目录
[2.1 流程总览](#2.1 流程总览)
[2.1.1 完整流程图(离线+在线全链路)](#2.1.1 完整流程图(离线+在线全链路))
[2.1.2 各模块协同逻辑(数据源→输出全链路拆解)](#2.1.2 各模块协同逻辑(数据源→输出全链路拆解))
[2.2 模块1:数据源加载(RAG的知识来源)](#2.2 模块1:数据源加载(RAG的知识来源))
[2.2.1 支持的数据源类型](#2.2.1 支持的数据源类型)
[2.2.2 数据源加载工具与实战](#2.2.2 数据源加载工具与实战)
[2.2.2.1 入门级工具(LangChain文件加载器)](#2.2.2.1 入门级工具(LangChain文件加载器))
[2.2.2.2 企业级工具(批量加载/实时同步工具)](#2.2.2.2 企业级工具(批量加载/实时同步工具))
[2.2.2.3 多数据源整合实战(代码可运行,带注释)](#2.2.2.3 多数据源整合实战(代码可运行,带注释))
[2.2.3 数据源质量评估与优化](#2.2.3 数据源质量评估与优化)
[2.2.3.1 无效数据识别与过滤](#2.2.3.1 无效数据识别与过滤)
[2.2.3.2 数据源更新策略](#2.2.3.2 数据源更新策略)
[2.3 模块2:文档预处理(决定检索质量的核心)](#2.3 模块2:文档预处理(决定检索质量的核心))
[2.3.1 预处理核心目标与流程](#2.3.1 预处理核心目标与流程)
[2.3.2 步骤1:文本清洗(实战代码+详细注释)](#2.3.2 步骤1:文本清洗(实战代码+详细注释))
[2.3.2.1 无效字符/格式去除](#2.3.2.1 无效字符/格式去除)
[2.3.2.2 编码标准化与去重](#2.3.2.2 编码标准化与去重)
[2.3.2.3 多语言文本清洗](#2.3.2.3 多语言文本清洗)
[2.3.3 步骤2:文档拆分(Chunk拆分策略详解)](#2.3.3 步骤2:文档拆分(Chunk拆分策略详解))
[2.3.3.1 拆分核心原则](#2.3.3.1 拆分核心原则)
[2.3.3.2 主流拆分策略](#2.3.3.2 主流拆分策略)
[2.3.3.3 拆分参数调优](#2.3.3.3 拆分参数调优)
[2.3.3.4 实战代码(Markdown/PDF拆分)](#2.3.3.4 实战代码(Markdown/PDF拆分))
[2.3.4 步骤3:元数据标注(适配运维/检索过滤)](#2.3.4 步骤3:元数据标注(适配运维/检索过滤))
[2.3.4.1 元数据核心字段设计](#2.3.4.1 元数据核心字段设计)
[2.3.4.2 元数据标注实战代码](#2.3.4.2 元数据标注实战代码)
[2.3.4.3 元数据与检索过滤的关联逻辑](#2.3.4.3 元数据与检索过滤的关联逻辑)
[2.3.5 预处理效果评估与优化技巧](#2.3.5 预处理效果评估与优化技巧)
[2.4 模块3:向量生成(文本→计算机可理解的语言)](#2.4 模块3:向量生成(文本→计算机可理解的语言))
[2.4.1 向量生成核心原理(通俗解读)](#2.4.1 向量生成核心原理(通俗解读))
[2.4.2 主流嵌入模型选型与对比](#2.4.2 主流嵌入模型选型与对比)
[2.4.2.1 入门级模型(Sentence-BERT:all-MiniLM-L6-v2)](#2.4.2.1 入门级模型(Sentence-BERT:all-MiniLM-L6-v2))
[2.4.2.2 企业级模型(OpenAI Embeddings/国产模型)](#2.4.2.2 企业级模型(OpenAI Embeddings/国产模型))
[2.4.2.3 模型选型原则](#2.4.2.3 模型选型原则)
[2.4.3 向量生成实战](#2.4.3 向量生成实战)
[2.4.3.1 单文本/批量文本向量生成](#2.4.3.1 单文本/批量文本向量生成)
[2.4.3.2 向量归一化与优化](#2.4.3.2 向量归一化与优化)
[2.4.3.3 向量维度选择与适配](#2.4.3.3 向量维度选择与适配)
[2.4.4 向量质量评估方法](#2.4.4 向量质量评估方法)
[2.5 模块4:向量存储(向量数据库实战)](#2.5 模块4:向量存储(向量数据库实战))
[2.5.1 向量数据库核心作用与原理](#2.5.1 向量数据库核心作用与原理)
[2.5.1.1 向量数据库与传统数据库的区别](#2.5.1.1 向量数据库与传统数据库的区别)
[2.5.1.2 向量索引的核心逻辑(加速检索)](#2.5.1.2 向量索引的核心逻辑(加速检索))
[2.5.2 主流向量数据库选型与对比(适配不同场景)](#2.5.2 主流向量数据库选型与对比(适配不同场景))
[2.5.2.1 入门级(Chroma/FAISS)](#2.5.2.1 入门级(Chroma/FAISS))
[2.5.2.2 企业级(Milvus/Pinecone)](#2.5.2.2 企业级(Milvus/Pinecone))
[2.5.2.3 选型关键指标](#2.5.2.3 选型关键指标)
[2.5.3 向量数据库实战(分场景代码)](#2.5.3 向量数据库实战(分场景代码))
[2.5.3.1 Chroma实战(入门级:初始化/存储/查询)](#2.5.3.1 Chroma实战(入门级:初始化/存储/查询))
[2.5.3.2 Milvus实战(企业级:分布式部署/批量操作)](#2.5.3.2 Milvus实战(企业级:分布式部署/批量操作))
[2.5.3.3 向量与元数据关联存储](#2.5.3.3 向量与元数据关联存储)
[2.5.4 向量数据库运维技巧(适合运维人员)](#2.5.4 向量数据库运维技巧(适合运维人员))
[2.5.4.1 数据持久化与备份](#2.5.4.1 数据持久化与备份)
[2.5.4.2 性能优化](#2.5.4.2 性能优化)
[2.5.4.3 故障排查与解决](#2.5.4.3 故障排查与解决)
[2.6 模块5:检索匹配(精准找到相关知识)](#2.6 模块5:检索匹配(精准找到相关知识))
[2.6.1 检索核心逻辑与评估指标](#2.6.1 检索核心逻辑与评估指标)
[2.6.1.1 召回率与精确率](#2.6.1.1 召回率与精确率)
[2.6.1.2 相似度计算方法](#2.6.1.2 相似度计算方法)
[2.6.2 基础检索策略实战](#2.6.2 基础检索策略实战)
[2.6.2.1 稠密检索(向量检索)代码实现](#2.6.2.1 稠密检索(向量检索)代码实现)
[2.6.2.2 稀疏检索(TF-IDF/BM25)代码实现](#2.6.2.2 稀疏检索(TF-IDF/BM25)代码实现)
[2.6.2.3 基础检索的优缺点与适用场景](#2.6.2.3 基础检索的优缺点与适用场景)
[2.6.3 高级检索策略(提升检索效果)](#2.6.3 高级检索策略(提升检索效果))
[2.6.3.1 混合检索(稀疏+稠密)实战代码](#2.6.3.1 混合检索(稀疏+稠密)实战代码)
[2.6.3.2 重排序策略(RRF/Cross-BERT)详解与代码](#2.6.3.2 重排序策略(RRF/Cross-BERT)详解与代码)
[2.6.3.3 元数据过滤检索](#2.6.3.3 元数据过滤检索)
[2.6.3.4 多轮检索(RAG-Fusion)实战](#2.6.3.4 多轮检索(RAG-Fusion)实战)
[2.6.4 检索策略调优技巧](#2.6.4 检索策略调优技巧)
[2.7 模块6:大模型生成与结果优化(最终输出)](#2.7 模块6:大模型生成与结果优化(最终输出))
[2.7.1 生成核心逻辑](#2.7.1 生成核心逻辑)
[2.7.1.1 提示词工程核心技巧](#2.7.1.1 提示词工程核心技巧)
[2.7.1.2 检索结果与提示词的拼接逻辑](#2.7.1.2 检索结果与提示词的拼接逻辑)
[2.7.2 大模型选型与调用实战](#2.7.2 大模型选型与调用实战)
[2.7.2.1 入门级(开源模型:Llama 2/Mistral)](#2.7.2.1 入门级(开源模型:Llama 2/Mistral))
