系列:《AI Agent 从原理到实战 ------ 解密 Claude Code 背后的工程智慧》 第2篇
引言
上一篇我们说到,AI Agent 的智能来自模型本身,而程序员的角色是造"车"(Harness)。但在讨论这辆车的具体构造之前,有一个更基础的问题要回答:Agent 和普通的 LLM 对话到底区别在哪?
你用 ChatGPT 的日常体验是这样的:你问一句,它答一句。你再问,它再答。每一轮对话都是你发起的。模型永远在"等你"。
但 Agent 不一样。你说一句话之后,它可能自己忙活了十分钟,中间调用了二十个工具,最后才回来跟你说"搞定了"。
这两者之间的鸿沟,其实只隔着一个东西------一个 while 循环。
Agent Loop:可能是软件史上最重要的 while 循环
先说结论。Agent 的最小结构可以用几行伪代码表达:
javascript
while (true) {
const response = await model.chat(messages);
if (!response.hasToolCall) {
return response; // 模型觉得做完了,返回给用户
}
// 模型调用了工具,执行它
const toolResult = await execute(response.toolCall);
// 把工具结果加入对话历史,让模型继续思考
messages.push(toolResult);
}就这么多。这就是所谓的 Agent Loop(代理循环)。

拆开来看:
- 把对话发给模型,让它思考该做什么
- 检查模型的回复------它是直接给了文字答案,还是要求调用某个工具?
- 如果是文字答案,说明模型认为任务完成了,把答案返回给用户,循环结束
- 如果是工具调用,执行这个工具,把执行结果塞回对话历史,回到第1步
核心思想很简单:让模型自己决定什么时候"再做一步",什么时候"到此为止"。
一个具体的例子
光看伪代码可能还是抽象,用一个真实场景走一遍。
假设你打开 Claude Code,对它说:
"帮我看看这个项目里有没有 bug"
接下来发生的事情是这样的:

整个过程中模型的回复:
"我检查了项目代码,发现并修复了两个问题: 1. main.py 中的 SQL 查询存在注入风险,已改为参数化查询 2. db.py 中事务异常处理缺少回滚,已补充 rollback 逻辑 所有 15 个测试均已通过。"
