第五章
dmidecode与free命令给出的内存大小不一样
sudo dmidecode -t memory | grep -E "^\s*Size:.*MB|^\s*Size:.*GB" | grep -v "No Module Installed"
free -h
固件
固件是位于主板上的使用SPI Nor Flash存储着的软件。起着在硬件和操作系统中间承上启下的作用。它对外提供的接口规范是高级配置和电源接口(ACPI,Advanced Configuration and Power Interface )
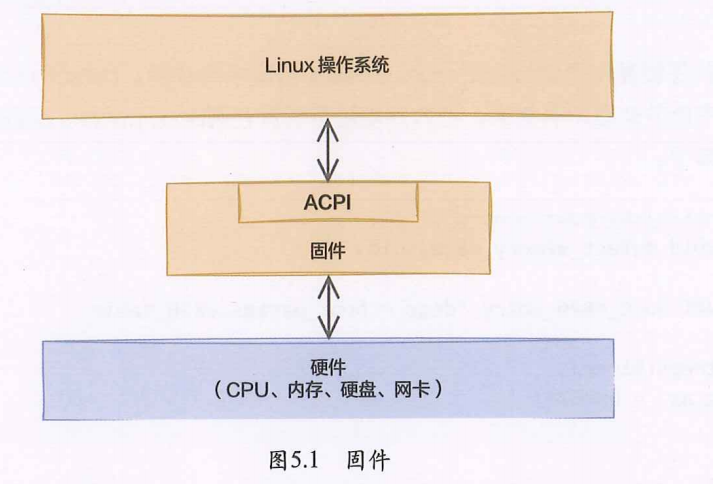
在这个规范中,定义了计算机硬件和操作系统之间的接口,包含的主要内容有计算机硬件配置描述、设备通信方式、电源功能管理等。在计算机启动的过程中,固件负责着硬件自检、初始化硬件设备、加载操作系统引导程序,将控制权转移到操作系统并提供接口供操作系统读取硬件信息。操作系统所需要的内存等硬件信息都是通过固件来获取的。
物理内存安装检测
操作系统启动后第一件关键事情就是:确定物理内存的分布情况(哪些地址可用、哪些不可用)
内核通过 BIOS 提供的标准接口:
int 0x15 + eax = 0xE820
来获取内存布局
返回的信息是一组结构体(e820 entry),每一项表示:
[起始地址, 长度, 类型]类型包括:
- usable(可用)
- reserved(保留)
- ACPI
- NVS 等
源码流程:
start_kernel
└── setup_arch
└── e820__memory_setup
├── x86_init.resources.memory_setup
│ └── default_machine_specific_memory_setup
│ └── e820__memory_setup_default
│ → 选择具体的内存探测方案(通常就是 E820)
│
├── sanitize_e820_map
│ → 清洗 BIOS 返回的内存布局(排序/去重/解决重叠/修正类型)
│
├── copy_e820_table
│ → 将 boot_params.e820_table 复制到全局 e820_table(内核正式使用)
│
└── e820__print_table
→ 打印最终物理内存布局(dmesg 中看到的内容)
(更早期:boot 阶段,实模式/过渡阶段)
main (arch/x86/boot/main.c)
└── detect_memory
└── detect_memory_e820
├── intcall(0x15, E820)
│ → 调用 BIOS 中断获取一条内存区间信息
│
├── 保存到 boot_params.e820_table
│ → 临时存储 BIOS 返回的原始数据
│
└── 循环直到所有内存区间获取完成
→ 得到完整物理内存地图(但可能是"脏数据")系统启动后,内核首先需要知道机器上有哪些物理内存是可以使用的。这个信息并不是内核自己发现的,而是由 BIOS 提供。内核在非常早期(还在 boot 阶段)通过 int 0x15, E820 接口不断向 BIOS 查询,每次获取一段物理内存区间的信息(起始地址、大小、类型),并把这些原始数据暂时存放在 boot_params.e820_table 中。
