Java 自研 ReAct Agent 半年后,我用 LangGraph 验证了这些设计取舍
本文基于真实生产项目:智能售货机运营 Agent,25 个 Tool,双模型网关,RAG,钉钉集成,已上线运营。
背景
半年前我用 Java 从零实现了一个 ReAct Agent,接了 Kimi 和 DeepSeek 双模型,做了 25 个业务 Tool,跑在 Spring Boot 微服务里。最近在补 Python AI 生态,把 LangGraph 认真看了一遍。
看完有一种感觉:不是 LangGraph 更好,是它把你写在 while 循环里的东西都显式化了。
这篇文章不是教程,是我作为一个 Agent 应用 工程师对两种实现方式的真实理解。核心观点是:如果你只是想让 Agent 跑起来,两种方式都够用;如果你需要状态持久化、任务中断、人工干预,那 LangGraph 解决的是你真正的痛点。
一、自研实现长什么样
先讲我自己写的东西,方便后面做对比。
核心结构
bash
AgentServiceImpl.java
├── 检查用户配额(Redis)
├── 加载会话历史(Caffeine Cache)
└── while (true):
├── MessageHistoryManager.truncate() ← 三步截断
├── ModelGateway.chat(messages, tools) ← 双模型
├── 解析 LLM 响应
│ ├── 纯文本 → 返回,退出循环
│ └── tool_calls → 校验权限 → 执行 Tool → 结果压缩 → 加入历史
└── 继续下一轮Tool 注册用 Spring 自动装配,@PostConstruct 扫描所有 AgentTool Bean 建索引,每次循环把工具描述打包成 JSON Schema 发给 LLM。
流式版本(SSE)
非流式逻辑清晰,但用户等待感差。流式版 StreamingAgentServiceImpl 改成 SSE,核心是 SseEmitter + 事件分类:
scss
session_start → text(逐字) → tool_call(running) → tool_result → tool_call(done/❌) → done用 ConcurrentHashMap<sessionId, SseEmitter> 管理连接,前端发停止请求时 remove 掉 emitter,下一轮循环检测到连接不存在就退出------这是自研实现"中断"的方式,后面会对比 LangGraph 的中断。
图一:两种实现的结构对比
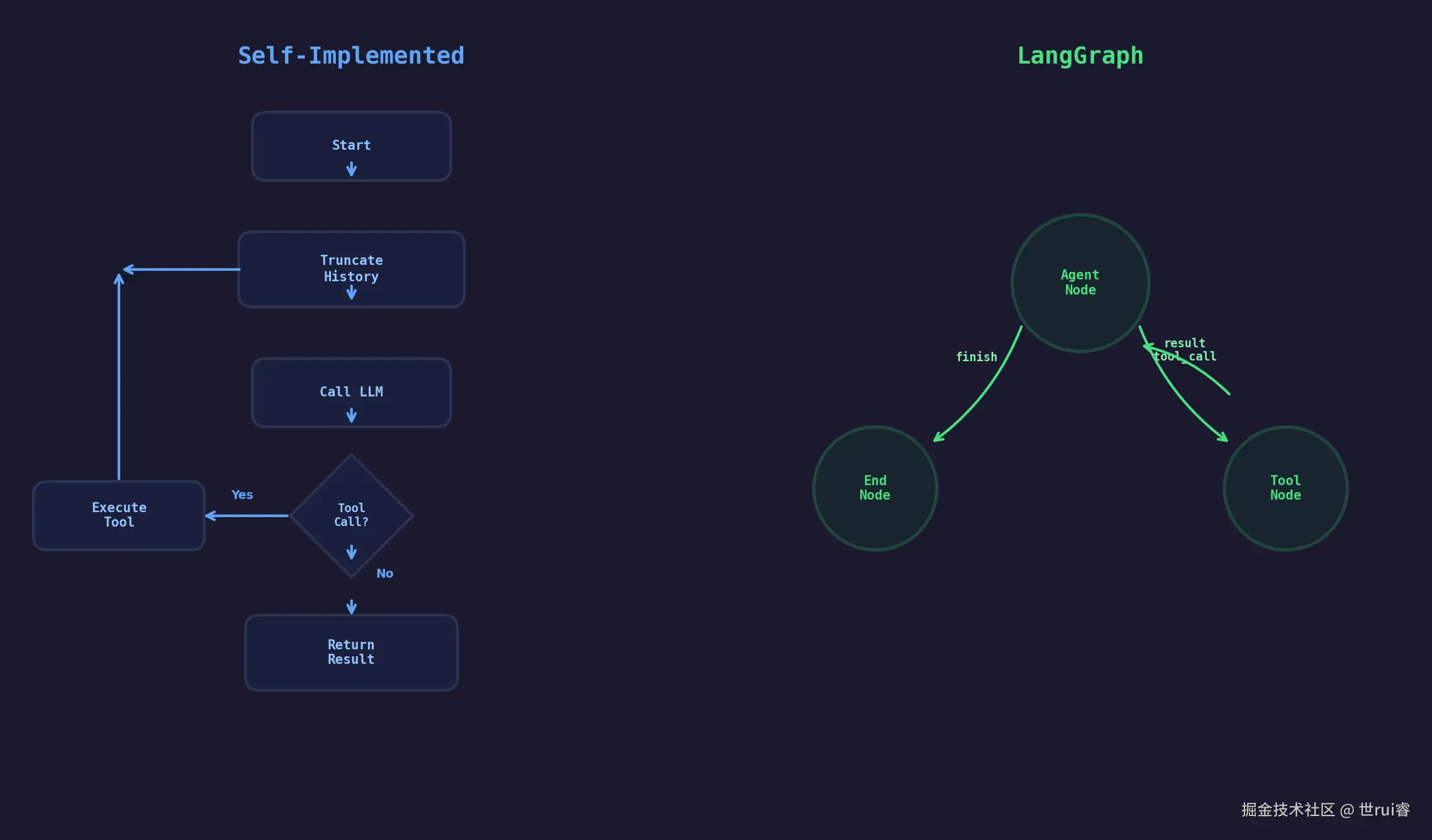
左侧是自研 Java 实现:while(true) 隐式循环,状态存在内存里,Resilience4j 管熔断,整个控制流在代码里是线性的。右侧是 LangGraph:显式有向图(StateGraph),每个节点是一个函数,边带条件,状态是 TypedDict,天然可序列化。
