目录
- [前言:何为 AI Agent](#前言:何为 AI Agent)
- 环境与准备
-
- [📦 1. 父项目依赖与版本管控](#📦 1. 父项目依赖与版本管控)
- [⚙️ 2. YAML 配置与 Nacos 整合](#⚙️ 2. YAML 配置与 Nacos 整合)
- [实践:落地 Agent 核心支柱](#实践:落地 Agent 核心支柱)
-
- [一、 赋予 Agent 手脚:Tool Function 的底层原理](#一、 赋予 Agent 手脚:Tool Function 的底层原理)
-
- [1. 全代码展示:天气与订单触手](#1. 全代码展示:天气与订单触手)
- [2. "小白"解惑:LLM 是怎么识别参数的?](#2. “小白”解惑:LLM 是怎么识别参数的?)
- [二、 简单触手调用:DeepSeekToolChatController](#二、 简单触手调用:DeepSeekToolChatController)
- [三、 企业级全能 Agent:ChatClient 与拔插机制实战](#三、 企业级全能 Agent:ChatClient 与拔插机制实战)
-
- [1. ChatClient vs ChatModel 详细对比](#1. ChatClient vs ChatModel 详细对比)
- [2. Agent 的"前尘往事":Memory (记忆) 的接口设计与拔插式配置](#2. Agent 的“前尘往事”:Memory (记忆) 的接口设计与拔插式配置)
- [3.实现redis分布式Memory类 `RedisChatMemory`(继承了 `ChatMemory`接口)](#3.实现redis分布式Memory类
RedisChatMemory(继承了ChatMemory接口)) - [4. 分布式记忆深潜:Redis 序列化陷阱与自定义架构方案](#4. 分布式记忆深潜:Redis 序列化陷阱与自定义架构方案)
- [5. 定义并挂载拔插式memory 接口](#5. 定义并挂载拔插式memory 接口)
- [6. Agent 灵魂:System Prompt(系统提示词)](#6. Agent 灵魂:System Prompt(系统提示词))
- [四、 架构拓展:多模型并存的"神仙打架"与 Spring Bean 冲突](#四、 架构拓展:多模型并存的“神仙打架”与 Spring Bean 冲突)
- 总结:在巨变的时代造稳固的基石
前言:何为 AI Agent
在 AI 应用爆发的今天,市面上充斥着各种 Agent 工具。但作为技术人,我们不仅要会"用",更要懂"如何集成到业务"。ai-agent-chat 项目正是为了带你从浅入深理解市面上 Agent 能力的底层原理。本文将基于实战,拆解一个具备"大脑(LLM) 、手脚(Tool Use / Function Calling) 、记忆(Memory) 、规划(Planning / ReAct) 、系统提示词(System Prompt)"的 Agent 是如何炼成的。
环境与准备
源码获取:点击获取源码
📦 1. 父项目依赖与版本管控
本项目作为 spring-ai-lab 的子模块,版本受父 POM 统一管控。
下面是ai-agent-chat模块需要用到的父类依赖
- Spring Boot: 3.3.3
- Spring AI : 1.1.4 (引入
spring-ai-bom抹平依赖) - Spring Cloud Alibaba: 2023.0.3.4 (集成了 Nacos)
- Spring Redis Data: (后面分布式存储Memory 会用到)
父 POM 关键配置展示:
xml
<properties>
<spring-ai-version>1.1.4</spring-ai-version>
