目录
[第一步:Input Embedding(输入嵌入)](#第一步:Input Embedding(输入嵌入))
[第二步:Positional Encoding(位置编码)](#第二步:Positional Encoding(位置编码))
[第三步:Multi-Head Attention(多头自注意力机制)](#第三步:Multi-Head Attention(多头自注意力机制))
[第四步:Add & Norm(残差连接与层归一化)](#第四步:Add & Norm(残差连接与层归一化))
[第五步:Position-wise Feed Forward(位置前馈网络)](#第五步:Position-wise Feed Forward(位置前馈网络))
[第六步:再次Add & Norm与模块堆叠](#第六步:再次Add & Norm与模块堆叠)
[关键:Masked Multi-Head Attention(掩码多头注意力)](#关键:Masked Multi-Head Attention(掩码多头注意力))
最后步骤:Linear(线性层)与Softmax(归一化指数函数)
前言
如果要评选出人工智能领域最出名的一句话,十有八九会是 "Attention Is All You Need"。这句话来自2017年的一篇论文,这篇论文发表之后,各家AI公司纷纷投入大量的资源和技术,它就是当今人工智能领域军备竞赛的发明者。这篇论文不仅彻底改变了技术领域,还缔造了一系列令人震惊的财富传奇。
论文发表之后,有一家创业公司敏锐地抓住了机会,借助论文中的理论迅速崛起。如今,这家公司的估值已经超过了3000亿美金,是这个世界上最炙手可热的公司之一,这家公司就是OpenAI。而这篇论文的八个作者,他们当时都在谷歌工作,后来纷纷从谷歌离职,其中的七位选择了创业,而他们创立的公司估值普遍达到了数亿到数十亿美金。
毫不夸张地说,只要读懂了这篇论文,你就掌握了人工智能的核心思想。在今天的视频中,我将带你读懂这个论文中最精华的部分,那个架构图的Transformer,以及著名的注意力计算公式。整个过程我只会用到我在幼儿园学过的数学知识。
铺垫:Transformer出现之前的AI困境
在正式开始之前,我们有必要先了解一下在Transformer出现之前的世界是什么样子的?在2010年代中期,循环神经网络RNN以及它的变种LSTM几乎完全统治了自然语言处理领域。然而,RNN有两个非常棘手的问题。
-
第一个问题就是RNN的核心思想是通过记忆前一步的信息来预测下一步,这就意味着每一步的计算都需要等待上一步完成。这种顺序依赖的机制就导致模型无法并行计算,很难充分利用现代计算机强大的运算处理能力。
-
第二个问题就是RNN的记性不太好,当句子或文本的长度稍长一些的时候,模型就很难有效地记住比较早出现的信息。比如:我今天买了一本书,上午去了趟图书馆,下午又去了咖啡厅,晚上才开始读它。这里的"它"指代的正是前面提到的"书"这个字,但由于中间隔了许多其它的信息,传统的RNN往往很难精确地记住这种长距离的依赖关系。
尽管后来出现了LSTM等改进技术,但是依旧没有彻底地解决长距离依赖和串行计算这两个问题。同时期还有卷积神经网络CNN,RNN比较擅长处理序列数据,就像一个逐字逐句读书的人,所以经常被用来处理语言和音频。而CNN则擅长处理具有空间局部特征的数据,就像一个拿着放大镜仔细观察图片的人,所以经常被用来处理图像。
CNN虽然能并行计算,但因为它的视野比较窄,也很难记住全局的信息。为了克服这些问题,2014年Bahdanau等人提出了注意力机制,也就是Attention,历史的车轮终于开始了转动。
转折:注意力机制的兴起与局限
注意力机制的核心思想是当模型处理信息时,它会学着为不同的信息分配注意力权重,知道哪些信息是重要的就要多关注,而哪些信息是不重要,可以忽略的,让模型也学会划重点。随后的几年,注意力机制迅速流行了起来,但那时候的注意力只是RNN或者CNN的辅助工具,没有人认为注意力可以脱离RNN或者CNN而独立地存在。
为什么大家会这么想?
