在计算机视觉领域,风格迁移是一种极具趣味性与实用性的技术 ------ 它能让普通图像或视频 "穿上" 艺术大师的 "外衣",实现照片秒变油画、视频实时滤镜的神奇效果。本文将从单张图片的风格迁移入手,逐步延伸到摄像头 / 视频的实时四宫格风格滤镜效果,结合 OpenCV 的 DNN 模块,从零拆解技术原理、代码逻辑与优化技巧,帮助你快速掌握这一热门应用。
一、风格迁移的核心原理与 OpenCV DNN 基础
1.1 什么是风格迁移?
风格迁移的本质是将一张图片(内容图)的内容与另一张图片(风格图)的艺术风格进行融合,生成一张兼具内容与风格的新图像。2015 年,Gatys 等人提出的基于深度学习的风格迁移算法奠定了该领域的基础,后续研究者又推出了可实时运行的轻量化模型(如本文使用的 .t7 格式模型),让风格迁移从离线走向实时。
1.2 OpenCV DNN 模块的作用
OpenCV 的 DNN(Deep Neural Network)模块支持加载预训练的深度学习模型,无需手动搭建网络即可完成推理。本文使用的 .t7 模型是基于 Torch 框架训练的风格迁移模型,通过 cv2.dnn.readNetFromTorch() 即可快速加载并运行。
1.3 单图风格迁移的核心流程
python
import cv2
image = cv2.imread('img1.jpeg')
cv2.imshow('yuan', image)
(h, w) = image.shape[:2]
# 构建输入Blob:将图像转换为模型可接受的格式
blob = cv2.dnn.blobFromImage(image, 1, (w, h), (0, 0, 0), swapRB=False, crop=False)
# 加载风格模型
net = cv2.dnn.readNetFromTorch(r'mmodelel\the_scream.t7')
# 模型推理
net.setInput(blob)
out = net.forward()
# 后处理:将模型输出转换为可视化图像
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()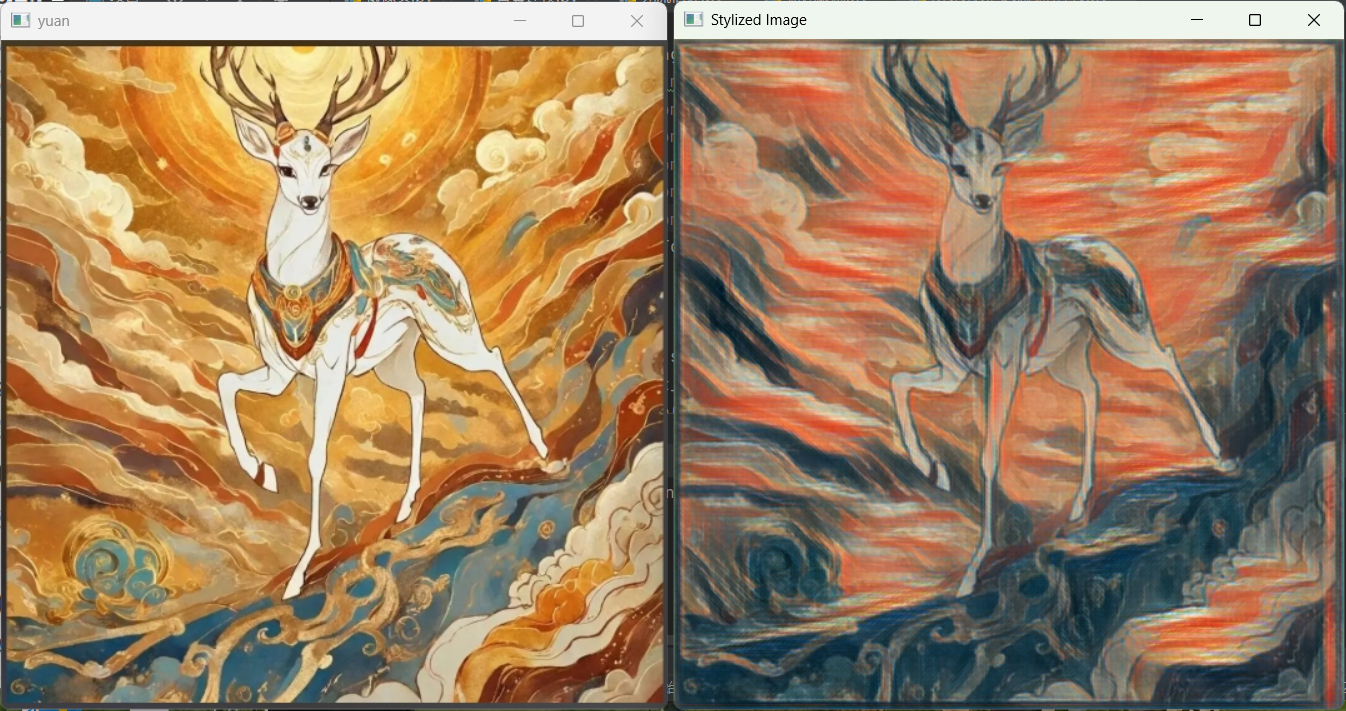
这段代码的核心步骤可拆解为:
- 图像读取与预处理 :通过
cv2.imread()读取图像,cv2.dnn.blobFromImage()将图像转换为模型输入格式(Blob),同时完成缩放、均值减法等操作。 - 模型加载与推理 :使用
cv2.dnn.readNetFromTorch()加载预训练模型,通过net.setInput()和net.forward()完成推理。 - 结果后处理 :模型输出是一个四维张量,需要通过
reshape、normalize和transpose转换为可显示的图像格式。
二、从单图到视频:实时四宫格滤镜的技术升级
2.1 视频处理的核心逻辑
视频本质上是由连续的帧组成的图像序列,因此视频风格迁移的核心是逐帧处理------ 对每一帧图像执行单图风格迁移的流程,再将处理后的帧连续显示即可。
2.2 四宫格滤镜的需求分析
作业要求将摄像头 / 视频画面分割为四个方格,每个方格应用不同的艺术风格,最终拼接成完整画面。实现这一需求需要解决三个关键问题:
- 画面缩放:为避免卡顿,需要先将画面缩放到合适尺寸。
- 画面分割:将单帧图像切割为四个子区域。
- 多模型并行推理:为四个子区域分别加载不同的风格模型。
2.3 完整代码实现与解析
python
import cv2
import numpy as np
FRAME_SIZE = 480
# 四个风格模型路径
STYLE_MODELS = [
r"model\starry_night.t7",
r"model\the_scream.t7",
r"model\feathers.t7",
r"model\la_muse.t7"
]
# 加载所有风格模型
nets = []
for model_path in STYLE_MODELS:
net = cv2.dnn.readNetFromTorch(model_path)
nets.append(net)
# 打开视频源(摄像头或本地视频)
cap = cv2.VideoCapture('video.mp4') # 0 表示摄像头
if not cap.isOpened():
exit()
# 主循环
while True:
# 读取一帧
ret, frame = cap.read()
if not ret:
break
