标签:AI编程, 开发效率, 最佳实践, 前后端协作, 工程化
摘要
本文基于工业Web应用项目的AI协作开发实践,主要以Qoder为开发工具,系统总结了一套可复用的开发方法论。通过实施验证前置、契约先行、最小工作单位、经验固化四大核心策略,将AI协作开发的有效产出率从约25%提升至50%以上。文章涵盖开发阶段规范、任务管理策略、AI工具使用规范等完整实践体系,并附可直接落地的检查清单和代码示例。
关键词:AI协作开发、开发效率、API契约、任务拆分、经验固化
一、背景与问题分析
1.1 效率损耗现状
基于个人项目回顾估算,AI协作开发的时间分布如下:
| 活动类型 | 时间占比 | 性质 |
|---|---|---|
| 同类问题反复修复 | 30% | 浪费 |
| 需求多轮澄清 | 20% | 可优化 |
| 重构后回归修复 | 15% | 可避免 |
| 契约对齐返工 | 10% | 可避免 |
| 有效开发产出 | 25% | 价值 |
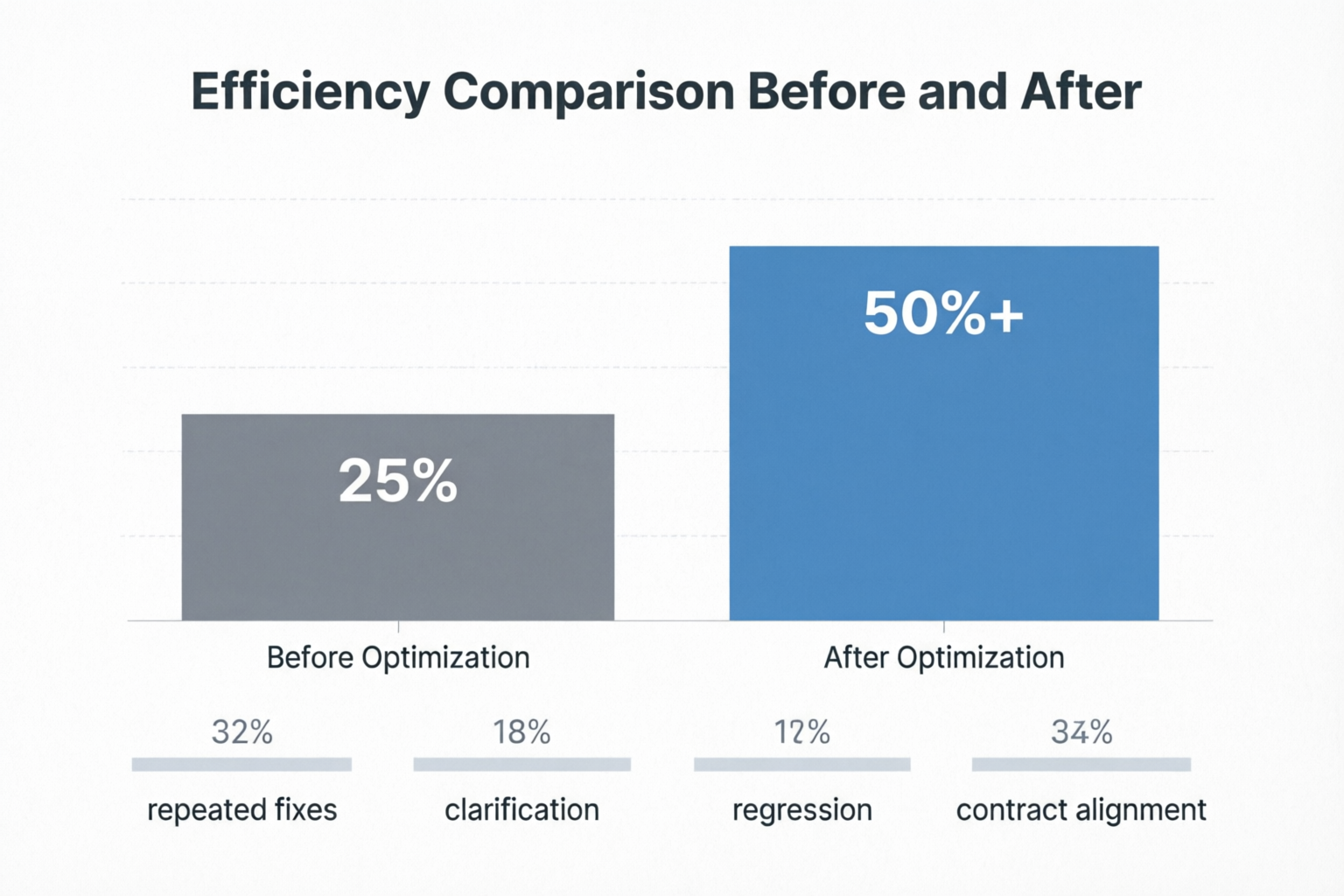
核心洞察:损耗率约75%,主要源于缺乏系统化的协作规范。
1.2 高频问题根因分析
| 问题 | 出现次数 | 根因 | 解决方案 |
|---|---|---|---|
API路径缺少 /v1/ |
5+ | 契约未先行 | 写入强制检查项 |
axios响应 response.data.data 解析错误 |
4+ | 响应格式未约定 | 统一解析函数 |
| 前端字段命名不一致 | 3+ | 命名转换未在API层处理 | API契约先行 |
!value 误判 ID=0 |
