作者:来自 Elastic Jeffrey Rengifo
学习如何将判断列表转换为 Learning To Rank( LTR )的训练数据,设计有效特征,并解读模型学到了什么。
Elasticsearch 提供了许多新功能,帮助你为你的使用场景构建最佳搜索解决方案。通过我们关于构建现代 Search AI 体验的实操 webinar,学习如何将这些功能付诸实践。你还可以立即开始免费的 cloud 试用,或在本地机器上试用 Elastic。
在 "使用判断列表评估搜索查询相关性" 一文中,我们构建了判断列表,并使用 _rank_eval API 来衡量搜索质量。尽管这种方法为我们提供了一种客观评估变更的方式,但提升相关性仍然需要手动进行查询调优。
如果判断列表回答的是 "How good is my ranking? ",那么 Learning To Rank( LTR )回答的是 "How do I systematically make it better?"
在本文中,我们迈出下一步:使用这些判断列表,通过 XGBoost、 Eland 和 Elasticsearch 训练一个 LTR 模型。我们将重点理解这一过程,而不是具体实现细节。完整代码请参考配套 notebook。
什么是 LTR?
LTR 使用机器学习( ML )为你的搜索引擎构建排序函数。与手动调优查询权重不同,你只需提供正确排序的示例(你的判断列表),让模型学习什么使文档相关。在 Elasticsearch 中,LTR 作为第二阶段重排器,在从 Elasticsearch 检索文档之后工作:
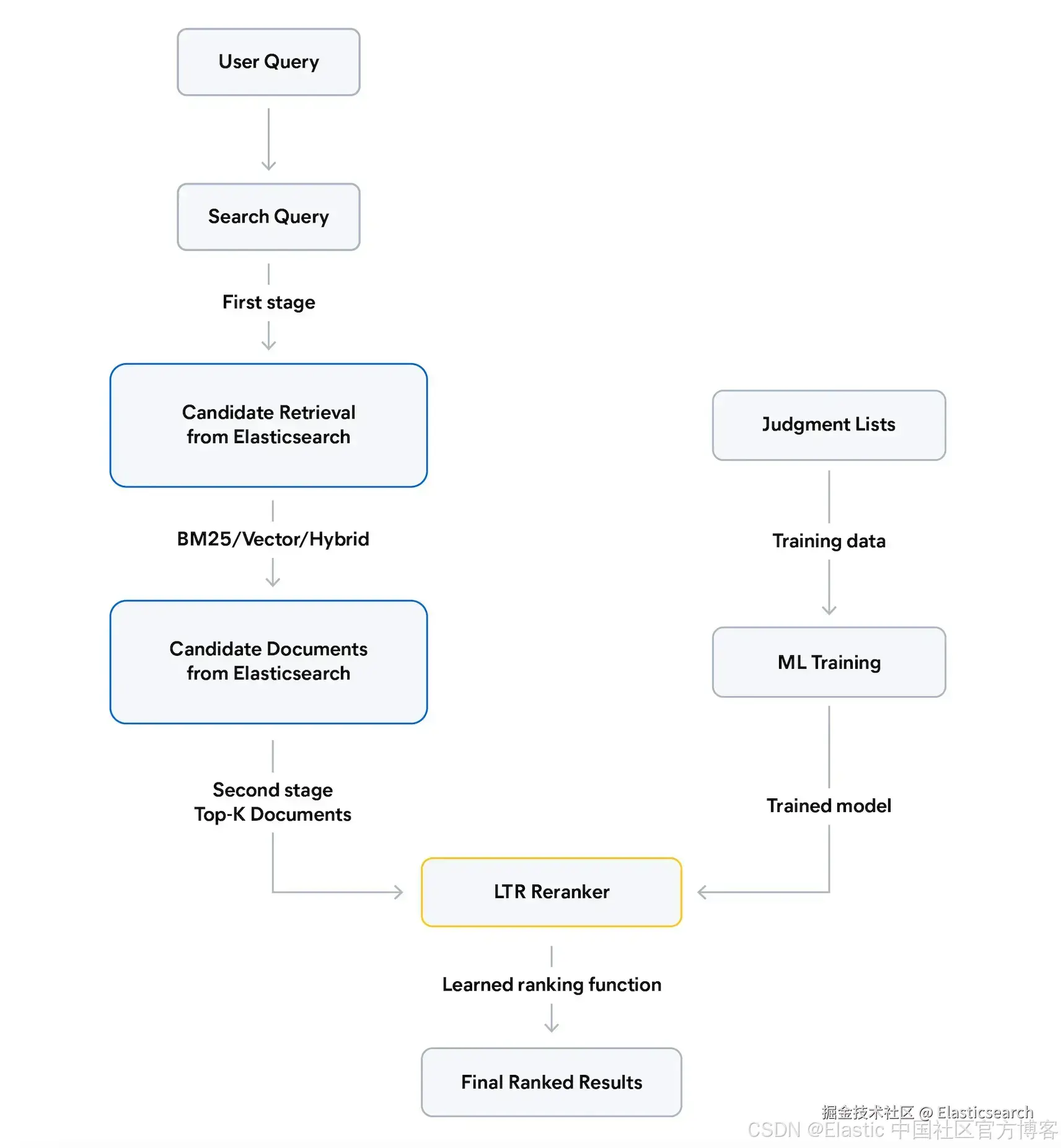
更深入的介绍,请参见在 Elasticsearch 中引入 Learning To Rank( LTR )。
从判断列表到模型的过程
判断列表告诉我们,对于给定查询,哪些文档应该排名更高。但模型无法直接从文档 ID 中学习。它需要数值信号来解释为什么某些文档具有潜在相关性。
该过程如下:
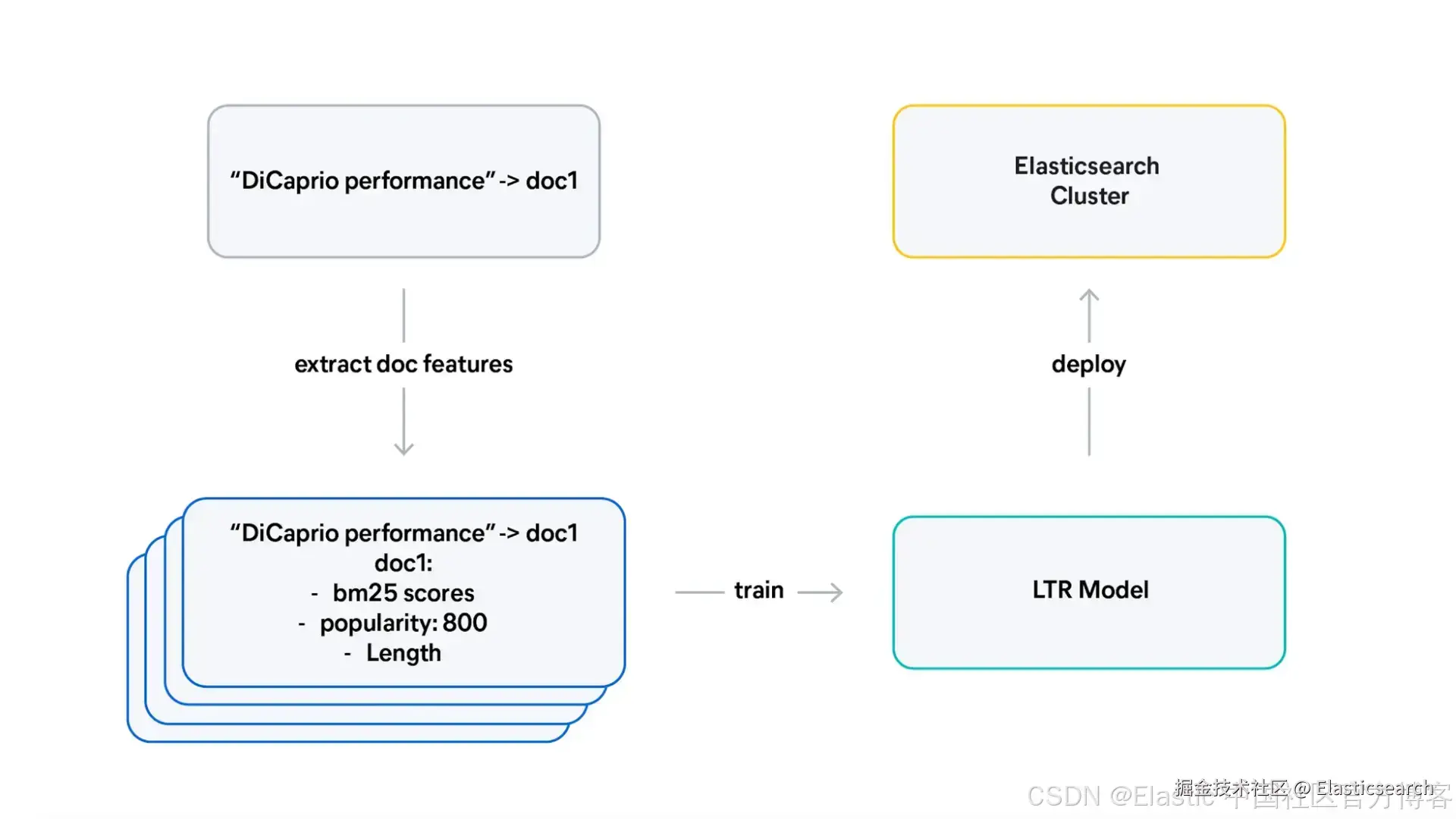
- 从判断开始。查询-文档对带有相关性评分,例如你定义 doc1 是 "DiCaprio performance" 搜索词的良好匹配。
