搜索优化------迭代加深dfs
- 迭代加深搜索
-
- [1443: Addition Chains](#1443: Addition Chains)
-
- 简单分析
- [迭代加深dfs + 剪枝](#迭代加深dfs + 剪枝)
- [P1763 埃及分数 - 洛谷](#P1763 埃及分数 - 洛谷)
- [迭代加深反例:P2730 魔板 - 洛谷](#迭代加深反例:P2730 魔板 - 洛谷)
- OJ参考
迭代加深搜索
迭代加深是一种限制搜索深度的深度优先搜索,本质还是 dfs,只不过在搜索的同时带上了一个深度 depth,当 depth 达到设定的深度时就返回。若一次搜索没有找到合法的解,就让设定的深度加一,从起点开始重新搜索。
因此,迭代加深搜索也能找到起点到目标的最短路径。
伪代码大致如下:
cpp
bool dfs(int dep, int max_dep) {
if (dep > max_dep) {
// 找到目标结点则返回真,否则返回假
}
}
void f() {
for (int dep = 1;; dep++) {
if (dfs(1, dep)) { // 在当前深度找到结果
// 处理结果
break;
}
}
}若仔细观察,会发现迭代加深搜索的过程和广度优先搜索十分相似,且因为会重复遍历部分结点使得迭代加深搜索更加耗时。之所以不直接用 bfs 而是迭代加深搜索,需要从 2 方面考虑:
空间上:
- bfs 是依靠队列一层一层的展开,此时一整层的数据都会加入队列中,使得队列的空间开销庞大,当状态比较多或者单个状态比较大时(例如抽象搜索树的结点为一个数组),使用队列的 bfs 会有空间溢出的风险。
- 而 dfs 时,每次只会走一个分支,因此空间复杂度相对较低。
时间上:
- 当搜索树的分支比较多 时,每增加一层 ,搜索复杂度会出现指数级爆炸式增长。
- 这时前面重复进行的部分所带来的复杂度几乎可以忽略,这也是为什么迭代加深是可以近似看成 bfs 的 dfs 实现。
- 并且,在 dfs 的过程中,也能利用深度 depth 进行一些剪枝操作。
综上所述,迭代加深 dfs 就类似于用 bfs 方式实现的 dfs,只不过它的空间复杂度相对较小而已,但不代表迭代加深 dfs 的题目简单多少, dfs 的难点剪枝,迭代加深 dfs 几乎全部继承;也不代表迭代加深 dfs 就一定比 bfs 好用,若不通过剪枝等手段控制搜索树增长, bfs 能解决的问题,使用迭代加深 bfs 反而会超时。
1443: Addition Chains
中译中:给定一个数列 { a 1 = 1 , a 2 , ... , a m = n } \{a_1=1,a_2,\dots,a_m=n\} {a1=1,a2,...,am=n} ,中间的 { a 2 , ... , a m } \{a_2,\dots,a_m\} {a2,...,am} 的任意一项均需满足 2 个条件:
- a i < a j a_i<a_j ai<aj , i < j i<j i<j 。
- a k = a i + a j a_k=a_i+a_j ak=ai+aj , 0 ≤ i , j ≤ k − 1 0\le i,j \le k-1 0≤i,j≤k−1 。 i i i 可以等于 j j j 。
简单分析
所以这个问题按照填每个数时的决策可绘制出抽象搜索树,当搜索树的某个深度为 m m m 的结点 a m = n a_m=n am=n 时,这条最短路径就是答案。
例如测试样例 7 可构建出如下抽象树:
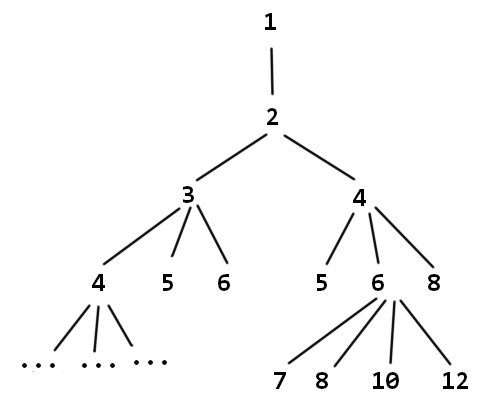
首先想到的就是 bfs 。但 n n n 可达 10000 (以 UVA 的题面为准),且还需要存储之前的结点的数据,很容易因为内存不足导致程序崩溃。
题目求的是 1 到 n n n 的最短路径,这个抽象树是个边权为 1 的图,所以可尝试使用 dfs 枚举所有的路径,只要找到第 1 条就可以直接输出。但一般的 dfs 会一股脑地走到叶结点再回归,这题显然没有明确的叶结点,所以需要使用迭代加深优化对 dfs 进行限制。
迭代加深dfs + 剪枝
首先是朴素迭代加深。设计一种 dfs 的递归函数,每层递归填一个格子 ,填格子的方式是在曾经填过的格子上选择格子作为当前格子的填写参照,因为要选 2 个,且可选相同的,为了不重复使用 2 层循环遍历。若在 ybt 提交的话,则要从最近的结点开始选值,若在 UVA 提交的话则无所谓。
不出意外地话必定超时,仅作为学习时参考:
cpp
#include <bits/stdc++.h>
using namespace std;
int path[10010] = {0};
int n;
bool dfs(int dep, int mdep) {
if (dep > mdep)
return path[mdep] == n;
// 因为ybt没有使用特殊判断,所以需要从上层结点开始遍历
// 但UVA就无所谓
for (int i = dep - 1; i >= 0; i--)
for (int j = i; j < dep; j++) {
path[dep] = path[i] + path[j];
if (dfs(dep + 1, mdep))
return true;
}
return false;
