目录
[1 认识ELF文件](#1 认识ELF文件)
[1.1 ELF文件类型](#1.1 ELF文件类型)
[1.2 ELF文件结构](#1.2 ELF文件结构)
[1.2.1 ELF Header](#1.2.1 ELF Header)
[1.2.2 Section Header Table](#1.2.2 Section Header Table)
[1.2.3 Section](#1.2.3 Section)
[1.2.4 Program Header Table](#1.2.4 Program Header Table)
[2 ELF形成到加载轮廓](#2 ELF形成到加载轮廓)
[2.1 ELF形成可执行](#2.1 ELF形成可执行)
[2.2 ELF可执行文件加载](#2.2 ELF可执行文件加载)
[3 链接与加载](#3 链接与加载)
[3.1 静态链接](#3.1 静态链接)
[3.2 进程加载动态库](#3.2 进程加载动态库)
[3.3 进程间加载动态库](#3.3 进程间加载动态库)
[3.4 动态链接](#3.4 动态链接)
[3.4.1 程序怎么与动态库映射起来的](#3.4.1 程序怎么与动态库映射起来的)
[3.4.2 程序怎么进⾏库函数调⽤](#3.4.2 程序怎么进⾏库函数调⽤)
[3.4.3 全局偏移量表------GOT](#3.4.3 全局偏移量表——GOT)
引入
思考:
- ⼀个ELF程序,在没有被加载到内存的时候,有没有地址呢?
- 进程mm_struct、vm_area_struct在进程刚刚创建的时候(虚拟地址空间),初始化数据从哪⾥来的?
问题一
⼀个ELF程序,在没有被加载到内存的时候,本来就有地址,当代计算机⼯作的时候,都采⽤"平坦模式"进⾏⼯作
平坦模式:
- 连续的虚拟地址空间
- 进程看到的虚拟地址空间是线性的,从 0x00000000 到 0xFFFFFFFF (32 位)或 0x0000000000000000 到 0xFFFFFFFFFFFFFFFF(64 位)。
- 代码、数据、堆、栈等全部通过统一的虚拟地址访问,无需分段机制。
- 直接使用偏移地址
- 在平坦模式下,指令中的内存地址(如 mov eax, 0x8048000 )直接对应虚拟地址,无需计算 起始地址 + 偏移。
- 由 MMU 和页表管理物理内存
- CPU 通过内存管理单元(MMU)和页表(Page Table)将虚拟地址转换为物理地址。
- 分段机制仍然存在(出于兼容性),但通常设置为所有段的基址为 0,界限为最大值,从而等效于平坦模式。
问题二
进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从ELF各个segment来,每个segment有⾃⼰的起始地址和⾃⼰的⻓度,⽤来初始化内核结构vm_area_struct中的start, end等范围数据,另外在⽤详细地址,填充⻚表
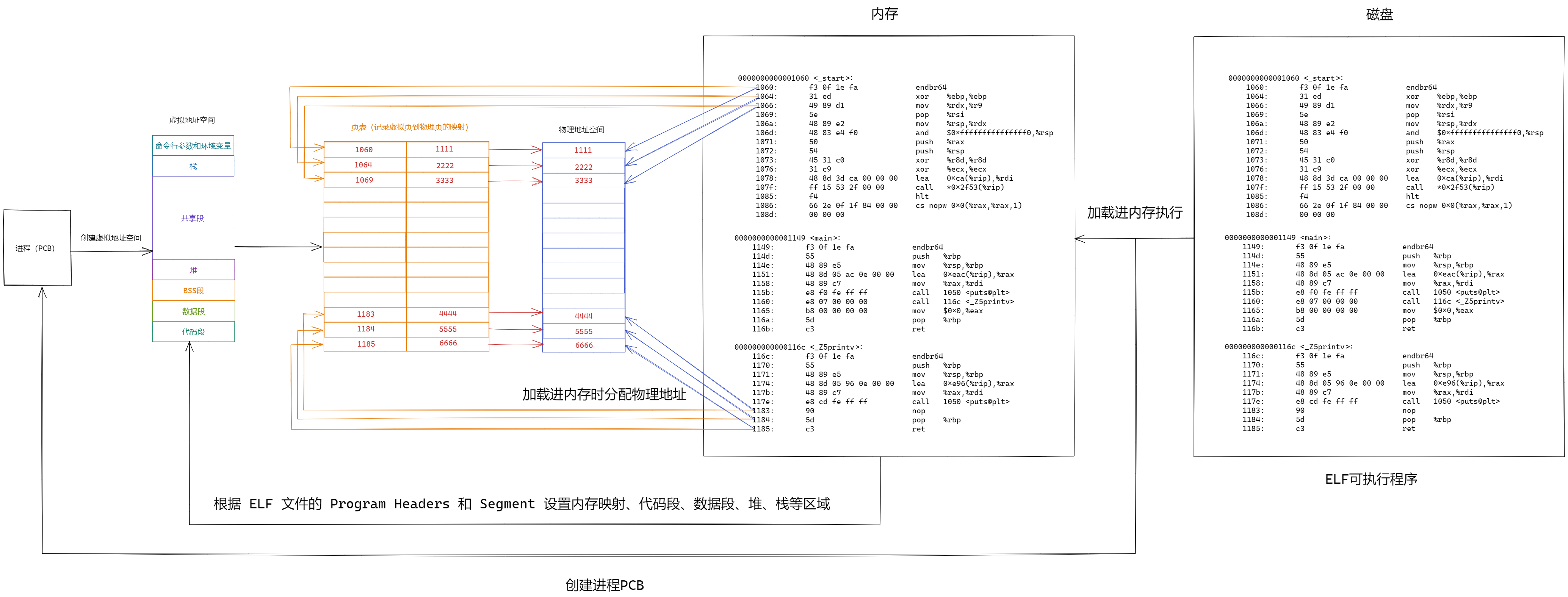
虚拟地址机制,不光光OS要⽀持,编译器也要⽀持
1 认识ELF文件
ELF(Executable and Linkable Format)是Unix/Linux系统中最常见的二进制文件格式,用于可执行文件、目标文件、共享库和核心转储
1.1 ELF文件类型
- 可执行文件(Executable) :可直接运行的程序(如**/bin/ls**)。
- 共享对象文件(Shared Object) :动态链接库(如**.so**文件)。
- 目标文件(Relocatable) :编译生成的**.o**文件,需进一步链接。
- 核心转储文件(Core Dump):程序崩溃时的内存快照。
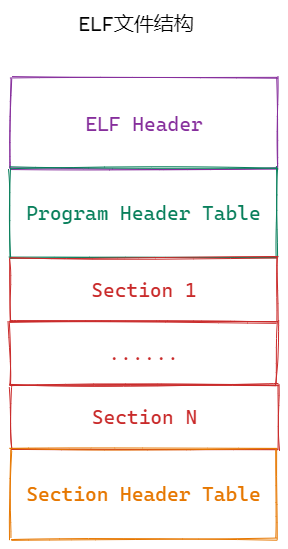
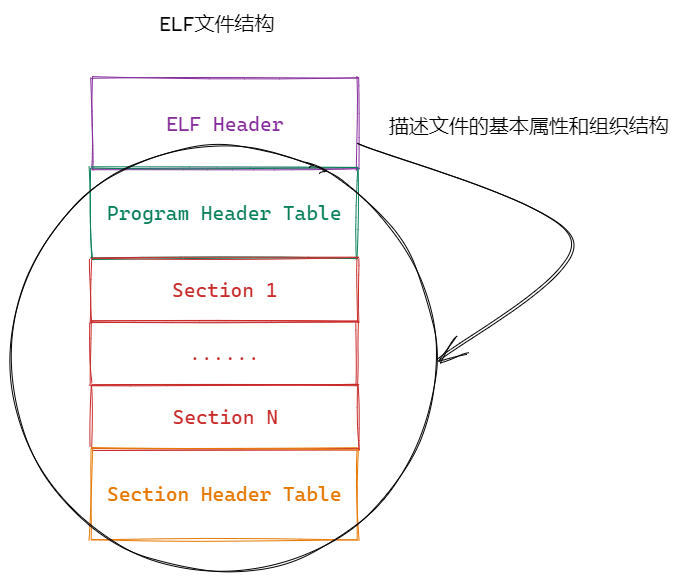
1.2 ELF文件结构
ELF文件由四部分组成:
- ELF头(ELF header):描述⽂件的主要特性。其位于⽂件的开始位置,它的主要⽬的是定位⽂件的其他部分。
- 程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。表⾥记着每个段的开始的位置和位移(offset)、⻓度,毕竟这些段,都是紧密的放在⼆进制⽂件中,需要段表的描述信息,才能把他们每个段分割开。
- 节头表(Section header table) :包含对节(sections)的描述。