两种方式都能跑通 ReAct 逻辑。区别在于对"循环状态"的态度:自研是隐式的,LangGraph 是显式的。
二、最难搞的部分:消息历史管理
如果你用过 OpenAI / Kimi 的 API,一定遇到过这个报错:
swift
400 Bad Request: messages[3].content is required或者超长上下文导致的费用暴涨。这是每个自研 Agent 必须面对的问题。
三步截断策略
我的 MessageHistoryManager 做了三步截断,顺序不能乱:
步骤一:数量截断
保留最新 30 条消息。超出的从最旧开始扔。
ini
if (messages.size() > MAX_COUNT) {
messages = messages.subList(messages.size() - MAX_COUNT, messages.size());
}步骤二:长度截断
数量没超,但总字符数可能超过 8000(传给 LLM 的上下文预算)。从最旧的消息开始逐条删,直到总长度达标。
scss
while (totalChars(messages) > MAX_CHARS && messages.size() > 1) {
messages.remove(0); // ArrayList remove(0) 是 O(n),消息量大时可改用 LinkedList
}步骤三:孤立修复(最关键,也最容易漏)
前两步截断之后,可能产生一种情况:tool_result 消息还在,但它对应的 tool_call 消息被截掉了。Kimi 会直接返回 400,DeepSeek 会返回乱序回复。
修复逻辑:遍历消息列表,遇到 tool_result 时检查前面是否有匹配的 tool_call id,没有就直接删除。同时处理空 content 的 assistant 消息------某些模型对空 content 的 assistant 消息会报错。
less
// 收集所有 assistant 消息里发出的 tool_call id(tool_call 在 assistant 消息的 tool_calls 数组里)
Set<String> toolCallIds = messages.stream()
.filter(m -> "assistant".equals(m.getRole()))
.flatMap(m -> m.getToolCalls().stream())
.map(ToolCall::getId)
.collect(Collectors.toSet());
// 删除找不到对应 tool_call 的孤立 tool_result
messages.removeIf(m ->
"tool".equals(m.getRole()) && !toolCallIds.contains(m.getToolCallId())
);图二:三步截断示意图
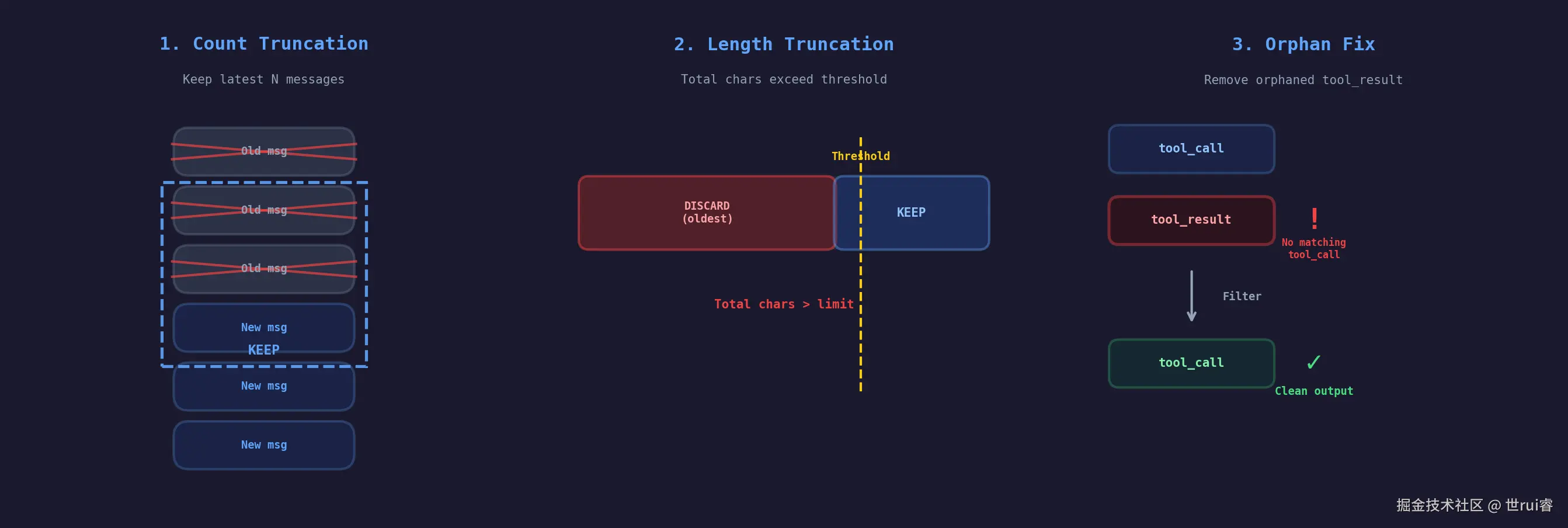
