Python 类型注解与运行时类型检查
本文适合谁:熟悉 Java 强类型系统、想理解 Python 类型注解在 AI 项目中如何工作的工程师。读完本篇,你能用 Type Hints + pydantic 写出类型安全的 AI 应用代码。
Python 没有编译期(代码运行前的静态检查阶段)类型检查,这是它和 Java 最大的工程化差异之一。Java 传错类型,IDE 里立刻红线报错,连编译都过不了。Python 传错类型,代码可以正常加载,等到那行代码被执行,才抛出一个看起来毫无关联的错误。
类型注解 + mypy(Python 的静态类型检查工具,不需要运行代码即可扫描类型错误),就是在弥补这个差距。在 LangGraph workflow 开发中,如果期望接收 State 对象的函数接收到了字符串,有类型注解时 mypy 在编写阶段就能发现这个问题,而不是等到运行时追栈报 AttributeError(属性访问错误,访问一个不存在的属性时抛出)。
1.1 为什么 AI 项目特别需要类型注解
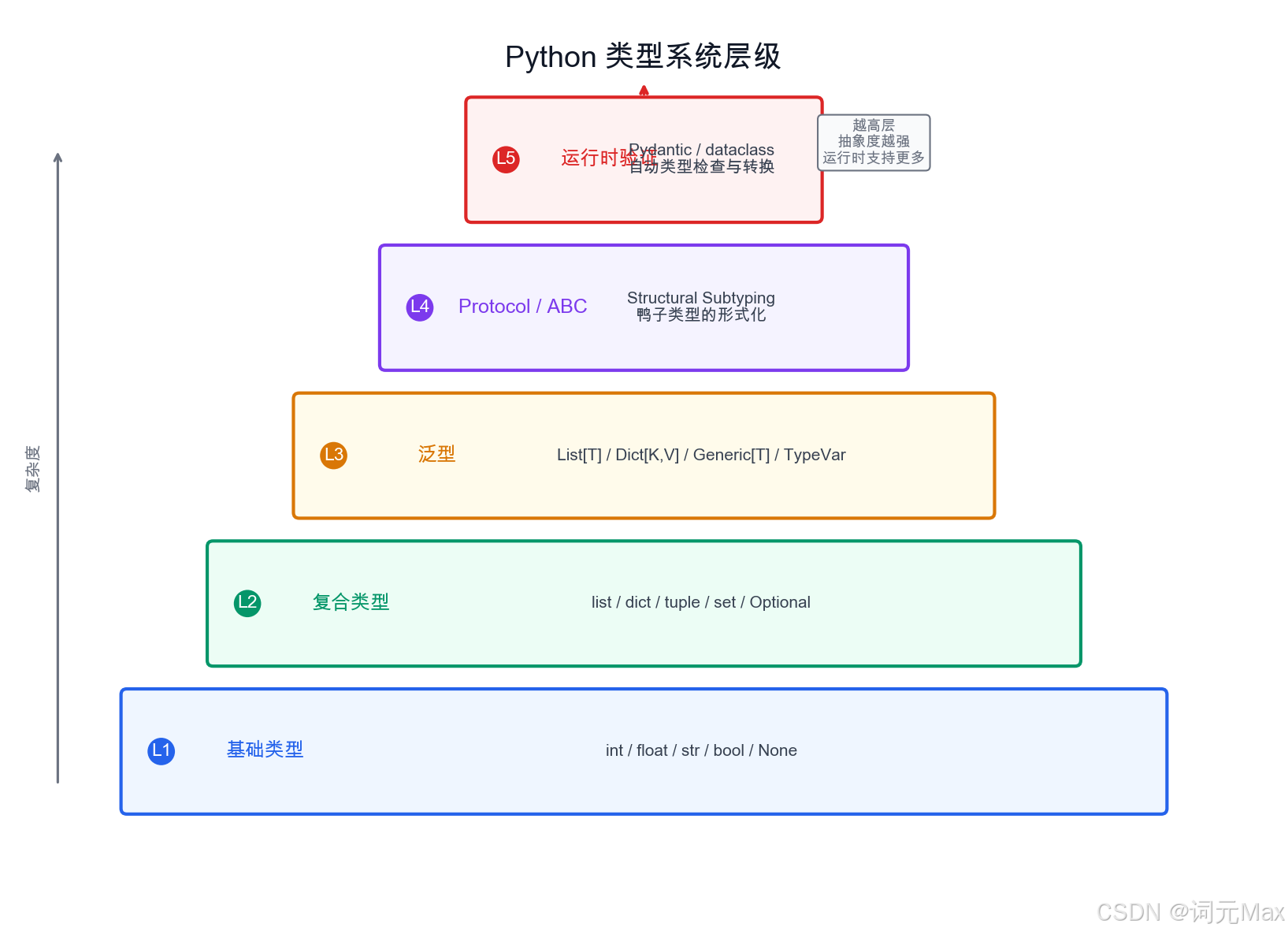
Python 类型系统从基础类型到运行时验证的五个层级
不是所有 Python 项目都需要严格的类型注解,但 AI 项目特别需要。有三个根本原因:
原因一:AI 框架深度依赖类型注解
LangChain、FastAPI、pydantic 这三个 AI 开发的核心库,都把类型注解作为功能实现的基础,而不仅仅是文档用途。
原因二:LLM 输出不稳定,需要在入口做类型约束
LLM 返回的 JSON 字段名可能变化,数值可能以字符串形式出现。没有类型约束,这类错误会在深层业务逻辑中以 KeyError 或 AttributeError 爆发,很难追踪到根源。
原因三:Java 背景工程师写 Python 更需要类型注解
习惯了 Java 强类型的工程师,在 Python 里失去了编译器的保护,类型注解是最接近 Java 体验的替代方案。
1.1.1 三大框架如何依赖类型注解
pydantic 依赖类型注解定义数据结构:
python
from pydantic import BaseModel
class ChatMessage(BaseModel):
role: str
content: str
tokens: int = 0
# pydantic 读取字段的类型注解,自动做类型转换和验证
# 传字符串 "42" 给 tokens 字段,pydantic 自动转成整数 42
msg = ChatMessage(role="user", content="你好", tokens="42")
print(msg.tokens) # 42(int,不是字符串)
print(type(msg.tokens)) # <class 'int'>FastAPI 依赖类型注解生成 API 文档:
python
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class ChatRequest(BaseModel):
