
在医学图像分割领域,近年来基于CNN和Vision Transformer(ViT)的模型层出不穷。然而,在面对皮肤病变(如黑色素瘤)时,这些模型往往面临着边界模糊、毛发遮挡、病灶颜色形态变化剧烈等严峻挑战。下图中(a) 是皮肤病变分割中的挑战性案例:第一行是颜色、形状和尺寸变化的挑战,第二行是模糊的边界,第三行是毛发遮挡,第四行是噪声干扰。
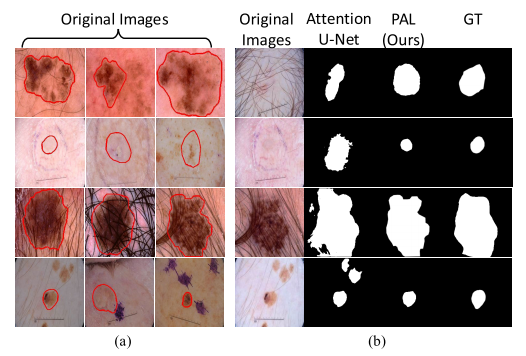
真实的皮肤科医生是如何克服这些干扰的?在临床中,医生绝不是仅凭第一眼的"整体感觉"下结论,而是依据ABCD准则(Asymmetry不对称性、Border边缘不规则、Color颜色变化、Diameter直径),将复杂的病灶**拆解为多个独立的"属性"**进行综合评估。
发表于医学图像顶级期刊 IEEE TMI (2025) 的论文《PAL: Boosting Skin Lesion Segmentation via Probabilistic Attribute Learning》,正是敏锐地捕捉到了这一临床直觉。它跳出了"端到端黑盒提取"的固有范式,提出了一种极具启发性的概率属性学习(PAL)框架。
本文将结合该论文的开源代码与核心数学推导,拆解这套"拥有医生解耦思维"的算法框架,并从工程落地的视角给出评判性分析。
一、 核心破局点:从"确定性黑盒"到"概率化分布"
现有的深度学习模型通常将图像映射为一个确定的、单一的高维特征向量。但在皮肤镜图像中,同一个病灶的内部属性可能截然不同(例如左侧深黑,右侧浅红)。用一个固定的向量去概括它,必然会丢失细节。PAL框架的思路是:不要用"一个确定的值"来表示病灶属性,而是将其建模为一个"高斯概率分布"。
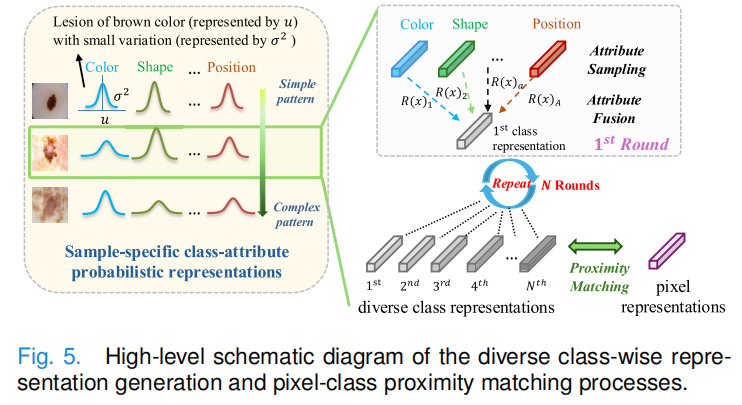
在论文图5中可以看到,PAL模型将颜色、形状等属性建模为高斯分布。通过蒙特卡洛采样(Sampling)和属性融合(Fusion),模型动态生成了 NNN 种不同的病灶形态参考,极大地拓宽了对病灶异质性的包容度。
模型通过推断出每个属性的均值 μ\muμ(最可能的模式)和方差 σ\sigmaσ(模式的变化程度),构建出多元高斯分布。随后,通过蒙特卡洛采样(Monte Carlo Sampling)从中抽取多个具体的属性特征。这就好比让AI在脑海中"构想"出该病灶可能呈现的几十种合理外观,从而在匹配时做到"见多识广"。
二、 PAL 架构
