本章导读:实时计算不是"更快的批处理"------它是一种全新的数据处理哲学。本章从"为什么需要实时"出发,深入 Spark Streaming 与 Structured Streaming 的架构内核,拆解 Watermark、状态管理、触发模式等关键机制,最终落地生产级实战配置。
13.1 设计思想:为什么需要实时计算?
批处理的天花板
想象你经营一家超市,每天晚上关门后统计今天的销售额。这就是批处理------数据攒够了再算。但有个问题:如果今天下午 3 点某件商品被大量盗窃,你要等到晚上 12 点才知道,损失已经无法挽回。
实时计算 解决的核心问题是:让数据的价值在产生的瞬间就被捕获和利用。
| 场景 | 批处理的代价 | 实时计算的价值 |
|---|---|---|
| 风控反欺诈 | 每小时批处理,欺诈交易已经完成 | 毫秒级拦截可疑交易 |
| 推荐系统 | T+1 更新用户兴趣 | 基于用户当前行为实时推荐 |
| 监控告警 | 次日才能发现服务异常 | 秒级感知并触发告警 |
| 实时报表 | 数据有延迟,决策滞后 | 管理层看到"现在"的业务状态 |
Spark 的选择:微批 vs 真流
Spark 在实时计算领域走了一条独特的路 :它没有像 Flink 那样从零构建流式引擎,而是选择了微批(Micro-Batch)------把无限的流切成一个个极小的批次,用批处理引擎高速处理。
这个选择带来了:
- ✅ 天然的 Exactly-Once 语义(批处理的事务性直接继承)
- ✅ 极高的吞吐量(批处理优化成熟)
- ⚠️ 延迟下限约 100ms(真正的毫秒级延迟需要用 Continuous Processing 模式)
实战口诀:Spark 流 = 极速批处理的流式包装,吞吐优先选 Spark,延迟优先选 Flink。
13.2 核心架构全景:两代引擎的对比
Spark 提供了两套实时计算 API,理解它们的关系是入门的第一步。
