在分布式系统开发中,Redis作为高性能的键值存储中间件,早已成为缓存、会话存储、消息队列等场景的首选。但随着业务体量增长,单节点Redis的性能瓶颈、单点故障等问题逐渐凸显,于是Redis架构沿着"解决痛点"的路径不断演进------从主从复制到哨兵模式,再到Redis Cluster,每一步都针对性解决了前一架构的核心缺陷。今天就结合实际生产场景,把这几种核心架构的原理、优缺点及适用场景讲明白,尤其吃透面试高频的哈希槽与一致性哈希区别。
一、哨兵模式:主从架构的"自动故障转移"升级
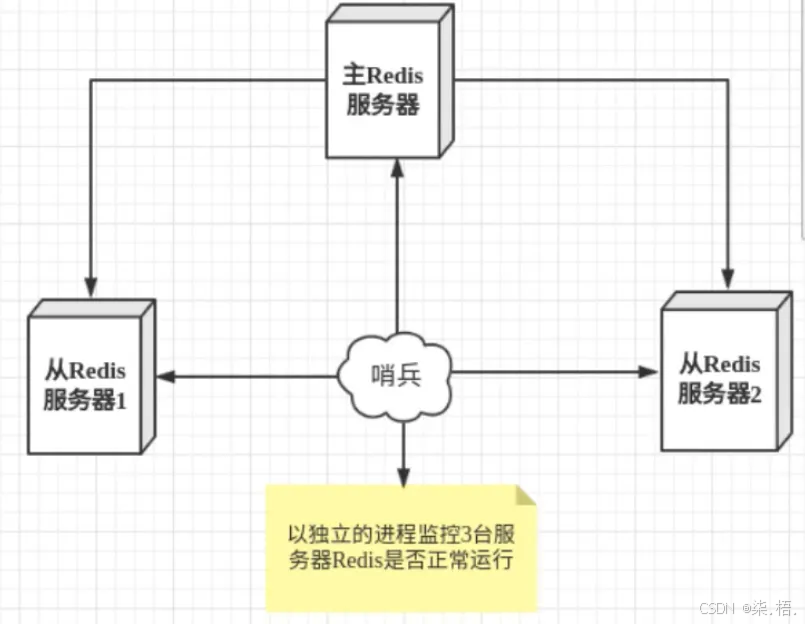
在了解哨兵模式之前,我们先明确一个前提:主从复制解决了Redis的读写分离和数据冗余问题,但当主节点宕机时,需要人工干预切换从节点成为新主,这在生产环境中会造成服务中断,无法满足高可用需求。而哨兵模式,正是在主从复制的基础上,补上了"自动故障转移"这关键一环。
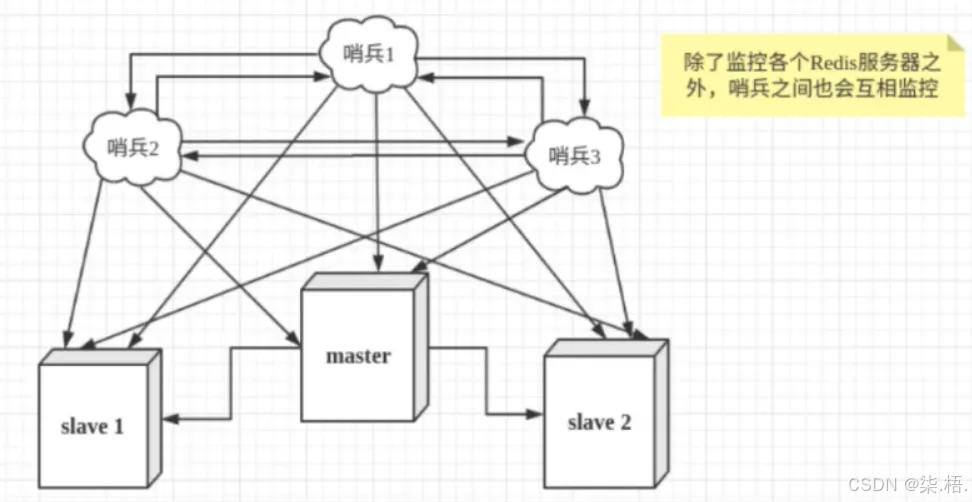
哨兵(Sentinel)本身是独立运行的进程,核心职责就像Redis集群的"守护者",持续监控所有Redis节点的健康状态。当它检测到主节点宕机时,会自动从从节点中选举出一个新的主节点,完成配置更新,整个过程无需人工介入,极大提升了Redis服务的可用性。
两个核心概念:主观下线与客观下线
哨兵判断主节点是否可用,并非单一节点说了算,而是通过"双重判断"避免误判,这也是生产环境中部署多哨兵的核心原因:
-
主观下线:单个哨兵检测到主节点没有响应(超过配置的超时时间),就会认为该主节点"主观下线"(主观是因为仅代表单个哨兵的判断,可能存在网络波动等误判情况)。
-
客观下线:当多数哨兵(通常超过半数)都检测到该主节点不可用,就会达成共识,判定主节点"客观下线",此时才会触发后续的自动故障转移流程。
这里需要注意:实际生产中一定会部署多哨兵集群(比如3个哨兵),目的是避免哨兵本身出现单点故障------如果只有一个哨兵,一旦它宕机,就无法实现自动故障转移,相当于失去了"守护者"。
哨兵模式的优缺点与适用场景
优势很明确:完全继承了主从复制的所有优点(读写分离、数据冗余),同时新增了自动故障转移能力,实现了Redis的高可用,部署难度也相对较低。
但缺点也同样突出:哨兵模式本质上还是"单主多从"架构,所有写操作依然集中在一个主节点上,随着业务增长,写压力会越来越大;同时,它无法实现在线扩容,当数据量达到单节点上限时,只能停机扩容,灵活性不足。
因此,哨兵模式更适合中大型业务场景------要求服务高可用,但数据量不算特别大、写压力也未达到单主节点瓶颈,比如中型电商的缓存服务、用户会话存储等。
