hello~ 很高兴见到大家! 这次带来的是Linux系统中关于线程这部分的一些知识点,如果对你有所帮助的话,可否留下你宝贵的三连呢?
个 人 主 页 : 默|笙

文章目录
- 一、线程
-
- [1.1 线程介绍](#1.1 线程介绍)
- [1.2 线程原理](#1.2 线程原理)
- 二、分页式存储管理
-
- [2.1 物理内存的管理](#2.1 物理内存的管理)
- [2.2 页表](#2.2 页表)
- [三、进程 vs 线程](#三、进程 vs 线程)
一、线程
1.1 线程介绍
- 什么是线程?什么是进程?进程就是内核数据结构 + 程序的代码与数据,这里的内核数据结构包含 PCB(task_struct)、管理虚拟地址空间的 mm_struct 以及对应的页表相关结构。
- 进程是承担系统资源分配的基本实体,而线程是进程内部的执行分支,也是 CPU 调度和执行的基本单位。
1.2 线程原理
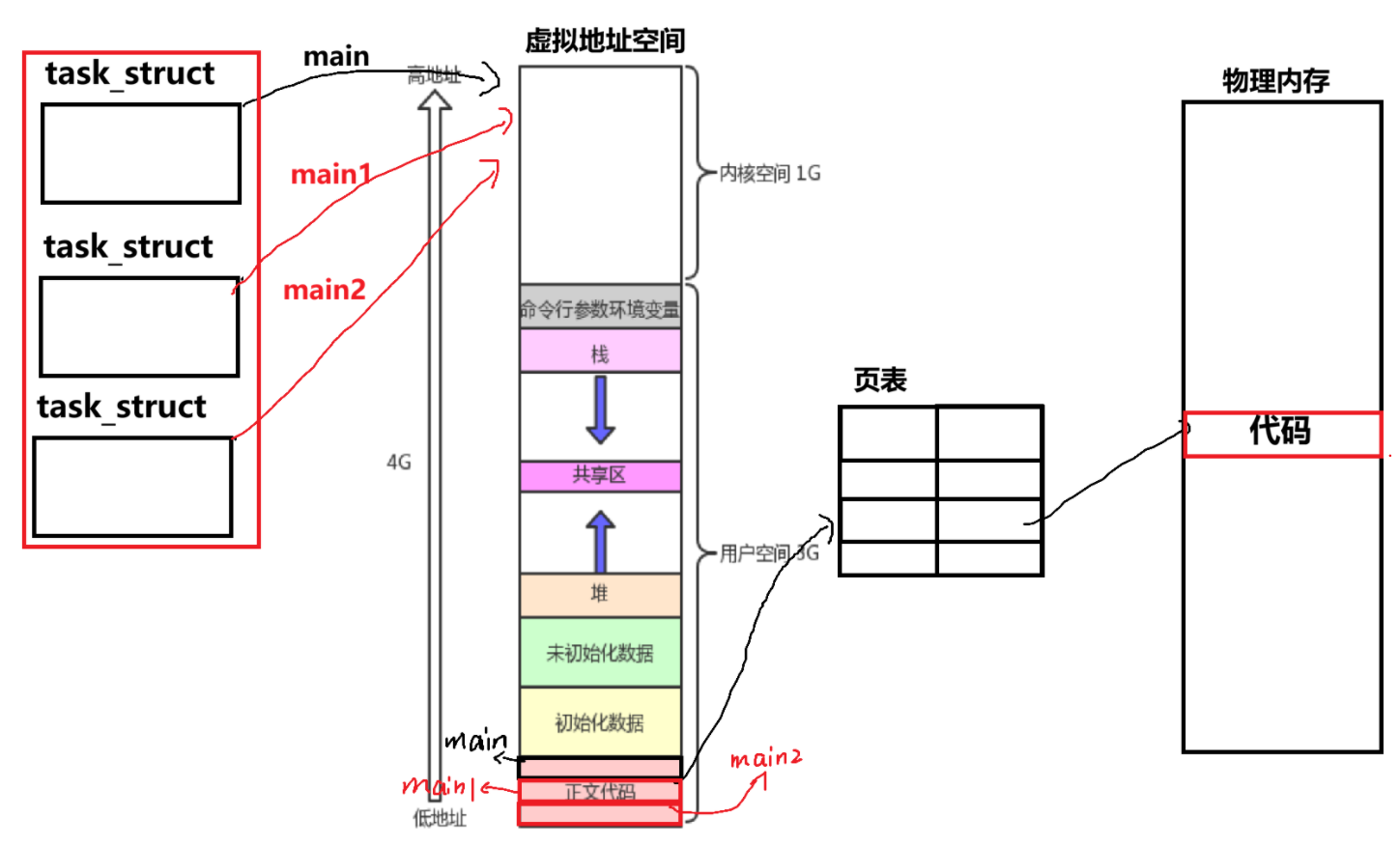
- 多线程就像是将代码分为了多份,有多个执行流,每个线程执行不同段的代码,每一个线程就是一个执行流。
- 所以进程内部会存在一个或多个执行流,我们之前所学的进程,是内部只有一个线程的进程。一个进程 = 一个或多个线程 + 虚拟地址空间 + 页表 + 代码数据,这一整套才是进程 。所以在创建进程的时候就要申请一大堆资源,这也是为什么说进程是承担分配系统资源的基本实体的原因。而创建线程在 Linux 里面就是多创建一个 task_struct 对对应的执行流进行管理。
Windows 系统下面是为线程特地创建了一个结构体叫做 TCB,而 Linux 是复用了 PCB 的结构,避免重新设计一整套针对线程的管理算法与逻辑。所以在 Linux 系统里面,所谓的线程其实应该叫做轻量级进程才对。在 CPU 的眼里,也就没有进程和线程一说,只有一个个的执行流。
- 在 Linux 系统中:执行流 = 轻量级进程。进程 = 一个或多个轻量级进程 + 虚拟地址空间、页表、代码数据等其他资源。