message: str
temperature: float = 0.7
@app.post("/chat")
async def chat(request: ChatRequest) -> dict:
# FastAPI 从 ChatRequest 的类型注解自动生成 OpenAPI schema
# /docs 页面的交互式文档就自动生成了,无需手写
return {"response": "..."}LangChain 的工具参数 schema 从类型注解生成:
python
from langchain.tools import tool
@tool
def search(query: str, max_results: int = 5) -> list[str]:
"""搜索网页内容。"""
...
# LangChain 通过函数的类型注解生成工具的 JSON Schema:
# {
# "name": "search",
# "parameters": {
# "query": {"type": "string"},
# "max_results": {"type": "integer", "default": 5}
# }
# }
# 没有类型注解,LLM 就不知道该怎么调用这个工具1.2 与 Java 强类型的对比
Java 工程师转 Python,在类型系统上最大的认知转变是:从"类型是强制的"到"类型是可选的文档"。
| 维度 | Java | Python |
|---|---|---|
| 类型声明 | 编译期强制 | 可选(Type Hints) |
| 类型检查时机 | 编译期 | 运行时(或 mypy 检查期) |
| 类型错误后果 | 无法编译 | 运行时报错 |
| 类型转换 | 显式转换,失败报错 | pydantic 自动转换 |
| IDE 支持 | 完整 | 有 Type Hints 才完整 |
| 空值类型 | @Nullable / Optional<T> |
`str |
| 泛型 | List<String>, Map<K, V> |
list[str], dict[K, V] |
Java 的 Optional vs Python 的 Optional/Union:
java
// Java
Optional<String> findUser(int id) {
if (exists(id)) return Optional.of(getUser(id));
return Optional.empty();
}
python
# Python(三种等价写法)
def find_user(user_id: int) -> str | None: # 推荐(Python 3.10+)
if exists(user_id):
return get_user(user_id)
return None
def find_user(user_id: int) -> Optional[str]: # 旧写法
...
