目录
-
- 一、概述
- 二、索引操作
- 三、文档操作
-
- [3.1 创建文档](#3.1 创建文档)
- [3.2 读取文档](#3.2 读取文档)
- [3.3 更新文档](#3.3 更新文档)
- [3.4 删除文档](#3.4 删除文档)
- 四、DSL查询操作
-
- [4.1 基础查询](#4.1 基础查询)
- [4.1 基础查询](#4.1 基础查询)
-
- [4.1.1 分词查询(match)](#4.1.1 分词查询(match))
- [4.1.2 精确查询(term)](#4.1.2 精确查询(term))
- [4.2 复合查询](#4.2 复合查询)
-
- [4.2.1 布尔查询(bool)](#4.2.1 布尔查询(bool))
- [4.3 范围查询](#4.3 范围查询)
-
- [4.3.1 范围查询(range)](#4.3.1 范围查询(range))
- [4.3.2 日期范围查询(date range)](#4.3.2 日期范围查询(date range))
- [4.4 全文搜索](#4.4 全文搜索)
-
- [4.4.1 短语查询(match_phrase)](#4.4.1 短语查询(match_phrase))
- [4.4.2 多字段查询(multi_match)](#4.4.2 多字段查询(multi_match))
- [4.5 高级查询](#4.5 高级查询)
-
- [4.5.1 函数评分查询(function_score)](#4.5.1 函数评分查询(function_score))
- [4.6 特殊查询](#4.6 特殊查询)
-
- [4.6.1 通配符查询(wildcard)](#4.6.1 通配符查询(wildcard))
- [4.6.2 前缀查询(prefix)](#4.6.2 前缀查询(prefix))
- [4.6.3 模糊查询(fuzzy)](#4.6.3 模糊查询(fuzzy))
- [4.6.4 查询字符串(query_string)](#4.6.4 查询字符串(query_string))
- [4.6.5 文本查询(text)](#4.6.5 文本查询(text))
- 五、聚合操作
-
- [5.1 指标聚合](#5.1 指标聚合)
-
- [5.1.1 求和聚合(sum)](#5.1.1 求和聚合(sum))
- [5.1.2 平均值聚合(avg)](#5.1.2 平均值聚合(avg))
- [5.2 桶聚合](#5.2 桶聚合)
-
- [5.2.1 词条聚合(terms)](#5.2.1 词条聚合(terms))
- [5.2.2 日期直方图聚合(date_histogram)](#5.2.2 日期直方图聚合(date_histogram))
- 六、性能优化
-
- [6.1 使用 Filter 上下文](#6.1 使用 Filter 上下文)
- [6.2 分页与滚动](#6.2 分页与滚动)
-
- [6.2.1 From/Size分页(from/size)](#6.2.1 From/Size分页(from/size))
- [6.2.2 滚动API(scroll)](#6.2.2 滚动API(scroll))
- [6.3 批量操作](#6.3 批量操作)
-
- [6.3.1 批量API(bulk)](#6.3.1 批量API(bulk))
- 七、总结
 适用ES版本:6.x
适用ES版本:6.x