- 提取特征 。对于每个查询-文档对,计算数值信号,其中一些仅与文档本身相关(例如流行度),另一些则与查询和文档的交互相关(例如 BM25 分数)。
- 训练模型。模型学习哪些特征模式可以预测高评分。
- 部署。将训练好的模型部署到你的 Elasticsearch 集群。
- 查询。使用该模型对搜索结果进行重新排序。
关键洞察是,特征必须能够捕捉你的判断所衡量的内容。如果你的判断列表偏好热门惊悚电影,但你的特征只包含文本匹配分数,那么模型就无法学习什么使这些文档相关。
什么是特征?
特征是描述查询-文档对的数值。在 Elasticsearch 中,我们使用返回分数的查询来定义特征。主要有三种类型:
- 查询-文档特征用于衡量查询与文档的匹配程度。Eland 提供了 QueryFeatureExtractor 工具来定义这些特征,它会为每个查询-文档对计算 BM25 相关性分数:
ini
`
1. QueryFeatureExtractor(
2. feature_,
3. query={"match": {"title": "{{query}}"}}
4. )
`AI写代码这会为每个文档提取相对于查询的 title 字段 BM25 分数。
- 文档特征 是与查询无关的文档属性。你可以使用 script_score 或 function_score 来提取这些特征:
erlang
`
1. QueryFeatureExtractor(
2. feature_,
3. query={
4. "script_score": {
5. "query": {"exists": {"field": "popularity"}},
6. "script": {"source": "return doc['popularity'].value;"}
7. }
8. }
9. )
`AI写代码- 查询特征描述查询本身,例如术语数量。这类特征较少见,但可以帮助模型处理不同类型的查询。
设计你的特征集
选择特征不是随机的。每个特征都应捕捉可能解释用户为何偏好某些文档的信号。让我们看看 LTR notebook 中的特征,并理解其设计逻辑:
| Feature | Type | Purpose |
|---|---|---|
title_bm25 |
