目录
[A Comprehensive Survey on Multimodal Retrieval-Augmented Generation:](#A Comprehensive Survey on Multimodal Retrieval-Augmented Generation:)
[1.2.检索策略(Retrieval Strategy)](#1.2.检索策略(Retrieval Strategy))
[1.2.1. 高效搜索与相似度检索](#1.2.1. 高效搜索与相似度检索)
[1.2.1. 模态中心检索](#1.2.1. 模态中心检索)
[1.2.3. 文档检索与布局理解](#1.2.3. 文档检索与布局理解)
[1.2.4. 重排序与选择策略](#1.2.4. 重排序与选择策略)
[1.3.融合机制(Fusion Mechanisms)](#1.3.融合机制(Fusion Mechanisms))
[1.3.1. 分数融合与对齐](#1.3.1. 分数融合与对齐)
[1.3.2. 注意力基机制](#1.3.2. 注意力基机制)
[1.3.3. 统一框架与投影](#1.3.3. 统一框架与投影)
[1.4.增强技术(Augmentation Techniques)](#1.4.增强技术(Augmentation Techniques))
[1.4.1. 上下文富集(Context Enrichment)](#1.4.1. 上下文富集(Context Enrichment))
[1.4.2. 自适应与迭代检索](#1.4.2. 自适应与迭代检索)
[1.5.生成技术(Generation Techniques)](#1.5.生成技术(Generation Techniques))
[1.5.1. 上下文学习(In-Context Learning, ICL)](#1.5.1. 上下文学习(In-Context Learning, ICL))
[1.5.2. 推理(Reasoning)](#1.5.2. 推理(Reasoning))
[1.5.3. 指令调优(Instruction Tuning)](#1.5.3. 指令调优(Instruction Tuning))
[1.5.4. 源归因与证据透明(Source Attribution and Evidence Transparency)](#1.5.4. 源归因与证据透明(Source Attribution and Evidence Transparency))
[1.5.5. 智能体生成与交互(Agentic Generation and Interaction)](#1.5.5. 智能体生成与交互(Agentic Generation and Interaction))
[1.6.训练策略(Training Strategies)](#1.6.训练策略(Training Strategies))
[1.6.1. 多阶段训练](#1.6.1. 多阶段训练)
[1.6.2. 跨模态对齐](#1.6.2. 跨模态对齐)
[1.6.3. 鲁棒性增强](#1.6.3. 鲁棒性增强)
[1.7.1. 数据集](#1.7.1. 数据集)
[1.7.2. 评估体系](#1.7.2. 评估体系)
[1.7.3. 应用领域](#1.7.3. 应用领域)
[A Survey on Multimodal Retrieval-Augmented Generation](#A Survey on Multimodal Retrieval-Augmented Generation)
[2.多模态文档解析与索引(Multimodal Document Parsing and Indexing)](#2.多模态文档解析与索引(Multimodal Document Parsing and Indexing))
[3.多模态搜索规划(Multimodal Search Planning)](#3.多模态搜索规划(Multimodal Search Planning))
[3.1.检索分类(Retrieval Classification)](#3.1.检索分类(Retrieval Classification))
[3.2.查询重构(Query Reformulation)](#3.2.查询重构(Query Reformulation))
[4.多模态检索(Multimodal Retrieval)](#4.多模态检索(Multimodal Retrieval))
[5.多模态生成(Multimodal Generation)](#5.多模态生成(Multimodal Generation))
[6.数据集与评估(Dataset & Evaluation)](#6.数据集与评估(Dataset & Evaluation))
A Comprehensive Survey on Multimodal Retrieval-Augmented Generation:
多模态检索增强生成综述: https://arxiv.org/pdf/2502.08826
分享两篇多模态RAG论文:

1.1.摘要
多模态 RAG 是在传统文本 RAG 基础上融合文本、图像、音频、视频、文档布局 等多模态信息的检索增强生成框架,核心解决大语言模型幻觉、知识过时问题,同时通过跨模态信息融合提升复杂任务的推理与生成能力。其整体架构可拆解为检索策略、融合机制、增强技术、生成技术、训练策略 五大核心模块,外加数据集与评估、应用领域、开放问题与未来方向三大支撑体系,各模块相互协同构成端到端的多模态 RAG 系统,以下对核心功能模块及支撑体系进行逐模块详细分析。