进入内核初始化阶段后,e820__memory_setup 会接管这些数据。此时内核并不会直接使用 BIOS 提供的结果,而是先通过 sanitize_e820_map 对这些数据进行清洗,因为 BIOS 返回的数据可能存在乱序、重叠甚至错误标记的问题。清洗完成后,内核将整理好的内存布局复制到全局的 e820_table 中,这才成为后续内核真正使用的物理内存描述。
最后,内核通过 e820__print_table 将这份整理后的内存地图打印出来(也就是你在 dmesg 中看到的内容)。从这一刻开始,这份 E820 内存布局就成为整个 Linux 内存管理体系的基础,后续的 memblock、buddy 分配器乃至 slab 分配器,都是在这份"可用物理内存范围"的基础上运行的。
memblock分配器
memblock分配器创建
内核在通过E820机制检测到可用的内存地址范围后,调用e820_memory_setup函数把检测结果保存到e820_table全局数据结构中。紧接着下一步就是调用e820_memblock_setup函数创建 memblock 内存分配器。
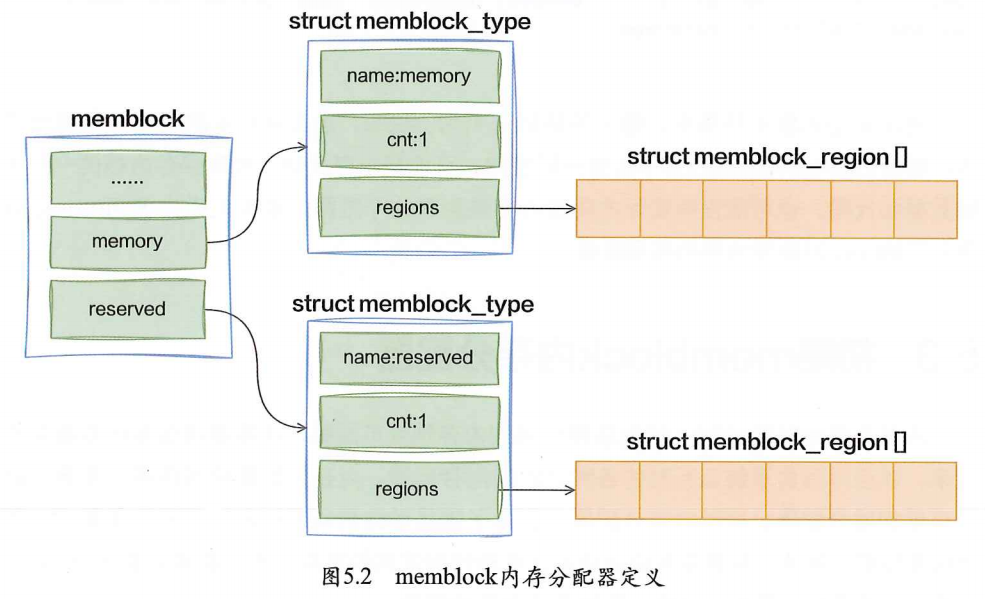
memblock = 把 e820 的内存划分为两类,并用数组管理
memblock的实现非常简单,就是按照检测到的内存地址范围是usable还是reserved分成两个对象,然后分别用memblock_region数组存起来。
函数调用
start_kernel
└── setup_arch
├── e820__memory_setup
│ → 先完成 E820 内存探测结果整理(得到 e820_table)
│
└── e820__memblock_setup
├── 遍历 e820_table(每一段物理内存)
│
├── if (entry->type == RESERVED / SOFT_RESERVED)
│ └── memblock_reserve(addr, size)
│ → 加入 memblock.reserved(表示已占用/不可分配)
│
├── else (usable)
│ └── memblock_add(addr, size)
│ → 加入 memblock.memory(表示可用内存池)
│
└── memblock_dump_all
→ 打印当前 memblock 状态(memory/reserved 列表)在内核通过 E820 获取并整理好物理内存布局之后,e820__memblock_setup 会遍历每一段内存,根据其类型将可用内存通过 memblock_add 加入 memblock.memory,将不可用或已占用内存通过 memblock_reserve 加入 memblock.reserved,从而构建出一个基于区间列表的简单内存管理结构;最终形成一个"可分配 + 已占用"分离的内存视图,供内核早期阶段进行物理内存分配使用。
向memblock分配器申请内存
crash kernel 内存申请
为什么要有这个机制?