[2.7.2.2 企业级(API调用:OpenAI/通义千问/文心一言)](#2.7.2.2 企业级(API调用:OpenAI/通义千问/文心一言))
[2.7.2.3 大模型调用代码(带异常处理)](#2.7.2.3 大模型调用代码(带异常处理))
[2.7.3 结果优化技巧](#2.7.3 结果优化技巧)
[2.7.3.1 Citations引用生成](#2.7.3.1 Citations引用生成)
[2.7.3.2 格式标准化](#2.7.3.2 格式标准化)
[2.7.3.3 幻觉抑制与冲突处理](#2.7.3.3 幻觉抑制与冲突处理)
[2.7.3.4 无检索结果时的兜底方案](#2.7.3.4 无检索结果时的兜底方案)
[2.7.4 生成效果评估与调优](#2.7.4 生成效果评估与调优)
[2.8 模块7:结果输出与交互](#2.8 模块7:结果输出与交互)
[2.8.1 输出格式适配](#2.8.1 输出格式适配)
[2.8.2 前端简单交互实现(适合前端开发者,代码实战)](#2.8.2 前端简单交互实现(适合前端开发者,代码实战))
[2.8.3 批量输出与导出功能](#2.8.3 批量输出与导出功能)
一、前言
随着大语言模型(LLM)的爆发式增长,如何让模型在保持强大生成能力的同时,能够准确、实时地访问和利用私有或专业领域知识,成为了一个核心挑战。检索增强生成(Retrieval-Augmented Generation, RAG)正是解决这一问题的关键技术范式。
RAG并非一个单一模型,而是一套系统工程。它巧妙地结合了信息检索与大语言模型的优势:首先从一个知识库中检索与用户问题最相关的信息片段,然后将这些信息作为"上下文"提供给大语言模型,从而生成更准确、更具时效性且可溯源的回答。与单纯的微调相比,RAG无需重复训练模型,成本更低,知识更新更灵活,是构建企业级、场景化AI应用的基石。
本文将带领读者深入RAG系统的内部,从数据加载、预处理、向量化、存储、检索到最终生成与输出,全链路拆解每一个核心模块。我们将结合理论讲解、主流技术选型对比,并提供大量带详细注释的可运行代码,力求让读者不仅能理解RAG"是什么",更能亲手搭建起一个完整的RAG应用,为后续的工程实践和优化打下坚实基础。
二、RAG系统工作流程详细解析
2.1 流程总览
2.1.1 完整流程图(离线+在线全链路)
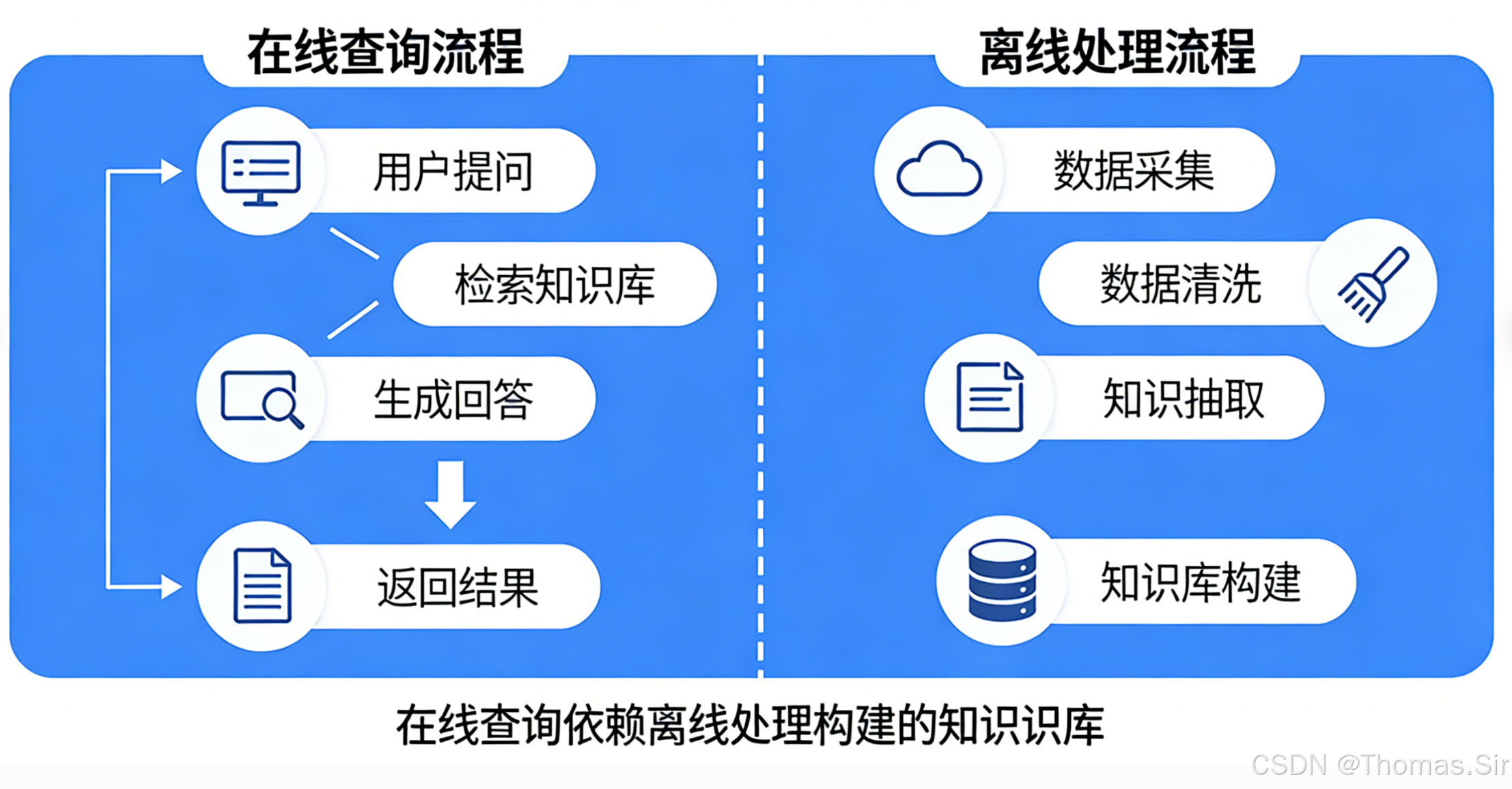
RAG系统的工作流程可以清晰地划分为两个阶段:离线处理阶段 和在线查询阶段。
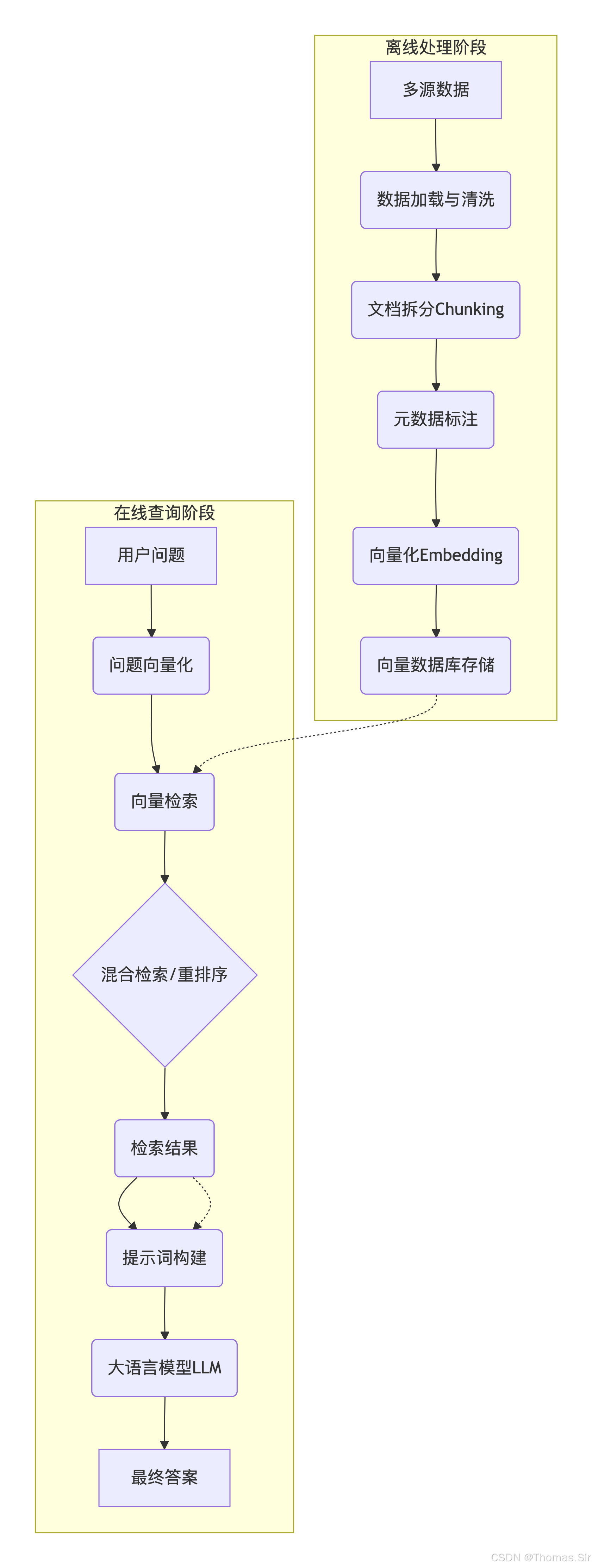
2.1.2 各模块协同逻辑(数据源→输出全链路拆解)
-
离线处理:将原始知识文档(PDF、数据库、网页等)转化为计算机可高效检索的形态。
-
数据源加载:读取不同来源、不同格式的原始数据。
-
文档预处理:清洗无效字符、将长文档拆分为语义完整的文本块(Chunk),并附上来源、时间等元数据。
-
向量生成:使用嵌入模型将每个文本块转化为固定维度的向量。这个向量是文本的"语义指纹",向量空间中的距离反映了文本之间的语义相似度。
-
向量存储:将生成的向量及其对应的原始文本块、元数据存入专门的向量数据库中,并构建高效的索引以加速检索。
-
-
在线查询:响应用户问题,从知识库中检索相关信息并生成答案。
-
问题输入:用户提出一个问题。
-
问题向量化 :使用与离线处理阶段完全相同的嵌入模型,将用户问题也转化为向量。
-
检索匹配:在向量数据库中,通过计算问题向量与所有存储向量的相似度,快速找到最相似的Top-K个文本块。高级策略还会结合关键词检索(BM25)和重排序来提升准确性。
-
提示词构建:将检索到的相关文本块与用户问题、系统指令(Prompt)拼接成一个完整的提示词。
-
大模型生成:将提示词发送给大语言模型(LLM),让LLM基于提供的上下文生成最终的自然语言回答。
-
结果输出:将生成的答案以用户期望的格式(网页、API JSON等)返回,并可附带引用来源。
-
2.2 模块1:数据源加载(RAG的知识来源)
2.2.1 支持的数据源类型
RAG系统的知识库可以来源于多种数据格式:
-
2.2.1.1 非结构化数据:最常见的数据类型,没有预定义的数据模型,如PDF、Word、Markdown、纯文本文件、HTML网页等。
-
2.2.1.2 结构化数据:以行和列的形式存储,如CSV文件、Excel表格、关系型数据库(MySQL, PostgreSQL)。这类数据通常需要通过SQL查询先转化为文本描述再进行处理。
-
2.2.1.3 半结构化数据:介于结构化和非结构化之间,如JSON、XML、通过API接口返回的数据。它们有结构但不够严格,解析时需要按需提取关键信息。
2.2.2 数据源加载工具与实战
2.2.2.1 入门级工具(LangChain文件加载器)
LangChain提供了非常方便的文档加载器,支持上百种格式。
python
# 安装依赖: pip install langchain pypdf python-docx
from langchain_community.document_loaders import TextLoader, PyPDFLoader, UnstructuredWordDocumentLoader
# 加载TXT文件
txt_loader = TextLoader("./data/sample.txt", encoding="utf-8")
txt_docs = txt_loader.load()
# 加载PDF文件
pdf_loader = PyPDFLoader("./data/rag_intro.pdf")
pdf_docs = pdf_loader.load()
# 加载Word文件
docx_loader = UnstructuredWordDocumentLoader("./data/report.docx")
docx_docs = docx_loader.load()
print(f"TXT文档数量: {len(txt_docs)}")
print(f"PDF文档数量: {len(pdf_docs)}")
print(f"Word文档数量: {len(docx_docs)}")2.2.2.2 企业级工具(批量加载/实时同步工具)
对于生产环境,需要处理海量数据,可以使用以下工具:
-
Airflow / Prefect:用于编排和管理批处理数据管道,定时从各种数据源(S3、数据库)拉取数据。
-
Debezium:用于实现数据库的Change Data Capture(CDC),实时捕获MySQL/PostgreSQL中的数据变更,并同步到向量数据库中。
-
LlamaIndex:相比LangChain,提供了更丰富的数据连接器(Data Connectors),特别是对各类数据源的结构化解析能力更强。
2.2.2.3 多数据源整合实战(代码可运行,带注释)
以下示例展示了如何从本地文件夹、MySQL数据库和API接口中加载数据。
python
# 安装依赖: pip install pymysql requests langchain
import os
import requests
import pymysql
from langchain_core.documents import Document
def load_local_files(directory_path):
"""从本地文件夹加载所有PDF和TXT文件"""
documents = []
for filename in os.listdir(directory_path):
filepath = os.path.join(directory_path, filename)
if filename.endswith('.txt'):
with open(filepath, 'r', encoding='utf-8') as f:
text = f.read()
documents.append(Document(page_content=text, metadata={"source": filename, "type": "local_txt"}))
