2026 年 3 月 31 日,Anthropic 的 Claude Code 因一个 npm source map 打包失误,将约 51.2 万行 TypeScript 源码完整暴露在公网上。1906 个文件、59.8MB 的 source map,把这个当前最复杂的 AI 编程 Agent 的内部架构全部摊在了阳光下。
大多数分析聚焦在记忆系统、卧底模式、反蒸馏这些"吸睛"的功能上。但翻遍主流 Agent runtime 的源码,我们认为 Claude Code 最被低估的部分,是它对自身行为的观测架构。这套架构揭示了一个正在成形的新领域:ABA------Agent Behavior Analysis,Agent 行为分析。
一、51 万行代码里,藏着一套完整的 Agent 可观测性工程
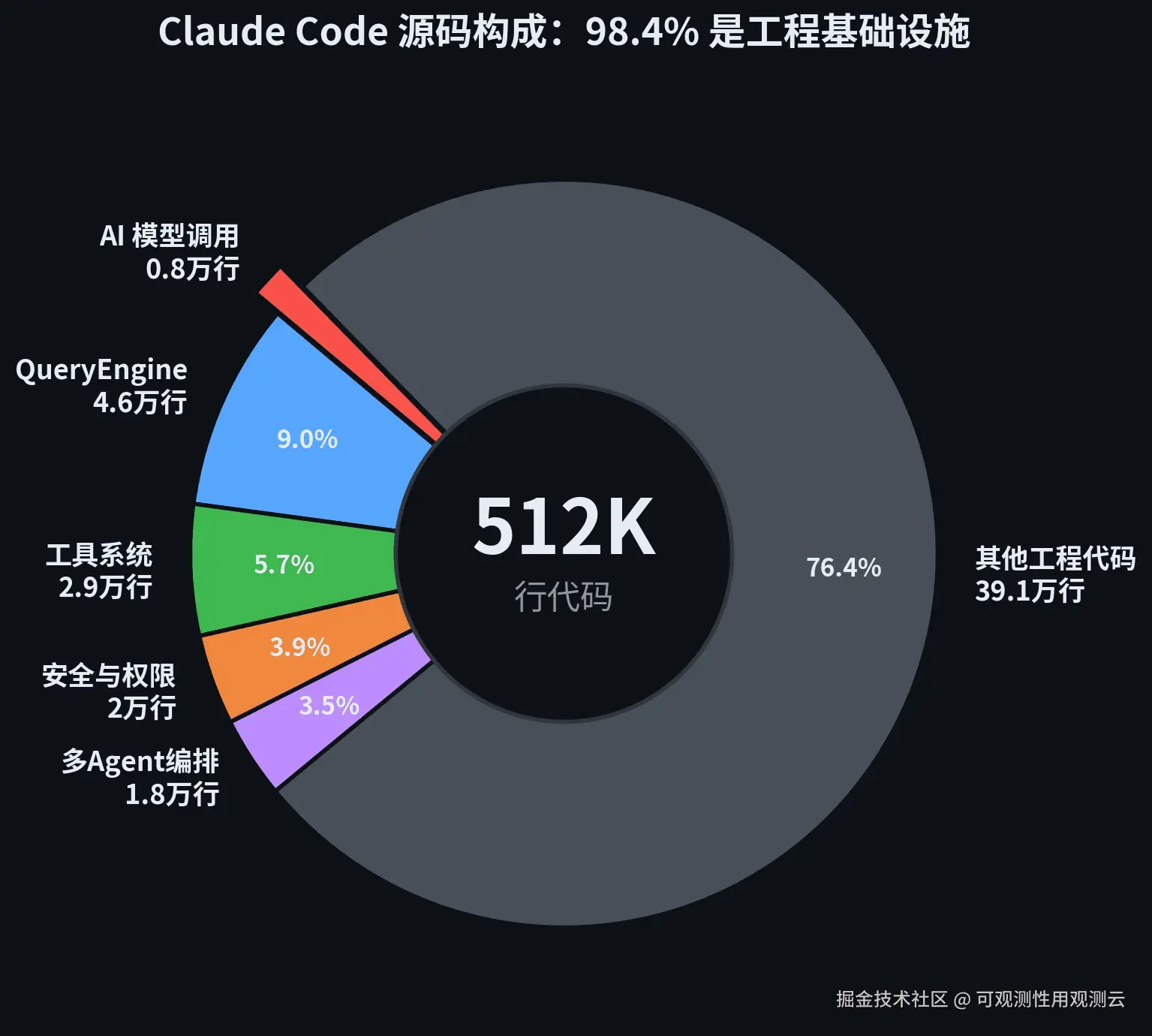
Claude Code 完全不是"套了个壳的 LLM"。The Neuron 的分析一针见血:它更接近一个面向软件工程的操作系统------权限层、记忆层、后台任务、IDE 桥接、MCP 管道、多 Agent 编排,全部堆叠在模型周围。据 The Neuron 与 alex000kim 的独立分析,51.2 万行 TypeScript 中,直接调用 AI 模型接口的代码只有约 8000 行,占 1.6%。剩下的 98.4%------4.6 万行的 QueryEngine、2.9 万行的工具系统、2 万行的安全与权限控制、1.8 万行的多 Agent 编排------全是围绕模型构建的工程基础设施。
泄露源码中的 INTERNAL_MODEL_REPOS 常量,不仅暴露了 Anthropic 的内部仓库列表,还揭示了 Undercover 模式的存在------该模式专门用于防止代号泄露。
但真正让我们兴奋的不是这些功能本身。是 services/analytics/ 和 utils/telemetry/ 这两个目录。