-
首先是思维惯性,处理序列任务就用RNN,处理图像任务就用CNN,这几乎是当时人工智能界的常识。
-
其次还有人类的认知本能,人们习惯逐字逐句地阅读,总觉得信息应该一步一步地传递下去。而注意力机制要同时处理文本中的所有词汇之间的关系,这种同时关注所有内容的思路实在是太反直觉了,更重要的是它听起来计算量就非常巨大,让很多人觉得根本都不切实际。
这就有点像量子力学刚出来的时候也是非常地反直觉,甚至连爱因斯坦都不愿意相信。讲到这里,我要给大家一个建议就是多干饭,因为干饭的时候往往会有好事发生。
诞生:Transformer的由来与团队
2016年,谷歌的工程师Illia Polosukhin在公司食堂干饭的时候向同事Noam Shazeer抱怨说搜索模型里面RNN反应太慢,达不到预期的效果。我们就叫他Illia和Noam吧。听完Illia的吐槽,Noam随后说了一句载入AI史册的话,这句话只有五个单词,全部来自初中词汇表,所以如果我在现场,可能我也行。这句话就是"Why Not Use Self Attention?"
于是这两个人立刻尝试这个疯狂的想法,项目刚一开始,Noam就给这个新模型取了一个响亮的名字Transformer。Transformer就是变形金刚的意思,因为他从小就是变形金刚的铁粉,他们甚至还在项目文档里画了一幅变形金刚的卡通图,并用一句底气十足的话作为文档的开篇"We Are Awesome"。
Noam早在2014年就开始关注注意力机制了,他的父亲Hans是欧洲著名的人工智能语言学家,父子二人曾经因为对注意力机制的看法不同在餐桌上激烈地争论。不过后来Hans自己在和学生一起创业开发大模型之后用的正是传统的架构,所以从结果来看还是儿子赢了。
Noam的团队迅速扩容到了七个人,最后加入的是谷歌的传奇级程序员Ashish Vaswani,他在2000年就进入了谷歌。那天Ashish路过的时候偶然听到Noam他们在讨论注意力机制,立刻停下脚步偷听了一阵。他本来就对当时风头正盛的LSTM心存不满,一直想彻底把它们换掉。就这样,这位身怀绝技的"扫地僧"正式加入了战局。
Ashish深厚的理论功底和多年的编程经验在Transformer模型的设计中得到了淋漓尽致的体现,团队成员经常用"魔法""炼金术"甚至"妖术"这种词来形容他的贡献。Ashish为Transformer引入了至关重要的多头注意力、位置编码等等很关键的设计,而这些概念我们都会在后面详细地讲解。
在论文脱稿之前,Ashish意外地发现自己的名字在作者里面排名第一位,赶紧提出反对意见。最后大家一致决定在每个人的名字后面都加上星号,并注明"作者贡献相等,排名随机"。这八位作者背景各异,其中六个人出生在美国以外的国家,回想起来那真的是一个黄金时代。