2+ | 边界值处理不当 | 使用 == null |
二、核心理念
2.1 两大核心原则
原则一:AI协作的重要核心,就是形成自动测试验证的闭环流程,反复迭代
原则二:最小工作单位原则
└── 随着任务进行,上下文会逐渐增多,模型会压缩上下文
└── 要建立最小工作单位,在这个单位内细致到每个代码
└── 不要让每次都从顶层进行任务理解2.2 五大效率杠杆

| 杠杆 | 原则 | 预期收益 |
|---|---|---|
| 验证前置 | 问题在AI侧发现 | 减少50%返工 |
| 契约先行 | 并行任务共享契约 | 消除联调失败 |
| 经验固化 | 已知问题不再复现 | 减少35%重复Bug |
| 最小单位 | 聚焦小任务执行 | 避免上下文衰减 |
| 回归保护 | 重构不破坏功能 | 消除关联Bug |
三、开发阶段规范
3.1 前期规划:详细规划 + 契约先行
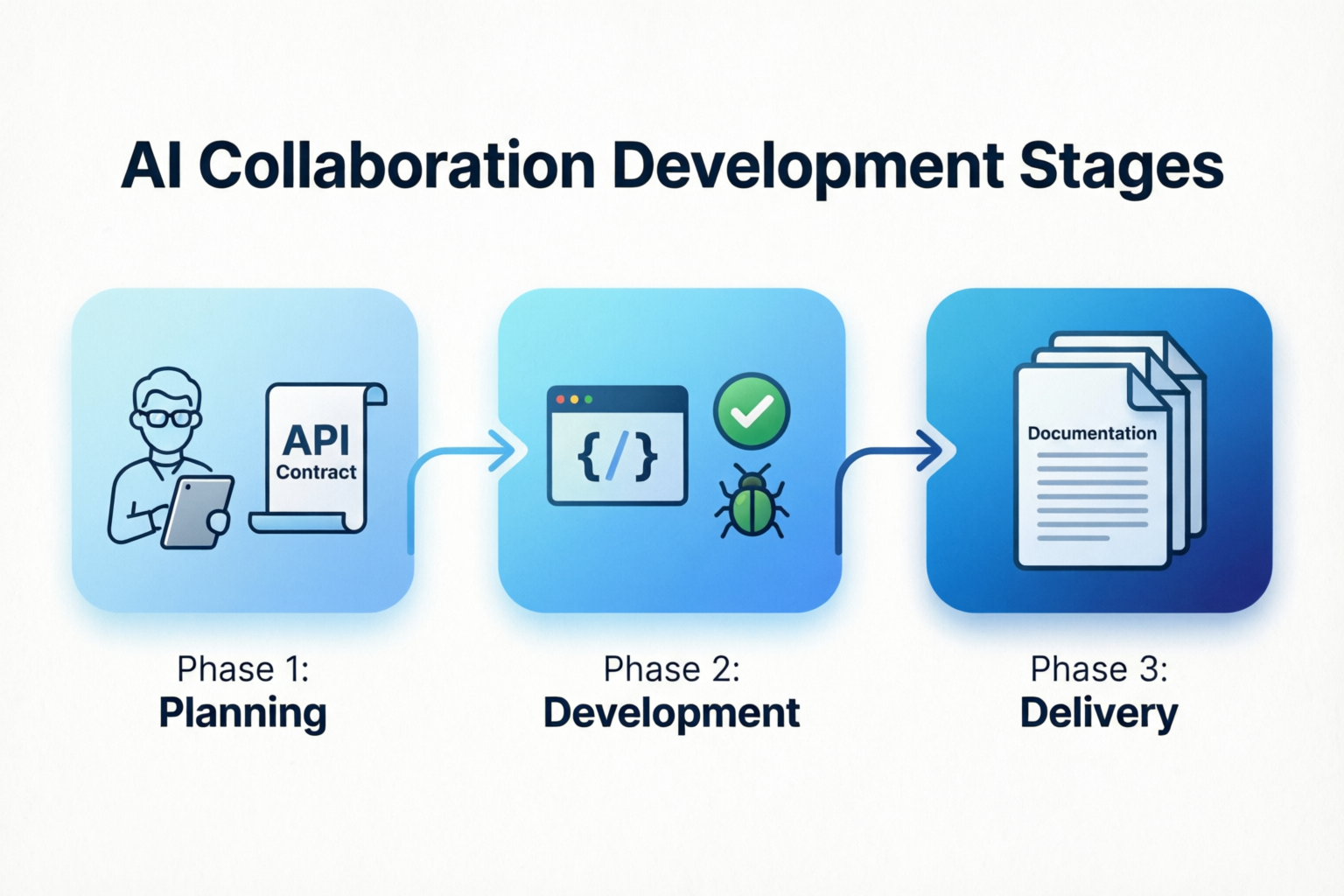
产品经理 ─┬─→ 前端规划
└─→ 后端规划 ─→ 架构师评审
↓
功能开发清单(统一)
↓
API契约文档(并行开发前必须完成)关键动作:
- 使用统一的功能开发清单
- 前后端并行开发前,先定义API契约
- 及时搭建编译、测试、清理等关键脚本
- 尽早生成日志,方便AI自行定位问题
3.2 中期验收:测试 + Bug表 + 验证闭环
开发完成 → 功能验证 → Bug记录 → 修复 → 再验证 → 归档
↓
使用 1bug.md 拆分任务
↓
完成后归档,再新建任务关键动作:
- 采用测试 + Bug表更新形式