# Python 不需要 Optional.of() 包装,直接返回值或 None1.3 基础类型注解
Python 内置类型直接用:
python
def process(
user_id: int,
name: str,
score: float,
active: bool
) -> None:
pass
# 变量注解
count: int = 0
names: list[str] = []
config: dict[str, str] = {}Optional 表示可以是某个类型,也可以是 None:
python
from typing import Optional
def find_user(user_id: int) -> Optional[str]:
# 可能返回用户名,也可能返回 None
...
# Python 3.10+ 的新写法(推荐)
def find_user(user_id: int) -> str | None:
...Union 表示可以是多种类型之一:
python
from typing import Union
def parse_id(raw: Union[str, int]) -> int:
if isinstance(raw, str):
return int(raw)
return raw
# Python 3.10+ 的新写法
def parse_id(raw: str | int) -> int:
...Any 表示不限制类型,相当于关掉类型检查------能不用就不用:
python
from typing import Any
def process_raw(data: Any) -> Any:
# 不推荐,除非真的不确定类型
# 如果用了 Any,mypy 不会对这个函数报告类型错误
...1.4 复杂类型
集合类型需要指定元素类型:
python
from typing import Callable
def analyze_texts(texts: list[str]) -> dict[str, int]:
return {text: len(text) for text in texts}
def get_range() -> tuple[int, int]:
return (0, 100)
# Callable[[参数类型列表], 返回值类型]
# 对应 Java 的函数式接口,如 Function<Integer, String>
def apply_transform(data: list[int], transform: Callable[[int], str]) -> list[str]:
return [transform(x) for x in data]
# 用法
result = apply_transform([1, 2, 3], lambda x: f"item_{x}")
# 预期输出:["item_1", "item_2", "item_3"]1.5 Python 3.10+ 的新语法
Python 3.10 开始,类型注解的语法大幅简化。
用 | 替代 Union 和 Optional:
python
# 旧写法(Python 3.8)
from typing import Optional, Union
def old_func(x: Optional[str]) -> Union[int, str]:
...
# 新写法(Python 3.10+,推荐)
def new_func(x: str | None) -> int | str:
...用小写内置类型替代 typing 里的泛型:
python
# 旧写法(Python 3.8)
from typing import List, Dict, Tuple, Set
def old_func(items: List[str]) -> Dict[str, int]:
...
# 新写法(Python 3.9+,推荐)
def new_func(items: list[str]) -> dict[str, int]:
...新项目直接用新语法,更简洁。老项目里两种写法混用,不需要强行统一。
1.6 TypedDict:给字典加类型
Python 的字典是最灵活的数据结构,但也是类型检查的死角。TypedDict(有类型约束的字典,明确声明每个键对应的值类型)可以给字典的键值对加类型约束。
LangGraph 的 State 就是用 TypedDict 定义的,这是 AI 开发里最常见的用法:
python
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
# messages 是消息列表,add_messages 是 reducer 函数
# Annotated 允许附加额外信息给类型检查器
messages: Annotated[list, add_messages]
# 当前步骤
current_step: str
# 是否需要调用工具
needs_tool_call: bool
# 工具调用结果
tool_results: list[dict]
# 最终回答
final_answer: str | None用 TypedDict 定义 State,LangGraph 知道每个字段的类型,IDE 也能给出准确的代码提示。访问 state["messages"] 时,IDE 知道这是 list 类型,访问 state["nonexistent"] 时,mypy 会直接报错。
TypedDict 还支持 total=False,表示所有字段都是可选的:
python
class PartialConfig(TypedDict, total=False):
temperature: float
max_tokens: int
model: str
# 可以只传部分字段
config: PartialConfig = {"temperature": 0.7} # 合法对比 Java 的 Map 和 POJO:
java
// Java 中用 Map 的痛苦:无类型提示,可能有任意 key
Map<String, Object> state = new HashMap<>();
state.put("messages", new ArrayList<>());
String step = (String) state.get("current_step"); // 需要强制转换
// Java 中 POJO 的繁琐:需要定义类、getter/setter
class AgentState {
private List<Message> messages;
private String currentStep;
// ...getter/setter...
