一、DNN模块是什么
OpenCV DNN模块是一个用于深度神经网络推理的模块,它允许用户在OpenCV中加载和运行预训练的深度学习模型。
主要特点为:
1、轻量: OpenCV 的深度学习模块只实现了模型推理功能,不涉及模型训练,这使得相关程序非常精简,加速了安装和编译过程。
2、外部依赖性低:重新实现一遍深度学习框架使得 DNN 模块对外部依赖性极低,极大地方便了深度学习应用的部署。
3、方便:在原有 OpenCV 开发程序的基础上,通过 DNN 模块可以非常方便地加入对神经网络推理的支持。
4、 集成:若网络模型来自多个框架,如一个来自 TensorFlow,另外一个来自 Caffe,则 DNN 模块可以方便地对网络进行整合。
5、通用性:DNN 模块提供了统一的接口来操作网络模型,内部做的优化和加速适用于所有网络模型格式,支持多种设备和操作系统。
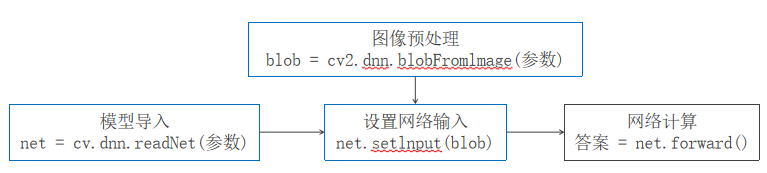
DNN 模块使用的主要函数及流程:
二、风格迁移是什么
风格迁移(Style Transfer)是一种计算机视觉和图像处理技术,它允许将一个图像的艺术风格应用到另一个图像上,从而创建出一个新的图像,同时保留了原始图像的内容,但采用了第二个图像的风格。这个技术的灵感来源于绘画和艺术领域,其中画家可以将不同风格的绘画技巧应用于同一个画布上,创造出具有独特风格的作品。
风格迁移的实现通常基于深度学习技术,特别是卷积神经网络,风格迁移主要包含:
内容图像: 这是你希望保留内容的原始图像,例如一张风景照片或一张照片中的人物。
风格图像: 这是你希望应用的艺术风格的图像,例如一幅著名画家的油画作品或一种艺术风格的图案。
生成图像: 这是最终生成的图像,它同时包含了内容图像的内容和风格图像的风格。
风格迁移的步骤如下:
1、使用卷积神经网络,通常是预训练的卷积神经网络(如VGG网络),提取内容图像的内容特征和风格图像的风格特征。这通常涉及到在网络的不同层次上计算特征表示。
2、定义一个损失函数,该函数包括两个部分:内容损失和风格损失。内容损失用于确保生成图像与内容图像相似,而风格损失用于确保生成图像的风格与风格图像匹配。
3、最小化损失函数,通过梯度下降或其他优化方法来调整生成图像的像素值,以使损失最小化。这将导致生成图像逐渐融合内容和风格。
4、重复上述过程,直到生成图像的质量满足要求,或者损失足够小。
三、核心函数讲解
3.1 图像预处理------cv2.dnn.blobFromImage()
python
blob = cv2.dnn.blobFromImage(
image, # 输入图像
scalefactor, # 表示对图像内的数据进行缩放的比例因子。具体运算是每个像素值*scalefactor,该值默认为 1。
size, # 将图像缩放到模型要求的输入尺寸(宽度,高度)
mean, # 减去数据集的均值,用于图像标准化
swapRB, # 是否将图像从 BGR → RGB
crop, # 缩放后是否居中裁剪
)参数介绍:
|-------------|---------------------------------------|---------|---------------------------------------------------------------|
| 参数 | 类型 | 默认值 | 说明 |
| image | ndarray | | 输入图像,OpenCV读取的BGR格式图像 |
| scalefactor | float | 1.0 | 像素值缩放系数: pixel = pixel × scalefactor 常用值:1/255.0(归一化到0-1) |
| size | tuple(宽度, 高度) | | 输出blob的(width, height),必须是模型要求的输入尺寸 |
| mean | tuple[float, float, float] 或 list | (0,0,0) | BGR 三个通道的均值,各通道要减去的均值: pixel = pixel - mean |
| swapRB | bool | False | 是否交换R和B通道: True:BGR→RGB False:保持BGR |
| crop | bool | False | 是否中心裁剪: True:调整大小后中心裁剪 False:直接resize |
返回值:
blob:4D数组,格式:(1, C, H, W)
1:batch size(单张图像)
C:通道数(RGB=3)
H:高度
W:宽度
补充:
若想批量处理图像则使用cv2.dnn.blobFromImages()
此函数接收图片列表,N = 你传入的图片张数
3.2 模型导入------cv2.dnn.readNet()
python
net = cv2.dnn.readNet(
model,
config = "",
framework = ""
)参数介绍:
model:模型权重文件(训练好的参数)
config:一组超参数和设置, 帮助控制模型的行为, 包括网络架构、训练过程、优化器等内容。
framework:DNN框架, 可省略, DNN模块会自动推断框架种类。
返回值:
net:返回网络模型对象。
python
# 支持的模型格式有Torch,TensorFlow,Caffe,DartNet, ONNX和Intel OpenVINO
# model参数 | config参数 | framework参数 | 函数名称
# *.caffemodel | *.prototxt caffe readNetFromCaffe
# *.pd | *.pbtxt tensorflow readNetFromTensorFlow
# *.t7 | *.net torch readNetFromTorch
# *.weight | *.cfg darknet readNetFromDarknet
# *.bin | *.xml dldt readNetFromModelOptimizer
# *.onnx | onnx readNetFromONNX为了避免上述繁杂的专用函数,可以统一使用cv2.dnn.readNet(),
3.3其他的重要函数
python
# 设置输入
net.setInput(blob, name="input") # name可选,指定输入层名称
# 前向传播
output = net.forward(outputName=None) # 输出指定层的结果