- 在线SQL转ES网址 :https://old.printlove.cn/tools/sql2es
一、概述
Elasticsearch DSL(Domain Specific Language) 是基于 JSON 的查询语言,用于执行复杂的搜索、聚合和数据操作。本文档系统整理了DSL的核心操作类型、语法结构和最佳实践,帮助开发者快速掌握ES查询能力。
二、索引操作
索引库 就类似 数据库表 ,mapping 映射就类似表的结构。
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是 JSON 文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL 是 ES 提供的 JSON 风格的请求语句,用来操作 ES,实现CRUD。 |
| 增 | PUT | 使用 PUT 请求创建或更新文档,指定文档ID |
| 删 | DELETE | 使用 DELETE 请求删除指定文档或整个索引 |
| 改 | POST | 使用 POST 请求更新文档,支持部分字段更新 |
| 查 | GET | 使用 GET 请求查询文档或索引信息 |
2.1 索引结构(Mapping)
在了解创建索引之前,我们需要先了解一下 ES 的索引结构定义,也就是 Mapping。
Mapping 是对索引库中文档的约束,常见的 Mapping 属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
index:是否创建索引,默认为trueanalyzer:使用哪种分词器(只有字符串中text需要用到)properties:该字段的子字段
2.2 分片(Shard)与副本(Replica)
1)核心概念
分片(Shard)是 Elasticsearch 中数据水平拆分的最小单元,用于实现 分布式存储与并行处理。每个分片本质上是一个独立的 Lucene 索引,包含独立的数据和倒排索引。副本(Replica)是分片的完整拷贝,用于实现 数据冗余、高可用性和读取负载均衡。
2)技术原理与作用
分片(Shard):
| 特性 | 说明 |
|---|---|
| 数据分布 | 索引被拆分为多个分片,数据均匀分布在不同节点上 |
| 并行处理 | 查询和索引操作可并行执行,提升吞吐量 |
| 容量扩展 | 单个分片有 50GB 上限,大容量需多分片 |
| 不可变性 | 分片创建后数量不可更改(需重新索引) |
分片策略:
- 主分片(Primary Shard):数据写入的目标分片,每个文档只存在于一个主分片
- 分片数决定:
分片数 = 总数据量 / 单个分片理想大小(通常 10-50GB/分片)
副本(Replica):
| 特性 | 说明 |
|---|---|
| 数据冗余 | 每个主分片可有一个或多个副本,防止数据丢失 |
| 高可用 | 主分片失效时,副本自动提升为主分片 |
| 读扩展 | 副本可处理查询请求,分担主分片压力 |
| 写限制 | 副本不接收写入,只接收主分片的变更日志 |
3)配置与计算
分片分配公式:
properties
总分片数 = 主分片数 + 副本数 × 主分片数 示例:
- 主分片数:3
- 副本数:1
- 总分片数:3 + (1 × 3) = 6(3个主分片 + 3个副本分片)
最佳实践建议:
- 分片数量规划
- 单个分片大小:10-50GB(避免过大影响性能)
- 分片数量:根据数据增长预估,预留 20-30% 余量