- 使用
1bug.md将任务拆分成小块执行 - 可通过md文件大小判断是否需要拆分
- 完成后归档,再新建任务
3.3 后期收尾:代码与文档同步
- 同步代码与文档,方便快速检索和特定修改
- 沉淀本次开发的经验到记忆系统
- 更新功能清单和API文档
四、任务管理策略
4.1 最小工作单位原则
核心洞察:
随着任务进行,上下文会逐渐增多,模型会对上下文压缩。要建立最小工作单位原则,在这个单位内细致到每个代码,不要让最小单位每次都从顶层进行任务理解------上下文窗口不够,聚焦在小单位进行。
实施建议:
- 建议单任务聚焦少量文件修改(通常不超过3个)
- 单Bug修复作为一个独立单位
- 复杂任务拆分为多个小单位依次执行
- 可通过md文件大小判断是否需要进一步拆分
4.2 任务拆分模式(1bug.md模式)
大任务
↓
拆分为多个 1bug.md
↓
┌─────────────────────┐
│ 1bug.md │
│ - Bug描述 │
│ - 定位分析 │
│ - 修复方案 │
│ - 验证结果 │
│ - 状态:完成/归档 │
└─────────────────────┘
↓
完成后归档,新建下一个4.3 模块与构件的分解策略
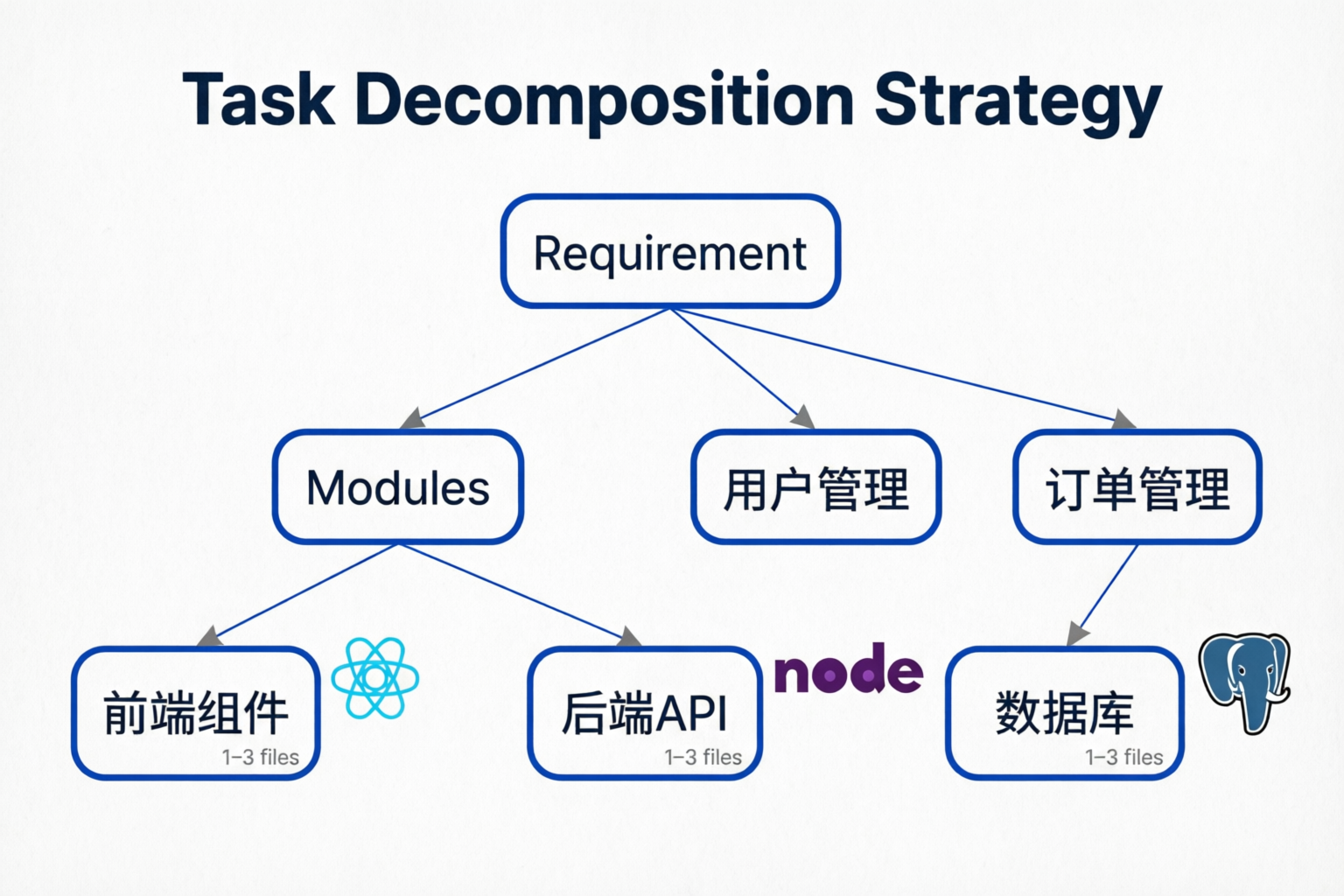
4.3.1 概念区分
| 维度 | 模块(Module) | 构件(Component) |
|---|---|---|
| 定义 | 按功能边界划分的独立单元 | 按技术栈划分的实现单元 |
| 划分依据 | 业务功能、领域边界 | 技术栈、代码层级 |
