TL;DR
- 场景:大数据平台配置,需要在YARN集群上部署Livy REST接口,并安装Griffin数据质量监控工具
- 结论:成功完成Livy 0.5.0和Griffin 0.5.0的编译安装、配置及服务启动,YARN集群模式运行
- 产出:详细的安装配置文档,包含环境变量、配置文件修改、服务启动步骤及SQL初始化说明
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| Livy 0.5.0 解压配置 | ✅ 已验证 | 解压至/opt/servers/livy-0.5.0 |
| Livy YARN Cluster模式 | ✅ 已验证 | livy.spark.master=yarn, deployMode=cluster |
| Livy REST接口启动 | ✅ 已验证 | nohup后台启动livy-server |
| Livy Hive上下文 | ✅ 已验证 | livy.repl.enable-hive-context=true |
| Griffin 0.5.0 解压配置 | ✅ 已验证 | 解压至/opt/servers/griffin-0.5.0 |
| MySQL quartz数据库初始化 | ✅ 已验证 | 执行Init_quartz_mysql_innodb.sql |
| HDFS hive-site.xml上传 | ✅ 已验证 | 上传至/spark/spark_conf/目录 |
| 环境变量配置 | ✅ 已验证 | JAVA_HOME/SPARK_HOME/LIVY_HOME/HADOOP_CONF_DIR |
上节到了Griffin的编译安装 下面继续
编译安装
续接上节,上节到了 Elasticsearch
Livy
基本介绍
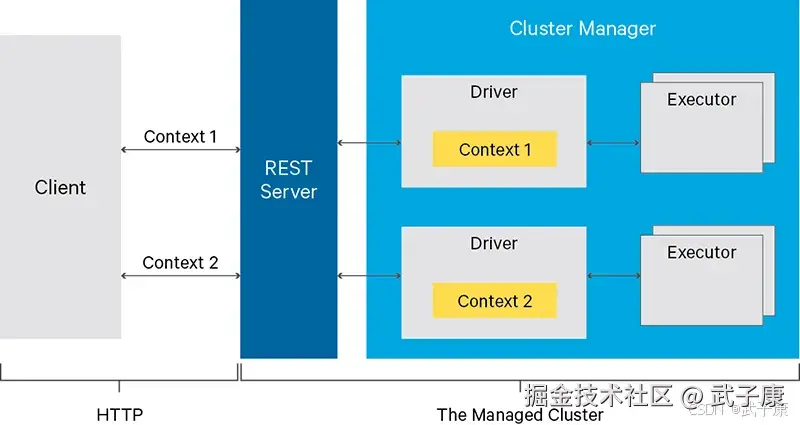 Livy 是一个用于 Apache Spark 的 REST 接口,旨在简化 Spark 作业的提交和管理,特别是在大数据处理场景中。它的主要功能是通过 REST API 与 Spark 集群进行交互,允许用户提交作业、执行代码片段并查询作业的状态和结果,而不需要直接与 Spark 的底层架构交互。 Livy 的一些关键功能包括:
Livy 是一个用于 Apache Spark 的 REST 接口,旨在简化 Spark 作业的提交和管理,特别是在大数据处理场景中。它的主要功能是通过 REST API 与 Spark 集群进行交互,允许用户提交作业、执行代码片段并查询作业的状态和结果,而不需要直接与 Spark 的底层架构交互。 Livy 的一些关键功能包括:
- 简化 Spark 作业提交:用户可以通过 HTTP 请求向 Livy 发送 Spark 作业,而不需要直接使用 spark-submit命令。
- 多语言支持:Livy 支持使用不同的编程语言提交作业,包括 Python(通过 PySpark)、Scala 和 R。
- Session 管理:Livy 可以管理 Spark 会话,允许多个用户在同一集群上共享会话,并执行交互式代码片段。
- 作业状态管理:Livy 提供 API 来查看作业的状态、日志以及结果,便于跟踪和监控任务执行。
- 集成:Livy 通常与 Jupyter Notebook、Zeppelin 等工具集成,以便用户可以在这些环境中使用 Spark 集群执行代码。
配置计划
我们的Spark是集群三台节点配置的,但是Livy可以不用配置集群,我们计划在主节点上进行配置:
shell
h121.wzk.icu解压配置
shell
cd /opt/software
unzip livy-0.5.0-incubating-bin.zip
mv livy-0.5.0-incubating-bin/ ../servers/livy-0.5.0处理结果如下图所示: 
环境变量
shell
# 设置环境变量
vim /etc/profile
# 设置完之后 记得刷新
source /etc/profile写入内容如下:
shell
export LIVY_HOME=/opt/servers/livy-0.5.0
export PATH=$PATH:$LIVY_HOME/bin对应的内容如下所示: 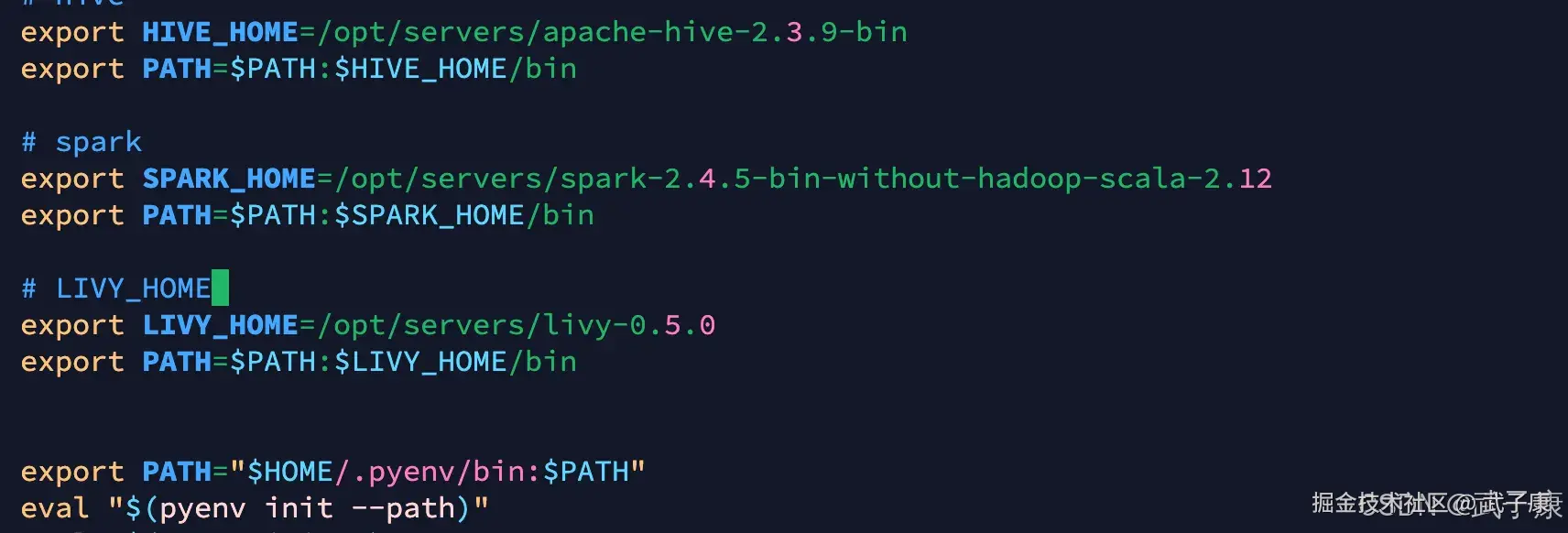