结合论文开源的PyTorch实现,可以将PAL的运转逻辑严谨地划分为以下四个阶段。论文架构在图2中有完整展示,图像特征进入双分支网络,概率头(Probabilistic Head)通过引入元属性表示(Meta class-attribute representations),经过 PMM 模块推断出分布,最终在多次采样与融合后完成像素级的概率匹配。
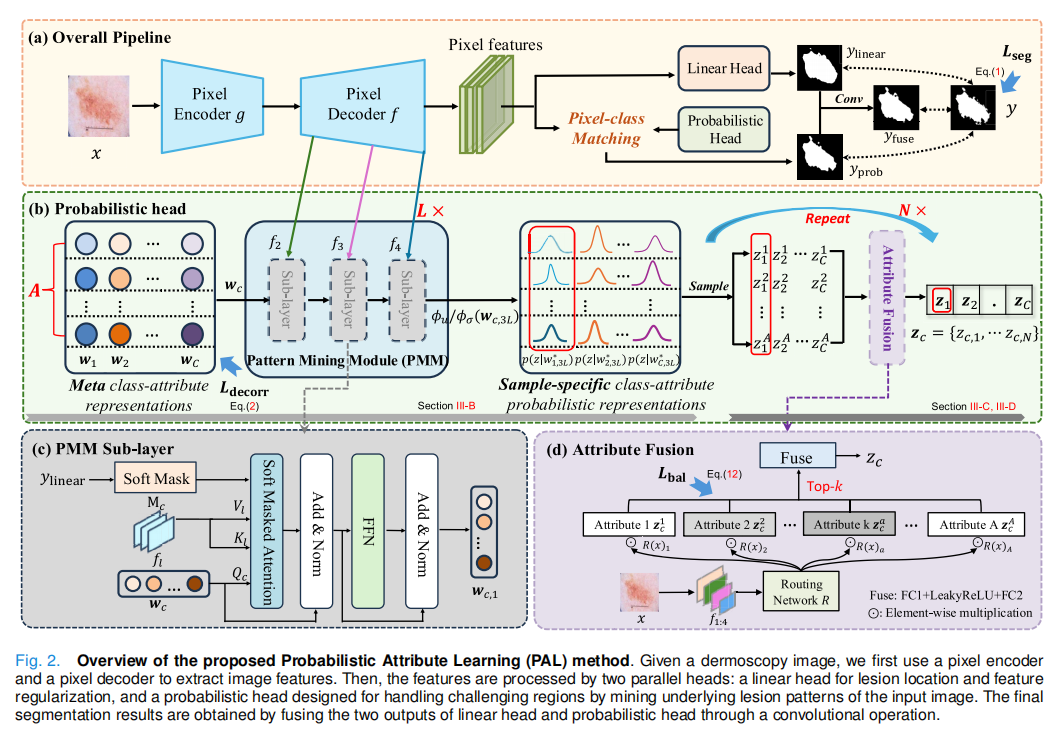
首先解释清楚上面的架构图:
图 2(a):宏观特征提取与双分支流水线
这部分展示了网络的骨干和宏观拓扑结构。
1.特征提取 (Pixel Encoder & Pixel Decoder): 给定一张皮肤镜图像 xxx,网络首先通过像素编码器(本文使用的是金字塔视觉 Transformer,即 PVTv2)提取多尺度特征,然后通过由独立线性层组成的像素解码器生成金字塔特征映射 。
2.双分支设计 (Dual Heads): 提取出的像素特征被送入两个并行的分支 :
线性头 (Linear Head): 这是一个常规的卷积分类头,主要用于病灶的粗略定位和特征正则化,它输出一个初步的分割结果 ylineary_{linear}ylinear 。
概率头 (Probabilistic Head): 这是本文的核心创新,专门用于处理诸如模糊边界、噪声干扰等具有挑战性的区域,它通过挖掘潜在的病灶模式来输出概率分割结果 yproby_{prob}yprob 。
3.输出融合: 最终,网络将 ylineary_{linear}ylinear 和 yproby_{prob}yprob 拼接后,通过一个卷积操作融合(Conv),得到最终的分割预测 yfusey_{fuse}yfuse 。
图 2(b):概率头内部机制 (Probabilistic head)
这是图 2 最庞大的部分,揭示了模型是如何利用概率和属性进行推理的。它分为三个连续的步骤:
-
输入先验 (Meta class-attribute representations): 图最左侧的矩阵 AAA 代表模型在全局训练中学习到的"元类-属性表示"(包含颜色、形状等通用知识),记为 wcw_cwc 。
-
模式挖掘 (Pattern Mining Module, PMM): 元表示 wcw_cwc 与图像的特征图 (f2,f3,f4)(f_2, f_3, f_4)(f2,f3,f4) 一起进入 PMM 模块(循环 LLL 次) 。经过 PMM 的处理后,网络输出了特定于当前图像的均值 μ\muμ 和方差 σ\sigmaσ 。这就在图中间生成了一排**"样本特定的高斯概率分布 (Sample-specific class-attribute probabilistic representations)"** 。
-