| 示例 | 用户管理模块、订单模块 | 前端组件、后端Controller、数据库表 |
| 粒度 | 较粗,一个模块可含多个构件 | 较细,单个技术实现单元 |
| 边界 | 跨技术栈 | 单一技术栈 |
4.3.2 分解示例
用户管理模块
├── 构件1:前端用户列表页面(Vue组件)
├── 构件2:后端用户API(Controller + Service)
├── 构件3:数据库用户表(Entity + Repository)
└── 构件4:用户认证逻辑(安全模块)
每个构件任务:聚焦1-3个文件修改4.3.3 分解决策树
收到需求
↓
识别涉及的模块(业务边界)
↓
定义模块间契约(API接口)
↓
每个模块拆分为构件任务:
├── 前端构件任务 → 1-3个Vue/TS文件
├── 后端构件任务 → 1-3个Controller/Service文件
└── 数据库构件任务 → 1-2个Entity/Repository文件
↓
按构件任务执行,每完成一个验证一个
↓
集成验证五、AI工具使用规范
5.1 AI交互手段总览
与AI Agent的交互手段共10种,分为四类:
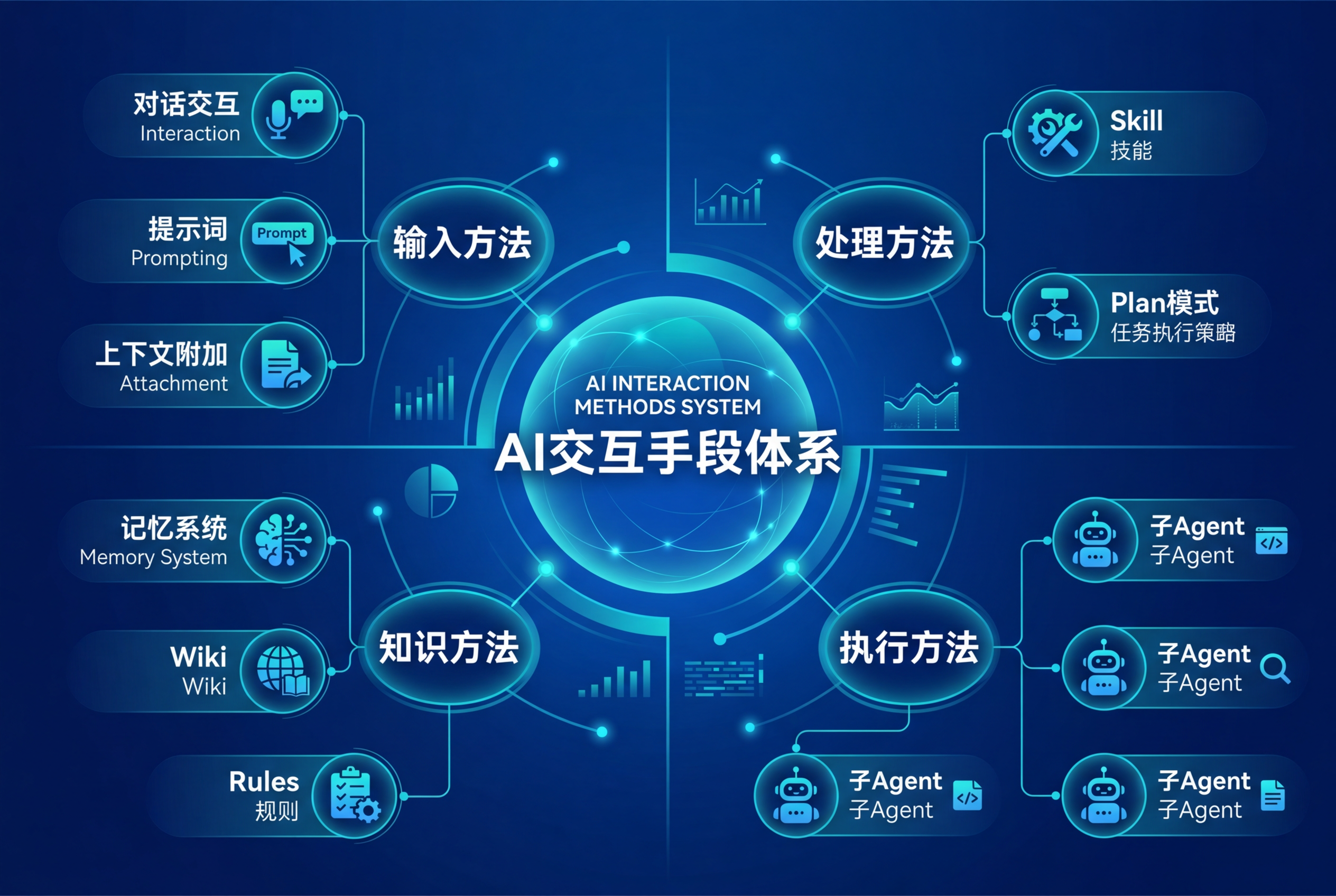
┌─────────────────────────────────────────────────────────────┐
│ AI交互手段体系 │
├──────────────────────────────────────────────────────────────┤
│ 【输入类】 │
│ ├── 对话交互 - 最基础的交互方式 │