- 节(Section ):ELF⽂件中的基本组成单位,包含了特定类型的数据。ELF⽂件的各种信息和数据都存储在不同的节中,如代码节存储了可执⾏代码,数据节存储了全局变量和静态数据等。
1.2.1 ELF Header
ELF 文件的 ELF Header 是整个文件的核心元数据,位于文件开头(偏移 0x0),用于描述文件的基本属性和组织结构
(1)ELF Header 结构:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT]; // Magic 和标识信息
Elf64_Half e_type; // 文件类型(可执行、共享库等)
Elf64_Half e_machine; // CPU 架构
Elf64_Word e_version; // ELF 版本
Elf64_Addr e_entry; // 程序入口地址(虚拟地址)
Elf64_Off e_phoff; // Program Header Table 的文件偏移
Elf64_Off e_shoff; // Section Header Table 的文件偏移
Elf64_Word e_flags; // 处理器特定标志
Elf64_Half e_ehsize; // ELF Header 自身大小
Elf64_Half e_phentsize; // Program Header 条目大小
Elf64_Half e_phnum; // Program Header 条目数量
Elf64_Half e_shentsize; // Section Header 条目大小
Elf64_Half e_shnum; // Section Header 条目数量
Elf64_Half e_shstrndx; // 节名字符串表的索引
} Elf64_Ehdr;(2)查看 ELF Header
使用 readelf -h 或 xxd查看:
readelf -h /bin/ls(3)示例
lz@VM-8-15-ubuntu:~/learn/lib$ readelf -h a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x4025e0
Start of program headers: 64 (bytes into file)
Start of section headers: 139024 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 11
Size of section headers: 64 (bytes)
Number of section headers: 27
Section header string table index: 261.2.2 Section Header Table
ELF 文件的 Section Header Table(节头表) 是描述文件中所有 节(Section) 的关键数据结构 ,如名称、类型、内存地址、文件偏移、权限 等。主要用于链接和调试阶段
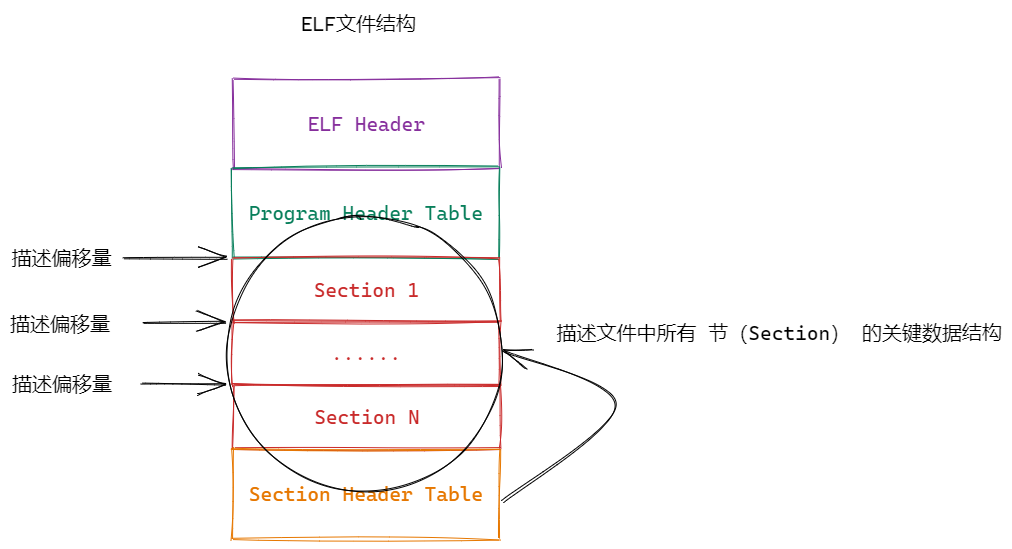
(1)Section Header Table 结构
typedef struct {
Elf64_Word sh_name; // 节名在.shstrtab中的偏移(字符串索引)
Elf64_Word sh_type; // 节类型(代码、数据、符号表等)
Elf64_Xword sh_flags; // 节属性(可读/写/执行等)
Elf64_Addr sh_addr; // 节在内存中的虚拟地址(若需加载)
Elf64_Off sh_offset; // 节在文件中的偏移量
Elf64_Xword sh_size; // 节的大小(字节数)
Elf64_Word sh_link; // 关联的其他节索引(如符号表关联字符串表)
Elf64_Word sh_info; // 附加信息(依赖节类型)
Elf64_Xword sh_addralign; // 地址对齐约束(如16字节对齐)
Elf64_Xword sh_entsize; // 条目大小(若节是表格,如符号表条目大小)
} Elf64_Shdr;(2)查看 Section Header Table
使用 readelf -S 查看
readelf -S /bin/ls(3)示例
lz@VM-8-15-ubuntu:~/learn/lib$ readelf -S a.out
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
// ..........