修改配置
shell
mv $LIVY_HOME/conf/livy.conf.template $LIVY_HOME/conf/livy.conf
vim $LIVY_HOME/conf/livy.conf修改内容如下:
shell
livy.server.host = 0.0.0.0
livy.spark.master = yarn
livy.spark.deployMode = cluster
livy.repl.enable-hive-context = true修改内容如下所示: 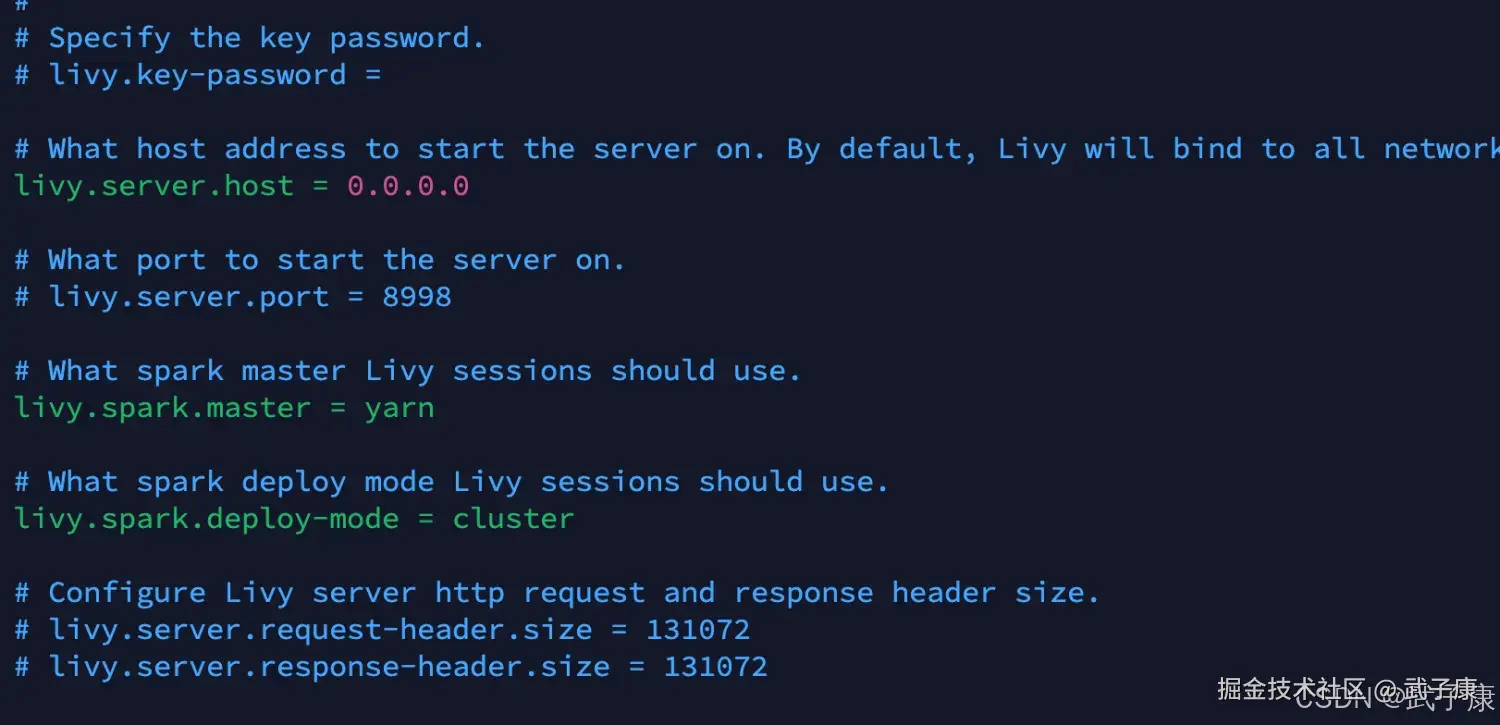 修改配置文件
修改配置文件
shell
mv $LIVY_HOME/conf/livy-env.sh.template $LIVY_HOME/conf/livy-env.sh
vim $LIVY_HOME/conf/livy-env.sh写入内容如下所示:
shell
export SPARK_HOME=/opt/servers/spark-2.4.5
export HADOOP_HOME=/opt/servers/hadoop-2.9.2/
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop写入内容如下所示: 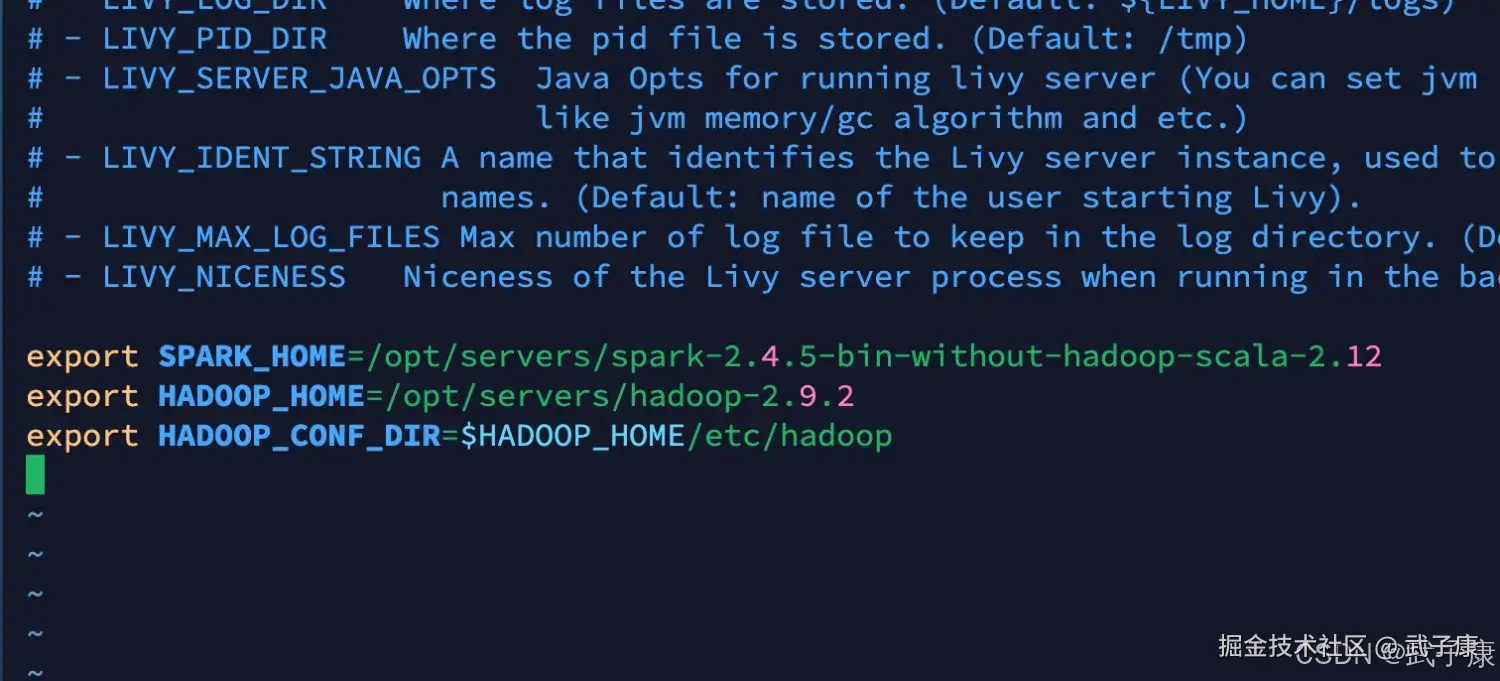
启动服务
shell
cd /opt/servers/livy-0.5.0
mkdir logs
nohup $LIVY_HOME/bin/livy-server &Griffin
前置介绍
"Griffin"是一个大数据领域的开源项目,特别是在分布式流处理和大数据系统的管理中具有一定的影响力。它最早由LinkedIn开发,用于处理大规模数据流。Griffin的设计目标是简化和自动化流数据处理和监控工作,使得在大数据应用中能够高效地处理实时数据流,同时提升数据的可追溯性和可靠性。
