Claude Code的「渐进式披露」------让AI Agent从"信息过载"到"精准高效"
一、开篇:为什么你的AI Agent总像"人工智障"?
你是不是也遇到过这些问题:
- 给Agent塞了全量代码/文档,它反而答非所问、出现幻觉;
- 工具堆了一堆,Agent不知道该用哪个,执行效率极低;
- 早期好用的工具,模型升级后反而成了"枷锁",限制灵活性。
这不是模型能力不行,而是信息供给方式错了------我们总想着"给得越多越好",却忽略了AI Agent的注意力和推理链路,就像给刚入职的新人甩100G文档,不如给它一个搜索工具+核心入口,让它自己探索。
而Anthropic的Claude Code,用「渐进式披露(Progressive Disclosure) 」设计哲学,完美解决了这个问题:不一次性塞所有信息,让Agent按需获取、分层展开,克制才是释放AI潜力的关键。
二、核心概念:什么是「渐进式披露」?
通俗理解
就像你逛图书馆:
- 先看目录(元数据),知道有哪些书、大概讲什么;
- 找到感兴趣的书,再看目录页(核心指令),了解整体结构;
- 遇到具体问题,才翻到对应章节(详细资源),精准获取信息。
AI Agent也是如此:先给"索引",再给"手册",最后给"细节",全程由Agent自主判断、按需加载,而非被动接收全量信息。
官方定义(Claude Code)
渐进式披露是一种分层信息供给机制 ,核心是:最小化初始上下文,最大化Agent自主探索能力,通过"元数据→核心指令→详细资源"的三层加载,实现Token消耗降低60%-80%、指令遵循率大幅提升。
三层加载机制(核心)
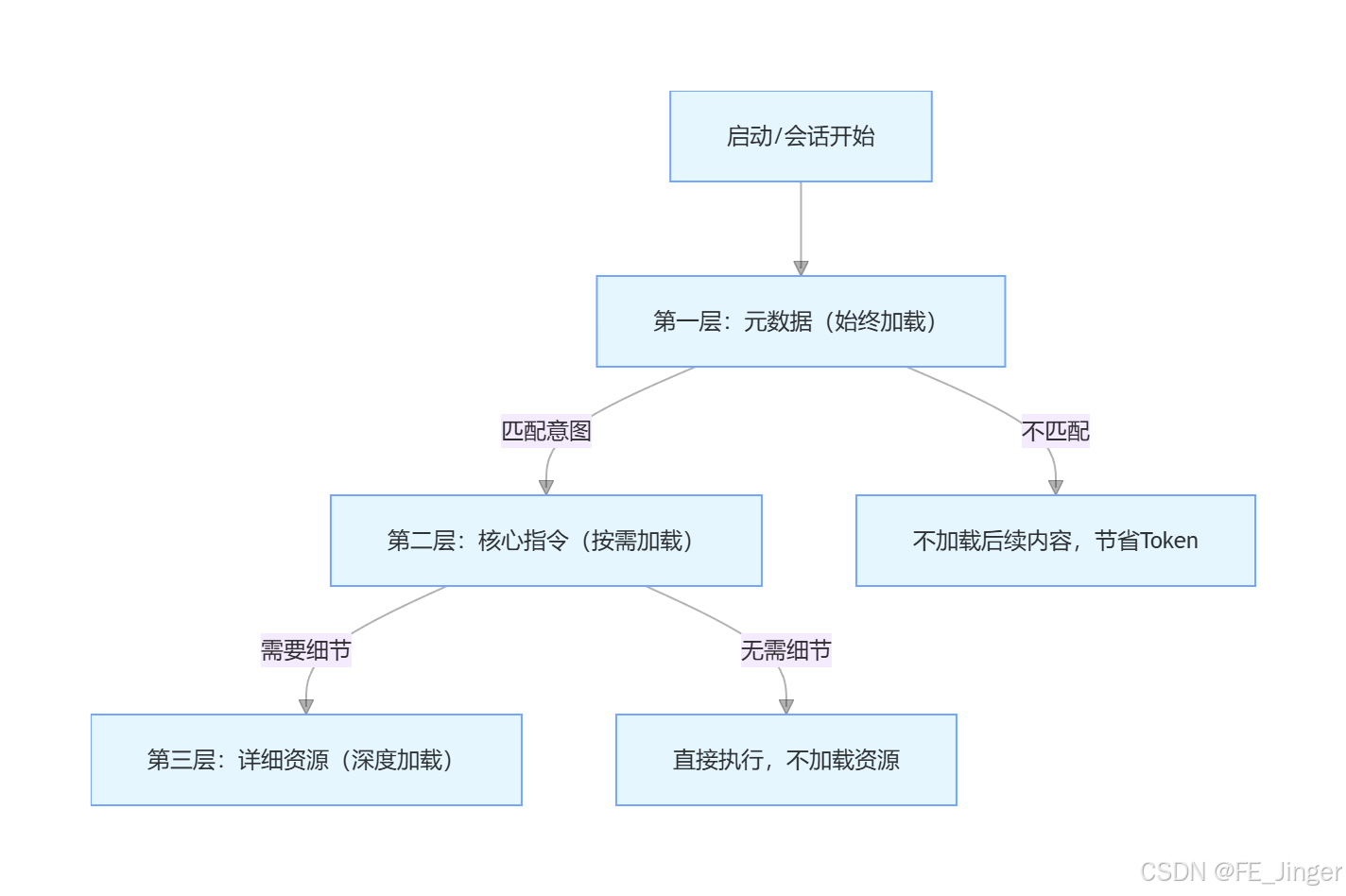
- 第一层(元数据):仅加载技能名称、描述(每个约50-100 Token),让Agent知道"有什么能力、什么时候用"。
- 第二层(核心指令):意图匹配后,加载SKILL.md(约1K-5K Token),包含任务逻辑、执行步骤。
- 第三层(详细资源):执行中需要细节时,才读取关联文档、脚本,用完即弃,不污染主上下文。
三、三大验证:Claude Code如何落地「渐进式披露」?