[30] .shstrtab STRTAB 0000000000000000 00003608
000000000000011a 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)1.2.3 Section
ELF 文件的 Section(节) 是组成二进制文件的基本逻辑单元 ,每个节存储特定类型的数据,如代码、数据、符号表、全局变量、字符串常量等
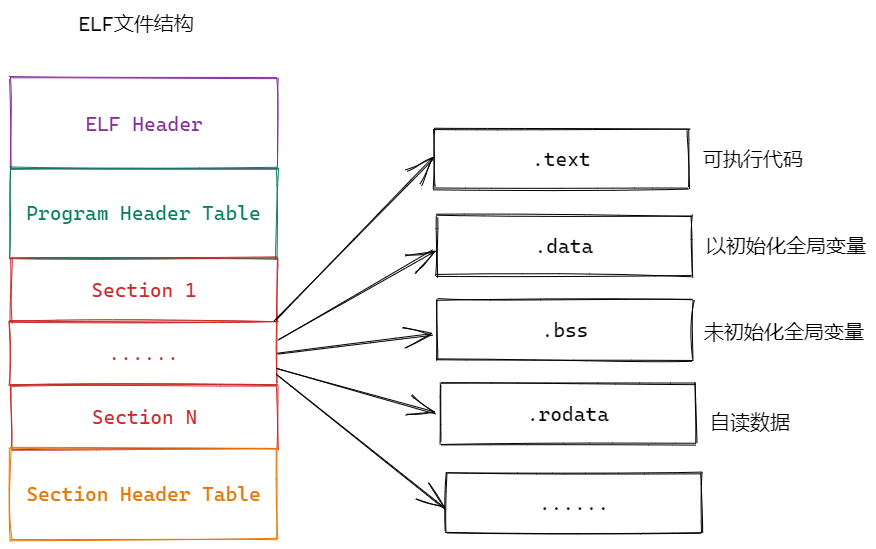
(1)查看 Section
使用 readelf -S 查看
readelf -S /bin/ls(2)示例
lz@VM-8-15-ubuntu:~/learn/lib$ readelf -S a.out
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
// ..........
[30] .shstrtab STRTAB 0000000000000000 00003608
000000000000011a 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)1.2.4 Program Header Table
ELF 文件的 Program Header Table(程序头表 ) 是操作系统加载和执行程序时使用的关键数据结构,它定义了如何将文件的 段(Segments) 映射到内存
我们知道操作系统在进行IO时是以4KB为单位进行读取,而我们的每一段节(Section)的大小不一定是4KB大小的,因此就需要对节(Section)进行一定的规则进行合并为系统读取的大小。Program Header Table(程序头表)就对节(Section)的合并进行的规定
合并的节(Section)就称为段(Segments)
(1)Program Header Table 结构
typedef struct {
Elf64_Word p_type; // 段类型(LOAD、DYNAMIC等)
Elf64_Word p_flags; // 权限标志(R/W/X)
Elf64_Off p_offset; // 段在文件中的偏移
Elf64_Addr p_vaddr; // 段在内存中的虚拟地址
Elf64_Addr p_paddr; // 物理地址(通常与虚拟地址相同)
Elf64_Xword p_filesz; // 段在文件中的大小
Elf64_Xword p_memsz; // 段在内存中的大小(可能包含.bss)
Elf64_Xword p_align; // 内存对齐方式
} Elf64_Phdr;(2)查看 Program Header Table
readelf -l /bin/ls(3)示例
lz@VM-8-15-ubuntu:~/learn/lib$ readelf -l a.out
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000400040 0x0000000000400040