}Python 的 TypedDict 结合了两者优点:字典的简洁 + 类型约束的安全。
1.7 Protocol:鸭子类型的类型安全版本
Java 通过接口(interface)约束类型。Python 有 Protocol(协议,一种灵活的接口约束方式),作用类似但更灵活------不需要显式继承,只要实现了对应的方法,就算是这个 Protocol 的子类型。这种方式叫"鸭子类型"(看起来像鸭子、叫声像鸭子,就当它是鸭子------只要有所需的方法,就认为满足该接口)。
python
from typing import Protocol
class Runnable(Protocol):
"""LangChain 最核心的抽象接口"""
def invoke(self, input: dict) -> dict:
...
def stream(self, input: dict):
...
# 任何有 invoke 和 stream 方法的类,都自动满足 Runnable Protocol
class MyChain:
def invoke(self, input: dict) -> dict:
return {"result": "..."}
def stream(self, input: dict):
yield {"chunk": "..."}
def run_chain(chain: Runnable, input: dict) -> dict:
return chain.invoke(input)
# MyChain 没有继承 Runnable,但 mypy 认为它满足 Runnable 协议
run_chain(MyChain(), {"question": "什么是 Agent"})与 Java 接口的对比:
java
// Java:必须显式声明 implements
interface Runnable {
Map<String, Object> invoke(Map<String, Object> input);
}
class MyChain implements Runnable { // 必须显式 implements
@Override
public Map<String, Object> invoke(Map<String, Object> input) {
return new HashMap<>();
}
}Python Protocol 更灵活:第三方库的类,即使没有你的代码,只要实现了方法就满足协议。这对于 AI 框架的扩展点设计非常有用。
1.8 运行时类型检查:pydantic BaseModel
类型注解只是注解,Python 运行时默认不做任何检查。如果需要运行时的类型验证,pydantic 是最好的选择。
python
from pydantic import BaseModel, Field, field_validator
from typing import Literal
class LLMConfig(BaseModel):
model: str = Field(description="模型名称")
temperature: float = Field(default=0.7, ge=0.0, le=2.0) # ge: >=, le: <=
max_tokens: int = Field(default=1000, gt=0)
provider: Literal["openai", "anthropic", "zhipu"] = "openai"
@field_validator("model")
@classmethod
def validate_model(cls, v: str) -> str:
# 自定义验证逻辑,类似 Java 的 @AssertTrue
if not v.strip():
raise ValueError("model 不能为空")
return v.strip()
# 正常创建
config = LLMConfig(model="gpt-4o", temperature=0.5)
print(config.model) # gpt-4o
print(config.max_tokens) # 1000(默认值)
# 类型转换:传字符串会自动转为 float
config2 = LLMConfig(model="gpt-4o", temperature="0.8")
print(type(config2.temperature)) # <class 'float'>
# 验证失败:temperature 超出范围
try:
bad_config = LLMConfig(model="gpt-4o", temperature=3.0)
except Exception as e:
print(e)
# 预期输出:temperature: Input should be less than or equal to 2pydantic 的好处不只是验证,还有序列化:
python
# 转成 dict(类似 Java 对象的 toMap())
config.model_dump()
# 预期输出:{'model': 'gpt-4o', 'temperature': 0.5, 'max_tokens': 1000, 'provider': 'openai'}
# 转成 JSON(类似 Jackson 的 writeValueAsString)
config.model_dump_json()
# 预期输出:{"model":"gpt-4o","temperature":0.5,"max_tokens":1000,"provider":"openai"}1.9 mypy 静态检查:在 CI 里跑
mypy 是 Python 最主流的静态类型检查工具。它读取类型注解,不运行代码,只做类型推断,发现类型不匹配的问题。
在项目根目录创建 mypy.ini:
ini
[mypy]
python_version = 3.11
strict = false ; 不开最严格模式,逐步迁移
ignore_missing_imports = true
