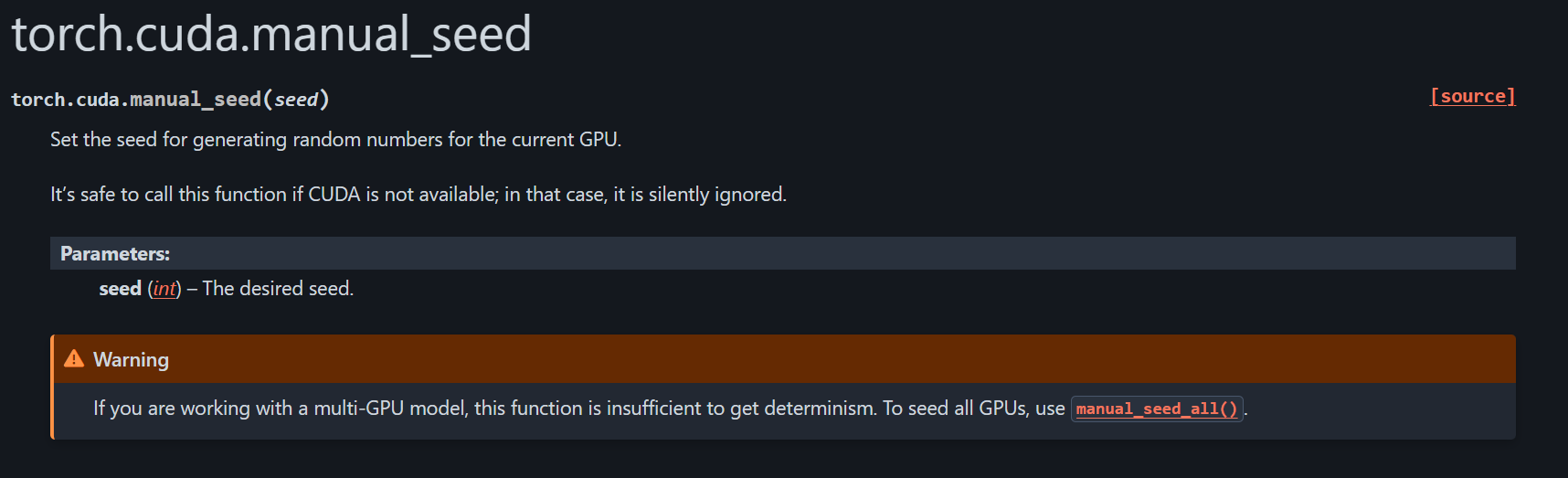
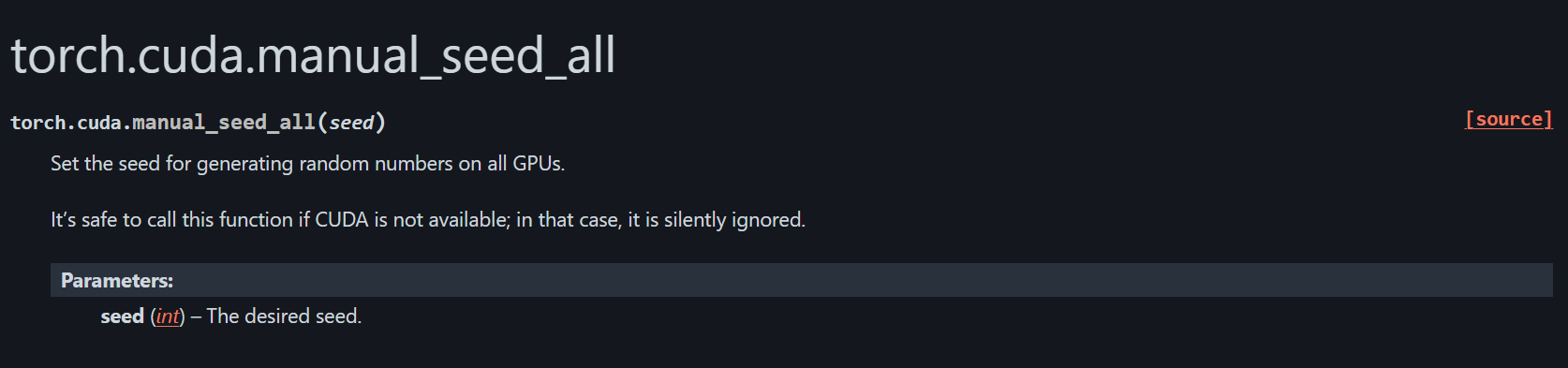
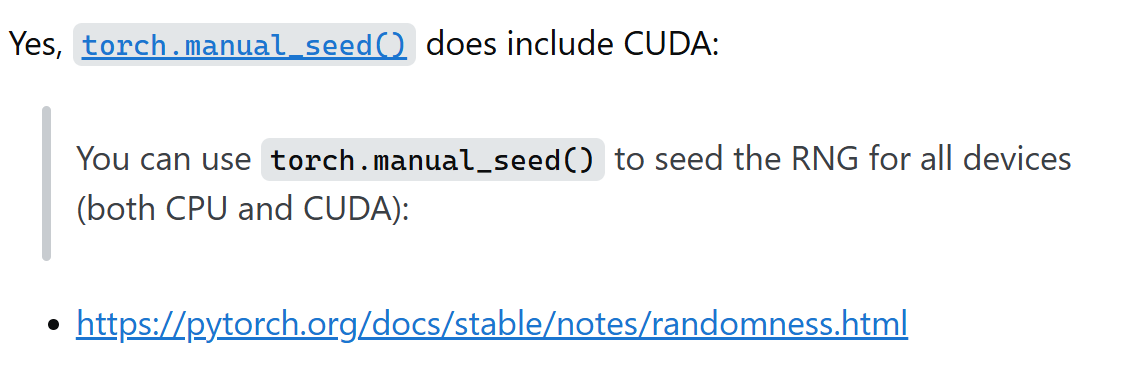