采样与循环 (Sample & Repeat): 模型通过蒙特卡洛采样(Sample),从这些分布中随机抽取具体的属性向量 zc1,zc2...z_c^1, z_c^2...zc1,zc2... 。为了获得丰富的模式,这个"采样+融合"的过程会重复执行 NNN 轮 (Repeat N×N \timesN×) ,从而产生 NNN 个不同的综合类别表示 zcz_czc 。
图 2©:模式挖掘子层微观结构 (PMM Sub-layer)
图 2© 放大了图 2(b) 中 PMM 模块的内部细节 。它的核心是软掩码注意力机制 (Soft Masked Attention) 。注意看左上角的 ylinear→Soft Mask Mcy_{linear} \rightarrow \text{Soft Mask } M_cylinear→Soft Mask Mc 。这里模型极其巧妙地利用了线性头 (Linear Head) 生成的初步预测结果 ylineary_{linear}ylinear,来制作一个软掩码矩阵 。这个掩码在计算 Cross-Attention 时,会引导网络把注意力集中在病灶区域,同时给背景区域赋予一个负的常数权重(而不是彻底屏蔽),从而抗干扰并防止训练崩溃 。
图 2(d):属性融合机制 (Attribute Fusion)
图 2(d) 解释了从高斯分布中采样出的 AAA 个独立属性,是如何被组合成一个完整的病灶表示 zcz_czc 的 。
路由网络 (Routing Network R): 并不是所有属性都同等重要。网络根据当前的图像特征 xxx,通过一个路由网络(借鉴了 Mixture of Experts 混合专家思想),计算出每个属性的重要性得分 R(x)R(x)R(x) 。
Top-k 选择与融合: 路由网络会挑选出得分最高的 kkk 个属性(Top-k),用得分乘以属性特征(Element-wise multiplication)后,送入全连接层(Fuse: FC1+LeakyReLU+FC2)进行非线性融合,最终输出这一轮的综合类别表示 zcz_czc 。
当图 2(b) 循环执行 NNN 次后,模型就拥有了 NNN 种不同的类别表示向量 。最后,看图 2(a) 中间的 Pixel-class Matching 连线 。网络会将提取出的每一个像素特征,与这 NNN 种类别的表示计算余弦相似度并求平均,以此产生极其鲁棒的概率分割预测 yproby_{prob}yprob 。整个图 2 展示了如何将粗糙的图像特征,转化为具有多属性解耦能力的概率分布,并最终指导精细化分割的全过程。
三、细节与源码解析
1. 提取全局先验:矩阵 AAA 到底是如何学习的?