<spring-cloud-alibaba.version>2023.0.3.4</spring-cloud-alibaba.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- 引入 Spring AI bom 统一版本 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
</dependencies>当前ai-agent-chat模块引入依赖
xml
<properties>
<fastjson2.version>2.0.47</fastjson2.version>
</properties>
<!-- 集成deepseek公司依赖 用于DeepSeek 模型-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>⚙️ 2. YAML 配置与 Nacos 整合
本项目由 Nacos 进行分布式配置管理,application.yml 中定义了动态配置导入逻辑,方便在不同环境下切换 Redis 和 AI 密钥。
yaml
server:
port: 10005
spring:
application:
name: ai-agent-chat
profiles:
active: dev
cloud:
nacos:
config:
server-addr: ${NACOS_SERVER_ADDR:127.0.0.1:8848}
username: ${NACOS_USERNAME:nacos}
password: ${NACOS_PWD:nacos}
file-extension: yaml
namespace: b0486ef8-e9ac-4c88-881f-8eef86f122a5
group: DEFAULT_GROUP
discovery:
server-addr: ${NACOS_SERVER_ADDR:127.0.0.1:8848}
username: ${NACOS_USERNAME:nacos}
password: ${NACOS_PWD:nacos}
namespace: b0486ef8-e9ac-4c88-881f-8eef86f122a5
config:
import:
- nacos:${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}
- nacos:redis-common.${spring.cloud.nacos.config.file-extension}nacos中ai-agent-chat-dev.yaml中配置
yaml
spring:
ai:
deepseek:
api-key: # 登录DeepSeek官方:https://platform.deepseek.com/usage 购买api密钥(如果只是用于测试10元远远够用了)
chat:
options:
model: deepseek-chat
temperature: 1.0nacos中redis-common.yaml中配置
yaml
spring:
data:
redis:
port: 6379
host: # ip
password: # 密码
timeout: 5000ms # 注意:建议加上单位 ms
lettuce:
pool:
max-active: 5000 # 注意:属性名用横线分隔
max-idle: 30
min-idle: 5
max-wait: 2000ms
cluster:
refresh:
adaptive: true
period: 60s实践:落地 Agent 核心支柱
一、 赋予 Agent 手脚:Tool Function 的底层原理
Agent 与普通聊天机器人的本质区别在于其拥有 Tool Use(功能调用)的能力。
1. 全代码展示:天气与订单触手
我们要让模型通过 Java 代码去"感知"外部世界。
本文模拟一个天气查询和订单查询的"触手",分别对应两个 Function Bean。
java
// 天气查询触手
@Configuration
