写在前面的话:
在复现过程中主要参考下边这篇文章,在此表示感谢!语义分割:YOLO26的分割模型训练自己的数据集(从代码下载到实例测试)
一、程序下载
官方程序地址如下:ultralytics:打造前沿SOTA YOLO模型,支持检测、分割、分类与姿态估计,快速精准易用 - AtomGit | GitCode
下载程序界面向下滑,下载预训练模型,下载后直接放ultralytics-main路径下
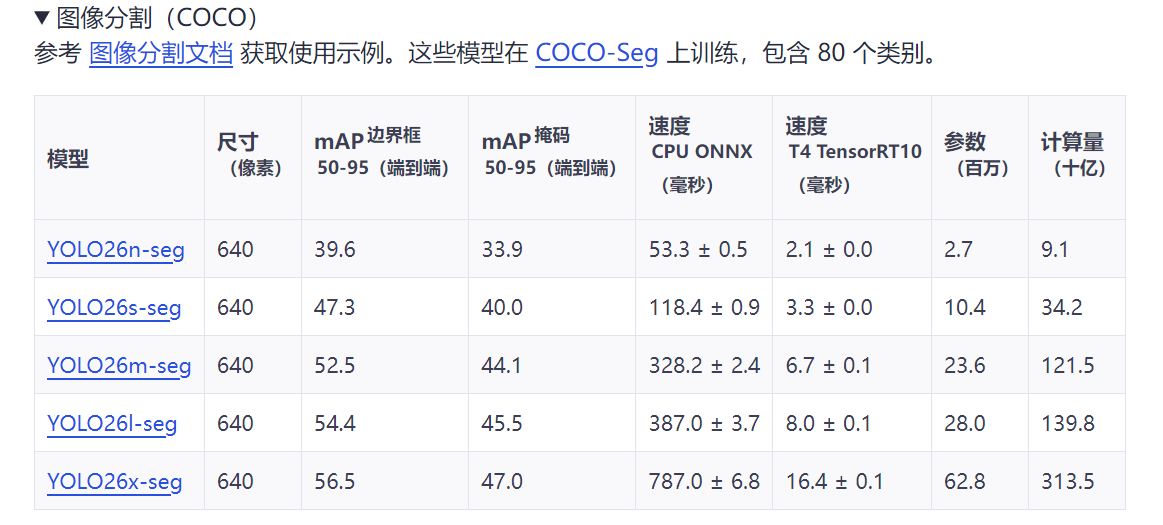
二、环境配置
1.创建虚拟环境
conda create -n yolo26seg python=3.11 -y2.激活虚拟环境
conda activate yolo26seg3.安装PyTorch
python -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu1184.安装 YOLOv26(ultralytics)
python -m pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple三、数据划分
在ultralytics-main目录下建文件夹datasets\images和datasets\labels,将图片数据放在images里,标签放在labels里,运行下边程序进行数据划分。
# coding: utf8
"""
数据存放在images文件夹下,标签存放在labels文件夹下,运行程序后目录结构如下:
datasets/
├── images/ # 原始文件已清空
│ ├── train/
│ ├── val/
│ └── test/
├── labels/ # 原始文件已清空
│ ├── train/
│ ├── val/
│ └── test/
├── train.txt
├── val.txt
└── test.txt
"""
import os
import shutil
import random
# ====================== 【只需修改这里】 ======================
DATASET_ROOT = r"C:\Users\ultralytics-main\datasets" # 你的数据集根目录
IMAGE_DIR = "images" # 原始图片文件夹
LABEL_DIR = "labels" # 原始标签文件夹
SPLIT_RATIO = [0.8, 0.1, 0.1] # 训练/验证/测试比例
# ==============================================================
def create_folders(root):
"""自动创建 train/val/test 文件夹"""
subsets = ['train', 'val', 'test']
for sub in subsets:
os.makedirs(os.path.join(root, IMAGE_DIR, sub), exist_ok=True)
os.makedirs(os.path.join(root, LABEL_DIR, sub), exist_ok=True)
def get_paired_files(img_dir, lab_dir):
"""自动配对图片和任意格式标签"""
# 支持的图片格式
img_exts = {'jpg', 'jpeg', 'png', 'bmp', 'tiff', 'tif', 'JPG', 'PNG'}
# 支持的标签格式(txt/json/png/jpg全支持)
lab_exts = {'png', 'jpg', 'jpeg', 'txt', 'json', 'bmp', 'PNG', 'JPG'}
img_map = {}
for img_file in os.listdir(img_dir):
ext = img_file.split('.')[-1].lower()
if ext in img_exts:
name = os.path.splitext(img_file)[0]
img_map[name] = img_file
lab_map = {}
for lab_file in os.listdir(lab_dir):
ext = lab_file.split('.')[-1].lower()
if ext in lab_exts:
name = os.path.splitext(lab_file)[0]
lab_map[name] = lab_file
pairs = []
for name in img_map:
if name in lab_map:
img_path = os.path.join(img_dir, img_map[name])
lab_path = os.path.join(lab_dir, lab_map[name])
pairs.append((img_path, lab_path))
print(f"✅ 成功配对图片+标签:{len(pairs)} 组")
if len(pairs) == 0:
raise Exception("❌ 没有匹配到图片和标签,请检查文件名!")