│ ├── 提示词 - 嵌入指令引导AI行为 │
│ └── 上下文附加 - attached_files、selected_codes等 │
│ │
│ 【流程类】 │
│ ├── Skill - 封装好的可复用工作流程 │
│ └── Plan模式 - 复杂任务的规划模式 │
│ │
│ 【执行类】 │
│ └── 子Agent(专家)- 专门化的子代理 │
│ │
│ 【知识类】 │
│ ├── 记忆系统 - 存储和检索动态经验 │
│ ├── Wiki/文档 - 项目知识库 │
│ └── Rules - 项目规则配置,自动注入上下文 │
│ │
│ 【管理类】 │
│ └── Todo管理 - 任务跟踪和进度管理 │
└─────────────────────────────────────────────────────────────┘5.2 小型全栈项目专家配置
| 专家 | 能力范围 | 推荐等级 | 理由 |
|---|---|---|---|
| frontend-expert | Vue/React + TypeScript + UI框架 | ⭐⭐⭐ 必要 | 前端开发频率高,专注提升质量 |
| backend-expert | 后端框架 + API + 数据库 | ⭐⭐ 推荐 | 后端开发频率高,主AI可兜底但专家更专业 |
| algorithm-expert | 核心业务算法 | ⭐ 按需 | 仅当项目有复杂业务算法时配置 |
专家调用决策:
| 任务类型 | 推荐方案 | 调用时机 |
|---|---|---|
