嗨~大家好,这里是春栀怡铃声的博客~
"做你害怕的事,然后发现,不过如此~"
哈喽呀,这篇文章来梳理 常考排序用C语言是如何是实现的。那我们坐稳发车喽!
目录
[1. 变量初始化(摆好牌桌)](#1. 变量初始化(摆好牌桌))
[2. 开始比大小(拉链咬合阶段)](#2. 开始比大小(拉链咬合阶段))
[3. 扫尾工作(把手里剩下的牌全扔桌上)](#3. 扫尾工作(把手里剩下的牌全扔桌上))
[4. 物归原主(将排好的牌拷贝回原数组)](#4. 物归原主(将排好的牌拷贝回原数组))
[1. 准备工作(租借场地)](#1. 准备工作(租借场地))
[2. 最外层循环:控制步长 gap 的翻倍](#2. 最外层循环:控制步长 gap 的翻倍)
[3. 内层循环:在当前 gap 下,将数组横向两两合并](#3. 内层循环:在当前 gap 下,将数组横向两两合并)
[4. 划定两块区域的边界(数学计算)](#4. 划定两块区域的边界(数学计算))
[5. 🚨 非递归的灵魂核心:越界修正机制 🚨](#5. 🚨 非递归的灵魂核心:越界修正机制 🚨)
[6. 拉链式合并(和递归版一模一样)](#6. 拉链式合并(和递归版一模一样))
[7. 及时搬回原数组](#7. 及时搬回原数组)
[8. 步长翻倍,进入下一趟,最后清理战场](#8. 步长翻倍,进入下一趟,最后清理战场)
希尔排序
希尔排序(Shell Sort)的核心哲学是:"先粗调,后微调" 。
它利用了插入排序的一个致命弱点和绝对优点:
-
弱点:面对完全乱序、极端反转的数组,插入排序极慢(接近 O(N^2) )
-
优点:面对**"基本有序"**的数组,插入排序快得飞起(接近 O(N) )
所以,希尔的发明逻辑就是:我先故意把数组按步长(gap)分组,让相隔很远的元素进行比较和交换。这样几次"粗调"下来,整个数组就"基本有序"了,最后再执行一次普通的插入排序(gap=1),瞬间通关!
#include<stdio.h>
#include<stdlib.h>
void ShellSort(int* a, int n)
{
int gap = n; // 初始步长设为数组长度
