📚 系列文章导航
前言
大家好呀~ 👋 欢迎回到《从 0 到 1 实现 AI Agent》系列的第二篇!
第一篇我们从零开始,一起把 DeepSeek LLM + 流式输出 + Tool Calling 跑通,亲手实现了一个最简的 ReAct Agent 原型 。当你输入「明天纽约天气怎么样?」时,Agent 已经能自己决定调用 get_forecast 工具,拿到真实数据后再用自然语言回答你。
那一刻,是不是已经感觉到 Agent 和普通 ChatBot 的本质区别 了? 它不再只是"会说话",而是开始拥有了"手和脚"------能主动调用外部能力来解决问题。
但第一篇跑完之后,你可能也发现了几个明显痛点:
- 每新增一个工具,都要手动写一大段 JSON Schema,手写到手软 😵
- 所有工具都是硬编码在代码里的,本地函数改一行都要重启项目
- 想让 Agent 做更复杂的事(比如查完天气后把结果写入文件、调用外部 API、甚至执行自定义逻辑),目前的工具系统就显得太僵硬了
今天,我们就来彻底解决这些问题:重新设计一套可扩展、易维护的 Tool 调用系统。
这一篇我们将实现:
- 统一的 Tool 抽象层,同时支持本地 Tool 和 远程 Tool
- Tool 配置化管理(使用 tools.json 模拟,后续可扩展为数据库 + Web 可视化界面)
- 通过 RestrictedPython 支持动态远程 Tool(把工具逻辑保存为代码字符串,动态安全执行)
- 最终让 Agent 能够完成复合任务:获取明天纽约的天气,并将结果写入本地 Markdown 文件
完成后,你的 Agent 将从"调用几个固定工具"进化成"能灵活组合本地 + 远程能力"的真正灵活、可扩展的版本。
听起来是不是已经有点小激动了?🚀
📌 阅读说明 本篇依然以实战动手为主。我们会一步步写代码、跑 Demo,同时也会在关键位置说明设计思路和潜在风险(尤其是动态执行代码的安全性)。 如果你还没看第一篇,建议先把基础的 LLM 调用和 Agent Loop 跑通再继续。
准备好了吗?我们把第一篇那个简陋的 Tool 系统彻底升级,让它真正"长大"!
第一节:Tool Server 的设计与实现
在开始重构之前,我们先来思考一个很重要的问题。
从第一篇的代码来看,其实大模型(LLM)根本不关心工具到底是怎么被调用的。它只负责两件事:
- 根据当前对话历史和工具列表,决定是否需要调用工具,以及调用哪个工具、传入什么参数;
- 拿到工具执行后的结果后,继续思考并给出最终回答。
至于工具是在本地执行,还是通过网络调用远程服务执行,对 LLM 来说是完全无感的。
这就给了我们很大的发挥空间!我们可以把 Tool 的定义 和执行 从 Agent 主代码中剥离出来,做成一个独立的 Tool Server,从而实现更灵活、可扩展的架构。
1. Tool Server 整体架构
我们将使用 FastAPI 搭建一个轻量级的 Tool 服务,它提供两个核心接口:
GET /tools------ 返回当前所有可用的 Tool 列表(供 Agent 加载)POST /tools/{tool_name}------ 执行指定的 Tool,并返回执行结果
这样做的好处非常明显:
- Agent 只需通过 HTTP 调用服务即可使用远程 Tool;
- 未来可以轻松把 Tool Server 部署到独立服务器,甚至支持多人共享 Tool;
- Tool 的新增、修改、删除都不需要重启 Agent 主程序。
2. Tool 数据模型定义
首先,我们需要定义 Tool 的结构。创建一个新文件 server/tool.py:
Python
from pydantic import BaseModel
from typing import Dict, List, Any
class ToolParametersProperty(BaseModel):
type: str
description: str | None = ""
title: str | None = None
class ToolParameters(BaseModel):
type: str = "object"
properties: Dict[str, ToolParametersProperty]
required: List[str]
additionalProperties: bool = False
class Tool(BaseModel):
name: str
description: str
strict: bool = False
parameters: ToolParameters
code: str # 工具的核心执行逻辑(代码字符串)这里最关键的就是新增的 code: str 字段。
它把工具的真实逻辑(原来的 get_forecast 函数体)以字符串的形式保存下来,后续我们会用 RestrictedPython 在沙箱中动态执行它。这也是本篇最核心的设计之一。