内核为了在崩溃时能记录崩溃的现场,方便以后排查分析,设计实现了一套kdump机制。kdump机制在服务器上启动了两个内核,第一个是正常使用的内核,第二个是崩溃发生时的应急内核。有了kdump机制,发生系统崩溃的时候kdump使用kexec启动到第二个内核中运行。这样第一个内核中的内存就得以保留下来。然后可以把崩溃时的所有运行状态都收集到dumpcore中。
函数调用
start_kernel
└── setup_arch
├── e820__memory_setup
│ → 获取物理内存布局(e820_table)
│
├── e820__memblock_setup
│ → 构建 memblock(memory / reserved)
│
├── reserve_crashkernel_low
│ ├── memblock_phys_alloc_range(size, align, 0, max_low)
│ │ → 从低端内存中找一块连续物理内存
│ │
│ ├── memblock_reserve(addr, size)
│ │ → 标记为 reserved(防止再次分配)
│ │
│ └── pr_info(...)
│ → 打印日志(低端 crashkernel)
│
└── reserve_crashkernel
├── memblock_phys_alloc_range(size, align, min, max)
│ → 在指定范围内申请 crashkernel 内存
│
├── memblock_reserve(addr, size)
│ → 加入 reserved 列表
│
└── pr_info(...)
→ 打印日志(普通 crashkernel)在 memblock 初始化完成后,内核通过 reserve_crashkernel_low 和 reserve_crashkernel 调用 memblock_phys_alloc_range 从可用物理内存中选取符合范围和对齐要求的连续区域,并通过 memblock_reserve 将其标记为已占用加入 reserved 列表,从而在系统启动早期预留出专门用于 crash kernel 的内存空间,这些内存在系统运行过程中不会被普通分配使用,以保证在内核崩溃时仍然有一块可靠的内存用于启动备用内核并完成内存转储。
页管理初始化
将来Linux的伙伴系统是按页的方式来管理所有的物理内存的,页的大小是4KB。每一个页都需要使用一个struct page对象来表示。这个对象也是需要消耗内存的。在不同的版本中,structpage的大小不一样,一般是64字节。
start_kernel
└── setup_arch
├── e820__memory_setup
│ → 获取物理内存布局(e820_table)
│
├── e820__memblock_setup
│ → 构建 memblock(memory / reserved)
│
└── x86_init.paging.pagetable_init
→ 初始化页表(建立虚拟地址映射)
└── paging_init
├── 初始化 zone(DMA / Normal 等内存区域划分)
│ → 把物理内存按用途分区
│
├── 为每个物理页创建 struct page
│ → 建立"页描述符数组"(核心数据结构)
