文章目录
- 前言
-
- [一、DIM 维度层概述:数仓里的 "标准字典" 与统一身份](#一、DIM 维度层概述:数仓里的 “标准字典” 与统一身份)
- [二、DIM 层独立分层的必要性:为什么一定要单独拆出来](#二、DIM 层独立分层的必要性:为什么一定要单独拆出来)
- [三、DIM 独立分层的开发思路:先做维度,再做明细](#三、DIM 独立分层的开发思路:先做维度,再做明细)
- [四、DIM 层核心关键点:唯一、准确、标准,是第一使命](#四、DIM 层核心关键点:唯一、准确、标准,是第一使命)
- [五、维度下沉策略:什么时候下沉 DWD、什么时候只在 DWS 关联](#五、维度下沉策略:什么时候下沉 DWD、什么时候只在 DWS 关联)
- 六、实战进阶:如何处理缓慢变化维
- 七、总结与结尾思考
前言
系列文章完整串联业务系统 + 数据集成 + 数据仓库 + BI 落地全链路。
深度拆解企业标准四层数仓架构 :ODS 原始层→DW 明细层→DIM 维度层→DM 主题层,详解每层设计逻辑、字段规范、脱敏规则、落地开发要点,搭配汽车流通 / 航空制造 ERP/MOM 真实业务案例 ,讲透如何把杂乱的原始数据,沉淀为企业可复用、可对账、可赋能的标准数据资产。
DIM 维度层:统一口径唯一身份证,独立分层落地策略
要实现数据的高效复用和灵活分析,还需要一个关键环节 ------ 维度层( DIM 层)。下面将聚焦 "DIM 维度层:维度建模与数据复用方案",讲解维度表的设计思 路、主数据管理方法,以及如何通过维度建模实现 "一次建模、多次复用",让数仓更具 灵活性和扩展性。
从真实开发顺序上,DIM 维度层应该优先于 DWD 层构建,再嵌入 DWD 层做协同开发 。但最终选择将它后置、单独成篇,主要基于两点考虑:第一,DIM 层并非传统数仓理论里的标准分层 ,如果放在 DWS 层之前同DWD层穿插讲解,容易打乱整体架构逻辑,给大家带来理解偏差。第二,在我看来,DIM 层无论什么业务场景,都建议要独立分层(虽然文章建议按业务场景确定) ,它直接决定口径统一、数据可信与长期可维护性,值得用一篇完整专题讲透、讲落地。因此,特意将 DIM 层单独拎出来,作为数仓实战中最关键、最容易被忽视的一篇重点讲解。
在汽车流通与航空制造这类复杂业务场景下,数仓建设常面临一个 "灵魂拷问":为什么销售报表的 "品牌销量" 和售后报表的 "品牌保有量" 永远对不上?为什么财务报表的 "客户等级" 和营销系统的定义差了三个百分点?