elif filename.endswith('.pdf'):
# 简化处理,实际应使用PyPDFLoader
documents.append(Document(page_content=f"PDF内容来自 {filename}", metadata={"source": filename, "type": "local_pdf"}))
return documents
def load_from_mysql():
"""从MySQL数据库加载数据,这里假设有一张'knowledge'表"""
connection = pymysql.connect(host='localhost',
user='your_user',
password='your_password',
database='your_db',
charset='utf8mb4')
documents = []
try:
with connection.cursor() as cursor:
sql = "SELECT id, title, content FROM knowledge WHERE is_active=1"
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
doc_id, title, content = row
documents.append(Document(page_content=content, metadata={"source": f"mysql_{doc_id}", "title": title, "type": "mysql"}))
finally:
connection.close()
return documents
def load_from_api():
"""从外部API加载数据"""
response = requests.get("https://jsonplaceholder.typicode.com/posts")
if response.status_code == 200:
posts = response.json()
documents = []
for post in posts[:5]: # 只取前5个作为示例
content = f"Title: {post['title']}\nBody: {post['body']}"
documents.append(Document(page_content=content, metadata={"source": f"api_{post['id']}", "type": "api"}))
return documents
else:
print(f"API请求失败: {response.status_code}")
return []
if __name__ == "__main__":
# 整合所有数据源
all_docs = []
all_docs.extend(load_local_files("./local_data"))
all_docs.extend(load_from_mysql())
all_docs.extend(load_from_api())
print(f"成功整合加载 {len(all_docs)} 个文档。")
for doc in all_docs[:3]:
print(f"来源: {doc.metadata['source']}, 内容预览: {doc.page_content[:50]}...")2.2.3 数据源质量评估与优化
2.2.3.1 无效数据识别与过滤
-
空文档/极短文档:内容长度小于指定阈值(如50字符)的文档应被过滤掉。
-
占位符/错误信息:检测文档中是否包含"404 Not Found"、"暂无数据"等无效关键词,并标记或过滤。
-
重复文档:通过文档内容的哈希值(如MD5)或相似度比对,识别并去重。
2.2.3.2 数据源更新策略
-
手动触发:适合初始化或低频更新,通过脚本或UI按钮手动触发重新加载和处理。
-
定时任务:使用Cron或调度框架(如Airflow)定期(如每天凌晨)检查数据源(如数据库表、文件系统)的更新时间,如有变更则进行增量或全量更新。
-
自动/实时同步:对于数据库,使用CDC工具(如Debezium)捕获数据变更,通过消息队列(如Kafka)触发RAG系统的增量更新,确保知识库的实时性。
2.3 模块2:文档预处理(决定检索质量的核心)
2.3.1 预处理核心目标与流程
预处理的目标是将原始文档转换为适合向量化和检索的、高质量的文本块。其核心流程为:
文本清洗 -> 文档拆分(Chunking) -> 元数据标注。
2.3.2 步骤1:文本清洗(实战代码+详细注释)
python
import re
import unicodedata
def clean_text(text: str) -> str:
"""
对文本进行清洗,去除HTML标签、特殊符号、标准化编码
Args:
text: 原始文本
Returns:
清洗后的文本
"""
# 1. 去除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 2. 去除URL
text = re.sub(r'http\S+|www\.\S+', '', text)
# 3. 去除特殊符号(保留中英文、数字、常用标点)
# \u4e00-\u9fff 匹配中文,a-zA-Z 匹配英文,0-9 匹配数字,\s 匹配空白,.,!?;: 匹配标点
text = re.sub(r'[^\u4e00-\u9fff\w\s.,!?;:()\[\]-]', '', text)
# 4. 去除多余的空格和换行
text = re.sub(r'\s+', ' ', text).strip()
# 5. 编码标准化,例如将全角字符转半角,NFKC规范化
text = unicodedata.normalize('NFKC', text)
return text
# 示例
dirty_text = """
<div>Hello, 世界!</div>
<a href="http://example.com">点击这里</a>
这是一个★测试★文本,包含特殊符号♠和大量 空格。
"这是中文引号"
"""
cleaned = clean_text(dirty_text)
print(cleaned)
# 输出: Hello, 世界! 这是一个测试文本,包含特殊符号和大量空格。 "这是中文引号"2.3.2.1 无效字符/格式去除
如上代码所示,通过正则表达式可以灵活地去除HTML标签、URL等不需要的内容。
2.3.2.2 编码标准化与去重
-
编码标准化 :使用
unicodedata.normalize将文本统一为NFKC或NFKD格式,处理全角/半角字符差异。 -
去重:在数据清洗后,可以使用一个字典来存储已经处理过的文本内容,通过内容的哈希值来判断是否重复。
2.3.2.3 多语言文本清洗
对于中英文混合的文本,上述正则表达式[\u4e00-\u9fff\w\s.,!?;:()\[\]-]能同时保留中文字符、英文单词(\w)和常用标点,是一种简单有效的适配方式。
2.3.3 步骤2:文档拆分(Chunk拆分策略详解)
2.3.3.1 拆分核心原则
-
语义完整性:每个文本块本身应是一个完整且可独立理解的语义单元,比如一个段落、一个列表项或一个章节。避免将一个完整的句子或概念拆分到两个不同的块中。
-
检索精准性:块的大小要适中。块太大,向量表示会过于模糊,检索的颗粒度不够;块太小,会丢失上下文信息,不利于LLM生成连贯的答案。
2.3.3.2 主流拆分策略
-
按固定长度拆分:最简单直接,通过字符数或token数进行拆分。优点是实现简单,缺点是容易破坏语义。
-
按句子拆分:使用句号、问号等作为分隔符,保证每个块是一个完整的句子。可通过NLP工具(如NLTK、spaCy)实现。
-
按段落/章节拆分 :使用
\n\n等换行符作为分隔,保留段落结构。对于Markdown、HTML等结构化文档,可以基于标题层级(如#,##)进行智能拆分。