- 可以打个比方:进程就好比一整个家庭,而线程就是家庭里的具体成员 ------ 爸爸、妈妈、爷爷、奶奶和我。我们五个人是独立的个体,每天各自处理不同的事情,但做的所有事都有一个共同目的:支撑和维持这个家庭正常运转。

- 可以使用 ps -aL 命令来查看系统里面的轻量级进程。可以使用系统接口 pthread_create 来创造线程。
-a :显示当前终端下所有用户的进程,把普通用户的执行进程都列出来。
-L :显示 轻量级进程(LWP) 信息,也就是线程信息。带上这个选项后,会额外展示线程 ID(LWP)、进程内线程总数(NLWP)等字段,让我们能看到一个进程内部有多少个线程。
- 测试代码:
cpp
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
void* threadRun()
{
while (1)
{
printf("new thread is running, pid: %d\n", getpid());
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, threadRun, NULL);
while (1)
{
printf("main thread is running,pid: %d\n", getpid());
sleep(1);
}
return 0;
}
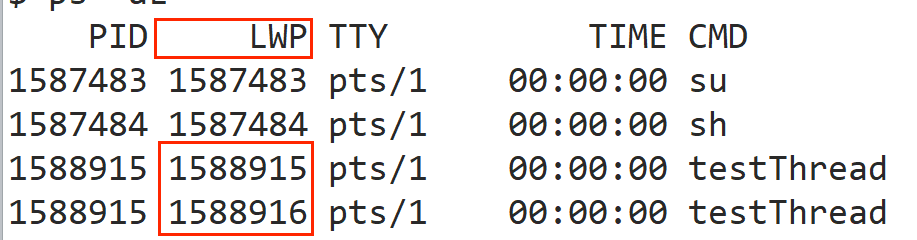
- 可以看到,这两个执行流的 pid 是相同的,说明它们属于同一个进程,而 LWP 不同,因为 LWP 是 Linux 内核中线程的唯一标识,是 CPU 调度的基本单位。操作系统通过 LWP 来调度不同的线程,其中编号小的是主线程。
二、分页式存储管理
2.1 物理内存的管理
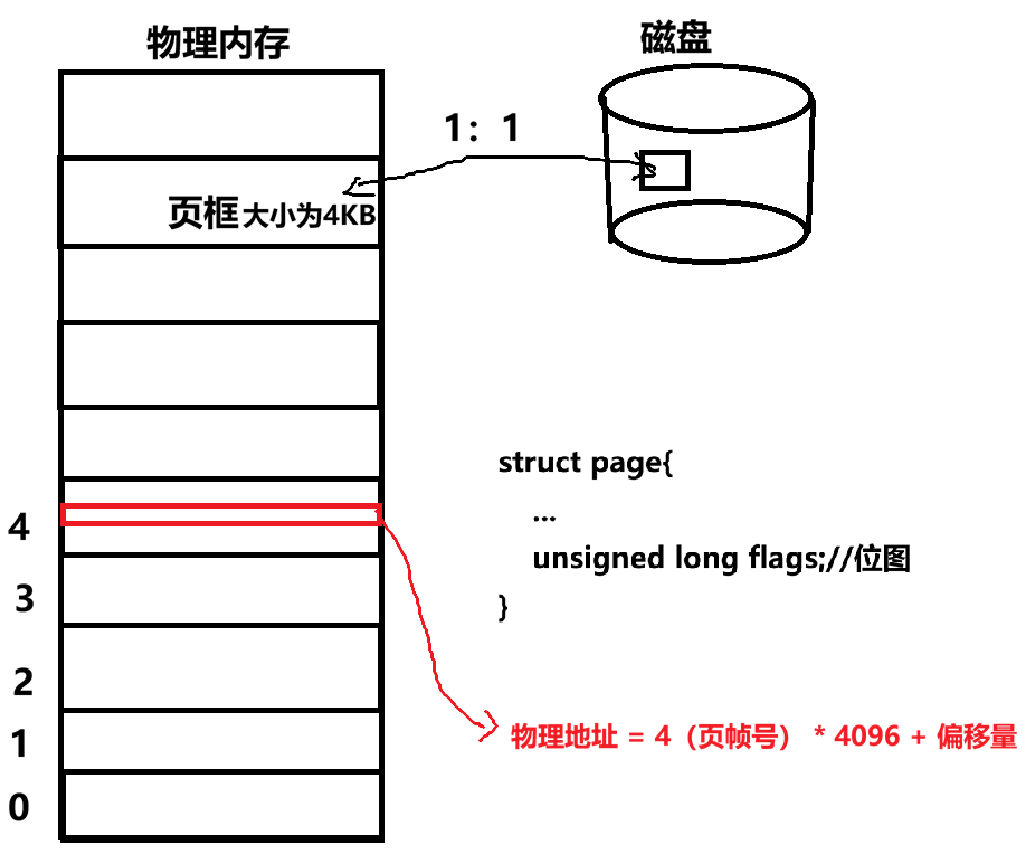