1. 上下文获取:从"被动喂饭"到"自主觅食"
早期痛点(传统RAG)
- 把代码切块、建向量索引,检索后硬塞进上下文;
- Agent被动接收,无法自主判断信息相关性,容易"捡了芝麻丢西瓜";
- 上下文膨胀、Token浪费,推理效率极低。
改进方案(渐进式披露)
- 给AgentGrep搜索工具 +文件入口权限,让它自主搜索代码库;
- 用Skills机制递归读取关联文件,实现多层嵌套搜索(比如读A文件,发现引用B,再读B,以此类推);
- 模型自主构建推理链路,精准定位所需信息,而非被动接收片段。

核心启发
别替Agent决定该看什么,给它工具、入口和权限,它的自主推理比你预设的更完整。
2. 能力扩展:从"全量堆砌"到"按需激活"
早期痛点(全量塞工具/文档)
- 把所有工具、文档塞进系统提示词,导致上下文污染;
- Agent面对海量信息,无法快速定位所需能力,执行混乱;
- 不常用的功能也占用上下文,浪费资源。
改进方案(子代理+文件引用)
- 用子代理(SubAgent):仅在需要时启动,专门处理特定问题(如配置MCP Server),找到答案就返回,不加载冗余文档;
- 详细规范独立成文件,系统提示词只留路径,Agent按需读取;
- 技能采用"延迟加载":只放轻量级钩子,用时再加载完整工具。
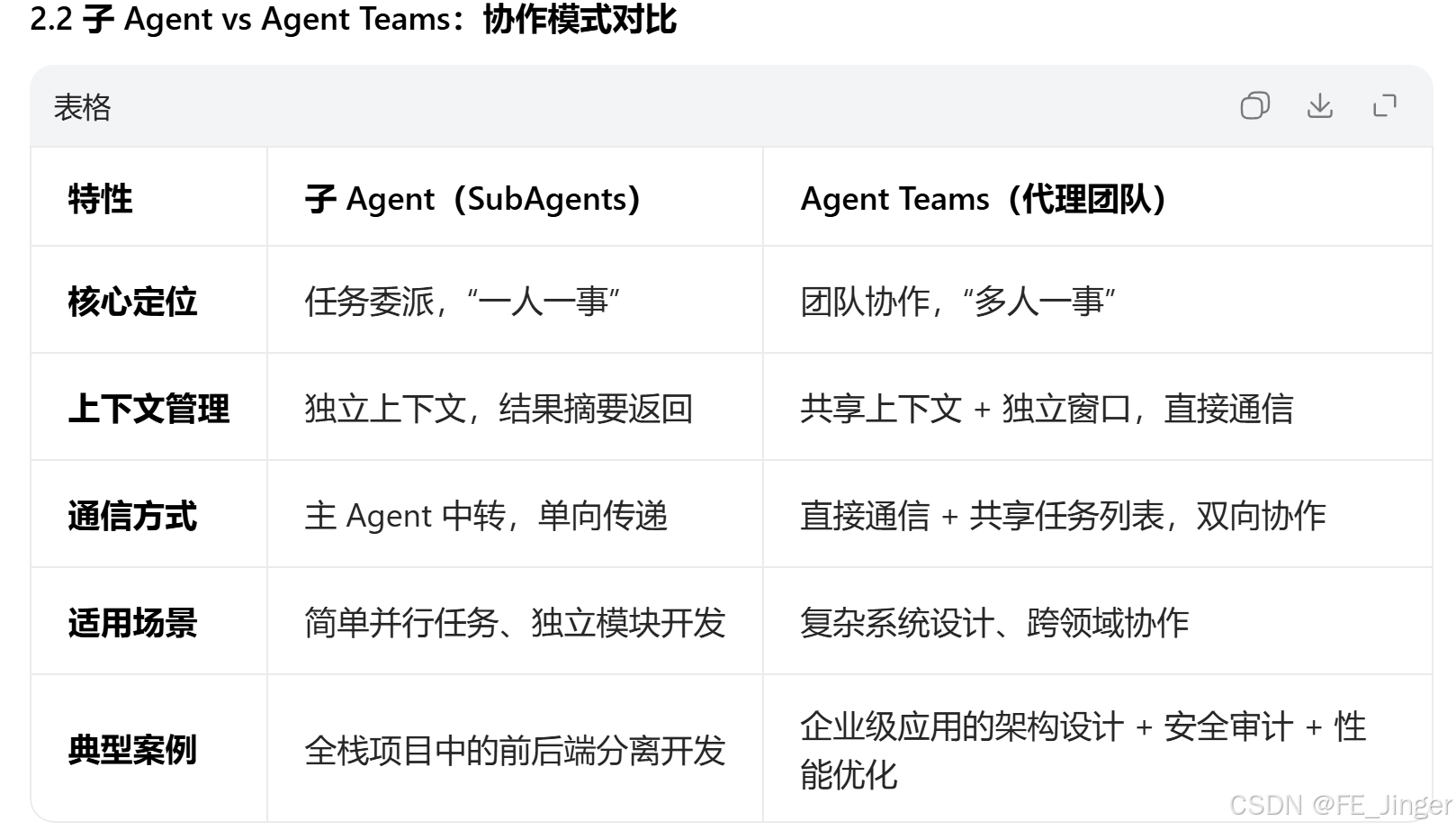
子 Agent(SubAgent) 是主 Agent(Orchestrator)派生的专业智能体,拥有独立上下文窗口、工具集和执行环境,专注于特定任务,完成后返回结果给主 Agent,不污染全局上下文

核心启发
扩展能力优先考虑子代理、文件引用,让Agent在需要时自主发现能力,而非一开始就把所有工具摆出来。
3. 工具迭代:从"辅助工具"到"淘汰枷锁"
早期痛点(Todo List工具)
- 早期Claude记忆能力弱,用Todo List强制提醒任务;
- 模型升级后,这种强制提醒反而限制灵活性,让Agent不敢调整任务、自主规划。
改进方案(Task工具)
- 替换为Task工具:支持任务依赖关系、多Agent进度共享;
- 模型可自主修改、删除任务,根据实际情况动态调整规划;
- 工具从"强制约束"变成"灵活辅助",适配模型能力升级。
核心启发
随着模型能力增强,要定期审视工具集,淘汰那些从辅助变成枷锁的旧工具。
四、实践落地:5步掌握「渐进式披露」设计