Tool 数据结构设计成这样也是尽量和 OpenAI Tool Schema 保持一致,方便传递
3. 实现 Tool Server 主程序
在正式写代码之前,先说明一下数据存储方式。
目前为了简化演示,我们使用 tools.json 文件来模拟数据库,存储所有的 Tool 配置。实际项目中 ,你完全可以把这些数据存入 MySQL、PostgreSQL 或 MongoDB 等数据库中,甚至进一步开发一个 Web 可视化配置管理系统(包含表单 + 在线代码编辑器),让用户可以通过界面轻松新增、编辑和删除 Tool。
类似这种:
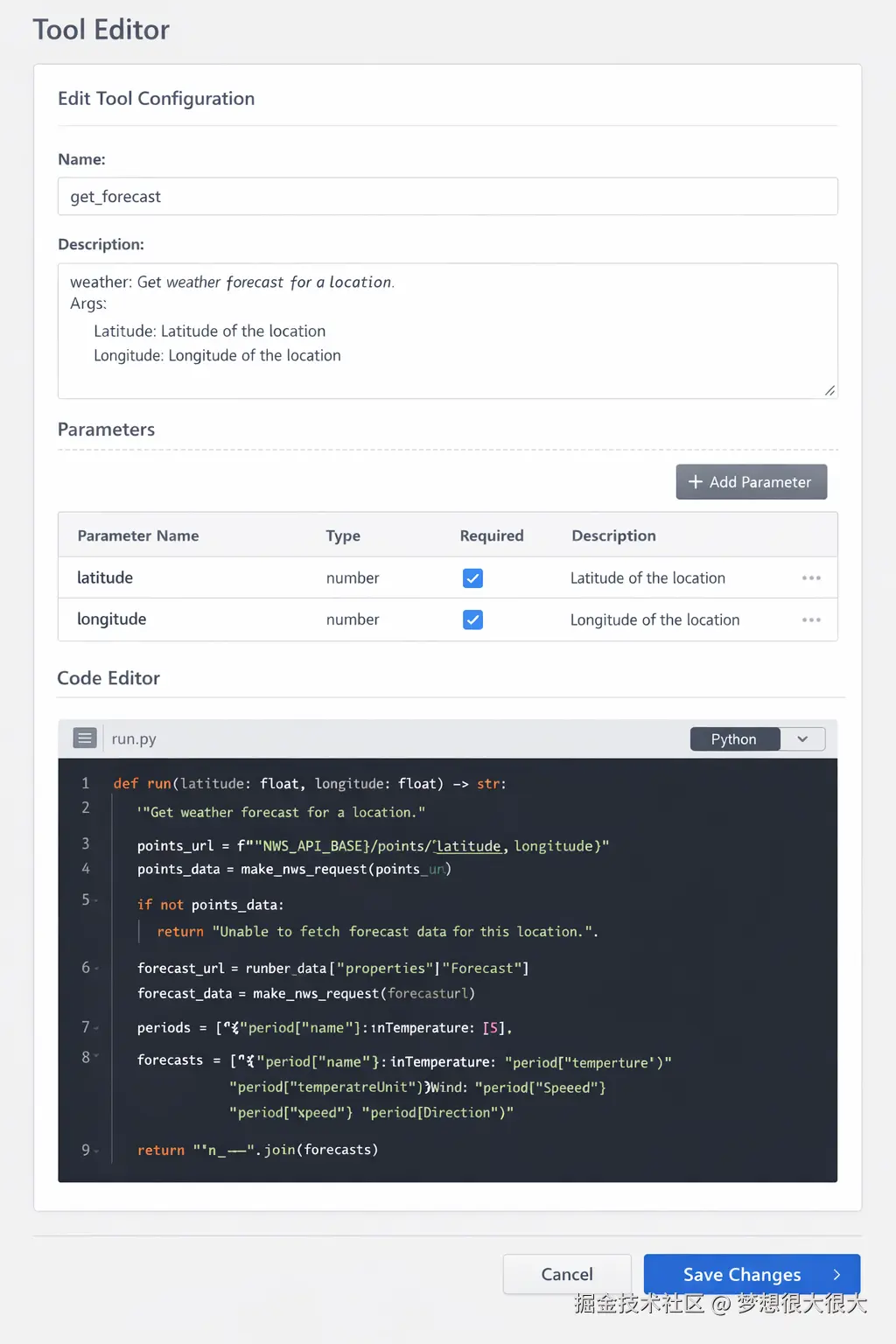
我们这里使用 JSON 文件只是为了降低入门门槛,让大家快速跑通原理。理解了这个设计后,后续替换成数据库或 Web 管理系统会非常自然。
新建文件 server/server.py,核心代码如下:
Python
from actuator import run_restricted
from anyio import to_thread
from crud import get_tool_by_name, load_tools
from fastapi import FastAPI
from pydantic import BaseModel
from tool import Tool
from utils import NWS_API_BASE, format_alert, make_nws_request
app = FastAPI()
# 转成大模型支持的 tool_call 的数据格式,方便 agent 中直接传递给大模型
class AgentTool(BaseModel):
type: str
function: Tool
# 获取所有可用 tools 列表数据库
@app.get("/tools")
async def get_tools() -> list[AgentTool]:
tools = load_tools()
data = [AgentTool(type="function", function=tool) for tool in tools]
return data
class ToolCallDto(BaseModel):
name: str
arguments: dict
# 调用执行 tool
@app.post("/tools/{tool_name}")
async def call_tool(tool_name: str, args: ToolCallDto):
tool = get_tool_by_name(tool_name)
if not tool:
return {"error": "Tool not found"}
try:
# 这里的代码不明白也没关系,你只要知道这里我们拿到 tool.code 字符串,
# 然后通过一种安全的方式将其当作代码块执行并拿到其返回结果即可
# 后面我们会贴出代码并单独解释
result = await to_thread.run_sync(
run_restricted,
tool.code, # 动态执行的核心
args.arguments,
# 这里传入工具函数可能需要的额外函数和常量
# 目前写死,后续可以改成工具定义里指定需要哪些函数和常量
# 或者借助一些 rules 工具来自动分析工具代码里用到了哪些函数和常量
# 这里的 NWS_API_BASE make_nws_request format_alert 其实就是第一篇文章中 get_forecast 函数中要用到的外部变量和函数
{
"NWS_API_BASE": NWS_API_BASE,
"make_nws_request": make_nws_request,
"format_alert": format_alert,
},
)
return {"result": result}
except Exception as e:
return {"error": str(e)}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)新建 server/crud.py:
Python
import json
from pathlib import Path
from typing import List
from tool import Tool
BASE_DIR = Path(__file__).parent
# 模拟从数据库中查询所有 tools
def load_tools() -> List[Tool]:
"""Load tools from the tools.json file and return a list of Tool instances."""