随着大数据技术的发展,实时流处理(如Apache Kafka、Apache Flink等)在许多应用场景中扮演着越来越重要的角色。处理这些流数据时,不仅需要确保高效的计算和数据吞吐量,还要实现数据的可追溯性和监控。为了应对这些挑战,Griffin应运而生,致力于提供一个高效、可扩展的解决方案,尤其是在数据质量监控和流处理作业的管理方面。
Griffin的目标包括:
- 数据质量控制: 自动化数据质量检查,确保流数据的准确性和完整性。
- 流处理作业管理: 对流处理作业进行有效的调度和监控,及时发现异常。
- 数据管道的透明度: 提供对数据流动过程的清晰视图,便于追踪和排查问题。
- 实时数据处理: 结合流处理系统,如Apache Kafka和Apache Flink,优化数据处理效率。
主要功能
Griffin的功能集中在数据质量控制和流处理管理上,以下是其一些核心功能:
- 数据质量监控: Griffin可以实时监控数据流中的各种质量问题,如数据丢失、重复、格式错误等,并生成报告或警告。这对于需要高质量数据的实时分析和决策过程尤为重要。
- 流数据治理: 它帮助管理数据流动的每个环节,确保数据在处理过程中符合质量要求,减少因数据问题导致的错误和偏差。
- 作业调度和监控: 对流处理作业进行调度,实时监控其状态和性能。它能够识别系统中可能的瓶颈,保证流处理任务的高效执行。
- 数据追溯: 在数据出现问题时,Griffin提供对数据来源的追溯功能,帮助用户快速定位问题的根源,确保数据的透明度和可追溯性。
架构设计
Griffin的架构通常包括以下几个组件:
- 数据接入层: 负责从数据源接入数据流。常见的数据源包括Apache Kafka、Apache Flink等流处理系统。
- 数据处理层: 对数据进行质量检查和流处理操作。该层可能包括数据清洗、校验等操作,确保流数据符合预期的质量标准。
- 监控和告警层: 提供流处理作业的监控和告警机制,及时发现问题并通知管理员。
- 数据存储和可视化层: 存储分析结果和质量报告,并通过可视化界面展示给用户,帮助用户理解数据流的状况。
解压配置
软件解压缩:(这里我是在 h122 节点)
shell
cd /opt/software