在论文的网络架构中,模型一开始需要一组"元类-属性表示(Meta class-attribute representations)",记为 wcw_cwc(图2(b))。这 AAA 个属性(论文中皮肤数据集设定为 A=10A=10A=10)是如何从图片中提取出来的呢?其实这是一个常见的认知误区。在底层代码中,这 AAA 个属性并不是 从当前输入图像中卷积出来的,而是作为网络的可学习参数(Learnable Parameters)全局固化的。在mask2former_decoder.py
python
if shareW:
# 类别属性的 Query (即论文中的矩阵 A)
self.query_feat = nn.ModuleList(
[nn.Embedding(self.cls_attributes, self.hidden_dim).cuda() for _ in range(num_queries)])在代码中,矩阵 AAA 本质上是一个 nn.Embedding 层。在模型训练的成千上万次迭代中,所有的皮肤镜图像都在反向传播时打磨这同一组 Embedding 的权重。最终,这组参数收敛成了一本**"全局先验字典"**------它记录了整个数据集中病灶最普遍的10种属性规律。
2. 探寻当前病灶:PMM模块与软掩码注意力
拿到一张新图像后,全局字典 wcw_cwc 需要与图像的多尺度特征(OS32, OS16, OS8)进行交互,以推断出当前这幅图中病灶属性的高斯分布。这一步在模式挖掘模块(PMM)中完成。
这其中包含两个极具工程价值的设计:
设计1:多尺度轮询式串行迭代: 作者设计了巧妙的"多尺度轮询式串行迭代 (Round-Robin Serial Iteration)"。 元表示 wcw_cwc 与图像特征 (f2,f3,f4)(f_2, f_3, f_4)(f2,f3,f4)不是 拼接在一起的,也不是 独立运行的,而是让 wcw_cwc 像闯关一样,依次穿过层层关卡,每次只跟某一个尺度的特征图进行交互。在 mask2former_decoder.py 的 forward 函数中:
python
# 外层循环:迭代 self.num_layers 次(对应论文的 3L 次,通常 dec_layers=9)
for i in range(self.num_layers):
# 核心魔法:取余数决定当前层用哪个尺度的特征图
level_index = i % self.num_feature_levels
# 获取掩码 (Soft Mask)
attn_mask = ...
# 交叉注意力机制 (Cross-Attention)
output = self.transformer_cross_attention_layers[i](
output, src[level_index], ... # src就是图像多尺度特征
)
# FFN
output = self.transformer_ffn_layers[i](output)图像提取出的多尺度特征 src 是一个列表,包含了 3 个不同分辨率的特征图 [OS32, OS16, OS8](分别对应代码里的 out5, out4, out3,即论文中的 f4,f3,f2f_4, f_3, f_2f4,f3,f2 级别)。
串行传递(Serial): 注意代码中的 output = layer(output, ...)。上一层的输出 output 直接作为下一层的输入 Query 继续运算。这意味着状态是累加和不断进化的。
轮询交互(Round-Robin): 代码 level_index = i % 3 揭示了多尺度特征并没有被拼成一个巨大的张量。第 0 层 (i=0): wcw_cwc 和 src[0] (最小分辨率,最高语义 OS32) 做 Cross-Attention。第 1 层 (i=1): 经过更新的 wc′w_c'wc′ 和 src[1] (中等分辨率 OS16) 做 Cross-Attention。第 2 层 (i=2): 再次更新的 wc′′w_c''wc′′ 和 src[2] (最大分辨率,最细纹理 OS8) 做 Cross-Attention。第 3 层 (i=3): 重新回到 src[0],循环往复。
对应论文中的 3L 结构: 论文提到 PMM 包含 3 层,并重复 LLL 次(总共 3L3L3L 层)。在代码中,如果你设置 args.dec_layers = 9,那么这个轮询(0->1->2)正好执行了 3 轮(L=3L=3L=3)。
可以认为wcw_cwc 是一组不断进化的全局代表。它从 nn.Embedding 出发,在 PMM 模块中进行 3L3L3L 次串行迭代 。在迭代过程中,它交替地、由粗到细地(OS32 -> OS16 -> OS8)向图像的不同特征层"询问"信息(Cross-Attention),最终蜕变成融合了当前图像所有尺度细节的特定样本表示 (Sample-specific representation)。
设计2:软掩码注意力 (Soft Masked Attention): 为了防止模型被大面积的背景噪声带偏,PAL利用一个辅助的线性分类头生成了粗略的预测,并转化为软掩码。背景区域被赋予一个负的常数 κ\kappaκ(实验中最优为 κ=−2\kappa=-2κ=−2),而不是传统的 −∞-\infty−∞。这种"保留合理干扰"的软掩码机制,有效防止了训练初期全背景导致 Softmax 出现 NaN(梯度爆炸)的致命错误,显著增强了鲁棒性。
3. 混合专家路由:Top-k 属性筛选
采样出 AAA 个具体属性后,模型需要将它们融合为一个完整的类别表示。但在不同的病灶中,各个属性的重要性是不同的(例如,颜色极浅的病灶,其形状和位置属性就更具决定性)。
PAL 引入了一个路由网络 R(x)R(x)R(x),基于当前图像特征计算出 10 个属性的得分,并仅挑选出得分最高的 kkk 个属性(实验设定 k=3k=3k=3)进行非线性融合。
zc=Fuse(flatten(R(x)∗zc1,...,zcA))z_c = \text{Fuse}(\text{flatten}(R(x) * z_c\^1, ..., z_c\^A))zc=Fuse(flatten(R(x)∗zc1,...,zcA))
为什么是 k=3k=3k=3? 论文的消融实验表明,增加 kkk 可以捕获更多样化的特征,但如果选中过多属性(例如 k>5k>5k>5),模型容易拟合到无关的噪声信息。k=3k=3k=3 是一个平衡了特征多样性与抗噪能力的最佳经验值。
4. 最终裁决:为什么要对 NNN 次匹配求平均?