过渡:论文核心内容铺垫
讲到这里,这篇论文的作者名单我们终于讲完了,接下来得加快点进度了。有了前面的铺垫,现在理解论文前两页的内容已经非常轻松了。论文的前两页分别是摘要、引言和背景,强调了Transformer完全抛弃了RNN的循环结构和CNN的卷积结构,仅依靠注意力机制,因此能够高度地并行,极大提高了训练的效率。它仅需要八块GPU训练十二个小时,就在翻译任务上超过了以往最优秀的模型。
接下来我们终于要进入这篇论文最核心的部分,就是"Transformer Model Architecture"图,这张图里藏着Transformer所有的秘密,让我们一步步地详细解析。这部分内容会很干,容我喝一口水。
核心解析(一):Transformer输入部分详解
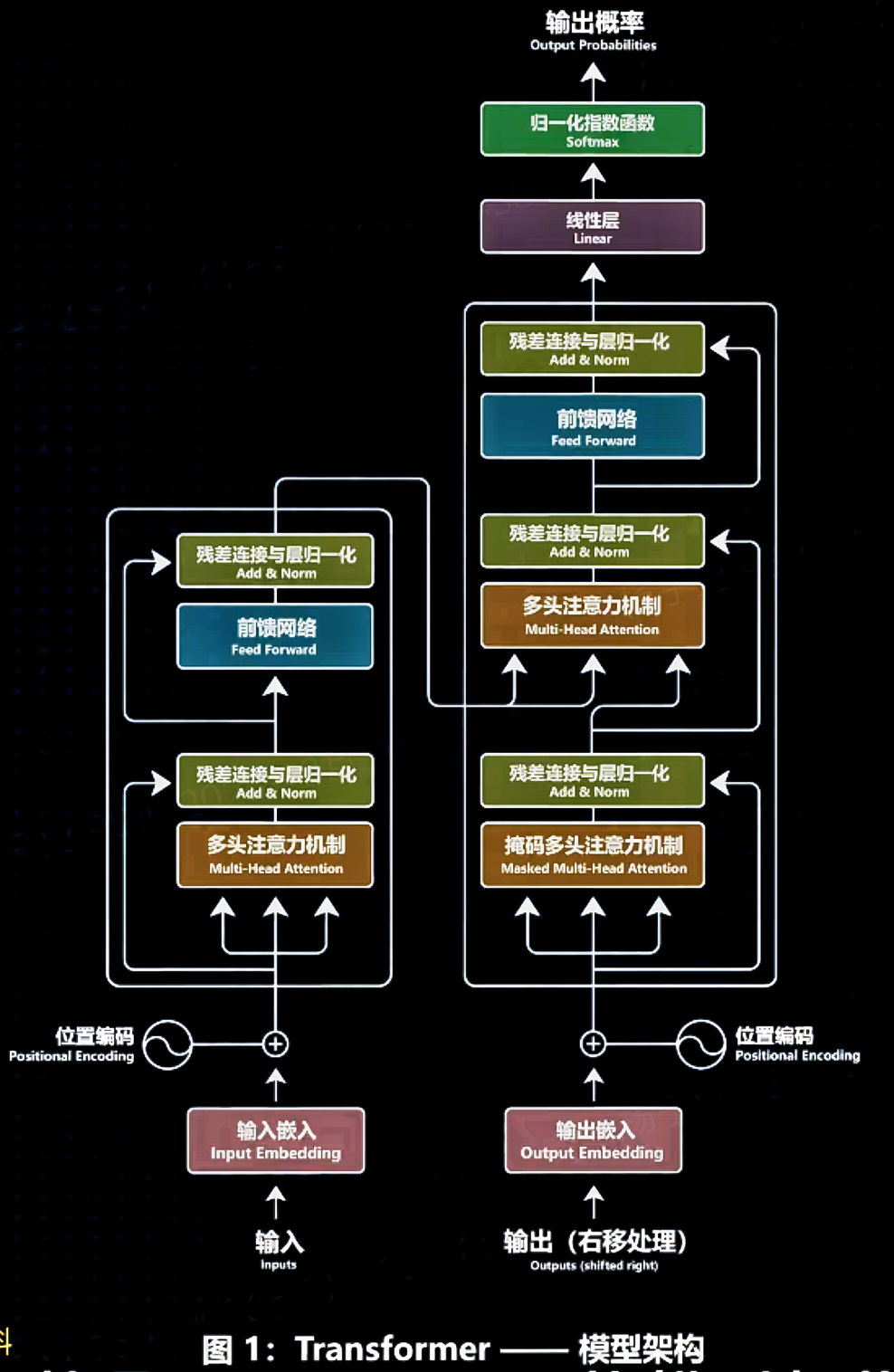
第一步:Input Embedding(输入嵌入)
我们掰开揉碎一步步地看,先看左边的"Inputs",也就是输入。当我们日常使用AI的时候,我们问AI的问题就是输入,而在训练AI的时候,我们提供给模型的语料数据同样也是输入。模型收到这些输入之后,首先要进行"Input Embedding",也就是输入嵌入。
我们平时使用的自然语言像中文或者英文,计算机是无法直接进行计算的,因此我们需要将语言中的单词转化成向量,计算机才能理解和处理这些信息。
举个具体的例子,现在有一些单词,把它排列在一个平面坐标系里面,这个坐标系有两个属性,横轴表示"科技程度",纵轴表示"生产力"。在真实的模型中,单词的含义远比二维平面更加复杂,它们被映射到一个512维的空间里面,可以简单理解为每个词都有512个不同维度的特征。
这些特征是模型通过学习大量语料后自动掌握的,但512维空间对于人来说实在太抽象,视频没办法直接展示,所以这里采用二维空间来代替。在这个二维空间中含义相似的单词会挨得很近,而含义相差很大的单词则会离得比较远。
**虽然自然语言本身无法参与数学运算,但被转换成向量之后就能很方便地进行向量运算了。**比如"墨索里尼"这个词在这个位置,"意大利"在这个位置,"德国"在这个位置,如果计算"墨索里尼 - 意大利 + 德国"就会得到一个新的位置,离这个位置最近的词最可能的就是"希特勒"。同样的,"北京 - 中国 + 法国"得到的新位置附近最可能出现的单词是"巴黎",而"教师 - 学校 + 医院"则是"医生"。
甚至如果你很好奇谁更像女版的蔡徐坤,也可以用向量来计算一下"蔡徐坤 - 男 + 女",然后看看这个位置附近出现的人是谁?