│
├── 建立伙伴系统(buddy allocator)
│ → 形成真正的内存分配器
│
└── 标记哪些页可用 / 不可用
→ reserved 不参与分配
└── mem_init
├── memblock_free_all
│ → 把 memblock 中的可用内存交给 buddy
│
└── 完成内存管理体系接管
→ memblock 退出在完成 memblock 对物理内存的初步管理后,内核通过页管理初始化(paging_init)建立页表映射、划分内存区域(zone),并为每个物理页创建对应的 struct page 结构,从而将"物理内存区间"转换为"可管理的页对象",随后初始化 buddy 分配器来接管内存分配;最后通过 memblock_free_all 将 memblock 中的可用内存全部交给 buddy 系统,从而完成从早期内存管理(memblock)向正式内存管理体系(页 + buddy)的过渡。
内存页管理模型也经过了几代的变化,在最早的时候,采用的是FLAT模型,中间还经历了DISCONTIG模型,现在都默认采用SPARSEMEM模型。SPARSEMEM模型在内存中就是一个二维数组。
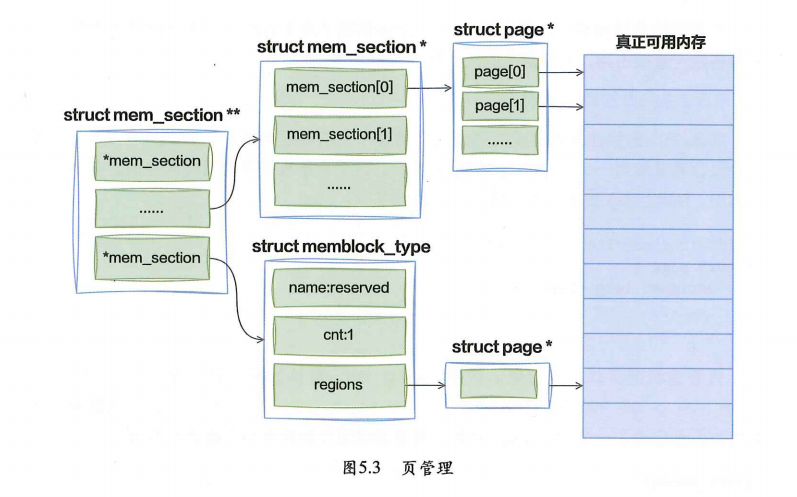
mem_section ** → 内存分段索引(两级结构)
↓
mem_section * → 每一段内存
↓
struct page[] → 每个物理页的描述符
↓
物理内存 → 真正的 RAM(4KB 一页)这是一个"从粗到细"的分层管理结构:先用 mem_section 分段,再用 struct page 管理每一页,从而让内核可以对物理内存进行精细化控制。
NUMA信息感知
NUMA的全称是Non-uniformmemoryaccess,是非一致性内存访问的意思
操作系统和硬件之间存在着这个固件(firmware),它的接口规范是ACPI。在ACPl的6.5接口规范第17章中描述了NUMA相关的内容。在ACPI中定义了两个表,分别是:
SRAT(System Resource Afinity Table),在这个表中表示的是CPU核和内存的关系图。包括有几个node,每个node里面有哪几个CPU逻辑核,有哪些内存。
SLIT(System LocalityInformation Table),在这个表中记录的是各个节点之间的距离。
函数调用
start_kernel
└── setup_arch
├── e820__memory_setup
│ → 获取物理内存布局(e820_table)
│
├── e820__memblock_setup
│ → 构建 memblock(memory / reserved 区间)
│
└── initmem_init
├── x86_numa_init
│ → NUMA 初始化入口(架构相关)
│
├── numa_init
│ → 通用 NUMA 初始化流程
│
├── x86_acpi_numa_init
│ → 通过 ACPI 获取 NUMA 信息
│
└── acpi_numa_init
├── acpi_table_parse(SRAT)
│ → 解析 SRAT 表(CPU/内存属于哪个 node)
│
├── 构建 numa_meminfo