1. 工具设计:少而精+延迟加载
- 核心工具控制在10-15个,遵循"Do one thing and do it well";
- 工具采用"轻量钩子+完整内容分离":启动时只加载元数据,用时再加载完整逻辑;
- 避免工具堆砌,优先用子代理扩展能力,而非新增主工具。
2. 提示词管理:核心+分离+路径
- 系统提示词(如CLAUDE.md)只放核心信息:项目简介、技术栈、关键规则(控制在5K Token内);
- 详细规范、文档独立成文件(如auth.md、api.md),放在统一目录;
- 提示词中只留文件路径,让Agent自主读取,不堆砌全量内容。
3. 提问方式:给方向+给入口,不给全量
- 错误示例:"帮我看所有代码,解决token刷新失败问题"(堆砌全量文件);
- 正确示例:"token刷新失败,报错xxx,从auth模块开始查,优先看token校验逻辑"(给方向+入口);
- 让Agent
自主定位文件、分析问题,而非被动接收全量信息。
4. 技能封装:三层结构标准化
.claude/skills/
└── incident-triage/ # 技能目录
├── SKILL.md # 第二层:核心指令(任务逻辑)
├── runbook.md # 第三层:详细操作手册
├── examples.md # 第三层:案例参考
└── scripts/ # 第三层:执行脚本
└── collect-context.sh- SKILL.md只放核心指令,详细内容放关联文件,Agent按需读取。
5. 迭代优化:定期审视+快速试错
- 每2-4周复盘工具集、提示词,淘汰低效、冗余内容;
- 小步迭代:先在单个任务上验证渐进式披露,再扩展到全场景;
- 关注Token消耗、执行效率、指令遵循率,用数据驱动优化。
五、总结:「渐进式披露」的本质------克制的力量
Claude Code的「渐进式披露」,本质是对AI Agent能力的信任与尊重:
- 我们总觉得"给得越多,AI越厉害",但事实是塞得越多,Agent越受限;
- 给Agent最小必要信息+自主探索能力,它反而能发挥出远超预期的推理与执行效率;
- Agent工具设计是"科学+艺术",没有银弹,只有多试、多迭代,才能找到最适配的信息供给方式。
六、互动思考
你在开发AI Agent时,遇到过哪些"信息过载"的问题?欢迎在评论区分享你的踩坑经历与解决方案,一起探讨「渐进式披露」的更多落地技巧!