| 纯前端开发 | frontend-expert | 涉及Vue/React/TS/组件开发 |
| 纯后端开发 | backend-expert 或 主AI | 涉及API/数据库/业务逻辑 |
| 架构决策 | 主AI + Plan模式 | 技术选型、模块划分 |
| Bug修复 | 先定位 → 对应专家或主AI | 确定Bug位置后 |
5.3 记忆系统使用规范
5.3.1 记忆类别
| 类别 | 用途 | 典型内容 |
|---|---|---|
common_pitfalls_experience |
常见陷阱 | axios解析错误、API路径问题、状态判断错误 |
task_flow_experience |
历史流程 | Bug修复流程、功能开发流程、重构流程 |
task_summary_experience |
任务总结 | 每次任务的关键经验和教训 |
important_decision_experience |
重要决策 | 架构决策、技术选型、流程规范 |
5.3.2 记忆触发三层体系
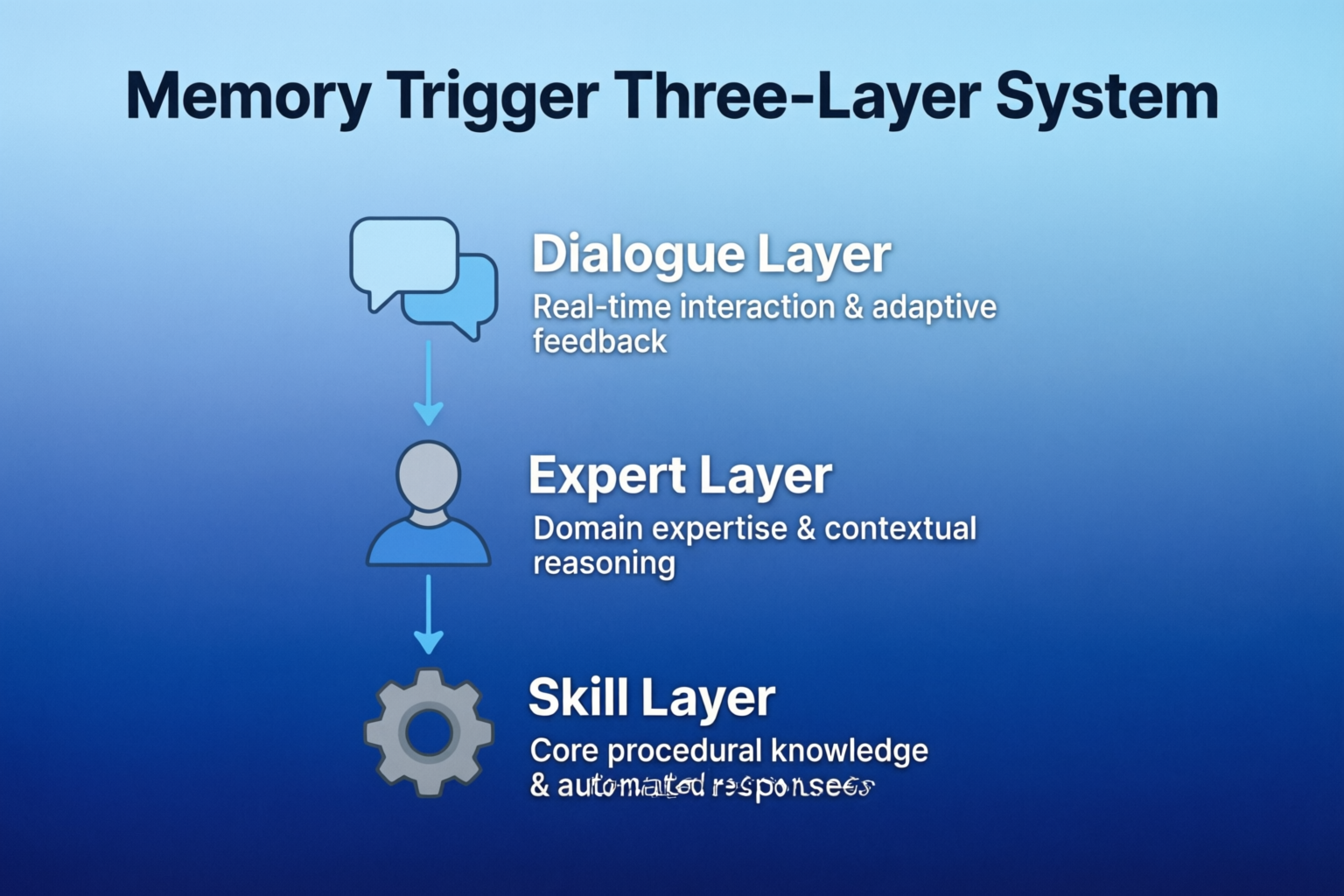
┌─────────────────────────────────────────────────────────────┐
│ 记忆触发三层体系
├─────────────────────────────────────────────────────────────┤
│ Layer 1: Skill层(流程标准化)
│ ├── Skill定义记忆检索+沉淀的流程模板
│ ├── 主AI按Skill流程执行记忆操作