再仔细观察一下刚才的例子,比如"意大利到墨索里尼"和"德国到希特勒"这两个向量的方向几乎完全一样,也就是它们的夹角非常小,因为它们表达的语义关系非常接近,都是在表达国家与领导人之间对应的关系。两个向量的夹角越小,它们的内积(点积)就越大,代表这两个单词的语义越相似。
而夹角越大,比如超过90度甚至接近180度,它们的内积就越小甚至为负,代表含义不同甚至相反。再想象一下一个512维的空间,每种语言都有大概3万个单词,在这个空间里面从坐标系的原点向每个单词所在的点画一条箭头,这些箭头就是词向量,也就是模型所理解的"单词的含义"。
第二步:Positional Encoding(位置编码)
第二步、"Positional Encoding",也就是位置编码。Transformer没有RNN那样的循环结构,它本身并不清楚单词在句子中的具体先后顺序,因此需要给每个单词添加一个独特的编码,让模型知道单词之间的位置信息。论文的作者在这里画了一个类似"阴阳"的小图标,其含义是Transformer使用正弦和余弦的函数组合来生成每个单词的位置信息编码。
第三步:Multi-Head Attention(多头自注意力机制)
这一部分是Transformer的核心理念,也最复杂,我们拆开揉碎了来讲。
**首先注意到图上这里有三个箭头,为什么是三个箭头?这三个箭头其实分别代表了三个非常重要的概念,就是Query、Key和Value,简称Q、K、V。**我们可以把输入句子里的每个单词都想象成一个"小人",现在这些小人需要互相了解一下对方,每个人都要回答两个问题:"我的身份是什么?"这个问题的答案就是它的K;"我想知道什么?"这个问题的答案就是它的Q。
我们看一个例子:"我今天买了一本书,上午去了趟图书馆,然后下午又去咖啡厅,晚上才开始读它。"这个句子中的"我",它的身份是什么?它的身份是"人称代词、句子的主体",也就是这个单词的K。而"我"这个词最关心的是什么?它想知道"我做了什么?""我去了哪里?"这就是它的Q。句子里面每个"小人"都要这样计算出它的Q和K,比如"书"和"它",它们的Q和K分别是这样。
这里可能就会有人问了,Q和K到底是怎么计算出来的?每个单词的Q和K都是由它们自己的词向量与模型在训练时学习到的参数矩阵相乘而计算出来的。因为Transformer模型在训练的时候已经学习过大量的文本,所以它能够很好地捕捉每个单词的语义信息。
接下来每个单词的Q都要与句子中所有其他单词的K做一个点积运算,简单来说就是拿每个单词自己的Q去和其他单词的K进行匹配,看看谁更合适。比如"它"的Q是"想知道自己指代的是什么东西",拿它的Q去碰"我"这个字的K,就会发现"我"是一个人称代词,不是"它"要找的,所以匹配不上。所以对于"它"这个字来说,就没有必要关注"我"这个字。
但是当"它"的Q碰到了"书"的K的时候情况就不一样了,"书"的K告诉我们:"我是一个名词,是一种能被买、被读的物品",正好和"它"的Q高度匹配,"书"这个词对于"它"来说就格外值得投入注意力去关注。
然后"它"再去查看这个单词的V,V可以理解成是这个单词的具体含义或客观信息。不过需要注意的是,这里的V并不是单词最初的向量,而是经过模型再次计算出来的一个新向量。比如"书"这个单词可能有很多不同的含义,模型在训练时学过大量语料,会发现绝大多数情况下"书"表示的是"成册的著作",而不是《尚书》。
因此"书"的向量会主要地表示"成册的著作"这个含义,而以较低的概率表示其他含义。于是具体的过程就是:"它"这个单词通过自己的Q和句子中每个词的K做匹配后,发现自己和"书"高度相关,于是就进一步查看"书"的V。接下来"它"的向量就会朝着"成册的著作"这个含义产生一定的偏移。
