📌 写在前面
2025年开年,DeepSeek-R1 的爆火让"强化学习"(Reinforcement Learning, RL)这个词再次冲上热搜。
当人们还在惊叹于 o3、Grok-3 的推理能力时,DeepSeek 用一份技术报告告诉我们:不需要海量人工标注,仅靠纯强化学习,AI 就能自我进化出复杂的推理能力------在 AIME 2024 数学竞赛中,模型准确率从 15.6% 飙升至 71%,甚至出现了"顿悟时刻"(Aha Moment)。
这不禁让人好奇:强化学习究竟是什么?为什么它能让大模型"突然开窍"? 今天,我们就来系统聊聊这项技术的前世今生。
🧠 一、强化学习:让 AI 像孩子一样学习
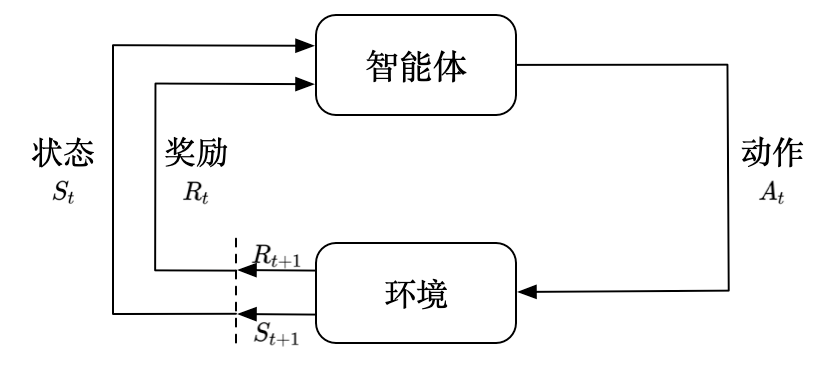
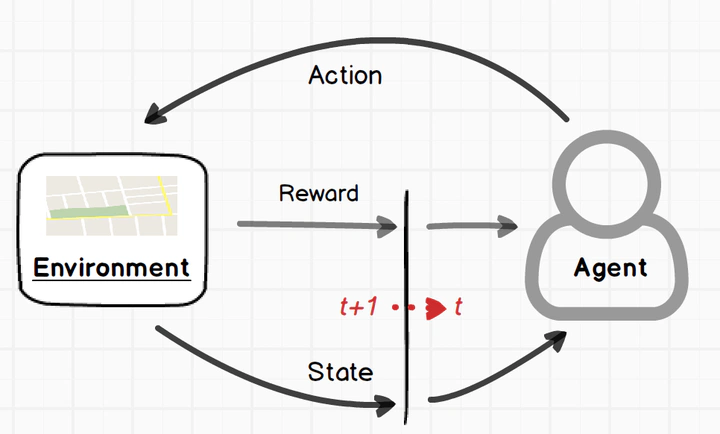
强化学习的核心思想,其实和教育孩子骑自行车没什么两样:
> 没有说明书,只有试错;没有标准答案,只有奖励和惩罚。
1.1 五大核心要素
| 要素 | 解释 | 类比(学骑车) |
|---|---|---|
| 🤖 Agent<br>智能体 | 做决策的 AI 主体 | 学车的孩子 |
| 🌍 Environment<br>环境 | 智能体所处的外部世界 | 操场、自行车、路面 |
| ⚡ State<br>状态 | 环境当前的情况 | 车身倾斜角度、速度 |
| 🎮 Action<br>动作 | 智能体可执行的操作 | 左拐、右拐、加速、刹车 |
| 🏆 Reward<br>奖励 | 环境对动作的反馈信号 | 保持平衡+1分,摔倒-10分 |
目标只有一个 :通过不断尝试,找到一套策略(Policy),让长期累积奖励最大化。
🧬 二、从巴甫洛夫的狗到 DeepSeek:RL 的三次进化
第一层:经典条件反射(1890s)
巴甫洛夫的狗实验证明:生物可以通过关联学习预测未来奖励 。这启发了现代 RL 中的价值函数(Value Function)------评估"当前状态有多好"。
第二层:试错学习(1911)
桑代克的猫和斯金纳的老鼠告诉我们:主动探索比被动接受更有效 。这直接对应了 RL 中的探索-利用困境(Exploration vs Exploitation)。
第三层:深度强化学习(2015+)