经过上述步骤,模型循环执行了 N=15N=15N=15 轮,生成了 15 个不同的类别表示(即 15 种子模式)。最后,模型提取出图像中的每一个像素特征,与这 15 个模式分别计算余弦相似度,并求期望(平均值)。
yprob=Ezcp(yc∣xi,zc)=1N∑n=1Nexp(d(f(xi),zc,n)/τ)∑exp(... )y_{prob} = \mathbb{E}{z_c}p(y_c\|x_i, z_c) = \frac{1}{N} \sum{n=1}^N \frac{\exp(d(f(x_i), z_{c,n})/\tau)}{\sum \exp(\dots)}yprob=Ezcp(yc∣xi,zc)=N1n=1∑N∑exp(...)exp(d(f(xi),zc,n)/τ)
你可能会有疑问:为什么要费力生成 15 个表示并求平均,而不是直接输出一个最准的?
这里蕴含着概率论与集成学习思想:
- 数学层面的蒙特卡洛积分: 由于病灶属性是连续的高斯分布,要计算像素属于该类的绝对概率,在数学上需要对分布求积分。在神经网络中,"对 NNN 个随机采样样本求平均"就是对积分期望的无偏估计。
- 规避高方差与漏诊: 重参数化采样(z=μ+ϵσz = \mu + \epsilon \sigmaz=μ+ϵσ)带有随机性。如果只采样 1 次,恰好取到了分布边缘的极端特征(如罕见的极浅色模式),正常像素的匹配度就会极低,导致假阴性。求平均相当于建立了一个"15人专家委员会",极大地降低了单次采样带来的预测方差,包容了病灶内部极高的类内异质性(Intra-class Heterogeneity)。
三、防止模式崩塌的双重Loss
为了保证概率和路由机制不"形同虚设",作者引入了两个严谨的辅助损失函数:
去相关损失 (LdecorrL_{decorr}Ldecorr): 通过惩罚元表示矩阵 wcwcTw_c w_c^TwcwcT 的非对角线元素,从数学上强制要求不同的属性向量必须是正交/独立的,真正实现了物理意义上的"属性解耦"。