// 1. 最外层增加一个控制 gap 缩小的循环!
while (gap > 1)
{
gap = gap / 2; // 每次步长减半,最后一次一定为 1
// 2. 遍历每一个分组
for (int j = 0; j < gap; j++)
{
// 3. 在当前分组内进行插入排序
for (int i = j; i < n - gap; i += gap)
{
int end = i;
int tmp = a[end + gap]; //修复:抓取同组的下一个元素
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end]; // 大数往后挪
end -= gap; // 指针往前移
}
else
{
break; // 找到合适位置,停止往前找
}
}
a[end + gap] = tmp; // 将数字放入正确的空位
}
}
}
}快速排序
快速排序的核心------1.在要排序的数组中选定一个目标值(key),左边一个指针(left)负责找比目标值大的,右边一个指针(right)负责找比目标值小的。
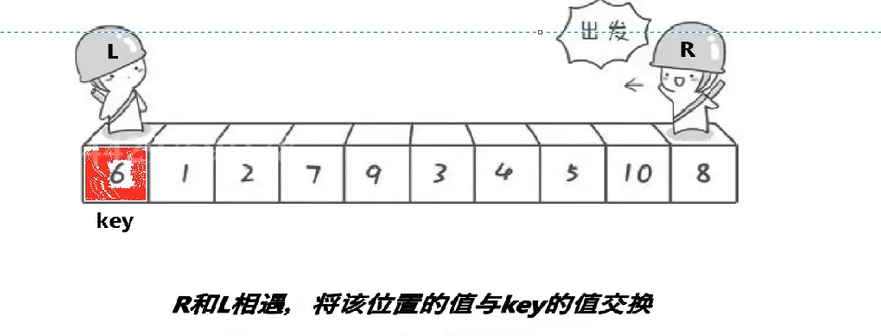
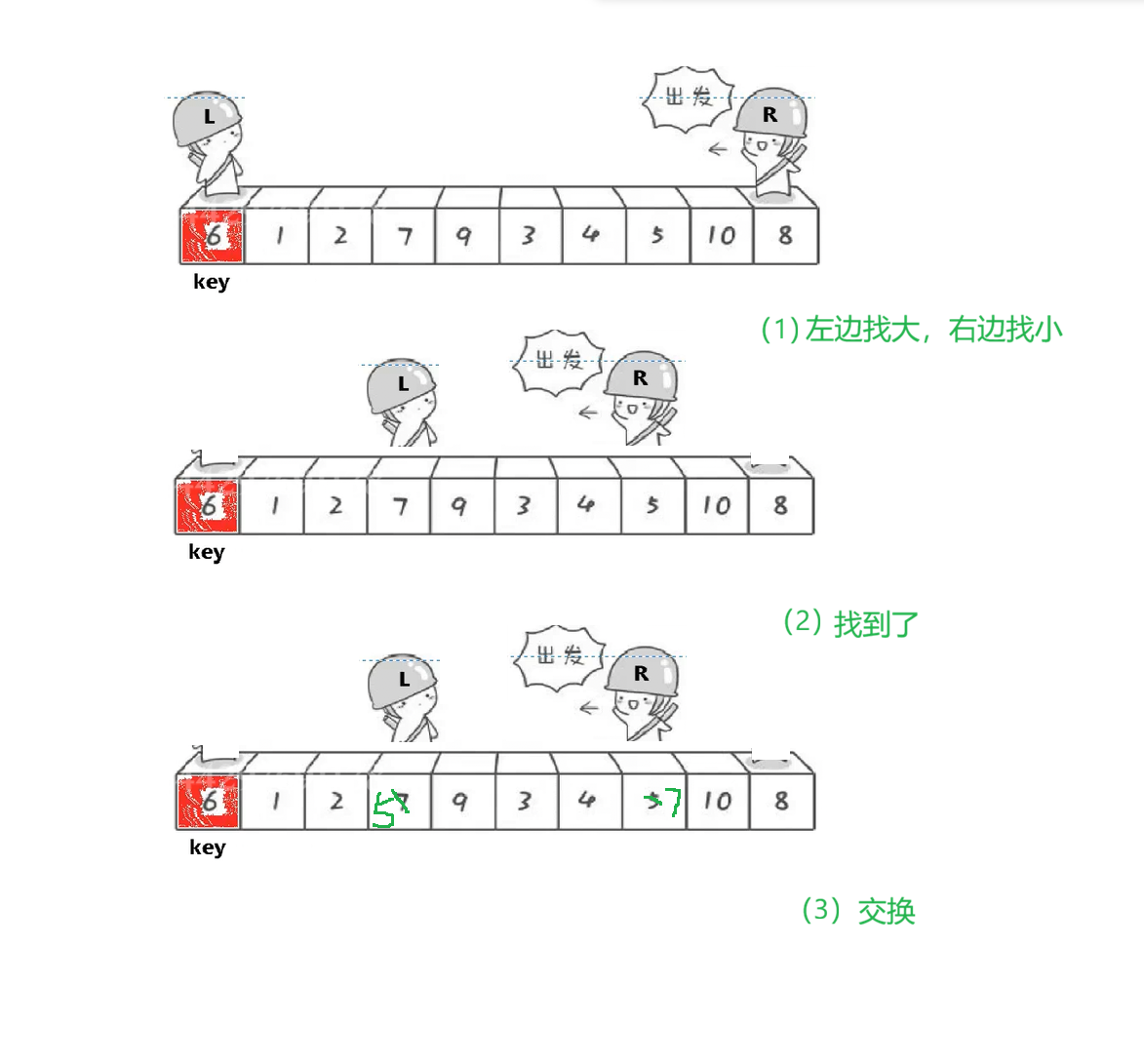
右边指针先走(很重要,下面会解释为什么这样做),2指针都找到时就将左右指针所指的值交换,直到左右指针相遇,将相遇的值与目标值交换,一次排序成功结束。
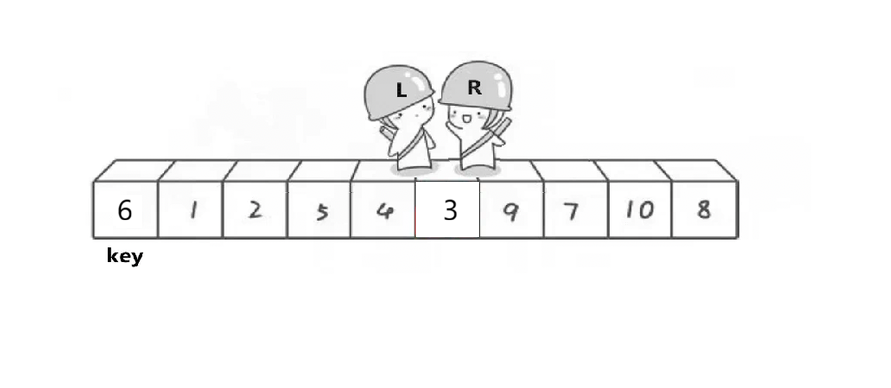
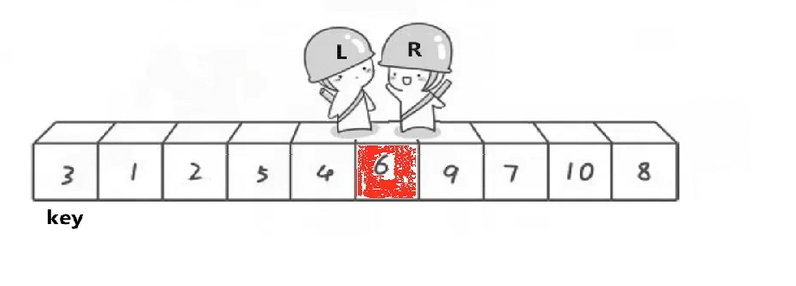
将key再继续指向6
此时目标值(key)的左边都是比目标值小的数,右边都是比目标值大的数,分成了2个区间
下一步就是分别在2个区间中进行第一步的操作,依次递归完成排序
重点
1.为什么相遇的位置一定比key小?为什么规定右指针先走?
1.左指针先碰到右指针,并且右指针先走,说明右指针所在位置比key小,做指针还未找到比key大的值,证明此处相遇的值小于key