│ └── 适用:高频重复任务(Bug修复、API对接、重构)
│
│ Layer 2: 专家层(提示词引导)
│ ├── 专家提示词中嵌入记忆检索指令
│ ├── 主AI/专家按提示词执行记忆操作
│ └── 适用:专家独立执行的任务
│
│ Layer 3: 对话层(灵活触发)
│ ├── 用户显式触发或AI自主识别
│ ├── 适用:临时性、非标准化任务
│ └── 特点:灵活但依赖意识
└─────────────────────────────────────────────────────────────┘
5.3.3 记忆检索决策矩阵
| 任务类型 | 推荐触发层 | 检索类别 | 检索深度 |
|---|---|---|---|
| Bug修复 | Skill层 | common_pitfalls + task_flow | deep |
| 前端开发 | 专家层 | common_pitfalls | shallow |
| 重构任务 | Skill层 | task_flow + task_summary | deep |
| 新功能 | 对话层 | expert_experience | shallow |
5.4 Plan模式使用规范
5.4.1 Plan触发决策树
收到任务后评估:
│
├── 任务影响范围 > 3个文件?
│ └── 是 → 进入Plan模式
│
├── 任务有多个可选方案?
│ └── 是 → 进入Plan模式(需要方案对比)
│
├── 任务涉及架构变更?
│ └── 是 → 进入Plan模式(需要评审)
│
├── 任务预计 > 30分钟?