2.3.3.3 拆分参数调优
-
chunk_size:每个文本块的大小。通常以token数衡量(如OpenAI模型1 token≈0.75个英文单词)。常见范围在256-1024个token之间。
-
chunk_overlap :相邻文本块之间的重叠字符数或token数。目的是保留上下文边界,防止关键信息正好落在拆分点上而丢失。通常设置为
chunk_size的10%~20%。
2.3.3.4 实战代码(Markdown/PDF拆分)
python
# 安装依赖: pip install langchain langchain-text-splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter, MarkdownHeaderTextSplitter
from langchain_community.document_loaders import PyPDFLoader
# 1. 通用文本拆分器,基于递归方式,优先按段落、句子、单词拆分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 每个块的大小,这里用字符数,生产环境建议用token
chunk_overlap=20,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""],
length_function=len,
)
long_text = "这是一段很长的文本。" * 50
chunks = text_splitter.split_text(long_text)
print(f"通用拆分得到 {len(chunks)} 个文本块。")
print(chunks[0])
# 2. 针对Markdown的标题拆分器
markdown_doc = """
# 第一章 RAG简介
## 1.1 什么是RAG
RAG是一种结合检索和生成的技术。
## 1.2 为什么需要RAG
为了解决LLM的幻觉和知识滞后问题。
# 第二章 核心组件
## 2.1 检索器
负责从知识库中找相关信息。
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_doc)
for split in md_header_splits:
print(f"元数据: {split.metadata}, 内容: {split.page_content[:50]}...")2.3.4 步骤3:元数据标注(适配运维/检索过滤)
2.3.4.1 元数据核心字段设计
| 字段名 | 类型 | 描述 | 示例 |
|---|---|---|---|
doc_id |
string | 文档的唯一标识符 | "pdf_12345" |
source |
string | 数据来源,如文件名、URL、表名 | "annual_report_2023.pdf" |
category |
string | 文档类别,用于过滤 | "finance", "technology" |
timestamp |
datetime | 文档创建或更新时间 | 2023-12-31 |
author |
string | 文档作者 | "John Doe" |
chunk_index |
int | 当前块在原始文档中的序号 | 0, 1, 2... |
2.3.4.2 元数据标注实战代码
python
from langchain_core.documents import Document
import hashlib
import time
def create_document_with_metadata(content: str, source_file: str, category: str):
"""为文档块创建带元数据的Document对象"""
doc_id = hashlib.md5(f"{source_file}_{time.time()}".encode()).hexdigest()
metadata = {
"doc_id": doc_id,
"source": source_file,
"category": category,
"timestamp": time.time(),
"char_length": len(content),
"chunk_index": None # 稍后在拆分循环中设置
}
return Document(page_content=content, metadata=metadata)
# 假设我们从PDF加载了内容并进行了拆分
dummy_content = "这是PDF文件的第一部分内容。"
doc1 = create_document_with_metadata(dummy_content, "my_pdf.pdf", "technical")
print(doc1.metadata)2.3.4.3 元数据与检索过滤的关联逻辑
在检索阶段,我们可以利用这些元数据进行预过滤,缩小检索范围。例如:
-
category = "finance":只从金融类文档中检索。 -
timestamp > "2023-01-01":只检索近一年的文档。 -
source contains "official":只从官方来源检索。
这可以极大地提高检索的准确性和效率,是构建企业级RAG系统的关键一环。
2.3.5 预处理效果评估与优化技巧
-
人工审查:随机抽样检查清洗和拆分后的文本块,确保语义完整、无噪声。
-
端到端测试:构建一个简单的检索器,针对一些典型问题,观察检索结果Top-K的文本块是否与问题高度相关。如果不相关,则可能是拆分粒度、元数据设计或清洗环节存在问题。
-
优化技巧:
-
对于代码块、表格等特殊格式,使用专门的解析器,而不是普通文本拆分。
-
对于标题和摘要,可以给予更高的权重(例如,在元数据中标记为"标题")。
-
尝试不同的拆分器和参数,通过量化指标(如Hit Rate, MRR)来选择最优配置。
-
2.4 模块3:向量生成(文本→计算机可理解的语言)
2.4.1 向量生成核心原理(通俗解读)
向量生成(嵌入)的核心是将一段文本映射到一个多维空间中的一个点。这个点的坐标(即向量)代表了文本的"语义"。
-
2.4.1.1 词嵌入与句嵌入的区别
-
词嵌入 :为单个词生成向量,如
Word2Vec。"king"和"queen"的向量会很接近,因为它们语义相似。 -
句嵌入 :为整个句子、段落或文档生成一个向量。它需要理解词与词之间的关系,从而捕捉整体的语义。
Sentence-BERT就是典型的句嵌入模型。
-
-
2.4.1.2 语义向量的核心价值
句嵌入向量强大的地方在于,它在向量空间中编码了文本的"含义"。如果两段话意思相近,无论它们使用的具体词汇是否相同,它们的向量在空间中的距离也会很近。这使得我们可以通过简单的数学计算(如余弦相似度)来实现语义检索。
2.4.2 主流嵌入模型选型与对比
2.4.2.1 入门级模型(Sentence-BERT:all-MiniLM-L6-v2)
-
特点:开源、免费、轻量级(~80MB),在CPU上就能跑得很快,适合学习和小型项目。
-
向量维度:384维。
-
来源:HuggingFace。
2.4.2.2 企业级模型(OpenAI Embeddings/国产模型)
-
OpenAI text-embedding-3-small/large:闭源,通过API调用,效果好,维度可选(1536/3072),但需要付费且存在数据隐私风险。
-
国产模型 :如智谱AI的
embedding-2、阿里的text-embedding-v1、百度文心Embedding-V1。国内访问速度快,符合国内数据合规要求。
2.4.2.3 模型选型原则
-
速度:在保证效果的前提下,优先选择推理速度快的模型。轻量级模型(如MiniLM)适合实时检索,大模型(如OpenAI)适合离线处理。
-
效果:通过MTEB(Massive Text Embedding Benchmark)排行榜来参考模型在不同任务(如检索、聚类)上的表现。
-