unzip griffin-griffin-0.5.0.zip
mv griffin-griffin-0.5.0/ ../servers/griffin-0.5.0/
cd ../servers/griffin-0.5.0运行结果如下图所示: 
SQL初始化
在MySQL中创建数据库quartz,并初始化
shell
# SQL 文件如下
/opt/servers/griffin-0.5.0/service/src/main/resources/Init_quartz_mysql_innodb.sql备注:要做简单的修改,主要是增加 use quartz;
shell
vim /opt/servers/griffin-0.5.0/service/src/main/resources/Init_quartz_mysql_innodb.sql
# 写入
use quartz;执行如下的结果:  创建数据库
创建数据库
shell
# 在MySQL中执行
# mysql中执行创建数据库
create database quartz;执行结果如下:  运行SQL文件:
运行SQL文件:
shell
# 在外部执行
# 命令行执行,创建表
cd /opt/servers/griffin-0.5.0/service/src/main/resources/
mysql -uhive -phive@wzk.icu < Init_quartz_mysql_innodb.sql执行结果可以连上数据库查看: 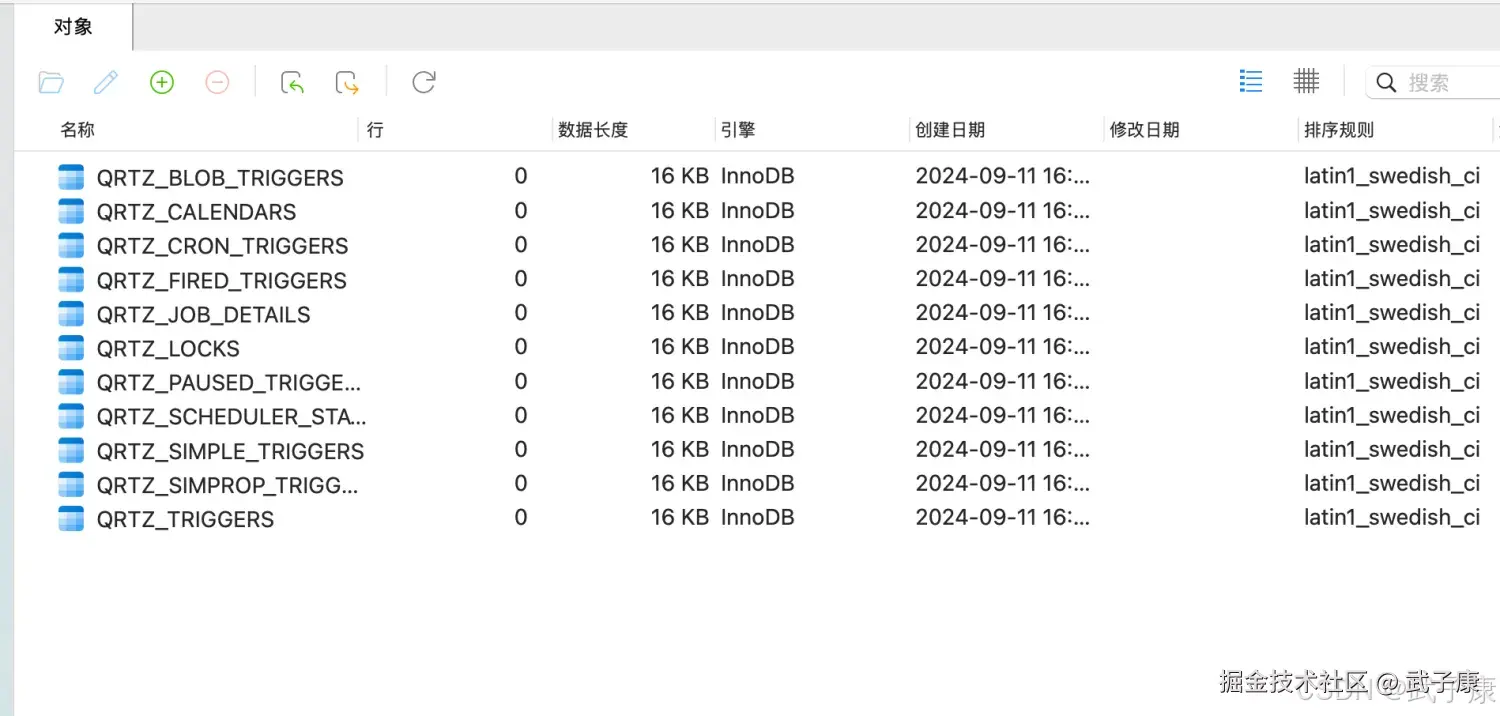
Hadoop 和 Hive
在HDFS上创建 /spark/spark_conf目录,并将Hive的配置文件hive-site.xml上传到该目录下
shell
hdfs dfs -mkdir -p /spark/spark_conf
hdfs dfs -put $HIVE_HOME/conf/hive-site.xml /spark/spark_conf/执行结果如下所示: 
- 备注:将安装Griffin所在的节点上的hive-site.xml文件,上传到HDFS对应目录中