2.右指针先碰到左指针,由于是右指针先走,说明左指针现在停的位置是上次交换过后的,左指针找大,右指针找小,交换过后,左指针指向位置小于key
由以上2种情况证明左右指针相遇位置一定小于key,规定右指针先走是为了保障左右指针相遇位置一定小于key
1.递归型
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void Quicksort(int * a,int left,int right)
{
if (left > right) return;
int keyi = left;
int begin = left, end = right;
while (begin < end)
{
while (begin < end && a[begin] < a[keyi]) begin++;
while (begin < end && a[end] > a[keyi]) end--;
Swap(&a[begin], &a[end]);
}
Swap(&a[begin], &a[keyi]);
keyi = begin;
Quicksort(a, left, keyi-1);
Quicksort(a, keyi+1,right);
}Swap函数,交换的是值,需要传入地址来改变值
如果传入的数组不存在,直接返回即可
1.在Quicksort函数中,传入指向数组的指针,左端点,右端点
2.新建2个变量对接左指针,右指针,尽量不改变传入的左端点 右端点
while (begin < end)
{
while (begin < end && abegin < akeyi) begin++;
while (begin < end && aend > akeyi) end--;
Swap(&abegin, &aend);
}
在begin<end的条件下
左指针(begin)找比keyi大的值,右指针(end)找比keyi小的值,同时找到就交换
begin==end ------代表相遇,相遇将 keyi 指向值 与相遇的值交换
然后让keyi 指向 begin和end相遇位置
接着进行递归
注意!