Claude Code 在可观测性上下的功夫,远不止"打日志 + 统计接口耗时"。它对 Agent 运行时的语义做了系统性建模,构成了迄今为止最完整的 Agent 可观测 工程样本。以下四件事,每一件都可以直接拿来用。
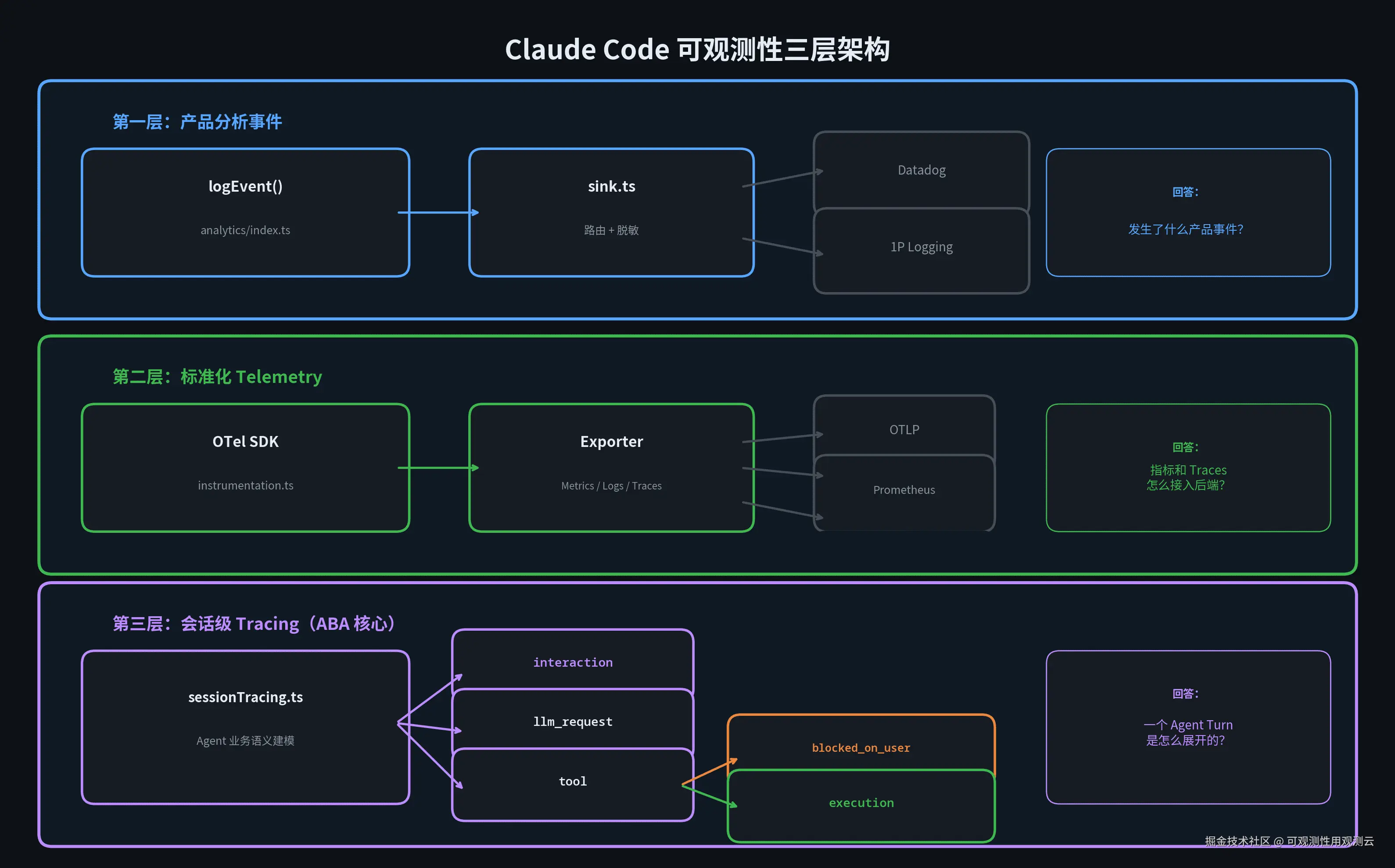
1.1 三层分离:不要一锅端
Claude Code 把可观测性拆成了三个独立层次,各管各的事:
第一层:产品分析事件。
入口在 services/analytics/index.ts,无依赖模块,提供 logEvent() 统一入口,sink 未挂载时先入队。后端路由在 sink.ts,分流到 Datadog 和 1P(first-party)event logging。回答的问题是:发生了什么产品事件? ------tengu_oauth_flow_start、tengu_plugin_install_command、tengu_session_resumed,产品经理和运营关注的东西。
第二层:标准化 telemetry。
主入口在 utils/telemetry/instrumentation.ts,用 OpenTelemetry 的 metrics / logs / traces,按 exporter 配置导向 OTLP、Prometheus、console 或内部导出器。回答的问题是:指标和标准 traces 怎么接入后端? ------基础设施观测层,强调标准生态兼容。
第三层:会话级 Tracing。
核心模块 utils/telemetry/sessionTracing.ts,不追踪网络请求,直接对 Claude Code 的业务语义建模------interaction、LLM request、tool 调用、hook、被用户阻塞的时间。回答的问题是:一个 Agent turn 在 runtime 里是怎么展开的?
