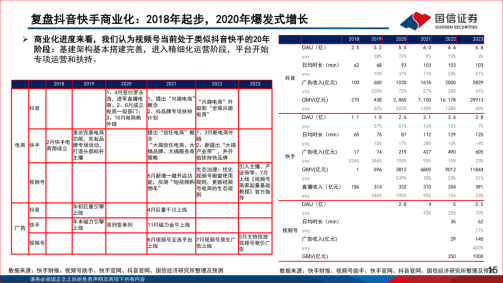
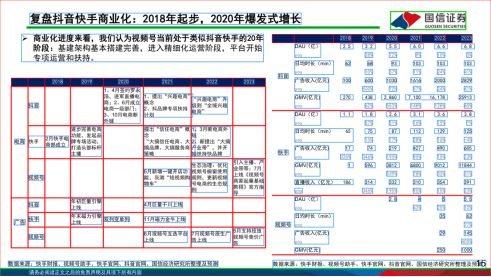
文章目录
- 预处理目的
- 适用范围
- 核心流程
-
- [一. 文档解析与提取 (Parsing & Extraction)](#一. 文档解析与提取 (Parsing & Extraction))
- [二. 数据清洗与降噪 (Data Cleaning)](#二. 数据清洗与降噪 (Data Cleaning))
-
- [1. 阶段输入](#1. 阶段输入)
- [2. 核心处理流程](#2. 核心处理流程)
- [3. 阶段输出](#3. 阶段输出)
- [三. 分块与切片 (Chunking / Text Splitting)](#三. 分块与切片 (Chunking / Text Splitting))
-
- [1. 阶段输入](#1. 阶段输入)
-
- [2. 主流文本切分策略盘点](#2. 主流文本切分策略盘点)
- [3. 阶段输出](#3. 阶段输出)
- [四. 元数据附加与多维标注 (Metadata Enrichment)](#四. 元数据附加与多维标注 (Metadata Enrichment))
-
- [1. 阶段输入](#1. 阶段输入)
- [2. 核心处理流程](#2. 核心处理流程)
- [3. 阶段输出](#3. 阶段输出)
- [五. 语义向量化 (Embedding)](#五. 语义向量化 (Embedding))
-
- [1. 阶段输入](#1. 阶段输入)
- [2. 核心处理流程](#2. 核心处理流程)
- [3. 阶段输出](#3. 阶段输出)
- [六. 入库建立索引 (Ingestion)](#六. 入库建立索引 (Ingestion))
-
- [1. 阶段输入](#1. 阶段输入)
- [2. 核心处理流程](#2. 核心处理流程)
- [3. 阶段输出](#3. 阶段输出)
- 结语
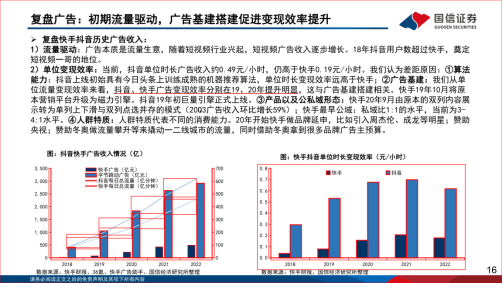
预处理目的
规范化非结构化文档(特别是 PDF 格式,如研报、财务报表、学术论文等)的预处理流水线,确保提取出的文本数据具备高信噪比和结构完整性,从而提升后续 RAG(检索增强生成)系统的检索精度与生成质量。
适用范围
适用于构建垂直领域知识库时,对本地或网络抓取的 PDF 文档进行解析、清洗、切片、向量化及入库的全生命周期管理。
核心流程
一. 文档解析与提取 (Parsing & Extraction)
- 输入:原始 PDF 文件
- 动作 :将人类视觉排版格式转换为机器可读格式,剥离核心文本、表格与图像信息。
- 纯文本类 :调用轻量级解析器(如
PyMuPDF、pdfminer.six)进行快速提取。 - 复杂表格类 :针对包含大量财务数据或参数的表格,使用
pdfplumber或基于视觉的深度学习模型(如LayoutLM)还原表格的行列结构。 - 扫描/图像类 :接入 OCR 引擎(如
PaddleOCR)进行光学字符识别。
- 纯文本类 :调用轻量级解析器(如
- 输出:粗粒度的纯文本字符串或半结构化数据(如 Markdown 格式的表格)。
纯文本类
方法1:PyMuPDF (fitz)
PyMuPDF 是一个基于 C/C++ 编写的底层开源 PDF 渲染库(MuPDF)的 Python 接口包。因为底层是 C++,它是目前 Python 生态中解析和渲染 PDF 速度最快的库之一。
- 作用 :