# 缩放画面(防卡顿)
h, w = frame.shape[:2]
scale = FRAME_SIZE / max(w, h)
frame = cv2.resize(frame, (int(w*scale), int(h*scale)), interpolation=cv2.INTER_AREA)
h, w = frame.shape[:2]
# 分割画面为四宫格
mid_h, mid_w = h // 2, w // 2
top_left = frame[0:mid_h, 0:mid_w]
top_right = frame[0:mid_h, mid_w:w]
bottom_left = frame[mid_h:h, 0:mid_w]
bottom_right = frame[mid_h:h, mid_w:w]
frames = [top_left, top_right, bottom_left, bottom_right]
# 对每个子区域应用不同风格
stylized_parts = []
for i, img in enumerate(frames):
ih, iw = img.shape[:2]
blob = cv2.dnn.blobFromImage(img, 1.0, (iw, ih), (0, 0, 0), swapRB=False, crop=False)
nets[i].setInput(blob)
out = nets[i].forward()
# 后处理
out = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out, out, 0, 255, cv2.NORM_MINMAX)
res = out.transpose(1, 2, 0).astype("uint8")
stylized_parts.append(res)
# 拼接四宫格
t_l, t_r, b_l, b_r = stylized_parts
top = np.hstack((t_l, t_r))
bottom = np.hstack((b_l, b_r))
result = np.vstack((top, bottom))
# 显示结果
cv2.imshow("result", result)
# 按Q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()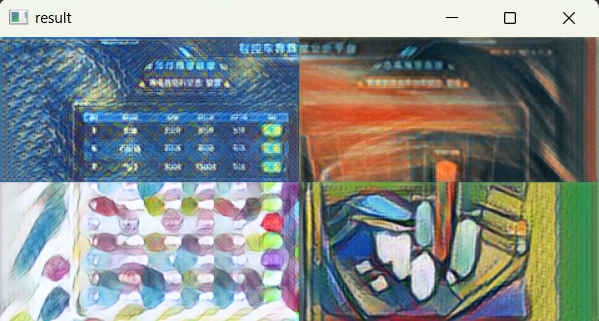
关键代码解析
- 模型加载:一次性加载四个风格模型,避免重复加载导致的性能损耗。
- 画面缩放 :通过
cv2.resize()将画面缩放到最大边为 480 像素,降低计算量,避免卡顿。 - 画面分割:使用数组切片将画面分为四个子区域,操作简单高效。
- 多模型推理:遍历四个子区域,分别使用不同的模型进行风格迁移。
- 画面拼接 :通过
np.hstack()和np.vstack()将四个风格化后的子区域拼接为完整画面。
三、性能优化与常见问题解决
3.1 性能优化技巧
- 画面缩放:降低输入图像的分辨率是提升实时性能最有效的方法,建议将最大边设置为 480~640 像素。
- 模型选择 :选择轻量化的风格模型(如本文使用的
.t7模型),避免使用大型模型导致推理速度过慢。 - 批量处理:如果需要处理大量视频帧,可以考虑批量处理,但实时场景下逐帧处理更合适。
3.2 见问题与解决方案
- 画面卡顿:检查是否未进行画面缩放,或模型加载过多导致内存占用过高。
- 画面显示异常 :确保后处理步骤正确,特别是
astype("uint8")转换,否则画面可能出现黑屏或花屏。 - 模型加载失败 :检查模型路径是否正确,确保
.t7文件存在且未损坏。
四、拓展应用与未来展望
4.1 拓展应用
- 多风格切换:通过按键事件实现不同风格模型的动态切换。
- 视频保存 :使用
cv2.VideoWriter()将处理后的视频保存到本地。 - 人脸风格迁移:结合人脸检测技术,仅对人脸区域应用风格迁移。
4.2 未来展望
随着深度学习技术的发展,风格迁移的实时性与效果将不断提升。未来,我们可以期待更轻量化的模型、更丰富的风格选择,以及与 AR/VR 技术的结合,为用户带来更加沉浸式的视觉体验。
总结
本文从单张图片的风格迁移入手,逐步实现了摄像头 / 视频的实时四宫格滤镜效果。通过 OpenCV 的 DNN 模块,我们可以快速加载预训练模型,完成风格迁移的推理过程。同时,通过画面缩放、分割与拼接等技巧,实现了高效的实时处理。希望本文能帮助你掌握风格迁移的核心技术,并激发你更多的创意应用。