为什么不能混在一起?因为一上来就追求"全都记下来",很快会踩三个坑:
- 命名体系失控(user_clicked_button 和 model_fallback_triggered 出现在同一个 event stream 里,没人分得清该归产品分析还是工程排查);
- 后端 schema 和 cardinality 爆炸(Agent 可观测数据天然是半结构化、高维度、高基数的);
- 看到很多"日志"但看不清因果链(一个 user turn 可能拆成多次 LLM request、多个 tool call、多个 subagent,数据平铺在一起只能靠 grep 拼凑)。
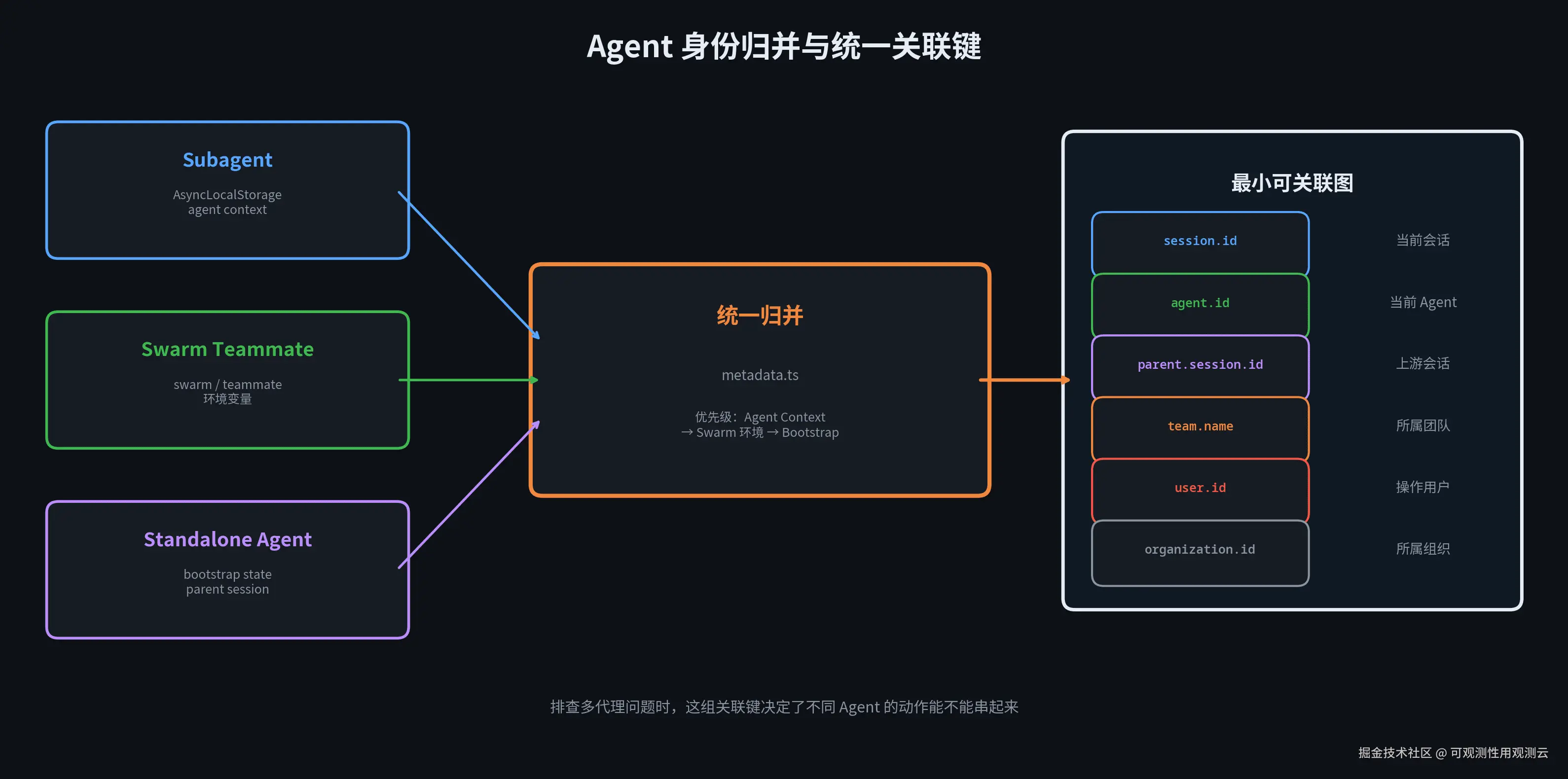
1.2 统一关联键:先把同一个实体串起来
Agent 系统里,真正困难的不是"生成一条事件",而是"让不同事件能被关联起来"。
Claude Code 在关联键上做得克制而精准,集中在两处管理:
- OTel 侧 (telemetryAttributes.ts):统一挂 user.id、session.id、organization.id 等跨信号共享属性。高基数字段受 OTEL_METRICS_INCLUDE_* 环境变量控制------作者在主动管理 cardinality,不是一股脑全塞进指标系统。
- Analytics 侧(metadata.ts):补了 agentId、parentSessionId、agentType、teamName。取值优先级是:AsyncLocalStorage 中的 agent context → swarm / teammate 环境 → bootstrap state 中的 parent session。
为什么这么复杂?因为同一个系统里,Agent 既可能是同进程 subagent,也可能是 swarm teammate,也可能是 standalone agent。可观测性层不能假定只有一种身份来源,必须自己做统一归并。归并之后,后端拿到的是一个最小可关联图:当前 session 是谁、当前 agent 是谁、上游 parent session 是谁、属于哪个 team。排查多代理问题时,这是关键。
1.3 Agent 语义级 Span:trace 一个 turn,不是 trace 一个函数
sessionTracing.ts 是整个架构中最有价值的部分。它把 Claude Code 的业务语义直接编码成了 span 类型:
- claude_code.interaction:一次用户交互回合(root span)
- claude_code.llm_request:一次模型调用
- claude_code.tool:一次工具调用
- claude_code.tool.blocked_on_user:等待用户批准
- claude_code.tool.execution:工具实际执行
- hook:钩子执行(仅 beta tracing 下创建)