; 对自己的代码严格检查
[mypy-src.*]
disallow_untyped_defs = true ; 所有函数必须有类型注解
warn_return_any = true ; 警告返回 Any 类型
warn_unused_ignores = true
; 对第三方库宽松处理
[mypy-langchain.*]
ignore_missing_imports = true常见的 mypy 错误类型:
python
def get_name() -> str:
user = find_user(42) # find_user 返回 Optional[str]
return user # 错误:Optional[str] 不能赋值给 str
# 正确写法:
# if user is None:
# return ""
# return user建议在 CI(Continuous Integration,持续集成,每次提交代码时自动运行测试和检查的流程)里加一步 mypy 检查,防止类型问题进入主分支:
yaml
# .github/workflows/ci.yml
- name: Type check
run: mypy src/1.10 完整示例:LangGraph State 定义
把上面的内容整合起来,写一个完整的 LangGraph workflow State:
python
from __future__ import annotations
from typing import TypedDict, Annotated, Literal
from langgraph.graph.message import add_messages
from pydantic import BaseModel
# 工具调用结果的结构(pydantic,有运行时校验)
class ToolResult(BaseModel):
tool_name: str
tool_input: dict
output: str
error: str | None = None
success: bool = True
# LangGraph State(TypedDict,提供 IDE 类型提示)
class ResearchState(TypedDict):
# 对话消息列表,add_messages 是内置的 reducer,会自动合并消息
messages: Annotated[list, add_messages]
# 用户原始问题
question: str
# 当前工作流阶段
phase: Literal["planning", "research", "synthesis", "done"]
# 搜索关键词列表
search_queries: list[str]
# 工具调用记录
tool_results: list[ToolResult]
# 已收集的参考资料
references: list[str]
# 最终报告
final_report: str | None
# 错误信息(如果有)
error: str | None
def create_initial_state(question: str) -> ResearchState:
"""创建初始 State,所有字段类型清晰。"""
return ResearchState(
messages=[],
question=question,
phase="planning",
search_queries=[],
tool_results=[],
references=[],
final_report=None,
error=None,
)
# 使用示例
if __name__ == "__main__":
state = create_initial_state("Python 和 Java 的类型系统有什么区别?")
# IDE 能准确提示 state 的每个字段类型
print(state["question"]) # str
print(state["phase"]) # Literal["planning", "research", "synthesis", "done"]
print(state["messages"]) # list
# 添加工具调用结果
result = ToolResult(
tool_name="search_web",
tool_input={"query": "Python type hints"},
output="Python 3.5 引入了类型注解...",
)
state["tool_results"].append(result)
print(f"工具调用记录:{len(state['tool_results'])} 条")
# 预期输出:
# Python 和 Java 的类型系统有什么区别?
# planning
# []
# 工具调用记录:1 条1.11 小结
| 特性 | Java | Python |
|---|---|---|
| 类型声明必须性 | 强制 | 可选(但 AI 项目强烈推荐) |
| 静态检查工具 | 编译器 | mypy / pyright |
| 运行时校验 | Bean Validation + AOP | pydantic |
| 接口约束 | interface + implements |
Protocol(结构性子类型) |
| 字典类型约束 | POJO 或 Map(无法约束 key) | TypedDict |
| 空值类型 | @Nullable, Optional<T> |
`str |
类型注解在 AI 开发里几乎是强制的。pydantic 要靠它做运行时验证,FastAPI 要靠它生成文档,LangChain 要靠它生成工具 schema,LangGraph 要靠它定义 State 结构。
有 Java 背景的开发者在这一点上有天然优势:已经习惯了类型约束,不会觉得"写类型注解很麻烦"。需要额外掌握的是 Python 类型系统的特有概念------TypedDict、Protocol、Annotated------这些没有直接对应的 Java 概念,需要实际写代码才能熟练。