- 特征识别:可以识别字体名称、字号大小,甚至颜色。可以通过字体大小来区分标题正文和垃圾信息,直接筛除垃圾信息(统计全文字号分布,字符数最多的字号就是正文字号)。
- 物理坐标系提取 :
PyMuPDF会精准返回每一个文本块(Block)、每一行(Line)、甚至每一个词(Span)的边界框。 - 图像提取:它可以把文档作者当初插入 PDF 里的原图(如 JPG、PNG)无损地"抠"出来,并保存到本地。
- 文档目录大纲提取 :使用
doc.get_toc()方法,可以一键获取全局骨架。 - 矢量线条与表格边框感知:它能读取到 PDF 页面上的所有矢量线条(直线、矩形框)。
- 效果:
方法2:pdfminer.six
解析速度虽然不如 PyMuPDF,但它对 PDF 内部树状结构(页面 -> 文本框 -> 文本行 -> 单个字符)的剖析极其精细。
- 特点 :
PyMuPDF的坐标系原点 (0,0) 在页面的左上角(往下 Y 递增)。而pdfminer.six的坐标系原点 (0,0) 在页面的左下角(往上 Y 递增)。- 段落聚合能力强,能把属于同一段落的多行文字框在一个蓝框里。
PyMuPDF只能理解"一行",而pdfminer可以理解多行。 pdfminer.six无法输出可视化的图片结果,没有像素、颜色的概念,它只能读取底层的二进制代码,计算每一个字符的 X、Y 坐标,然后根据这些坐标"猜"出哪些字连成了一行,哪些行拼成了一个段落。而PyMuPDF底层包含了强大的图形渲染引擎,不仅能读字,还能真正把 PDF 转换为像素点并画框标线。
- 效果 :
方法3:pypdf
它的设计初衷并不是为了理解文档的内容,而是为了操作文档的物理属性。
- 特点 :
- 页面级物理操作:拆分与合并(把一份 1000 页的文件切成 10 份,或者拼接多个独立文件);旋转与裁剪(处理扫描反了的页面或裁剪白边)。
- 全局元数据提取 :能够瞬间抓取 PDF 的
/Author(作者)、/CreationDate(创建时间)、/Title(标题)、/Producer(生成软件)等底层属性。 - 安全与权限控制:给 PDF 文件加密解密,或者读取文档权限。
- 轻量级纯文本提取:对于没有任何排版、单栏到底的纯文本 PDF,仅用纯 Python 环境就能快速提取。
- 现在的RAG文件预处理仍会用到,通常处理大文件物理切片,把一份 500 页的重型宏观经济研报喂给 PyMuPDF 转图片,或者喂给 MinerU 这种视觉大模型,极容易导致内存溢出。还可以用于RAG知识入库时的元数据标签注入,调用 reader.metadata 抓取这份 PDF 原本的生成时间和作者,在存入 Chroma 时,把这些信息作为过滤标签打在每一个 Chunk 上。
- 适用场景:通常处理大文件物理切片,防止内存溢出;用于 RAG 知识入库时的元数据标签注入。不适合做版面分析、表格提取、复杂公式和图像识别。
- 效果 :

方法4:Unstructured
2022 年下半年诞生,它不是一个底层的解析库,而是一个极其庞大且臃肿的"缝合怪",它内部把市面上所有的库全包了一遍。
- 特点 :
- 安装困难:底层工具依赖多,易导致编译环境问题。
- 生态占有率高 :在企业级 RAG 市场占有率极高,
LangChain和LlamaIndex默认的文档加载器底层调用的就是Unstructured。 - 智能路由 :像一个智能路由器,提供了统一的 API 接口和调度逻辑(如纯文本用
pdfminer,扫描版用tesseract,复杂表格用yolox模型)。
表格类
方法1:pdfplumber
由数据新闻调查机构开源的 Python 库,初衷是从恶劣的公开文件中解救数据。
- 特点 :