下图展示了 Spark 实时计算的整体架构全景,包括两代引擎与数据流向:
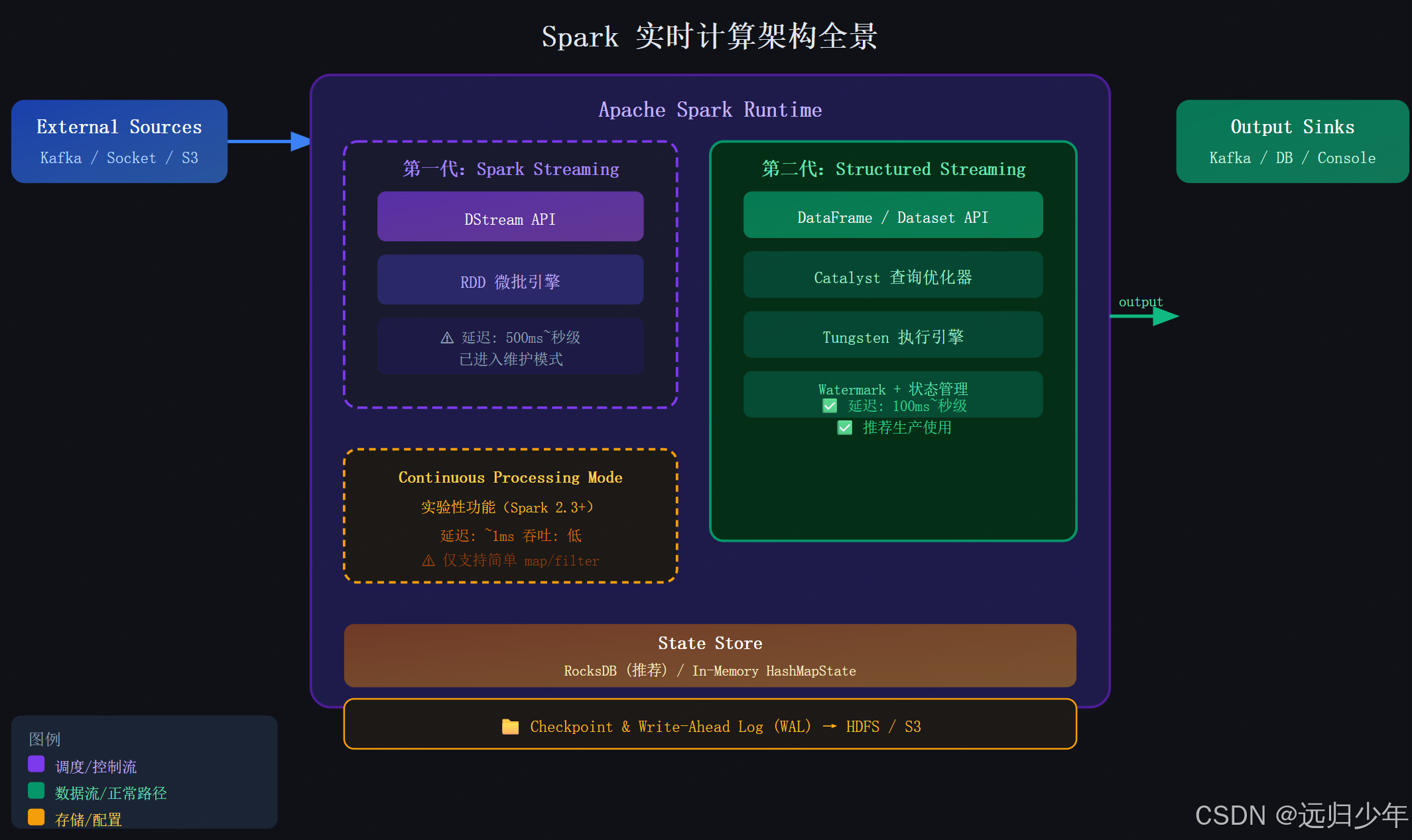
架构核心结论:
-
两代引擎,选新不选旧:Spark Streaming(DStream API)已进入维护模式,Structured Streaming 是官方推荐的唯一生产级选择。它底层复用了批处理的 Catalyst + Tungsten 优化栈,性能更强、语义更清晰。
-
状态是实时计算的心脏:所有有意义的流式计算(聚合、Join、去重)都需要维护状态。State Store 的选型(RocksDB vs 内存)直接决定了任务的稳定性上限。
-
Checkpoint 是生命线:没有 Checkpoint,任何实时任务在重启后都会从头开始,数据要么丢失要么重复。
实战口诀:新项目只用 Structured Streaming,State 用 RocksDB,Checkpoint 必须配。
13.3 第一代引擎:Spark Streaming 与 DStream
虽然 DStream 已是"遗产",理解它能帮助你看清 Structured Streaming 解决了哪些痛点。
DStream(Discretized Stream,离散化流)的核心思想是:把时间轴切成等长的批次窗口,每个窗口内的数据形成一个 RDD 。
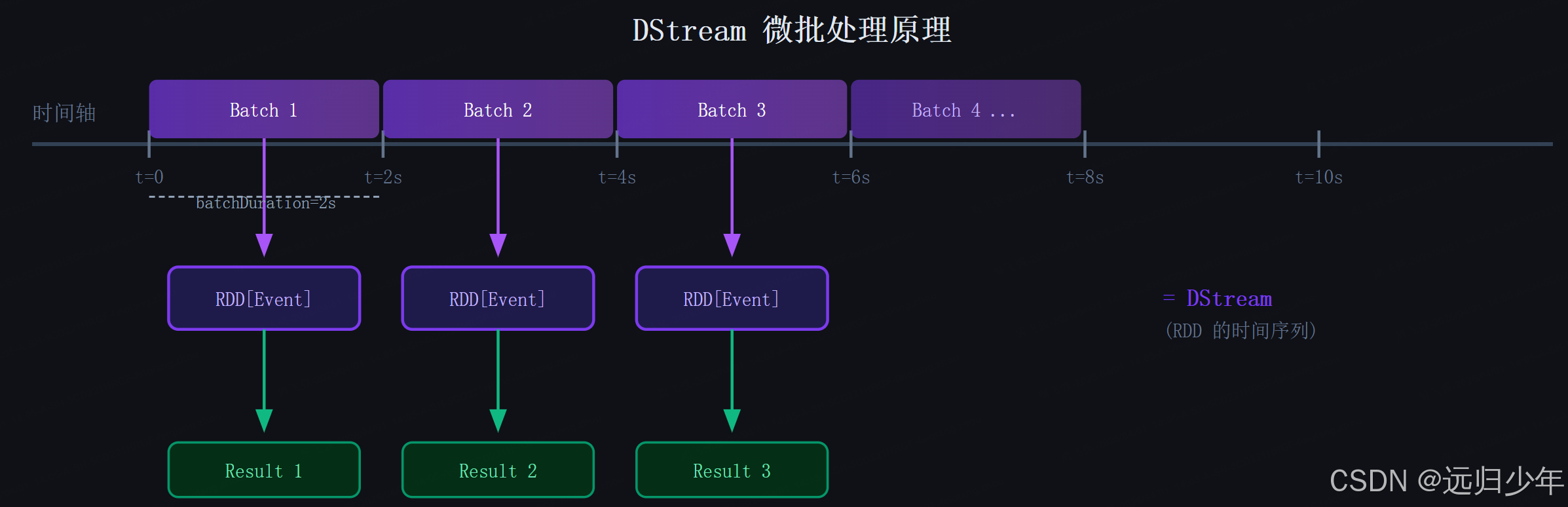
DStream 核心结论:
-
DStream 本质是 RDD 的时间序列 :每个 batchDuration 窗口内的数据形成一个 RDD,DStream 就是这些 RDD 按时间排列的集合。你对 DStream 的
map、filter操作,实际上是对每个 RDD 做相同操作。 -
batchDuration 是一把双刃剑:设得小(如 500ms),延迟低但调度开销大;设得大(如 10s),吞吐高但实时性差。这个矛盾无法根本解决,是 DStream 的结构性缺陷。