经过这种偏移之后,"它"这个单词的向量中也就带上了"成册的著作"的信息,最终模型就理解了"它"在这句话中具体的指代是什么。
在这里要特别强调一下,上面举的例子都是为了让大家更直观理解注意力机制的工作原理。在实际的Transformer模型中,Q、K、V都不是具体的自然语言,而是512维空间中的数学向量。这个过程也都是通过向量的数学计算来完成的。因此这三个箭头的意思就是Q、K、V。
在Transformer的自注意力机制中,句子里的每一个单词都会对其他单词分配不同的注意力权重,然后根据注意力权重的大小产生不同程度的向量偏移,而正是这些偏移让AI形成了对语义的深层理解。这就是Transformer中最核心的"Attention",也就是注意力机制。
多头注意力的具体原理
为什么叫做"Multi-Head Attention"(多头注意力)?所谓多头注意力,就是同时并行地做多次自注意力的计算,每一次自注意力计算都被称作一个"头",每个头都使用一组独立的参数矩阵。简单来说,就是使用多个不同的视角来观察输入的句子。
比如有一个头可能更关注句子的语法结构,这个头的注意力计算就会更多地判断每一个词究竟是名词还是动词,词与词在语法上的关系。有的头可能特别关注代词,想弄清楚每一个代词究竟指代的是谁。有的头可能更关注单词的情绪色彩,想分辨出哪些词带着积极乐观的情绪,哪些词的含义是负面或消极的。
在论文中这个"多头"一共有8个,刚才说的语法结构、代词、情绪色彩这些例子都是为了方便大家直观理解。事实上模型并不会告诉每个头具体应该关注什么,它们完全是通过数学方法自动发现和学习的。模型会自动地从大量数据中发现最适合的8种关注方式。
另外,每个单词最初都是用512维的向量表示,但因为每个头只需要关注一个特定的方面,因此每个头并不需要处理完整的512维信息。在实际实现中,每个头只需要处理64维的信息。也就是说,对于每个输入句子,8个头会各自独立地进行注意力计算,每个头产生一个64维的结果,最后再把这8个64维的结果拼接在一起(8×64=512),再次回到原始的512维向量大小。
通过这种多头机制,Transformer就能够同时从不同角度理解和处理语言信息,大幅度地提升了模型的表达能力和效果。到这里,最难的多头注意力终于讲清楚了。
第四步:Add & Norm(残差连接与层归一化)
完成多头注意力之后,还需要进行"Add & Norm",也就是残差连接与层归一化。前面的多头注意力可以理解成模型为每一个单词计算出了一个"偏移量",这个偏移量表示单词在结合上下文之后需要进行的调整。
-
残差连接的作用就是把这个偏移量加回原始信息的输入向量,得到一个实际的新向量。换句话说,残差连接通过相加把原始信息和模型计算出来的新信息组合到一起。
-
接下来"Layer Norm"会对这些向量进行标准化处理,具体就是让每个向量的数值分布重新调整到均值为0、方差为1的标准分布。简单来说,就是给数据重新调整一下它的比例尺和中心位置,让数据分布更加稳定,训练模型时更容易收敛,效果也更好。
第五步:Position-wise Feed Forward(位置前馈网络)
然后数据就来到了"Position-wise Feed Forward",也就是位置前馈网络。我们还是把每个单词都看成一个"小人",刚才的注意力机制就好比是团队开会,每个人都会在会上与其他成员沟通交流,获得了很多来自成员的想法和信息。但在开会之后,每个人都需要回到自己的房间里面独自思考和消化一下刚才获得的信息。