- 精确字典属性:精确获取每一个字符的字典属性(字体、字号、颜色)。
- 页面裁剪过滤 :利用坐标直接"裁剪"页面
page.crop((x0, y0, x1, y1)),彻底过滤边缘噪音(如页眉页脚)。 - 精细版面分析 :继承了
pdfminer.six的能力,将 PDF 解析为包含详尽坐标的 DOM 树。 - 逆向反推还原:剥离页面上的物理线条,逆向反推还原图表原始数值。
- 视觉调试引擎:深度集成 ImageMagick 和 Pillow 库,实现"所见即所得"的文档逆向工程。
- 表格重构能力:算法提取线条交点重构网格;面对"三线表"计算空白间隙强行切分列,一行代码转换成 DataFrame。
- 缺点 :底层消耗大量 CPU 算力,速度慢。
- 效果 :

蓝框:框住的是 pdfplumber(底层依赖 pdfminer.six)识别出的一个"词 (Word)"或"单字"。它通过解析 PDF 底层的汇编指令(比如 TJ 或 Tj 操作符),计算出每一个字符的精确 X、Y 坐标、宽度和高度,然后把距离足够近的字符聚合成一个蓝框。可以让你直观看到解析器是否漏读了字,或者双栏排版的坐标是否发生错乱
红框:PDF并没有表格这个属性,pdfplumber 算法在遍历了页面上所有的蓝框(文字)和物理线条(直线、矩形)后,计算交点,"猜"出来的表格最大物理边界。让你在提取数据前,肉眼验证算法有没有把表格框歪,或者有没有把两张独立的表格错误地连在了一起。
方法2:Camelot
- 设计初衷:极其精准地还原表格成 Pandas DataFrame,依靠 C 语言和 OpenCV。
- 特点 :
- 双解析算法 :
Lattice(网格模式)寻找闭合横竖线交点;Stream(流模式)基于字符对齐和空白间距计算列边界。 - 缺点:依赖环境难装,使用频率下降。
- 双解析算法 :
- 效果 :
- Camelot 自带的画图工具会把所有字符用粉色/蓝色小框标出,并把表格的网格线用红色轮廓高亮。
- TXT文件中Camelot 可以给出解析准确度得分(Accuracy)和空白占比(Whitespace)。而且,直接调用了 .df.to_markdown(),那些原本黏在一起的数字,现在变成了完美对齐的 DataFrame 格式。(安装太麻烦)
方法3:Tabula-py
-
设计初衷 :Tabula-py 本质上是一个 Python 包装器(Wrapper)。它在底层调用的是用 Java 编写的
tabula-java库。最初,它是为了帮助那些不懂编程的调查记者从政府公开的 PDF 报告里把死板的数据放进 Excel 而诞生的。。 -
特点:
- 环境依赖重:需要跨语言环境依赖,必须安装 Java。
- 适用场景:不适合高并发轻量级系统,适合离线数据清洗批处理,提取规整表格极稳定。
-
效果:
- 没有冗余的物理坐标、没有复杂的框线解释,直接干脆地给你展示一个完美的 Markdown 表格。(由于不常用,且有平替的其他方法,因此这里没有安装java环境)
图像类
方法1:MinerU (magic-pdf)
上海人工智能实验室开源的顶级文档解析项目。使用频率高
- 特点 :
- 视觉重构 :将 PDF 转为高清图片,利用 LayoutLMv3 / YOLO 看穿排版,裁剪图片并输出极度干净的 Markdown(包括公式
$$E=mc^2$$)。 - 算力要求高:是一个完整的 AI 模型推断流水线,建议配备 Nvidia 独立显卡(GPU)。
- 视觉重构 :将 PDF 转为高清图片,利用 LayoutLMv3 / YOLO 看穿排版,裁剪图片并输出极度干净的 Markdown(包括公式
- 效果 :

方法2:PaddleOCR