with open(BASE_DIR / "tools.json", "r", encoding="utf-8") as f:
tools_data = json.load(f)
tools = [Tool.model_validate(t) for t in tools_data]
return tools
# 模拟通过 tool_name 从数据库中查询对应的 tool
def get_tool_by_name(name: str) -> Tool | None:
"""Get a tool by its name."""
tools = load_tools()
for tool in tools:
if tool.name == name:
return tool
return None说明:
load_tools() 和 get_tool_by_name() 目前操作的是 JSON 文件,这其实就是在模拟"从数据库读取 Tool 配置"的过程。等你以后把数据迁移到真实数据库时,只需要把这两个函数改成 SQL 查询或 ORM 操作即可,其他代码几乎不用改。
我们看一下数据库(tools.json)中现有的数据:
json
[
{
"name": "get_forecast",
"description": "weather: Get weather forecast for a location.\n\nArgs:\n latitude: Latitude of the location\n longitude: Longitude of the location\n",
"strict": false,
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"description": "",
"title": "Latitude"
},
"longitude": {
"type": "number",
"description": "",
"title": "Longitude"
}
},
"required": ["latitude", "longitude"],
"additionalProperties": false
},
// 真正需要执行的"函数体"的代码字符串
"code": "\ndef run(latitude: float, longitude: float) -> str:\n \"\"\"Get weather forecast for a location.\n\n Args:\n latitude: Latitude of the location\n longitude: Longitude of the location\n \"\"\"\n # First get the forecast grid endpoint\n points_url = f\"{NWS_API_BASE}/points/{latitude},{longitude}\"\n points_data = make_nws_request(points_url)\n\n if not points_data:\n return \"Unable to fetch forecast data for this location.\"\n\n # Get the forecast URL from the points response\n forecast_url = points_data[\"properties\"][\"forecast\"]\n forecast_data = make_nws_request(forecast_url)\n\n if not forecast_data:\n return \"Unable to fetch detailed forecast.\"\n\n # Format the periods into a readable forecast\n periods = forecast_data[\"properties\"][\"periods\"]\n forecasts = []\n for period in periods[:5]: # Only show next 5 periods\n forecast = f\"\"\"\n{period[\"name\"]}:\nTemperature: {period[\"temperature\"]}°{period[\"temperatureUnit\"]}\nWind: {period[\"windSpeed\"]} {period[\"windDirection\"]}\nForecast: {period[\"detailedForecast\"]}\n\"\"\"\n forecasts.append(forecast)\n\n return \"\\n---\\n\".join(forecasts)\n"
}
]4. 为什么 Tool Server 可以用任何语言实现?
其实这个 Tool Server 完全不限制必须使用 Python。
Node.js 可以使用 vm2 实现代码沙箱,Java 有 Easy Rules / Groovy,Go 也可以通过插件机制或外部进程实现动态执行。
这里我们先用 Python + RestrictedPython 是因为代码通用,不需要再创建一个工程,方便管理,但你完全可以根据自己的技术栈选择最适合的语言来实现 Tool Server。
其实这里我个人还是建议使用 Node.js 或者 Java,因为在"动态代码沙箱执行"方面,其生态还是更加成熟。
本节小结
通过这一节,我们成功把 Tool 的定义(Schema + code)和执行逻辑独立成了一个 Tool Server。
大模型只需要拿到 Schema 就能决策,真正的执行则交给 Tool Server 动态完成。
你有没有发现?我们已经自然地走进了 Web 开发 最擅长的领域!后续我们可以轻松引入高并发、消息队列(Kafka)、gRPC、微服务架构等技术,尤其是在构建 Multi-Agent 系统时,这种松耦合的设计会变得非常重要。
Web 开发者心想:AI(工具) 用着我们的技术栈,最后还想把我们给优化掉......这叫什么事儿啊~ 😂
拳头有点硬~👊
下一节,我们将重点实现 动态 Tool 执行引擎 ------ 使用 RestrictedPython 安全地运行保存在 code 中的代码逻辑。
第二节:动态 Tool 执行沙箱的实现
在第一节中,我们已经把工具的逻辑(代码)变成了数据库或 JSON 文件中的一段 字符串。但问题随之而来:如何让 Agent 安全地执行这段字符串?
如果直接使用 Python 内置的 exec() 函数,这就相当于给你的服务器开了一个"后门"------任何能修改工具配置的人,都可以通过一行 os.system('rm -rf /') 让你的系统瞬间瘫痪。
为了实现既能动态扩展功能,又能保障系统安全 ,我们需要构建一个代码沙箱 。这里我们引入了 RestrictedPython。
1. 什么是 RestrictedPython?