while (begin < end && abegin < akeyi) begin++;
while (begin < end && aend > akeyi) end--;
这2处循环为什么重复写begin<end --为了在进行begin++ 和 end-- 时不越界
2.双指针+递归型
双指针区别于第一种的是 利用双指针代替上一种相对复杂的写法
int PartSort2(int* a, int left, int right)
{
int prev = left, keyi = left, cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
{
prev++;
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}
void Quicksort2(int* a, int left, int right)
{
if (left >= right) return;
int keyi = PartSort2(a, left, right);
Quicksort2(a, left, keyi - 1);
Quicksort2(a, keyi + 1, right);
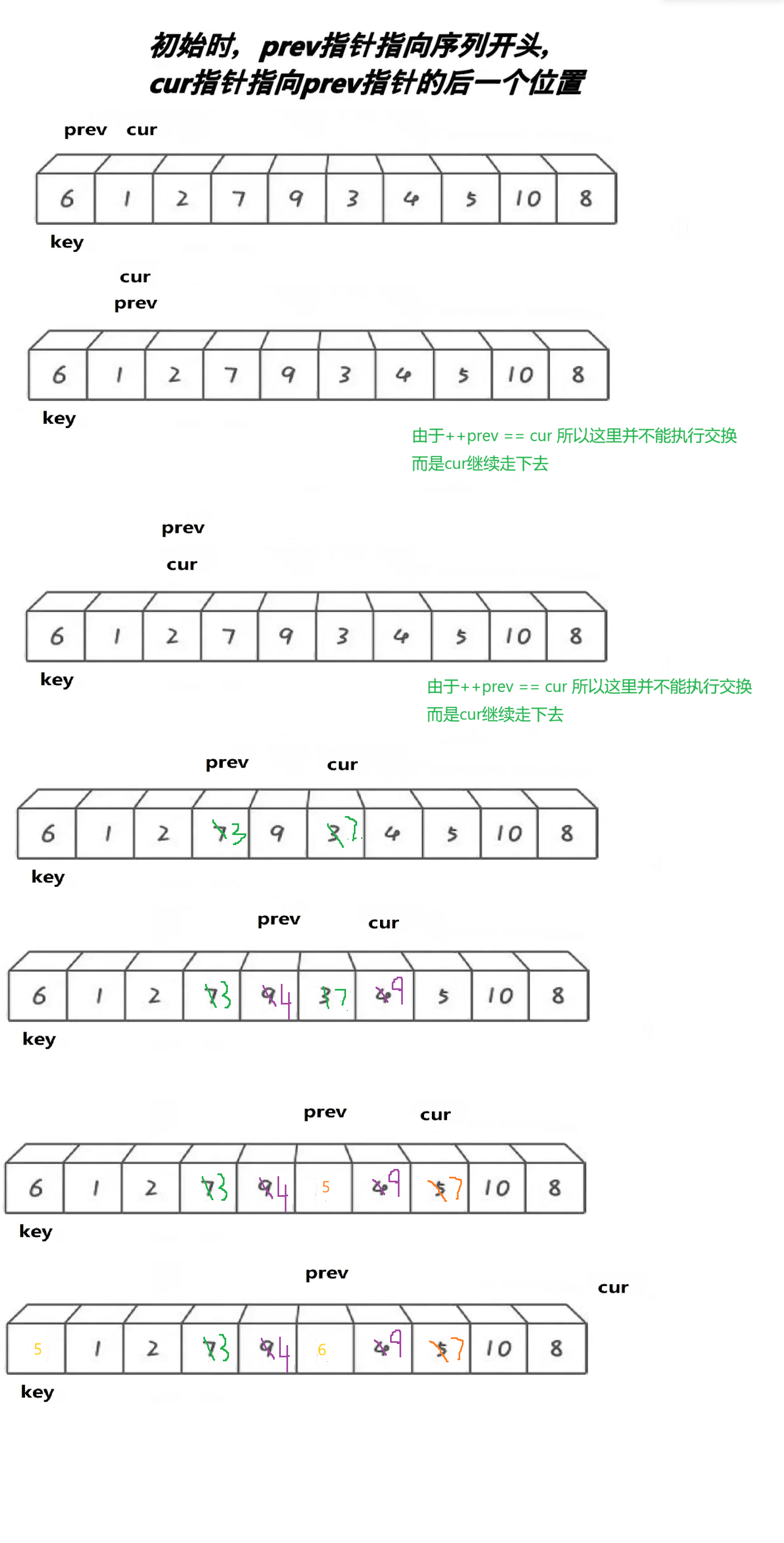
}核心------cur指针找比keyi指向位置小的值
prev在cur指针找到后,走到下一位,交换下一位的prev的值与cur指向的值
(注意!prev走向的下一位不能和cur指向同一位置,此时不可交换,需要cur , prev 都接着走向下一位)
直到 cur 指向位置没有值,此时交换 keyi 和prev 指向位置的值。
这样一次排序就已经写好,在 keyi 左边都是小于 keyi 位置值,右边都是大于 keyi 位置值
进行递归即可
图片演示:
归并排序
如果要用一句话概括归并排序,那就是:"分而治之"。它就像是把一叠乱序的扑克牌不断对半撕开,直到每堆只剩 1 张牌(1张牌自然是有序的),然后再把两小堆合并成一大堆有序的牌,最终拼回完整的一叠。
1.递归型
打工函数 _MergeSort(核心递归逻辑) 这个函数负责具体的"拆分"和"合并"。