│ → 记录:每段内存属于哪个 node
│
└── numa_register_memblks
├── memblock_set_node(addr, size, nid)
│ → 给每个 memblock region 标记 node id
│
├── alloc_node_data(nid)
│ → 为每个 node 分配 pglist_data(内存管理结构)
│
└── memblock_dump_all
→ 打印带 NUMA 信息的 memblock在内核完成 memblock 初始化之后,通过 ACPI 的 SRAT 表获取硬件提供的 NUMA 拓扑信息,将每段物理内存与对应的 NUMA 节点建立关联(numa_meminfo),随后在 numa_register_memblks 中通过 memblock_set_node 将 node id 标记到 memblock 的每个内存区间上,并为每个节点分配独立的内存管理结构(pglist_data),从而把原本统一的物理内存划分为多个 NUMA 节点的内存池,为后续基于本地性优化的内存分配打下基础。
伙伴系统
伙伴系统相关数据结构
ailab1@k8s-master:~/Desktop$ numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
node 0 size: 31686 MB
node 0 free: 24253 MB
node distances:
node 0
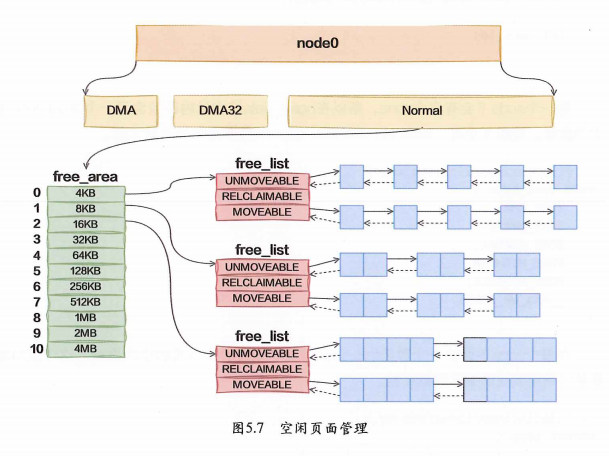
0: 10 内存管理的Page如图所示
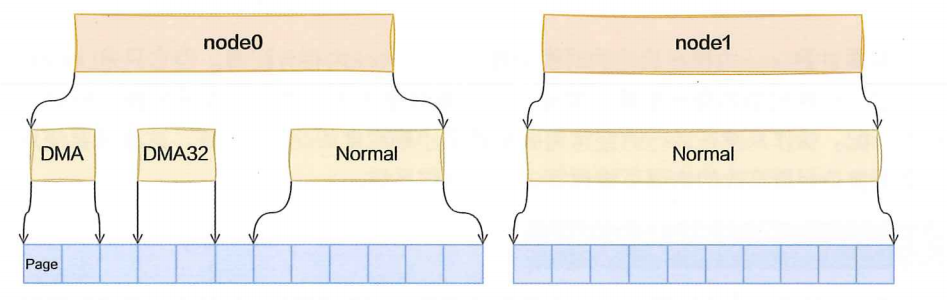
Zone表示内存中的一块范围,有不同的类型:
- ZONE_DMA:地址段最低的一块内存区域,支持ISA(Industry StandardArchitecture)设备DMA访问。
- ZONE_DMA32:该Zone用于支持32位地址总线的DMA设备,只在64位系统里才有效。
- ZONE NORMAL:在X86-64架构下,DMA和DMA32之外的内存全部在NORMAL的Zone里管理。
数据结构如下
struct zone {
const char *name;
struct free_area free_area[MAX_ORDER];
}pglist_data表示一个NUMA节点的全部内存管理结构
struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
int node_id;
}Linux 将物理内存按 NUMA 节点划分为多个 node,每个 node 再按用途划分为多个 zone,每个 zone 内通过 free_area(伙伴系统)管理 struct page,从而实现分层、可扩展的物理内存管理体系。
从 memblock 到最终结构的演进
memblock(区间)
↓
NUMA(分 node)
↓
zone(按用途)
↓
struct page(页级)
↓
free_area(管理空闲页)伙伴算法管理空闲页面
通过cat /proc/pagetypeinfo可以看到当前系统里伙伴系统各个尺寸的可用连续内存块数量