}
int main() {
// freopen("in.in", "r", stdin);
path[0] = 1;
while (cin >> n, n > 0) {
for (int mdep = 1;; mdep++) { // 枚举深度
if (dfs(1, mdep)) { // 当前深度可找到答案
cout << path[0]; // UVA会识别末尾空格,以UVA为主
for (int i = 1; i <= mdep; i++)
cout << ' ' << path[i];
cout << '\n';
break;
}
}
}
return 0;
}此时就需要考虑剪枝:
-
可行性剪枝:当当前深度的 p a t h d e p ≤ p a t h d e p − 1 pathdep\le pathdep-1 pathdep≤pathdep−1 时,说明当前格子取值小了,需要找更大的值,所以跳过。
-
可行性剪枝:当当前深度的 p a t h d e p > n pathdep> n pathdep>n 时,后续的数只会更大,此时直接 break 循环即可。
-
最优化剪枝:当搜索时以最小幅度进行取值,此时应该有 p a t h d e p = p a t h d e p − 1 + 1 pathdep=pathdep-1+1 pathdep=pathdep−1+1 ,因为迭代加深有深度限制,所以可在这个分支预测未来的结点大小:
p a t h m d e p = p a t h d e p + ( m d e p − d e p ) pathmdep=pathdep+(mdep-dep) pathmdep=pathdep+(mdep−dep) 。若 p a t h m d e p > n pathmdep>n pathmdep>n ,则没有必要进行这个子树的搜索,直接
break掉当前循环。 -
最优化剪枝:当搜索时以最大幅度进行取值,此时可在这个分支预测未来的结点的值:
p a t h m d e p = p a t h d e p × 2 m d e p − d e p pathmdep=pathdep\times 2^{mdep-dep} pathmdep=pathdep×2mdep−dep ,若 p a t h m d e p < n pathmdep<n pathmdep<n ,则说明当前格子取值小了,需要找更大的值,所以跳过。
这里的剪枝分 2 种,一种是跳过某一循环状态即 continue ,另一种是直接终止当前循环即 break 。前者是当前的值取小了,在当前深度条件下基本不可能取得答案,后者则是值取大了,则包括它在内的后续取值只会更大。
1443:【例题4】Addition Chains 迭代加深 + + + 剪枝优化参考:
cpp
#include <bits/stdc++.h>
using namespace std;
void IOinit() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
}
int path[10010] = {0};
int n;
bool dfs(int dep, int mdep) {
if (dep > mdep)
return path[mdep] == n;
// 因为ybt没有使用特殊判断,所以需要从上层结点开始遍历
// 但UVA就无所谓
for (int i = dep - 1; i >= 0; i--) // ybt需要逆序枚举
for (int j = i; j < dep; j++) {
int x = path[i] + path[j];
// 剪枝
if (x <= path[dep - 1]) // 小了,需要找更大的
continue;
if (x > n) // 因为单调性原因,后续只会更大,所以break
break;
if (x * (1 << (mdep - dep)) < n) // 小了,需要找更大的
continue;
if (x + (mdep - dep) > n) // 因为单调性原因,后续只会更大
break;
path[dep] = x;
if (dfs(dep + 1, mdep))
return true;
}
return false;
}
int main() {
// freopen("in.in", "r", stdin);
IOinit();
path[0] = 1;
while (cin >> n, n > 0) {
// 枚举深度要从0开始,因为n=1的情况也要考虑
for (int mdep = 0;; mdep++) {
if (dfs(1, mdep)) { // 当前深度可找到答案
cout << path[0];
for (int i = 1; i <= mdep; i++)
cout << ' ' << path[i];
cout << '\n';
break;
}
}
}
return 0;
}P1763 埃及分数 - 洛谷
题目的意图很明显,给定一个 a b \frac{a}{b} ba ,要求做题人将它分解为 a b = ∑ x 1 x \frac{a}{b}=\sum\limits_{x}\frac{1}{x} ba=x∑x1 的形式,且分母保证全不相等的同时尽可能地小,同时分解的项数尽可能地小,所以还附带一个最短路的性质,可以尝试迭代加深算法。