根节点的选择极其说明问题:可观测性的基本单位是"用户的一次交互回合",不是某次网络请求。一次 turn 通常包含 prompt 处理、多次模型调用、多个工具执行、可能的人工确认、hook 和恢复逻辑。没有 interaction 作为根节点,后面所有 span 碎成平铺事件,读 trace 时完全看不出这轮到底发生了什么。
更精妙的是 tool.blocked_on_user 这个 span。很多 Agent 平台做 tracing 只追踪模型延迟和工具延迟,但 Claude Code 还单独追踪"等用户批准的时间"。这等于承认了一个事实:Agent 的真实耗时不全是机器耗时,权限审批和人工中断本身就是主链路的一部分。把这类时间独立出来之后,你才能回答:慢是因为模型慢还是审批慢?某类工具成功率低,是执行问题还是审批被拒绝太多?一个 turn 很长,时间主要花在 Agent 计算上还是等人上?
这就是 Agent 行为观测的核心价值:不是告诉你"Agent 调了什么 API",而是告诉你"Agent 的一次完整行为是怎么展开的、卡在哪里、为什么卡"。
实现上,sessionTracing.ts 用 AsyncLocalStorage 保存 interactionContext 和 toolContext,后续的 llm_request、tool.execution、hook 自动挂到正确父节点下。并发归因也做了处理------endLLMRequestSpan() 明确提醒调用方,多请求并发时(warmup、topic classifier、主线程请求同时在飞)必须传回原始 span 实例,否则响应会被错误归因。悬挂 span 清理用 WeakRef + 30 分钟 TTL + 60 秒扫描间隔,源码注释写得很直接:这是 "safety net for spans that were never ended"------aborted streams、uncaught exceptions、mid-query 中断,在 Agent runtime 里不是边缘情况,是常态。
1.4 信号各归各位,Taxonomy 即治理
Claude Code 没有把所有信号都压成"事件"。Event 看离散行为(某类行为是否发生),Trace 看因果链(一个 turn 怎么展开的),Metric 看趋势(session 数、token 统计、成本)。不分层的话,要么什么都塞 trace 导致 trace 爆炸,要么什么都打 event 之后只能写 SQL 拼执行过程。
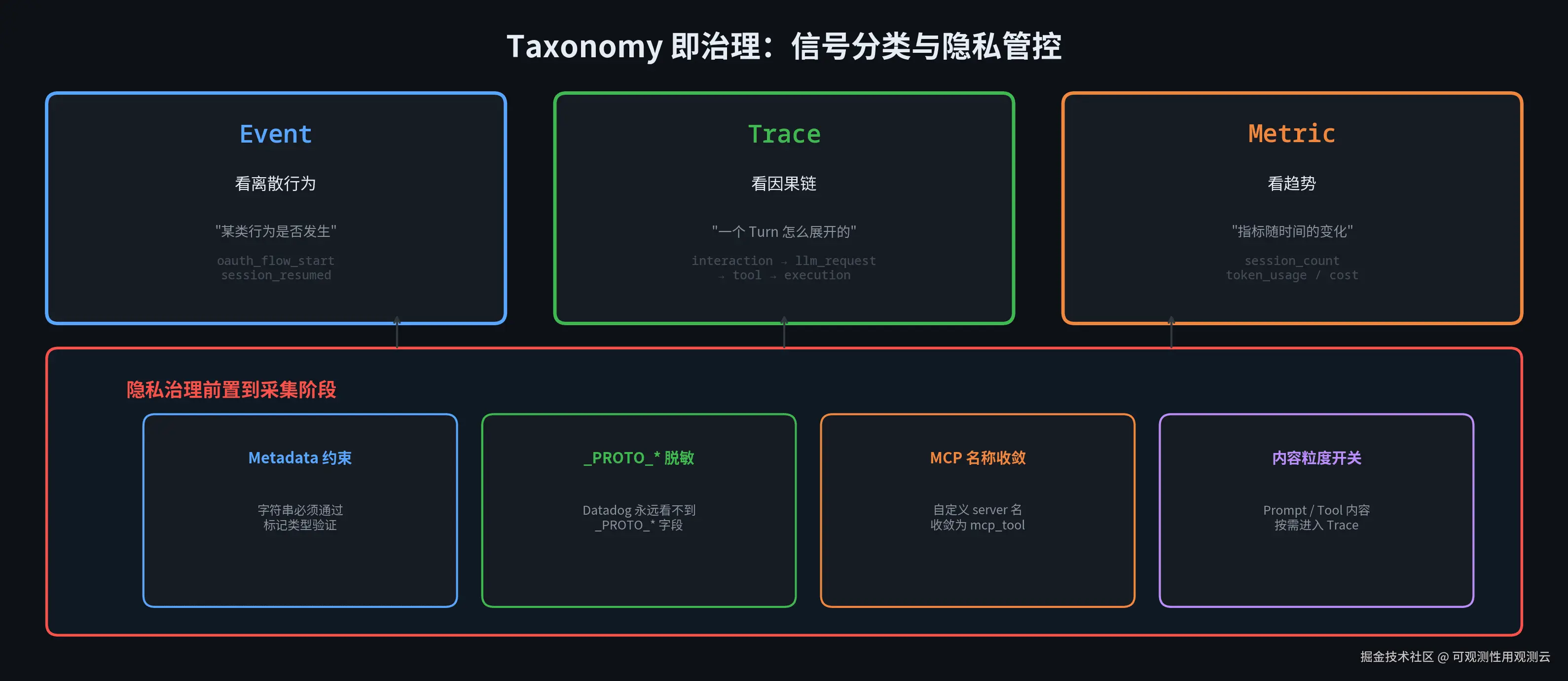
更值得注意的是隐私治理前置到了采集阶段:
- logEvent() 的 metadata 被限制成数值和布尔值;字符串要进来,必须显式通过一个名字极长的标记类型:AnalyticsMetadata_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS。名字看着像玩笑,意图很认真:在类型层就限制误报敏感信息。