一句话理解:
RestrictedPython = 一个安全版 Python 解释器
它可以限制代码:
- 不能 import 任意模块
- 不能访问文件系统
- 不能访问网络
- 不能调用危险内置函数
- 只能使用我们"白名单"允许的能力
换句话说:
Tool 的代码只能在我们允许的"能力边界"里运行。
这正是我们需要的东西。
目前 RestrictedPython 不支持
async/await,所以在后面实现中我们需要做一下同步代码的包装
2. 核心执行器 run_restricted 的实现
我们来看一下 server/actuator.py 中的核心逻辑。这段代码负责接收字符串,并在一个"受限的笼子"里运行它。
Python
from RestrictedPython import compile_restricted, safe_globals
from RestrictedPython.Eval import default_guarded_getitem, default_guarded_getiter
from RestrictedPython.Guards import full_write_guard
# 1. 定义沙箱的基础安全环境
SAFE_BUILTINS = {
**safe_globals, # 包含基础数学运算、字符串处理等安全函数
"_getitem_": default_guarded_getitem, # 安全的对象索引访问
"_getiter_": default_guarded_getiter, # 安全的迭代
"_write_": full_write_guard, # 限制对属性的非法写入
}
def build_tool_globals(extra_funcs: dict):
"""构建工具运行时的全局变量,注入必要的外部依赖"""
g = SAFE_BUILTINS.copy()
g.update(extra_funcs) # 允许注入如 httpx 请求等特定"超能力"
return g
def run_restricted(code: str, arguments: dict, extra_funcs: dict):
"""
动态执行工具代码
:param code: 存储在数据库中的代码字符串
:param arguments: 大模型生成的调用参数
:param extra_funcs: 允许工具使用的外部函数(如网络请求函数)
"""
# 编译代码:RestrictedPython 会检查语法并剥离危险操作
byte_code = compile_restricted(code, "<tool>", "exec")
globals_dict = build_tool_globals(extra_funcs)
locals_dict = {}
# 在受限环境中执行
exec(byte_code, globals_dict, locals_dict)
# 约定:每个动态 Tool 的代码字符串中必须包含一个 run 函数作为入口
run_func = locals_dict.get("run")
if run_func is None:
raise ValueError("工具代码中必须定义 'def run(...):' 入口函数")
# 执行并返回结果
return run_func(**arguments)3. "超能力"的按需注入
单纯的沙箱是什么都干不了的(连网都连不上)。但在 call_tool 的 FastAPI 接口中,我们通过 extra_funcs 参数,有针对性地给工具开了"绿灯":
Python
# 在 server.py 中
result = await to_thread.run_sync(
run_restricted,
tool.code,
args.arguments,
{
"NWS_API_BASE": NWS_API_BASE, # 注入常量
"make_nws_request": make_nws_request, # 注入封装好的安全网络请求函数
"format_alert": format_alert, # 注入格式化工具
}
)设计精髓:
- 最小权限原则 :工具代码本身不能直接
import httpx,它只能使用我们"喂"给它的make_nws_request。 - 环境解耦 :开发者可以在
server.py里统一管理 API Key 和请求频率限制,而动态工具只需要关心业务逻辑。
4. 动态 Tool 编写规范
为了让这个系统跑通,我们在 tools.json 里的 code 字段必须遵循一个简单的约定:必须包含 def run(...): 接口。
例如,我们要新增一个"计算器"工具,只需要在 Web 界面(或 JSON)输入:
Python
python
def run(a: float, b: float, operation: str) -> str:
if operation == "add":
return str(a + b)
return "Unsupported operation"Agent 在下次调用时,就会通过 locals_dict.get("run") 找到这个函数并传入 a=1, b=2 进行执行。
本节小结
通过 RestrictedPython + FastAPI,我们亲手打造了一个 "云端大脑 (LLM) -> 指令下发 -> 沙箱执行 -> 结果回传" 的闭环。
现在的 Tool Server 就像是一个技能仓库。你可以随时随地在 Web 界面上写一段 Python 代码并保存,你的 Agent 就能"秒会"这项新技能。
既然"远程技能"已经搞定,那么 Agent 如何处理那些涉及本地敏感操作(如读写本地文件)的任务呢?下一节,我们将进入 "本地 Tool 的实现与 Agent 架构重构" 。
第三节:本地工具的实现与 Agent 架构重构
虽然远程 Tool Server 很强大,但有些任务(比如读写本地项目代码、操作本地数据库)交给远程服务器执行既不安全也不方便。因此,我们需要一套本地工具集。
目前我们的实现采用的是"静态定义"的方式,这能让你最直观地理解工具的 Schema 是如何与逻辑绑定的。
1. 本地工具的静态定义
在 tools/base.py 中,我们手动定义了工具的 Schema (给大模型看的说明书)和 Mapping(对应的 Python 函数)。
Python
import os
from .file_ops import read_file, write_file # 具体的磁盘操作函数
# 1. 任务终结器:告诉 Agent 什么时候该停下
def attempt_completion(result: str = "") -> str:
"""标记任务完成,并返回最终结果给用户"""
return result if result else "任务已完成。"
# 2. 工具函数映射表:将 Schema 中的 name 映射到真实的 Python 函数
LOCAL_TOOLS_MAP = {
"read_file": read_file,
"write_to_file": write_file,
"attempt_completion": attempt_completion,
}