路由平衡损失 (LbalL_{bal}Lbal): 利用变异系数(Coefficient of Variation, CV)作为惩罚项。防止 Top-k 路由网络"偷懒"永远只选那固定的 3 个属性,迫使模型在全局训练中对所有属性"雨露均沾"。
四、实验结果
为了验证概率属性学习(PAL)的实际效能,作者在两大类截然不同的医学图像任务上进行了详尽的测试,并辅以严密的消融实验来证明每一个模块的不可或缺性。
1. 皮肤病变主战场:突破模糊边界与复杂干扰
在 ISIC 2017 和 ISIC 2018 两个公认的皮肤病变基准数据集上,作者将 PAL(分别搭载 ResNet50 和 PVTv2 骨干网络)与涵盖了 CNN 系列(如 U-Net, nnUNet)和 Transformer 系列(如 TransUNet, XBound-Former)的最前沿模型进行了全面对比 。
量化指标的全面领先: 如论文的 Table I 所示,搭载 PVTv2 的 PAL 模型在 ISIC 2017 上实现了 0.8191 的 IoU 和 0.8912 的 Dice 系数,在衡量边界贴合度的 HD95(95% 豪斯多夫距离)上更是降至 12.3324 。这表明模型不仅"找得准"病灶主体,而且"画得精"病灶边缘。
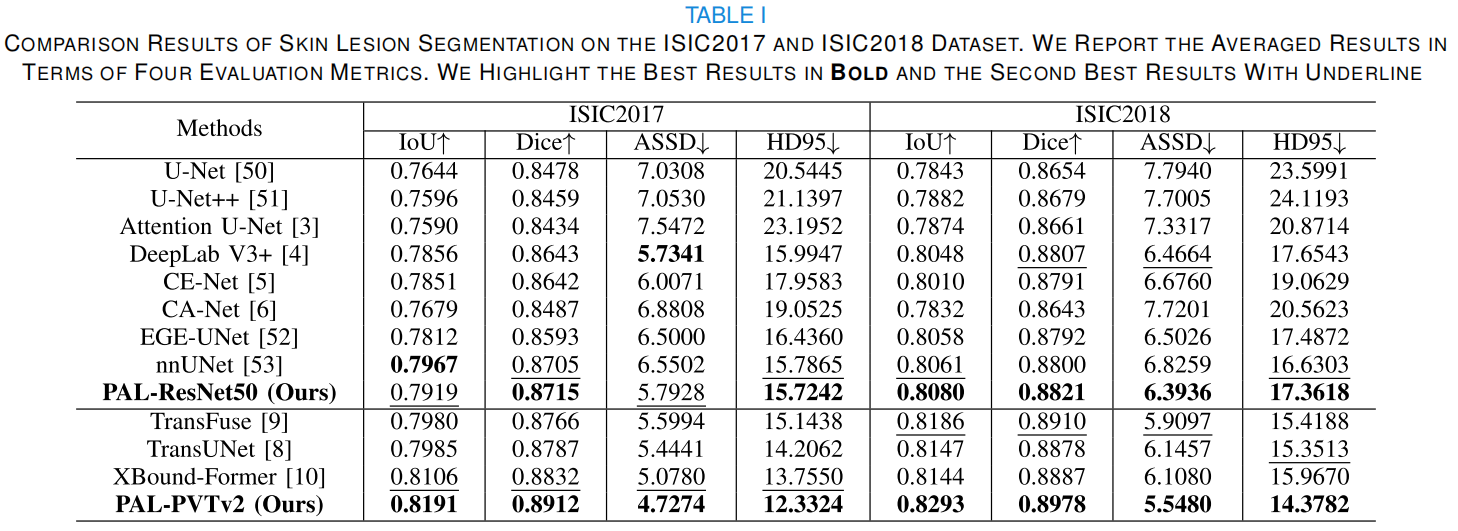
定性视觉的抗干扰能力: 纯数字的提升在临床上可能缺乏直观感。
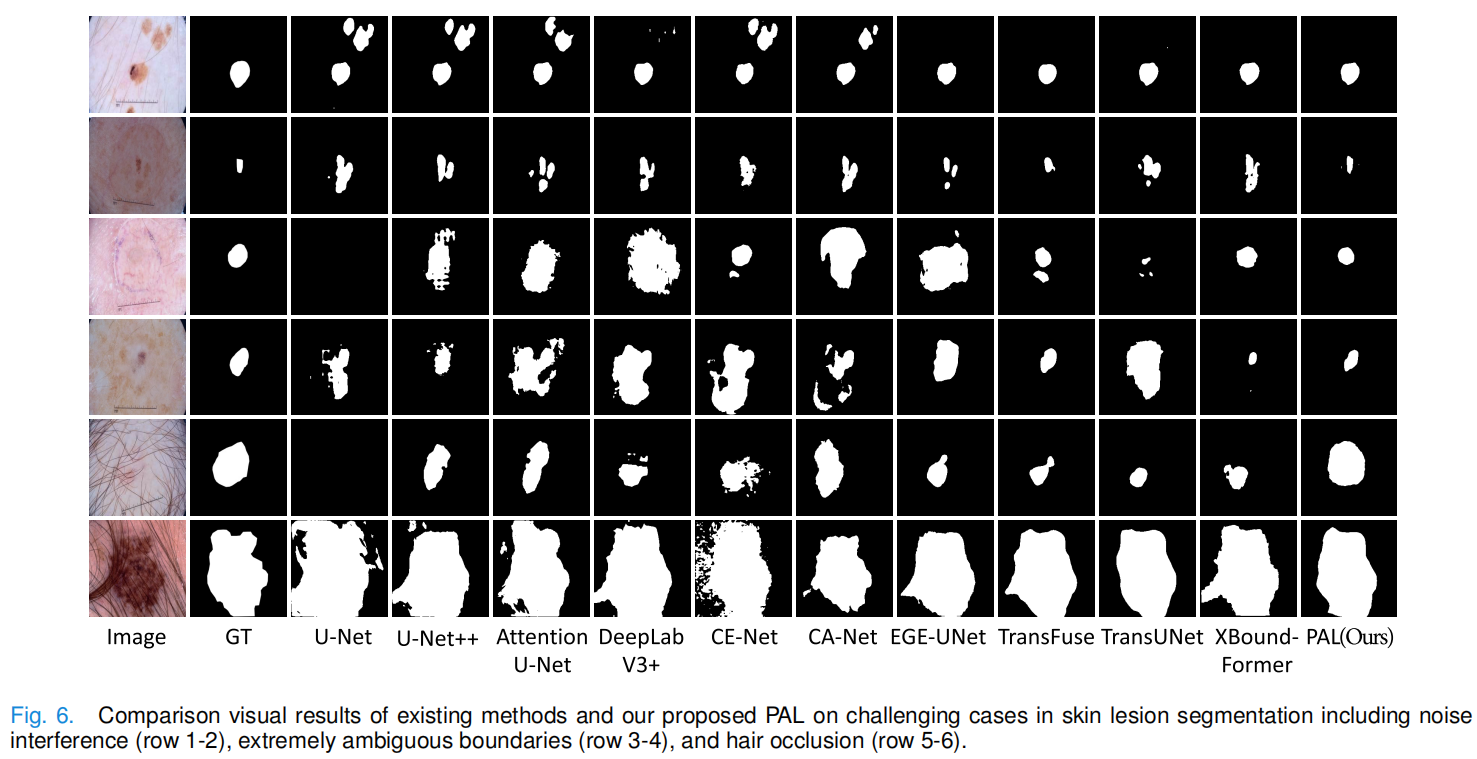
2. 泛化性大考:肠道息肉分割的跨界挑战
为了证明 PAL 不是一个只能在皮肤图像上"过拟合"的特定技巧,作者直接将其平行迁移到了肠道息肉分割任务(Polyp-seg,包含5个子数据集)中 。息肉同样具有边界模糊、颜色与肠壁高度相似的临床痛点 。
外部测试集的稳健表现: 评估医学模型泛化能力的核心在于"未见过的外部数据集"。在极具挑战性的 ETIS 外部测试集上,PAL 的 IoU 达到了 0.7722,FβwF_\beta^wFβw 达到了 0.8496,领先了专门针对息肉设计的先进模型 Polyp-PVT 高达 6.8% 。这有力地证明了:一旦模型掌握了"将病灶属性解耦为概率分布"的思考方式,这种逻辑是可以跨器官、跨模态迁移的。