位置前馈网络做的就是这个事情,在这里每个单词都会单独地重新组织一下自己身上的向量信息。具体的做法就是把原来每个单词512维的向量升级到2048维,然后通过ReLU激活函数保留正数部分(把所有负数变成0),实现非线性变换。最后再从2048维降回512维。这个过程会去掉一些冗余信息,只保留最有用、最关键的信息,进一步增强了模型的非线性表达能力。
这里就不再进一步展开了,因为这种通过先升维再降维来提高模型表达能力的方式,并不是Transformer的首创,像Autoencoder(自编码器)、ResNet(残差网络)以及卷积神经网络里的BottleNeck层等等都采用过类似的策略。
第六步:再次Add & Norm与模块堆叠
然后我们把信息再经过一遍"Add & Norm",再次完成对信息的整理。
到这里,我们就把输入部分的过程讲完了。大家可能注意到在这个架构图左侧标了一个"Nx",意思是图中的这个模块是重复堆叠多次的。在原始的Transformer论文中,这个结构堆叠了6次,可以把它理解成是6个这样的模块串联在一起,第一个模块的输出会作为第二个模块的输入,以此类推,连续完成6次这样的处理过程。
为什么要堆叠多层?因为仅进行一次注意力信息的处理,往往不足以充分捕捉语言中最复杂、最细致的关系。而Transformer通过多个堆叠层反复地对信息进行加工和提炼,就能够逐层更深入挖掘句子中的各个细节,从而更精准、更全面地表达复杂的信息。
有人可能会问:这里为什么是6层而不是12层或者更多呢?这个层数是越多越好吗?事实上,在现在的一些主流大模型中,Transformer的层数确实达到了几十甚至上百层,但并不是层数越多越好。
包括前面讲到的很多数字,比如为什么一个向量是512维而不是1024或者2048维?为什么多头注意力要用8个头、每个头64维,而不是16个头、每个头32维?这些具体的数值都是模型的设计者根据理论分析、硬件限制以及大量实验结果最终确定下来的超参数。
核心解析(二):Transformer输出部分详解
输出的基本逻辑(以翻译任务为例)
讲到这里,我们就转到右边输出的部分,看看Transformer输出部分最具体如何工作的。
可以简单地理解成,输出(右移处理)就是让模型"一个个吐字"的过程。现在我们结合一个具体的任务,就可以直接来看Transformer完整的工作方式了。
比如,我们的任务是把"我爱你"这三个字翻译成英文。
首先,"我爱你"这三个字会经过多头注意力、位置前馈网络计算,这时模型就对这三个字的含义和上下文关系有着深入而全面的理解。这些信息会作为右侧的K和V。
一开始,模型还没有任何的输出内容,这时有一个默认的初始向量"<start>"作为Q。因为现在模型的任务是翻译,它就会寻找句子中最适合作为起始词的内容,发现"我"是句子的主语,于是输出了第一个词"I"。
输出了第一个词"I"之后,这时的Q就是"I表达的情感或动作是什么",它再次查看左侧传过来的K,找到了"爱"这个词,因为"爱"对应的V是"对人或事有深厚的感情",于是就生成了第二个词"love"。
生成了"love"之后,这时的Q就是"我爱的究竟是谁呢",因此输出了第三个词"you"。
到这里,模型就输出了完整的句子"I love you",然后发现已经完成了翻译,就会输出一个"<end>"来表示生成结束。
关键:Masked Multi-Head Attention(掩码多头注意力)
知道了整体流程之后,我们再回头看右侧的"Embedding"和"Positional Encoding",和左侧的原理是一样的。但右侧有一个特别的**"Masked Multi-Head Attention",这又是为什么呢**?