老板函数 MergeSort(入口与准备) 这个函数是给用户调用的,它的主要任务是**"租借场地"**(申请内存),然后把活儿派给手下去干。
打扫战场:活干完了,把临时桌面 tmp 还给系统(free),并且把指针置空(tmp = NULL),这是一个防止产生"野指针"的好习惯。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (begin >= end) //不存在这个数组,直接返回
return;
int mid = (end + begin) / 2;
int i = begin;
_MergeSort(a, tmp, begin, mid); //使用递归方式来进行排序
_MergeSort(a, tmp, mid + 1, end); //这里要注意为什么是 [begin,mid] [mid+1,end]
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++]; //取得分为2大类中,更小的那个,
//并且begin1++为了继续进行循环
}
else
{
tmp[i++] = a[begin2++];//
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a+begin,tmp+begin, (end - begin + 1) * sizeof(int)); //拷贝复习
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}图解示意:
配合代码,逐帧拆解"核心动作"
为了看懂那几个复杂的 while 循环,我们把镜头放大到上面图里的"第2次合并":
此时,左边 2, 6 和右边 8 准备合并。
它们在原数组 a 中的下标分别是:左半区 0~1,右半区 2~2。
1. 变量初始化(摆好牌桌)
int begin1 = begin, end1 = mid; // 左半区:begin1 = 0, end1 = 1
int begin2 = mid + 1, end2 = end; // 右半区:begin2 = 2, end2 = 2
int i = begin; // 临时桌面的起点:i = 0脑海中的画面:
-
原数组 a 里的牌: 2, 6, 8, ...