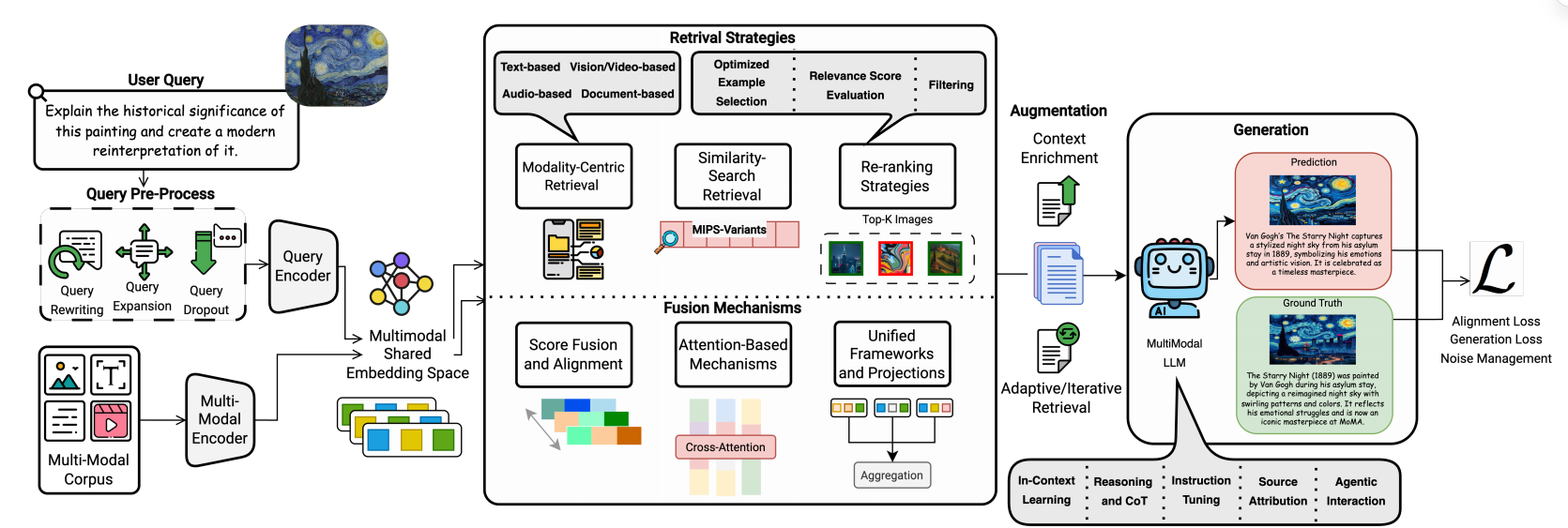
1.2.检索策略(Retrieval Strategy)
检索是多模态 RAG 的基础,核心目标是从多模态语料库中高效、精准检索与查询相关的跨模态信息,解决传统单模态检索的模态割裂问题,同时平衡检索精度与计算效率。该模块分为
- 高效搜索与相似度检索、
- 模态中心检索、
- 文档检索与布局理解、
- 重排序与选择策略
四大子方向,是多模态信息获取的核心环节。
1.2.1. 高效搜索与相似度检索
核心是将不同模态编码至统一嵌入空间,实现跨模态直接检索,并通过高效相似度计算方法降低大规模语料的检索成本。
- 多模态编码器:基于 CLIP、BLIP、MARVEL、Uni-IR 等模型,通过对比学习、跨模态注意力融合视觉 / 文本 / 音频特征,实现模态间的语义对齐;典型如 CLIP 完成视觉 - 文本基础对齐,BLIP 通过训练中融入跨模态注意力提升特征丰富度。
- 高效相似度计算 :主流采用最大内积搜索(MIPS) 及其变体(BanditMIPS、FARGO、TPU-KNN),实现高维嵌入的亚线性查找;针对 MIPS 量化导致的召回率下降问题,提出自适应量化方法 (ADQ),在嵌入分布密集区动态分配比特数;同时结合稀疏 - 稠密混合检索,用稀疏词汇信号补充稠密嵌入,提升检索鲁棒性。
- 新兴方向:学习型索引结构(Deeperimpact),将搜索树嵌入神经参数,让检索路径适配数据分布,降低延迟与存储开销。
1.2.1. 模态中心检索
针对文本、视觉、视频、音频单一模态的特性设计专属检索策略,兼顾各模态的信息表达特点,是多模态检索的基础组成。
| 模态类型 | 核心特点 | 典型方法 / 模型 | 应用场景 |
|---|---|---|---|
| 文本中心 | 仍是多模态 RAG 的基础,注重细粒度语义匹配与领域特异性 | BM25(传统)、MiniLM/BGE-M3(稠密检索)、ColBERT/PreFLMR(令牌级交互) | 文本证据检索、跨模态查询的文本辅助匹配 |
| 视觉中心 | 基于图像特征的知识提取,支持零样本图像检索 | EchoSight、ImgRet、VQA4CIR(组合图像检索) | 视觉相似内容检索、图像作为查询的跨模态检索 |
| 视频中心 | 融入时间动态特征,解决长视频上下文处理与时序一致性问题 | iRAG(增量检索)、Video-RAG(OCR/ASR 辅助长视频理解)、CTCH(时序依赖建模) | 视频问答、视频内容分析、长视频检索 |
| 音频中心 | 绕过传统 ASR 流水线,直接将原始音频映射至共享空间 | WavRAG、SEAL(统一音频嵌入)、LA-RAG(语音 - 语音精细检索) | 音频问答、语音对话、音频字幕生成 |
1.2.3. 文档检索与布局理解
针对含文本、图像、表格、布局的多模态文档(PDF、发票、表单),突破传统 OCR 依赖,实现端到端的文档信息检索。
- 核心突破:ColPali 实现端到端文档图像检索,通过视觉 - 语言骨干网络嵌入页面补丁,无需 OCR;ColQwen2、M3DocVQA 进一步支持动态分辨率处理与多页整体推理。
- 布局对齐:ViTLP、DocLLM 通过预训练将空间布局与文本对齐,CREAM 采用粗到细检索平衡精度与计算成本;mPLUG-DocOwl 1.5/2 实现无 OCR 依赖的跨格式结构学习(发票、表单)。
- 高效适配:SV-RAG 通过双 LoRA 适配器,分别实现证据页面检索与问答,利用多模态大模型(MLLM)的固有检索能力。
1.2.4. 重排序与选择策略
检索的后处理环节,核心是对初筛的多模态候选结果进行优先级排序、过滤无关信息,提升检索结果的相关性与质量,分为三大子策略:
- 优化示例选择:多步检索结合有监督 / 无监督方法,如 RULE 通过 Bonferroni 校正校准检索上下文,降低事实性风险;聚类基关键帧选择保证视频检索的多样性。
- 精细化相关性评分:融合多模态相似度度量(SSIM、NCC、BERTScore),如 VR-RAG 结合跨模态文本 - 图像相似度与模态内视觉相似度;分层后处理整合段落级与答案置信度评分。
- 过滤机制:硬负样本挖掘(GME、MM-Embed)缓解模态偏差;共识基过滤(MuRAR、ColPali)通过源归因与多向量映射过滤低相似度候选;动态模态过滤(RAFT、MAIN-RAG)训练检索器忽略干扰数据。
1.3.融合机制(Fusion Mechanisms)
融合是多模态 RAG 的核心关键 ,解决不同模态特征的语义对齐、信息互补、协同推理 问题,将检索到的多模态信息整合成统一、可解释的表示形式,为后续生成提供高质量上下文。该模块分为分数融合与对齐、注意力基机制、统一框架与投影三大子方向,核心目标是实现跨模态信息的深度融合而非简单拼接。
1.3.1. 分数融合与对齐
通过模态间的相似度分数融合、嵌入空间对齐,将不同模态的检索分数 / 特征映射至同一语义空间,实现基础的跨模态信息融合。
- 核心方法:将文本 / 表格 / 图像转换为单一文本格式(Zhi Lim et al.),通过跨编码器计算相关性评分;CLIP/BLIP 分数融合(Sharifymoghaddam et al.),将多模态特征对齐至 CLIP 共享空间;原型基嵌入网络(Xue et al.),将视觉对象 - 谓词对映射至文本原型空间,实现视觉 - 文本特征对齐。
- 典型模型:REVEAL 将检索分数注入注意力层,最小化查询与知识嵌入的 L2 范数差异;VISA 通过 DSE 模型将文本查询与视觉文档表示编码至共享空间;VISRAG 对 VLM 隐藏状态进行位置加权平均池化,提升关键令牌的相关性权重。
1.3.2. 注意力基机制
基于自注意力、跨注意力、协同注意力实现多模态特征的动态交互,精细调节模态间的信息流动,平衡特异性与可解释性,是目前主流的融合方式。
- 核心类型:跨注意力(EMERGE、MORE)整合异构模态,需任务专属注意力头;协同注意力(RAMM)结合自注意力与跨注意力,融合生物医学图像 / 文本与输入数据;门控跨注意力(Xu et al.)将文本生成条件于视觉特征,提升可控性。
- 进阶优化:MV-Adapter 通过跨模态绑定共享潜因子,对齐视频 - 文本嵌入;M2-RAAP 通过字幕引导的重加权策略,结合帧 - 令牌注意力过滤失配特征;Kim et al. 利用预训练 CLIP ViT-L/14 实现跨模态记忆检索,通过注意力融合实现视频稠密字幕生成。
- 缺点:部分方法(如 M2-RAAP)计算复杂度较高,难以大规模部署。
1.3.3. 统一框架与投影
将多模态输入整合为统一的特征表示 / 张量,通过分层融合、稠密 - 稀疏投影等方式,实现多模态信息的结构化整合,提升融合效率。
- 分层融合:Hybrid-RAG 采用分层跨链与后期融合处理医疗数据;IRAMIG 通过迭代整合多模态结果生成统一知识表示,提升一致性。
- 张量扁平化:M3DocRAG 将多页文档扁平化为单一嵌入张量;PDF-MVQA 提出联合粒度检索器,融合粗粒度语义实体表示与细粒度令牌级文本内容。
- 稠密 - 稀疏投影:Dense2Sparse 将 BLIP/ALBEF 的稠密嵌入转换为稀疏词汇向量,通过 L1 正则化保证稀疏性,优化存储与可解释性。
- 模态转换:SAM-RAG 通过为图像生成字幕,将多模态输入转换为单模态文本,降低后续处理复杂度;DQU-CIR 根据查询复杂度,动态将图像转换为文本字幕或为文本叠加图像。
1.4.增强技术(Augmentation Techniques)
增强技术是对检索到的多模态上下文进行精细化处理 的环节,解决传统 RAG "单次检索直接生成" 导致的上下文相关性不足、检索结果冗余 / 缺失问题,通过上下文富集、自适应与迭代检索提升多模态上下文的质量,为生成环节提供更精准、丰富的支撑。
1.4.1. 上下文富集(Context Enrichment)
核心是细化、扩展检索到的多模态信息,补充上下文细节,提升与查询的相关性,让生成环节拥有更全面的背景知识。
- 信息扩展:EMERGE 整合实体关系与语义描述,丰富上下文;MiRAG 通过实体检索与查询重构,扩展初始查询,提升视觉问答的后续性能。
- 结构化重构:Video-RAG 通过查询解耦,将用户查询重构为结构化检索请求,提取长视频的辅助多模态上下文;Img2Loc 在提示中同时包含相似与相异点,帮助排除不合理的地理定位。
- 跨模态补充:为文本检索结果补充视觉特征,为视觉检索结果补充文本描述,实现模态间的信息互补。
1.4.2. 自适应与迭代检索
针对复杂多模态查询 (如多跳推理、开放域问答),通过动态调整检索策略、多轮迭代优化,实现检索结果的逐步精细化,解决单次检索无法满足复杂查询需求的问题。
- 自适应检索 :根据查询的模态类型、粒度需求动态调整检索策略,如 UniversalRAG 将查询动态路由至最适合的语料库(段落 / 文档、视频片段 / 完整视频);SKURG 根据查询复杂度确定检索跳数;SAM-RAG 通过 MLLM 动态判断是否需要外部知识,过滤无关内容。
- 迭代检索:融入前序检索 / 生成的反馈,多轮优化检索结果,如 OMGM 采用粗到细的多步检索,从实体粗搜索逐步细化至精细文本过滤;IRAMIG 根据检索内容动态更新查询;OMG-QA 整合情景记忆,保证多轮检索的推理连续性;RAGAR 通过多模态分析与前序响应,迭代调整检索策略,提升上下文一致性。
1.5.生成技术(Generation Techniques)
生成是多模态 RAG 的最终环节 ,核心是基于原始多模态查询 + 增强后的多模态上下文 ,生成准确、连贯、符合跨模态语义的结果,同时解决生成过程中的幻觉、源归因、复杂推理 问题。该模块融合了大语言模型的生成能力与多模态推理能力,分为上下文学习、推理、指令调优、源归因与证据透明、智能体生成与交互五大子方向。
1.5.1. 上下文学习(In-Context Learning, ICL)
将检索到的多模态信息作为少样本示例,无需重新训练,直接提升多模态 RAG 的推理能力,是零样本 / 少样本场景下的核心生成策略。
- 基础应用:RMR、RA-CM3 将 ICL 扩展至多模态 RAG,利用检索的多模态示例引导生成;RAG-Driver 从记忆数据库中检索相关驾驶经验,细化 ICL 过程。
- 示例选择优化:MSIER 提出多模态有监督上下文示例检索框架,通过 MLLM 评分器评估文本与视觉相关性,提升示例质量;Raven 引入上下文融合学习,整合多样化的上下文示例,性能优于标准 ICL。
1.5.2. 推理(Reasoning)
针对复杂多模态任务 (如多跳推理、事实核查、组合图像检索),通过链式推理、树状推理等方法,将复杂推理分解为连续步骤,提升生成结果的连贯性与鲁棒性。
- 链式推理(CoT):Multimodal-CoT 将文本 CoT 扩展至多模态,实现跨模态的分步推理;RAGAR 提出RAG 链与 RAG 树,细化事实核查查询,探索分支推理路径。
- 证据验证:VisDoM、SAM-RAG 将 CoT 与证据整理、多阶段验证结合,提升生成准确性;LDRE 利用 LLM 进行发散式组合推理,通过稠密描述与文本修改优化字幕,提升零样本组合图像检索性能。
- 跨模态分布推理:VisDoM 擅长处理关键信息分布在不同模态的场景,实现跨模态的信息整合与推理。
1.5.3. 指令调优(Instruction Tuning)
针对特定应用场景,对多模态生成模型进行指令微调 / 偏好微调,让模型适配不同的多模态任务需求,提升生成结果的任务特异性与质量。
- 视觉特征提取:RA-BLIP 基于 InstructBLIP 的 Q-Former 架构,根据问题指令提取视觉特征;RAGPT 通过上下文感知提示器,从相关实例生成动态提示。
- 自适应检索与排名:MR²AG、RagVL 训练 MLLM 实现自适应检索调用、相关证据识别与排名能力提升,优化响应准确性。
- 偏好微调:MMed-RAG 通过偏好微调,让模型平衡检索知识与内部推理;Rule 通过直接偏好优化,微调医疗多模态大模型,缓解对检索上下文的过度依赖。
- 数据集构建:MegaPairs、Surf 从 LLM 错误中构建多模态指令调优数据集,针对性提升生成质量。
1.5.4. 源归因与证据透明(Source Attribution and Evidence Transparency)
多模态 RAG 的关键特性,核心是让生成结果可追溯,明确标注结果的多模态证据来源,解决大模型生成的幻觉问题与可解释性问题。
- 文本证据归因:OMG-QA 通过提示让 LLM 在生成中显式引用证据;MuRAR 通过源基检索器整合多模态信息,优化生成结果的信息性,但召回率受限于证据分布。
- 视觉证据归因:VISA 利用视觉 - 语言模型生成带视觉源归因的答案,高亮检索截图中的证据,但跨模态 / 多段落证据的归因准确性有待提升。
- 核心挑战:如何精准定位跨模态的细粒度证据(如文本中的某句话 + 图像中的某个区域),而非仅标注整体文档 / 图像。
1.5.5. 智能体生成与交互(Agentic Generation and Interaction)
目前的前沿方向,将多模态 RAG 与智能体(Agent) 结合,实现自主 / 半自主的跨模态检索、推理、生成与交互,支持复杂任务的端到端处理,突破传统静态 RAG 的局限性。
- 人机交互:AppAgent v2 实现移动 GUI 导航;USER-LLM R1 通过动态画像生成个性化对话智能体,适配老年用户需求。
- 领域专用智能体:MMAD 解决工业异常检测问题;Yi et al. 提升临床报告生成质量,降低幻觉;CollEX 为研究者提供科学文献的交互式探索。
- 复杂推理智能体:HM-RAG 实现跨多模态数据流的分层多智能体协同;CogPlanner 引入认知启发的规划框架,迭代重构查询并自适应选择检索策略。
1.6.训练策略(Training Strategies)
训练策略是支撑多模态 RAG 各模块性能的基础保障 ,核心是通过多阶段训练、跨模态对齐、鲁棒性增强 ,让模型更好地捕捉跨模态交互特征,提升检索、融合、生成的整体性能。该模块分为多阶段训练、跨模态对齐、鲁棒性增强三大核心方向,同时包含多种专用损失函数的设计与应用。
1.6.1. 多阶段训练
多模态 RAG 的训练遵循预训练 + 微调的两阶段范式,兼顾跨模态特征的通用学习与任务特异性适配。
- 预训练 :在大规模配对多模态数据集上训练,建立跨模态的基础语义关系,核心优化前缀语言建模损失(L_PrefixLM),同时结合对比损失(L_contra)、解纠缠正则化损失(L_decor)、对齐正则化损失(L_align),分别实现查询 - 伪真值知识对齐、嵌入表达能力增强、查询 - 知识对齐细化(如 REVEAL 模型)。
- 微调 :针对下游任务(视觉问答、图像字幕、医疗报告生成),采用交叉熵损失进行任务特异性优化,将预训练的通用跨模态特征适配至具体任务。
1.6.2. 跨模态对齐
核心是通过对比学习让正样本对(如匹配的图像 - 文本)在嵌入空间更接近,负样本对更远离,实现多模态特征的语义对齐,是多模态 RAG 训练的核心环节。
- 基础损失:InfoNCE 损失是主流选择,被 VISRAG、MegaPairs、SAM-RAG 等广泛采用,提升检索增强生成的性能。
- 对比学习优化:EchoSight 选择视觉相似但语义不同的负样本,提升检索准确性;HACL 引入对抗字幕作为干扰项,缓解幻觉;UniRaG 利用硬负样本文档,提升模型对相关 / 无关上下文的辨别能力;eCLIP 损失融合专家标注数据与辅助 MSE 损失,细化嵌入质量。
- 数据增强:Mixup 策略生成合成正样本对,提升模型泛化能力;Dense2Sparse 引入图像到字幕(ℓ(I→C))和字幕到图像(ℓ(C→I))损失,结合 L1 正则化保证稀疏性,平衡稠密与稀疏表示。
1.6.3. 鲁棒性增强
针对多模态训练中的噪声、模态偏差、对抗扰动问题,通过多种策略提升模型的鲁棒性,保证在复杂场景下的稳定性能。
- 噪声处理:MORE 在训练中注入无关结果,让模型聚焦相关输入;AlzheimerRAG 通过渐进式知识蒸馏,在保持跨模态对齐的同时降低噪声;RA-BLIP 提出 ASKG 策略,通过去噪增强损失过滤相关知识,无需微调且降低计算开销。
- 模态偏差缓解:Buettner and Kovashka 量化多语言检索中的翻译与原生感知差距,针对性缓解模态偏差;硬负样本挖掘、模态感知采样进一步平衡各模态的特征贡献。
- 对抗鲁棒性:RagVL 通过噪声注入训练 ,在数据层添加硬负样本,在令牌层施加高斯噪声并重新加权损失,提升对多模态噪声的鲁棒性;RA-CM3 采用查询丢弃,训练中随机移除查询令牌,作为正则化方法提升生成器的泛化能力。
- 核心挑战:目前多模态 RAG 易受知识投毒攻击(MMPoisonRAG、Poisoned-MRAG),少量对抗性知识注入即可劫持跨模态检索并破坏生成,鲁棒防御机制仍待研究。
1.7.支撑体系:数据集、评估与应用领域
多模态 RAG 的落地与发展依赖专用数据集与评估体系的支撑,同时已在多个领域实现规模化应用,形成 "技术 - 数据 - 评估 - 应用" 的闭环。
1.7.1. 数据集
多模态 RAG 数据集覆盖图像 - 文本、视频 - 文本、音频 - 文本、医疗、时尚、3D、知识问答 等多领域,分为大规模预训练数据集 与任务特异性微调数据集,部分为单模态数据集但可通过组合形成多模态语料。
- 大规模预训练:LAION-5B(58.5 亿图像 - 文本对)、MINT-1T(34 亿图像 + 1 万亿文本令牌)、HowTo100M(13.6 亿视频片段),为跨模态特征学习提供海量数据。
- 任务特异性:医疗领域(MIMIC-CXR、CheXpert)、视觉问答(VQA v2、OK-VQA)、文档理解(DocVQA、M3DocVQA)、视频问答(ActivityNet-QA、MSRVTT-QA)。
- 核心局限性:存在偏见与公平性问题 (网络爬取数据继承社会偏见)、标注质量与噪声 trade-off 、长上下文与真实世界复杂性捕捉不足 、对抗性样本缺失等问题。
1.7.2. 评估体系
多模态 RAG 的评估是多维度、跨模块 的,需同时评估检索性能、生成质量、模态对齐、鲁棒性、效率,涵盖检索指标、生成指标、跨模态专用指标三大类。
- 检索性能:Top-K 准确率、Recall@K、MRR(平均倒数排名),核心衡量检索的精准度与召回率。
- 生成质量:文本生成(BLEU、ROUGE、METEOR、BERTScore)、图像字幕(CIDEr、SPICE、SPIDEr)、图像质量(FID、KID、IS)、音频质量(FAD、人工评估 OVL/REL)。
- 跨模态专用:CLIP Score(图像 - 文本相似度)、领域专用指标(医疗的临床相关性、地理定位的测地距离)。
- 效率与鲁棒性:FLOPs、执行时间、检索延迟;对抗性扰动下的性能保持率、噪声容忍度。
- 核心局限性:多数基准仅单独评估检索或生成,缺乏检索 - 生成协同的整体评估框架。
1.7.3. 应用领域
多模态 RAG 已在医疗、软件工程、时尚电商、娱乐社交 等领域实现落地,同时向自动驾驶、无线网络、地理空间、工业检测等新兴领域延伸,核心价值是通过跨模态信息融合解决领域内的知识密集型、复杂推理问题。
| 应用领域 | 核心场景 | 典型模型 / 方法 | 核心价值 |
|---|---|---|---|
| 医疗与医药 | 放射报告生成、临床决策、哮喘患者支持 | MMED-RAG、RULE、AsthmaBot、FactMM-RAG | 缓解医疗报告幻觉,整合医学影像 / 电子病历 / 文献,提升诊断准确性 |
| 软件工程 | 代码生成、提交信息生成、API 检索 | DocPrompting、RACE、REDCODER | 从技术文档 / 版本历史中检索上下文,提升代码的语义连贯性与规范性 |
| 时尚与电商 | 跨模态商品检索、时尚图像编辑、虚拟试衣 | UniFashion、Fashion-RAG、VITON-HD | 实现图像 - 文本的风格对齐,提升商品检索精度与个性化设计能力 |
| 娱乐与社交 | 体育赛事分析、短视频热度预测、多媒体内容理解 | SoccerRAG、MMRA | 融合视频 / 图像 / 文本 / 统计数据,实现赛事战术分析与内容传播预测 |
| 新兴应用 | 自动驾驶决策、无线网络韧性、图像地理定位 | RAG-Driver、ENWAR、Img2Loc | 实现实时多模态信息检索,提升自主系统的可解释性与决策鲁棒性 |
1.8.总结
多模态 RAG 的核心是将传统文本 RAG 的检索增强范式扩展至多模态领域 ,通过检索策略 实现多模态信息的高效获取,融合机制 实现跨模态语义的深度对齐,增强技术 实现检索上下文的精细化处理,生成技术 实现准确、可解释的跨模态生成,训练策略实现模型的跨模态对齐与鲁棒性增强,五大模块相互协同,解决大语言模型的幻觉、知识过时问题,同时提升模型对复杂多模态任务的处理能力。
目前多模态 RAG 已在多个领域落地,但仍面临跨模态对齐不充分、可解释性差、鲁棒性不足、效率偏低等问题,未来的发展将围绕智能体化、统一嵌入空间、推理增强、隐私与规模化展开,逐步向更通用、更可靠、更高效的多模态智能系统演进,成为通向人工通用智能(AGI)的重要路径。
A Survey on Multimodal Retrieval-Augmented Generation
论文地址:https://arxiv.org/pdf/2504.08748
1.MRAG概述
-
定义与价值
- 多模态检索增强生成(MRAG):通过整合文本、图像、视频等多模态数据,扩展传统文本 RAG 框架,实现多模态检索与生成,解决 LLMs 幻觉问题,提升响应质量。
- 核心价值:突破文本模态限制,利用多模态语境信息,适配更复杂的真实场景(如视觉问答、多模态内容生成)。
-
发展历程
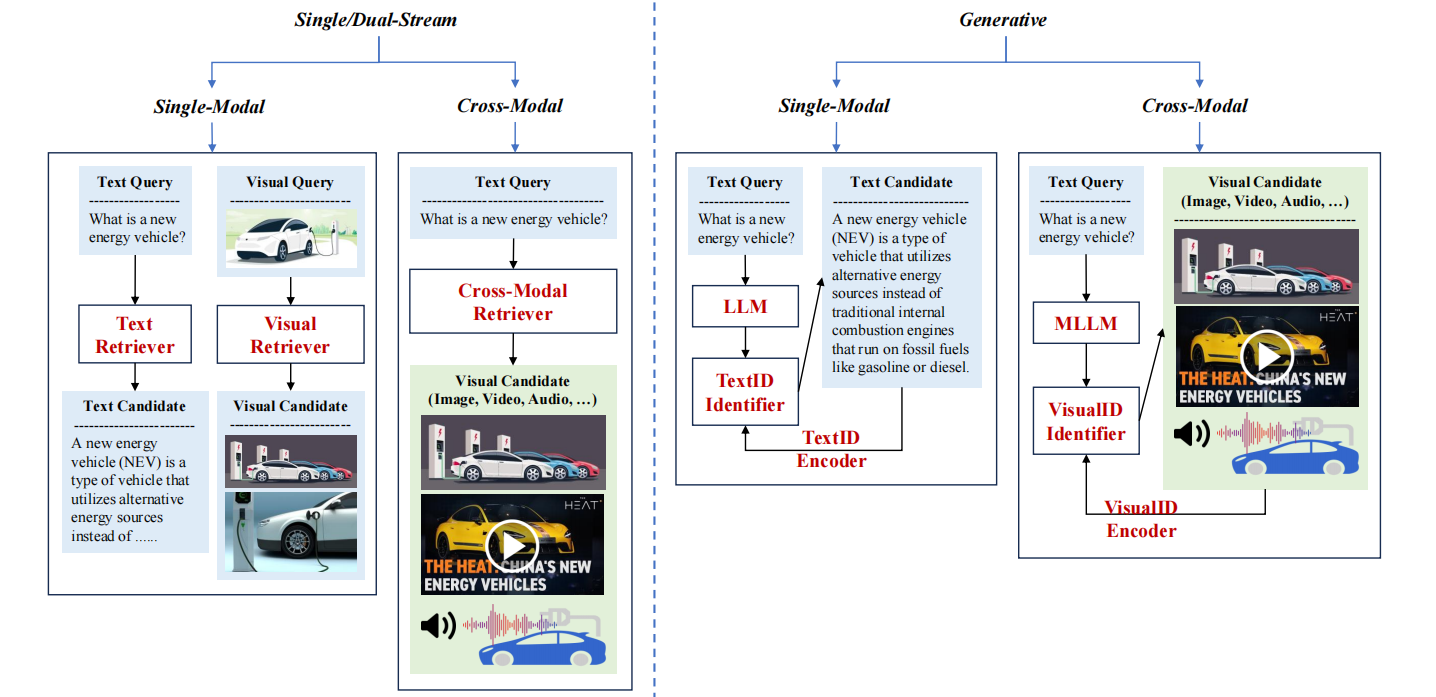
阶段 核心特征 关键改进 局限性 MRAG1.0(伪多模态) 将非文本数据转为文本描述,沿用 RAG 架构 实现多模态数据初步整合 信息丢失严重、检索瓶颈、生成难度大 MRAG2.0(真多模态) 保留原始多模态数据,支持跨模态检索 引入 MLLMs,减少模态转换损失 文本查询准确性下降、多模态检索性能待提升 MRAG3.0(端到端多模态) 保留文档截图、支持多模态输出、扩展场景 统一 VQA 与 RAG 任务,新增多模态生成场景
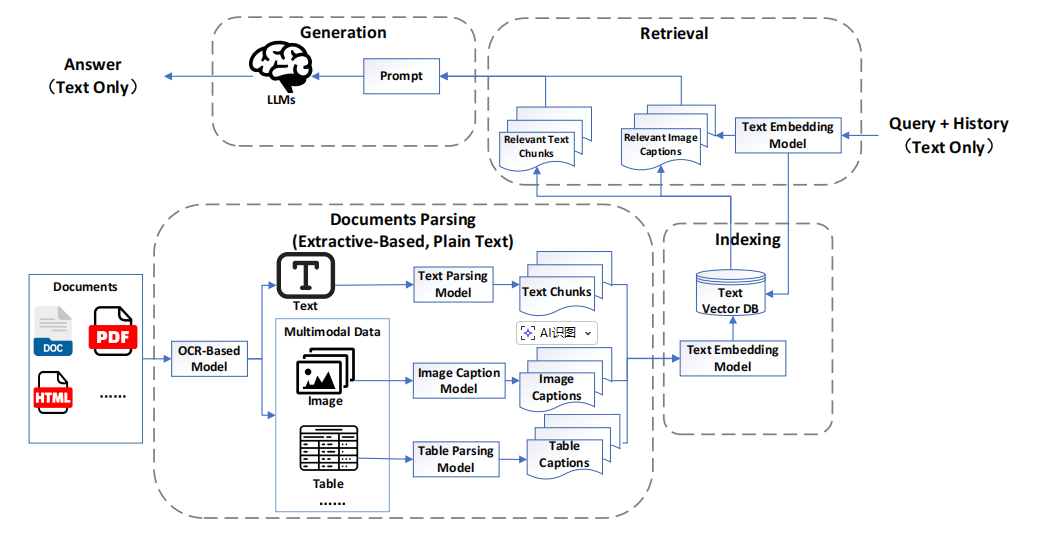
图1.MRAG1.0的架构通常被称为"伪MRAG",与传统的RAG非常相似,由三个模块组成:文档解析和索引、检索和生成。虽然总体该过程基本保持不变,关键区别在于文档解析阶段。在这个阶段,采用专门的模型将不同的模态数据转换为特定于模态的字幕。这些标题然后与文本数据一起存储,以供后续阶段使用。
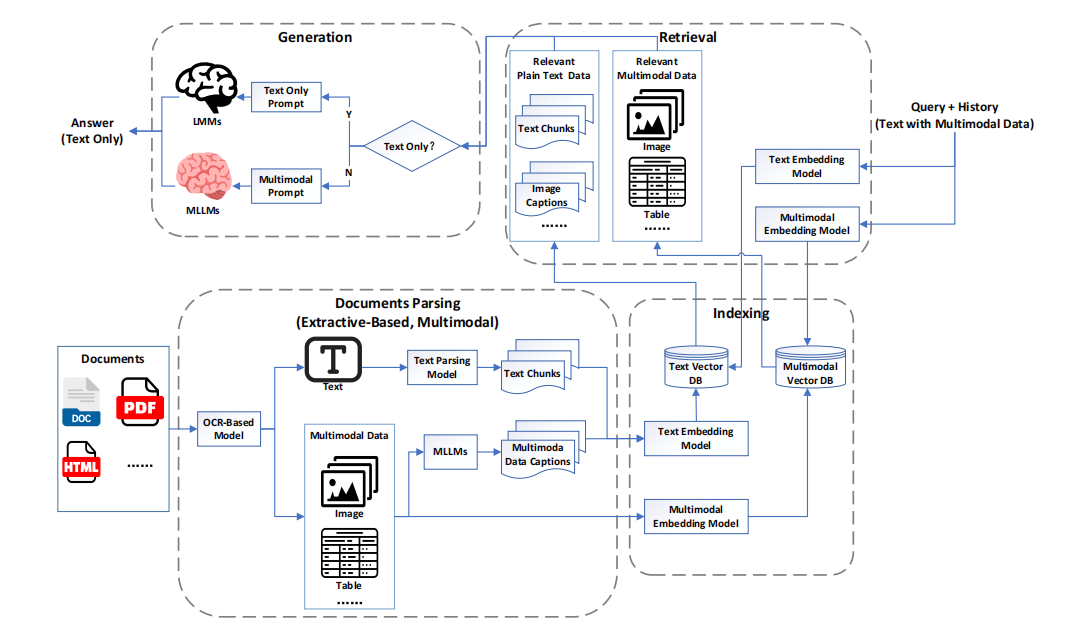
图2。MRAG2.0的架构通过文档解析和索引保留了多模态数据,同时引入多模态检索和MLLM进行答案生成,真正进入多模态时代。
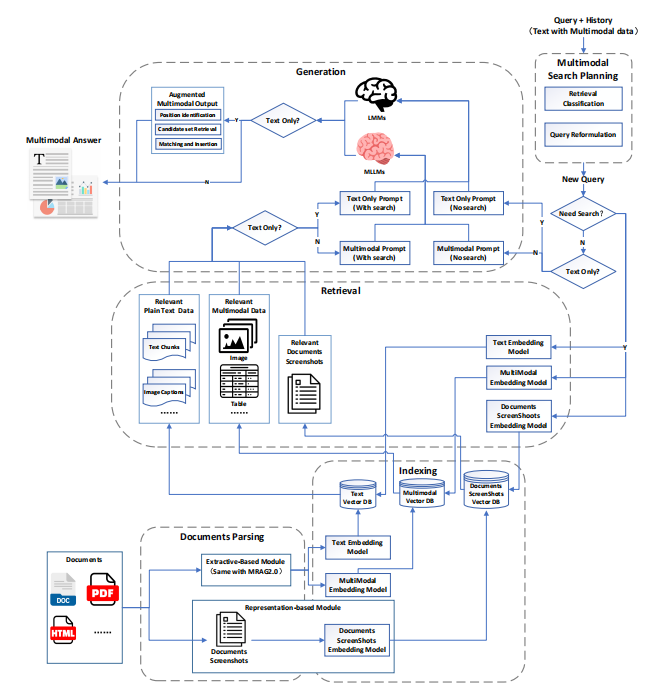
图3。MRAG3.0架构在文档解析和索引过程中集成了文档截图尽量减少信息丢失的阶段。
在输入阶段,统一视觉问答(VQA)和检索增强生成(RAG)任务,同时改进用户查询精度。
在输出阶段,多模态检索增强组合模块增强了通过将纯文本转换为多模式格式来生成答案,从而丰富信息传递。
举个例子:
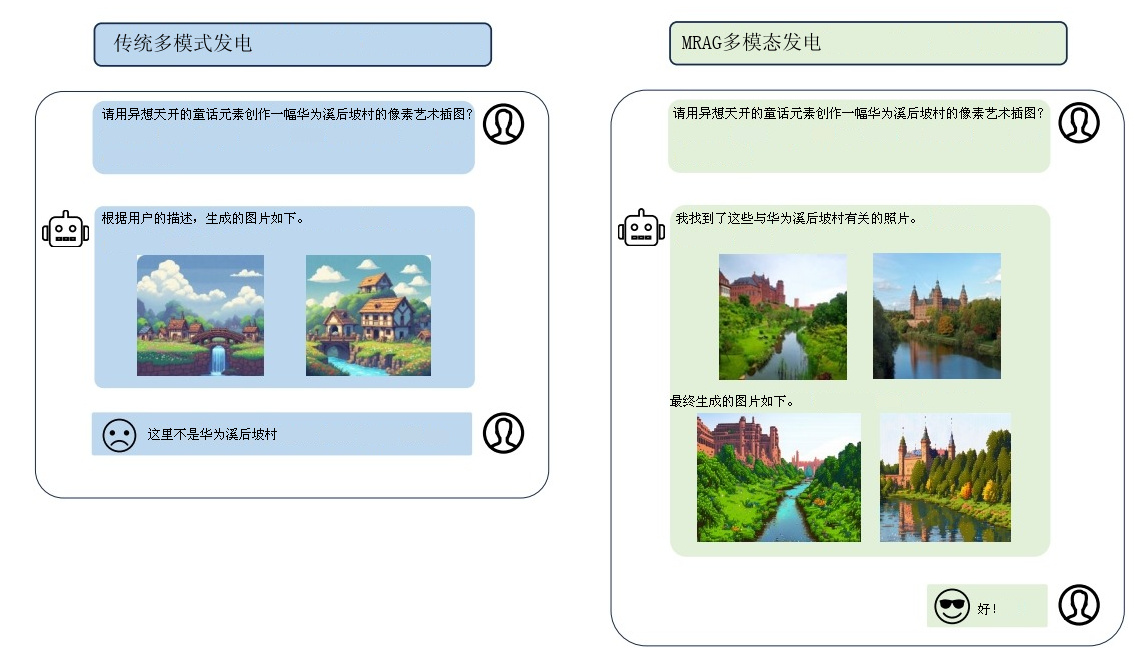
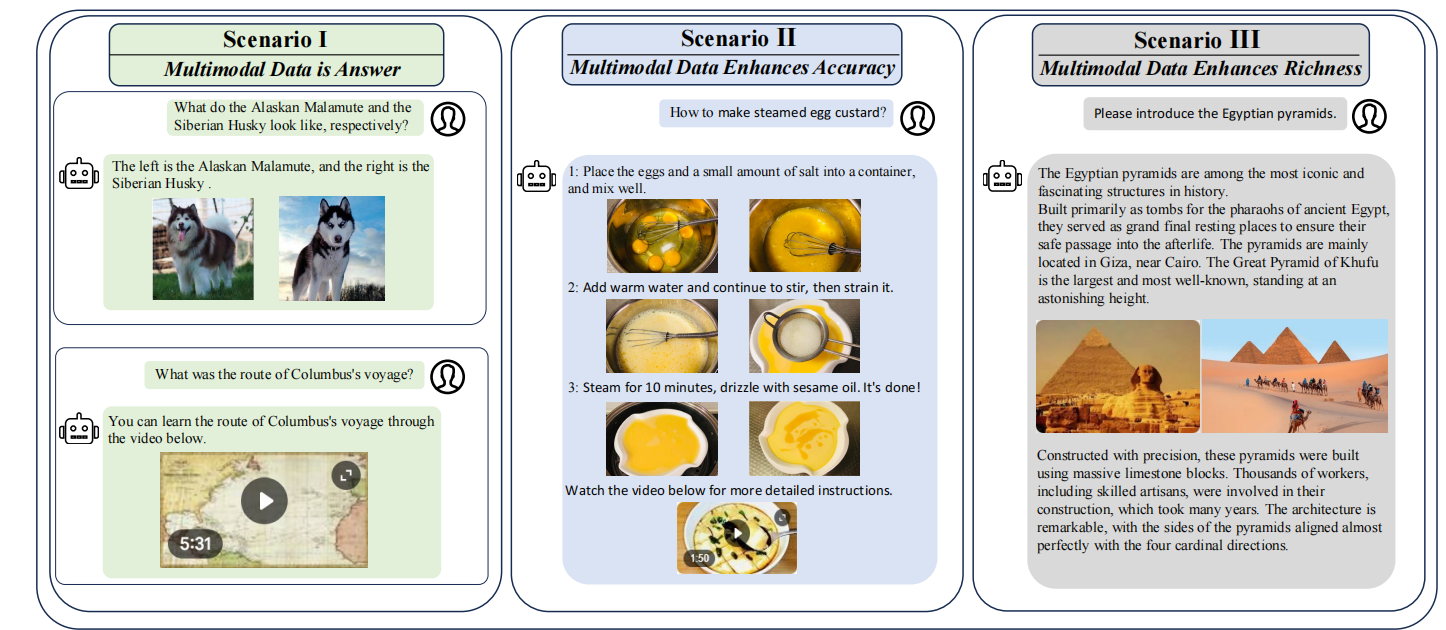
图5. 问答场景中的多模态输出可分为三种不同类型。
在子场景I中,仅使用图片或视频即可完全解答用户的查询,无需补充文本信息。
子场景II需结合文本与图片进行分步解释,以确保内容清晰准确;若省略图片,可能会导致用户在特定步骤产生困惑。
在子场景III中,补充图片丰富了答案所传递的信息,但移除图片并不会影响答案的准确性。
2.多模态文档解析与索引(Multimodal Document Parsing and Indexing)
作为 MRAG 的 "数据预处理核心",负责将原始多模态文档(如 PDF、HTML、图像、视频)转化为可检索、可利用的结构化 / 半结构化数据,为后续检索与生成提供高质量知识基础,直接影响 MRAG 系统的端到端性能。
| 文档类型 | 定义 | 典型示例 | 处理难点 |
|---|---|---|---|
| 非结构化多模态数据 | 无固定格式 /schema,包含文本、图像、音频、视频等 | 随机拍摄的图片、无标注视频、纯文本段落 | 信息提取难度大,需精准识别模态边界与语义关联 |
| 半结构化多模态数据 | 无严格数据库 schema,但保留部分组织特征 | PDF、HTML、XML、JSON 文件 | 解析时易丢失固有结构(如 HTML 标签含义、PDF 布局) |
| 结构化多模态数据 | 遵循预定义格式与固定 schema | 关系数据库、知识图谱、标准化表格 | 需将自然语言查询转化为精准的结构化查询语言(如 SQL) |
2.1.核心解析方法
-
提取式(Extraction-based)
- 核心逻辑:先从文档中提取多模态信息(文本、图像、表格等),再将提取结果结构化处理后存储。
- 细分流程:
- 纯文本提取:针对半结构化文档(如 PDF、HTML),通过规则 - based 工具(pymupdf、jsoup)提取文本,适用于简单格式,但无法处理图像内文本。
- 多模态提取:保留原始多模态数据(如图像、视频),同时为非文本元素生成描述(如图像 caption),需依赖 OCR、表格解析模型(TableNet)、图表解析模型(UniChart)。
- 关键技术:OCR 流水线(文本检测→文本识别→文本解析)、Transformer-based 文档解析模型(LayoutLM 系列、DocFormer),解决复杂布局与多模态信息关联问题。
-
表征式(Representation-based)
- 核心逻辑:不单独提取模态信息,而是将文档整体(如页面截图)作为表征单位,通过嵌入模型转化为向量存储,避免信息丢失。
- 关键技术:文档截图嵌入(DSE 模型)、整体文档表征方法(拆分长文档为 MLLM 可处理的片段)、混合表征策略(OCR 文本 + 文档截图并行索引)。
- 优势:保留文档原始布局与跨模态关联;不足:对存储与嵌入模型性能要求较高。
2.2.索引构建流程
- 文档预处理:拆分长文档为语义连贯的片段(文本 chunking)、生成非文本元素描述(图像 caption、视频摘要)。
- 多模态嵌入:通过统一嵌入模型(如 CLIP、FLAVA)将文本片段、非文本描述、文档截图转化为向量。
- 存储:向量存储于多模态向量数据库,支持后续跨模态检索。
3.多模态搜索规划(Multimodal Search Planning)
作为 MRAG 的 "决策中枢",负责分析用户多模态查询(如 "请结合图片说明如何组装家具"),制定最优检索策略(是否检索、检索哪些模态、如何优化查询),解决传统固定流程检索的僵化问题,提升检索效率与相关性。
两大核心任务
3.1.检索分类(Retrieval Classification)