_PROTO_*分层脱敏:sink.ts 在 Datadog fanout 前统一调 stripProtoFields(),Datadog 永远看不到_PROTO_*字段;只有 1P exporter 拿到完整 payload。一个过滤点管住所有 sink。- MCP 工具名收敛:sanitizeToolNameForAnalytics() 默认把 mcp____ 收敛成 mcp_tool------用户自定义的 MCP server 名可能包含个人信息。
- 内容粒度开关:OTEL_LOG_USER_PROMPTS、OTEL_LOG_TOOL_CONTENT、OTEL_LOG_TOOL_DETAILS 分别控制 prompt 文本、工具内容、工具参数是否进入 trace。
Taxonomy 是治理问题,不只是分类。可观测性从一开始就要和隐私、基数、后端能力一起设计。
小结:ABA 的四个可以直接带走的结论
- 先做目标分层。产品事件、标准 telemetry、会话 tracing 三层各管各的事。
- 统一关联键比多打一条日志重要。sessionId、agentId、parentSessionId、teamName 决定了多代理系统的动作能不能串起来。
- 业务语义级 tracing 才真正有用。interaction、llm_request、tool.blocked_on_user 比函数耗时更能解释 Agent 为什么慢、卡在哪。
- Taxonomy 是治理问题。对 metadata、字符串、MCP 名称和字段粒度的约束,说明可观测性从一开始就要和隐私、基数、后端能力一起设计。
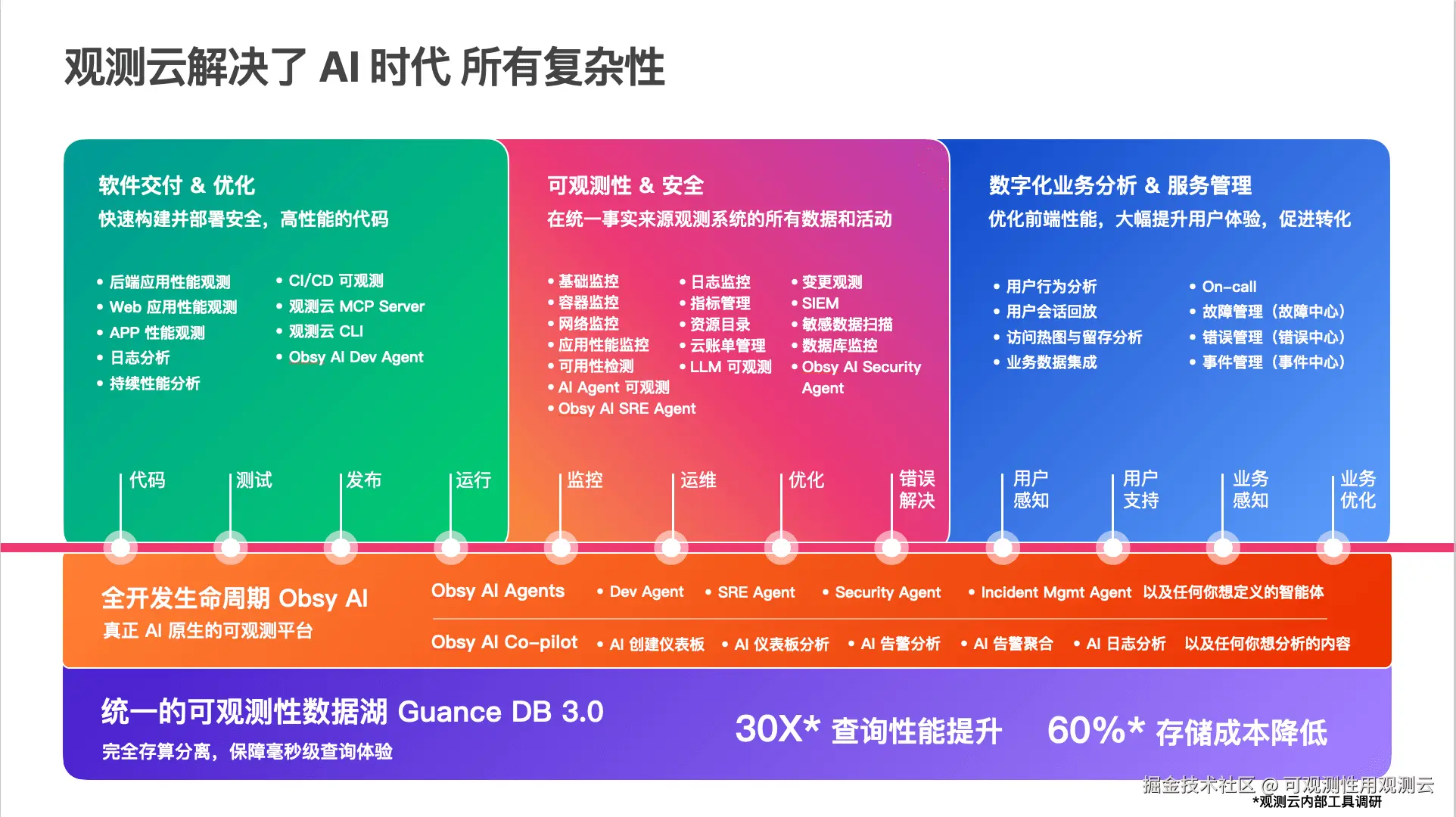
二、工程美学:为什么观测云天然适合做 Agent 可观测
观测云和 Claude Code 的可观测架构设计上有一些趋同。当 AI Agent 走进企业生产环境,问题会变得更加尖锐:你不是在观测自己的 Agent,你是在观测别人的 Agent------而且它正在操作你的生产系统。观测云的架构,天然就是解决这类问题的最优解。
2.1 数据模型不应该是预设的:Schemaless 的力量
Claude Code 的 metadata.ts 做了一个很工程化的决定:Agent 的身份来源不是预设的。同一个系统里,Agent 可能是 subagent、teammate、standalone,可观测性层必须自己做统一归并,而不是假定只有一种身份模型。
观测云的 GuanceDB 做了同样的选择,但在更底层:Schemaless。允许写入任意字段,实时增删数据字段,不需要手动维护数据模型。这不是偷懒,这是对现实的尊重------在可观测性场景中,你永远无法预知下一个需要观测的维度是什么。Agent 系统尤其如此:今天你需要 sessionId,明天可能需要 parentSessionId,后天可能需要 teamName。如果每加一个字段都要改 schema、跑 migration,可观测性就永远追不上业务变化的速度。
Claude Code 在应用层解决了"Agent 身份不可预设"的问题。观测云在存储层解决了"观测维度不可预设"的问题。同一个思路,不同的层次,观测云消除了解决问题的摩擦成本。
2.2 采集和处理必须分离,且处理必须可编程