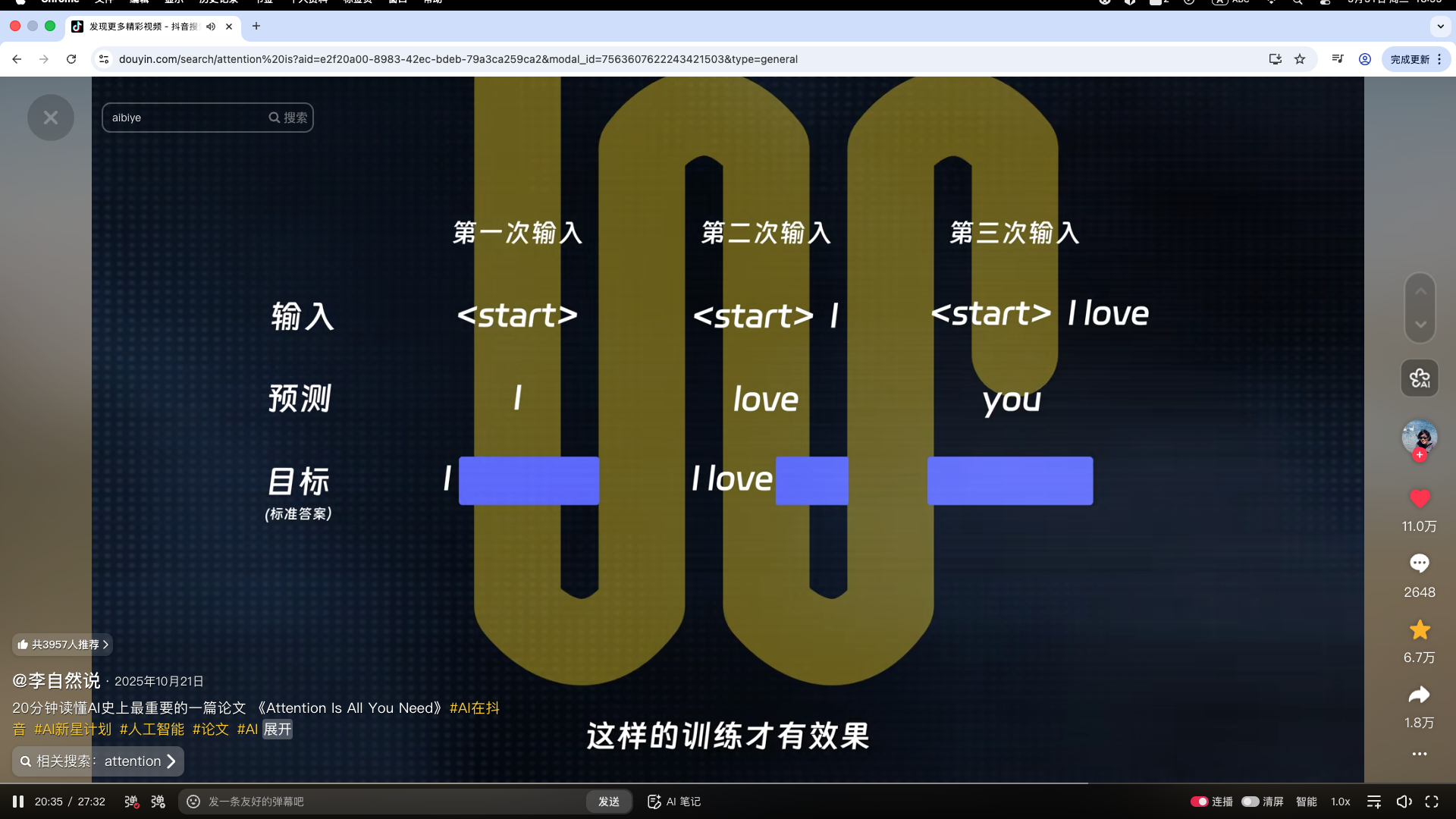
因为在很多AI任务中,每一个问题其实都是有一个标准答案的。比如我们在训练模型翻译的时候,模型的预测结果需要和标准答案进行比对。但标准答案肯定不能让模型事先看到,否则训练也就没有意义了。
为了避免这种情况,就需要让模型只能看到以前生成的内容,而无法看到未来的信息,这就是"Masked"这个词的含义。
具体来说,在训练阶段,开始时Q的输入是"<start>",模型预测第一个词;然后用第一个词作为输入,模型预测第二个词;再用前两个词作为输入,模型预测第三个词,逐字逐步地进行下去。
对比一下就会发现,模型的输入相比标准答案都往右移动了一位,这也就是图中下方标注"shifted right"的含义。
上面说的这些步骤都是在训练阶段进行的,也就是模型在学习的时候。而在推理阶段,也就是实际翻译的时候,模型的Q仍然从"<start>"开始,模型同样无法提前知道未来的信息,因此推理时的原理和训练阶段是完全一样的。
训练就像平时做练习题,而推理则像是考试,只能依靠之前训练时学到的能力去完成。
最后步骤:Linear(线性层)与Softmax(归一化指数函数)
后面这几步的处理和左边基本是一样的,经过多层的"Add & Norm"和"Feed Forward"之后,就会进入"Linear"(线性层)和"Softmax"(归一化指数函数)层。
"Linear"层的任务是将生成的向量映射到实际的词汇表上面。前面我们讲过"北京 - 中国 + 法国 = 巴黎"这样的向量运算,但这个向量仅仅是一组数值,Linear层的作用就是把这些数值映射到我们真实使用的词汇表上面,比如"巴黎""伦敦""罗马"等。
"Softmax"的作用是把任意的实数值转化成介于0到1之间的概率,并且让所有概率之和等于1。比如模型在翻译"爱"这个词时,可能会计算出"love"的概率是0.8,"like"的概率是0.2,然后模型会根据计算出的概率大小,选择最可能的单词作为输出。
我相信大家现在应该能够很好地理解Transformer的输出过程了。
核心公式解析:注意力计算公式
相比之前的RNN模型,Transformer没有循环依赖,整个结构是如此的简洁和优雅,却又拥有如此强大的能力。
现在再回头看论文中的注意力计算公式 。

这个公式我们也能很清楚地理解了。
-
Q、K、V的含义前面都讲过了;
-