环境变量
确认如下的必要环境变量都配置完毕:
shell
JAVA_HOME
SPARK_HOME
LIVY_HOME
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Livy服务启动失败 | SPARK_HOME或HADOOP_HOME环境变量未配置 | 检查livy-env.sh中export语句是否完整 | 添加export SPARK_HOME=/opt/servers/spark-2.4.5等环境变量 |
| Livy提交Spark作业报错 | YARN cluster模式配置错误 | 检查livy.conf中livy.spark.master和livy.spark.deployMode | 确认配置为yarn和cluster |
| Griffin SQL初始化失败 | MySQL中quartz数据库未创建 | 手动登录MySQL执行create database quartz | 先创建数据库再执行SQL文件 |
| HDFS上传hive-site.xml失败 | 当前用户无HDFS写入权限 | 执行hdfs dfs -ls /spark/spark_conf检查 | 使用hdfs用户或修改目录权限 |
| Livy REST API无法访问 | Livy服务未启动或端口被占用 | 检查livy-server进程是否存在 | kill后重新nohup启动 |
| Hive上下文启用失败 | livy.repl.enable-hive-context配置项缺失 | 检查livy.conf是否包含该配置项 | 添加livy.repl.enable-hive-context = true |
| Griffin启动无反应 | JAVA_HOME环境变量缺失 | 确认/etc/profile中是否配置JAVA_HOME | source /etc/profile后重试 |
| MySQL连接被拒绝 | MySQL用户权限不足 | 检查mysql -uhive -phive@wzk.icu能否登录 | 授权用户访问quartz数据库 |