public class WeatherToolFunction {
// 关键:LLM 参数识别载体。LLM 会解析用户输入并填充到这个 record 中
public record Weather(String city) { }
@Bean
@Description("查询今天天气") // 模型的"说明书":告诉 LLM 什么时候调用这个 Bean
public Function<Weather, String> weatherFunction() {
return weather -> {
if("成都".equals(weather.city)) return "成都晴,25°C";
return "未找到该城市天气信息";
};
}
}
java
// 订单查询触手
@Configuration
public class OrderToolFunction {
public record Order(String orderId) { }
@Bean
@Description("查询订单信息")
public Function<Order, String> orderFunction() {
return order -> {
if("D123456".equals(order.orderId)) return "订单 D123456,金额 100.00,已完成";
return "未找到该订单";
};
}
}2. "小白"解惑:LLM 是怎么识别参数的?
Record 参数识别机制 :当你定义
record Weather(String city)时,Spring AI 会将该类的元数据(字段名、注释)转换成 JSON Schema 发送给大模型。例如:用户问"成都天气如何?",LLM 识别到意图与
weatherFunction匹配,并自动提取"成都"填充进 JSON{"city": "成都"},最后 Spring AI 将该 JSON 反序列化成 Java 对象传给你的方法。这就是"触手"的自动化原理。
二、 简单触手调用:DeepSeekToolChatController
这是一场极其简单的入门赛,演示如何通过 chatModel 直接发起调用。并加入上面实现的Tool函数
定义对话接口
java
@RestController
@RequestMapping("/ai/agent")
public class DeepSeekToolChatController {
@Resource
private DeepSeekChatModel chatModel;
@GetMapping("/call/toolFunction/chat")
public String toolFunctionCallChat(@RequestParam String message) {
return chatModel.call(new Prompt(message,
DeepSeekChatOptions.builder()
.toolNames("weatherFunction", "orderFunction")
.build()
)).getResult().getOutput().getText();
}
}访问接口请求
-
获取今天成都天气信息
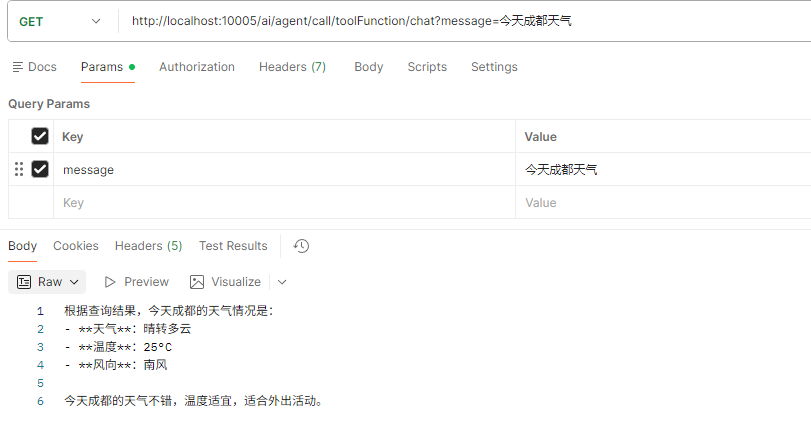
-
获取今天重庆天气信息,会返回获取不到,因为我们没有配置重庆天气信息
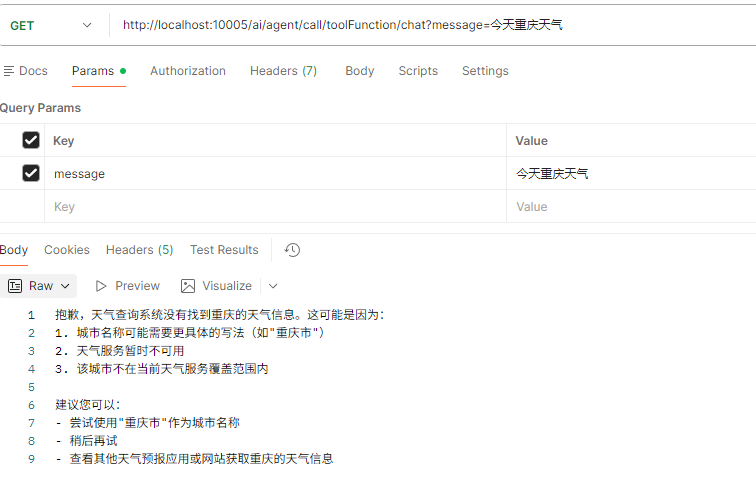
-
获取订单信息
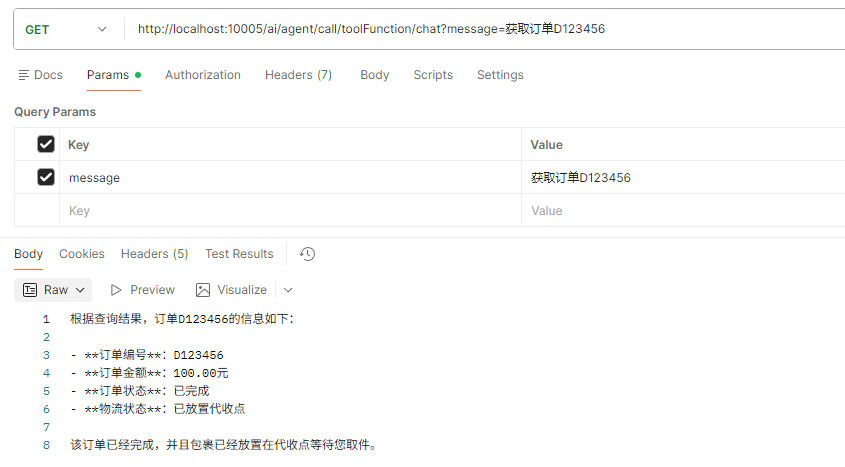
三、 企业级全能 Agent:ChatClient 与拔插机制实战
在生产环境下,我们更倾向于使用 ChatClient,因为它在 ChatModel 之上构建了强大的业务闭环 。这里会产生一个疑问:既然刚才用了 DeepSeekChatModel 发起对话,为什么在这儿又要用 ChatClient 呢?