- 避免过度分片:过多小分片会增加集群开销
- 副本策略
- 生产环境:至少 1 个副本(保证高可用)
- 关键数据:可设置 2 个副本(容忍多节点故障)
- 测试环境:可设为 0 副本(节省资源)
- 硬件考量
- 每个分片需要独立的内存和磁盘资源
- 副本数增加会加倍存储需求
- 副本数增加可提升读取吞吐量
4)实际应用场景
场景一:电商订单索引
json
{
"settings": {
"number_of_shards": 5, // 5个主分片
"number_of_replicas": 1 // 每个主分片1个副本
}
}- 总容量:假设每个分片 20GB,总存储需求 = 5 × 20GB × (1+1) = 200GB
- 可用性:可容忍 1 个节点故障
场景二:日志分析系统
json
{
"settings": {
"number_of_shards": 10, // 10个主分片
"number_of_replicas": 0 // 无副本(日志可重建)
}
}- 写入性能优先,存储成本敏感
- 数据可通过日志重放重建
2.2 创建索引(PUT)
基本语法:
- 请求方式:PUT
- 请求路径:
/{索引名称},可以自定义 - 请求参数:mapping映射
格式:
json
PUT /索引名称
{
"settings": {
"number_of_shards": 5, // 分片数
"number_of_replicas": 1 // 副本数
},
"mappings": {
"_doc": {
"properties": {
"字段名1":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": false
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
}示例:
json
PUT /user_info
{
"settings": {
"number_of_shards": 5, // 分片数
"number_of_replicas": 1 // 副本数
},
"mappings": {
"_doc": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
}
}
}
}
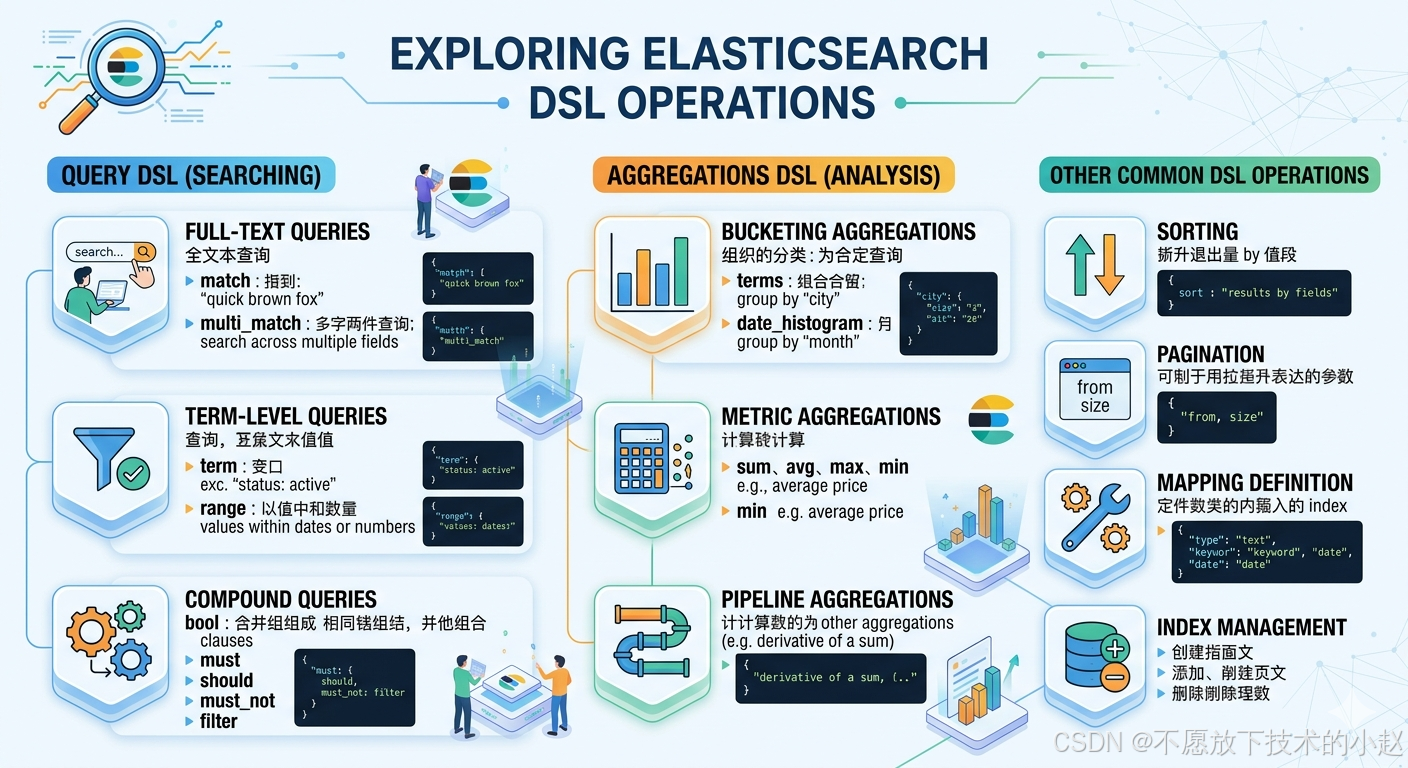
}使用PUT请求创建新索引,可定义分片、副本和字段映射。
json
PUT /products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"title": { "type": "text" },
"price": { "type": "float" },
"status": { "type": "keyword" },
"publish_date": { "type": "date" }
}
}
}
}-
PUT /index_name:创建或更新索引的REST API端点 -
settings:定义索引的物理配置,如分片和副本数量 -
mappings:定义字段的数据类型和索引方式,是数据建模的核心 -
_doc:类型名。- 如果是ES 6.x:使用
"doc"或"_doc"作为类型名 - 如果是ES 7.x+:使用
"_doc"或直接省略类型名
- 如果是ES 6.x:使用
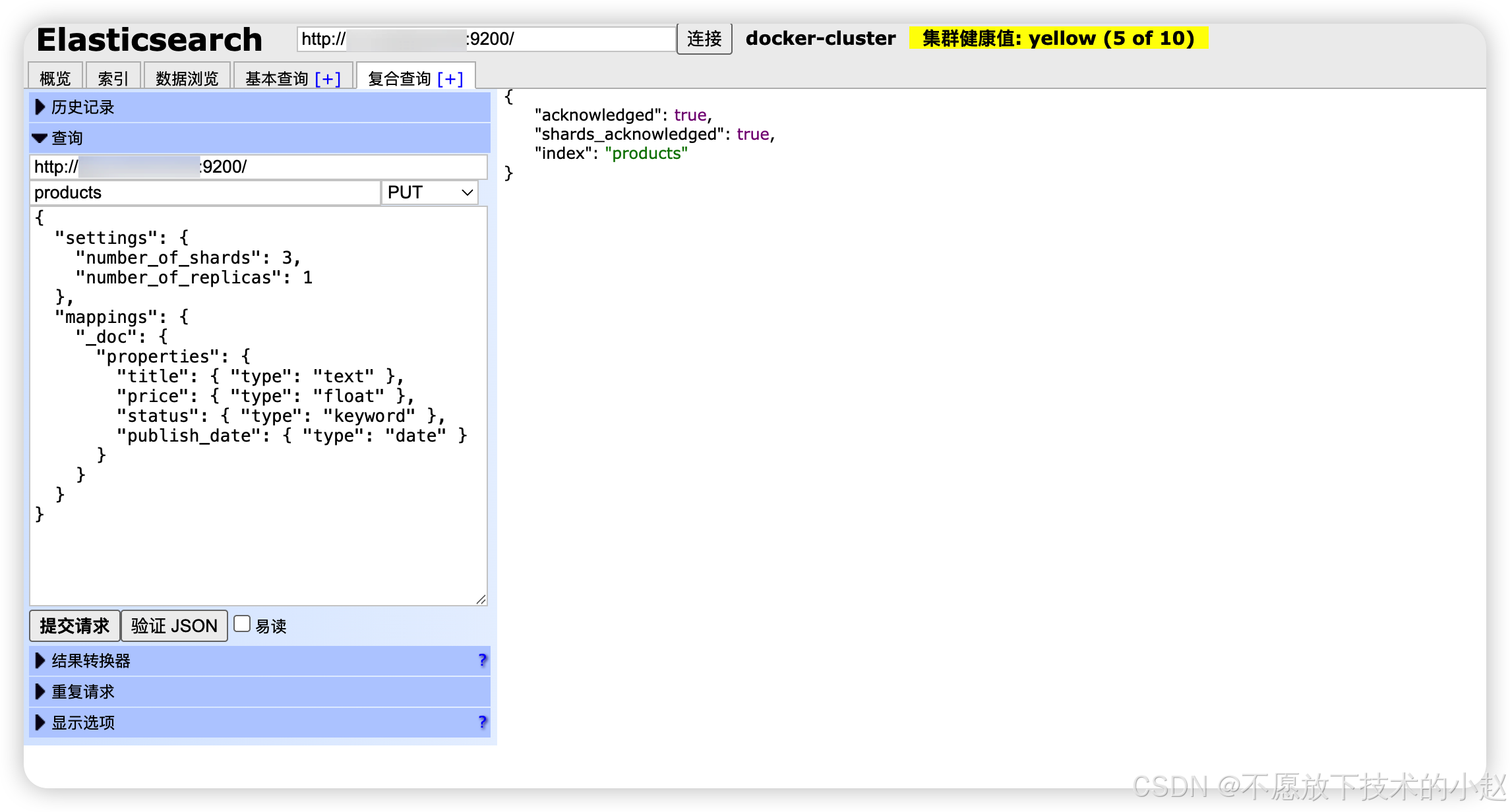
2.3 查询索引(GET)