Query-document | 标题匹配是强相关信号。例如,标题为 Star Wars 的电影在查询 "star wars" 时应排名靠前。 |
actors_bm25 |
Query-document | 一些用户按演员姓名搜索。如果搜索 "leonardo dicaprio movies",应返回主演 Leonardo DiCaprio 的影片。 |
title_all_terms_bm25 |
Query-document | 标题匹配的更严格版本,要求所有查询词都必须出现。它有助于区分完全匹配与部分匹配。 |
actors_all_terms_bm25 |
Query-document | 与上述严格匹配逻辑相同,但专门应用于演员。 |
popularity |
Document | 当相关性相近时,用户通常更偏好知名电影。热门 Star Wars 电影应排在低预算、标题包含 "Star Wars" 的模仿片之上。 |
注意这里的策略:
- 同一概念的多重信号。我们同时有 title_bm25(宽松)和 title_all_terms_bm25(严格)。宽松版本对至少有一个查询词匹配标题的文档打分,严格版本要求所有词都必须出现。对于短查询,宽松匹配可能就足够;而对于较长、具体的查询,严格匹配可能更重要。模型可以学习何时依赖哪种匹配。
- 文本特征加上质量特征。仅靠文本匹配可能返回包含正确词语但无关的文档。popularity 特征允许模型在文本分数相近时提升知名、高质量内容。
- 覆盖不同查询类型。有些查询针对标题(如 "star wars"),有些针对演员(如 "dicaprio movies")。为两者提供特征意味着模型可以处理多样化搜索。
在设计自己的特征时,问自己:"一个人会用哪些信号来判断文档是否相关?" 这些就是你的候选特征。
构建训练数据集
一旦定义了特征,我们就为判断列表中的每个查询-文档对提取它们。结果是一个训练数据集,每行包含:
- 查询标识符
- 文档标识符
- 相关性评分(来自判断列表)
- 所有特征值
下面是一个简化示例:
| `query_id` | `query` | `doc_id` | `grade` |
|---|---|---|---|
| qid:1 | star wars | 11 | 4 |
| qid:1 | star wars | 12180 | 3 |