这题可通过简单的迭代加深搜索遍历出部分情况,每层递归代表一个分数。但这种朴素解法无法处理数据量大的情况,想要通过 OJ 还需要进行剪枝:
cpp
#include <bits/stdc++.h>
#include <unistd.h>
using namespace std;
using LL = long long;
LL a, b; // a/b
LL path[1010];
LL gcd(LL a, LL b) {
return b ? gcd(b, a % b) : a;
}
bool dfs(int dep, int mdep, LL x, LL y, LL lt) {
if (dep > mdep)
return x == 0;
for (LL i = lt; i <= a * b; i++) { // 纯暴力无优化
if (x * i < y) // x/y小于1/i
continue;
LL t1 = x * i - y, t2 = y * i; // 经过叠加后的新的分子分母
LL g = gcd(t1, t2);
t1 /= g, t2 /= g;
path[dep] = i;
if (dfs(dep + 1, mdep, t1, t2, i + 1))
return true;
}
return false;
}
int main() {
// freopen("in.in", "r", stdin);
cin >> a >> b;
for (int mdep = 1; mdep <= 7; mdep++) {
if (dfs(1, mdep, a, b, 2)) {
for (int i = 1; i <= mdep; i++)
cout << path[i] << ' ';
cout << endl;
}
}
return 0;
}最优化剪枝:优化枚举和搜索范围
之前的递归函数的设计:bool dfs(int dep, int mdep, LL x,LL y,LL lt) 很明显不合理,原因是最小的分数是 1 10 7 \frac{1}{10^7} 1071 ,一层递归或许支持枚举如此庞大的数,但若干层就不允许,即使使用上层递归的 lt 优化也不行。
所以第一个优化就是确定每层递归的决策的上、下界,即最优化剪枝。
首先确定递归函数的含义:
- 每层递归函数代表所有已枚举的分数的和。
- 目标分数 a b \frac{a}{b} ba 减去已枚举分数的和之后的剩余。
方案 1 需要枚举到 mdep+1 层才能获取分数的和,但会让 dfs 多遍历一层。搜索树的每一层比上一层多增加的结点往往是指数级别的 ,多遍历一层都很有可能造成超时。
方案 2 仅需枚举到 mdep 层即可完成递归,此时判断第 mdep 层是否是 1 ? \frac{1}{?} ?1 即可。
所以使用方案 2 。
然后优化每层递归的枚举上 、下界:
即 path[dep] 应该填什么数,设 L < p a t h d e p < R L<pathdep<R L<pathdep<R ,则首先确定 L , R L,R L,R 的取值范围。
- 分析下界取值:
因为每层递归的分母都必须比上个格子的分母大,所以弄一个全局数组后,就可直接使用 path[dep-1] 来获取,不需要额外上传 lt 。所以 p a t h d e p > p a t h d e p − 1 pathdep>pathdep-1 pathdep>pathdep−1 。
使用方案 2 之后,递归函数初始的 x y = a b − ∑ z 1 z \frac{x}{y}=\frac{a}{b}-\sum\limits_z \frac{1}{z} yx=ba−z∑z1 ,所以
x y > 1 p a t h d e p \frac{x}{y}>\frac{1}{pathdep} yx>pathdep1 ,否则搜索将无法进行。所以 p a t h d e p > y x pathdep>\frac{y}{x} pathdep>xy 。
综上,下界取值 L = max ( p a t h d e p − 1 , y x ) + 1 L=\max(pathdep-1,\frac{y}{x})+1 L=max(pathdep−1,xy)+1 。
- 分析上界取值:
和 1443:【例题4】Addition Chains 类似, 所有格子的填法按照最低幅度增长,有
x y = 1 t + 1 t + 1 + 1 t + 2 + ⋯ + 1 t + m d e p − d e p \frac{x}{y}=\frac{1}{t}+\frac{1}{t+1}+\frac{1}{t+2}+\dots+\frac{1}{t+mdep-dep} yx=t1+t+11+t+21+⋯+t+mdep−dep1 ,假设 path[dep]=t 。
所以每个位置的最小填法是 1 t + m d e p − d e p \frac{1}{t+mdep-dep} t+mdep−dep1 。但因为是分母的填法,所以这种填法是 x y \frac{x}{y} yx 最大的一种分解方式,此时应该有