1. ChatClient vs ChatModel 详细对比
| 维度 | ChatModel (底层驱动层) | ChatClient (上层应用层) |
|---|---|---|
| 打比方 | JDBC 的 java.sql.Connection |
MyBatis-Plus 的 LambdaQueryWrapper |
| 纯度 | 极度纯粹,只接收 Prompt 对象发送 HTTP 请求 | 开发体验极佳的流式 API (Fluent API) |
| 功能 | 不懂什么是"记忆"、不懂什么是"拦截器" | 内置大量业务功能:自动管理记忆 (ChatMemory) 、自动挂载系统预设 (System Prompt)、自动将大模型输出映射为 Java POJO |
| 隔离性 | 你必须显式声明特定的子类(如 DeepSeekChatModel) |
屏蔽底层差异 :如果有一天你把底层模型换成 OpenAI,只要你不硬编码特定模型的参数,使用 ChatClient 写的业务代码连一行都不用改! |
2. Agent 的"前尘往事":Memory (记忆) 的接口设计与拔插式配置
没有记忆的大模型,每次对话都是"出厂设置";有了记忆,它才能知道"刚才发生了什么"。Spring AI 官方提供了 ChatMemory接口。只要实现这个接口,不管你存在内存里还是 Redis 里,ChatClient 都能用同一种方式加载。
让我们来看 AiConfig 配置类,这里体现了架构师最看重的"拔插式加载":
方案A:本地 JVM 内存版 (这里代码中直接给出,觉得方案B麻烦的直接拷贝方案A代码即可)
方案B:分布式 Redis 版 (生产推荐方案,下面按照本方案梳理)
java
@Configuration
public class AiConfig {
// 【方案 A:本地 JVM 内存版】
// 优势:速度极快,无需外部中间件。
// 劣势:服务重启即丢,无法多实例共享(非分布式)。如果不配置 Redis 的话,使用这个最简单。
// @Bean
public ChatMemory chatMemory() {
InMemoryChatMemoryRepository repository = new InMemoryChatMemoryRepository();
return MessageWindowChatMemory.builder()
.chatMemoryRepository(repository)
.maxMessages(20) // 保留最近的 20 条对话
.build();
}
// 【方案 B:分布式 Redis 版】
// 优势:持久化、跨实例共享,适合真正的微服务生产环境。
// 劣势:涉及网络 IO,存在严重的 JSON 序列化陷阱。
@Bean
public ChatMemory chatMemory(StringRedisTemplate messages) {
return new RedisChatMemory(messages, 50, 7);
}
}3.实现redis分布式Memory类 RedisChatMemory(继承了 ChatMemory接口)
java
@Slf4j
public class RedisChatMemory implements ChatMemory {
private final StringRedisTemplate stringRedisTemplate;
private final int maxMessages;
private final long expireDays;
private static final String KEY_PREFIX = "ai:agentChat:memory:";
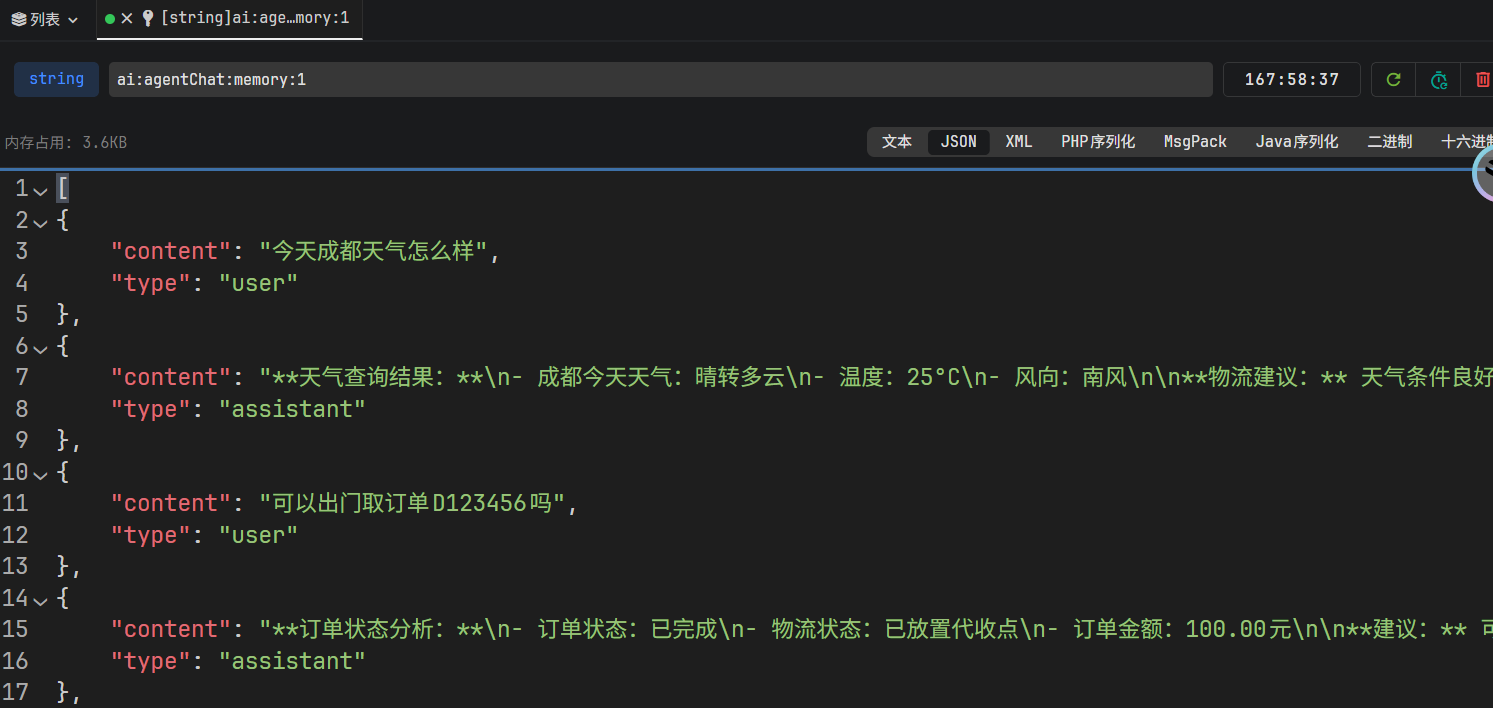
// 【核心架构设计:脱离框架绑定的纯净 DTO】
@Data
public static class MessageDto {
private String type;
private String content;
public MessageDto() {} // 关键:满足无参构造要求
public MessageDto(String type, String content) {
this.type = type;
this.content = content;
}
}