获取索引的设置、映射和统计信息。
GET /index/_settings:查看索引的配置参数
json
// 获取索引设置
GET /products/_settings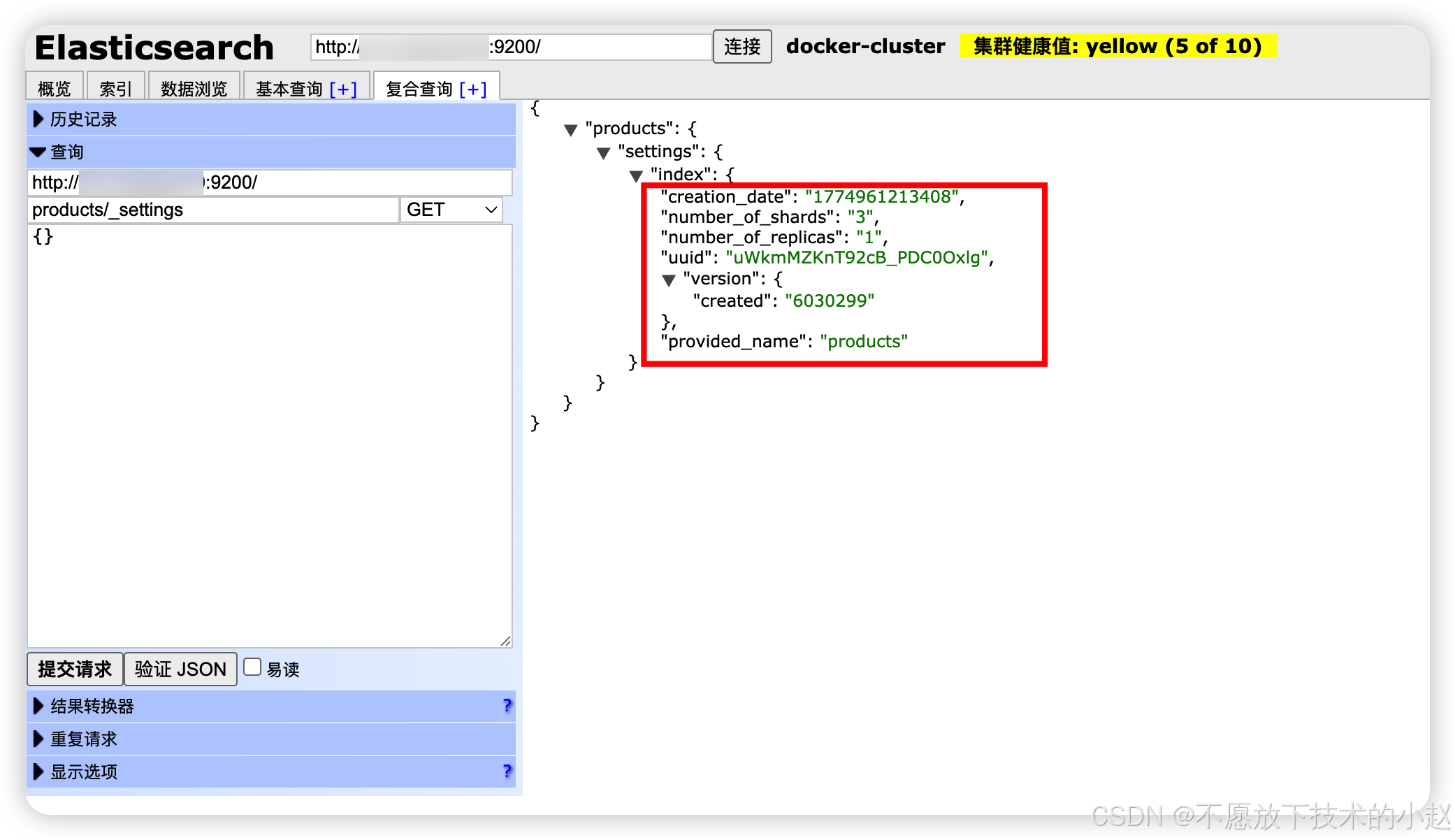
GET /index/_mapping:查看字段结构定义
java
// 获取索引映射
GET /products/_mapping
GET /index/_stats:获取索引的存储、文档数量等运行时指标
java
// 获取索引统计信息
GET /products/_stats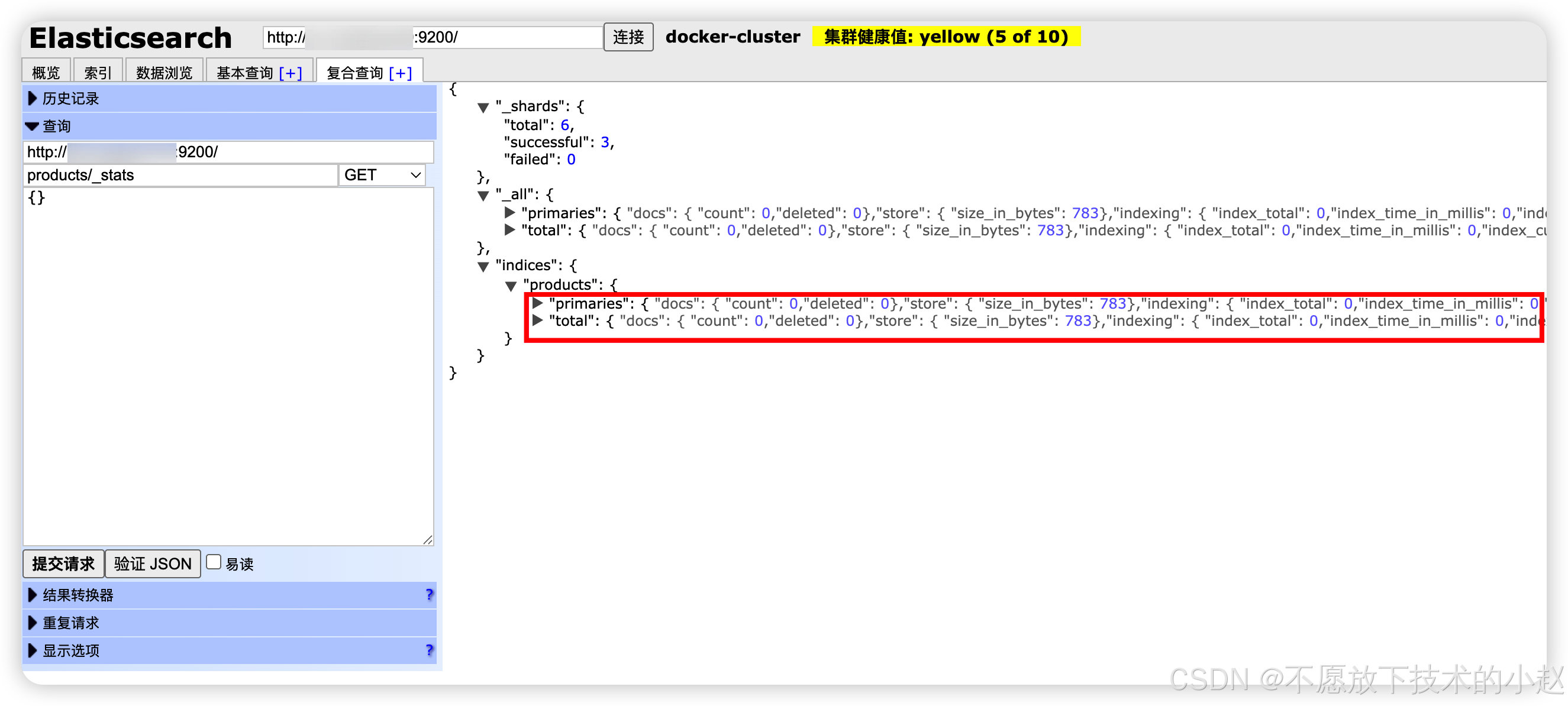
2.4 更新索引(PUT)
动态修改索引设置或添加新字段映射。
生产环境建议
✅ 推荐做法
- 先在测试环境验证
- 非高峰时段执行
- 小批量逐步添加
- 添加前备份映射配置
- 监控集群性能和状态
❌ 避免做法
- 不要修改现有字段类型
- 不要删除已有字段
- 不要在高并发时段操作
- 不要一次添加过多字段
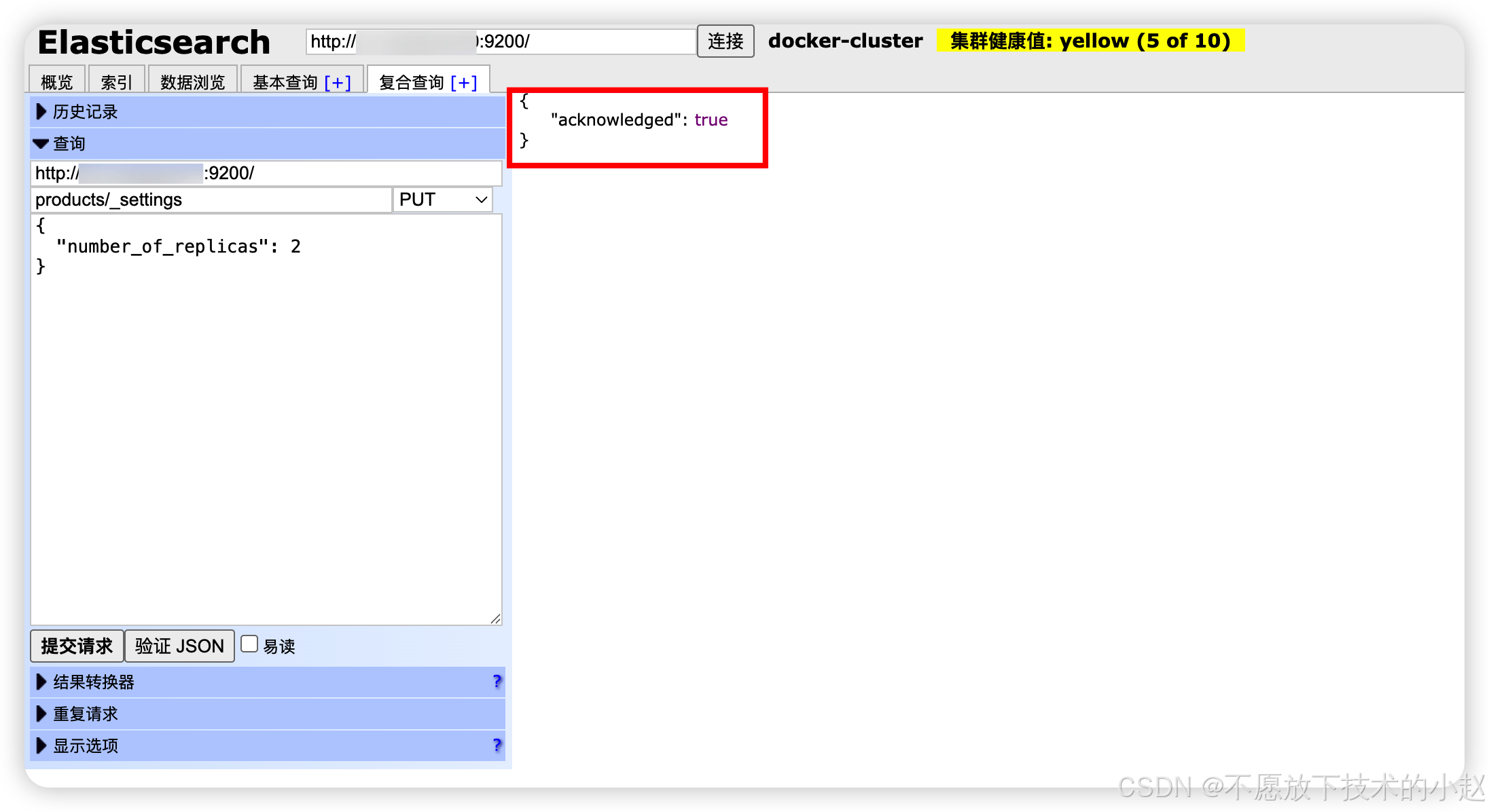
_settings:用于调整索引的运行时参数,如副本数。
java
// 更新副本数量
PUT /products/_settings
{
"number_of_replicas": 2
}
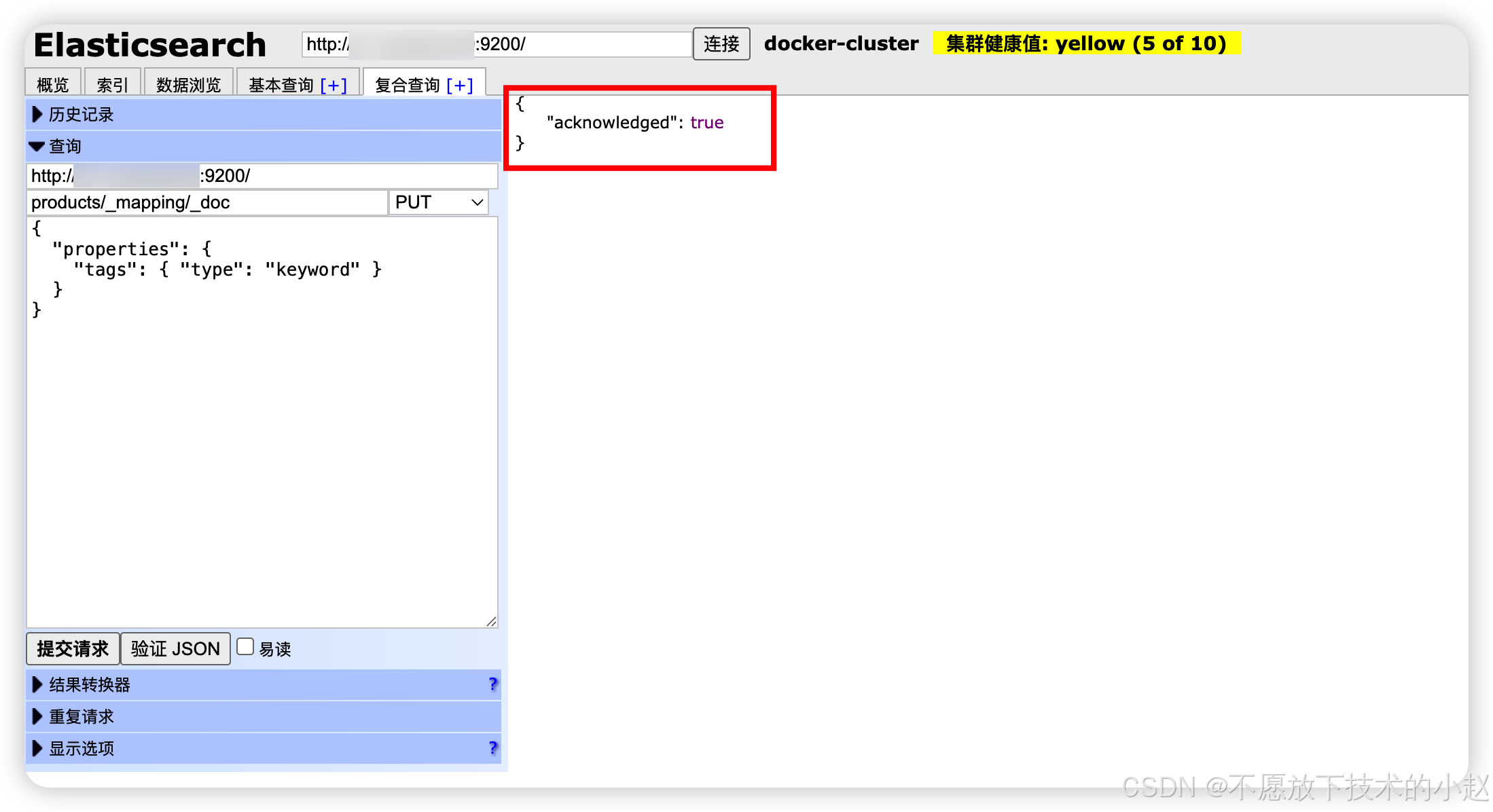
_mapping:用于扩展字段定义,生产环境应谨慎使用。
json
// 添加新字段映射
PUT /products/_mapping/_doc
{
"properties": {
"tags": { "type": "keyword" }
}
}
2.5 删除索引(DELETE)
使用DELETE请求移除整个索引及其数据。
DELETE /index_name:永久删除索引,操作不可逆,需确认数据备份
json
DELETE /products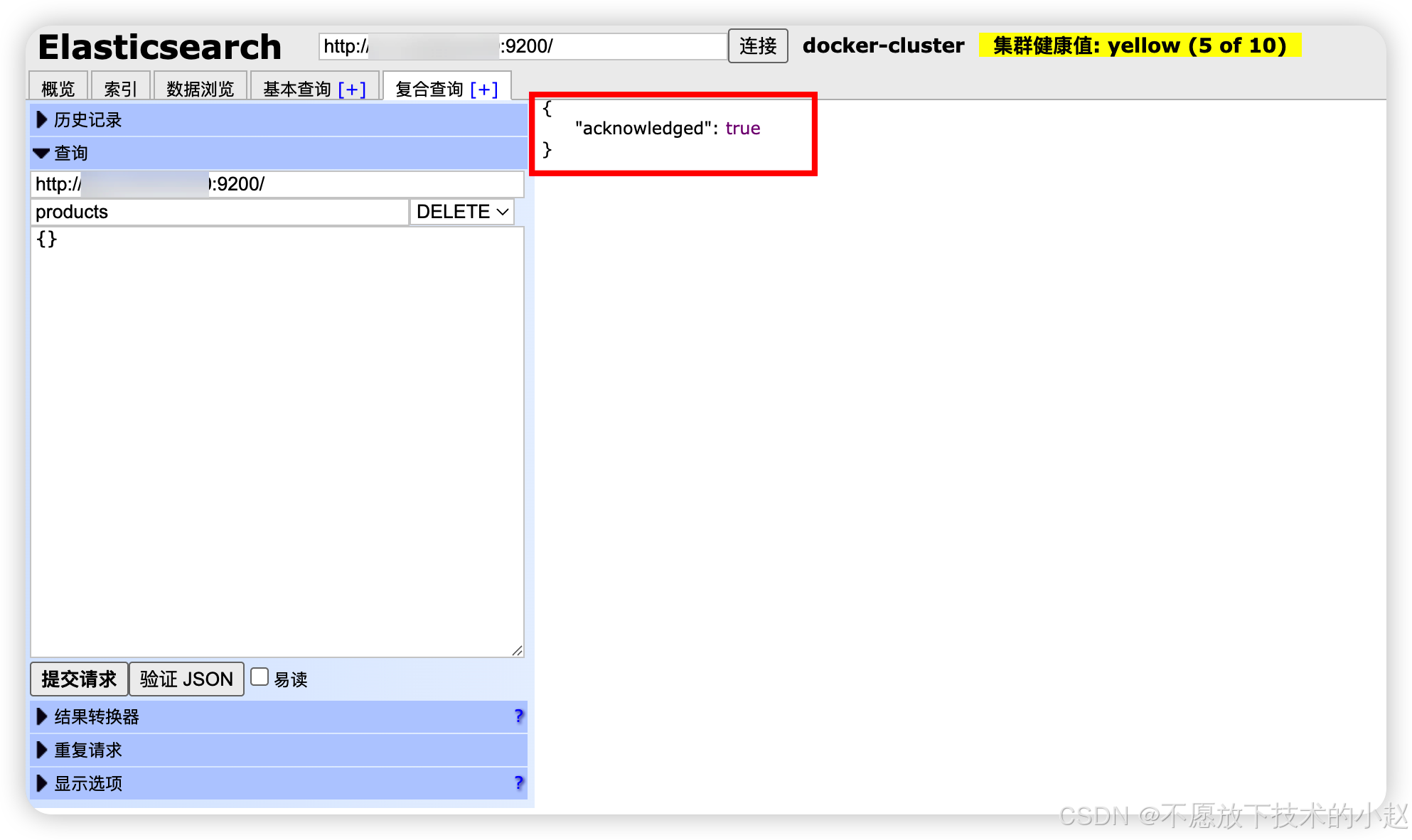
三、文档操作
文档操作是 Elasticsearch 数据操作的核心,涵盖文档的创建、读取、更新和删除,是日常数据交互的基础。
3.1 创建文档
使用 PUT 或 POST 请求向索引中添加新文档。
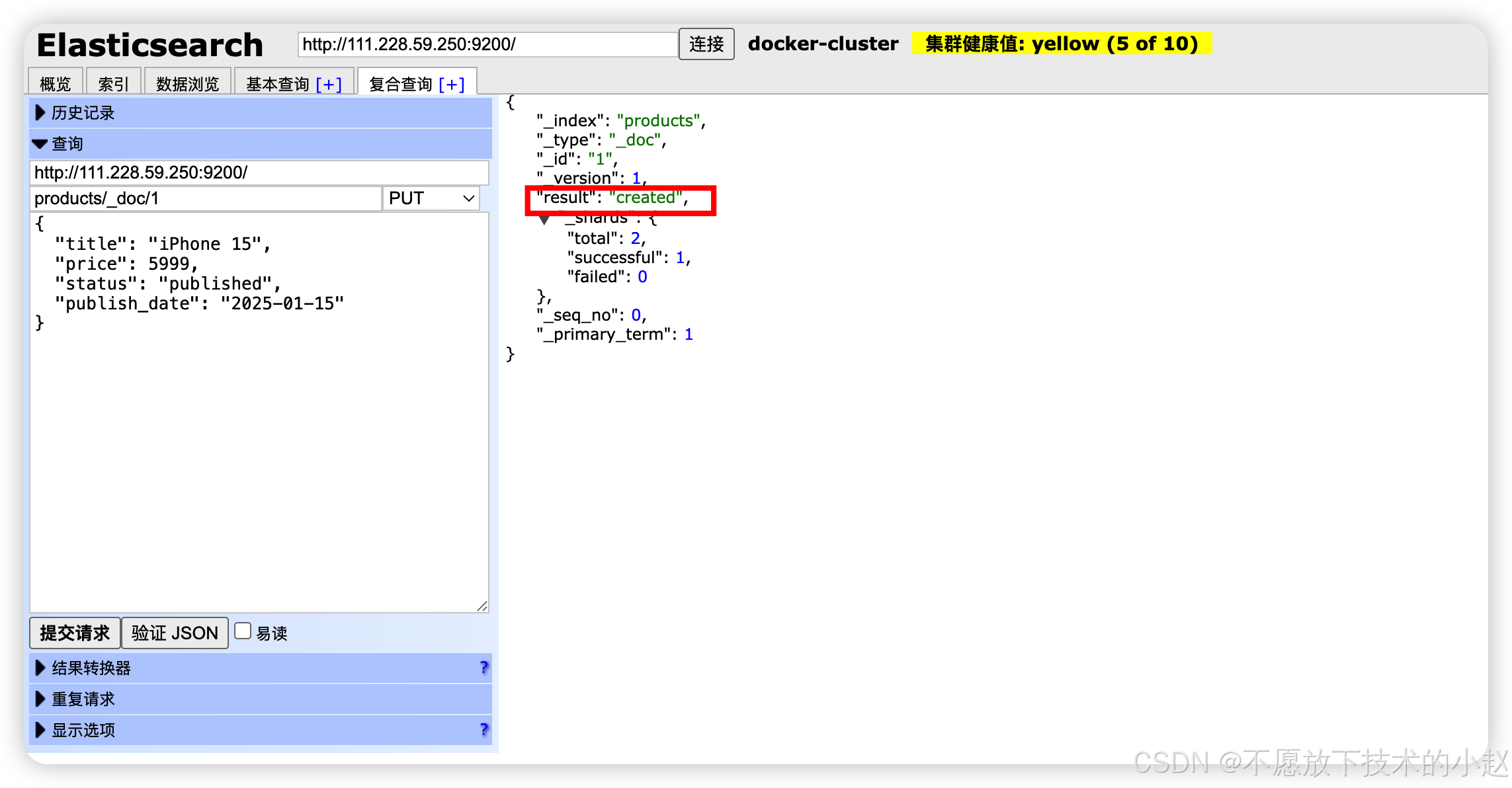
PUT /index/_doc/id:指定文档ID创建,若ID已存在则更新。
java
// 指定ID创建文档
PUT /products/_doc/1
{
"title": "iPhone 15",
"price": 5999,
"status": "published",
"publish_date": "2025-01-15"
}
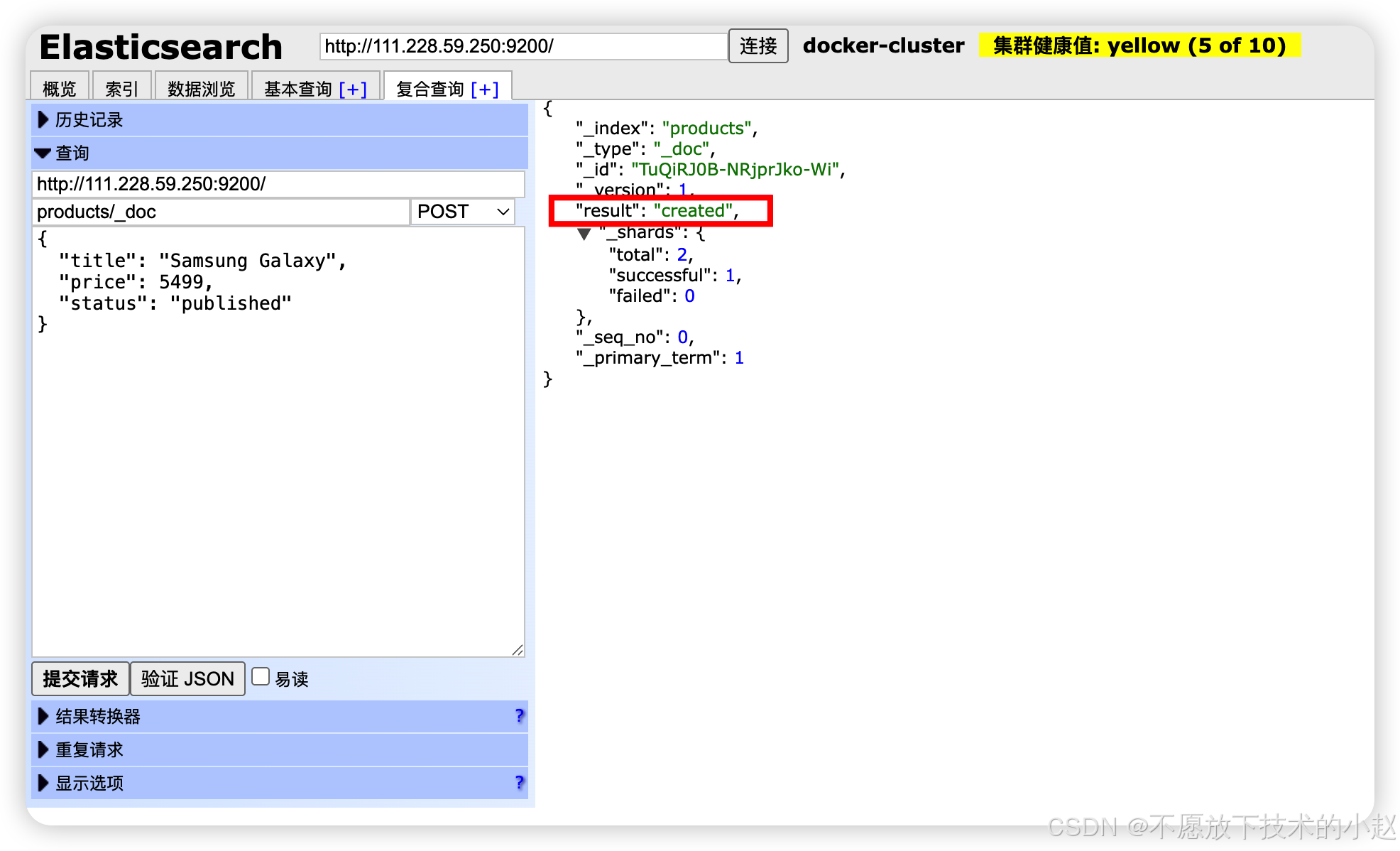
POST /index/_doc:不指定ID,由ES自动生成唯一ID。
json
// 自动生成ID创建文档
POST /products/_doc
{
"title": "Samsung Galaxy",
"price": 5499,
"status": "published"
}
_doc:推荐使用_doc端点,比_old_type更现代。
3.2 读取文档
根据文档ID或查询条件获取文档内容。
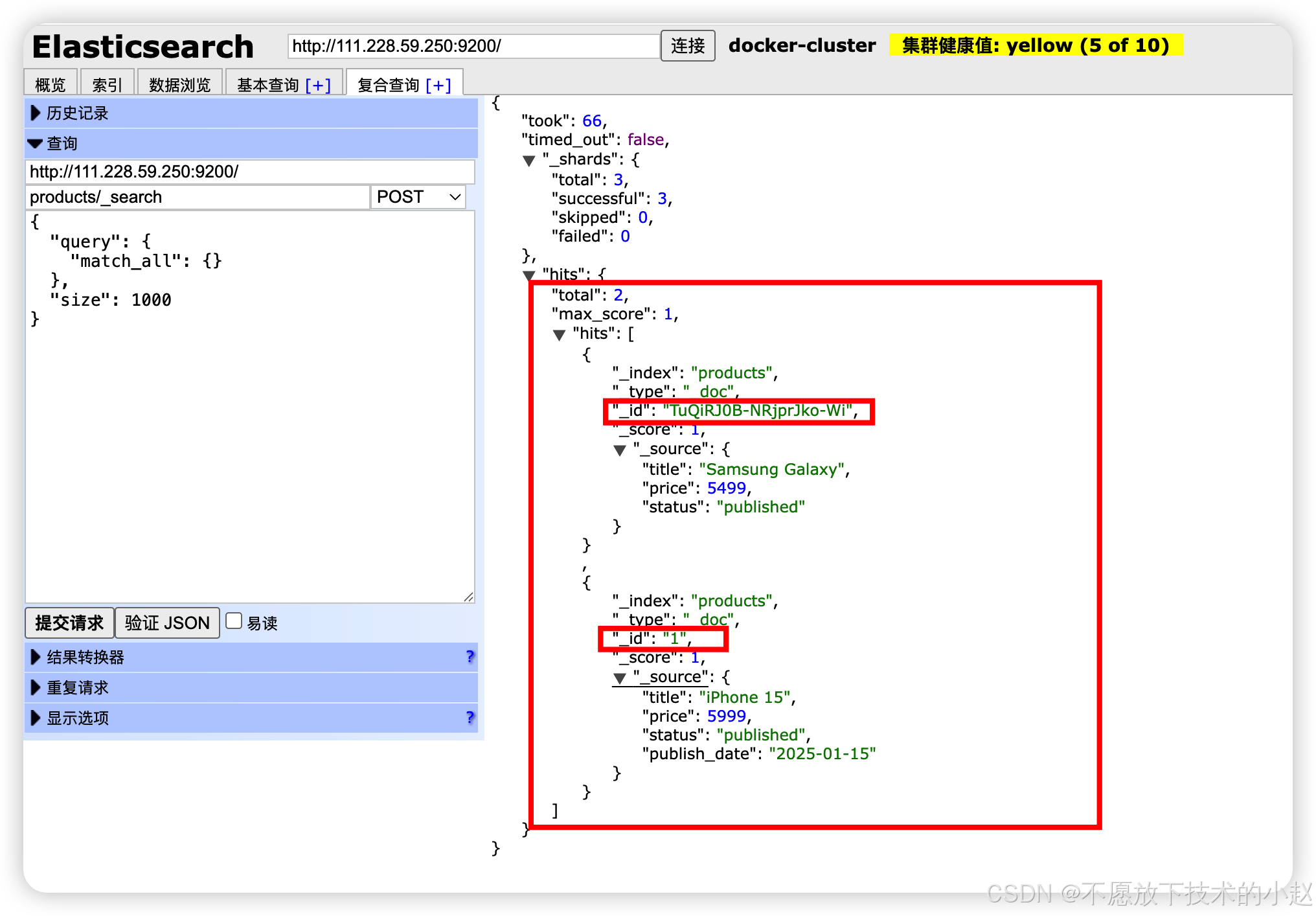