第三步的坑最容易踩到,但也最容易被忽略。我们上线前测试没发现,是真实用户用了一周后反馈"偶尔返回 400"才查出来的。根本原因是长会话 + 密集工具调用时,截断后孤立 tool_result 的概率大幅上升。
三、双模型网关:比你想的更复杂
用 Kimi 作主力,DeepSeek 做备用,看起来很简单,实际有几个细节:
非流式降级很直接:主模型抛异常就切备用,同时钉钉报警。
流式降级复杂 :HTTP 流式回包一旦开始,回调已经在 onData 里了,try-catch 捕不到------你得在 onError 回调里判断 hasData 标志位:
hasData = false(还没收到任何数据)→ 可以无感切换 DeepSeekhasData = true(已经有数据流出去了)→ 没有办法撤回,只能透传错误
这个细节 LangGraph 不帮你解决,框架层面不感知你用哪家模型。
四、再看 LangGraph:它解决了什么
好,说完了自研实现里真实踩过的坑,现在回过头来看 LangGraph,就能理解它为什么那样设计了。
LangGraph 的核心抽象是 StateGraph:
python
from langgraph.graph import StateGraph, END
from typing import TypedDict
class AgentState(TypedDict):
messages: list
tool_calls: list
graph = StateGraph(AgentState)
graph.add_node("llm_call", call_llm)
graph.add_node("tool_exec", execute_tools)
graph.add_conditional_edges(
"llm_call",
lambda s: "continue" if s["tool_calls"] else "end",
{"continue": "tool_exec", "end": END}
)
graph.add_edge("tool_exec", "llm_call")
graph.set_entry_point("llm_call")
app = graph.compile()这段代码 while(true) 里面的逻辑画成了一张图(即文章开头的图一)。功能上等价,但有两个重要差别:
差别一:状态是一等公民
LangGraph 的 State 是一个 TypedDict,每一步都在更新它。这意味着:
- 持久化:用 Checkpointer(SQLite/Redis)存储 State,崩溃后从断点恢复
- 回放:任意给定 State,重新跑一遍
- 时间旅行:LangGraph Studio 里可以回到某一步重新执行
我的 Caffeine Cache 只是把整个消息列表序列化存了,粒度是"会话",不是"每一步的中间状态"。
差别二:中断(Human-in-the-loop)