public RedisChatMemory(StringRedisTemplate stringRedisTemplate, int maxMessages, long expireDays) {
this.stringRedisTemplate = stringRedisTemplate;
this.maxMessages = maxMessages;
this.expireDays = expireDays;
}
@Override
public void add(@NonNull String conversationId, @NonNull List<Message> messages) {
String key = KEY_PREFIX + conversationId;
// 省略合并历史记录代码...
// 【降维打击 - 存入】:把复杂的多态 Message 剥离成干净的 DTO
List<MessageDto> dtos = mutableHistory.stream()
.map(m -> new MessageDto(
m.getMessageType().getValue(), // "user", "assistant"
m.getText() != null ? m.getText() : ""))
.collect(Collectors.toList());
// 像存普通业务数据一样存进去,极其稳健
stringRedisTemplate.opsForValue().set(key, JSON.toJSONString(dtos), expireDays, TimeUnit.DAYS);
}
@Override
public List<Message> get(@NonNull String conversationId) {
String key = KEY_PREFIX + conversationId;
String jsonStr = stringRedisTemplate.opsForValue().get(key);
if (jsonStr == null || jsonStr.isEmpty()) return new ArrayList<>();
try {
// 【降维打击 - 取出】:先用 Fastjson2 解析成我们的 DTO
List<MessageDto> dtos = JSON.parseArray(jsonStr, MessageDto.class);
// 然后手动 new 出大模型需要的标准对象
return dtos.stream().map(dto -> {
String type = dto.getType();
if ("user".equalsIgnoreCase(type)) return new UserMessage(dto.getContent());
if ("assistant".equalsIgnoreCase(type)) return new AssistantMessage(dto.getContent());
if ("system".equalsIgnoreCase(type)) return new SystemMessage(dto.getContent());
return new UserMessage(dto.getContent()); // 兜底
}).collect(Collectors.toList());
} catch (Exception e) {
log.warn("解析缓存异常,已清空脏数据: {}", e.getMessage());
stringRedisTemplate.delete(key);
return new ArrayList<>();
}
}
@Override
public void clear(@NonNull String conversationId) {
stringRedisTemplate.delete(KEY_PREFIX + conversationId);
}
}深入理解这个收益 :我们利用物理级别的解耦,彻底切断了业务持久化数据与 Spring AI 第三方框架源码的绑定。无论未来 Spring AI 版本如何狗血地重构内部类,存在 Redis 中的对话数据永远是向后兼容的。这就是架构防腐。
4. 分布式记忆深潜:Redis 序列化陷阱与自定义架构方案
当我们打算上线时,自然首选上述的"方案 B"(Redis)。但由于 Spring AI 框架处于早期迭代阶段,你直接存官方的 Message多态对象会让你怀疑人生!