# 3. 标准的 OpenAI Tool Schema 列表
LOCAL_TOOLS = [
{
"type": "function",
"function": {
"name": "write_to_file",
"description": "将内容写入指定的本地文件。如果文件存在则覆盖,不存在则创建。",
"parameters": {
"type": "object",
"properties": {
"absolutePath": {"type": "string", "description": "文件的绝对路径"},
"content": {"type": "string", "description": "要写入的内容"}
},
"required": ["absolutePath", "content"],
"additionalProperties": False,
},
},
},
# ... 其他工具如 read_file 和 attempt_completion 的 Schema
]2. 本地与远程的"双轨制"加载
为了让 Agent 同时拥有本地和远程的能力,我们在 Agent 类初始化时进行"能力聚合":
Python
class Agent:
async def load_tools(self):
"""核心逻辑:合并双向能力"""
# 加载本地写死的工具
self.local_tools = get_tools_from_local()
# 通过 HTTP 从远程 Server 感知新技能
self.server_tools = await get_tools_from_server()
print(f"✅ 能力装载完毕!本地工具: {len(self.local_tools)} | 远程工具: {len(self.server_tools)}")
async def tool_call(self, tool_name: str, arguments: dict) -> str:
"""统一分发中心"""
# 优先在本地寻找映射关系
if tool_name in LOCAL_TOOLS_MAP:
return LOCAL_TOOLS_MAP[tool_name](**arguments)
# 如果本地没有,则发起网络请求交给远程 Tool Server 执行
return await call_tool_on_server(tool_name, arguments)3. 关于更高级的"本地工具加载机制"
你可能会问: "本地工具现在是写死的,如果我也想让它像远程工具一样动态加载(比如丢一个 Python 文件进文件夹,Agent 自动就能用),该怎么办?"
这其实就是 MCP (Model Context Protocol) 协议尝试解决的问题之一。
核心思路是:
- 定义一套标准接口。
- 实现一个本地加载器,扫描特定目录下的
.py文件。 - 自动解析函数签名生成 JSON Schema。
- 使用我们上一节提到的
RestrictedPython或类似的沙箱在本地执行这些代码。
笔者的话: 目前为了让大家快速上手,我们先采用"手动定义"的方式。如果你对 "如何实现一套生产级的、基于 MCP 标准的本地工具动态发现机制" 感兴趣,请在留言区扣个 1 或者大声告诉我!如果需求强烈,我会在本系列的进阶篇中专门手把手带大家撸一套 MCP-Ready 的本地插件系统。
本节小结
现在的 Agent 已经不再是一个"只会吹牛"的聊天机器人了。
- 它能通过 Remote Tool 去外网搜集情报(查天气、调 API);
- 它能通过 Local Tool 在你的电脑上写代码、记笔记;
- 它甚至知道通过
attempt_completion在任务完成后礼貌地向你汇报。
attempt_completion我们在下一节会提到,其实就是在prompt中和大模型的一个约定☝️
万事俱备,只欠东风。在下一节中,我们将重构最关键的 Agent Loop,看看它是如何处理大模型那"九曲十八弯"的思考链路,并最终完成一个"查天气 + 写文件"的复合任务。
第四节:Agent 核心循环的进化(底层流式逻辑重构)
在上一篇中,我们的流式输出只是简单的文本。但现在,我们需要处理大模型传回的碎块化 JSON。
1. 攻克流式 Tool Calls 的难点
当你使用 DeepSeek 且开启 stream=True 时,工具调用的参数(arguments)不是一次性给你的,而是像挤牙膏一样,一小块一小块传回来的:
- 第 1 块:
{"name": "get_f - 第 2 块:
orecast", "argu - 第 3 块:
ments": "{"lat"...
我们需要在底层驱动 DeepSeekLLM 中实时截获并拼接这些碎块。
2. DeepSeekLLM 驱动层的改造
看这段硬核代码,重点在于我们如何处理 attempt_completion 的实时显示:
Python
async def stream_chat(
self,
messages: list,
tools: list = [],
) -> AsyncGenerator[Union[str, Dict], None]:
"""支持实时拼接工具参数并同步 yield 内容"""
response = await self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=tools,
stream=True,
)
tool_calls: List[Dict] = []
attempt_completion_index = None # 标记"任务总结"工具的索引
async for chunk in response:
delta = chunk.choices[0].delta
# 1. 纯文本内容:直接抛给 UI 展示
if delta.content:
yield delta.content
# 2. 核心:处理工具调用的"碎块"
if delta.tool_calls:
for tool_delta in delta.tool_calls:
idx = tool_delta.index
# 初始化该索引下的工具对象
while len(tool_calls) <= idx:
tool_calls.append({"id": None, "type": "function", "function": {"name": None, "arguments": ""}})
tc = tool_calls[idx]
if tool_delta.id: tc["id"] = tool_delta.id
if tool_delta.function and tool_delta.function.name:
tc["function"]["name"] = tool_delta.function.name
# 关键逻辑:如果是完成任务的工具,记录下它的 index
if tool_delta.function.name == "attempt_completion":
attempt_completion_index = idx
if tool_delta.function and tool_delta.function.arguments:
new_part = tool_delta.function.arguments
tc["function"]["arguments"] += new_part # 拼接 JSON 字符串
# 特殊优化:如果 Agent 正在写最终总结,我们不等拼接完,直接 yield 出来!
# 这样用户就能实时看到 Agent 正在汇报的内容,而不是对着屏幕发呆
if attempt_completion_index == idx:
yield {"type": "completion_stream", "content": new_part}
# 流式结束,发送完整的 tool_calls 信号
valid_tool_calls = [tc for tc in tool_calls if tc.get("function", {}).get("name")]
if valid_tool_calls:
yield {"type": "tool_calls", "tool_calls": valid_tool_calls}3. 给 Agent 下达"军令状":System Prompt 的约束
大模型天生有一种"话痨"属性,如果你不明确告诉它什么时候结束,它可能会在完成任务后继续问你"还有什么需要帮忙的吗"。
在我们的 Agent 类初始化时,通过 self.messages 注入了一段至关重要的协议:
Python
self.messages = [
{
"role": "system",
"content": """
你是一个智能助手,可以帮助用户完成各种任务。你可以调用一些工具来获取信息或执行操作。
一旦你完成了用户的任务,你必须使用 attempt_completion 工具向用户展示任务结果。
如果任务不可操作,你也要使用 attempt_completion 工具向用户解释原因。
""",
}
]这段约定的核心逻辑有三点:
- 强制闭环 :我们把
attempt_completion定义为一个工具,而不是普通的对话。这意味着大模型必须经历"思考 -> 决策 -> 调用"的过程来结束任务。 - 统一出口 :无论任务成功还是失败,都必须经过这个工具。这让我们的代码逻辑(
if tool_name == "attempt_completion": return)有了可靠的触发点。 - 结果导向 :通过要求它在调用该工具时提供
result参数,我们迫使大模型在最后对整个执行路径做一个总结,给用户一个清晰的交代。
💡 深度解析:为什么不让它直接说话,而是调用工具?
如果让 Agent 直接用文本回复"任务完成",在复杂的流式输出中,我们很难精准判断它是真的做完了,还是只是在中间过程发发牢骚。
而调用工具是一个极其明确的信号 。这就好比程序员写
return语句,只有明确执行了return,函数才会结束。这种"工具即返回"的设计,是构建可靠 Agent 系统的基石。我在这里也是参考了 Cline 的设计。
4. Agent Loop 改造
Agent 的运行其实就是一个循环:
用户问题
↓
LLM 思考
↓
是否需要工具?
├─ 否 → 直接回答 → 结束
└─ 是 → 调用工具 → 把结果加入上下文 → 再问 LLM循环直到 LLM 调用 attempt_completion。
核心代码如下(精简版,保留关键逻辑):