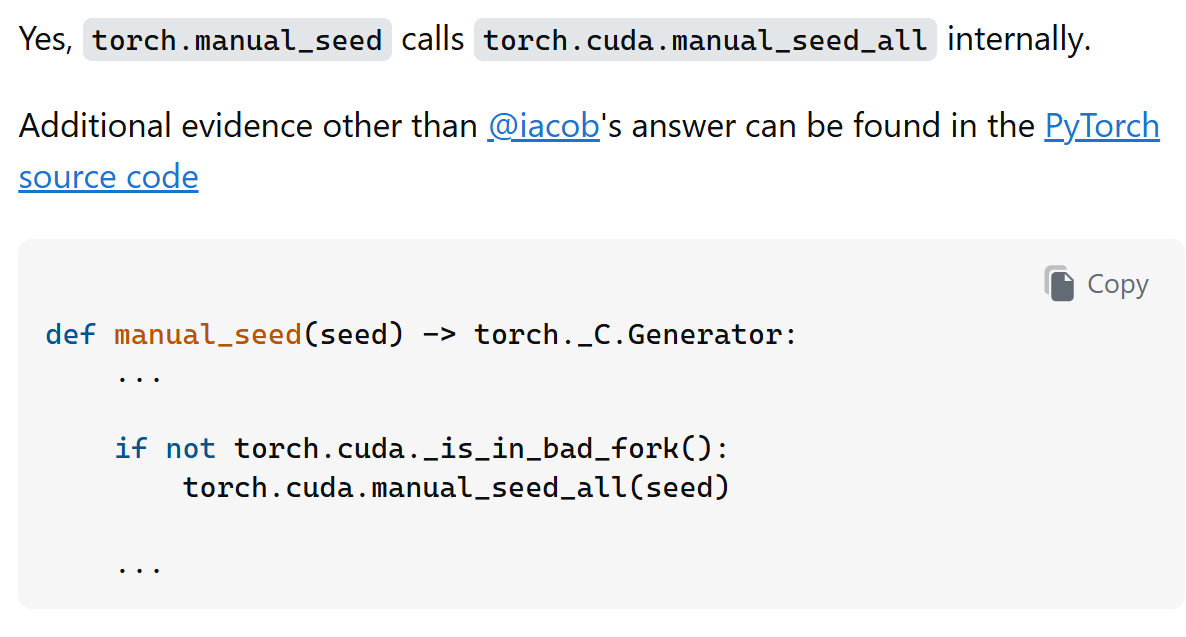
也就是除了manual_seed之外,cuda层面的manual_seed,
如果torch.manual_seed是在所有cpu、gpu设备上都兼容的,那么我们还需要设置cuda吗?