LangGraph 的 interrupt_before / interrupt_after 可以在节点执行前后暂停,等待外部输入再继续。
ini
graph.compile(interrupt_before=["tool_exec"])这个在需要"执行写操作前让人确认"的场景非常有用。
我的实现里,写操作权限是在 Tool execute 方法里校验的,用户如果没有权限就报错返回。但 LangGraph 的中断是在图执行层面,暂停期间可以修改 State 再继续------比如用户可以改工具参数再确认。
五、横向对比
| 维度 | 自研 Java | LangGraph |
|---|---|---|
| 循环控制 | while(true) 手写,完全可控 |
StateGraph 显式图,可视化 |
| 状态粒度 | 会话级(消息列表整体) | 步骤级(每个节点后都可 checkpoint) |
| 中断 / 恢复 | 靠 emitter remove 间接实现 | interrupt_before/after 原生支持 |
| 消息截断 | 自己写三步逻辑(踩坑) | 无内置;LangChain 有 trim_messages 但仍需自己配置策略 |
| 熔断降级 | Resilience4j 完整支持 | 无内置,需自己包装 |
| 流式 | SseEmitter + 自定义事件协议 | stream_mode 内置多种模式 |
| Tool 注册 | Spring List<AgentTool> 自动装配 |
@tool 装饰器 + 列表传入 |
| 调试可见性 | 自写日志 + SSE 事件 | verbose=True + LangGraph Studio |
| 多租户 | TenantContextHolder 手动传递 | 无概念,需自己处理 |
| 部署 | Spring Boot 微服务,天然融入现有体系 | FastAPI / 独立服务,需额外集成 |
六、我的判断
什么时候选自研 Java:
- 业务在 Spring Cloud 生态里,需要和现有 Feign/MyBatis/Redis 无缝集成
- 有熔断、多租户、权限等横切需求,Resilience4j 等工具很成熟
- 循环逻辑不复杂,Tool 数量可控,不需要状态持久化
什么时候 LangGraph 值得迁移:
- 需要人工干预节点(审批、确认、二次输入)
- 需要任务中断后从断点继续(长时间任务、多步规划)
- Agent 逻辑复杂,节点有并行分支,图结构能帮助推理
现实答案: 对我们的项目,自研 Java 现在足够用。但我在用 LangGraph 复现核心功能的过程中学到的最有价值的一点是:把 Agent 的控制流画出来------哪怕最后不用 LangGraph,这个"图思维"也让我把自研的代码重新审视了一遍,发现了几个隐藏的状态管理 bug。
工具是手段,清晰的思维模型才是真正的价值。
参考
如果你也在做企业级 AI Agent,你是选自研还是接框架?欢迎评论区聊聊你的权衡逻辑。