由百度开源的 OCR 中英文混合提取之王。
-
特点:
- 极致轻量:PP-OCRv4 模型总大小不到 20MB,支持 CPU 极速推断。
- 极高鲁棒性:对中文简繁体、生僻字、印章遮挡有极高鲁棒性,甚至能还原 HTML 代码或 Excel。
- 协同使用 :常与
MinerU协同,负责识别MinerU裁剪下的特定图像区域的文字。
-
效果:


方法3:Nougat / Marker
- Nougat:Meta 开源,目前把数学公式转成 LaTeX 代码最准的开源模型。
- Marker:内置极度强悍的启发式过滤算法,彻底剔除边缘水印、页眉页脚。不仅支持 PDF,还完美解析 EPUB、MOBI、HTML。它尝试直接提取纯文本,遇到复杂排版才唤醒视觉模型,生成的 Markdown 段落极其完美连贯。
- 效果 :
与之前的方法不同,Marker处理后的效果是上一页的半句话,和下一页的半句话完美拼在了一行,没有任何多余的页码和免责声明插在中间
二. 数据清洗与降噪 (Data Cleaning)
数据清洗与降噪是构建高质量 RAG 数据底座的关键前置环节,核心目标是提升文本的信噪比。
1. 阶段输入
- 由解析模块输出的非结构化或半结构化原始文本流。
2. 核心处理流程
- a.规则化去噪
- 处理对象:对语义理解无实质贡献的结构化干扰信息。
- 执行逻辑:构建基于正则表达式与关键词匹配的启发式规则库。
- 具体动作:批量删除跨页重复出现的页眉、页脚、独立页码;剔除"免责声明"、"评级说明";清洗无效 URL 或死链。
- b.物理断裂修复
- 处理对象:绝对坐标排版导致的非自然强制换行("硬回车")。
- 执行逻辑:基于标点符号边界规则与上下文探测进行判定。
- 具体动作 :若换行符
\n前未出现标准的结句标点,则判定为物理断层并抹除换行符,将跨行短句重新拼接为逻辑完整的连续段落。
- c.字符级标准化
- 处理对象:可能导致分词器异常或干扰检索的底层字符。
- 执行逻辑:底层的字符编码统一与清洗。
- 具体动作 :Unicode 规范化剔除零宽空格(
\u200b);统一全半角标点;修复特征数值间的异常空格。
3. 阶段输出
- 去除了排版噪音、格式规范且语义段落连续的高质量长文本字符串,可直接下发至后续的文本切片模块。
三. 分块与切片 (Chunking / Text Splitting)
分块与切片是决定召回精度的关键步骤,防止语义碎片化,帮助 Embedding 模型捕捉完整上下文。
1. 阶段输入
- 经过预处理、降噪且具备高度语义连贯性的标准化长文本字符串。
2. 主流文本切分策略盘点
- a.基于启发式规则的递归切分 (70% - 80%)
- 核心逻辑 :分级降级的贪心算法(如
\n\n>\n>。>空格)。优先级边界尝试切断,超限则向下级下探。 - 优势:计算开销极低,速度快;配合 Overlap 缓解边界截断。
- 局限性:物理层面的"盲切",可能切断长逻辑链。
- 核心逻辑 :分级降级的贪心算法(如
- b.基于文档结构的切分 (15% - 20%)
- 核心逻辑:依赖结构化标签(如 Markdown Header)进行边界划分。
- 优势:高度贴合论述逻辑,深度绑定层级元数据,支持高精度过滤溯源。
- 局限性:极其依赖前置解析模块的输出质量。
- c.基于向量与大模型的语义切分 (5% - 10%)
- 核心逻辑:摒弃物理标点,利用神经网络(语义切分 Semantic Chunking)或 LLM(智能体切分 Agentic Chunking)探测语义话题转移进行切分。
- 优势:最优的语义连贯性。
- 局限性:计算复杂度呈指数级上升,成本高昂。
3. 阶段输出