二、Redis Cluster:解决写压力与扩容的分布式方案
哨兵模式解决了高可用,但没能解决"写压力集中"和"无法在线扩容"这两个核心痛点。当业务进入大型分布式阶段,数据量激增、并发写请求暴涨,单主架构已经无法支撑,此时Redis Cluster(Redis集群)就成为了生产中的首选方案------它的设计目标,就是彻底解决这两个痛点,实现Redis的分布式部署。
Redis Cluster的三大核心特点
与主从、哨兵架构相比,Redis Cluster的核心差异在于"分布式",主要体现在三个方面:
-
去中心化:集群中没有固定的"主节点"概念,连接任意一个主节点,都能通过集群路由访问到整个集群的所有数据,无需像哨兵模式那样依赖固定主节点,避免了中心节点的瓶颈。
-
多主多从:集群中有多个主节点,每个主节点都可以独立处理写操作,实现了写操作的并行处理,彻底解决了单主架构的写压力集中问题;同时,每个主节点都可以配置从节点,用于数据备份和故障转移------当某个主节点宕机时,其从节点会自动选举为新主,保证服务不中断。
-
分片存储:这是Redis Cluster实现分布式的核心,通过"哈希槽"将数据均匀分配到多个主节点上,避免单节点数据量过大。这里的哈希槽,也是Redis Cluster与其他分布式存储方案的核心区别。
三、面试重点:一致性哈希与哈希槽的区别
提到分布式存储的分片方案,很多人会先想到一致性哈希------这是分布式存储的通用算法,但Redis Cluster并没有采用它,而是选择了自定义的"哈希槽"方案。要吃透Redis Cluster,就必须搞懂这两者的区别,这也是面试中高频考察的知识点。
先搞懂:一致性哈希的原理与痛点
一致性哈希的出现,是为了解决传统哈希取模的致命缺陷:传统哈希取模时,一旦节点增减(比如新增一个Redis节点),所有数据的哈希值都会重新计算,导致所有数据重新映射到不同节点,大量缓存失效,进而引发缓存雪崩,对业务造成致命影响。
一致性哈希的解决方案是:构建一个环形哈希空间(范围0~2^32-1),将数据和节点都通过哈希算法映射到这个环上;数据存储时,顺时针找到环上第一个节点,将数据存储在该节点。这样一来,当节点增减时,只影响该节点相邻的少量数据,大部分数据的映射关系不会改变,避免了大量缓存失效。
但一致性哈希也有不足:当节点数量较少时,容易出现数据倾斜------比如只有2个节点,可能会导致其中一个节点承担大部分数据,无法实现负载均衡。
Redis专属:哈希槽的原理与优势
Redis Cluster没有采用一致性哈希,而是设计了"哈希槽"(Hash Slot)这种专属分片方案,核心逻辑更简单、更高效:
Redis Cluster固定有16384个哈希槽(这个数量是Redis官方经过权衡网络通信、内存占用等因素确定的,既能保证分片均匀,又能降低节点间心跳包的开销),集群中的所有主节点会均分这些槽位(比如3个主节点,就每个节点分配约5461个槽位)。
数据定位的逻辑非常清晰,三步就能完成:
-
通过CRC16算法计算key的哈希值(CRC16是一种简单高效的哈希算法,适合短key的计算);
-
将计算出的哈希值对16384取模,得到对应的哈希槽编号(范围0~16383);
-
找到该哈希槽编号对应的主节点,将数据存储到该节点,读取时也遵循同样的逻辑。
相比一致性哈希,哈希槽的优势更为明显,也是它成为Redis Cluster核心的原因:
-
数据分配均匀:16384个槽位均匀分配给主节点,不会出现一致性哈希的"数据倾斜"问题;
-
扩容缩配便捷:扩容时,只需将部分槽位从现有主节点迁移到新主节点,缩配时同理,无需改动全局数据的映射关系,也不会导致大量缓存失效;
-
查询效率更高:无需像一致性哈希那样遍历环形空间寻找节点,通过哈希槽直接定位主节点,查询速度更快。
四、三大架构对比:找准适合你的场景
梳理完Redis的核心架构,我们用一张清晰的对比,帮大家快速找准不同场景下的选型方案------这也是生产部署和面试中最常遇到的问题:
| 架构类型 | 核心作用 | 优势 | 不足 | 适用场景 |
|---|---|---|---|---|
| 主从复制 | 读写分离、数据冗余 | 部署简单,分担读压力,数据有备份 | 主节点故障需人工切换,无自动高可用,写压力集中 | 中小型、读多写少,对高可用要求不高的场景(如小型系统缓存) |
| 哨兵模式 | 自动故障转移,实现高可用 | 继承主从优点,自动切换主节点,高可用有保障 | 写压力集中,无法在线扩容,数据量受单节点限制 | 中大型、要求高可用,数据量不算特别大的场景(如中型电商缓存) |
| Redis Cluster | 多主并行写、水平扩容,分布式高可用 | 解决写压力和扩容问题,去中心化,负载均衡,高可用 | 部署和维护难度稍高,需理解哈希槽机制 | 大型分布式、海量数据、高并发写,需水平扩容的场景(如大型电商、分布式系统) |
五、总结:Redis架构演进的核心逻辑
最后,我们用一句话梳理Redis架构的演进脉络,帮大家建立完整的知识体系:单节点Redis存在性能和单点故障隐患→主从复制解决读写分离和数据冗余→哨兵模式解决自动故障转移,实现高可用→Redis Cluster解决写压力集中和在线扩容,适配大型分布式场景。
其中,哈希槽是Redis Cluster实现分片的核心,也是Redis与其他分布式存储方案的关键区别;而一致性哈希作为通用的分布式分片算法,了解它与哈希槽的差异,不仅能帮我们更好地理解Redis Cluster,也是面试中的高频考点。