0x0000000000000268 0x0000000000000268 R 0x8
INTERP 0x00000000000002a8 0x00000000004002a8 0x00000000004002a8
0x000000000000001c 0x000000000000001c R 0x1
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x000000000001e4a8 0x000000000001e4a8 R E 0x200000
LOAD 0x000000000001e4e0 0x000000000061e4e0 0x000000000061e4e0
0x00000000000013e8 0x0000000000002578 RW 0x200000
DYNAMIC 0x000000000001e4f8 0x000000000061e4f8 0x000000000061e4f8
0x0000000000000200 0x0000000000000200 RW 0x8
NOTE 0x00000000000002c4 0x00000000004002c4 0x00000000004002c4
0x0000000000000044 0x0000000000000044 R 0x42 ELF形成到加载轮廓
2.1 ELF形成可执行
将C/C++源码编译形成目标文件(.o),而目标文件(.o)的内部格式就是ELF格式的
链接的本质:将多个目标文件(.o)的节(Section)进行合并形成节(Section)
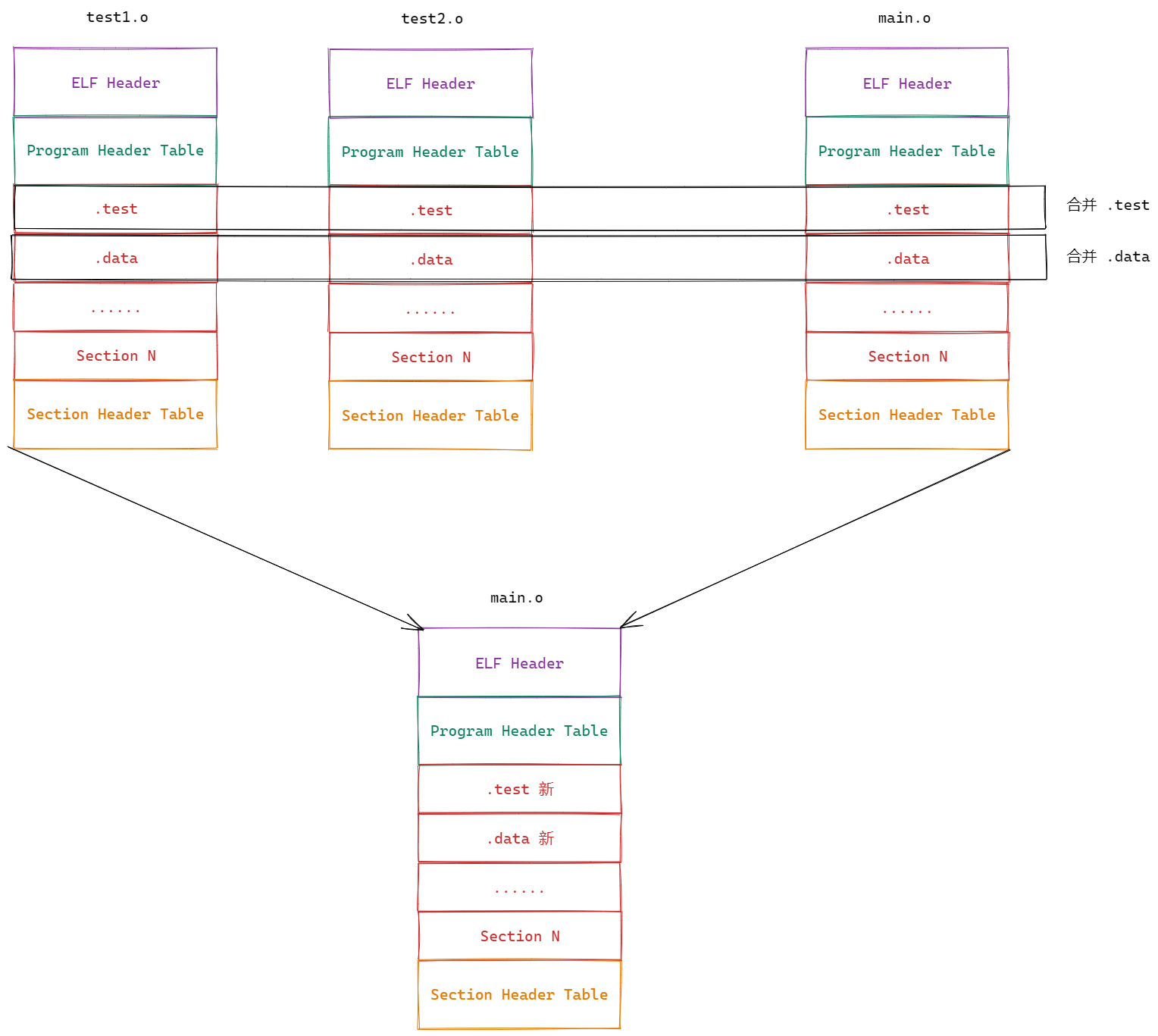
实际合并是在链接时进⾏的,但是并不是这么简单的合并,也会涉及对库合并,此处不做过多追究
2.2 ELF可执行文件加载
⼀个ELF可执行文件会有多种不同的Section,在加载到内存的时候,进⾏Section合并,形成segment
合并原则:
相同属性,⽐如:可读,可写,可执⾏,需要加载时申请空间等
很显然,这个合并⼯作也已经在形成ELF的时候,合并⽅式已经确定了,具体合并原则被记录在了ELF的 程序头表(Program header table) 中
为什么要进行Section合并?
我们知道操作系统在进行IO时是以4KB为单位进行读取,而我们的每一段节(Section)的大小不一定是4KB大小的,因此就需要对节(Section)进行一定的规则进行合并为系统读取的大小。Program Header Table(程序头表)就对节(Section)的合并进行的规定
假设⻚⾯⼤⼩为4096字节(内存块基本⼤⼩,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占⽤3个数据块,⽽合并后,它们只需2个数据块
此外,操作系统在加载程序时,会将具有相同属性的section合并成⼀个⼤的segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
3 链接与加载
3.1 静态链接
将C/C++源文件编译形成可重定向目标文件(.o)