| qid:1 | star wars | 278427 | 1 |
| qid:2 | tom hanks movies | 857 | 4 |
| qid:2 | tom hanks movies | 13 | 3 |
需要注意的几点:
- NaN 值是正常的。当查询未匹配某个字段时,该特征不会返回分数。电影 Star Wars 的 title_bm25 很高,但 actors_bm25 为空,因为查询 "star wars" 并未匹配任何演员姓名。
- 训练期间查询会被分组。query_id 列告诉模型哪些文档需要相互比较。对于 "star wars",它会学习文档 11(评分 4)应排在文档 278427(评分 1)之前。
但重点是:模型不会记住这些具体查询。相反,它学习一般模式,例如 "title_bm25 高且 popularity 高的文档往往评分高"。当遇到新查询时,模型会应用这些学习到的模式来排序结果。
- 特征必须能够解释评分差异。看看 qid:1:评分 4 的文档比评分 1 的文档具有更高的 title_bm25 和更高的 popularity。这些模式就是模型学习的内容。
训练 LTR 模型
在准备好训练数据集后,我们使用带有 ranking 目标的 XGBoost 模型进行训练。模型构建决策树以学习模式,例如:
-
"如果 title_bm25 > 10 且 popularity > 50,则预测高相关性。"
-
"如果 title_bm25 缺失但 actors_bm25 > 12,仍然预测中等相关性。"
实际训练过程如下:
ini
`
1. from xgboost import XGBRanker
2. from sklearn.model_selection import GroupShuffleSplit
4. # Create the ranker model:
5. ranker = XGBRanker(
6. objective="rank:ndcg",
7. eval_metric=["ndcg@10"],
8. early_stopping_rounds=20,
9. )
11. # Shaping training and eval data in the expected format.