当深度学习遇上 RL,诞生了 DQN、AlphaGo、ChatGPT。
> 如今,我们进入了第四次进化 :大模型 + 强化学习 = 推理能力的涌现。
⚙️ 三、核心技术揭秘:PPO、GRPO 与奖励机制
DeepSeek-R1 的成功,离不开两项关键技术:GRPO 算法 和可验证奖励机制。
3.1 PPO vs GRPO:谁是更好的"教练"?
传统 RL 使用 PPO(近端策略优化) ,但它需要维护一个与策略模型同等大小的价值模型(Critic),训练成本极高。
GRPO(群体相对策略优化) 做了巧妙改进:
- ❌ 抛弃价值模型
- ✅ 通过"组内评分对比"估计基线
- 💡 大幅降低显存占用,提升训练效率
3.2 奖励设计:AI 的"应试教育"
DeepSeek-R1 采用了基于规则的奖励系统:
- 准确性奖励:答案是否正确(数学题的硬性标准)
- 格式奖励 :是否按要求输出思维链(
<think>...</think>标签)
关键洞察 :不需要告诉 AI"如何思考",只需要告诉它"什么是对的",AI 自己就能进化出长链式推理(Chain-of-Thought)和自我反思能力。
🚀 四、RL Scaling Law:推理能力的"顿悟时刻"
DeepSeek-R1-Zero 的实验揭示了一个惊人现象:
> 随着 RL 训练步数增加,模型的推理能力不是线性提升,而是"涌现"的。
4.1 两个关键指标
- Pass@1 准确率:从 15.6% → 71.0%(AIME 2024)
- 响应长度:思考时间自动延长,模型学会"多想想"
4.2 "Aha Moment":AI 的自我觉醒
在训练日志中,研究人员发现了这样的思考痕迹:
> "Wait, let me verify this step again... Actually, I made a mistake in the previous calculation. Let me recalculate from the beginning."
这不是人工预设的程序,而是 RL 训练自发产生的反思行为。
🌐 五、应用场景:RL 正在重塑哪些领域?
✅ 大模型后训练(Post-training)
- ChatGPT、Claude、DeepSeek 都用 RLHF(人类反馈强化学习)对齐价值观
- 最新趋势:RLVR(可验证奖励强化学习) 替代人工标注,实现自我迭代
✅ 金融交易
- 高频交易策略优化
- 风险管理与资产配置
- 据 Research Nester 报告,2024 年 RL 市场规模已超 527 亿美元
✅ 机器人控制
- 宇树科技机器人的平衡控制
- 机械臂抓取、导航任务
✅ 游戏与电竞
- AlphaGo、OpenAI Five、AlphaStar
- 超越人类顶尖选手的极限
🔮 六、未来展望:通往 AGI 的必由之路?
Sebastian Raschka 在 2025 年的最新博客中指出:
> "我们正接近单纯扩大模型规模和数据的极限,而基于 RL 的推理训练,是突破瓶颈的关键。"
三个确定性趋势:
-
Test-Time Computing(测试时计算)
不再一味堆参数量,而是让模型"思考更久"(类似 o3 的扩展思考模式)
-
Self-Play(自我博弈)
模型通过自我对弈生成数据,实现数据飞轮闭环
-
多模态 RL
从文本推理扩展到视觉、听觉、具身智能
📝 总结
强化学习不是新鲜事物,但大模型时代的 RL 正在展现前所未有的潜力:
- 🔹 无需人工标注:纯 RL 即可激发推理能力
- 🔹 自我进化:模型自主发现复杂策略
- 🔹 可解释性:思维链让"黑盒"变透明
DeepSeek-R1 的意义不仅在于性能接近 o1,更在于它证明了:给 AI 一个目标,让它自己去探索,可能比手把手教更有效。
这或许正是通往通用人工智能(AGI)的关键路径:不是记忆所有知识,而是学会如何学习。