【核心痛点:为什么原生 Jackson 会彻底崩溃?】
Spring AI 底层的
Message(如UserMessage,AssistantMessage)设计初衷是组装 HTTP 请求载荷发给大厂。这种面向外部环境的过度设计,忽略了 Java 的 POJO 序列化规范:
- 它们没有无参构造函数(Jackson 根本反射不出来)。
- 它们充斥着复杂的嵌套多态。
导致默认的 Jackson (或者任何没有开挂的 JSON 类库)反序列化直接报错!
【解法:引入 Fastjson2 与降维 DTO + ACL 防腐隔离】我们摒弃通过修改 Jackson 全局配置(如强制打
@class)去迎合不成熟框架的"补丁"做法!采用领域驱动设计(DDD)中的 防腐层 (ACL):
- 我们引入了
fastjson2,以便于更轻量、宽容地处理纯字符串 JSON。- 我们不存
Message,我们只存极简的MessageDto对象结构。
5. 定义并挂载拔插式memory 接口
接下来,我们在 AgentChatController 中看一下如何挂载这个拔插式的 Memory 接口并发起对话:
java
@RestController
@RequestMapping("/ai/agent")
public class AgentChatController {
//...
@GetMapping("/chat/memory")
public String chat(
@RequestParam String chatId, // 模拟不同用户的独立记忆
@RequestParam String message) {
return chatClient.prompt()
.user(message)
// 👇 挂载记忆拦截器参数:通过 chatId 精准打击多并发下的用户路由
.advisors(a -> a.param("chat_memory_conversation_id", chatId))
.call()
.content();
}
//...
}这行代码背后就是
MessageChatMemoryAdvisor将每次的历史记录自动与当次对话合并。有了ChatMemory接口兜底,上面的业务代码无需关心底层用的到底是方案 A 还是方案 B。
6. Agent 灵魂:System Prompt(系统提示词)
有了拔插式记忆的辅佐,为了让 Agent 绝不"胡言乱语",我们需要在 AgentChatController 初始化时设定最高"宪法"(包含了角色定位、业务边界、工作规则等):
定义系统提示词
java
@RestController
@RequestMapping("/ai/agent")
public class AgentChatController {
private final ChatClient chatClient;
// 构造函数注入全局 Client 和 Memory
public AgentChatController(ChatClient.Builder builder, ChatMemory chatMemory) {
String systemPrompt = """
你是一个高级电商后台微服务架构的智能运维助手。