-
左手指着 a0 (数字2),右手指着 a2 (数字8)。
-
临时桌面 tmp 是空的,桌面指针 i=0。
2. 开始比大小(拉链咬合阶段)
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2]) {
tmp[i++] = a[begin1++];
} else {
tmp[i++] = a[begin2++];
}
}
如果左手最上面的牌 abegin1 更小,就把它抽出来,放到桌子 tmpi 上。然后桌面指针 i 往后挪(i++),左手剩下的牌的指针 begin1 也往后挪(begin1++)。
否则(右手牌更小或一样大),就把右手的牌放到桌子上,右手指针 begin2++,桌面指针 i++。
【第 1 轮循环】:
-
比较 a0(数字2) 和 a2(数字8)。
-
2 < 8,左手牌更小!
-
动作:把 2 放到 tmp0。
-
指针移动:i 变成 1,begin1 变成 1。
-
现状:tmp = 2, _, _
【第 2 轮循环】:
-
比较 a1(数字6) 和 a2(数字8)。
-
6 < 8,还是左手牌更小!
-
动作:把 6 放到 tmp1。
-
指针移动:i 变成 2,begin1 变成 2。
-
现状:tmp = 2, 6, _
【触发退出条件】:
-
此时 begin1 变成了 2,而 end1 是 1。begin1 > end1 了!
-
左手的牌已经出完了!while 循环结束。
3. 扫尾工作(把手里剩下的牌全扔桌上)
while (begin1 <= end1) { tmp[i++] = a[begin1++]; }
while (begin2 <= end2) { tmp[i++] = a[begin2++]; }-
左手的牌出完了,第一个 while 进不去。
-
右手还剩下一张 a2(数字8)。进入第二个 while。
-
动作:把 8 直接放到 tmp2 中。
-
现状:tmp = 2, 6, 8 。合并完美结束!
4. 物归原主(将排好的牌拷贝回原数组)
memcpy(a+begin, tmp+begin, (end - begin + 1) * sizeof(int));-
为什么要有这一步?
因为所有的排序都在 tmp 这个临时内存里完成的,原数组 a 里的这一段还是一团糟(可能是 6, 2, 8)。
-
动作:
把 tmp 下标 0~2 的内容 2, 6, 8,原封不动地覆盖到 a 数组的 0~2 位置上。
-
结果:
原数组的左半部分彻底有序了!接下来,代码会去处理右半部分的 5, 3, 1,最后再把它们"终极合并"。
-
数据搬运阶段
memcpy(a+begin, tmp+begin, (end - begin + 1) * sizeof(int)); //拷贝复习
} -
把排好的牌还回去 :前面所有的合并操作,都是在"临时桌面" tmp 上完成的。现在区间 begin, end 已经在 tmp 里变得完美有序了,我们需要把它们原封不动地复制回原数组 a 的对应位置。
-
memcpy 参数拆解:
-
目标地址:a + begin (从原数组的 begin 位置开始覆盖)
-
源地址:tmp + begin (从临时数组的 begin 位置开始拿)
-
拷贝的字节数:(end - begin + 1) 是这个区间的数字个数,乘以 sizeof(int) (每个数字占用的字节数,通常是 4 字节),算出来就是总共要拷贝多少字节。
-
Q:为什么要分为begin , mid mid+1 ,end ?
A:必须这样分,是为了做到不重不漏 。mid 是向下取整的。比如 begin=0, end=1,mid=0。
左边变成 0, 0(遇到上面 begin>=end 停止),右边变成 1, 1(也停止)。
如果写成 begin, mid-1 和 mid, end,在 begin=0, end=1 时,右边会变成 0, 1,导致无限死循环! 所以 begin, mid 和 mid+1, end 是防止死循环的绝对标准写法。
2.循环实现型
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//非递归形式的归并排序
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap<n)
{
for (int i = 0; i < n; i += 2*gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + gap * 2-1;
if (begin2 >= n) break;//
if (end2 >= n) end2 = n - 1;//
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if(a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}配合代码,逐句拆解
非递归版没有了递归调用的开销,它的骨架是两个 while/for 循环嵌套。
1. 准备工作(租借场地)
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL) {
perror("malloc fail");
return;
}- 和递归版一样,我们必须申请一个大小为 n 的临时数组 tmp 作为"合并专用工作台"。如果申请失败就退出。
2. 最外层循环:控制步长 gap 的翻倍
int gap = 1;
while (gap < n)
{-
int gap = 1;:初始设定每个小块的长度为 1。
-
while (gap < n):只要小块的长度还没有覆盖整个数组,就继续干活。比如长度 6 的数组,gap 会经历 1 -> 2 -> 4,当 gap 变成 8 时,循环结束。
3. 内层循环:在当前 gap 下,将数组横向两两合并
for (int i = 0; i < n; i += 2*gap)
{-
i += 2*gap 是关键!因为我们是两组两组地合并。
-
当 gap = 1 时,i 每次跳 2 步(处理第 0,1 个,然后第 2,3 个...)