90% 的口径不一致、指标打架、分析不可信,问题往往不出在计算逻辑(Sum/Count 没算错),而出在维度没有统一、维度没有提前治理、维度没有独立沉淀。
很多团队做数仓,只知道 ODS→DWD→DWS→ADS,对 DIM 维度层要么模糊不清,要么直接揉进 DWD 里 "顺便处理"。初期虽快,但随着业务线扩张,这种 "宽表思维" 会导致数据资产越来越重,维护成本指数级上升。
把 DIM 层单独拎出来,结合双行业实战经验,讲清楚:是什么、为什么要独立分层、怎么做、怎么下沉、怎么复用。
一、DIM 维度层概述:数仓里的 "标准字典" 与统一身份
在传统经典数仓模型里,维度(DIM)通常不做独立分层,而是和事实表一起在 DWD 明细层中配套开发。但在企业级复杂业务、多系统、强合规、高数据质量要求的场景下,把 DIM 独立分层,会让整个数仓的稳定性、复用性、一致性提升一个量级。
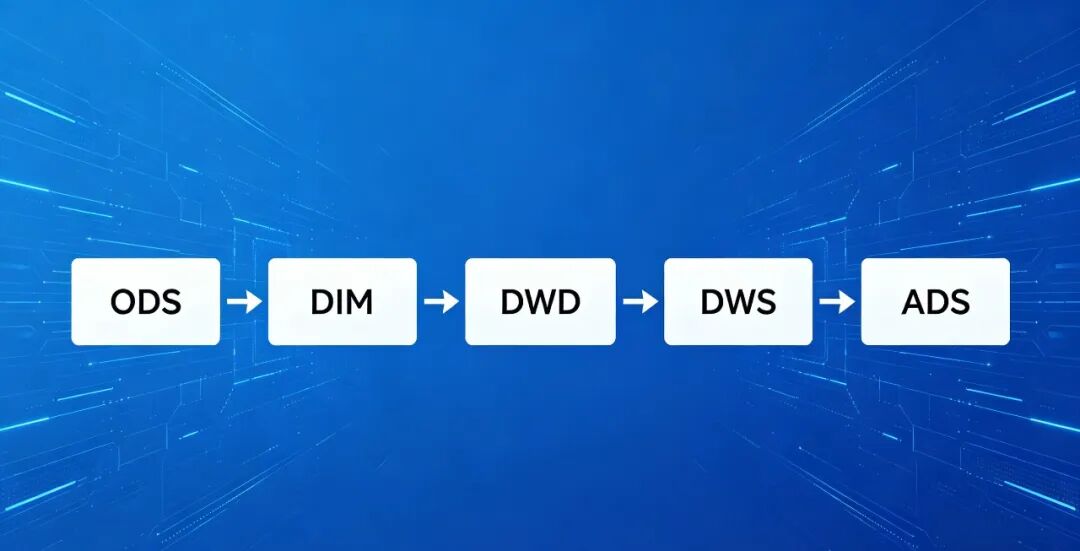
简单理解各层定位:
-
ODS
:原始数据入口,黑匣子,保持与业务库一致。
-
DIM
:标准维度字典,提供全局唯一的 "身份证"。
-
DWD
:业务事实明细,清洗后的行为数据。
-
DWS
:主题汇总数据,面向分析。
-
ADS
:应用数据,直接给报表 / 大屏 / 接口。
DIM 层的核心作用:
-
维度标准化
:把各系统混乱的名称(如 "华晨宝马" vs "宝马汽车")、编码、状态、枚举统一成一套标准口径。
-
主数据唯一化
:一个客户、一台车、一个零件、一个门店,全局只有唯一标识(Surrogate Key)。
-
分析能力支撑
:支撑按区域、品牌、车型、时间、供应商等任意维度筛选、下钻、聚合。
-
缓慢变化管理
:记录维度历史变更(如门店更名、客户升级、零件替换),支持回溯分析。
一句话总结:事实表决定你 "统计了什么",维度表决定你 "怎么看懂这些数据"。
二、DIM 层独立分层的必要性:为什么一定要单独拆出来
很多数仓项目一开始图快,不做独立 DIM 层,直接把维度字段写死在 DWD 宽表里,后期会付出巨大代价。独立 DIM 分层,核心解决 4 个问题:

-
**形成企业级 "数据说明书"**DIM 层就是数仓的官方字典:品牌有哪些、车系有哪些、客户如何分类、零件如何划分。独立分层后,全公司所有分析、报表、大屏,都用同一套说明,不再各说各话。
-
极高的复用价值,一次开发处处用车型维度、客户维度、门店维度、供应商维度...... 几乎所有业务主题都会复用。独立维护一套,销售、售后、库存、金融、生产、质量全都调用,不用重复开发、重复清洗、重复对齐。
-
**保证全场景 "唯一标签"**一台车、一个客户、一个订单,在销售里是一个标签,在售后里是同一个标签,在财务里还是同一个标签。DIM 独立分层,就是为了全局唯一、全域一致。
-