成本:开源模型免费,API模型按token计费。对于海量数据,计算成本是需要重点考虑的。
-
隐私:对于敏感数据,必须使用本地部署的开源模型,确保数据不出域。
2.4.3 向量生成实战
python
# 安装依赖: pip install sentence-transformers
from sentence_transformers import SentenceTransformer
import numpy as np
# 1. 加载模型
# 本地首次运行会自动下载模型,也可以提前下载到指定目录
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. 单文本向量生成
text = "检索增强生成(RAG)是一种结合了信息检索和文本生成的技术。"
embedding = model.encode(text)
print(f"向量维度: {embedding.shape}") # 输出: (384,)
print(f"向量前5个值: {embedding[:5]}")
# 3. 批量文本向量生成(推荐)
texts = [
"RAG技术可以有效减少大模型的幻觉现象。",
"向量数据库是RAG系统中用于存储和检索向量的关键组件。",
"Chunk拆分策略对检索效果影响很大。"
]
# 使用batch size参数,可以控制内存占用,加快处理速度
embeddings = model.encode(texts, batch_size=32, show_progress_bar=True)
print(f"批量向量生成形状: {embeddings.shape}") # 输出: (3, 384)
# 4. 向量归一化与优化
# 归一化后的向量,其点积就等于余弦相似度,能加快检索速度
embeddings_normalized = embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
print(f"归一化后向量的模长: {np.linalg.norm(embeddings_normalized, axis=1)}") # 输出: [1. 1. 1.]2.4.3.1 单文本/批量文本向量生成
如上所示,SentenceTransformer库提供了非常简洁的接口。批量生成可以显著利用GPU并行计算能力,提高处理速度。
2.4.3.2 向量归一化与优化
归一化将向量的长度缩放为1。这样做有两个好处:
-
计算余弦相似度只需做点积,比计算欧氏距离更快。
-
对于某些距离计算(如FAISS的IP索引),归一化是必需的。
2.4.3.3 向量维度选择与适配
向量维度越高,理论上能表示的信息越丰富,但计算和存储成本也越高。选择时需确保:
-
嵌入模型输出的维度与向量数据库预期的维度一致。
-
如果使用API模型,注意API的维度限制。
2.4.4 向量质量评估方法
评估嵌入质量通常不单独进行,而是结合最终的检索效果来评估。
-
定性评估 :人工检查
问题向量与检索到的文本块向量在语义上是否匹配。 -
定量评估 :使用标注好的问答对数据集,计算检索的召回率(Recall) 和**平均倒数排名(MRR)**等指标。
2.5 模块4:向量存储(向量数据库实战)
2.5.1 向量数据库核心作用与原理
2.5.1.1 向量数据库与传统数据库的区别
-
传统数据库(如MySQL) :擅长对精确值(如
id=1)或简单的范围条件进行查询,无法高效处理基于语义的相似性搜索。查询"与这句话意思最接近的10句话"对传统数据库而言是几乎不可能完成的任务。 -
向量数据库 :专为处理高维向量数据而设计。它提供了高效的**近似最近邻(ANN)**搜索能力,能在数亿甚至数十亿的向量中,在毫秒级时间内找到与目标向量最相似的K个向量。
2.5.1.2 向量索引的核心逻辑(加速检索)
暴力搜索(遍历所有向量计算相似度)在海量数据下不可行。向量索引通过牺牲少量精度来换取极高的速度,常见算法有:
-
IVF(Inverted File Index):对向量空间进行聚类,搜索时先找到最相关的几个聚类,再在这些聚类内部进行搜索。
-
HNSW(Hierarchical Navigable Small World):构建一个多层图结构,实现对数级别的搜索复杂度,是目前综合性能最好的索引之一。
-
PQ(Product Quantization):对向量进行压缩,大幅减少内存占用和计算量。
2.5.2 主流向量数据库选型与对比(适配不同场景)
2.5.2.1 入门级(Chroma/FAISS)
-
Chroma:
-
特点 :纯Python实现,开箱即用,默认集成
all-MiniLM-L6-v2模型,支持元数据过滤,非常适合学习、原型验证和小型应用。 -
存储:可持久化到本地磁盘。
-
-
FAISS:
- 特点:Facebook开源的向量检索库,不是数据库,而是强大的算法库。它提供了极其丰富和高效的索引类型,但缺乏数据持久化、分布式等数据库功能。适合在已有数据基础设施上,需要极高性能的场景。
2.5.2.2 企业级(Milvus/Pinecone)
-
Milvus:
- 特点:目前最流行的开源向量数据库,功能完备。支持分布式部署、云原生、多种索引类型、数据分片、权限管理等,是大规模生产环境的理想选择。
-
Pinecone:
- 特点:全托管的云向量数据库服务。无需运维,提供高可用和自动扩展,但成本较高,适合不想管理基础设施的团队。
2.5.2.3 选型关键指标
-
检索速度:在特定数据集上的QPS(每秒查询数)和延迟。
-
可扩展性:能否支持十亿级以上的向量,是否支持水平扩展。
-
运维成本:自建Milvus需要维护Kubernetes等基础设施,而Pinecone则无需运维,但费用更高。
2.5.3 向量数据库实战(分场景代码)
2.5.3.1 Chroma实战(入门级:初始化/存储/查询)
python
# 安装依赖: pip install chromadb langchain langchain-chroma
import chromadb
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
# 初始化嵌入模型
embedding_function = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# 初始化Chroma客户端(持久化到本地目录)
chroma_client = chromadb.PersistentClient(path="./chroma_db")
# 创建或获取集合(相当于传统数据库的"表")
collection = chroma_client.get_or_create_collection(
name="my_knowledge_base",
metadata={"hnsw:space": "cosine"} # 指定使用余弦相似度
)
# 存储向量(包含文本和元数据)
texts = [
"RAG技术的核心是检索和生成。",
"向量数据库使得语义搜索成为可能。",
"混合检索结合了关键词和向量搜索的优势。"
]
ids = ["doc1", "doc2", "doc3"]
metadatas = [{"source": "book1", "page": 10}, {"source": "book1", "page": 15}, {"source": "blog"}]
# 方法1: 直接使用Chroma客户端
collection.add(
documents=texts,
metadatas=metadatas,
ids=ids
)
# 方法2: 使用LangChain的Chroma封装(更符合RAG流程)
# 将文档和嵌入一起存储
langchain_chroma = Chroma.from_texts(
texts=texts,
embedding=embedding_function,
metadatas=metadatas,
client=chroma_client,
collection_name="my_knowledge_base_lc"
)
# 查询
query = "什么是RAG?"