- 定义:根据查询特征、MLLM 能力、历史检索结果,从动作空间(不检索、文本检索、图像检索等)中选择最优检索策略。
- 数学表达:
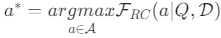 ,其中FRC为检索控制函数,Q为查询,D为历史文档。
,其中FRC为检索控制函数,Q为查询,D为历史文档。 - 关键价值:避免无效检索(如文本查询无需图像检索),减少误导性信息引入。
3.2.查询重构(Query Reformulation)
- 定义:当需要检索时,整合查询的文本 / 视觉信息、历史检索结果,生成更精准的增强查询Q∗,甚至分解为多步原子子查询。
- 数学表达:
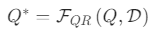 ,其中FQR为查询增强函数。
,其中FQR为查询增强函数。 - 适用场景:处理模糊查询、多跳推理查询(如 "图中产品的生产厂家在 2023 年的新品是什么")。
| 策略类型 | 核心特征 | 代表方法 | 优势 | 局限性 |
|---|---|---|---|---|
| 固定规划(Fixed Planning) | 预定义检索流程,无动态调整 | 文本中心检索(Plug-and-Play)、图像中心检索(Wiki-LLaVA) | 实现简单,适配单一场景 | 灵活性差,计算开销高,易产生冗余结果 |
| 自适应规划(Adaptive Planning) | 基于查询与上下文动态调整策略 | OmniSearch(自适应性规划代理)、CogPlanner(迭代查询优化) | 适配复杂查询,提升检索效率 | 模型复杂度高,需大量训练数据 |
4.多模态检索(Multimodal Retrieval)
作为 MRAG 的 "知识获取核心",从多模态向量数据库中精准召回与查询相关的多模态知识(文本片段、图像、视频等),为生成阶段提供事实依据,核心目标是 "高召回率 + 高相关性"。
4.1.检索器(Retriever)
核心组件,负责初步召回候选结果
| 架构类型 | 核心逻辑 | 适用场景 | 代表模型 / 方法 |
|---|---|---|---|
| 单 / 双流结构 | 单流:统一语义空间建模跨模态交互;双流:分离模态编码后对比对齐 | 单模态检索、跨模态检索(文本 - 图像 / 视频) | 单流:ColBERT;双流:CLIP、VSE++ |
| 生成式结构 | 通过生成文档标识符(DocID)实现检索,将检索转化为序列生成任务 | 文本检索、跨模态检索(文本 - 图像) | GENRE(文本 DocID 生成)、IRGen(视觉 token 生成) |
关键技术:
- 文本检索:稀疏检索(TF-IDF、BM25)、稠密检索(双编码器架构、多向量表征)。
- 跨模态检索:文本 - 图像(PVSE、IRRA)、文本 - 视频(CLIP4Clip、HiT)、文本 - 音频(ATR、CMRF)、统一多模态检索(FLAVA、UniIR)。
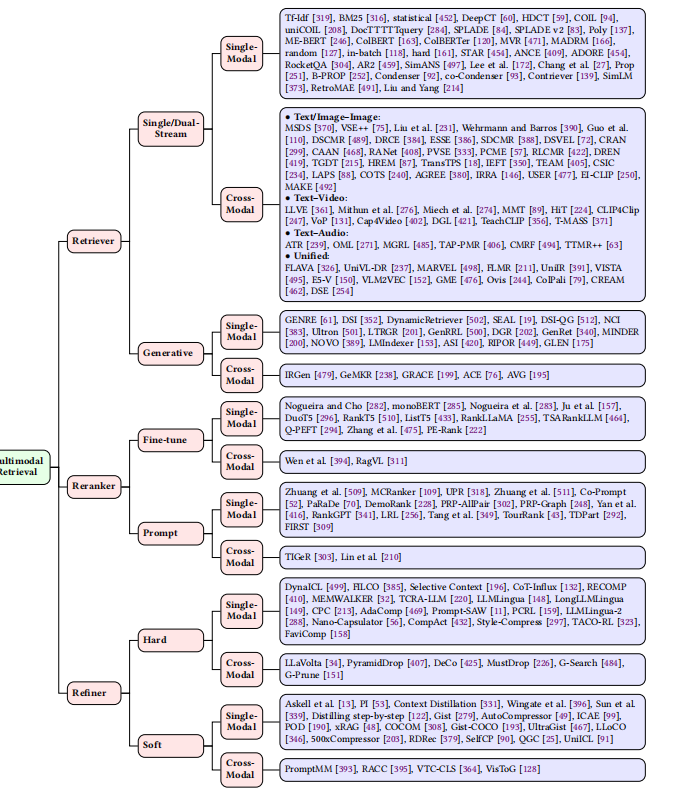
4.2.重排器(Reranker)
对初步召回结果排序,提升相关性
-
分类标准:基于大模型使用方式
类型 核心逻辑 优势 局限性 微调式(Fine-tuning-as-Reranker) 对 PLMs/MLLMs 进行监督微调,适配重排任务 相关性排序精度高 需大量标注数据,计算成本高 提示式(Prompting-as-Reranker) 零 / 少样本提示大模型,直接生成相关性排序 灵活高效,无需微调 性能依赖提示质量与模型通用性 -
关键方法:文本重排(monoBERT、RankLLaMA)、跨模态重排(RagVL、TIGeR)。
4.3.精炼器(Refiner)
优化检索结果,去除冗余 / 噪声,适配 LLM 输入
分类标准:提示类型
| 类型 | 核心逻辑 | 实现方式 | 代表方法 |
|---|---|---|---|
| 硬提示(Hard Prompt) | 过滤低价值内容,保留关键信息,使用自然语言 tokens | 规则过滤、语义压缩 | LLMLingua(困惑度 - based 压缩)、MustDrop(视觉 token 筛选) |
| 软提示(Soft Prompt) | 将提示编码为连续向量,嵌入模型输入层 | 无人工设计成本,适配模型优化 | Gist(元学习生成 gist tokens)、AutoCompressor(循环记忆压缩) |
核心目标:解决 LLM 上下文窗口有限、推理速度慢、灾难性遗忘问题。
5.多模态生成(Multimodal Generation)
作为 MRAG 的 "结果输出核心",基于用户查询与检索到的多模态知识,通过多模态大语言模型(MLLMs)生成包含多模态信息的响应(如文本 + 图像、文本 + 视频),核心目标是 "一致性 + 相关性 + 丰富度"。
5.1.输入模态与关键技术
| 输入模态组合 | 核心挑战 | 关键技术 | 代表模型 |
|---|---|---|---|
| 图像 + 文本 | 模态对齐与语义融合 | 视觉 - 语言预训练(VLP)、查询 Transformer | BLIP-2、Qwen-VL、LLaVA |
| 视频 + 文本 | 时空动态信息建模 | 视频分解(关键帧 + 运动)、时序 tokenization | Video-ChatGPT、Video-LaVIT |
| 统一任意模态 | 模态无关架构设计 | 多模态适配器、扩散解码器 | GPT-4、HuggingGPT、NExT-GPT |