3. 消融实验与可解释性自证
作者在 Table III 中进行了极度详实的消融实验(Ablation Studies),逐一移除了核心组件:
概率头(Probabilistic Head)真的有用吗? 将基础模型加上概率头后,IoU 从 0.8063 提升至 0.8175,再结合线性融合(最终的 PAL),进一步攀升至 0.8191 。这证实了引入高斯分布采样的核心价值。
软掩码(Soft Masked Attention)的巧思: 实验明确对比了三种注意力机制。如果完全去掉掩码,IoU 跌至 0.8104;如果使用传统的硬掩码(Vanilla Masked,即将背景权重设为极小值彻底屏蔽),IoU 仅为 0.8125 。这从数据上证实了前文的分析:保留背景的适度干扰(软掩码),反而增强了模型对复杂边界的鲁棒性 。
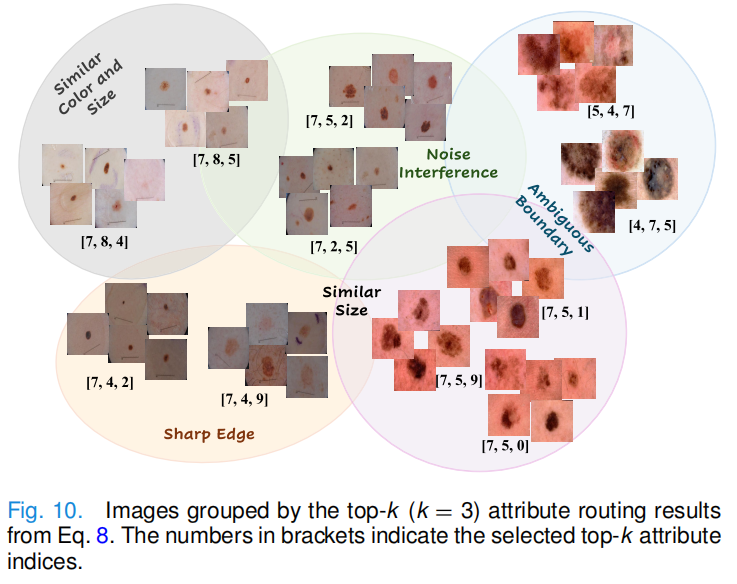
属性到底学到了什么?(可解释性验证)模型根据自动挑选的 Top-k 属性对图像进行分组。可以清晰地看到,被分配到同一组的病灶,在视觉上确实呈现出了"边界模糊"、"包含噪声"或"边缘锐利"等高度一致的临床模式。* 这是整篇论文在可解释性上最漂亮的一击。作者根据路由网络 R(x)R(x)R(x) 挑选出的 Top-k 属性对测试图像进行聚类。结果发现,被模型判定为"核心属性相同"的病灶,在人类视觉下确实表现出了极高的相似性(例如,某一组全是有严重噪声干扰的图像,另一组全是边缘极其锐利的图像) 。这证明网络确实在底层学到了具有实际物理意义的解耦属性,而不是在做毫无逻辑的"数字游戏"。
五、批判性分析
PAL 框架在 ISIC 皮肤数据集和外部的肠道息肉数据集上均取得了极具竞争力的表现,展现了其强大的跨域泛化能力,这里对论文内容进行一些批判性思考,只是一家之言。
1. 高斯分布的"单峰"局限性