cpp
lz@VM-8-15-ubuntu:~/learn/lib/test$ ls -l
-rw-rw-r-- 1 lz lz 88 May 27 21:33 main.cpp
-rw-rw-r-- 1 lz lz 1496 May 27 21:34 main.o
-rw-rw-r-- 1 lz lz 64 May 27 21:32 print.cpp
-rw-rw-r-- 1 lz lz 1504 May 27 21:34 print.o查看编译形成可重定向目标文件(.o)的反汇编代码
(1)main.o
cpp
lz@VM-8-15-ubuntu:~/learn/lib/test$ objdump -d main.o
main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <main+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <main+0x17>
17: e8 00 00 00 00 call 1c <main+0x1c>
1c: b8 00 00 00 00 mov $0x0,%eax
21: 5d pop %rbp
22: c3 ret(2)print.o
cpp
lz@VM-8-15-ubuntu:~/learn/lib/test$ objdump -d print.o
print.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <_Z5printv>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <_Z5printv+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <_Z5printv+0x17>
17: 90 nop
18: 5d pop %rbp
19: c3 ret
我们可以看到这⾥的 call 指令,它们分别对应之前调⽤的 printf 和 run 函数,但是你会发现他们的跳转地址都被设成了0?
在编译 hello.c 的时候,编译器是完全不知道 printf 和 run 函数的存在的,⽐如他们位于内存的哪个区块,代码⻓什么样都是不知道的。因此,编辑器只能将这两个函数的跳转地址先暂时设为0。
在链接的时候无论是自己的目标的文件(.o)还是动静态库的目标文件(.o),在加载到内存的时候,会进⾏Section合并,形成segment,这时就会根据segment修正函数调用地址
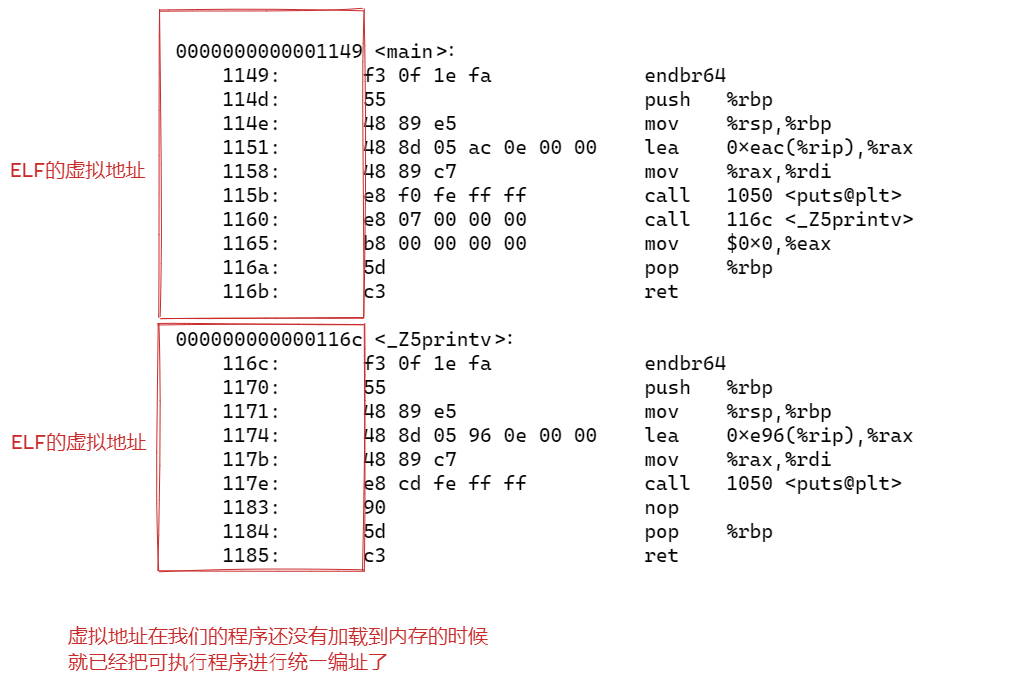
(3)链接目标文件形成可执行文件
cpp
0000000000001149 <main>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1158: 48 89 c7 mov %rax,%rdi
115b: e8 f0 fe ff ff call 1050 <puts@plt>
1160: e8 07 00 00 00 call 116c <_Z5printv>
1165: b8 00 00 00 00 mov $0x0,%eax
116a: 5d pop %rbp
116b: c3 ret
000000000000116c <_Z5printv>:
116c: f3 0f 1e fa endbr64
1170: 55 push %rbp
1171: 48 89 e5 mov %rsp,%rbp
1174: 48 8d 05 96 0e 00 00 lea 0xe96(%rip),%rax # 2011 <_IO_stdin_used+0x11>
117b: 48 89 c7 mov %rax,%rdi
117e: e8 cd fe ff ff call 1050 <puts@plt>
1183: 90 nop
1184: 5d pop %rbp
1185: c3 ret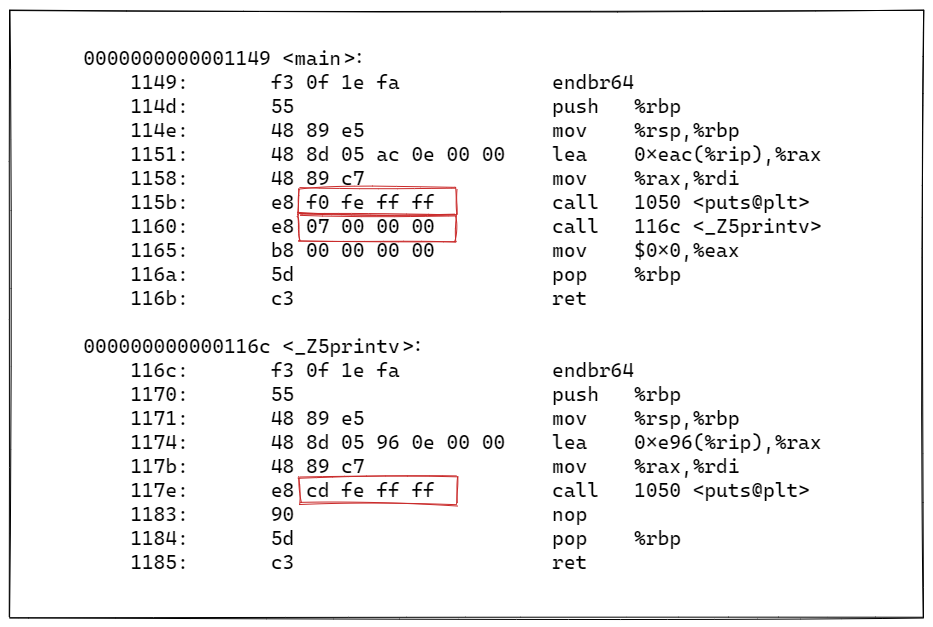
最终:
两个目标文件(.o)的代码段合并到了⼀起,并进⾏了统⼀的编址
链接的时候,会修改.o中没有确定的函数地址,在合并完成之后,进⾏相关call地址,完成代码调⽤
链接其实就是将编译之后的所有⽬标⽂件连同⽤到的⼀些静态库运⾏时库组合,拼装成⼀个独⽴的可执⾏⽂件 。其中就包括我们之前提到的地址修正,当所有模块组合在⼀起之后,链接器会根据我们的.o⽂件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从⽽修正它们的地址。这其实就是静态链接的过程。
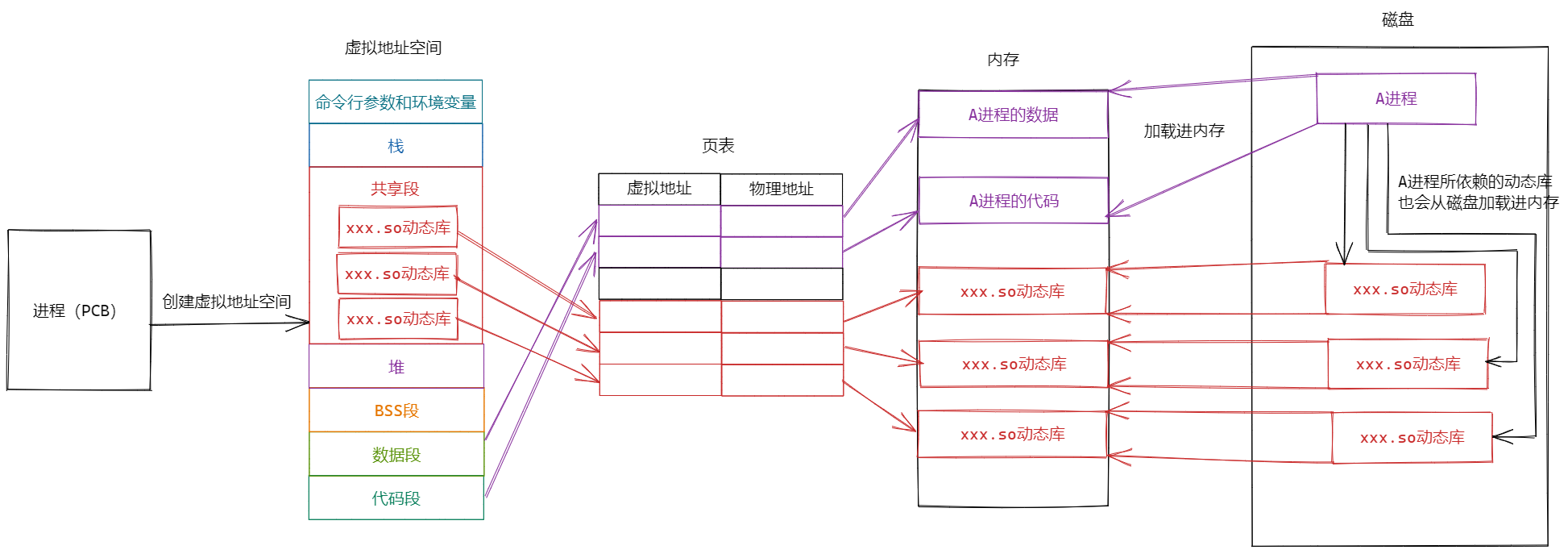
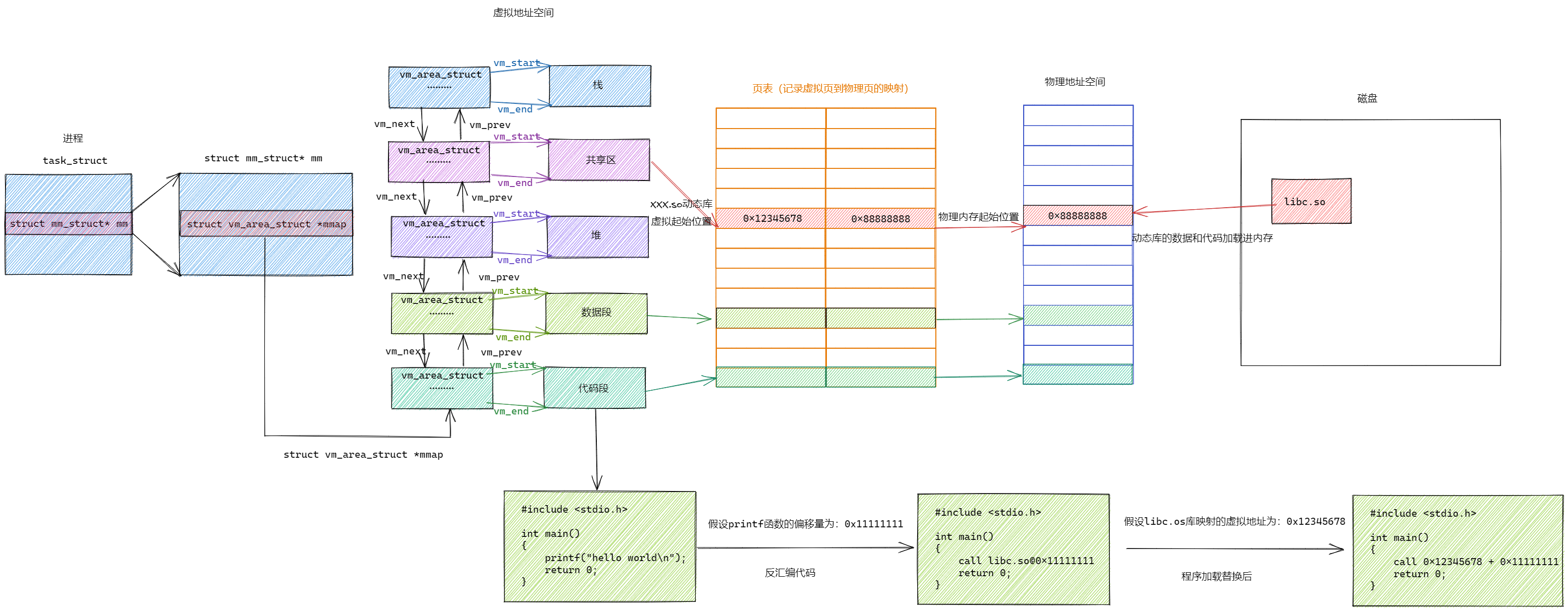
3.2 进程加载动态库
一个进程在加载到内存时,进程所依赖的动态库也会别一起加载到内存,此时库和进程之间的代码和数据是相互分离的
进程的虚拟地址空间中------共享区中的地址映射的就是当前进程所依赖的所有动态库
共享区是一个很大的空间,同时可以映射很多的动态库,在进程运行期间可用通过页表中的映射关系,从而找到库函数的地址并进行调用
3.3 进程间加载动态库
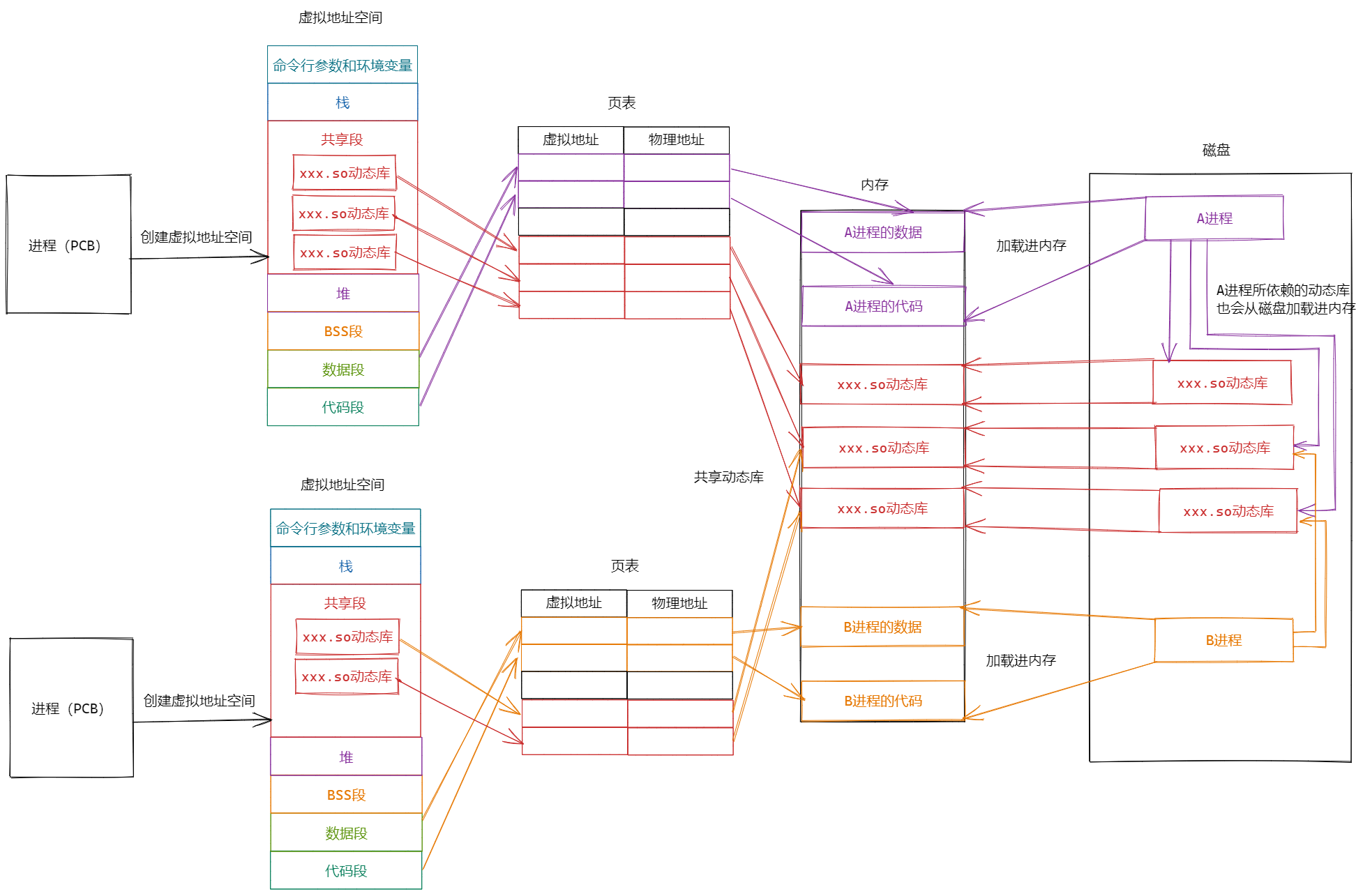
一个进程在加载到内存时,进程所依赖的动态库也会别一起加载到内存
但是如果进程所依赖的动态库已经被其他进加载进内存时,此时进程就会与其他进程共享动态库,就不会再次加载所依赖的动态库了
动态库的本质:通过地址空间映射,对公共代码进行去重
3.4 动态链接
编译器在进行编译链接时,默认采用的是动态链接的方式
静态链接最⼤的问题在于⽣成的⽂件体积⼤,并且相当耗费内存资源。随着软件复杂度的提升,我们的操作系统也越来越臃肿,不同的软件就有可能都包含了相同的功能和代码,显然会浪费⼤量的硬盘空间
动态链接可以将需要共享的代码单独提取出来,保存成⼀个独⽴的动态链接库,等到程序运⾏的时候再将它们加载到内存,这样不但可以节省空间,因为同⼀个模块在内存中只需要保留⼀份副本,可以被不同的进程所共享
问:动态链接到底是如何⼯作的??