Python
# 2. 执行所有工具(支持并行)
for tc in tool_calls:
tool_name = tc["function"]["name"]
try:
tool_args = (
json.loads(tc["function"]["arguments"])
if tc["function"]["arguments"]
else {}
)
except json.JSONDecodeError:
tool_args = {}
print(
f"[Warning] 参数解析失败: {tc['function']['arguments']}\n"
)
if tool_name != "attempt_completion":
print(f"tool_call: {tc} \n")
print(f"→ 调用工具: {tool_name}({tool_args})\n")
result = await self.tool_call(
tool_name=tool_name, arguments=tool_args
)
# 把工具结果喂回模型
self.messages.append(
{"role": "tool", "tool_call_id": tc["id"], "content": result}
)
# 如果调用的是 attempt_completion → 任务结束
if tool_name == "attempt_completion":
# 已经实时打印过了,这里只需收尾
print("✅ 任务已完成")
return
print("📨 工具返回:", result, "\n")如果你仔细看,会发现:
Agent 本质就是一个 while True。
但就是这个循环,让 LLM 从"会聊天"变成了"会干活"。
本节小结
如何让 Agent 从"聊友"变成"员工"?
这一节我们重构了 Agent 的执行逻辑,让它从一个只会聊天的网友,变成了**"眼里有活、干活有交代"**的专业数字员工。
- 懂规矩(立下复命制) :我们在系统提示词(System Prompt)里给 Agent 立了死规矩:任务干完必须调用
attempt_completion工具。这就像给程序装了"退出键",防止它任务完成后还拉着你瞎聊。 - 有眼力(汇报看得见) :我们改造了底层驱动,让 Agent 在写最终报告时能边写边展示。你看着屏幕上建议一个个跳出来,这种"实时进度条"让交互更有确定感。
- 效率高(任务一起抓) :现在的 Agent 循环支持并行调用。如果你让它查三个城市的天气,它能一次性把指令全发出去,然后根据反馈(不管是成功还是报错)快速思考下一步。
一句话总结: 我们通过提示词约束 、数据流缝补 和循环调度,让 Agent 真正做到了"干活有交代,汇报有回音"。
第五节:复合任务实战演练
现在,让我们把所有代码串联起来,给 Agent 下达一个极具挑战性的指令:
任务:
"帮我查一下明天纽约的天气,然后根据天气情况写一段 100 字左右的穿衣建议,保存在 "/Users/xxx/weather.md" 文件中。"
注:目前
write_to_file需要绝对路径。当然,你也可以通过增加一个get_env工具让 Agent 自动获取当前环境,这里我们先手动指定。