POST /index/_search:获取所以下的全部文档。
java
POST /products/_search
{
"query": {
"match_all": {}
},
"size": 1000
}
GET /index/_doc/{id}:获取单个文档,性能最优。
java
// 根据ID获取单个文档
GET /products/_doc/1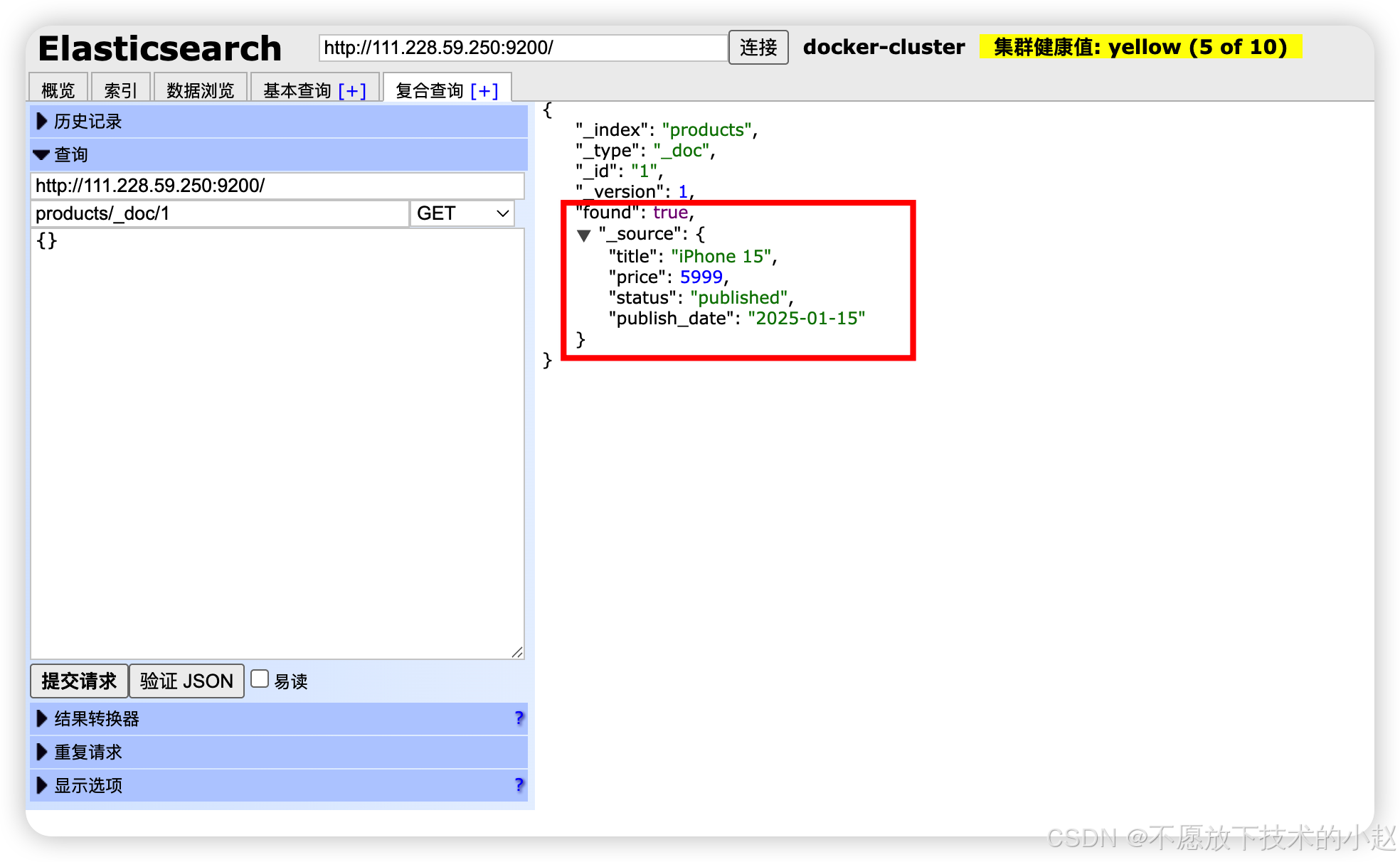
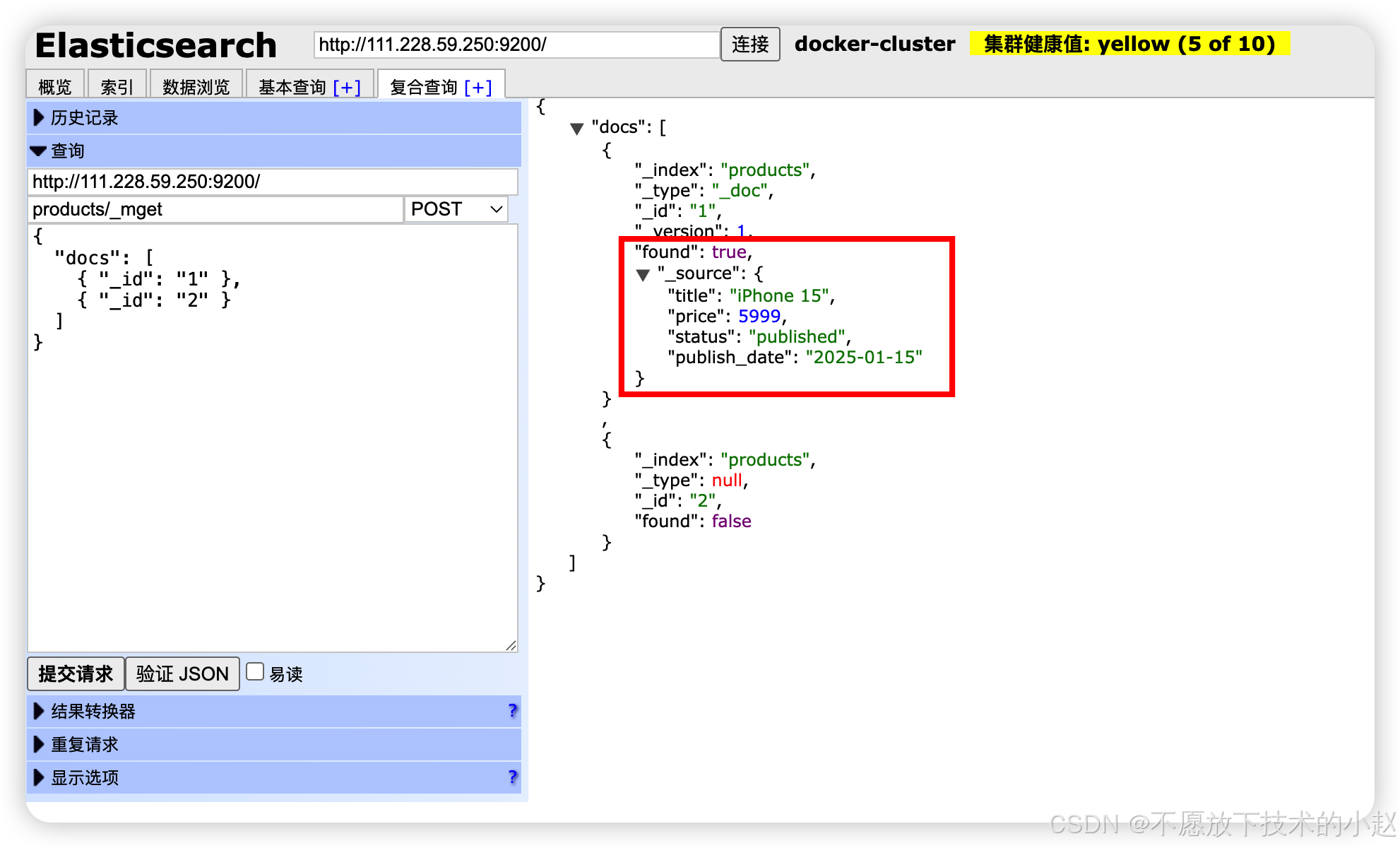
_mget:批量获取,减少网络请求次数
java
// 批量获取多个文档
POST /products/_mget
{
"docs": [
{ "_id": "1" },
{ "_id": "2" }
]
}
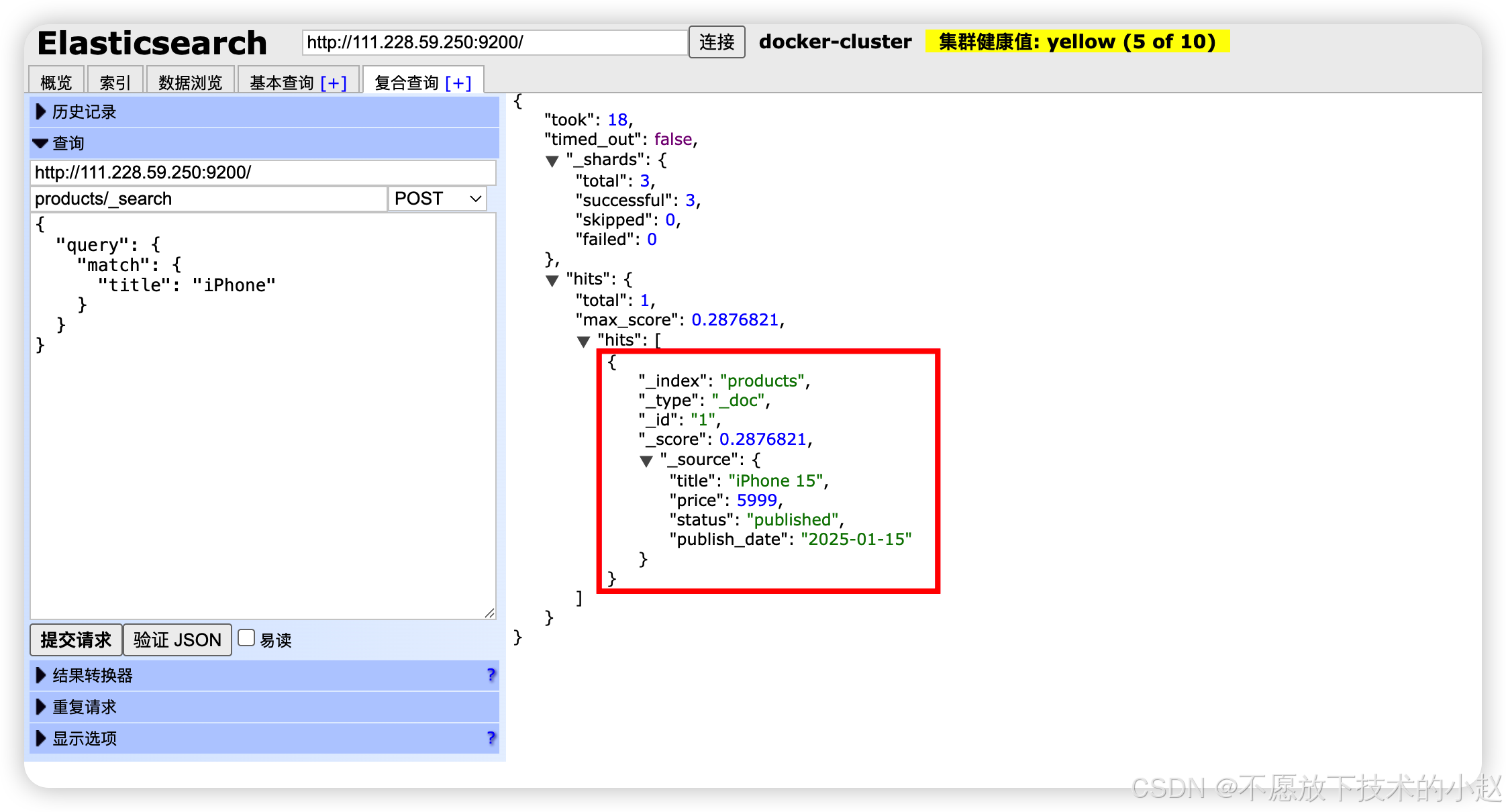
_search:通过DSL查询获取符合条件的文档集合
json
// 根据查询条件搜索文档
POST /products/_search
{
"query": {
"match": {
"title": "iPhone"
}
}
}
3.3 更新文档
修改已有文档的内容,支持全量更新和部分更新。
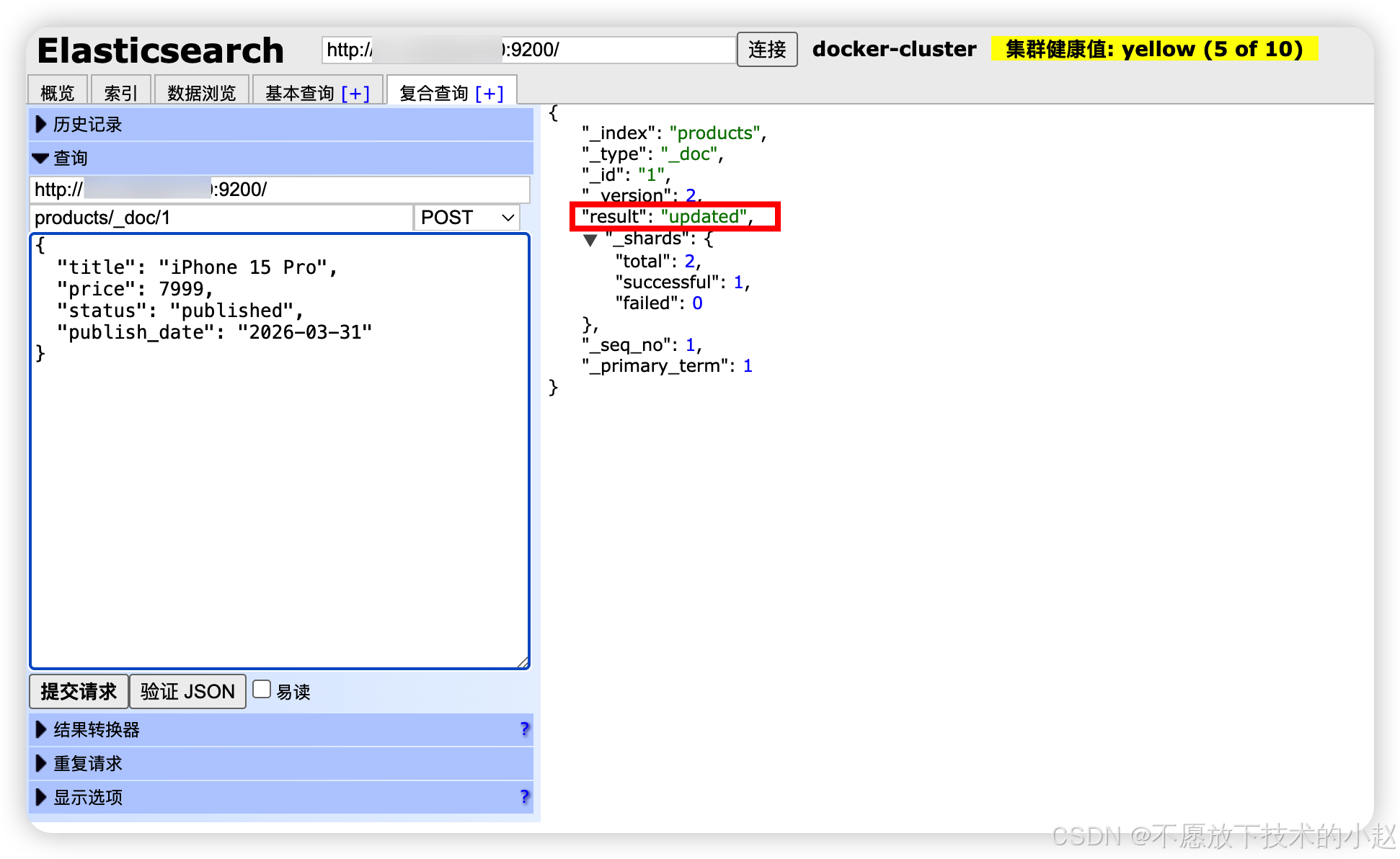
PUT /index/_doc/{id}:全量更新,必须提供完整文档。
java
// 全量更新(覆盖整个文档)
PUT /products/_doc/1
{
"title": "iPhone 15 Pro",
"price": 7999,
"status": "published",
"publish_date": "2026-03-31"
}
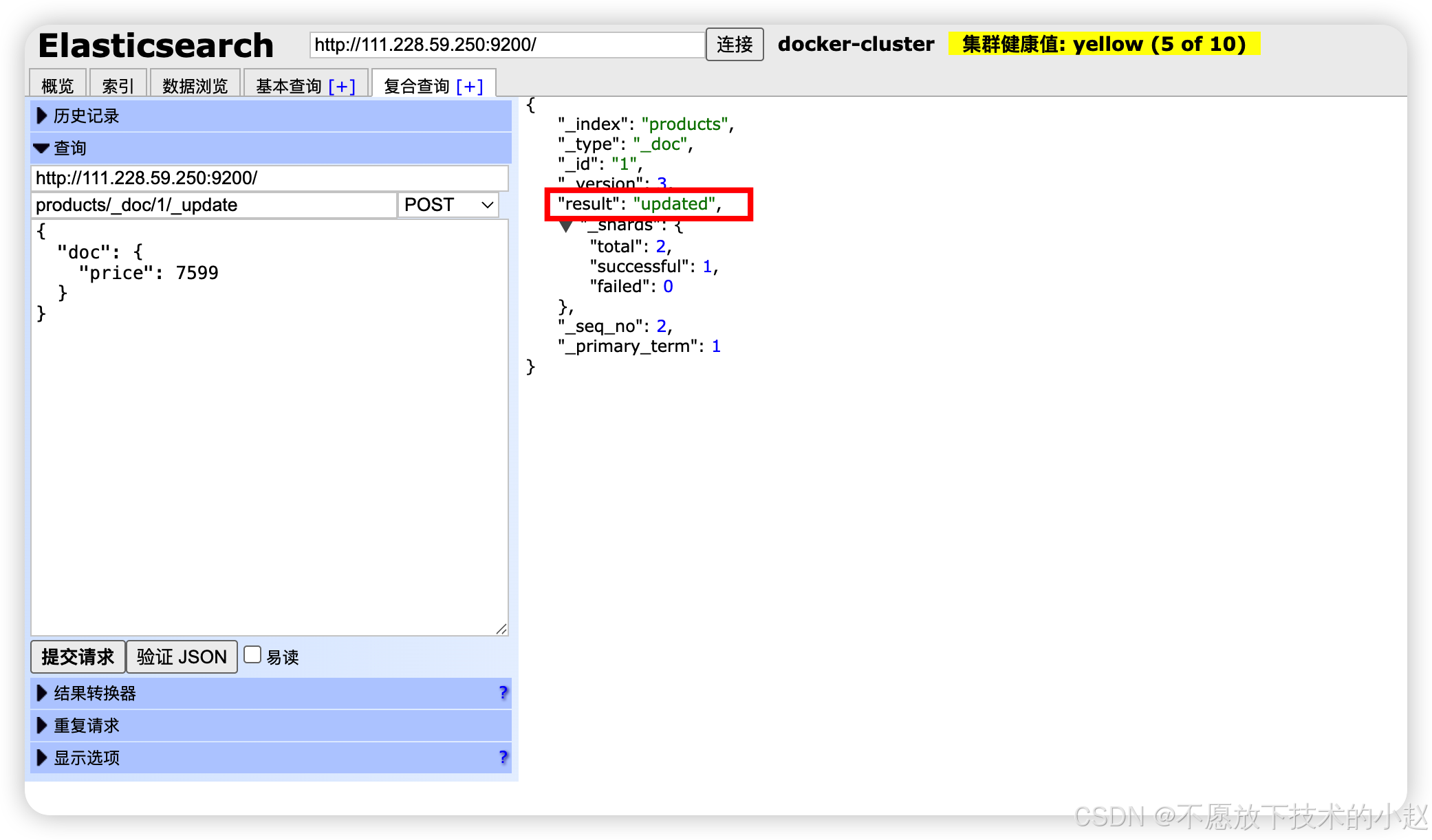
POST /index/_doc/{id}/_update:部分更新,使用doc包裹字段。
java
// 部分更新(仅修改指定字段)
POST /products/_doc/1/_update
{
"doc": {
"price": 7599
}
}
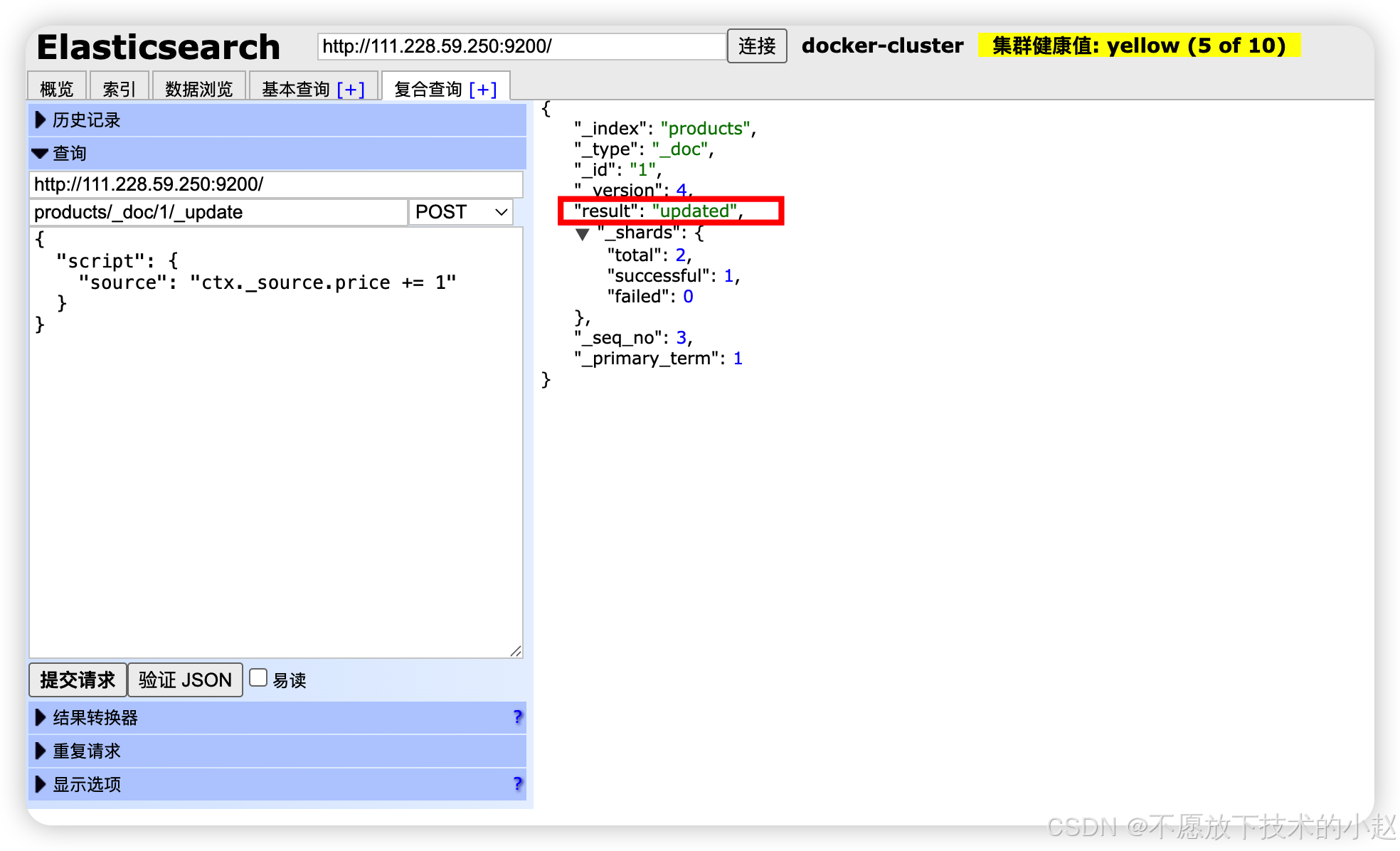
script:支持动态脚本更新,适用于计数器等场景。
json
// 使用脚本更新(如自增)
POST /products/_update/1
{
"script": "ctx._source.price += 1"
}
3.4 删除文档
移除指定ID的文档或批量删除符合条件的文档。
DELETE /index/_doc/id:根据ID删除单个文档。
java
// 删除单个文档
DELETE /products/_doc/1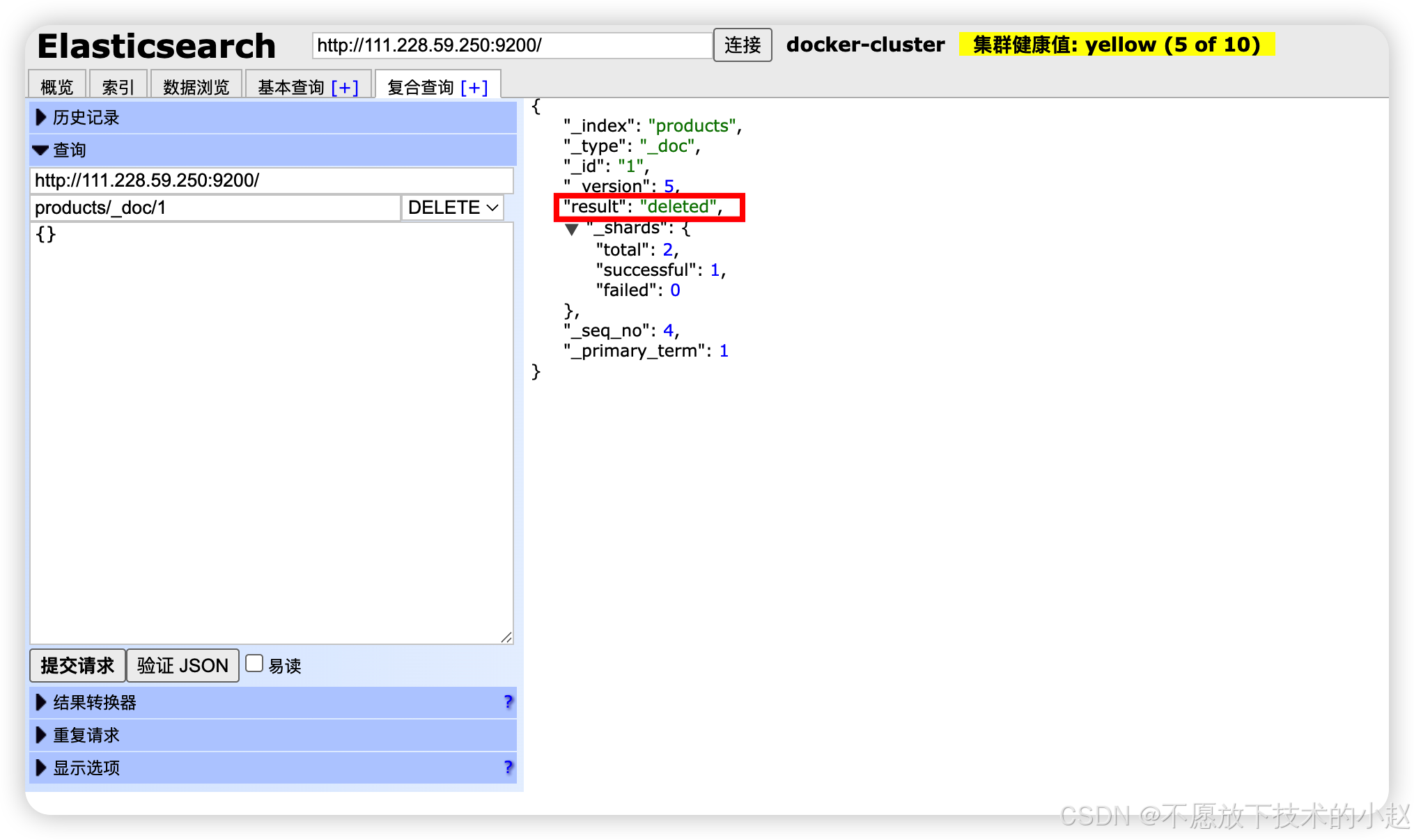
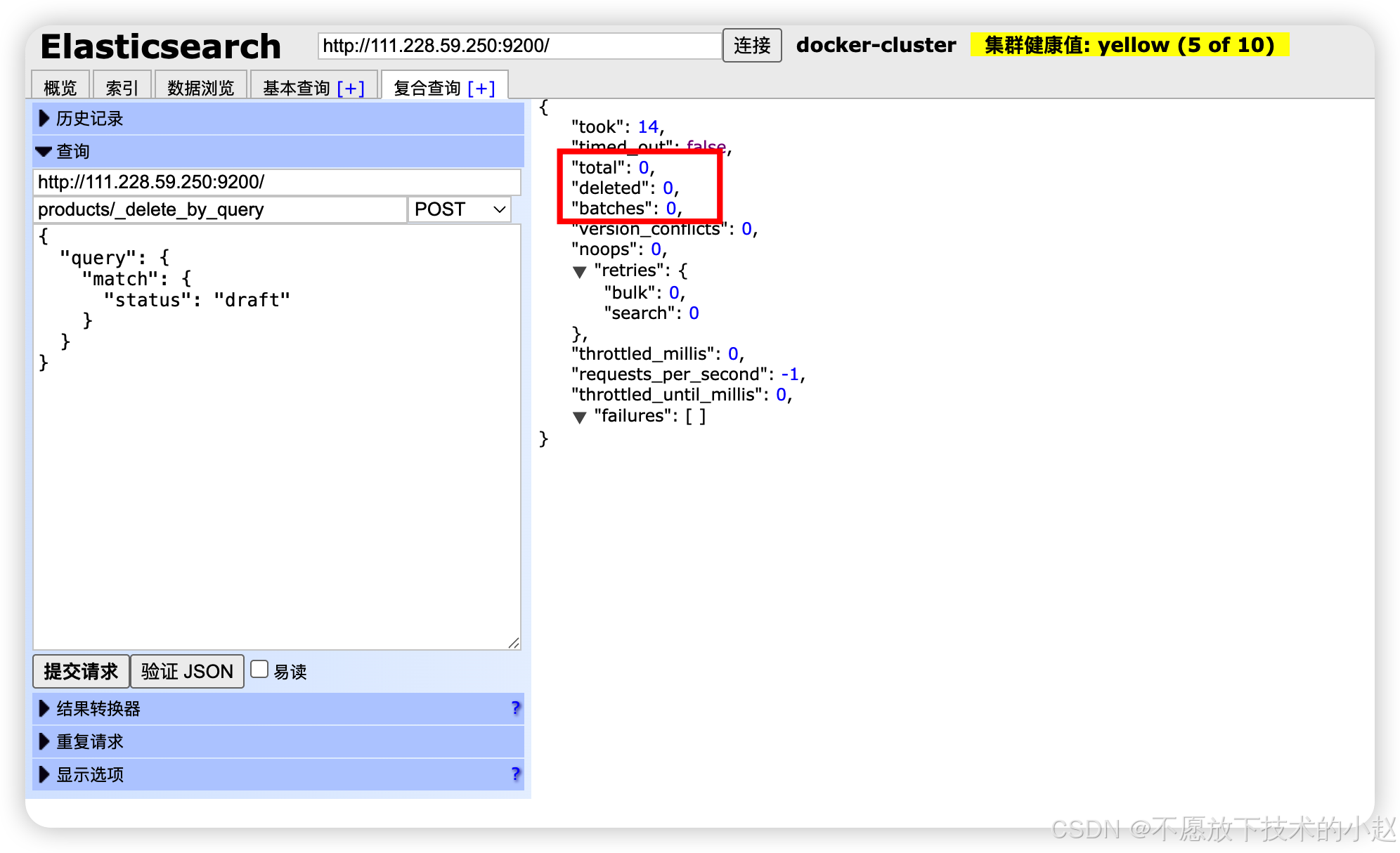
_delete_by_query:根据DSL查询条件批量删除,慎用于生产环境。
json
// 批量删除(根据查询条件)
POST /products/_delete_by_query
{
"query": {
"match": {
"status": "draft"
}
}
}
四、DSL查询操作
请求方式:POST
请求地址 :
http://<es-host>:<port>/<index-name>/_search所有DSL查询操作均使用以上统一的请求方式、地址和请求头格式,具体查询内容以JSON格式放在请求体中。