│ └── 是 → 进入Plan模式(需要拆分步骤)
│
└── 以上都不满足
└── 直接执行5.4.2 Plan内容模板
Plan: 任务名称
1. 目标定义
- 用户需求:原文引用
- AI理解:复述确认,确保理解一致
- 验收标准:可验证的完成条件
2. 方案选择(如有多方案)
方案 描述 优点 缺点 A ... ... ...
- 选择:方案X
- 理由:...
3. 执行步骤
步骤 动作 预期结果 验证方法 风险 1 ... ... ... ... 2 ... ... ... ... 4. 验证计划
- 编译检查
- 功能验证
- 回归检查
5. 回滚方案
- 触发条件:什么情况下回滚
- 回滚步骤:如何恢复
5.5 Rules规则配置
Rules是项目级规则配置,存储在 .qoder/rules 目录,自动注入到AI提示词中。
建议配置的Rules:
| Rule名称 | 类型 | 内容要点 |
|---|---|---|
coding-style |
Always Apply | 编码风格、命名规范 |
api-convention |
Always Apply | API路径、响应格式约定 |
vue-rules |
Specific Files (*.vue) | Vue组件规范 |
示例配置 (api-convention.md):
API约定规则
- API路径必须使用
/api/v1/前缀 - axios响应必须使用
response.data.data - 状态判断使用
=== null而非!value - 前后端字段命名转换在API层处理
六、沟通效率优化
6.1 问题描述规范
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 前端报错 | 截图 > 语言描述 | 截图包含完整上下文,语言描述效率低 |
| 后端报错 | 日志 + 请求/响应截图 | 结构化信息便于AI定位 |
| 功能问题 | 操作步骤 + 预期 + 实际 | 可复现性强 |
6.2 上下文附加最佳实践
| 方式 | 信息完整度 | AI理解效率 | 适用场景 |
|---|---|---|---|
| 截图 | 高 | 高 | 前端问题、UI问题 |
| selected_codes | 精确 | 高 | 代码修改、重构 |
| attached_files | 完整 | 中 | 需要完整上下文 |
| 语言描述 | 低 | 低 | 简单问题 |
关键原则 :截图/选中代码 > 语言描述
七、检查清单
7.1 基础检查
- 代码编译/构建成功
- 无 TypeScript/ESLint 错误
- 无控制台报错
7.2 功能验证(验证前置)
- 核心功能可执行
- 关键路径无报错
- 状态变量正确更新
- UI正确展示结果
7.3 契约对齐
- API路径含 /v1/ 前缀
- 响应正确解析(注意 data.data)
- 字段命名转换正确
7.4 回归检查
- 本次修改未破坏现有功能
7.5 已固化规则(强制执行)
- API路径必须使用
/v1/前缀 - axios响应必须正确解析(
response.data.data) - 状态判断使用
=== null而非!value - 前后端字段命名转换在API层处理
八、度量与持续优化
8.1 关键指标
| 指标 | 当前 | 目标 |
|---|---|---|
| 同类问题复现率 | 4+次 | <1次 |
| 契约对齐失败率 | 30%+ | <5% |
| 验证前置执行率 | 20% | 90% |
8.2 每周回顾清单
- 本周有哪些"已知问题"再次出现?
- 本周有哪些任务可以用Skill但没用?
- 本周有哪些联调失败是契约问题?
- 最小工作单位原则是否被遵守?
8.3 改进优先级
| 优先级 | 改进项 |
|---|---|
| 立即 | 验证前置(使用检查清单) |
| 立即 | 任务启动时检索记忆 |
| 短期 | 创建backend-expert |
| 短期 | 建立API契约模板 |
| 中期 | 完善Wiki作为专家上下文入口 |
九、总结
9.1 最重要的三个洞察
- 自动测试验证闭环是AI协作的核心,反复迭代
- 最小工作单位原则解决上下文衰减问题
- 截图 > 语言描述减少沟通损耗
9.2 一句话总结
验证前置 + 契约先行 + 最小工作单位 + 经验固化 = 高效AI协作
附录:文档维护
| 版本 | 日期 | 变更内容 |
|---|---|---|
| v1.0 | 2026-03-24 | 整合诊断报告与实践经验总结 |
| v2.0 | 2026-03-26 | 全面修订,增加交互手段体系、Rules配置、上下文机制 |
本指南基于个人经验总结,部分技巧需要与Qoder工具绑定,大部分理论通用。欢迎交流讨论。