数据治理与质量可控维度是数据质量的重灾区:错别字、简称、别名、空值、乱码。DIM 单独分层,可以集中清洗、集中校验、集中质控、集中发布,从源头解决脏数据。
三、DIM 独立分层的开发思路:先做维度,再做明细
在复杂业务(汽车流通、航空制造)里,正确的数仓开发顺序不是从 ODS 直接跑 DWD,而是:ODS → 优先建设 DIM → 再开发 DWD 事实明细
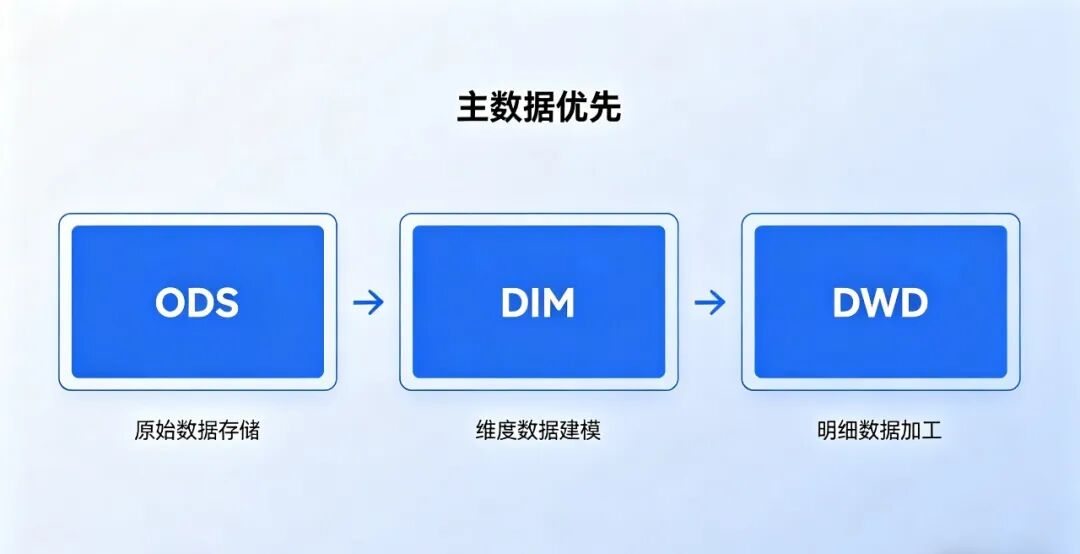
-
数据来源:对接 ODS 层原始主数据所有维度的源头,全部来自 ODS 层:客户、商品、车型来自 ODS 业务主数据表;组织、门店、人员来自 ODS 系统基础表;供应商、物料、工序来自 ODS 的 MES/WMS 数据。不允许跳过 ODS 直接接业务库,不允许手写硬编码维度。
-
开发顺序:DIM 优先于 DWD 构建先把分析要用的维度全部建好、洗好、发布稳定,再去做 DWD 事实宽表。
-
DWD 开发只需要 "关联",不需要 "边做边洗维度"
-
需求变更时,只改 DIM,不用改一堆 DWD/DWS
-
数据问题定位极快:事实是事实,维度是维度,互不干扰
- 集中整合:形成全场景标准维度池
把跨系统、跨业务域的维度,在 DIM 层统一整合、统一编码、统一名称。
汽车流通行业示例:
-
产品类维度:品牌维度、车系维度、车型维度、车型细分维度
-
主体类维度:客户维度(姓名、年龄、性别、等级、标签)
-
业务类维度:保险维度(交强险、商业险、险种、保单状态)
-
售后类维度:维修类型维度、故障类型维度、配件维度、工位维度
所有分析场景:新车销售、二手车、售后维修、续保、延保、会员、库存...... 全部从这一套 DIM 取数。
- DIM 复用:让 DWD 只关心事实,不关心口径
DWD 开发时,直接通过唯一键关联 DIM,即可拿到标准名称、标准编码、标准枚举。从而保证:
-
数据准确(来源唯一,不会出现两个版本)
-
数据唯一(同一主体在任何明细里标识一致)
-
可追溯(出问题直接查 DIM,快速定位)
四、DIM 层核心关键点:唯一、准确、标准,是第一使命
DIM 层和其他层最大的不同:ODS 求原始、DWD 求清晰、DWS 求高效、DIM 求唯一、准确、标准。
- DIM 只保证三件事
-
唯一性:一个实体只有一条最新有效记录
-
标准性:名称、编码、状态、描述统一
-
准确性:经过清洗、去重、规则校验,可对外发布
- 独立分层带来的核心收益:跨场景口径绝对一致
举一个汽车流通真实痛点案例:
-
销售分析用的品牌、车系、车型,是销售系统标准录入
-
售后维修分析用的品牌、车系、车型,是维修工单手工录入
-
没有独立 DIM 层时,两边各自写死在宽表里
-
结果:售后大量错别字、简称、乱填,导致销售统计的品牌≠售后统计的品牌,报表对不上,领导不认,审计不过