PAL 通过 PMM 模块为每个属性估计了一个高斯分布 N(μ,σ2)\mathcal{N}(\mu, \sigma^2)N(μ,σ2)。但在真实的医学影像中,单个属性(例如颜色)在同一病灶内极有可能是"多峰的(Multimodal)"------比如左侧深黑,右侧鲜红。强行用单一的均值和方差去拟合多峰分布,可能会抹杀掉极端的关键特征。
如果使用高斯混合模型(GMM)或基于扩散模型(Diffusion)的采样机制来替代单一高斯分布,拟合更复杂的拓扑流形是否可行?但是这样无疑会大幅增加模型运算开销。
2. 对先验超参数的高度敏感
该框架严重依赖对"总属性数 AAA"和"选择数 kkk"的人为定义。论文中皮肤数据集 A=10A=10A=10,息肉数据集 A=8A=8A=8。这意味着,若要将此框架迁移至肝脏肿瘤或肺结节分割任务中,必须重新进行高昂的网格搜索来确定最佳的超参数组合。它尚未实现真正的"开箱即用"。
3. N=15N=15N=15轮采样"带来的隐性访存开销
虽然论文声明推理时间小于 0.1 秒/图,但在推理阶段,为了获取稳定的期望,模型必须执行完整的 N=15N=15N=15 轮"重参数化采样 →\rightarrow→ 非线性融合 →\rightarrow→ 全图余弦相似度计算"的链路。在处理超高分辨率(如4K病理切片)或高帧率视频流(如内窥镜手术视频)时,这种额外的张量运算依然会对边缘端设备的显存带宽造成不小的压迫。
客观而言,尽管引入多次蒙特卡洛采样和多重 Loss 约束略微增加了训练阶段的复杂度和超参数调试成本 ,但其在极具挑战性的医学场景下换取的高鲁棒性和可解释性,也算是一笔非常划算的"算法交易"。
小结
这篇论文是对现有"纯数据驱动"视觉分割范式的一次精彩反思。它通过优雅的概率统计模型(高斯分布建模 + 蒙特卡洛采样 + 混合专家路由),成功地将人类医生的"多属性解耦思维"注入了神经网络。尽管在复杂分布的拟合与工程调参上仍面临挑战,但其向"知识驱动与概率推理"迈出的这一步,无疑为下一代可解释性医学图像分析提供了一个极具潜力的研究范本。