results = collection.query(
query_texts=[query],
n_results=2,
# 可以使用where条件进行元数据过滤
# where={"source": {"$eq": "book1"}}
)
print(f"检索到的文本: {results['documents'][0]}")
print(f"相似度分数: {results['distances'][0]}")2.5.3.2 Milvus实战(企业级:分布式部署/批量操作)
Milvus企业级部署通常通过Docker或Kubernetes。以下展示Python客户端的基本操作。
python
# 安装依赖: pip install pymilvus
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
import numpy as np
# 1. 连接到Milvus服务(需先启动Milvus服务)
connections.connect(alias="default", host='localhost', port='19530')
# 2. 定义集合的Schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384), # 维度必须与模型一致
FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=200)
]
schema = CollectionSchema(fields, description="RAG知识库")
collection_name = "rag_kb"
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
collection = Collection(name=collection_name, schema=schema)
# 3. 创建索引
index_params = {
"metric_type": "IP", # 内积,适用于归一化向量
"index_type": "IVF_FLAT",
"params": {"nlist": 128}
}
collection.create_index(field_name="embedding", index_params=index_params)
# 4. 插入数据(批量)
vectors = np.random.rand(100, 384).tolist() # 模拟100个384维向量
ids = list(range(100))
sources = [f"doc_{i}" for i in range(100)]
data = [ids, vectors, sources]
collection.insert(data)
collection.load() # 加载到内存,准备检索
# 5. 检索
search_params = {"metric_type": "IP", "params": {"nprobe": 10}}
query_vector = np.random.rand(1, 384).tolist()
results = collection.search(
data=query_vector,
anns_field="embedding",
param=search_params,
limit=5,
output_fields=["source"]
)
for hits in results:
for hit in hits:
print(f"ID: {hit.id}, Distance: {hit.distance}, Source: {hit.entity.get('source')}")2.5.3.3 向量与元数据关联存储
在Chroma和Milvus中,元数据字段是作为Schema的一部分与向量一起存储的。在检索时,可以通过where或output_fields参数来指定元数据过滤条件和需要返回的字段。
2.5.4 向量数据库运维技巧(适合运维人员)
2.5.4.1 数据持久化与备份
-
Chroma :数据默认持久化在
./chroma_db目录,定期备份该目录即可。 -
Milvus:
-
元数据:通常存储在MySQL或Etcd中,需备份这些数据库。
-
数据:存储在对象存储(如MinIO、S3)中,需开启云存储的版本管理或定期快照。
-
2.5.4.2 性能优化
-
索引调优:
-
HNSW :调优
M(每个节点的最大连接数)和efConstruction(构建时动态列表大小)参数。M越大,准确率越高但内存占用越大。 -
IVF :调优
nlist(聚类数量)。nlist越大,搜索时可能需要的候选集nprobe就越大。
-
-
缓存策略:Milvus等数据库本身有缓存机制。合理分配内存,将频繁访问的数据(如索引)驻留在内存中,可以大幅提升查询速度。
2.5.4.3 故障排查与解决
-
常见问题:
-
连接失败:检查服务端口是否开放,网络是否通畅。
-
查询变慢:可能是数据量增加导致索引效率下降,考虑重建索引或增加硬件资源。
-
内存溢出 :向量索引(尤其是HNSW)非常消耗内存。对于海量数据,考虑使用
PQ等压缩索引来降低内存占用。
-
-
监控:使用Prometheus + Grafana监控Milvus的各项指标(QPS、延迟、内存使用、磁盘I/O)。
2.6 模块5:检索匹配(精准找到相关知识)
2.6.1 检索核心逻辑与评估指标
2.6.1.1 召回率与精确率
-
召回率(Recall@K) :在所有真正相关的文档中,检索器成功召回(返回)了多少个。
Recall@K = (被召回的相关文档数) / (总相关文档数)。高召回意味着没有遗漏重要知识。 -
精确率(Precision@K) :在检索器返回的K个文档中,有多少个是真正相关的。
Precision@K = (被召回的相关文档数) / K。高精确率意味着返回的结果质量高,噪音少。
2.6.1.2 相似度计算方法
-
余弦相似度 :衡量两个向量在方向上的相似性,取值范围-1,1。值越接近1,表示方向越一致,语义越相似。计算公式为
cos(θ) = (A·B) / (||A||*||B||)。如果向量已归一化,则直接计算点积A·B。 -
欧氏距离:衡量两点之间的直线距离,范围[0, +∞)。距离越小,表示向量越相似。
-
点积:如前所述,归一化后的向量的点积等价于余弦相似度。
2.6.2 基础检索策略实战
2.6.2.1 稠密检索(向量检索)代码实现
这其实就是向量数据库的query功能,我们已经在2.5.3节中展示过。
2.6.2.2 稀疏检索(TF-IDF/BM25)代码实现
稀疏检索基于关键词匹配,使用BM25算法,效果优于TF-IDF。
python
# 安装依赖: pip install rank-bm25
from rank_bm25 import BM25Okapi
import jieba # 用于中文分词
# 模拟一个文档集合
corpus = [
"这是第一个文档,它讨论的是RAG技术。",
"第二个文档是关于向量数据库的构建。",
"第三个文档主要讲混合检索和重排序。",
]
# 中文分词
tokenized_corpus = [list(jieba.cut(doc)) for doc in corpus]
# 构建BM25模型
bm25 = BM25Okapi(tokenized_corpus)
# 查询
query = "什么是RAG技术"
tokenized_query = list(jieba.cut(query))
# 计算每个文档与查询的相关性得分
scores = bm25.get_scores(tokenized_query)
print(f"BM25得分: {scores}")
# 获取Top-K个文档
top_k = bm25.get_top_n(tokenized_query, corpus, n=2)
print(f"BM25 Top-2: {top_k}")2.6.2.3 基础检索的优缺点与适用场景
-
稠密检索:擅长理解语义,能找出使用不同词汇表达的相似内容。但对生僻词、特定领域术语(如产品型号)的处理不如关键词检索。
-
稀疏检索:简单、可解释性强,对精确匹配(如名称、ID)效果好。但无法理解同义词,容易受停用词干扰。
2.6.3 高级检索策略(提升检索效果)
2.6.3.1 混合检索(稀疏+稠密)实战代码
混合检索的核心思想是融合两种检索结果的得分,取长补短。
python
import numpy as np
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
import jieba
class HybridRetriever:
def __init__(self, corpus):
self.corpus = corpus
# 初始化BM25
tokenized_corpus = [list(jieba.cut(doc)) for doc in corpus]
self.bm25 = BM25Okapi(tokenized_corpus)
# 初始化嵌入模型
self.embedder = SentenceTransformer('all-MiniLM-L6-v2')
# 计算并存储所有文档的向量(离线阶段)
self.corpus_embeddings = self.embedder.encode(corpus)
def search(self, query, top_k=3, alpha=0.5):
"""
alpha: 混合系数,alpha=0 时完全由BM25决定,alpha=1 时完全由向量决定
"""
# 1. 计算BM25得分
tokenized_query = list(jieba.cut(query))
bm25_scores = self.bm25.get_scores(tokenized_query)
# 归一化BM25得分(Min-Max归一化)
bm25_scores = (bm25_scores - np.min(bm25_scores)) / (np.max(bm25_scores) - np.min(bm25_scores) + 1e-8)
# 2. 计算向量相似度得分
query_embedding = self.embedder.encode([query])[0]
# 计算点积(余弦相似度),假设向量已归一化
dense_scores = np.dot(self.corpus_embeddings, query_embedding)
# 归一化
dense_scores = (dense_scores - np.min(dense_scores)) / (np.max(dense_scores) - np.min(dense_scores) + 1e-8)