return pairs
def split_dataset(pairs, root, ratio):
"""划分数据集 + 剪切移动 + 生成txt"""
random.seed(42)
random.shuffle(pairs)
total = len(pairs)
train_num = int(total * ratio[0])
val_num = int(total * ratio[1])
splits = [
('train', 0, train_num),
('val', train_num, train_num + val_num),
('test', train_num + val_num, total)
]
for subset, start, end in splits:
count = end - start
print(f"\n📂 生成 {subset} 集:{count} 张")
img_sub_folder = os.path.join(root, IMAGE_DIR, subset)
lab_sub_folder = os.path.join(root, LABEL_DIR, subset)
txt_save_path = os.path.join(root, f"{subset}.txt")
with open(txt_save_path, 'w', encoding='utf-8') as f:
for i in range(start, end):
img_src, lab_src = pairs[i]
img_name = os.path.basename(img_src)
lab_name = os.path.basename(lab_src)
shutil.move(img_src, os.path.join(img_sub_folder, img_name))
shutil.move(lab_src, os.path.join(lab_sub_folder, lab_name))
# 写入txt
img_line = f"{IMAGE_DIR}/{subset}/{img_name}".replace('\\', '/')
lab_line = f"{LABEL_DIR}/{subset}/{lab_name}".replace('\\', '/')
f.write(f"{img_line} {lab_line}\n")
if __name__ == '__main__':
img_dir = os.path.join(DATASET_ROOT, IMAGE_DIR)
lab_dir = os.path.join(DATASET_ROOT, LABEL_DIR)
print("🚀 开始划分数据集...")
create_folders(DATASET_ROOT)
paired = get_paired_files(img_dir, lab_dir)
split_dataset(paired, DATASET_ROOT, SPLIT_RATIO)
print("\n🎉 全部完成!")四、配置文件
在ultralytics-main路径下创建data.yaml,修改数据集路径,分割的类别及数量。
path: ../datasets # 数据集所在路径
train: train.txt # 数据集路径下的train.txt
val: val.txt # 数据集路径下的val.txt
test: test.txt # 数据集路径下的test.txt
is_segment: true
# 类别数量(必须和下面 names 数量一致)
nc: 5
# Classes
names:
0: 汽车
1: 货车
2: 非机动车
3: 道路
4: 行人
5: 护栏五、模型训练、验证、推理
1.模型训练
新建ultralytics-main\train.py,程序如下修改相关参数即可,训练结果路径为:ultralytics-main\runs\segment\train
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'yolo26-seg.yaml') # 默认n m只需写yolo26m即可定位到m模型
model.load('yolo26n-seg.pt') # 是否加载预训练权重
model.train(data=r'data.yaml',
task='segment', # 任务类别
imgsz=640,
epochs=300,
single_cls=False, # 多类别设置False
batch=8,
workers=0,
device='0',
amp=True,
optimizer="AdamW"
)2.模型验证
新建ultralytics-main\val.py,程序如下修改相关参数即可。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/segment/train/weights/best.pt')
model.val(data='data.yaml',
task='segment',
imgsz=640,
batch=16,
split='test', #使用测试集评估
workers=10,
device='0',
)3.推理
新建ultralytics-main\detect.py,程序如下修改相关参数即可,推理结果路径为runs\segment\predict。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/segment/train/weights/best.pt')
model.predict(
source='datasets/images/test',
imgsz=512,
device='0',
save=True,
boxes=False # 关闭检测框绘制
)六、模型导出
新建ultralytics-main\export.py,将模型导出为onnx格式,程序如下修改相关参数即可, 运行程序后在runs\segment\train\weights里生成best.onnx。
from ultralytics import YOLO
if __name__ == "__main__":
pth_path = r"runs/segment/train/weights/best.pt"
model = YOLO(pth_path) # 加载自定义训练模型
# Export the model
model.export(format='onnx', opset=12)