1 t + 1 t + 1 + 1 t + 2 + ⋯ + 1 t + m d e p − d e p ≥ x y \frac{1}{t}+\frac{1}{t+1}+\frac{1}{t+2}+\dots+\frac{1}{t+mdep-dep}\ge\frac{x}{y} t1+t+11+t+21+⋯+t+mdep−dep1≥yx ,否则无法将 x y \frac{x}{y} yx 分解。
但这个等式无法通过常规手段计算,也不需要计算出它的值,只需知道它的大概取值即可。所以需要使用不等式放缩的手段:
x y ≤ 1 t + 1 t + 1 + 1 t + 2 + ⋯ + 1 t + m d e p − d e p < 1 t + 1 t + ⋯ + 1 t ⏟ m d e p − d e p + 1 个 1 t = m d e p − d e p + 1 t \frac{x}{y}\le \frac{1}{t}+\frac{1}{t+1}+\frac{1}{t+2}+\dots+\frac{1}{t+mdep-dep}\\<\underbrace{\frac{1}{t}+\frac{1}{t}+\dots+\frac{1}{t}}_{mdep-dep+1\text{个}\frac{1}{t}}=\frac{mdep-dep+1}{t} yx≤t1+t+11+t+21+⋯+t+mdep−dep1<mdep−dep+1个t1 t1+t1+⋯+t1=tmdep−dep+1
所以 x y < m d e p − d e p + 1 t \frac{x}{y}< \frac{mdep-dep+1}{t} yx<tmdep−dep+1 , t < ( m d e p − d e p + 1 ) y x t<\frac{(mdep-dep+1)y}{x} t<x(mdep−dep+1)y 。
综上,上界取值 : R = ( m d e p − d e p + 1 ) y x R=\frac{(mdep-dep+1)y}{x} R=x(mdep−dep+1)y 。
最后确定递归函数的边界条件:
题目要求不仅要找到最少的分解次数,还要找到分母尽可能小的分数集合,所以递归时得到的分解方案不一定是分母最小的,后续 dfs 时可能发现更小的。所以需要 2 个数组 path 和 ans , ans 负责记录最优答案,若发现一种更优解则更新 ans 数组。
所以当枚举到 1 ? \frac{1}{?} ?1 时,判断当前 path 是否是更优解,是的话就进行更新。
此时因为已经找到更优解,再用原来的上、下界
max ( p a t h \[ d e p − 1 , y x ) + 1 , ( m d e p − d e p + 1 ) y x ] \\max(path\[dep-1,\frac{y}{x})+1,\frac{(mdep-dep+1)y}{x}] max(path\[dep−1,xy)+1,x(mdep−dep+1)y] 已经不合适,所以最新的上下界应该为
max ( p a t h \[ d e p − 1 , y x ) + 1 , min ( a n s m d e p , ( m d e p − d e p + 1 ) y x ) ] \\max(path\[dep-1,\frac{y}{x})+1,\min(ansmdep,\frac{(mdep-dep+1)y}{x})] max(path\[dep−1,xy)+1,min(ansmdep,x(mdep−dep+1)y)] ,前提是 ans 数组已经记录了答案。
但遗憾的是,这个思路在二十世纪末是可以通过这道题,也就是数据量偏小的 1444:埃及分数 。但现在有人提出更优的剪枝策略,所以这个思路在 P1763 埃及分数 - 洛谷 会超时。
1444:埃及分数 参考:
cpp
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
LL path[1010], ans[1010];
LL a, b;
LL gcd(LL a, LL b) {
return b ? gcd(b, a % b) : a;
}
void dfs(LL dep, LL mdep, LL x, LL y) {
if (dep >= mdep) {
if (x != 1 || y <= path[dep - 1])
return;
path[dep] = y;
if (ans[0] == 0 || y < ans[mdep]) {
for (int i = 1; i <= mdep; i++)
ans[i] = path[i];
ans[0] = mdep;
}
return;
}
// 最优化剪枝
LL L = max(path[dep - 1], y / x) + 1;
LL R = (mdep - dep + 1) * y / x;
if (ans[0] > 0)
R = min(ans[mdep], R);
for (LL i = L; i <= R; i++) {
LL up = i * x - y, down = i * y;
LL g = gcd(up, down);
path[dep] = i;
dfs(dep + 1, mdep, up / g, down / g);
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> a >> b;