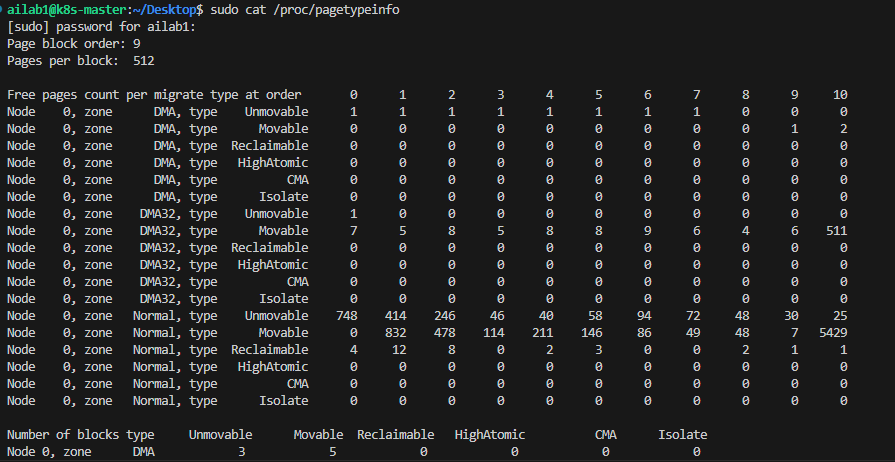
内存先按用途划分为 DMA、DMA32、Normal 等 zone,每个 zone 内都有一套伙伴系统(free_area),按 order(4KB 到 4MB)管理不同大小的连续页块;每个大小的块又按照迁移类型(UNMOVABLE、RECLAIMABLE、MOVABLE)分别挂在不同的 free_list 链表上,从而既能按"大小"快速找到合适的连续内存,又能按"可迁移性"减少内存碎片,最终实现高效且可控的物理页分配。
当内核或者用户进程需要物理页的时候,就可以调用alloc_pages申请真正的物理内存。alloc_pages从zone的free_area空闲页面链表中寻找合适的内存块返回
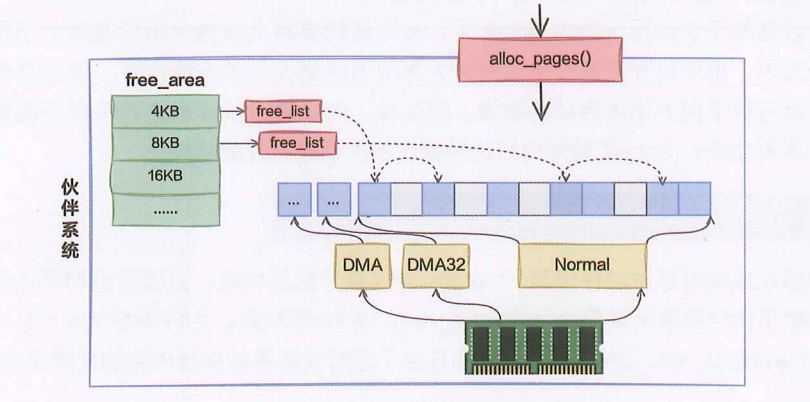
当内核调用 alloc_pages() 申请一块连续物理页时,会先在对应 zone(DMA / DMA32 / Normal)中查找目标大小(order)的 free_area 链表(free_list);如果该大小的链表为空,就会向更大的 order 查找可用块,一旦找到,就逐级"向下拆分"(大块拆成多个小块),最终得到所需大小的连续页块返回给调用者,同时把拆分过程中多余的小块重新挂回对应的 free_list 中;整个过程就是在不同 zone 中,从伙伴系统的分级空闲链表里"找 → 借 → 拆 → 回填"的过程,实现连续物理内存的高效分配。
memblock向伙伴系统交接物理内存
整体调用链
start_kernel
└── setup_arch
├── e820__memory_setup
├── e820__memblock_setup
├── paging_init
└── mem_init
└── memblock_free_all ← ★交接发生在这里函数入口,把memblock.memory 里的"可用内存"逐页交给 buddy
void memblock_free_all(void)
{
pages = free_low_memory_core_early();
totalram_pages_add(pages);
}free_low_memory_core_early()
(1)reserved 内存处理
(2)遍历可用内存
// 1. 处理 reserved
memmap_init_reserved_pages();
// 2. 遍历所有"可用内存"
for_each_free_mem_range(...)
__free_memory_core(start, end);__free_memory_core()
__free_memory_core
└── __free_pages_memory
└── memblock_free_pages
└── __free_pages_ok
└── __free_one_page最后把page加入zone->free_area,从这时候开始,这页内存正式归buddy管了
总结一下,就是memblock_free_all 通过遍历 memblock 中的可用内存区间,将每个物理页转换为 struct page 并逐个加入对应 zone 的 buddy(free_area)链表中,从而把内存管理权从 memblock 正式移交给伙伴系统。