Claude Code 的可观测性链路有一个很清晰的分层:analytics/index.ts 负责事件入口(采集),sink.ts 负责后端路由和脱敏(处理),两者通过队列解耦。logEvent() 的调用方不知道后端是 Datadog 还是 1P,sink 可以延迟装配,启动早期的事件不会丢。
观测云的 DataKit 做了同样的事,但做得更彻底。DataKit 是一个独立的数据采集器,部署在目标环境中。采集到的数据经过 Pipeline ------一个运行在 DataKit 上的轻量级可编程脚本语言------进行自定义解析、切割、过滤和结构化转换,然后通过统一的 Dataway 接口上报。
关键词是可编程。Claude Code 的 sink.ts 里,脱敏逻辑(stripProtoFields())、采样配置(tengu_event_sampling_config)、字段约束(marker type)都是硬编码在 TypeScript 里的。这对一个单一产品来说够用了。但对一个要服务千差万别的 Agent 系统的可观测性平台来说,处理逻辑必须是用户可定义的。
Pipeline 就是这个答案。你可以用它把 OpenClaw 的非结构化日志切割成结构化字段,可以用它过滤掉不需要的数据,可以用它在采集阶段就完成脱敏------而不是等数据到了平台再处理。这和 Claude Code 的 _PROTO_* 分层脱敏是同一个设计直觉:治理要前置到采集阶段,只不过观测云把这个能力开放给了用户。
2.3 查询语言必须是自研的、统一的
Claude Code 内部有一个 4.6 万行的 QueryEngine,负责在 Agent 运行时对上下文、记忆、代码库进行检索和推理。它不是简单地把所有东西塞进上下文窗口,而是建立了按需检索机制------记忆是索引,不是仓库。
观测云自研了 DQL(Debug Query Language) ,专门为时序数据、日志数据、事件数据的高效查询和分析而设计。一条 DQL 可以跨数据源关联查询------trace_id 在链路数据里,token 用量在指标数据里,错误详情在日志里,一条查询串起来,不用跨三个界面来回跳。
这背后是同一个执念:当你面对的数据足够复杂、足够异构时,通用查询语言不够用,你需要一个为你的领域专门设计的查询语言。 Claude Code 的 QueryEngine 是为 Agent 认知状态设计的;DQL 是为可观测性数据设计的。两者都拒绝了"用现成的就行"这个诱惑。
2.4 对高基数的敬畏与治理
Claude Code 的 telemetryAttributes.ts 里,session.id、版本号、account UUID 这些字段是否带上,受 OTEL_METRICS_INCLUDE_* 环境变量控制。作者在主动管理 cardinality------高基数字段不是默认全塞进指标系统的。MCP 工具名默认收敛成 mcp_tool,只有白名单内的 server 才放更细的名字出去。
GuanceDB 的针对高基数指标做了写入和查询优化,确保高基数不影响数据库稳定性。