query:查询关键字,所有查询条件都放在query对象中。
4.1 基础查询
4.1 基础查询
4.1.1 分词查询(match)
用于全文搜索,会对查询文本进行分词处理。
match:分词查询关键字,用于全文搜索,会对查询文本进行分词处理。
json
{
"query": {
"match": {
"title": "Elasticsearch DSL"
}
}
}4.1.2 精确查询(term)
精确匹配,不进行分词,适用于keyword类型字段。
term:精确查询关键字,用于精确匹配字段值,不进行分词处理。
json
{
"query": {
"term": {
"status.keyword": {
"value": "published"
}
}
}
}4.2 复合查询
4.2.1 布尔查询(bool)
组合多个查询条件,支持must、should、must_not、filter四种逻辑。
bool:布尔查询关键字,用于组合多个查询条件。must:必须满足的条件,会影响相关性评分。filter:过滤条件,不影响评分,可被缓存。must_not:必须不满足的条件。
json
{
"query": {
"bool": {
"must": [
{ "match": { "title": "DSL" } }
],
"filter": [
{ "range": { "publish_date": { "gte": "2025-01-01" } } }
],
"must_not": [
{ "term": { "status.keyword": "draft" } }
]
}
}
}4.3 范围查询
4.3.1 范围查询(range)
用于数值、日期等范围条件筛选。
range:范围查询关键字,用于指定字段的范围条件。gte:大于等于。lte:小于等于。
json
{
"query": {
"range": {
"age": {
"gte": 18,
"lte": 65
}
}
}
}4.3.2 日期范围查询(date range)
专门用于日期范围查询,支持日期数学表达式。
range:范围查询关键字,用于日期范围筛选。now:当前时间。d:天。
json
{
"query": {
"range": {
"timestamp": {
"gte": "now-7d/d",
"lte": "now/d"
}
}
}
}4.4 全文搜索
4.4.1 短语查询(match_phrase)
短语匹配,要求分词后的词项按顺序连续出现。
match_phrase:短语查询关键字,要求分词后的词项按顺序连续出现。
json
{
"query": {
"match_phrase": {
"content": "全文搜索功能"
}
}
}4.4.2 多字段查询(multi_match)
在多个字段上执行相同的match查询。
multi_match:多字段查询关键字,在多个字段上执行相同的查询。
json
{
"query": {
"multi_match": {
"query": "Elasticsearch",
"fields": ["title", "content", "tags"]
}
}
}4.5 高级查询
4.5.1 函数评分查询(function_score)
自定义评分函数,实现个性化排序。
function_score:函数评分查询关键字,用于自定义评分函数。gauss:高斯衰减函数,用于基于时间或距离的评分衰减。boost_mode:评分合并模式,如multiply表示相乘。
json
{
"query": {
"function_score": {
"query": { "match": { "title": "DSL" } },
"functions": [
{
"gauss": {
"publish_date": {
"origin": "now",
"scale": "7d",
"offset": "1d",
"decay": 0.5
}
}
}
],
"boost_mode": "multiply"
}
}
}4.6 特殊查询
4.6.1 通配符查询(wildcard)
通配符查询,支持 * 匹配任意字符序列和 ? 匹配单个字符。
wildcard:通配符查询关键字,支持*和?通配符。
json
{
"query": {
"wildcard": {
"user": {
"value": "ki*y"
}
}
}
}4.6.2 前缀查询(prefix)
前缀查询,匹配包含指定前缀的词项。
prefix:前缀查询关键字,匹配包含指定前缀的词项。
json
{
"query": {
"prefix": {
"user": {
"value": "ki"
}
}
}
}4.6.3 模糊查询(fuzzy)
模糊查询,基于编辑距离匹配相似词项。
fuzzy:模糊查询关键字,基于编辑距离匹配相似词项。fuzziness:模糊度设置,AUTO表示自动计算。
json
{
"query": {
"fuzzy": {
"user": {
"value": "ki",
"fuzziness": "AUTO"
}
}
}
}4.6.4 查询字符串(query_string)
查询字符串查询,支持复杂的Lucene查询语法,可使用 AND、OR、NOT 等逻辑操作符。
query_string:查询字符串关键字,支持复杂的Lucene查询语法。
json
{
"query": {
"query_string": {
"query": "(content:this OR name:this) AND (content:that OR name:that)"
}
}
}4.6.5 文本查询(text)
文本查询,用于对文本内容进行搜索(在ES高版本中常指 match 系列查询)。
match:文本查询关键字,用于对文本内容进行搜索。operator:操作符,and表示所有词项都必须匹配。
json
{
"query": {
"match": {
"content": {
"query": "搜索文本",
"operator": "and"
}
}
}
}五、聚合操作
aggs:聚合关键字,所有聚合操作都放在aggs对象中。
5.1 指标聚合
5.1.1 求和聚合(sum)
计算指定字段的总和。
sum:求和聚合关键字,计算指定字段的总和。
json
{
"aggs": {
"total_price": {
"sum": {
"field": "price"
}
}
}
}5.1.2 平均值聚合(avg)
计算指定字段的平均值。
avg:平均值聚合关键字,计算指定字段的平均值。
json
{
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}5.2 桶聚合
5.2.1 词条聚合(terms)
按字段值分组,返回各组的文档数量。
terms:词条聚合关键字,按字段值分组统计文档数量。
json
{
"aggs": {