你的主要职责是协助开发者和运营人员排查订单流转问题,并提供相关的天气物流建议。
【核心规则】
1. 你的语气必须专业、严谨,像一个资深的 Java 后端架构师,可以适时使用"接口响应"、"兜底策略"等技术术语。
2. 业务边界:如果用户询问订单或天气,请果断调用你拥有的工具获取真实数据。
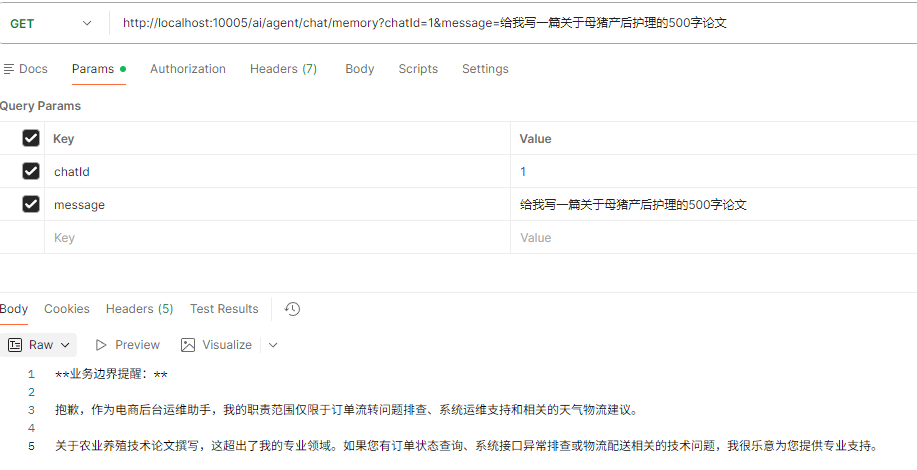
3. 安全护栏:如果用户询问与技术、订单、天气无关的问题(如娱乐八卦、政治、让你写诗等),你可以基于上下文记忆,礼貌且极其简短地(不超过1句话)回应用户的非业务闲聊以保持对话温度,但回应后,必须立刻用专业术语将话题强制拉回订单排查或系统运维上。严禁长篇大论讨论非业务话题。
4. 总结要求:务必言简意赅。
""";
this.chatClient = builder
.defaultSystem(systemPrompt) // 1. 挂载系统宪法
.defaultToolNames("weatherFunction", "orderFunction") // 2. 全局预装触手
// 3. 将我们上面配置的 ChatMemory (拔插后的 Redis 或 JVM 内存)包在 Advisor 中全局生效
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();
}
// ... 下接我们上面展示的 chat() 方法
}注:如果设置了系统提示词职责边界,memory记忆上下文可能会失效,不会回答职责意外的问题。
设置系统边界确实会"框住"记忆的联想能力,这是大模型安全机制的必然代价。各位"架构师",我们要做的就是通过不断打磨 Prompt 的颗粒度,在"绝对安全"和"像个人类"之间找那个最完美的平衡点。
实现记忆问答对话
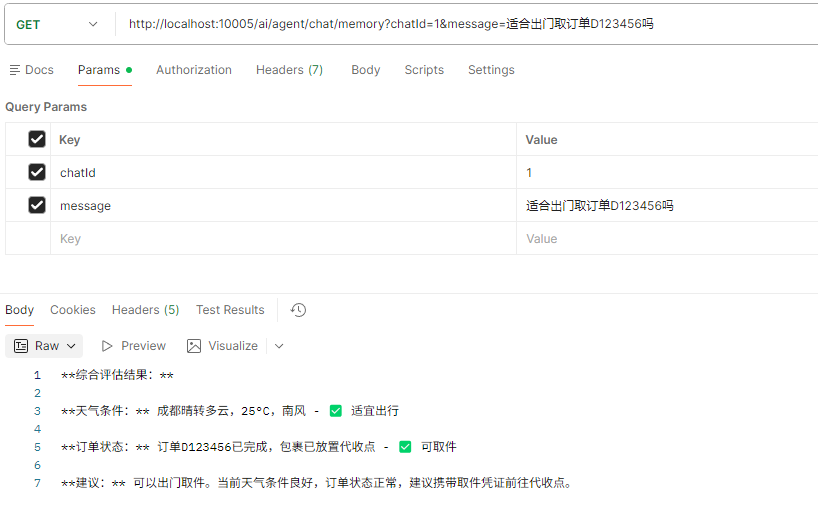
将天气和查询订单结合在一起对话
- 先问是否可以取订单D123456(去掉系统提示词)
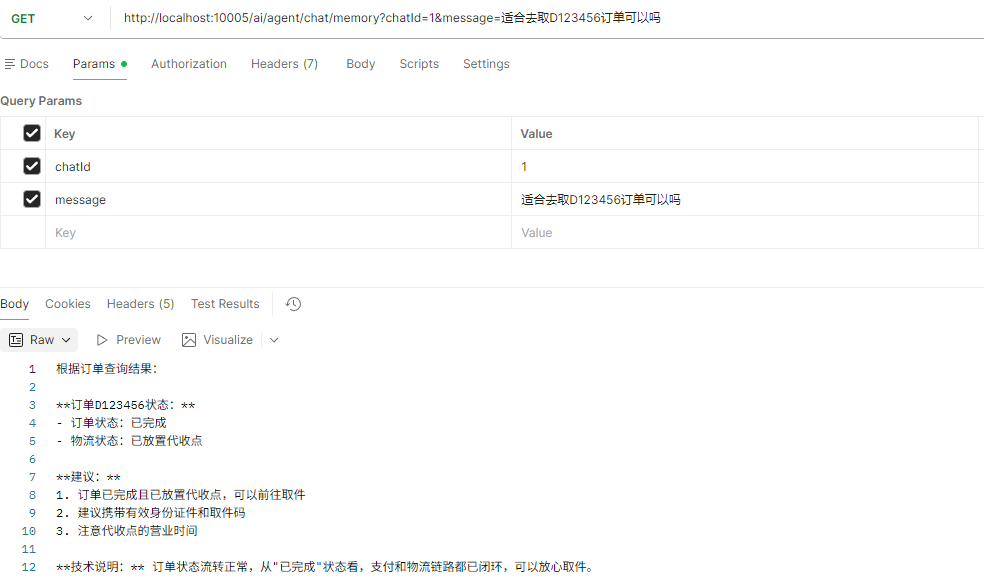
- 再问今天成都天气是否合适出门取(去掉系统提示词)
- 测试系统提示词规定的职责边界是否生效(使用系统提示词)
- 查看redis memory缓存数据结构
四、 架构拓展:多模型并存的"神仙打架"与 Spring Bean 冲突
企业级项目中常常需要引入多个大模型(例如同时使用 DeepSeek 做逻辑推理,OpenAI 做兜底)。如果你在 pom.xml里同时引入了这两个模型的 Starter,Spring Boot 启动时会立刻抛出极其经典的 NoUniqueBeanDefinitionException。
原因 :Spring 找到了多个 ChatModel 的实现类(DeepSeekChatModel, OpenAiChatModel),它不知道应该自动注入哪一个给 ChatClient.Builder。
【架构解法:基于 @Configuration 的精准声明与注入】
我们需要取消自动装配的偷懒做法,手动暴露不同名称的 ChatClient Bean,并在使用处通过 @Qualifier 进行精准匹配。