这不是巧合。任何做过可观测性的人都知道,高基数是可观测性系统的头号杀手。Claude Code 在客户端侧用环境变量和白名单管理它;观测云在存储引擎层解决它。同一个敌人,不同的战场。
2.5 总结一下这种设计趋同
在四个地方独立地走向了相同的工程结论。
因为当你认真面对"如何让复杂系统的内部状态变得可理解"这个问题时,工程上的最优解是收敛的。
三、场景驱动:企业级 Agent 行为监控的真实价值
随着 Agent 逐步接管企业核心业务流程,让我们看看在实际企业环境中,Agent可观测是如何发挥作用的。
场景一:成本刺客的精准定位(Token 消耗归因)
痛点:某企业上线了基于大模型的智能客服 Agent,月底账单暴涨 300%。研发团队翻遍了应用日志,只知道总 Token 消耗巨大,却无法回答:是哪个技能(Skill)最耗 Token?是哪个版本的 Prompt 导致了上下文膨胀?
Agent 观测价值:通过观测云的 Agent 调用分析看板,企业可以应用、模型、甚至具体的 sessionId 进行聚合分析。团队迅速定位到:是一个新增的"历史订单查询"技能,在多轮对话中未做上下文截断,导致每次请求都带着数百条历史记录去请求大模型。精准归因后,三行代码的修复就挽回了每天数千元的 API 浪费。

场景二:失控 Agent 的紧急熔断(实时告警与行为追踪)
痛点:一个用于自动化运维的 Agent 被授权执行数据库清理任务。由于某个边界条件判断失误,Agent 开始在生产库中执行大范围的 DELETE 操作。传统的监控系统只看 CPU 和内存,对这种"业务逻辑层面"的破坏毫无察觉。
Agent 观测价值:Agent 的每一次 Tool Use(如执行 SQL)都被记录为语义级 Span。观测云的实时告警策略检测到该 Agent 在 1 分钟内连续调用了 50 次高危工具(execute_sql_delete),立即触发了 Webhook 告警,并联动自动化脚本吊销了该 Agent 的数据库权限。事后,通过完整的 Trace 链路,研发团队清晰地复盘了 Agent 是如何一步步推导出错误结论的。

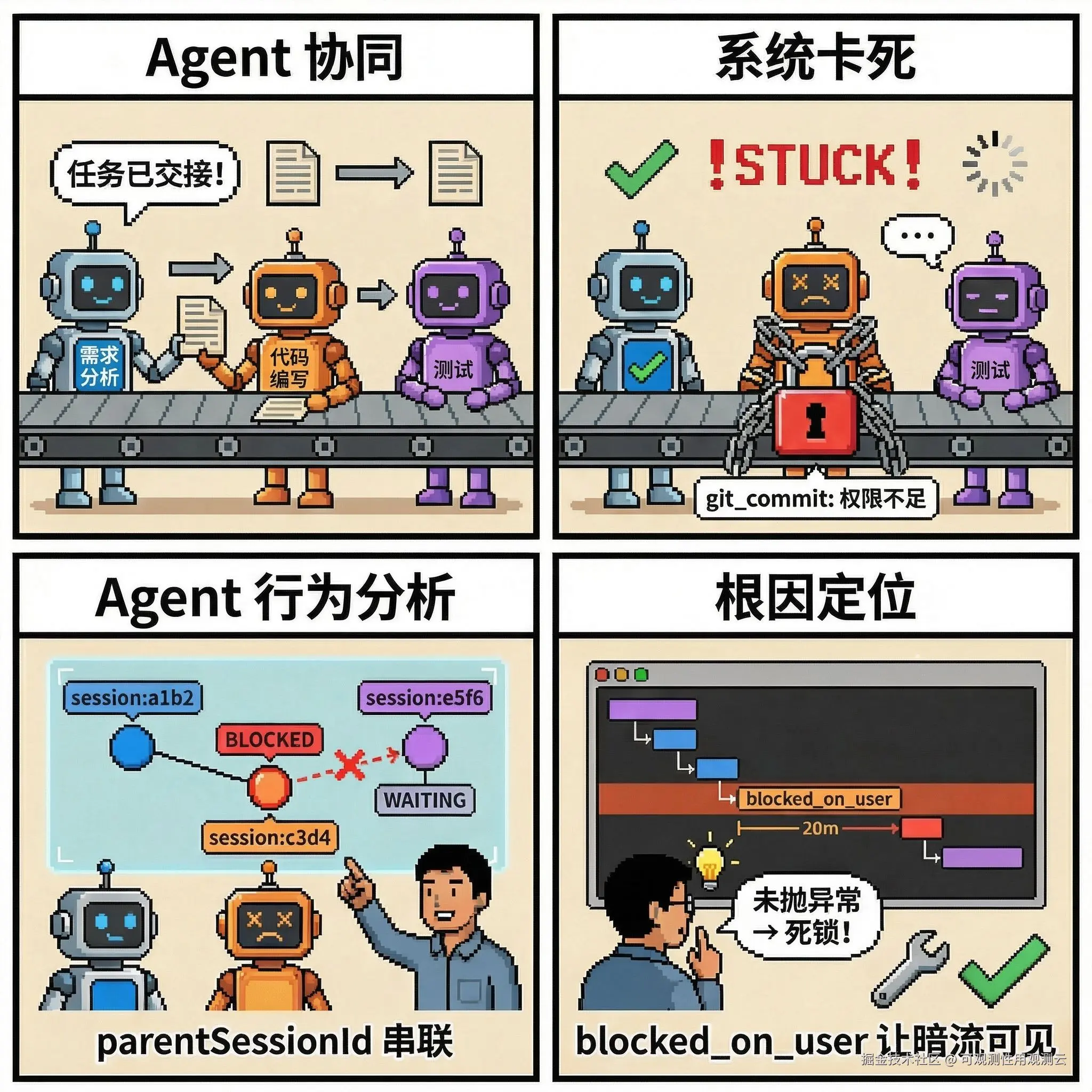
场景三:多 Agent 协同的死锁排查(统一关联键与拓扑分析)
痛点:在复杂的研发场景中,企业部署了"需求分析 Agent"、"代码编写 Agent"和"测试 Agent"组成的 Swarm。最近系统频繁卡死,需求分析 Agent 认为任务已交接,测试 Agent 却在无限等待代码产出。
Agent 观测价值:依靠 parentSessionId 和 agentId 的统一关联,观测云将离散的 Agent 动作串联成了一张完整的服务拓扑图。通过拓扑分析,团队直观地看到:代码编写 Agent 在调用 git_commit 工具时,由于缺少权限被阻塞(对应 Claude Code 中的 tool.blocked_on_user 状态),但它未能正确向上游抛出异常,导致整个 Swarm 陷入死锁。Agent行为分析让这种跨 Agent 的"暗流"变得清晰可见。
场景四:合规审计与越权监测(隐私治理前置)
