写在前面:
PostgreSQL 是一款开源、企业级的关系型数据库,凭借其强大的扩展性、完备的标准支持、极致的稳定性和丰富的生态 ,成为从传统业务到前沿科研场景的首选方案。它原生支持复杂SQL、事务ACID、JSON/JSONB等半结构化数据,更通过PostGIS扩展提供业界领先的地理空间数据处理能力,完美适配地球化学、GIS等空间数据密集型项目。
目录
前言
本文用到的注释说明:
| 符号 | 用途 | 使用位置 |
|---|---|---|
# |
Shell/Bash 注释 | Linux 命令行、脚本文件(.sh) |
-- |
SQL 注释 | psql 内部、SQL 文件(.sql) |
混用示例:
Shell 脚本中调用 psql
psql -U postgres -d dbname << EOF-- 这是 SQL 注释,在 EOF 块内有效
SELECT * FROM table_name;
EOFPostgreSQL数据库层级组织结构:
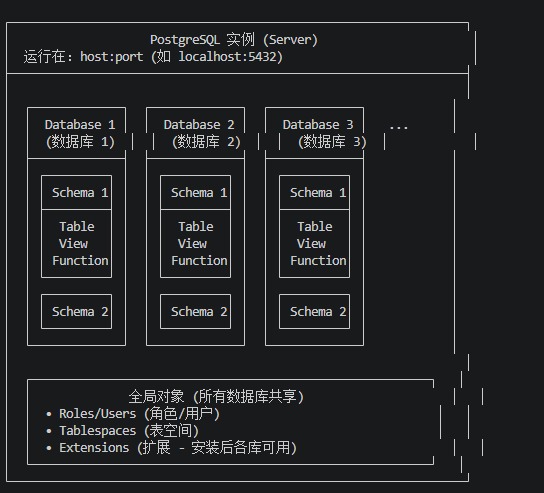
1、实例(Instance/Server)
PostgreSQL 服务器是一个持续运行的后台程序,负责监听网络连接(默认端口5432)、管理所有数据库、处理用户登录和权限验证、执行 SQL 查询并返回结果等等。
关键特点:
-
一台服务器上可以运行多个数据库
-
服务器有统一的配置文件,控制内存、连接数、日志等
-
一个 PostgreSQL 服务可以托管多个数据库
-
有统一的配置文件 postgresql.conf 和 pg_hba.conf
2、角色/用户(Roles/Users)
PostgreSQL中用户和角色是同一个概念,角色可以登录就是用户。
角色属性:
| 属性 | 说明 |
|---|---|
SUPERUSER |
超级管理员,bypass 所有权限检查 |
LOGIN |
可以登录数据库 |
CREATEDB |
可以创建数据库 |
CREATEROLE |
可以创建角色 |
INHERIT |
继承成员角色的权限 |
REPLICATION |
可以建立复制连接 |
3、数据库(Database)
-
数据库之间逻辑隔离:不同数据库之间的数据完全独立,一个连接以此智能访问一个数据库
-
客户端一次连接只能访问一个数据库
-
跨数据库查询需要用 dblink 扩展
4、Schema(模式)
模式是数据库内部的逻辑分组容器,用于组织表、视图、函数等对象。
为什么需要模式?
(1)避免命名冲突
不同模式可以有相同名字的表:
数据库:app_db
├── public 模式
│ └── 用户表
└── audit 模式
└── 用户表 (审计日志)
访问时用 public.用户表 或 audit.用户表区分。
(2)权限管理
可以按模式授予权限:
-
财务人员只能访问 finance 模式
-
开发人员只能访问 dev 模式
(3)业务分组
按业务模块组织:
数据库
├── sales 模式 (销售相关表)
├── inventory 模式 (库存相关表)
└── hr 模式 (人事相关表)
每个数据库创建时自动包含三个模式:
| 模式名 | 用途 | 能否删除 |
|---|---|---|
public |
用户默认使用的模式 | 能 |
pg_catalog |
系统表和函数 | 不能 |
information_schema |
标准元数据视图 | 不能 |
当查询表时不写模式名,PostgreSQL 会按搜索路径查找。
例如搜索路径是 sales, public:
查询 SELECT * FROM orders 会先找 sales.orders
如果找不到,再找 public.orders
5、数据表(Tables)
表是存储实际数据的结构,由行和列组成。
表的组成:
表:用户表
├── 列定义 (结构)
│ ├── id (整数,主键)
│ ├── 姓名 (文本,非空)
│ ├── 邮箱 (文本,唯一)
│ └── 创建时间 (时间戳,默认当前时间)
│
└── 数据行 (内容)
├── 行 1: (1, 张三,zhang@example.com, 2026-01-01)
├── 行 2: (2, 李四,li@example.com, 2026-01-02)
└── ...
表的约束:
| 约束类型 | 作用 |
|---|---|
| 主键(PRIMARY KEY) | 唯一标识一行 |
| 外键(FOREIGN KEY) | 引用其他表的主键 |
| 唯一(UNIQUE) | 列值不能重复 |
| 非空(NOT NULL) | 列值不能为空 |
| 检查(CHECK) | 列值必须满足条件 |
6、视图(Views)
视图是虚拟表,基于SQL查询结果定义,不存储实际数据。
视图的作用:
-
简化复杂查询:把多表关联写成一个视图,用户只需查询视图,不用关心底层结构
-
数据安全:视图可以隐藏敏感列,用户只能看到视图暴露的数据
-
统一数据口径:定义标准化的计算逻辑,所有用户得到一致的结果
7、扩展(Extensions)
扩展是PostgreSQL的插件机制,可以添加额外功能。
常用扩展介绍:
| 扩展名 | 核心价值与典型场景 |
|---|---|
postgis |
PostgreSQL 最核心的地理空间扩展,为地质、GIS 项目提供空间数据类型(如 geometry/geography)、空间索引、空间分析函数,是你地球化学数据库项目的核心依赖 |
pg_stat_statements |
数据库性能调优必备,可统计所有 SQL 的执行耗时、调用次数、IO 情况,用于慢查询排查与性能优化 |
dblink |
实现跨库数据查询,可在一个 PostgreSQL 实例中访问另一个实例的数据库,适合多库数据同步、跨库统计 |
uuid-ossp |
生成标准 UUID(如 UUIDv1/v4),用于分布式系统、唯一主键生成 |
pgcrypto |
提供加密 / 解密函数(如 pgp_sym_encrypt),用于敏感数据(如密码、密钥)的存储加密 |
pg_trgm |
基于三元组算法实现模糊匹配,支持 LIKE/ILIKE 模糊查询的索引加速,提升全文搜索、地址匹配效率 |
hstore |
存储键值对(key-value)数据,适合存储半结构化、动态属性数据,无需提前定义表结构 |
扩展是在数据库级别安装的:在数据库A安装postgis,不影响数据库B。安装后,该数据库的所有模式都可以使用扩展功能。
8、权限体系
权限从上到下继承:
服务器级权限
↓
数据库级权限
↓
模式级权限
↓
表级权限
↓
列级权限
权限类型
数据库级权限:
-
CONNECT --- 允许连接到数据库
-
CREATE --- 允许在数据库中创建新对象
-
TEMPORARY --- 允许创建临时表
模式级权限:
-
USAGE --- 允许使用模式中的对象
-
CREATE --- 允许在模式中创建新对象
表级权限:
-
SELECT --- 查询数据
-
INSERT --- 插入数据
-
UPDATE --- 更新数据
-
DELETE --- 删除数据
-
TRUNCATE --- 清空表
-
REFERENCES --- 创建外键引用
常见问题解答:
Q1: 什么时候用多个数据库,什么时候用多个模式?
用多个数据库:完全隔离、独立备份、不同应用
用多个模式:逻辑分组、共享数据、同一应用
Q2: 为什么默认都有一个 public 模式?
PostgreSQL 约定俗成的惯例,方便用户快速开始使用,不需要先创建模式。
Q3: 扩展安装后所有数据库都能用吗?
不能。扩展是在单个数据库中安装的,每个数据库需要单独安装。
Q4: 一个用户可以访问多个数据库吗?
可以。用户登录后可以切换到同一服务器上的任何数据库(如果有权限)。
Q5: 模式可以跨数据库访问吗?
不能。必须先切换到对应数据库,才能访问该数据库的模式。
一、连接数据库
#基本连接(username用户名默认为postgres,database_name数据表名默认为postgres)
psql -U username -d database_name#指定主机、端口
psql -h localhost -p 5432 -U username -d database_name#使用环境变量连接
export PGHOST=localhost
export PGPORT=5432
export PGUSER=postgres
export PGPASSWORD=your_password
export PGDATABASE=postgres
psql#连接字符串方式
psql "postgresql://username:password@host:port/database"#列出可连接的数据库
psql -U postgres -l二、psql内部命令
--列出所有数据库
\l 或 \list--列出所有表
\dt--列出所有表(含 schema)
\dt *.*--查看表结构
\d table_name--查看详细表结构(含索引、约束)
\d+ table_name--列出所有函数
\df--列出所有视图
\dv--列出所有序列
\ds--查看索引
\di--查看用户
\du--查看表空间
\db--切换数据库
\c database_name--查看当前数据库
\conninfo--查看schema
\dn--看表字段的详细描述
\d\d table_name三、用户与权限管理
--创建用户
CREATE USER username WITH PASSWORD 'password';--创建超级用户
CREATE USER admin WITH SUPERUSER;--删除用户
DROP USER username;--修改用户密码
ALTER USER username WITH PASSWORD 'new_password';--创建数据库
CREATE DATABASE dbname OWNER username;--删除数据库
DROP DATABASE dbname;--授权
GRANT ALL PRIVILEGES ON DATABASE dbname TO username;
GRANT SELECT ON TABLE table_name TO username;
GRANT ALL ON ALL TABLES IN SCHEMA public TO username;--撤销授权
REVOKE SELECT ON table_name FROM username;--查看用户权限
\du四、数据查询与管理
--基本查询
SELECT * FROM table_name LIMIT 10;--统计行数
SELECT COUNT(*) FROM table_name;--查看表结构
SELECT column_name, data_type, is_nullable
FROM information_schema.columns
WHERE table_name = 'table_name';--查看所有表
SELECT tablename FROM pg_tables WHERE schemaname = 'public';--查看数据库大小
SELECT pg_size_pretty(pg_database_size('dbname'));--查看表大小
SELECT
relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total
FROM pg_catalog.pg_statio_user_tables
ORDER BY pg_total_relation_size(relid) DESC;--查看活动连接
SELECT * FROM pg_stat_activity;--终止连接
SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'dbname';--清空表
TRUNCATE TABLE table_name;--删除表
DROP TABLE table_name;五、备份与恢复
#备份整个数据库
pg_dump -U postgres -d dbname -f backup.sql#备份为自定义格式(压缩、可选择恢复)
pg_dump -U postgres -d dbname -Fc -f backup.dump#备份指定表
pg_dump -U postgres -d dbname -t table_name -f table_backup.sql#备份所有数据库
pg_dumpall -U postgres -f all_backup.sql#只备份结构(无数据)
pg_dump -U postgres -d dbname -s -f schema_only.sql#恢复数据库
psql -U postgres -d dbname < backup.sql#恢复dump文件
pg_restore -U postgres -d dbname backup.dump#恢复时清楚原有数据
pg_restore -U postgres -d dbname --clean backup.dump#恢复指定表
pg_restore -U postgres -d dbname -t table_name backup.dump六、导入导出csv
#从SQL导出CSV
psql -U postgres -d dbname -c "\COPY (SELECT * FROM table_name) TO 'output.csv' WITH CSV HEADER"#从CSV导入数据
psql -U postgres -d dbname -c "\COPY table_name FROM 'input.csv' WITH CSV HEADER"#使用COPY命令(服务器端)
psql -U postgres -d dbname -c "COPY table_name TO '/path/output.csv' WITH CSV HEADER"#导入CSV到表
psql -U postgres -d dbname -c "COPY table_name FROM '/path/input.csv' WITH CSV HEADER"七、索引操作
--创建索引
CREATE INDEX idx_name ON table_name(column_name);--创建唯一索引
CREATE UNIQUE INDEX idx_name ON table_name(column_name);--创建复合索引
CREATE INDEX idx_name ON table_name(col1, col2);--创建表达式索引
CREATE INDEX idx_name ON table_name(LOWER(column_name));--创建部分索引
CREATE INDEX idx_name ON table_name(column_name) WHERE condition;--删除索引
DROP INDEX idx_name;--查看索引
SELECT indexname, indexdef FROM pg_indexes WHERE tablename = 'table_name';八、配置与维护
--查看配置参数
SHOW server_version;
SHOW work_mem;
SHOW shared_buffers;
SHOW max_connections;--查看所有配置
SELECT name, setting, unit FROM pg_settings;--重新加载配置
SELECT pg_reload_conf();--查看扩展
\dx--安装扩展postgis
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
CREATE EXTENSION IF NOT EXISTS postgis;--删除扩展
DROP EXTENSION extension_name;九、shell脚本实用命令
#!/bin/bash
#检查PostgreSQL是否运行
systemctl status postgresql#启动PostgreSQL
sudo systemctl start postgresql#停止PostgreSQL
sudo systemctl stop postgresql#重启PostgreSQL
sudo systemctl restart postgresql#查看PostgreSQL日志
tail -f /var/log/postgresql/postgresql-*.log#进入psql并执行SQL文件
psql -U postgres -d dbname -f script.sql#执行单条SQL并输出结果
psql -U postgres -d dbname -c "SELECT COUNT(*) FROM table_name;"#批量执行SQL
echo "SELECT * FROM table_name;" | psql -U postgres -d dbname欢迎交流!🌹🌹