-
没有原生的事件时间支持:DStream 只知道"数据到达 Spark 的时间"(处理时间),无法正确处理乱序数据,这是它被 Structured Streaming 取代的核心原因之一。
实战口诀:DStream 看懂即可,生产环境不要用,面试能讲清楚"它解决了什么,又留下了什么坑"就够了。
13.4 第二代引擎:Structured Streaming 核心架构
Structured Streaming 的核心设计哲学是:把流式数据看作一张无界的表(Unbounded Table),每批新数据就是追加到这张表的新行,所有对静态 DataFrame 的 SQL 操作都可以直接用于流式处理。
无界表模型

无界表模型核心结论:
-
"流"是"表"的语法糖 :Structured Streaming 最聪明的设计是让开发者用写批处理 SQL 的方式写流处理。
df.writeStream.start()和df.write.save()在语法上几乎相同,极大降低了学习成本。 -
三种输出模式决定数据语义:
- Append:只输出新增行(不可变行,适合简单转换)
- Update:只输出本次批次中被更新的行(适合聚合)
- Complete:每次触发都输出全部结果表(适合小结果集排序)
-
Result Table 是逻辑概念 :Spark 不会真的把全表存在内存里,它只维护产生 Result Table 所需的最小状态。
实战口诀:Structured Streaming = 批处理 SQL + 触发器 + 状态管理,三位一体缺一不可。
13.5 关键机制一:Watermark(水印)与乱序处理
乱序数据是流式计算的头号敌人。手机弱网环境下产生的事件,可能延迟几分钟甚至几小时才到达 Kafka。没有 Watermark,你永远不知道一个时间窗口是否已经收到了所有数据。
类比:Watermark 就像快递的"截单时间"------快递公司说"今天 23:59 之前下单的,算今日订单"。晚于这个时间的单子,就算进明天。Watermark 告诉 Spark:"比水位线更早的数据,即使迟到也不再接受。"
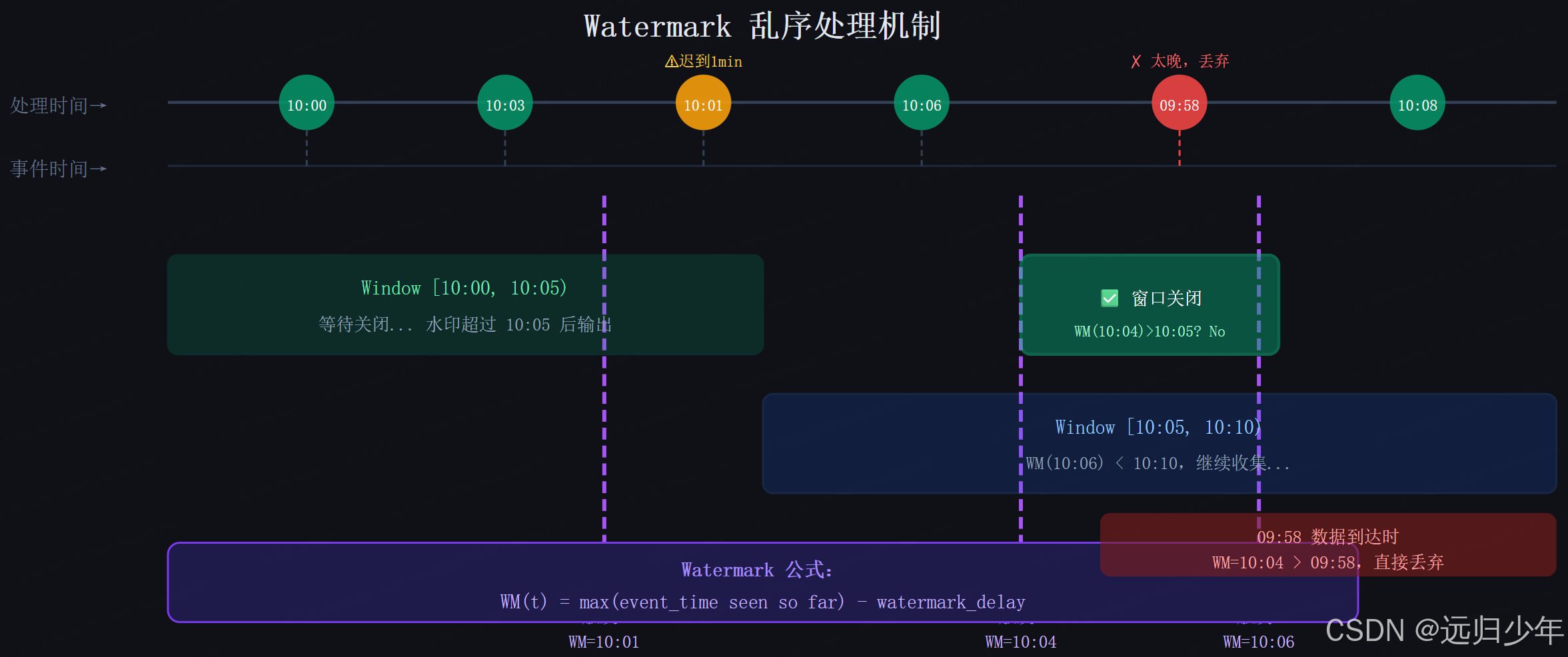
Watermark 核心结论:
-
Watermark = 事件时间最大值 − 容忍延迟:这是一个"滑动下界",它告诉 Spark:"比我更早的数据,我不再等了。" 窗口结束时间小于 Watermark 时,该窗口关闭并输出结果。
-
延迟参数是业务决策,不是技术参数 :
withWatermark("event_time", "2 minutes")意味着你愿意牺牲 2 分钟的结果延迟,换取对最多 2 分钟乱序数据的容忍。延迟设得越大,内存中需要维护的待处理窗口越多。 -
超过 Watermark 的数据会被静默丢弃 :这是 Watermark 的代价,生产中必须监控丢弃率指标(
numRowsDroppedByWatermark)。
实战口诀:水印延迟 = 业务能接受的"等迟到同学"的时长,设太短丢数据,设太长压内存。
13.6 关键机制二:触发模式(Trigger)
触发模式控制 Structured Streaming 何时处理数据,是调节延迟与吞吐的核心旋钮。

触发模式核心结论:
-
90% 的生产任务用
ProcessingTime:指定一个合理的间隔(如"10 seconds"或"1 minute"),在延迟与系统开销之间取得平衡。间隔越短,Kafka offset commit 越频繁,Driver 调度压力越大。 -
AvailableNow是新时代的"调度流":它让你用 Structured Streaming 的 Checkpoint 语义替代传统的批处理调度(Airflow + SparkSQL),实现"从上次停下来的地方继续",非常适合数仓增量更新场景。 -
Continuous不要在聚合场景使用:它的限制极多,生产级毫秒延迟请考虑迁移到 Apache Flink。
实战口诀:实时流选 ProcessingTime + 合理间隔;调度批选 AvailableNow;Continuous 只是个 demo。
13.7 关键机制三:状态管理与 State Store
有状态操作(Stateful Operations)是区分"玩具级"和"生产级"流处理任务的分水岭。任何需要跨批次"记住"信息的操作都是有状态的。
常见的有状态操作:
- 窗口聚合(
groupBy + window) - 流-流 Join
deduplicateWithinWatermark(去重)mapGroupsWithState/flatMapGroupsWithState(自定义状态)
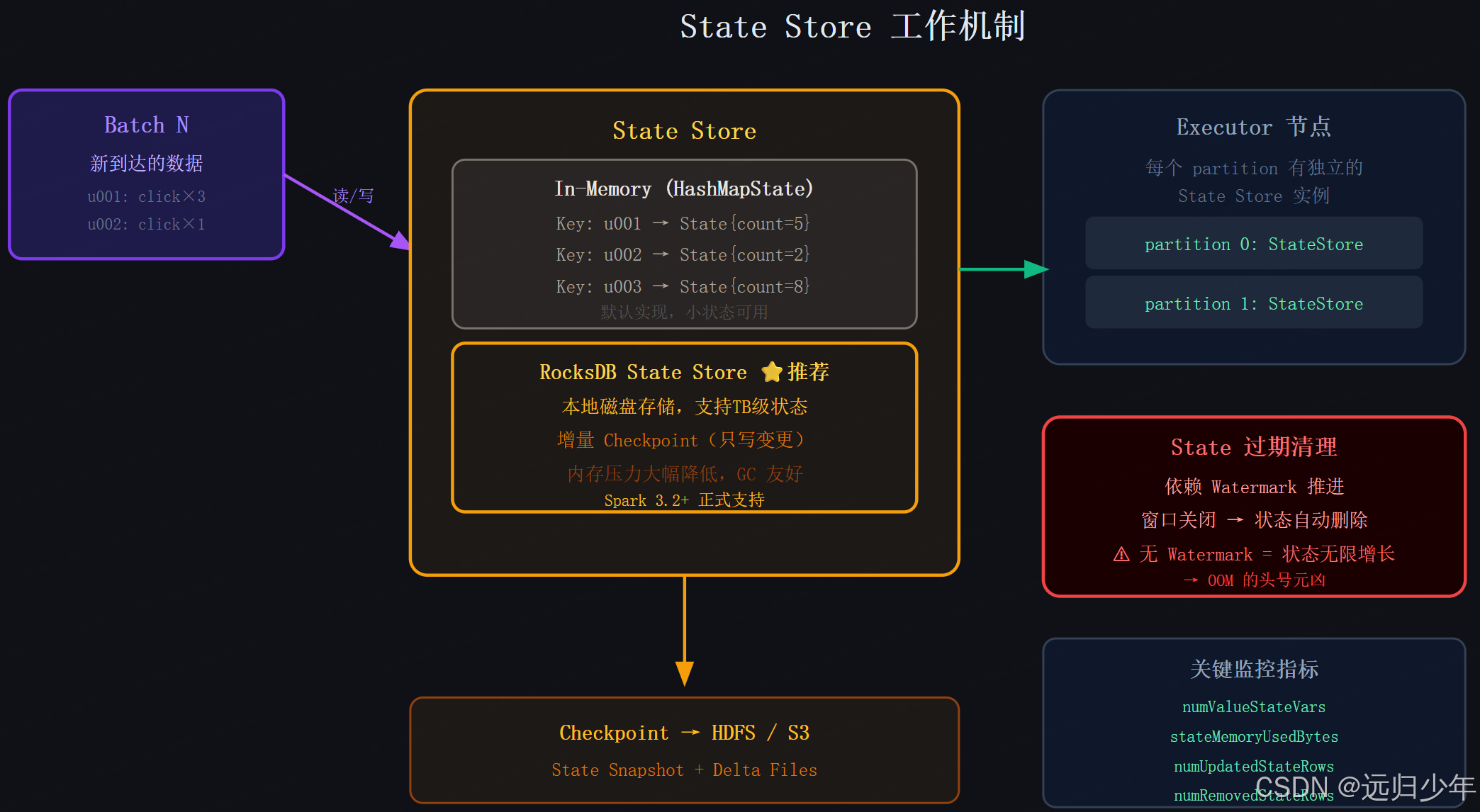
状态管理核心结论:
-
没有 Watermark 的有状态操作是定时炸弹 :状态永远不会被清理,随着时间推移必然导致 OOM(内存溢出)。无论如何,有状态操作必须配合
withWatermark。 -
大状态必须用 RocksDB:超过 10GB 的状态用内存 HashMapState 必然 OOM,RocksDB 把状态落到本地磁盘并做增量 Checkpoint,内存占用降低 80% 以上。
-
状态与 Partition 强绑定 :每个 Executor 的每个 Partition 维护独立的 State Store,这意味着
repartition会破坏状态关联。改变并行度前必须通过 Checkpoint 重置。
实战口诀:有状态必配 Watermark,大状态必用 RocksDB,改并行度必须重置 Checkpoint。
13.8 新老对比:Spark Streaming vs Structured Streaming

13.9 横向对比:Spark Structured Streaming vs Apache Flink
生产中常见的选型困惑:什么时候用 Spark,什么时候用 Flink?
| 维度 | Spark Structured Streaming | Apache Flink |
|---|---|---|
| 处理模型 | 微批(默认)/ 连续(实验性) | 真流式(事件驱动) |
| 延迟 | 100ms ~ 秒级 | 毫秒级 |
| 吞吐量 | 极高(批处理优化成熟) | 高(略低于 Spark 大批次) |
| 状态管理 | RocksDB State Store | RocksDB(更成熟) |
| SQL 支持 | Spark SQL(完整) | Flink SQL(功能追赶中) |
| 生态整合 | 与 Spark 批处理无缝衔接 | 独立生态 |
| 运维复杂度 | 中(依托 Spark 集群) | 高(独立 JobManager/TaskManager) |
| 适用场景 | 吞吐优先、与批处理混合 | 延迟优先、复杂事件处理(CEP) |
选型口诀:延迟 < 100ms 选 Flink,其他大多数场景 Spark 更省心。
13.10 生产实战:完整可运行示例
场景描述
从 Kafka 消费用户行为日志,统计每 5 分钟内每个用户的点击次数,结合 Watermark 处理 2 分钟内的乱序数据,将结果写入 Kafka 和控制台。
依赖配置(build.sbt / pom.xml)
scala
// build.sbt
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-sql" % "3.5.0",
"org.apache.spark" %% "spark-sql-kafka-0-10" % "3.5.0",
// ⭐ 生产必须:RocksDB State Store
"org.apache.spark" %% "spark-sql-kafka-0-10" % "3.5.0"
)完整代码示例
scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.{OutputMode, Trigger}
import org.apache.spark.sql.types._
object UserClickAggregation {
def main(args: Array[String]): Unit = {
// ===== 1. SparkSession 配置 =====
val spark = SparkSession.builder()
.appName("UserClickRealtime")
// ⭐ 生产关键:启用 RocksDB State Store,避免大状态 OOM
.config("spark.sql.streaming.stateStore.providerClass",
"org.apache.spark.sql.execution.streaming.state.RocksDBStateStoreProvider")
// ⭐ RocksDB 增量 Checkpoint,减少 S3/HDFS 写入量
.config("spark.sql.streaming.stateStore.rocksdb.changelogCheckpointing.enabled", "true")
// ⭐ 调整 shuffle partition 数,避免状态碎片化(根据数据量调整)
.config("spark.sql.shuffle.partitions", "200")
// ❌ 错误写法: 不配置 stateStore.providerClass,默认 HashMap,大状态必 OOM
.getOrCreate()
import spark.implicits._
// ===== 2. 定义 Kafka 消息的 Schema =====
// 原始消息格式: {"user_id":"u001","event_time":"2024-01-15T10:00:01","action":"click"}
val eventSchema = StructType(Seq(
StructField("user_id", StringType, nullable = false),
StructField("event_time", TimestampType, nullable = false),
StructField("action", StringType, nullable = true)
))
// ===== 3. 读取 Kafka Source =====
val rawStream = spark.readStream
.format("kafka")
// ⭐ 生产建议: 指定 assign 而非 subscribe,精确控制 partition 消费
.option("kafka.bootstrap.servers", "kafka-broker-1:9092,kafka-broker-2:9092")
.option("subscribe", "user-events")
// ⭐ 限速:防止 Kafka 积压时突发大批次打垮下游
.option("maxOffsetsPerTrigger", "500000")
// 首次启动从最新位置开始(生产常用)
.option("startingOffsets", "latest")
// ⭐ Kafka 消费者配置:指定消费者组
.option("kafka.group.id", "spark-realtime-click")
.load()
// ===== 4. 解析 JSON 消息 =====
val parsedStream = rawStream
.selectExpr("CAST(value AS STRING) as json_str", "timestamp as kafka_ts")
.withColumn("data", from_json($"json_str", eventSchema))
// 展开嵌套字段
.select(
$"data.user_id",
$"data.event_time", // 使用业务事件时间,而非 Kafka 入队时间
$"data.action",
$"kafka_ts" // 保留 Kafka 时间用于监控
)
// ❌ 错误做法: 用 kafka_ts(处理时间)做窗口,无法正确处理乱序
// ✅ 正确做法: 用业务 event_time 做窗口
// ===== 5. 核心处理:Watermark + 窗口聚合 =====
val aggregated = parsedStream
// ⭐ 关键配置:2分钟的 Watermark 延迟
// 含义:允许最多 2 分钟迟到的数据,超时丢弃
.withWatermark("event_time", "2 minutes")
// 过滤只统计 click 行为
.filter($"action" === "click")
// ⭐ 滑动窗口:5分钟窗口,每1分钟滑动一次
// 如果只需要滚动窗口,把第三个参数去掉即可
.groupBy(
window($"event_time", "5 minutes", "1 minute"),
$"user_id"
)
.agg(
count("*").as("click_count"),
min($"event_time").as("first_event_time"),
max($"event_time").as("last_event_time")
)
// 展开 window struct 便于下游使用
.select(
$"window.start".as("window_start"),
$"window.end".as("window_end"),
$"user_id",
$"click_count",
$"first_event_time",
$"last_event_time"
)
// ===== 6. 写出到 Kafka =====
val kafkaSink = aggregated
// 构造 Kafka value(JSON 格式)
.select(
// ⭐ Kafka key = user_id,保证同一用户数据在同一 partition,有序
$"user_id".as("key"),
to_json(struct($"*")).as("value")
)
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "kafka-broker-1:9092,kafka-broker-2:9092")
.option("topic", "user-click-aggregated")
// ⭐ 必须配置:Checkpoint 路径,保证 Exactly-Once 和断点续传
.option("checkpointLocation", "s3a://my-bucket/checkpoints/user-click-agg")
// ⭐ Update 模式:只输出本批次中被更新的结果行(窗口聚合的最佳选择)
// ❌ 错误: Append 模式不能与有聚合的窗口查询配合(除非有 Watermark 且窗口已关闭)
.outputMode(OutputMode.Update())
// ⭐ 每 30 秒触发一次,平衡延迟与调度开销
.trigger(Trigger.ProcessingTime("30 seconds"))
.start()
// ===== 7. 同时写到控制台(开发调试用)=====
// ❌ 生产不要保留 Console Sink,仅用于本地调试
val consoleSink = aggregated
.writeStream
.format("console")
.option("truncate", "false")
.option("numRows", "20")
.outputMode(OutputMode.Update())
.trigger(Trigger.ProcessingTime("30 seconds"))
.start()
// ===== 8. 等待任务结束 =====
// awaitAnyTermination: 任一 stream 失败即退出
spark.streams.awaitAnyTermination()
}
}常见错误配置对比
scala
// ============================================
// ❌ 错误 1: 忘记配置 Checkpoint
// ============================================
df.writeStream
.format("kafka")
// 没有 checkpointLocation!