# 3. 混合得分
combined_scores = alpha * dense_scores + (1 - alpha) * bm25_scores
# 4. 获取Top-K结果
top_indices = np.argsort(combined_scores)[-top_k:][::-1]
results = [self.corpus[idx] for idx in top_indices]
return results, combined_scores[top_indices]
# 使用示例
corpus = [
"RAG是一种结合检索和生成的技术。",
"向量数据库用于存储和检索向量。",
"BM25是一种基于统计的检索方法。"
]
retriever = HybridRetriever(corpus)
results, scores = retriever.search("检索技术", top_k=2)
print(results)2.6.3.2 重排序策略(RRF/Cross-BERT)详解与代码
混合检索是第一步,重排序(Rerank)则是对第一步返回的Top-N(如50个)结果,用一个更强大、更精确的模型进行二次排序,最终返回给用户Top-K(如5个)。
-
RRF(Reciprocal Rank Fusion) :一种简单有效的融合方法,不依赖于得分,而是基于排名。公式:
score(d) = Σ 1/(k + rank_i(d)),其中k是常数(通常60)。RRF对异常值不敏感,实现简单。 -
Cross-BERT(Cross-Encoder):将(问题,文档)对作为一个输入,通过BERT模型直接输出一个相关性得分(0-1)。它比向量检索的"双塔模型"更精确,因为它让问题和文档在模型中进行了更深度的交互。但计算成本非常高,无法用于大规模检索,因此只用于小规模重排序。
python
# 安装依赖: pip install sentence-transformers
# Cross-Encoder重排序示例
from sentence_transformers import CrossEncoder
# 加载一个Cross-Encoder模型
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# 假设我们从混合检索中得到了候选文档列表
query = "什么是RAG技术"
candidates = [
"RAG是一种结合检索和生成的技术,能有效解决幻觉问题。",
"今天天气真好。",
"向量数据库是RAG系统的核心组件。",
"RAG,即检索增强生成,是当前LLM应用的主流架构。"
]
# 构建(查询, 文档)对
pairs = [(query, doc) for doc in candidates]
# 计算得分
scores = cross_encoder.predict(pairs)
# 按得分排序
reranked_results = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
for doc, score in reranked_results:
print(f"Score: {score:.4f}, Document: {doc[:50]}...")2.6.3.3 元数据过滤检索
在Chroma的query函数中,我们已经展示了如何使用where参数。在Milvus中,也支持在search时传入expr表达式进行过滤。
python
# Chroma元数据过滤
results = collection.query(
query_texts=[query],
n_results=5,
where={"source": {"$in": ["book1", "book2"]}, "page": {"$gte": 10}}
)2.6.3.4 多轮检索(RAG-Fusion)实战
RAG-Fusion的核心思想是:让LLM根据原始问题生成多个相关的问题(查询扩展),然后对每个生成的问题都进行一次检索,最后将所有检索结果融合起来。
python
import requests
import numpy as np
# 假设有一个调用LLM生成相关问题的函数
def generate_related_queries(original_query, num_queries=3):
# 此处应调用一个轻量级LLM(如GPT-3.5)来生成
# 为简化,我们返回一些伪代码
if "RAG" in original_query:
return [
original_query,
"RAG系统架构是什么?",
"RAG如何减少大模型幻觉?",
"向量检索在RAG中扮演什么角色?"
]
return [original_query]
# 假设有检索函数
def search(query, top_k=2):
# 这里是模拟的检索结果,实际应调用向量数据库
if "RAG" in query:
return [{"text": "RAG系统由检索器和生成器组成。", "score": 0.9}]
else:
return [{"text": "其他信息。", "score": 0.5}]
def rag_fusion(query):
related_queries = generate_related_queries(query)
all_results = []
for q in related_queries:
results = search(q)
for res in results:
# RRF 或 其他融合方法
all_results.append(res)
# 根据分数去重并排序
# 简化:按分数排序
all_results.sort(key=lambda x: x['score'], reverse=True)
# 去重
seen = set()
unique_results = []
for r in all_results:
if r['text'] not in seen:
seen.add(r['text'])
unique_results.append(r)
return unique_results
print(rag_fusion("RAG是什么?"))2.6.4 检索策略调优技巧
-
场景匹配:
-
FAQ/客服场景:用户问题通常比较短,关键词明确,可优先使用混合检索。
-
专业文档/论文检索:用户问题可能较长,语义复杂,可提高稠密检索的权重。
-
-
参数调优:
-
调整混合检索中的
alpha值。 -
调整BM25中的
k1和b参数(控制词频饱和度和文档长度归一化)。 -
调整重排序时的候选集大小
top_n和最终返回大小top_k。
-
-
A/B测试:在生产环境中,通过A/B测试来对比不同检索策略对最终用户满意度的影响。
2.7 模块6:大模型生成与结果优化(最终输出)
2.7.1 生成核心逻辑
将检索到的上下文和用户问题,以精心设计的提示词模板传递给LLM,LLM基于此生成回答。
2.7.1.1 提示词工程核心技巧
一个优秀的RAG提示词模板通常包含以下部分:
-
系统指令:定义LLM的角色、任务目标和输出格式。
-
上下文信息:将检索到的文档内容放入其中。
-
用户问题:用户的问题。
-
回复引导:告诉模型如何开始回答。
2.7.1.2 检索结果与提示词的拼接逻辑
python
def build_prompt(query, retrieved_docs):
context = "\n\n".join([f"[文档{i+1}]: {doc.page_content}" for i, doc in enumerate(retrieved_docs)])
prompt = f"""你是一个智能助手,请根据以下提供的上下文信息来回答用户的问题。
如果上下文信息中没有相关内容,请如实告知"我没有找到相关信息"。
<上下文>
{context}
</上下文>
问题:{query}
请给出一个清晰、准确的回答。如果回答中使用了上下文中的信息,请注明来源,如(文档1)。
回答:
"""
return prompt2.7.2 大模型选型与调用实战
2.7.2.1 入门级(开源模型:Llama 2/Mistral)
可使用transformers库在本地加载和运行,适合开发测试,但对硬件(GPU显存)有较高要求。
2.7.2.2 企业级(API调用:OpenAI/通义千问/文心一言)
python
import os
from openai import OpenAI
from dashscope import Generation
from http import HTTPStatus
# 示例1: 调用OpenAI API
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def call_openai(prompt):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": prompt}
],
temperature=0.3, # 控制随机性,值越小输出越确定
max_tokens=500,
)
return response.choices[0].message.content
# 示例2: 调用阿里云通义千问API
def call_qwen(prompt):
response = Generation.call(
model='qwen-turbo',
prompt=prompt,
api_key=os.getenv("DASHSCOPE_API_KEY"),
result_format='message',
)
if response.status_code == HTTPStatus.OK:
return response.output.choices[0].message.content
else:
return f"Error: {response.code} - {response.message}"2.7.2.3 大模型调用代码(带异常处理)
python
def safe_llm_call(prompt, llm_func, max_retries=3):
"""带重试和异常处理的LLM调用包装器"""
for attempt in range(max_retries):
try:
return llm_func(prompt)
except Exception as e:
print(f"LLM调用失败 (尝试 {attempt+1}/{max_retries}): {e}")
if attempt == max_retries - 1:
return "抱歉,当前无法生成回答,请稍后重试。"
# 简单的指数退避
time.sleep(2 ** attempt)2.7.3 结果优化技巧