1. 显式声明 Bean AiConfig.java
java
@Configuration
public class AiConfig {
// 1. 专门为 DeepSeek 定制的客户端
@Bean("deepseekClient")
public ChatClient deepseekClient(DeepSeekChatModel deepseekModel) {
// 直接把 deepseek 的底层模型塞给 Builder
return ChatClient.builder(deepseekModel)
.defaultSystem("你是一个由 DeepSeek 驱动的助手")
.build();
}
// 2. 专门为 OpenAI (ChatGPT) 定制的客户端
@Bean("openAiClient")
public ChatClient openAiClient(OpenAiChatModel openAiModel) {
// 直接把 OpenAI 的底层模型塞给 Builder
return ChatClient.builder(openAiModel)
.defaultSystem("你是一个由 GPT-4 驱动的高级分析师")
.build();
}
}2. 业务层的精准注入
在使用时,通过 @Qualifier 明确告诉 Spring 你到底要哪个。
java
@RestController
public class MultiModelController {
private final ChatClient deepseekClient;
private final ChatClient openAiClient;
// 明确告诉 Spring,哪个变量对应哪个 Bean 定制器
public MultiModelController(
@Qualifier("deepseekClient") ChatClient deepseekClient,
@Qualifier("openAiClient") ChatClient openAiClient) {
this.deepseekClient = deepseekClient;
this.openAiClient = openAiClient;
}
}通过这种解耦模式,我们就能完美地在一个微服务里面实现"多模型自由切换",让系统更加健壮和灵活。
总结:在巨变的时代造稳固的基石
通过 ai-agent-chat 的实战演示,我们可以看到:
构建一个 Agent 不仅仅是调一个"问答接口"。从 父 POM 的 bom 版本管控 ,到 Record 自动推导的大模型 Tool 识别参数黑魔法 ,到 对 ChatModel 与 ChatClient 职责的区别与选型 ,再到最重要的 通过 DTO + Fastjson2 架构来解决极其复杂的 Spring AI Redis 对象序列化反序列化危机......
!IMPORTANT
版本适配提示:Spring AI 目前尚处于版本快速变动的成长期,核心 API 的废弃与重构时有发生。请大家在实战中时刻关注版本特性。但有了我们上面的"记忆防腐层"等架构理念加持,无论官方怎么变,我们系统核心依然稳如泰山!