- Content:语义对齐的文本片段。
- Metadata:自动挂载元数据(原文标题、页码、段落索引等)为多维检索提供索引支撑。
四. 元数据附加与多维标注 (Metadata Enrichment)
在向量数据库中注入结构化字段,利用布尔过滤大幅缩小搜索范围,解决概念指代模糊问题。
1. 阶段输入
- 经由切片模块生成的标准化文本块列表(Text Chunks)。
2. 核心处理流程
- a.基础物理属性标注 (100%):记录源文件 ID、物理定位(页码、切片序号)、时间戳,确保结果可追溯。
- b.文档逻辑结构注入 (40% - 50%):静态注入 Markdown 标题层级链(Heading Path)和邻域切片索引,支持业务边界感知和窗口扩展。
- c.语义标签与实体提取 (10% - 15%):利用 NLP 提取关键词,生成摘要,或利用 LLM 预生成潜在 QA 匹配用户模糊提问。
3. 阶段输出
- 结构化文本对象 (Enriched Objects):以 JSON 或字典封装的文本及关联元数据,直接用于向量数据库入库。
五. 语义向量化 (Embedding)
将文本映射到一个能够表达深层语义关系的高维连续数学空间中,为余弦相似度、内积检索提供计算基础。
1. 阶段输入
- 携带结构化元数据的标准化文本块对象集合。
2. 核心处理流程
- a.高维空间映射 :调用稠密检索模型(如
bge-m3、text-embedding-3-small),将自然语言映射为高维浮点数数组。 - b.深层语义特征捕获:确保向量具备"语义对齐"特性,语义相近文本块空间坐标相近。
- c.归一化与降维处理 (可选):执行 L2 归一化以加速点积运算;应用截断或 Matryoshka 表示法降低维度压缩存储。
3. 阶段输出
- 向量化数据记录 (Vectorized Records):包含 Dense Vector(计算依据)、Payload/Document(原始内容)、Metadata(结构化标签)的三位一体封装结构。
六. 入库建立索引 (Ingestion)
物理持久化存储并构建高效的向量空间拓扑结构(ANN 索引),保障海量知识库的毫秒级召回。
1. 阶段输入
- Dense Vectors、Payloads 和 Metadata 构成的完整记录集。
2. 核心处理流程
- a.数据对齐与原子化写入:在向量数据库(如 Chroma, Milvus)中强绑定记录并执行持久化写入,保障灾备恢复。
- b.近似最近邻(ANN)索引构建 :
- HNSW :构建分层的导航小世界图索引,将检索复杂度降至
O(logN)。 - IVF:聚类算法划分空间胞元,平衡内存占用与速度。
- HNSW :构建分层的导航小世界图索引,将检索复杂度降至
- c.检索接口预热与性能优化:对元数据建立标量索引支持布尔过滤;通过内存预热最小化冷启动延迟。
3. 阶段输出
- 高性能结构化知识库 (Production-Ready Vector Store):具备毫秒级响应能力、支持混合检索,可供 AI Agent 实时调用的知识矩阵。
结语
构建真正具备工业级生产力的 RAG 系统,从来都不是大模型算力的单向碾压,而是底层数据质量的精细博弈。本文梳理的六步标准流水线(SOP),正是为了在混沌的非结构化文档与 AI Agent 之间,搭建一座高信噪比的桥梁。
从暴力的物理坐标解析,到克制的启发式降噪;从兼顾语义的滑动切片,到高维空间的数学映射。当纯净、连贯且带有丰富元数据的知识矩阵成功落盘至向量数据库的那一刻,数据预处理的使命便圆满完成。
万丈高楼平地起,愿这份 SOP 能为您的 AI 知识库构建之路提供一些帮助。