LL g = gcd(a, b);
a /= g, b /= g;
for (LL mdep = 1;; mdep++) {
dfs(1, mdep, a, b);
if (ans[0] > 0) {
for (LL i = 1; i <= mdep; i++)
cout << ans[i] << ' ';
return 0;
}
ans[0] = 0;
}
return 0;
}最优化剪枝:少枚举2层搜索树
若仔细分析优化一层搜索树的思路,会发现当递归枚举到 mdep-1 层时,就已经有 x y = 1 X + 1 Y \frac{x}{y}=\frac{1}{X}+\frac{1}{Y} yx=X1+Y1 ,所以 k x k y = X + Y X Y \frac{kx}{ky}=\frac{X+Y}{XY} kykx=XYX+Y , k k k 是正整数,于是就有
{ X + Y = k x X Y = k y \begin{cases}X+Y=kx\\XY=ky\end{cases} {X+Y=kxXY=ky ,所以 X X X 、 Y Y Y 是同一个二元一次方程 Y 2 − k x Y + k y = 0 Y^2-kxY+ky=0 Y2−kxY+ky=0 的一个解。
所以 Δ = k 2 x 2 − 4 k y \Delta=\sqrt{k^2x^2-4ky} Δ=k2x2−4ky ,使得 Δ > 0 \Delta>0 Δ>0 ,就要有 k > 4 y x 2 k>\frac{4y}{x^2} k>x24y 。
此时方程就有一组解: X = k x + Δ 2 , Y = k x − Δ 2 X=\frac{kx+\sqrt{\Delta}}{2},Y=\frac{kx-\sqrt{\Delta}}{2} X=2kx+Δ ,Y=2kx−Δ 。
因此只需要从 4 y x \frac{4y}{x} x4y 开始枚举出 k k k ,发现合适的 k k k 时就可以找到最后 2 个分数,尽管有枚举成本,但比起遍历第 mdep 层的搜索树简直是小巫见大巫。
但 k k k 只有下界 4 y x 2 \frac{4y}{x^2} x24y 无法枚举,还需要知道上界。
观察 { X + Y = k x X Y = k y \begin{cases}X+Y=kx\\XY=ky\end{cases} {X+Y=kxXY=ky 可发现 k = X + Y x = X Y y k=\frac{X+Y}{x}=\frac{XY}{y} k=xX+Y=yXY ,而在没有找到答案之前, X , Y X,Y X,Y 可达 10 7 10^7 107 ,所以 X + Y < 2 × 10 7 , X Y < ( 10 7 ) 2 X+Y<2\times 10^7,XY<(10^7)^2 X+Y<2×107,XY<(107)2 。
因此可设一个变量 mmax=1e7 ,min(2*mmax/x,mmax*mmax/y) 作为 k k k 的上界。也不用担心 mmax 太大,每次找到答案都可更新 mmax=ans[mdep] 缩小上界。
在枚举 k k k 时还要注意一些细节:
- Δ ≠ 0 \Delta\ne 0 Δ=0 ,否则 X = Y X=Y X=Y ,这是不允许的。
- ⌊ Δ × Δ ⌋ = k 2 x 2 − 4 k y \lfloor\sqrt{\Delta\times \Delta}\rfloor= k^2x^2-4ky ⌊Δ×Δ ⌋=k2x2−4ky ,否则 X X X 和 Y Y Y 都是浮点数会导致答案错误。
- ( k x ± Δ ) m o d 2 ≠ 0 (kx\pm\sqrt{\Delta})\bmod 2\ne0 (kx±Δ )mod2=0 ,否则 X X X 和 Y Y Y 都是浮点数会导致答案错误。
- 题目可能一开始就给 a b = 1 ? \frac{a}{b}=\frac{1}{?} ba=?1 ,所以需要做特判,否则会出错。
所以P1763 埃及分数 - 洛谷 最终参考程序:
cpp
#include <bits/stdc++.h>
using namespace std;
using LL = long long;
LL path[1010], ans[1010];
LL a, b;
LL mmax = 1e7; // 新增递归出口的枚举边界参考
LL gcd(LL a, LL b) {
return b ? gcd(b, a % b) : a;
}
void dfs(LL dep, LL mdep, LL x, LL y) {
// 优化递归出口
if (dep + 1 >= mdep) {
// 4y/(x*x)向上取整
LL L = (4 * y + x * x - 1) / (x * x);
LL R = min(2 * mmax / x, mmax * mmax / y);
for (LL k = L; k < R; k++) {
// Delta,德尔塔
LL dlt = sqrt(k * k * x * x - 4 * k * y);
// dlt需是完全平方数
if (dlt * dlt != k * k * x * x - 4 * k * y)
continue;
// dlt不为0,否则X==Y不符合条件
if (dlt == 0)
continue;
