本节内容系统介绍了Apache Spark的核心架构与发展历程。Spark作为统一的大数据处理引擎,基于内存计算模型,具备极高的处理速度与扩展性。其核心组件包括用于结构化数据处理的Spark SQL、实时流计算的Spark Streaming、机器学习库MLlib及图计算框架GraphX,实现了多场景下的统一计算。Spark打破了Hadoop的基准纪录,支持Scala、Python等多种语言,广泛应用于交互式分析、机器学习及实时数据处理等场景,是大数据计算领域的主流技术。
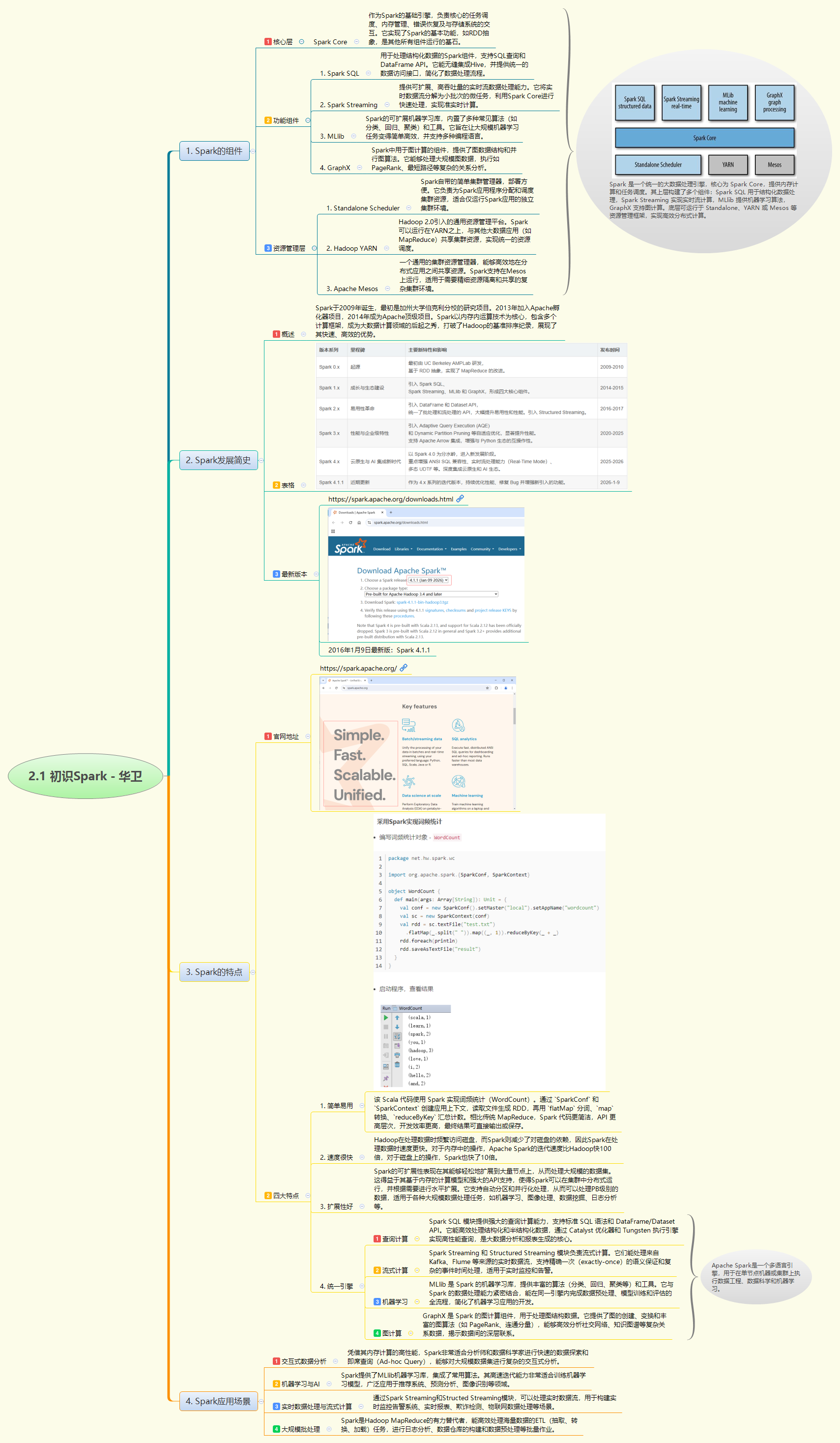
本节内容系统介绍了Apache Spark的核心架构与发展历程。Spark作为统一的大数据处理引擎,基于内存计算模型,具备极高的处理速度与扩展性。其核心组件包括用于结构化数据处理的Spark SQL、实时流计算的Spark Streaming、机器学习库MLlib及图计算框架GraphX,实现了多场景下的统一计算。Spark打破了Hadoop的基准纪录,支持Scala、Python等多种语言,广泛应用于交互式分析、机器学习及实时数据处理等场景,是大数据计算领域的主流技术。