12. X = judgments_with_features[ltr_config.feature_names]
13. y = judgments_with_features["grade"]
14. groups = judgments_with_features["query_id"]
16. # Split the dataset in two parts respectively used for training and evaluation of the model.
17. group_preserving_splitter = GroupShuffleSplit(n_splits=1, train_size=0.7).split(
18. X, y, groups
19. )
20. train_idx, eval_idx = next(group_preserving_splitter)
22. train_features, eval_features = X.loc[train_idx], X.loc[eval_idx]
23. train_target, eval_target = y.loc[train_idx], y.loc[eval_idx]
24. train_query_groups, eval_query_groups = groups.loc[train_idx], groups.loc[eval_idx]
26. # Training the model
27. ranker.fit(
28. X=train_features,
29. y=train_target,
30. group=train_query_groups.value_counts().sort_index().values,
31. eval_set=[(eval_features, eval_target)],
32. eval_group=[eval_query_groups.value_counts().sort_index().values],
33. verbose=True,
34. )
`AI写代码在训练过程中,模型尝试这些规则的不同组合,并衡量生成的排序与判断评分的匹配程度。它使用一个称为归一化折扣累积增益(Normalized Discounted Cumulative Gain, NDCG)的指标进行评分。NDCG 达到 1.0 表示模型的排序完全匹配你的判断。分数较低意味着一些相关文档排在了它们本应出现的位置之下。
训练过程中还使用了一种称为早停(early stopping)的技术。如果模型的分数在若干轮中不再提升,训练会自动停止。这可以防止模型过度记忆训练数据,从而影响其对新查询的泛化能力。
配套 notebook 包含完整的训练代码。
理解你的 LTR 模型学到了什么
训练完成后,XGBoost 可以显示模型最依赖的特征。你可以使用 XGBoost 内置可视化生成特征重要性图:
ini
`
1. from xgboost import plot_importance
3. plot_importance(ranker, importance_type="weight")
`AI写代码参数 importance_type="weight" 显示每个特征在决策树分裂中被使用的频率。下面是生成的图表:
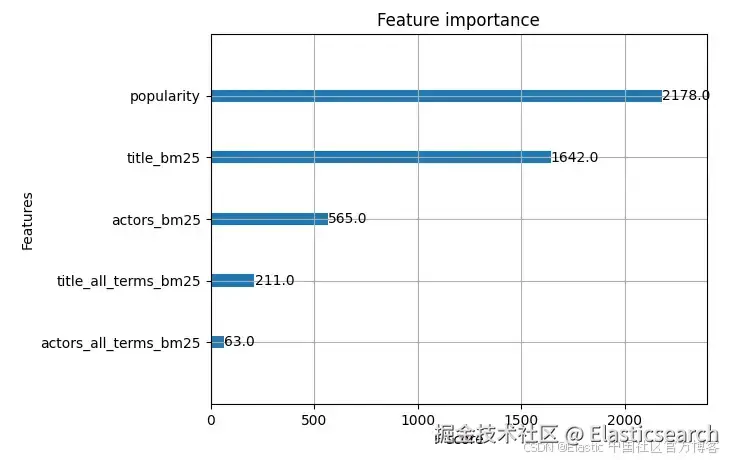
F 分数统计每个特征在模型所有决策树中用于分裂决策的次数。值越高,说明模型越依赖该特征。
在此示例中:
- popularity (2178):最重要的特征。模型经常使用 popularity 来区分相关与非相关文档。
- title_bm25 (1642):第二重要特征。标题匹配在电影搜索中非常关键。
- actors_bm25 (565):中等重要。对于包含演员的查询很有用。
- title_all_terms_bm25 (211):偶尔有用。严格匹配对某些查询有帮助。
- actors_all_terms_bm25 (63):很少使用。模型发现此特征预测能力较低。
该图表有助于你迭代特征集。如果某个预期重要的特征显示几乎为零的重要性,需要调查原因。可能是特征提取未按预期工作,或者该信号在你的判断数据中实际上不能预测相关性。
部署和使用 LTR 模型
训练完成后,使用 Eland 将模型上传到 Elasticsearch:
ini
`
1. MLModel.import_ltr_model(
2. es_client=es_client,
3. model=ranker,
4. model_id="ltr-model-xgboost",
5. ltr_model_config=ltr_config,
6. es_if_exists="replace",
7. )
`AI写代码上传后,该模型可以作为重评分重检器(rescorer retriever)使用,并可与其他重检索器(retrievers)器结合,用于多阶段搜索管道:
bash
`
1. GET movies/_search
2. {
3. "retriever": {
4. "rescorer": {
5. "rescore": {
6. "window_size": 50,
7. "learning_to_rank": {
8. "model_id": "ltr-model-xgboost",
9. "params": {
10. "query": "star wars"
11. }
12. }
13. },
14. "retriever": {
15. "standard": {
16. "query": {
17. "multi_match": {
18. "fields": ["title", "overview", "actors", "director", "tags", "characters"],
19. "query": "star wars"
20. }
21. }
22. }
23. }
24. }
25. }
26. }
`AI写代码响应(简化版):
bash
`1. "hits": {
2. "total": {
3. "value": 852,
4. "relation": "eq"
5. },
6. "max_score": 25.165691,
7. "hits": [
8. {
9. "_index": "movies",
10. "_id": "11",
11. "_score": 25.165691,
12. "_source": {
13. "title": "Star Wars"
14. }
15. },
16. {
17. "_index": "movies",
18. "_id": "12180",
19. "_score": 25.092865,
20. "_source": {
21. "title": "Star Wars: The Clone Wars"
22. }
23. },
24. {
25. "_index": "movies",
26. "_id": "181812",
27. "_score": 23.456198,
28. "_source": {
29. "title": "Star Wars: The Rise of Skywalker"
30. }
31. },
32. {
33. "_index": "movies",
34. "_id": "140607",
35. "_score": 23.320757,
36. "_source": {
37. "title": "Star Wars: The Force Awakens"
38. }
39. },
40. ...`AI写代码第一阶段查询使用 BM25 检索候选文档。然后 LTR 模型使用它学到的所有特征对前 50 个结果进行重新排序。
在此示例中,仅使用 multi_match 查询可能会在前几个位置返回一些相关性较低的结果,而 LTR 帮助修正了这些问题:
bash
`
1. {
2. "hits": [
3. {
4. "_index": "movies",
5. "_id": "11",
6. "_score": 10.971989,
7. "_source": {
8. "title": "Star Wars"
9. }
10. },
11. {
12. "_index": "movies",
13. "_id": "12180",
14. "_score": 9.923633,
15. "_source": {
16. "title": "Star Wars: The Clone Wars"
17. }
18. },
19. {
20. "_index": "movies",
21. "_id": "1022100",
22. "_score": 8.9880295,
23. "_source": {
24. "title": "Andor: A Disney+ Day Special Look"
25. }
26. },
27. {
28. "_index": "movies",
29. "_id": "278427",
30. "_score": 8.845748,
31. "_source": {
32. "title": "Family Guy Presents: It's a Trap!"
33. }
34. },
35. ...
36. ]
37. }
`AI写代码结论
从判断列表到可用的 LTR 模型的路径包括三个关键步骤:设计捕捉相关性信号的特征、构建将这些特征与判断评分配对的训练数据集,以及训练能够学习模式的模型。
我们之前的文章成为这个过程的起点。你的评分定义了 "相关" 的含义以及如何衡量,而你的特征为模型提供了预测所需的信号。
有关完整实现及包含 9,750 部电影和 384,755 条判断记录的数据集,请参见 LTR notebook。对于高级用例,如个性化搜索,请参见使用 LTR 的个性化搜索。