结论:动态链接实际上将链接的整个过程推迟到了程序加载的时候
⽐如我们去运⾏⼀个程序,操作系统会⾸先将程序的数据代码连同它⽤到的⼀系列动态库先加载到内存,其中每个动
态库的加载地址都是不固定的,操作系统会根据当前地址空间的使⽤情况为它们动态分配⼀段内存。
当动态库被加载到内存以后,⼀旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。
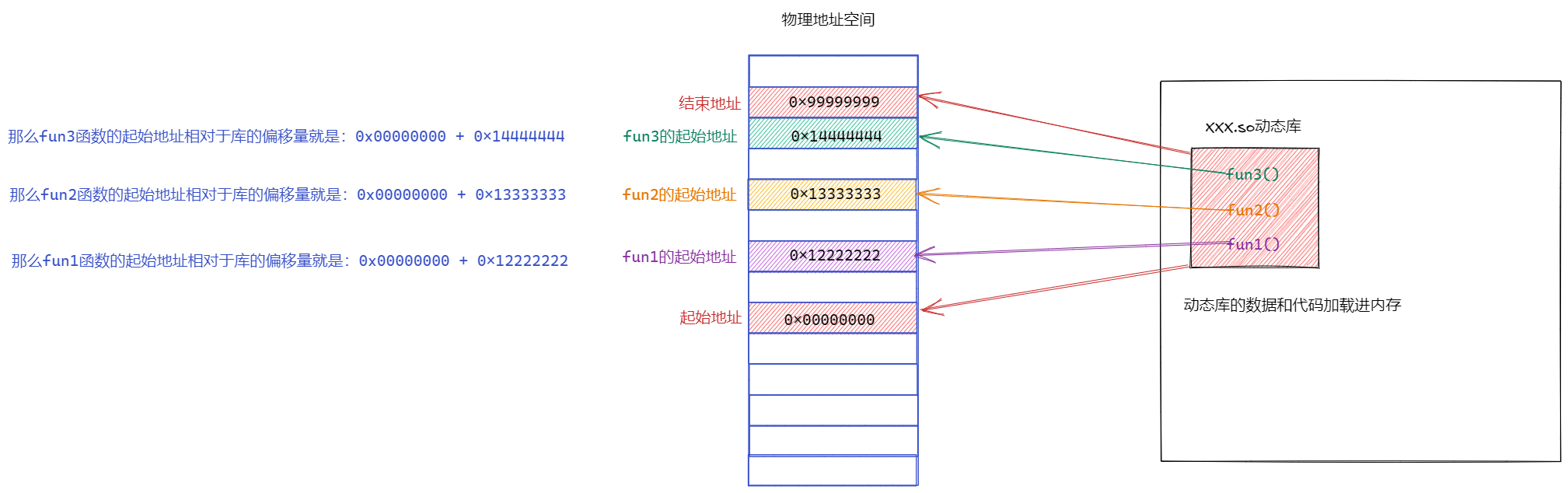
(1)动态库中的相对地址
动态库为了随时进⾏加载,为了⽀持并映射到任意进程的任意位置,对动态库中的⽅法,统⼀编址,采⽤相对编址的⽅案进⾏编制的
当访问库中任意⽅法,只需要知道 库的起始虚拟地址+⽅法偏移量 即可定位库中的⽅法
库的起始物理地址:
在库加载进内存时,OS会分配地址
偏移量:
编译形成动态库时,每个函数相对于库的偏移量就已经确定了
3.4.1 程序怎么与动态库映射起来的
动态库也是一个文件,进程需要访问就要加载动态库到内存
当动态库加载到内存时分配物理地址后,相应的进程就会在虚拟地址空间的共享区创建动态库的起始虚拟地址,通过页表与物理地址空间的动态库起始地址进行映射,当进程访问动态库函数时就可以通过函数在动态库中的偏移量进行调用
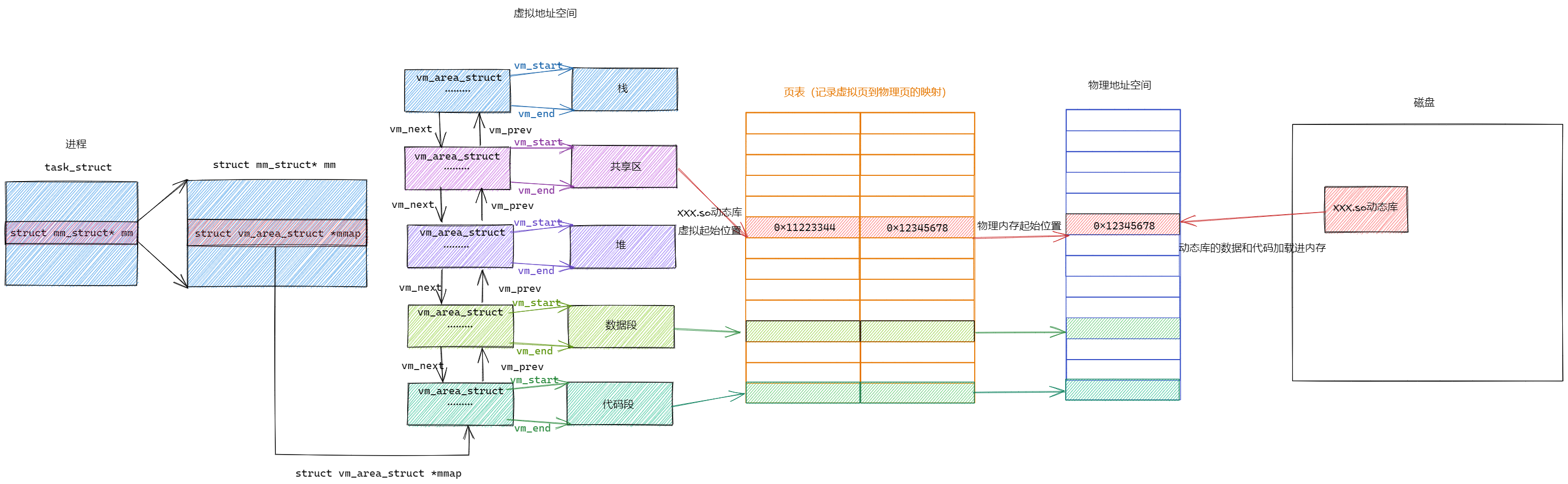
我们的进程找到动态库的本质:也是⽂件操作,不过我们访问库函数,通过虚拟地址进⾏跳转访问的,所以需要把动态库映射到进程的虚拟地址空间中
3.4.2 程序怎么进⾏库函数调⽤
- 库已经被我们映射到了当前进程的地址空间中
- 库的虚拟起始地址我们也已经知道了
- 库中每⼀个⽅法的偏移量地址我们也知道
- 所有:访问库中任意⽅法,只需要知道库的起始虚拟地址+⽅法偏移量即可定位库中的⽅法
- ⽽且:整个调⽤过程,是从代码区跳转到共享区,调⽤完毕在返回到代码区,整个过程完全在进程地址空间中进⾏的.