痛点:金融企业引入了财务分析 Agent,要求其只能访问脱敏后的报表数据。如何向审计部门证明,这个拥有极高自主性的 Agent 没有偷偷读取包含客户隐私的原始数据库?
Agent 观测价值:一旦发现 Agent 尝试调用未在白名单内的 MCP Server(如尝试连接外部网络或访问原始库),系统会立即记录并阻断。这不仅是技术监控,更是满足监管要求的合规底座。
四、趋势:每个进入生产环境的 Agent,都需要行为分析
Claude Code 的泄露给整个行业上了一课。不是关于安全(虽然那也很重要),而是关于复杂自治系统的可治理性。
Claude Code 每天浪费 25 万次 API 调用的故事(autoCompact.ts 中的注释,1279 个会话出现 50 次以上连续失败,最高达 3272 次),本质上是一个缺乏可观测性的故事。修复方案是三行代码------MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3------但发现问题的前提是你能看到这个指标。
当 Agent 从开发者工具走向企业生产系统,这类问题只会更多、更隐蔽、代价更高。
Claude Code 的架构告诉我们,一个生产级 AI Agent 的可观测性代码的复杂度不亚于其核心功能代码。services/analytics/ 和 utils/telemetry/ 两个目录下的设计精度和工程治理水平,说明 Anthropic 把 Agent 行为分析当成了一等公民------三层可观测性架构、语义级 span 模型、统一关联键、隐私治理前置、失败补偿链路(磁盘缓冲 + quadratic backoff + span TTL cleanup),这不是事后补的"日志系统",这是和 Agent 核心逻辑同步设计的基础设施。
但 Claude Code 是自己观测自己。它不需要考虑"别人的 Agent 长什么样"。
观测云要做的是更难的事:让每一个 Agent------不管是白盒的 Claude Code、灰盒的 OpenClaw、还是企业自研的闭箱 Agent------的每一次 interaction、每一个 tool call、每一段 blocked_on_user 的等待,都变成可查询、可关联、可治理的遥测数据。
期待我们把它变成每个 Agent 都能用的基础设施,为每个企业提供开箱即用的 Agent 可观测能力。
参考资料:
- Ars Technica: Entire Claude Code CLI source code leaks
- The Neuron: Anthropic Leaks Claude Code, a Blueprint for AI Coding Agents
- alex000kim: The Claude Code Source Leak
- Odaily: What Exactly Are AI Agents Doing? A Complete Analysis of the 500,000-Line Claude Code Leak
- 此间山林:从 Claude Code 源码学习怎么做 Agent 可观测性(上)(下)
- 观测云产品文档