5.2.输出模态与场景分类
- 输出模态类型:文本 + 图像、文本 + 视频、文本 + 音频、多模态混合(如文本 + 图像 + 表格)。
- 三大核心场景:
| 场景 | 定义 | 示例 | 关键要求 |
|---|---|---|---|
| 多模态数据即答案 | 无需文本,仅通过多模态数据即可回答查询 | "阿拉斯加雪橇犬与哈士奇的外观区别"→输出对比图像 | 多模态数据精准匹配查询意图 |
| 多模态数据提升准确性 | 多模态与文本结合,确保答案清晰无歧义 | "如何注册 Gmail 账号"→文本步骤 + 截图指引 | 多模态元素与文本步骤一一对应 |
| 多模态数据增强丰富度 | 多模态数据非必需,但提升用户体验 | "介绍埃菲尔铁塔"→文本描述 + 实景图像 / 视频 | 多模态元素与文本语义连贯 |
5.3.关键技术难点与解决方案
| 技术难点 | 解决方案 | 代表方法 |
|---|---|---|
| 多模态输入整合灵活性低 | 模态无关架构,动态适配任意输入组合 | NExT-GPT(多模态适配器 + 扩散解码器) |
| 多模态输出一致性差 | 跨模态对齐训练,确保文本与非文本信息匹配 | InternLM-XComposer(图像插入位置识别 + 相关性匹配) |
| 多模态元素插入位置不合理 | 基于文本语义与叙事流,智能判断插入点 | MuRAR(源归因确定插入点) |
| 输出多样性与相关性平衡 | 条件采样、多路径生成 | Conditional Diffusion(文本条件约束图像生成) |
6.数据集与评估(Dataset & Evaluation)
为 MRAG 系统的训练、验证与优化提供基准,通过标准化数据集与评估指标,量化系统在 "检索准确性、生成质量、多模态交互" 等维度的性能。
6.1.数据集
| 分类维度 | 类型 | 核心用途 | 代表性数据集 | 关键特征 |
|---|---|---|---|---|
| 任务目标 | 检索与生成联合数据集 | 评估端到端 MRAG 性能 | MultiModalQA | 29,918 个问题,覆盖文本 / 表格 / 图像,35.7% 需跨模态推理 |
| 任务目标 | 检索与生成联合数据集 | 视觉中心 MRAG 评估 | MRAG-bench | 1,353 个选择题,16,130 张图像,9 类场景 |
| 任务目标 | 生成专用数据集 | 多模态理解与生成基础评估 | MME | 14 个子任务,覆盖感知(如目标检测)与认知(如逻辑推理) |
| 任务目标 | 生成专用数据集 | 结构化文档处理评估 | DocVQA | 50,000 个问答对,12,767 张文档图像 |
| 应用场景 | 生成专用数据集 | 科学场景评估 | SciFIBench | 2000 个选择题,涉及 8 类科学图表,含对抗性负例 |
| 应用场景 | 生成专用数据集 | 工业场景评估 | MME-Industry | 21 个工业领域,1050 个问答对,50 个 / 领域 |
6.2.评估策略
评估策略(按实施主体)
| 策略 | 核心逻辑 | 优势 | 局限性 |
|---|---|---|---|
| 人类评估 | 人类标注者根据预设标准评分(如准确性、相关性) | 金标准,贴合真实用户需求 | 耗时耗力,易受主观偏见影响 |
| 规则 - based 评估 | 基于预定义规则 / 算法计算指标(如文本匹配度) | 客观高效,可复现性强 | 难以捕捉语义相关性与多模态一致性 |
| LLM/MLLM-based 评估 | 利用大模型对比生成结果与参考答案,自动评分 | 灵活全面,适配多模态场景 | 受模型自身偏见与能力限制 |
6.3.评估指标
| 指标类型 | 适用场景 | 代表性指标 | 计算逻辑 |
|---|---|---|---|
| 规则类指标 | 文本生成质量、检索准确性 | 精确匹配(EM) | 生成结果与参考答案完全一致则为 1,否则为 0 |
| 规则类指标 | 文本生成质量、检索准确性 | ROUGE-N | 计算生成文本与参考文本的 N 元组重叠率 |
| 规则类指标 | 检索准确性 | 平均 reciprocal 排名(MRR) | 首个相关结果排名的倒数平均值 |
| 规则类指标 | 图像描述质量 | CIDEr、SPICE | CIDEr:TF-IDF 加权文本相似度;SPICE:场景图语义匹配 |
| LLM 类指标 | 生成质量与忠实度 | 答案精度(Answer Precision) | 生成知识被参考答案支持的比例 |
| LLM 类指标 | 生成质量与忠实度 | 忠实度(Faithfulness) | 生成结果与检索知识的事实一致性 |
| LLM 类指标 | 生成质量与忠实度 | 幻觉率(Hallucination) | 生成内容中无事实依据的比例 |
补充:模块间协同流程
- 文档解析与索引 → 多模态搜索规划:解析后的结构化数据为搜索规划提供 "可检索模态类型" 与 "数据分布信息",帮助规划模块选择最优检索策略。
- 多模态搜索规划 → 多模态检索:规划模块输出的 "检索策略" 与 "优化后查询" 直接指导检索器的模态选择、重排器的排序标准、精炼器的优化方向。
- 多模态检索 → 多模态生成:精炼后的多模态知识作为 "外部上下文" 输入生成模块,与用户查询融合,确保生成结果的事实性与相关性。
- 多模态生成 → 反馈优化:生成结果可反向反馈至搜索规划与检索模块(如未找到相关多模态数据时,重新调整检索策略),形成闭环。