-
当 gap = 2 时,i 每次跳 4 步(处理 03,然后 47...)
-
-
i 代表着每一对"准备合并的两个小块"的总起点。
4. 划定两块区域的边界(数学计算)
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + gap * 2 - 1;-
第一组(左手牌):从 i 开始,长度为 gap。所以终点是 i + gap - 1。
-
第二组(右手牌):紧挨着第一组,从 i + gap 开始,长度也是 gap。终点是 i + gap*2 - 1。
5. 🚨 非递归的灵魂核心:越界修正机制 🚨
为什么非递归难写?因为如果是 6 个元素,gap=4 时,程序傻傻地去算边界,会发现 end2 算出来是 7,但数组最大下标只有 5,这就越界了!所以必须打补丁。
if (begin2 >= n) break;-
情况A(右半区完全不存在):
-
对应图里的第 2 趟,最后剩下 1, 3 时,i=4。此时左半区是 4~5。算出来的右半区起点 begin2 是 6。
-
可是数组总共只有 0~5 啊!说明右手根本没有牌。
-
对策:既然右手没牌,左手这副牌 1, 3 就不需要合并了,直接 break 跳出 for 循环,把它留在原数组 a 里就行。
if (end2 >= n) end2 = n - 1;
-
-
情况B(右半区存在,但不够 gap 个):
-
对应图里的第 3 趟,gap=4, i=0。左半区 2,5,6,8 是 0~3。右半区 1,3 算出来的起点是 4,终点是 7(end2=7)。
-
可是数组只有 0~5。说明右手有牌,但是牌不够 4 张,只有 2 张。
-
对策 :有几张就合几张!强制把右手的终点 end2 修正为数组的最后一个元素下标 n-1(即 5)。这样右半区就变成了合理的 4~5。
-
6. 拉链式合并(和递归版一模一样)
int j = i;
while (begin1 <= end1 && begin2 <= end2) {
if(a[begin1] < a[begin2]) {
tmp[j++] = a[begin1++];
} else {
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1) { tmp[j++] = a[begin1++]; }
while (begin2 <= end2) { tmp[j++] = a[begin2++]; }- 这段逻辑没有任何变化。就是比较左右两边的牌,谁小谁就先放到工作台 tmp 上。最后把手里剩下的牌全甩上去。
7. 及时搬回原数组
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}-
关键点 :这句 memcpy 是写在 for 循环里面的!
-
意思是:合并好一对,就马上搬回去一对。
-
搬运的起点是 i,总共搬运的长度是 end2 - i + 1。(因为 end2 已经被修正过,所以这里绝对不会越界拷贝垃圾数据)。
8. 步长翻倍,进入下一趟,最后清理战场
gap *= 2;
}
free(tmp);
tmp = NULL;
}-
当前 gap 所有的对子都合并完了,gap 乘 2,开始下一轮更长区间的合并。
-
循环结束后,数组完美有序,释放工作台 tmp 的内存,防止内存泄漏。
记住它的核心三步曲:
-
控制 gap 翻倍
-
每次跳 2*gap 去找两堆牌
-
右半边没牌就休息(break),右半边牌不够就修正(end2 = n-1)。