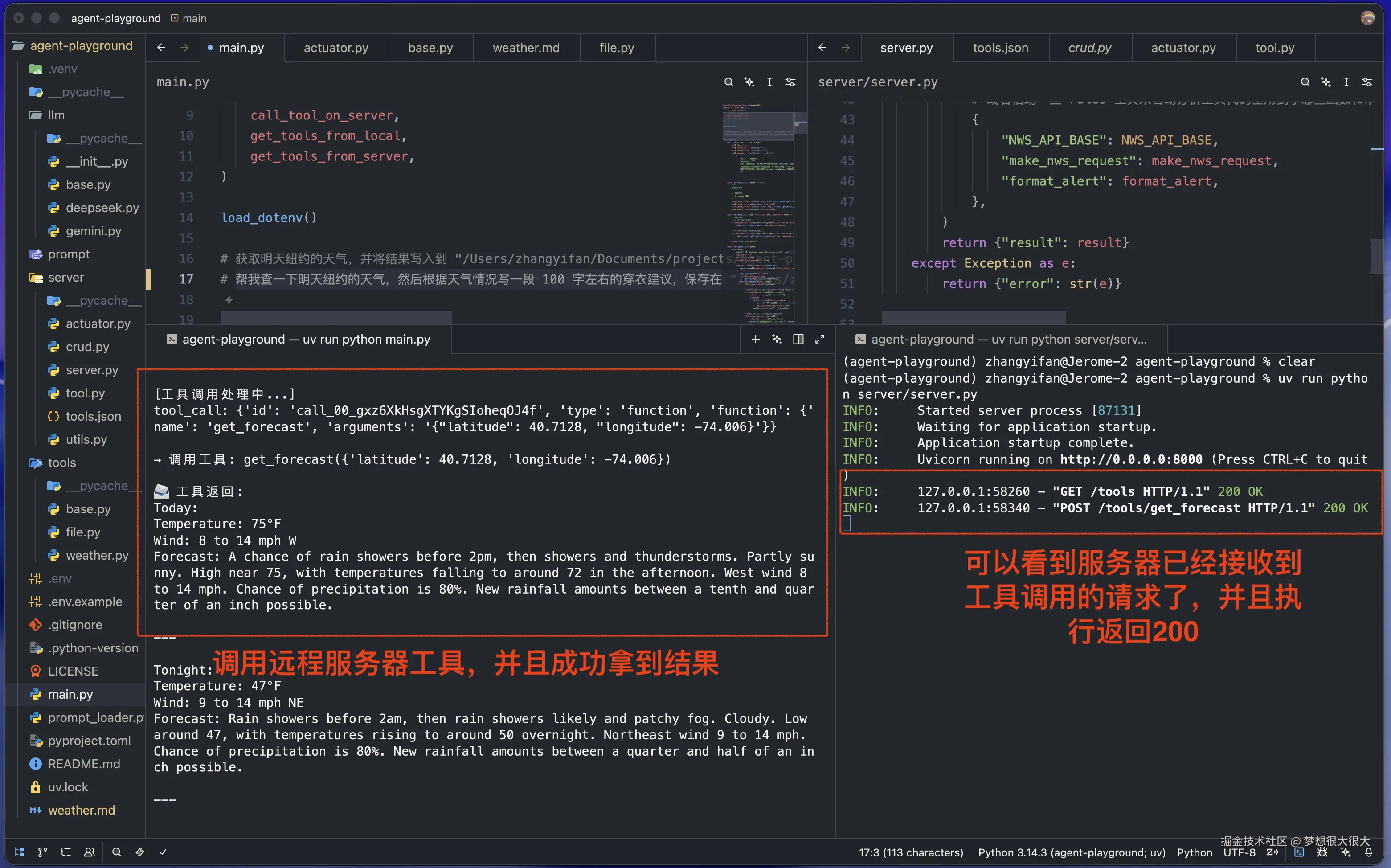
1. 轨迹追踪(Trace):
Agent 并不是在"盲跑",而是经历了严密的逻辑链:
- Step 1:感知与规划 ------ 发现缺失天气数据,调用远程工具
get_forecast。 - Step 2:远程执行 ------ 沙箱返回纽约明天"有雨,10°C"。
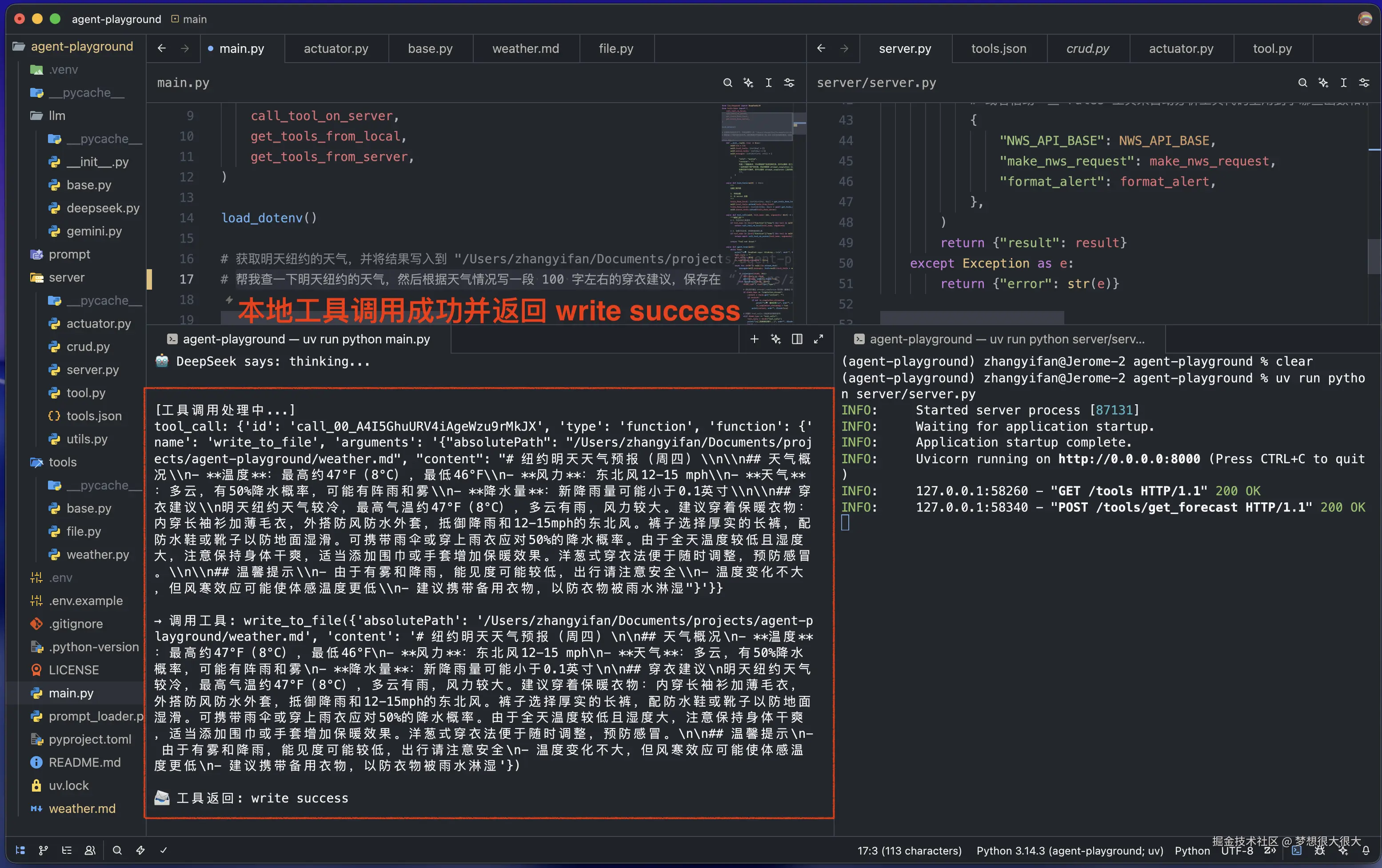
- Step 3:逻辑加工 ------ 根据天气构思建议,意识到需要写文件,调用本地
write_to_file。 - Step 4:本地执行 ------ Python 在本地硬盘精准创建并写入
weather.md。 - Step 5:任务收工 ------ 确认保存后,调用
attempt_completion正式复命。
2. 运行演示:
远程工具调用:
本地工具调用:
文件写入成功:
3. 进阶思考:为什么 Agent 需要"任务进度"?
在演示中你可能发现了一个细节:在大模型接收任务到呼叫第一个工具之间,有一段明显的**"思考空白期"**。
这是因为 DeepSeek-R1 这种推理模型正在后台进行高强度的逻辑拆解。在生产环境里,这种空白会让用户感到焦虑。
思考过程 vs 任务进度 (Task Progress)
- 思考过程:是 Agent 的"内心戏",往往很杂乱,包含大量技术细节。
- 任务进度:是 Agent 的"职业素养"。
我们可以借鉴 Cline 的协议,要求 Agent 在行动前先报备清单。这样用户看到的不再是卡顿,而是实时更新的状态:
- 获取纽约天气数据
- 撰写穿衣建议
- 写入本地 weather.md 文件
这种"确定性"的反馈,是让 AI 从"聊友"变成"专业工具"的关键。 这种 Prompt 治理的艺术,正是我们接下来要探索的领域。
全篇总结
如果第一篇是:
让 LLM 学会使用工具
那么这一篇就是:
给 LLM 建了一整套"技能系统"
现在你的 Agent 已经具备了:
架构层升级
| 能力 | 第一篇 | 第二篇 |
|---|---|---|
| Tool 调用 | 本地硬编码 | 本地 + 远程 |
| Tool 扩展 | 改代码重启 | 配置化动态加载 |
| Tool 执行 | 普通函数 | 沙箱安全执行 |
| Agent Loop | 简单版 | 完整 ReAct |
| 能力组合 | 单工具 | 多步骤任务 |
一句话总结:
你的 Agent 已经从"玩具"进化成了"系统"。
下一篇预告(非常关键 🚨)
到这里,其实出现了一个更大的问题:
现在 Tool 已经可以无限扩展了。
那 Prompt 怎么管理?
- 如何让 Agent 更聪明地规划任务?
- 如何避免无限循环?
- 如何让 Agent 记住长期上下文?
- 如何构建真正可用的 Multi-Agent?
下一篇我们将进入:
Agent 的大脑 ------ Prompt Engineering + Memory 设计
这将是真正决定 Agent 智商的一章 🧠
🔗 源码与延伸阅读
本文源码仓库:GitHub - agent-playground
如果你对 Agent 的演进方向非常感兴趣,强烈推荐提前预习 B 站这个关于 Prompt 的硬核系列: