一、背景介绍
之前写了一篇Flink实时场景下Hudi-Insert开发实践的文章,主要讲述纯插入操作场景下的技术原理与配置实践。然而,Upsert能力才是Hudi实现数据湖准实时数据更新的一大利器,Hudi凭借其Upsert(Update+Insert)能力,高效处理数据的插入、更新与删除操作,并保证基于主键的数据唯一性和一致性。今天聚焦在Hudi-Upsert操作场景,介绍Upsert模式的的技术原理、适用场景、关键参数与最佳实践,提供一套可落地的开发实践参考。
二、Hudi-Upsert技术特性与适用场景
1.Hudi-Upsert技术特性
Hudi的upsert模式是 Hudi-Flink 写入的核心模式,其核心逻辑为:将流式数据的插入、更新、删除操作统一写入 Hudi MOR 表,基于 主键(分区表需结合分区字段)的索引机制,自动将写入行为标记为update(主键已存在)或insert(主键不存在),保障表中数据的唯一性与一致性;同时支持基于precombine.field字段解决同主键数据冲突,基于hoodie.is_deleted字段实现物理删除。
- 增量写入:Flink 将 CDC 流数据写入 Hudi MOR 表的增量日志文件(Log File),保证秒级低延迟写入。
- 主键去重与冲突解决:基于「主键 + 分区字段」判断数据唯一性,若存在同主键数据,通过precombine.field指定的时间 / 版本字段排序,自动保留最新记录。
- 物理删除支持:通过hoodie.is_deleted字段标记删除记录,实现数据的物理删除(而非逻辑标记)。
- Compaction 合并:定期将 Log 文件合并到 Parquet 基础数据文件,生成新版本的基础文件,解决 Log 文件堆积问题,平衡读写性能。
2.Hudi-Upsert应用场景
基于Upsert模式的技术特性,其典型应用场景包括:
- 数据库变更流捕获(CDC)
从MySQL Binlog或Flink CDC流中获取的数据,包含大量INSERT、UPDATE、DELETE操作。使用Upsert模式写入Hudi MOR表,可确保Hudi表中始终保留每条记录的最新状态,且不会出现重复数据。这正是构建实时ODS层的核心方案。
- 实时数据同步与ETL
在数仓分层建设中,ODS层到DWD层的处理往往需要保留数据的变更历史。开启changelog.enabled参数后,Hudi MOR表可保留消息的所有变更(I/-U/U/D),下游Flink作业可进行全链路的增量计算。
- 数据湖上的近实时查询
对于需要兼顾写入实时性与查询性能的场景,MOR表的Upsert模式提供了理想的平衡------写入时仅追加Log文件,查询时通过Compaction合并成Parquet,实现分钟级数据可见。
三、Hudi-Upsert参数配置指南
1.Flink-Hudi表基础with参数
|------------------------------------------------------------|
| 'connector' = 'hudi' |
| 'table.type' = 'MERGE_ON_READ' |
| 'path' = '' |
| 'write.operation' = 'upsert' |
| 'hoodie.datasource.write.recordkey.field' = '' |
| 'hoodie.datasource.write.partitionpath.field' = '' |
| 'metadata.enabled' = 'false' |
| 'hive_sync.enable' = 'true' |
| 'hive_sync.db' = '' |
| 'hive_sync.table' = '' |
| 'hive_sync.mode' = 'hms' |
| 'hive_sync.metastore.uris' = '' |
| 'hive_sync.table.strategy' = 'RT' |
| 'hoodie.datasource.write.hive_style_partitioning' = 'true' |
| 'index.type' = 'BUCKET' |
| 'hoodie.bucket.index.num.buckets' = '' |
| 'write.precombine' = 'true' |
| 'precombine.field' = '' |
| 'write.rate.limit' = '' |
其他自定义参数可参阅Hudi官网(https://hudi.apache.org/docs/1.0.2/configurations)。
2.Compaction介绍
Compaction 是 Hudi MOR 表的独有核心机制,其核心逻辑是:定期将 MOR 表中的增量日志文件(Log File)合并到对应的Parquet 基础数据文件,生成新版本的基础数据文件,解决 Log 文件过多导致的查询性能下降问题,平衡写入延迟与查询性能。
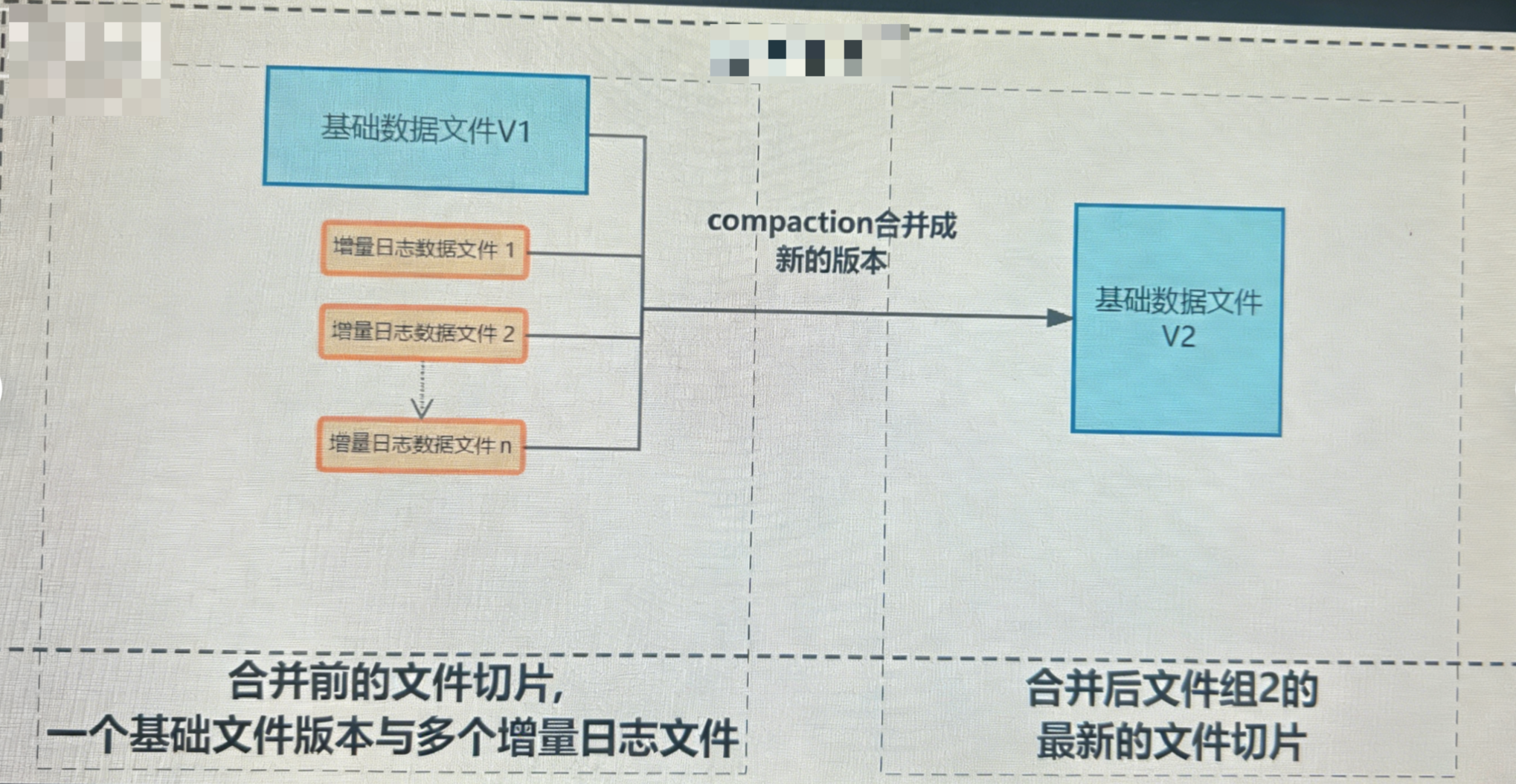
Compaction 分为两个独立阶段:
- 计划生成:由 Flink 写入任务实时生成合并计划(必须配置compaction.schedule.enabled='true');
- 计划执行:分为在线合并(Flink 任务内异步执行)和离线合并(独立 Spark 任务执行)两种方式,二选一。
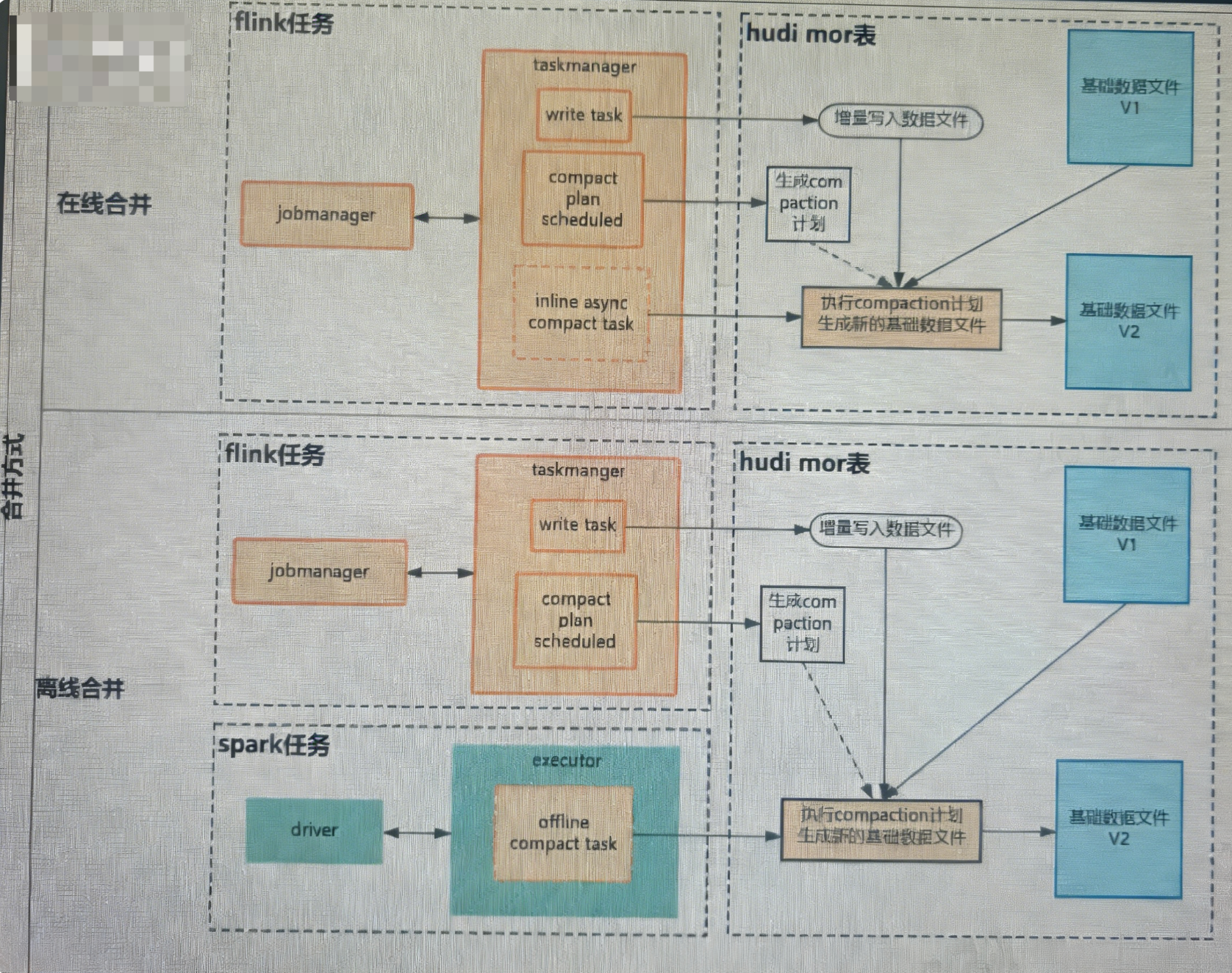
其中Compaction核心参数说明如下:
| 参数名 | 含义 | 默认值 | 详细说明 |
|---|---|---|---|
compaction.async.enabled |
是否启用异步合并(MOR 表专属) | true |
设为true为在线合并模式 ,false为离线合并模式 |
compaction.schedule.enabled |
是否启用生成合并计划(MOR 表专属) | true |
在线 / 离线合并均需设置为true,由 Flink 任务实时生成合并计划 |
compaction.trigger.strategy |
合并触发策略 | num_or_time |
支持按 commit 次数(num_commits)或时间(time)触发合并 |
compaction.delta_commits |
多少次 delta commit 生成合并计划 | 5 |
离线合并需与 checkpoint 间隔配合,至少 20-30 分钟生成一次计划,推荐配置 10-15 |
compaction.delta_seconds |
多少秒触发 compaction | 3600 |
离线合并需与 checkpoint 间隔配合,至少 20-30 分钟生成一次计划 |
compaction.max_memory |
合并可用内存(MB,超出则溢写) | 100 |
直接影响 log 文件合并效率,推荐不低于 300MB;数据量越大,需增大该值提升合并效率 |
write.task.max.size |
单个 write task 最大内存(MB) | 1024 |
单桶 1GB 的 Parquet 文件合并耗时约 5min,该值与compaction.max_memory共同决定合并性能 |
根据内部实践,内存设置一般存在以下关系:compaction.max_memory < write.task.max.size < taskmanager堆内存(约taskmanager总内存40%)。
3.在线/离线Compaction实践
为保障Hudi表数据查询性能,我们以20min内完成Compaction为目标,在内部展开多场景压测验证(数据大小、字段数、TPS、资源规格等),最后制定了一个Compaction策略选型的参考原则:
- checkpoint 间隔 120s
- 单条数据大小 0.2kb
- 表字段数 60
- parquet 文件大小推荐 0.3g~1g,最大不超过 2g
| 存量数据量 | 在线合并适用 TPS | 离线合并适用 TPS |
|---|---|---|
| 0-1000w | ≤4000 | >4000 |
| 1000w-2000w | ≤3000 | >3000 |
| ≥2000w或 TPS>4000 | 不推荐 | 推荐 |
- 存量数据量≤1000w(在线合并)
| TPS 区间 | TM 资源 | 合并和写入配置 |
|---|---|---|
| 0-1000 | 4c12g | 'compaction.max_memory'='300', ``'write.task.max.size'='1200',``'write.rate.limit'='1200' |
| 1000-2500 | 6c18g | 'compaction.max_memory'='500', ``'write.task.max.size'='1800',``'write.rate.limit'='3000' |
| 2500-4000 | 8c24g | 'compaction.max_memory'='500', ``'write.task.max.size'='1800',``'write.rate.limit'='6000' |
- 存量数据量 1000w-2000w(在线合并)
| TPS 区间 | TM 资源 | 合并和写入配置 |
|---|---|---|
| 0-1000 | 4c12g | 'compaction.max_memory'='300', ``'write.task.max.size'='1200',``'write.rate.limit'='1200' |
| 1000-2000 | 6c18g | 'compaction.max_memory'='500', ``'write.task.max.size'='1800',``'write.rate.limit'='3000' |
| 2000-3000 | 8c24g | 'compaction.max_memory'='500', ``'write.task.max.size'='1800',``'write.rate.limit'='5000' |
- 存量数据量>2000w或TPS>4000(离线合并)
| TPS 区间 | TM 资源 | 合并和写入配置 |
|---|---|---|
| 0-5000 | 4c12g | 'compaction.max_memory'='100', ``'write.task.max.size'='1200',``'write.rate.limit'='7000' |
| 5000-8000 | 6c18g | 'compaction.max_memory'='100', ``'write.task.max.size'='1900',``'write.rate.limit'='10000' |
| 8000-12000 | 8c24g | 'compaction.max_memory'='100', ``'write.task.max.size'='1900',``'write.rate.limit'='13000' |
四、总结展望
本文围绕Flink写入Hudi MOR表的Upsert模式,系统介绍了其技术原理、应用场景以及核心的Compaction配置实践。技术没有银弹,通过深入理解原理、结合场景精准调优,我们能够最大化发挥Flink-Hudi-Upsert组合的潜力,为实时数据湖建设提供坚实支撑。
五、附录(Flink-Hudi Upsert 与 Insert 多维对比)
| 对比维度 | Flink-Hudi Upsert-MOR | Flink-Hudi Insert-MOR | 核心选型结论 |
|---|---|---|---|
| 写入核心逻辑 | 主键匹配,支持增 / 改 / 删,自动去重、保留最新版本 | 纯追加写入,无主键匹配、无去重,允许主键重复 | 有更新 / 删除 / 保最新 → Upsert;纯日志追加 → Insert |
| 索引依赖 | 必须维护主键索引(Bucket/Bloom),索引开销高 | 不依赖主键索引,无索引查询 & 写入开销 | 高吞吐日志场景优先 Insert,节省索引资源 |
| 冲突处理 | 依赖precombine.field自动覆盖旧数据,解决乱序 |
不处理冲突,多条同主键数据全部留存 | 需要数据收敛→Upsert;需要全链路溯源→Insert |
| 删除能力 | 原生支持物理 / 逻辑删除 CDC 数据 | 不支持删除标记,删除数据会变成新增记录 | CDC 业务、订单状态变更必选 Upsert |
| 后台治理机制 | 依赖Compaction合并日志,解决增量更新堆积 | 依赖Clustering聚类,解决小文件碎片 | 合并目的不同:Upsart 收敛数据,Insert 规整文件 |
| 性能开销 | 写入延迟中等,高 TPS 下易受 Compaction 抢占资源 | 写入延迟极低,峰值吞吐远高于 Upsert | 亿级日志埋点、IoT 时序数据首选 Insert |
| 适用数据体量 | 中低~高 TPS,存量大、频繁更新的业务数据 | 超高 TPS,不可变、仅追加的流水数据 | 60 字段:Upsert 建议≤4000TPS,Insert 可上万 TPS |
| 运维复杂度 | 需区分在线 / 离线 Compaction,关注数据一致性 | 只需治理小文件 Clustering,逻辑简单 | 轻量化运维、快速上线优先 Insert |
| 典型业务场景 | MySQL CDC 入湖、实时维表、订单交易、用户画像 | APP 埋点、行为日志、系统监控、IoT 设备数据 | 业界标准选型,严格匹配业务数据特征 |