2.7.3.1 Citations引用生成
在提示词中明确要求LLM在回答中使用脚注或括号注明来源。我们可以在build_prompt中为每个文档编号,并在系统指令中要求LLM引用这些编号。
2.7.3.2 格式标准化
在系统指令中指定输出格式,如"使用Markdown格式,如果内容包含列表,请使用1. 2. 3.列出",或要求返回JSON格式以便前端直接渲染。
2.7.3.3 幻觉抑制与冲突处理
-
冲突处理:如果检索到的多个文档之间观点冲突,可以在提示词中指示模型:"如果上下文信息中存在矛盾,请指出并说明不同来源的观点"。
-
幻觉抑制:通过严格限定LLM只能基于"上下文"回答,可以有效抑制幻觉。同时,加入"如果没有相关信息,请直接说不知道"的指令,可以防止模型强行编造答案。
2.7.3.4 无检索结果时的兜底方案
当检索器返回的文档与问题相关度普遍很低(如所有相似度分数都低于阈值)时,可以:
-
不调用LLM,直接返回"抱歉,没有找到与您问题相关的信息。"
-
或者,调用LLM但使用一个特殊的提示词:"用户问了一个问题,但我们的知识库中没有相关信息,请礼貌地告知用户您无法回答这个问题,并建议ta换一种方式提问。"
2.7.4 生成效果评估与调优
-
人工评估:这是最可靠的方式,从准确性、相关性、流畅性、信息量等维度对答案进行打分。
-
自动评估 :使用
ROUGE、BLEU等指标衡量答案与标准答案的相似度。但这对开放性问题并不完全适用。更高级的评估使用LLM-as-a-judge,即用GPT-4等强模型来给生成的答案打分,但这存在偏见和成本问题。
2.8 模块7:结果输出与交互
2.8.1 输出格式适配
-
网页:返回HTML片段,或者通过API返回JSON格式数据,由前端负责渲染。
-
文档:生成Markdown格式的报告,供用户下载。
-
API接口 :返回一个标准的JSON对象,包含
answer(答案字符串)、sources(引用来源列表)等字段。
2.8.2 前端简单交互实现(适合前端开发者,代码实战)
一个简单的HTML/JavaScript前端,用于展示聊天界面。
html
<!DOCTYPE html>
<html>
<head>
<title>RAG 问答助手</title>
</head>
<body>
<div id="chat-container" style="width: 500px; margin: auto;">
<div id="messages" style="border: 1px solid #ccc; height: 400px; overflow-y: scroll; padding: 10px;"></div>
<input type="text" id="user-input" style="width: 80%;" placeholder="输入你的问题...">
<button onclick="sendMessage()">发送</button>
</div>
<script>
async function sendMessage() {
const input = document.getElementById('user-input');
const message = input.value;
if (!message) return;
// 显示用户消息
const messagesDiv = document.getElementById('messages');
messagesDiv.innerHTML += `<div><b>用户:</b> ${message}</div>`;
// 调用后端API
const response = await fetch('/api/query', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({query: message})
});
const data = await response.json();
// 显示助手回复
messagesDiv.innerHTML += `<div><b>助手:</b> ${data.answer}</div>`;
if (data.sources) {
messagesDiv.innerHTML += `<div><small>来源: ${data.sources.join(', ')}</small></div>`;
}
input.value = '';
// 滚动到底部
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
</script>
</body>
</html>对应的后端Flask API示例:
python
from flask import Flask, request, jsonify
# 假设我们已有rag_query函数
app = Flask(__name__)
@app.route('/api/query', methods=['POST'])
def query():
data = request.json
user_query = data.get('query')
# 调用RAG系统的核心处理函数
answer, sources = rag_system.query(user_query) # 返回答案和来源
return jsonify({"answer": answer, "sources": sources})
if __name__ == '__main__':
app.run(debug=True)2.8.3 批量输出与导出功能
对于离线任务(如分析1000份文档),可以将结果批量输出到一个CSV或JSON文件中,方便用户下载和后续分析。
三、本章练习题与解答
一、选择题
-
以下哪个不是RAG系统的核心组成部分?
A. 向量数据库
B. 大语言模型
C. 关系型数据库
D. 嵌入模型
-
关于文档拆分,以下说法错误的是?
A.
chunk_overlap是为了保持上下文连贯性。B. 按固定长度拆分通常比按语义拆分效果更好。
C. 拆分粒度太大会导致检索结果模糊。
D. 拆分粒度太小会丢失上下文信息。
-
在进行向量检索时,通常使用哪种相似度计算方法?
A. 曼哈顿距离
B. 余弦相似度
C. 杰卡德相似系数
D. 编辑距离
-
以下哪种检索策略最适合用于处理同义词问题?
A. BM25
B. TF-IDF
C. 稠密向量检索
D. 全文索引
-
为了抑制大模型的幻觉现象,以下哪种提示词工程方法最有效?
A. 让模型自由发挥
B. 只提供少量上下文
C. 明确指示模型只能基于给定的上下文回答
D. 提高模型的
temperature参数
二、填空题
-
RAG的全称是___________。
-
在向量数据库中,用于加速检索的数据结构通常被称为___________。
-
BM25检索算法属于___________检索,而基于嵌入的检索属于___________检索。
-
在混合检索中,常用的得分融合算法是___________。
-
在元数据过滤中,如果我们只想检索
category为"技术"且timestamp大于2023-01-01的文档,需要设置的条件是___________。
三、简答题
-
请简述RAG系统离线处理和在线处理阶段的主要任务。
-
解释为什么文档预处理中的"拆分"步骤如此关键,并列举两种常用的拆分策略。
-
什么是向量数据库?与传统关系型数据库相比,它解决了什么问题?
-
混合检索为什么要结合稠密检索和稀疏检索?请说明各自的优势和不足。
-
请解释什么是"幻觉",并说明RAG系统如何帮助缓解这一问题。
四、实操题
-
使用
LangChain和Chroma,搭建一个简单的RAG系统。要求:-
从本地加载一个文本文件。
-
对文件内容进行清洗和拆分(
chunk_size=100)。 -
使用
all-MiniLM-L6-v2模型生成向量并存入Chroma。 -
编写一个检索函数,输入一个问题,返回Top-2个最相关的文本块。
-
-
基于上一题的系统,增加一个LLM生成模块。调用OpenAI或通义千问的API,结合检索到的文本块生成最终答案。要求答案中能标注信息来源(例如,引用自"文档1")。
四、标准答案
一、选择题
-
C
-
B
-
B
-
C
-
C
二、填空题
-
检索增强生成
-
索引
-
稀疏,稠密
-
RRF (Reciprocal Rank Fusion) 或 加权平均
-
{"category": "技术", "timestamp": {"$gt": "2023-01-01"}}(具体语法取决于数据库)
三、简答题
-
离线处理 :主要负责构建知识库,包括数据加载、清洗、拆分、向量化以及存入向量数据库。在线处理:负责响应用户请求,包括将用户问题向量化、在向量数据库中检索相关文档、构建提示词、调用LLM生成答案。
-
文档拆分是关键因为它直接影响了检索的颗粒度和准确性。如果拆分不当,可能导致检索结果包含大量无关信息或遗漏关键信息。常用策略:按固定长度拆分 (简单快速),按语义拆分 (如按段落、章节,语义完整),按句子拆分(保留句子完整性)。
-
向量数据库是专门用于存储和检索高维向量数据的数据库系统。它解决了传统关系型数据库无法高效进行"语义相似性搜索"的问题,通过构建向量索引,能在海量数据中快速找到语义上最相近的内容。
-
稠密检索 擅长语义理解,能找出同义但不同词的表达,但可能忽略精确的关键词匹配;稀疏检索擅长精确匹配,可解释性强,但无法处理语义鸿沟。混合检索结合两者,既能保证对特定术语的召回,又能利用语义理解提升结果的全面性。
-
幻觉是指LLM生成看似合理但事实上不正确或不存在的内容。RAG通过检索出真实可靠的上下文信息,并将这些信息作为LLM生成的"事实基础",严格限制了模型"编造"的空间,从而有效抑制了幻觉。
五、总结
至此,我们已完整地剖析了RAG系统的全貌。从数据源加载、文档预处理,到向量化、存储,再到检索匹配和最终的大模型生成,每一个环节都至关重要,共同决定了RAG应用的整体效果。
构建一个高质量的RAG系统,远不止是简单地调用几个API。它是一个系统工程,需要我们在"检索精度"和"生成质量"之间找到精妙的平衡。数据源的清洗质量决定了知识库的"纯净度",文档拆分策略影响了检索的"颗粒度",嵌入模型和向量数据库的选择关系到系统的"效率与成本",而高级检索策略和提示词工程则是提升"最终效果"的关键。
希望通过本文的理论讲解和实战代码,能够帮助读者建立起对RAG系统深入且体系化的理解。RAG技术仍在飞速发展,新的模型、更智能的检索策略、以及多模态RAG都是未来的方向。掌握了核心原理和工程实践,你将有能力在自己的业务场景中灵活运用RAG技术,构建出真正有价值、可信赖的AI应用。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!