# 获取网络信息
layer_names = net.getLayerNames() # 获取所有层名
unconnected_layers = net.getUnconnectedOutLayers() # 获取输出层索引四、注意事项
1、通道顺序:OpenCV默认BGR,许多模型期望RGB,注意swapRB参数
2、归一化:确保预处理与模型训练时一致
3、尺寸匹配:输入尺寸必须与模型要求一致
4、均值减法:如果模型训练时进行了均值减法,推理时也要做
5、输出解析:不同模型的输出格式不同,需要根据具体任务解析
五、实例
5.1 对图片进行风格迁移
图片:

python
import cv2
# 读取输入图像
image = cv2.imread(r'..\data\Amiya.jpeg')
# 显示输入图像
cv2.imshow('yuan tu', image)
cv2.waitKey(0)
'''-----------图片预处理----------------'''
(h, w) = image.shape[:2] # 获取图像尺寸
# 函数cv2.dnn.blobFromImage:实现图像预处理,从原始图像构建一个符合人工神经网络输入格式的四维块。
# blob = cv2.dnn.blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None)
# 参数:
# image:表示输入图像。
# scalefactor:表示对图像内的数据进行缩放的比例因子。具体运算是每个像素值*scalefactor,该值默认为 1。
# size:用于控制blob的宽度、高度。
# mean:表示从每个通道减去的均值。 (0, 0, 0): 表示不进行均值减法。即, 不对图像的B、G、R通道进行任何减法操作。
# 若输入图像本身是B、G、R通道顺序的, 并且下一个参数swapRB值为True,
# 则mean值对应的通道顺序为R、G、B。 opencv BGR RGB
# swapRB:表示在必要时交换通道的R通道和B通道。一般情况下使用的是RGB通道。而OpenCV通常采用的是BGR通道。
# 因此可以根据需要交换第1个和第3个通道。该值默认为 False。
# crop:布尔值, 如果为 True, 则在调整大小后进行居中裁剪。
# 返回值: blob: 表示在经过缩放、裁剪、减均值后得到的符合人工神经网络输入的数据。该数据是一个四维数据,
# 布局通常使用N(表示batch size)、C(图像通道数,如RGB图像具有三个通道)、H(图像高度)、W(图像宽度)表示
blob = cv2.dnn.blobFromImage(image, scalefactor=1, size=(w, h), mean=(0, 0, 0), swapRB=False, crop=False)
net=cv2.dnn.readNetFromTorch(r'..\data\model\la_muse.t7')
# 设置神经网络的输入
net.setInput(blob)
# 对输入图像进行前向传播, 得到输出结果
out = net.forward()
# 将输出结果转换为合适的格式
# out是四维的: B*C*H*W
# B:batch图像数量(通常为1), C:channels通道数, H: height高度、W: width宽度
# ======输出处理========
# 重塑形状(忽略第1维), 4维变3维
# 调整输出out的形状,模型推理输出out是四维BCHW形式的, 调整为三维CHW形式
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
#对输入的数组(或图像)进行归一化处理,使其数值范围在指定的范围内
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度
result = out_new.transpose(1, 2, 0)
# 显示转换后的图像
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()结果:

5.2对视频或摄像头进行风格迁移
python
import cv2
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print('Cannot open video')
exit()
global net
net = cv2.dnn.readNetFromTorch(r'..\data\model\la_muse.t7')
while True:
ret, frame = cap.read()
if not ret:
break
frame = cv2.resize(frame,None,fx=0.5, fy=0.5)
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, scalefactor=1, size=(w, h), mean=(0, 0, 0), swapRB=False, crop=False)
# 设置神经网络的输入
net.setInput(blob)
# 对输入图像进行前向传播, 得到输出结果
out = net.forward()
# 将输出结果转换为合适的格式
# out是四维的: B*C*H*W
# B:batch图像数量(通常为1), C:channels通道数, H: height高度、W: width宽度
# ======输出处理========
# 重塑形状(忽略第1维), 4维变3维
# 调整输出out的形状,模型推理输出out是四维BCHW形式的, 调整为三维CHW形式
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
# 对输入的数组(或图像)进行归一化处理,使其数值范围在指定的范围内
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度
result = out_new.transpose(1, 2, 0)
# 显示转换后的图像
cv2.imshow('Stylized Image', result)
if cv2.waitKey(60) == 27:
break
cap.release()
cv2.destroyAllWindows()