// 排除X,Y不为整数的情况
if ((k * x - dlt) % 2 || (k * x + dlt) % 2)
continue;
LL X = (k * x - dlt) / 2, Y = (k * x + dlt) / 2;
path[dep] = X, path[mdep] = Y;
// 新情况比原来的情况更优则更新
if (ans[0] == 0 || path[mdep] < ans[mdep]) {
for (LL i = 1; i <= mdep; i++)
ans[i] = path[i];
mmax = ans[mdep];
ans[0] = mdep;
}
// 找到最小的即可break
break;
}
return;
}
LL L = max(path[dep - 1], y / x) + 1;
LL R = (mdep - dep + 1) * y / x;
if (ans[0] > 0)
R = min(ans[mdep], R);
for (LL i = L; i <= R; i++) {
LL up = i * x - y, down = i * y;
LL g = gcd(up, down);
path[dep] = i;
dfs(dep + 1, mdep, up / g, down / g);
}
}
int main() {
// freopen("in.in", "r", stdin);
cin >> a >> b;
LL g = gcd(a, b);
a /= g, b /= g;
if (a == 1) { // 题目可能设置边界条件
cout << b;
return 0;
}
for (LL mdep = 1;; mdep++) { // 迭代加深dfs
dfs(1, mdep, a, b);
if (ans[0] > 0) {
for (LL i = 1; i <= mdep; i++)
cout << ans[i] << ' ';
return 0;
}
ans[0] = 0;
}
return 0;
}这个参考程序不知道多少年后又会被新数据给 hack 掉,这也是老题的特点,测试样例是活的,时代是进步的。
迭代加深反例:P2730 魔板 - 洛谷
P2730 [IOI 1996 / USACO3.2 魔板 Magic Squares - 洛谷](https://www.luogu.com.cn/problem/P2730)
迭代加深 dfs 不能全面代替 bfs ,因为迭代加深 dfs 相比 bfs ,会重复遍历一部分结点。例如这个魔板,可使用哈希表存储状态,使用函数指针存储转动魔板的操作。
超时的迭代加深dfs参考
这里给出一个超时的迭代加深 dfs :
cpp
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
void turnA(string &st) {
swap(st[0], st[7]), swap(st[1], st[6]);
swap(st[2], st[5]), swap(st[3], st[4]);
}
void turnB(string &st) {
char a = st[3], b = st[4];
for (int i = 2; i >= 0; i--)
st[i + 1] = st[i];
for (int i = 5; i <= 7; i++)
st[i - 1] = st[i];
st[0] = a, st[7] = b;
}
void turnC(string &st) {
char a = st[1], b = st[2], c = st[5], d = st[6];
st[2] = a, st[5] = b, st[6] = c, st[1] = d;
}
void (*turn[3])(string &) = {turnA, turnB, turnC};
string start = "12345678", aim;
int path[1010] = {0};
bool dfs(int dep, int mdep, string &st) {
if (dep == mdep)
return st == aim;
string tmp = st;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 8; j++)
tmp[j] = st[j];
turn[i](tmp);
path[dep] = i;
if (dfs(dep + 1, mdep, tmp))
return true;
}
return false;
}
int main() {
// freopen("in.in", "r", stdin);
for (int i = 0; i < 8; i++) {
char ch;
cin >> ch;
aim += ch;
}
// 迭代加深dfs
string st = start;
for (int mdep = 1;; mdep++) {
for (int i = 0; i < 8; i++)
st[i] = start[i];
if (dfs(1, mdep, st)) {
cout << mdep - 1 << endl;
for (int i = 1; i < mdep; i++)