// 后果:重启后重复消费、状态丢失、无法保证 Exactly-Once
.start()
// ✅ 正确:必须指定 checkpointLocation
df.writeStream
.format("kafka")
.option("checkpointLocation", "hdfs:///checkpoints/my-job")
.start()
// ============================================
// ❌ 错误 2: 有状态操作不配 Watermark
// ============================================
df.groupBy(
window($"event_time", "5 minutes"), // 有窗口聚合
$"user_id"
).count()
// 后果:状态永远不会被清理,运行几小时后 OOM
// ✅ 正确:有状态操作必须先设 Watermark
df.withWatermark("event_time", "2 minutes")
.groupBy(window($"event_time", "5 minutes"), $"user_id")
.count()
// ============================================
// ❌ 错误 3: Output Mode 与操作不匹配
// ============================================
df.withWatermark("event_time", "2 minutes")
.groupBy(window($"event_time", "5 minutes"))
.count()
.writeStream
.outputMode(OutputMode.Append()) // ❌ 聚合+Watermark 不能用 Append
// 错误信息: Append output mode not supported when there are streaming aggregations
// ✅ 正确:聚合操作用 Update 或 Complete
.outputMode(OutputMode.Update())
// ============================================
// ❌ 错误 4: 在生产环境使用 Trigger.Once()
// ============================================
df.writeStream
.trigger(Trigger.Once())
// 问题:Spark 3.3+ 已标记为 deprecated,大积压时单批次超时风险高
// ✅ 正确:Spark 3.3+ 使用 AvailableNow
.trigger(Trigger.AvailableNow())
// ============================================
// ❌ 错误 5: 忘记限速,Kafka 积压时 OOM
// ============================================
spark.readStream
.format("kafka")
.option("subscribe", "events")
// 没有 maxOffsetsPerTrigger!积压 1 亿条数据时第一批全部加载 → OOM
// ✅ 正确:根据任务处理能力设置合理的限速
.option("maxOffsetsPerTrigger", "500000")
.load()13.11 排障指南
常见问题排查思路
问题 1:任务运行一段时间后越来越慢(Batch Duration 持续上升)
排查路径:
1. Spark UI → Streaming tab → 查看 "Input Rate" vs "Processing Rate"
- 如果 Processing Rate < Input Rate → 消费跟不上生产,需要扩容或降低计算复杂度
2. 查看 "State Operators" 标签 → stateMemoryUsedBytes 是否持续增长
- 如果是 → Watermark 没有正确配置,或状态没有被清理
3. 检查 GC 时间 → Executor GC time > 10% → 考虑切换到 RocksDB State Store问题 2:重启后数据重复或丢失
原因:Checkpoint 配置有误或 Checkpoint 目录被删除
解决:
- 确认 checkpointLocation 已配置且持久化到可靠存储(HDFS/S3)
- 确认 Sink 支持幂等写入(Kafka + 事务 Producer,或数据库 upsert)
- 如果是 Schema 变更导致 Checkpoint 不兼容,需要手动删除 Checkpoint 重置问题 3:Watermark 不推进,窗口迟迟不关闭
原因:某个 partition 的数据停止了(Kafka partition 上没有新消息)
解决:
- 检查上游 Kafka 各 partition 的消费 lag
- 设置 spark.sql.streaming.watermarkDelayMs(强制推进水印的超时)
- 或给每个 partition 定期发送"心跳"事件问题 4:Exactly-Once 语义失效,数据重复
原因:Sink 不支持幂等写入,或 Checkpoint 与 Sink 状态不一致
解决:
- Kafka Sink:启用事务 Producer
.option("kafka.transactional.id", "spark-streaming-txn-001")
- 数据库 Sink:使用 upsert/merge 代替 insert
- 文件 Sink:使用 ForeachBatch + 临时文件 + 原子 rename13.12 本章总结
核心认知地图:
实时计算本质
├── 不是"更快的批处理"
└── 是"数据价值的即时捕获"
Spark 实时架构
├── Spark Streaming (DStream) → 维护模式,了解即可
└── Structured Streaming → 唯一的生产选择
├── 无界表模型(流 = 表的增量追加)
├── Watermark(乱序容忍的截止时间)
├── Trigger(何时处理的旋钮)
└── State Store(跨批次记忆的载体)
生产三要素
├── Checkpoint(生命线)
├── Watermark(乱序处理)
└── RocksDB State Store(大状态稳定性)
选型原则
├── 吞吐优先 / 与批处理混合 → Spark Structured Streaming
└── 延迟 < 100ms / CEP → Apache Flink本章终极口诀:
新项目选 Structured,状态用 RocksDB;
Watermark 防乱序,Checkpoint 保语义;
延迟靠 Trigger 调,吞吐靠并行控;
有状态必有 WM,无 WM 必有 OOM。