https://docs.pytorch.org/docs/stable/generated/torch.manual_seed.html
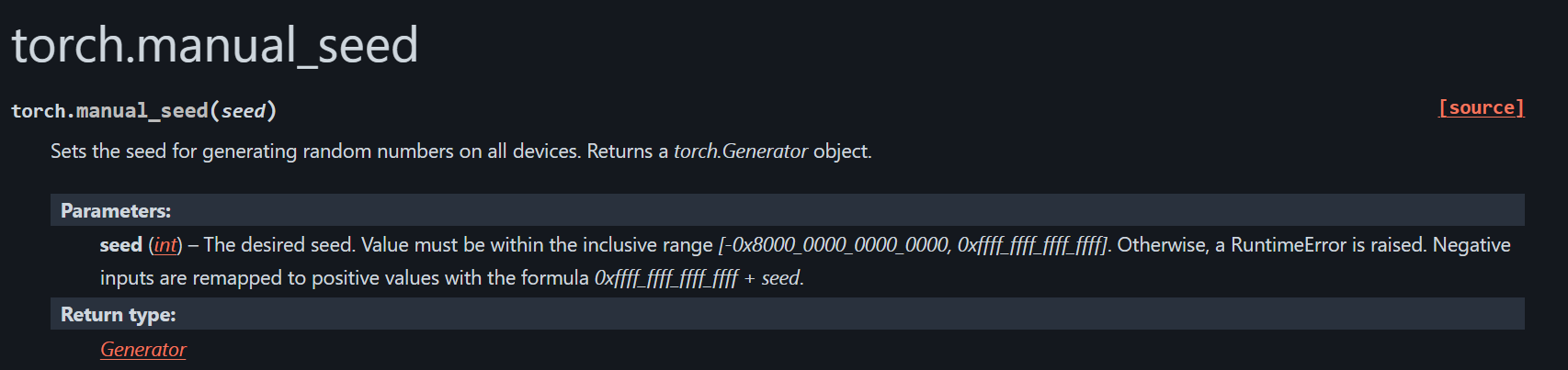
https://docs.pytorch.org/docs/stable/generated/torch.cuda.manual_seed.html
🌟 我们可以写一个更一般的函数,
python
import random
import numpy as np
import torch
import os
def seed_everything(seed:int = 2026):
random.seed(seed) # python random模块
np.random.seed(seed) # numpy 模块
torch.manual_seed(seed) # pytorch随机数生成
torch.cuda.manual_seed(seed) # ⚠️ 与上面冗余
torch.cuda.manual_seed_all(seed) # 多gpu, 仍需设置
os.environ["PYTHONHASHSEED"] = str(seed) # 强制让 Python 的哈希算法(hash)每次运行都用同一个随机种子,
让字典、集合、类的哈希结果完全固定、可复现
# torch.backends.cudnn.benchmark = False /禁用基准测试功能会导致 cuDNN(CUDA卷积操作) 确定性选择算法, 但是性能下降
# torch.backends.cudnn.deterministic = True / 搭配前面cuDNN算法确定性
# torch.use_deterministic_algorithms(True) /避免使用非确定性算法, 无必要慎用
# 关于dataloader, 我们以官方文档为准, 具体split操作可以参考上面的example
def seed_worker(worker_id):
worker_seed = torch.initial_seed() % 2**32
numpy.random.seed(worker_seed)
random.seed(worker_seed)
g = torch.Generator()
g.manual_seed(0)
DataLoader(
train_dataset,
batch_size=batch_size,
num_workers=num_workers,
worker_init_fn=seed_worker,
generator=g,
)
python
# 1个更简短的版本
import os
import random
import numpy as np
import torch
def set_seed(seed):
"""
Set the random seed for reproducibility.