3.4.3 全局偏移量表------GOT
我们的程序运⾏之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道
然后对我们加载到内存中的程序的库函数调⽤进⾏地址修改,在内存中⼆次完成地址设置(这个叫做加载地址重定位)
问题:
对函数调用进行地址修改?修改的是代码区?代码区不是只读的吗?能修改吗?
所以:
动态链接采⽤的做法是在 .data (可执⾏程序或者库⾃⼰)中专⻔预留⼀⽚区域⽤来存放函数的跳转地址,它也被叫做全局偏移表GOT,表中每⼀项都是本运⾏模块要引⽤的⼀个全局变量或函数的地址。
(1).data区域(数据段)是可读写的,所以可以⽀持动态进⾏修改
cpp
lz@VM-8-15-ubuntu:~/learn/lib/test$ readelf -S code
// ......
[24] .got PROGBITS 0000000000003fb8 00002fb8
0000000000000048 0000000000000008 WA 0 0 8
// ......
lz@VM-8-15-ubuntu:~/learn/lib/test$ readelf -l code
// ......
05 .init_array .fini_array .dynamic .got .data .bss
// ......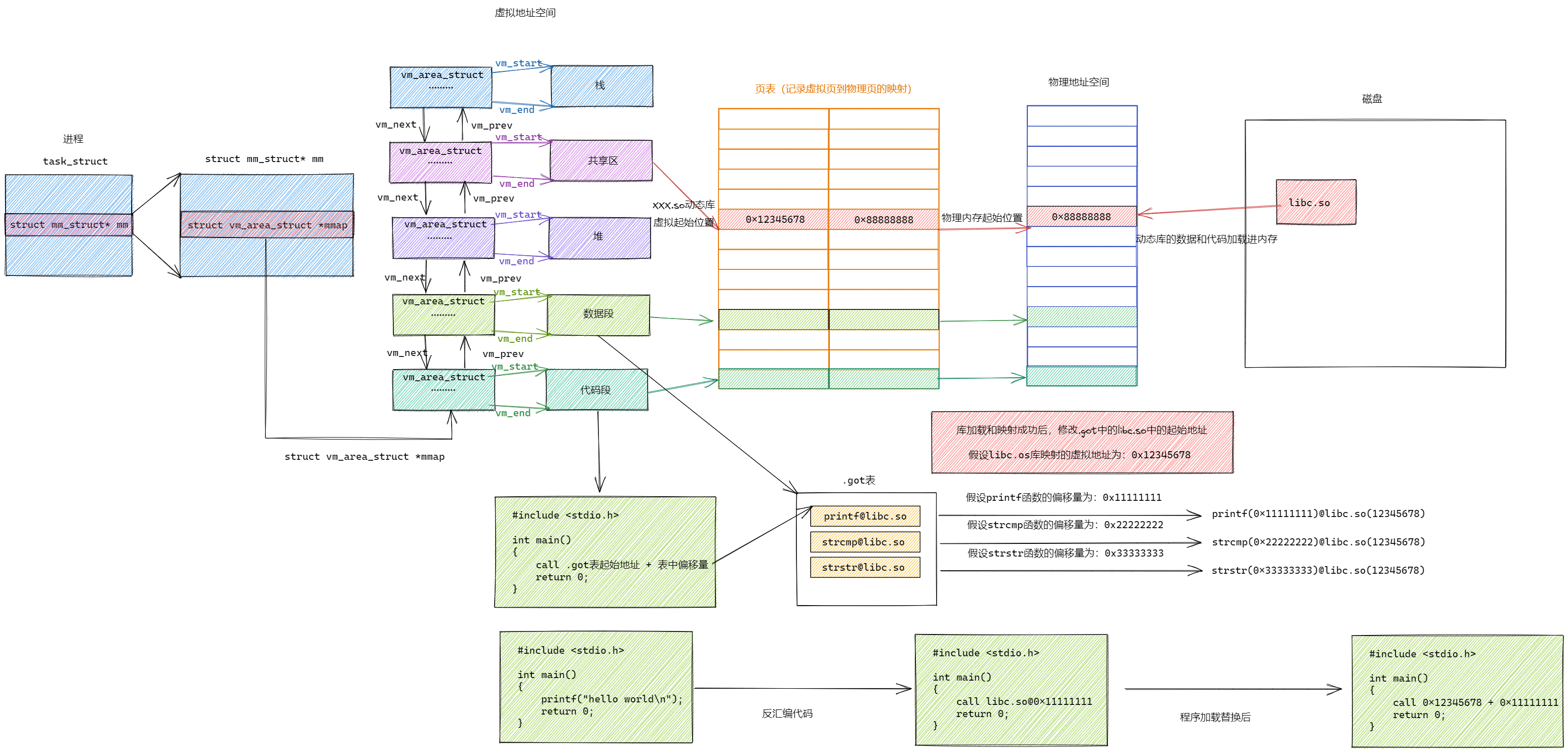
由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的每个动态库都有独⽴的GOT表,所以进程间不能共享GOT表。
在调⽤函数的时候会⾸先查表,然后根据表中的地址来进⾏跳转,这些地址在动态库加载的时候会被修改为真正的地址
这种⽅式实现的动态链接就被叫做 PIC 地址⽆关代码 。换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是为什么之前我们给编译器指定 -fPIC 参数的原因。
PIC = 相对编址 + GOT