"group_by_status": {
"terms": {
"field": "status"
}
}
}
}5.2.2 日期直方图聚合(date_histogram)
按时间间隔(如天、月)对文档进行分组。
date_histogram:日期直方图聚合关键字,按时间间隔对文档进行分组。calendar_interval:日历间隔,如month表示按月分组。
json
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
}
}
}
}六、性能优化
6.1 使用 Filter 上下文
在不需要相关性评分的场景下,将查询放入filter子句,利用缓存提升性能。
filter:过滤上下文关键字,用于不需要评分的查询条件,可被缓存。
json
{
"query": {
"bool": {
"filter": [
{ "range": { "date": { "gte": "2023-01-01" } } }
]
}
}
}6.2 分页与滚动
6.2.1 From/Size分页(from/size)
适用于浅分页(前几千条数据)。
from:起始位置,从0开始。size:返回的文档数量。
json
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}6.2.2 滚动API(scroll)
适用于深分页或全量导出数据。
scroll:滚动API关键字,用于深分页或全量导出数据。scroll_id:滚动ID,用于获取下一批数据。
json
// 初始化Scroll
POST /products/_search?scroll=1m
{
"size": 1000,
"query": {
"match_all": {}
}
}
// 使用Scroll ID获取下一批数据
GET /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjJ3UFEAAAAAAAABBBZCRU41ajJyanhWbFZwU2ZIQnBsT1EAAAAAAAAAAA=="
}6.3 批量操作
6.3.1 批量API(bulk)
在一个请求中执行多个索引、更新或删除操作,减少网络开销。
bulk:批量API关键字,在一个请求中执行多个操作。index:索引操作。delete:删除操作。
json
POST /_bulk
{ "index": { "_index": "products", "_id": "1" } }
{ "title": "Product A", "price": 100 }
{ "index": { "_index": "products", "_id": "2" } }
{ "title": "Product B", "price": 200 }
{ "delete": { "_index": "products", "_id": "3" } }七、总结
本文档系统整理了Elasticsearch DSL的核心操作,涵盖了查询、聚合、索引管理和性能优化等关键领域。掌握这些常用操作,能够有效提升数据检索和分析的效率。在实际应用中,建议结合具体业务场景,灵活运用各种DSL特性,并持续关注性能优化,以构建高效稳定的搜索和分析系统。
整理完毕,完结撒花~🌻
参考地址:
1.Elasticsearch之索引库操作,https://blog.csdn.net/biyifengfei/article/details/141205475