**DIM 独立分层后:**先集中把品牌 / 车系 / 车型洗成唯一标准;销售 DWD 关联 DIM;售后 DWD 也关联 DIM。从此:销售怎么看,售后就怎么看,全公司口径统一。
五、维度下沉策略:什么时候下沉 DWD、什么时候只在 DWS 关联
DIM 独立分层后,会面临一个高频问题:维度字段要不要下沉(冗余)到 DWD 明细宽表里?

一句话先讲透:下沉 = 空间换性能,不下沉 = 性能换空间。
- 推荐做法:核心场景维度下沉到 DWD 明细层
把常用维度字段(如品牌、车系、车型、客户等级、门店区域)直接冗余到 DWD。
-
好处:支持明细下钻、分析性能极高、业务使用更简单
-
坏处:明细层存在数据冗余,占用一定存储
- 特殊情况:非核心场景不在 DWD 下沉
如果场景是非核心、低频、临时分析,可以:
-
DWD 只存维度主键(如 dim_vehicle_id)
-
在 DWS 聚合时再关联 DIM 取名称
-
好处:节省存储、降低开发成本、加工更快
- 重要结论:DIM 是否独立分层,看业务复杂度
-
业务复杂、多系统、数据质量严、审计要求高(汽车 / 航空 / 制造)→ 强烈建议 DIM 独立分层,稳定、复用、好治理
-
业务简单、系统少、低成本优先、要求不高→ 可直接把维度做到 DWD 里,不独立分层
下沉原则:
核心业务场景 → 下沉到 DWD 明细
非核心场景 → 只在 DWS 聚合时关联
六、实战进阶:如何处理缓慢变化维
在 DIM 层建设中,最棘手的是缓慢变化维。例如:一个客户从 "普通" 升级为 "VIP",或者一家门店从渝中区搬到了两江新区。
- 拉链表(SCD Type 2)
汽车、航空行业强烈推荐优先使用。在 DIM 表中增加start_date和end_date字段。
-
操作方式:变更时不覆盖原记录,原记录结束日期置为变更前一天,新增一条生效记录
-
价值:可精准还原 "交易发生时" 的维度状态,支持历史回溯与审计
- 覆盖法(SCD Type 1)
直接覆盖旧值。
- 适用场景:对历史状态不敏感,如 "修正错别字"
七、总结与结尾思考
DIM 维度层,是数仓里最容易被忽视、但价值最稳定的一层。它不直接产生报表,却决定所有报表可不可信;它不直接承担计算,却管住所有计算的口径。
-
传统数仓里,DIM 常合并在 DWD
-
复杂企业实战中,DIM 必须独立分层
-
DIM 优先开发,保证唯一、准确、标准
-
核心维度下沉 DWD,支撑下钻与高效分析
-
非核心按需关联,兼顾成本与效率
回到开头的问题:为什么你的指标总对不上?很可能不是计算错了,而是维度没有独立、没有统一、没有提前治理。把 DIM 层建好,你的数仓就成功了一半。
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
数仓实战第四篇|DIM 维度层:统一口径唯一身份证,独立分层落地策略(汽车流通 + 航空制造双行业实战版)