"""
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False其实全文写到这里,我们会发现,没有一个100%、完美覆盖全框架的伪随机数生成的种子固定方案。
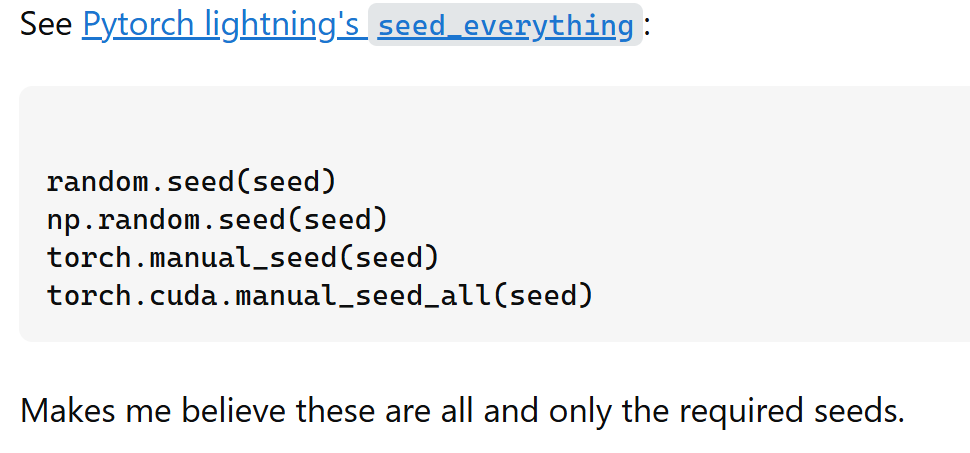
有很多第三方,非torch官方的库,他们设置seed的方式也不近相同。
所以,我们更多应该思考的是:随机种子的设定对大部分的模型会不会产生特别大的实质性影响,如果神经网络更多会和迭代次数、学习率等固定参数的调参相关,那么我们是否可以将专注力转移到更核心的地方。
还有一些问题?
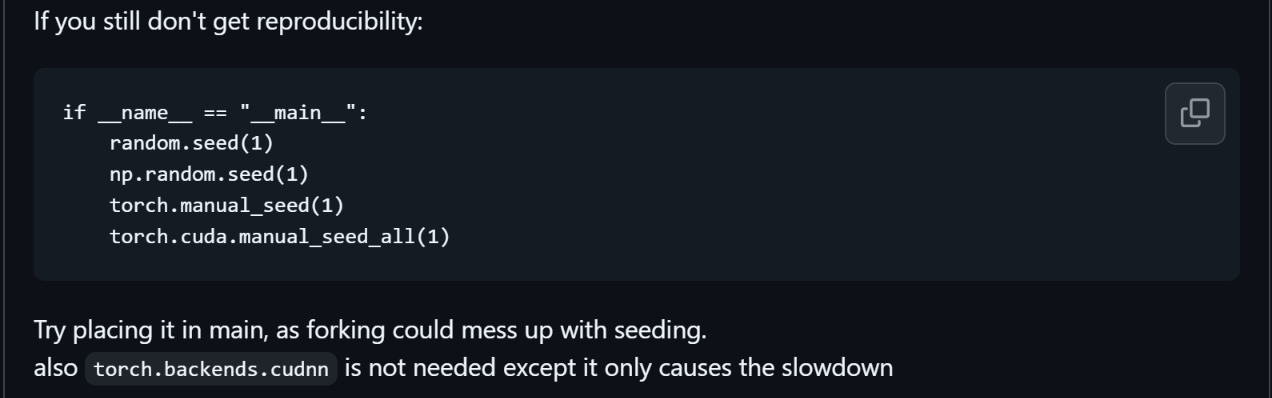
就是我应该在什么地方设置随机数固定的操作,
是import前的各个模块文件,
还是执行文件import后、具体代码前,
还是主文件/执行文件的main标识符后?
⚠️ 这个问题我还没有深入调研过,暂且扔个链接,先存档,等日后有空遇到这个问题再提笔写一写。
参考:https://github.com/pytorch/pytorch/issues/7068
参考
几篇有趣的博客,没有放上来,可以参考:
https://towardsdatascience.com/optimizing-the-random-seed-99a90bd272e/