cout << char(path[i] + 'A');
return 0;
}
}
return 0;
}在这个样例超时:
输入:
3 4 2 1 5 6 7 8输出:
18
ABCABBBCBBBCBCABCB迭代加深dfs支持的搜索树高度分析
迭代加深 dfs 能支持的最大深度并没有一个固定的数值,它取决于以下因素:
-
搜索空间大小
深度每增加 1,节点数可能指数增长(分支因子 )。若分支因子较大,深度稍大(如 20 ∼ 30 20\sim 30 20∼30 )就可能产生天文数字的节点,导致时间超限。这题魔板尽管数据量是 18 层搜索树,但 3 个转动操作需要开辟函数栈帧,会带来一定的时间开销,所以深度为 18 时就会超时。
分支因子是搜索树中每个节点的平均子节点数量,用于衡量状态空间扩展的宽度。
-
剪枝强度
高效的剪枝可以大幅减少实际扩展节点数,从而支持更大的深度。例如在P1784 数独 - 洛谷、 P1379 八数码难题 - 洛谷 等启发式剪枝强的题目中,深度可达上百。
-
内存限制
迭代加深本身只记录当前路径(深度 × \times × 状态空间),空间开销小,因此深度受限于栈空间(通常递归深度几千没问题)。但若状态本身很大(如棋盘),深度也会受限。
-
时间限制
算法竞赛中常见迭代加深的深度在 10 ∼ 50 10\sim 50 10∼50 之间,经过强剪枝后可处理到 100 左右。极少数问题(如某些搜索题)深度可达几百,但往往需要极小的分支因子和强剪枝。
理论上迭代加深 dfs 可支持任意深度,但实际能跑的深度受问题分支因子、剪枝能力和时间限制共同决定,没有统一的上限。
魔板朴素bfs参考程序
P2730 [IOI 1996 / USACO3.2 魔板 Magic Squares - 洛谷](https://www.luogu.com.cn/problem/P2730) 参考:
cpp
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
void turnA(string &st) {
swap(st[0], st[7]), swap(st[1], st[6]);
swap(st[2], st[5]), swap(st[3], st[4]);
}
void turnB(string &st) {
char a = st[3], b = st[4];
for (int i = 2; i >= 0; i--)
st[i + 1] = st[i];
for (int i = 5; i <= 7; i++)
st[i - 1] = st[i];
st[0] = a, st[7] = b;
}
void turnC(string &st) {
char a = st[1], b = st[2], c = st[5], d = st[6];
st[2] = a, st[5] = b, st[6] = c, st[1] = d;
}
void (*turn[3])(string &) = {turnA, turnB, turnC};
string aim;
unordered_map<string, int> dp;
unordered_map<string, bool> vis;
unordered_map<string, pair<string, int>> pt;
int bfs() {
queue<string> q;
q.push("12345678"), vis["12345678"] = 1;
dp["12345678"] = 0, pt["12345678"] = {"", -1};
while (!q.empty()) {
string np = q.front();
q.pop();
if (np == aim)
return dp[aim];
for (int i = 0; i < 3; i++) {
string tmp = np;
turn[i](tmp);
if (vis.count(tmp))
continue;
vis[tmp] = 1;
dp[tmp] = dp[np] + 1;
pt[tmp] = {np, i};
q.push(tmp);
if (tmp == aim)
return dp[aim];
}
}
return dp[aim];
}
int main() {
// freopen("in.in", "r", stdin);
for (int i = 0; i < 8; i++) {
char ch;
cin >> ch;
aim += ch;
}
cout << bfs() << endl;
stack<int> sk;
for (int op = pt[aim].second; op != -1;) {
sk.push(op);
op = pt[pt[aim].first].second;
aim = pt[aim].first;
}
while (sk.size()) {
cout << char(sk.top() + 'A');
sk.pop();
}
return 0;
}OJ参考
P2730 [IOI 1996 / USACO3.2 魔板 Magic Squares - 洛谷](https://www.luogu.com.cn/problem/P2730)