整个过程中,你只说了一句话。模型自己走了八步。每一步都是它自己判断的------读什么文件、改什么代码、什么时候跑测试、测试失败了怎么办。
这就是 Agent Loop 的威力。
为什么这个循环如此重要
你可能会想:就一个 while 循环,有这么了不起吗?
了不起的地方在于,它改变了控制权的归属。
在传统软件里,控制权在程序员手里。程序走哪条分支、调用什么函数、执行什么顺序,全是代码写死的。用户按下按钮,程序做预设的事。
在普通的 LLM 对话里,控制权在用户手里。每一轮都是用户发起的,模型只是响应。
而在 Agent Loop 里,控制权交给了模型。 模型自己决定下一步做什么,自己决定什么时候结束。程序员不预设流程,用户不需要逐步引导。
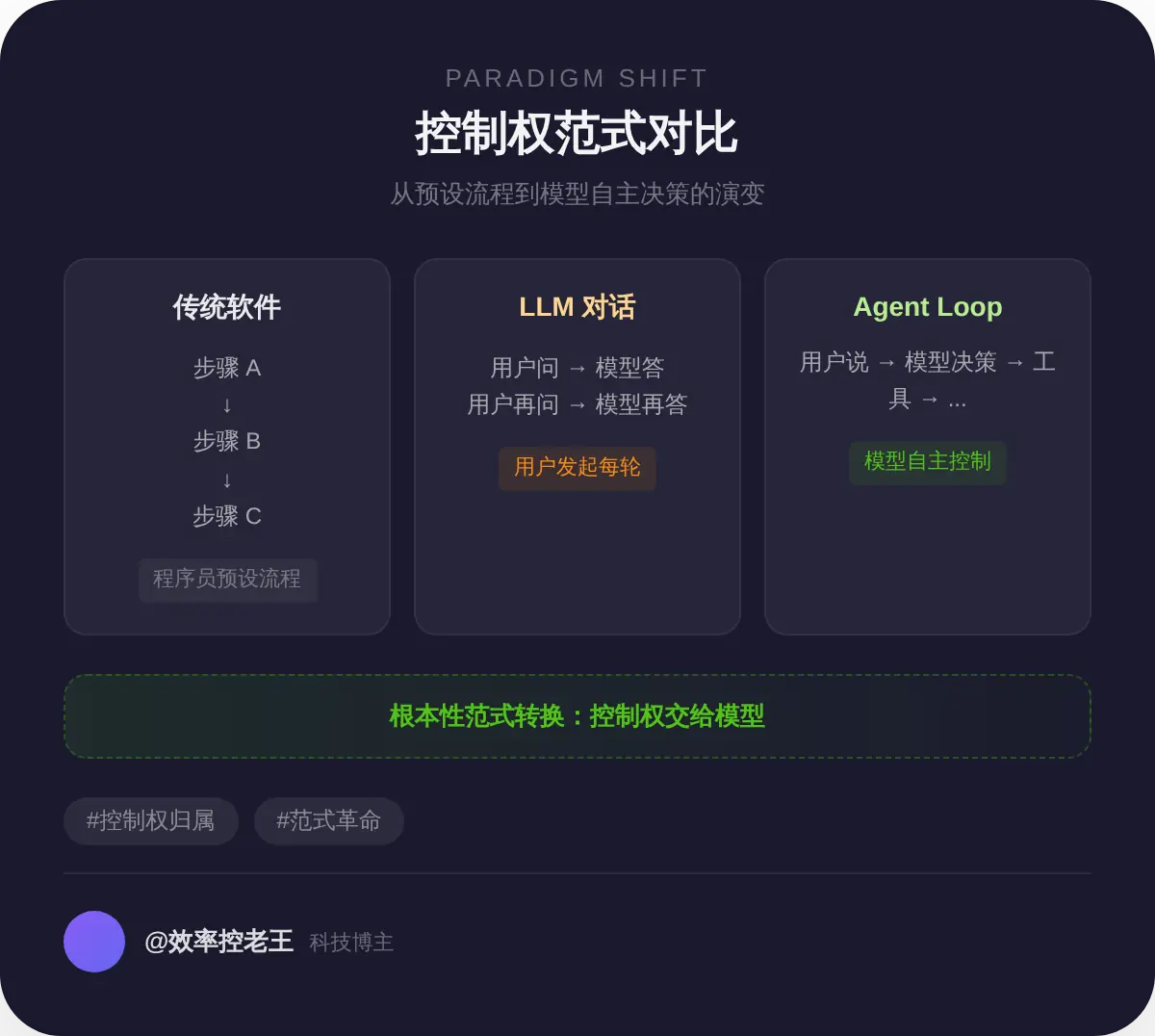
这是一个根本性的范式转换。
关键洞察:循环本身永远不变
再看一眼那段伪代码。从 Claude Code 到 Cursor、Devin、各种编程 Agent,它们的核心循环结构都是一样的。差异不在循环本身,而在循环上"挂"了什么东西:
- 挂了什么工具?能读文件还是能操作数据库?能跑终端命令还是能发 HTTP 请求?
- 喂了什么知识?项目文档、代码规范、行业知识?
- 怎么管理上下文?对话太长了怎么办?怎么让模型记住重要的东西、忘掉不重要的?
- 设了什么权限边界?允许模型自己执行命令还是每一步都要人确认?
循环是骨架,这些东西是血肉。骨架简单到不能再简单,但血肉的设计可以极其复杂------这也是为什么不同的 Agent 产品体验差异巨大,即使它们底层用的是同一个模型。
Agent 的能力 = 模型的智能 × Harness 的质量模型的智能我们管不了(等 Anthropic 和 OpenAI 迭代),但 Harness 的质量完全在我们手里。
小结
这篇文章的核心信息:
- Agent 和普通 LLM 对话的区别就在一个 while 循环------Agent Loop
- 这个循环做的事很简单:模型调了工具就继续,没调工具就结束
- 它的重要性在于把控制权从程序员/用户转移给了模型
- 循环本身不变,变的是往循环上"挂"什么东西------工具、知识、上下文、权限
那"挂什么东西"这件事到底怎么做?怎么设计才对?这就是下一篇要聊的 Harness 工程------可能是 AI 时代程序员最重要的新技能。