√d_k是一个缩放因子,使计算的结果更加稳定;
-
QK^T表示序列中每个Q和其他所有位置K的相关性;
-
然后再通过softmax函数将这些相关性转化为注意力权重;
-
最后将这些注意力权重与矩阵V相乘,最终得到融合了上下文信息的新表示。
现在是不是觉得这个公式还是挺容易看懂的?
论文标题的由来
在论文的后半部分,作者介绍了更多模型的实现细节以及训练时的一些设置。在结论部分,他们已经意识到了Transformer有着更广的应用前景,而不仅仅局限在翻译任务。
这些作者们意识到他们需要一个文章标题,而当时注意力机制只是作为RNN的辅助工具出现的,"只需要注意力机制就足够了"这个想法非常的反直觉。这时,Noam想到了披头士乐队有一首经典的歌曲《All You Need Is Love》,灵感这么一来,论文的标题"Attention Is All You Need"就诞生了。
总结概念
- 输入嵌入(Input Embedding):将自然语言单词转化为高维向量(如 512 维),让计算机可处理。向量间的关系可通过运算体现(如 "北京 - 中国 + 法国 = 巴黎",体现语义逻辑)。
- 位置编码(Positional Encoding):给单词添加位置信息,因为 Transformer 无循环结构,需通过正弦 / 余弦函数组合来明确单词在句子中的顺序。
- 多头自注意力(Multi-Head Attention):
- 每个单词生成Q(查询)、K(键)、V(值) 三个向量。Q 代表 "想知道什么",K 代表 "自身身份",V 代表 "具体含义"。
- 多个 "头"(如 8 个)从不同视角(语法、代词指代、情绪色彩等)并行计算注意力,最后拼接结果,让模型从多维度理解语义。
- 残差连接与层归一化(Add & Norm):残差连接将原始信息与新信息结合,层归一化让数据分布更稳定,便于模型训练。
- 前馈网络(Feed Forward):对每个单词的向量独立处理(先升维再降维),提炼关键信息,增强模型表达能力。
- 多层堆叠(Nx):将上述模块重复堆叠(如 6 层),逐层挖掘文本细节,提升对复杂信息的表达能力。
从机器翻译到智能对话,从文本生成到图像理解,到处都有Transformer的影子。一个个耀眼的名字背后,个个都流淌着Transformer的血脉。
如果你也想成为下一个Transformer,那么下一次AI革命性的突破,也许就是屏幕前的你。