- 物理内存会被操作系统划分为一个个固定大小的页框(也叫物理页帧),在 x86 等常见架构下(比如windows/Linux),其默认大小为4KB。这一设定决定了虚拟内存与磁盘之间进行数据换入、换出的基本单位是 4KB(文件在磁盘上的存储基本单位为磁盘块 / 簇,并非内存分页的 4KB)。
- 假设物理内存容量为 4GB,那么该物理内存中总共包含的页框数量为:4GB ÷ 4KB =1048576 个。面对数量如此庞大的页框,操作系统必须对其进行高效管理;而操作系统管理硬件资源的核心思路,正是先描述,再组织。内核用来描述单个物理页框的核心数据结构就是 struct page,介绍一些它内部的成员变量:
- flags:它内部包含一个 flags(位图) 成员变量,本质是以比特位形式记录页框的各类状态(例如页框是否空闲、属于用户进程还是内核、是否为脏页、是否被锁定等),内核通过操作这些标志位,实现对物理页框的状态管理与控制。
- _mapcount:表示该物理页被页表项映射的次数,记录有多少个页表指向这个页(每一个进程都有自己的页表)。当该计数变为 0 时,说明此页当前没有被任何进程使用,内核就可以将其标记为空闲,在后续内存分配中重新分配使用。页表接下来会讲到。
- virtual:用于记录该物理页对应的内核虚拟地址。
- 用来整合这些 struct page 结构体的数据结构是一个全局数组,在 Linux 内核中通常称为 mem_map,即 struct page mem_map1048576;。每一个物理页框都有一个专属编号,本质就是数组的下标,这个专属编号叫做页帧号 PFN 。将页帧号乘以页大小 4096,就可以直接算出该页框在物理内存中的起始物理地址。
- 若要定位到页框内部某个字节的具体位置,只需先通过页帧号找到对应物理页框的起始物理地址,再加上该字节在页内的偏移量,即可得到最终的物理内存地址。而任意一个页框内的地址都可以直接找到它所处的 page 的属性,只需要将自己的物理地址右移 12 位(即除以 4096)即可得到对应的页帧号。
- 对 2 的整数次幂进行乘除运算,本质上等价于对二进制数进行左移或右移操作。
2.2 页表
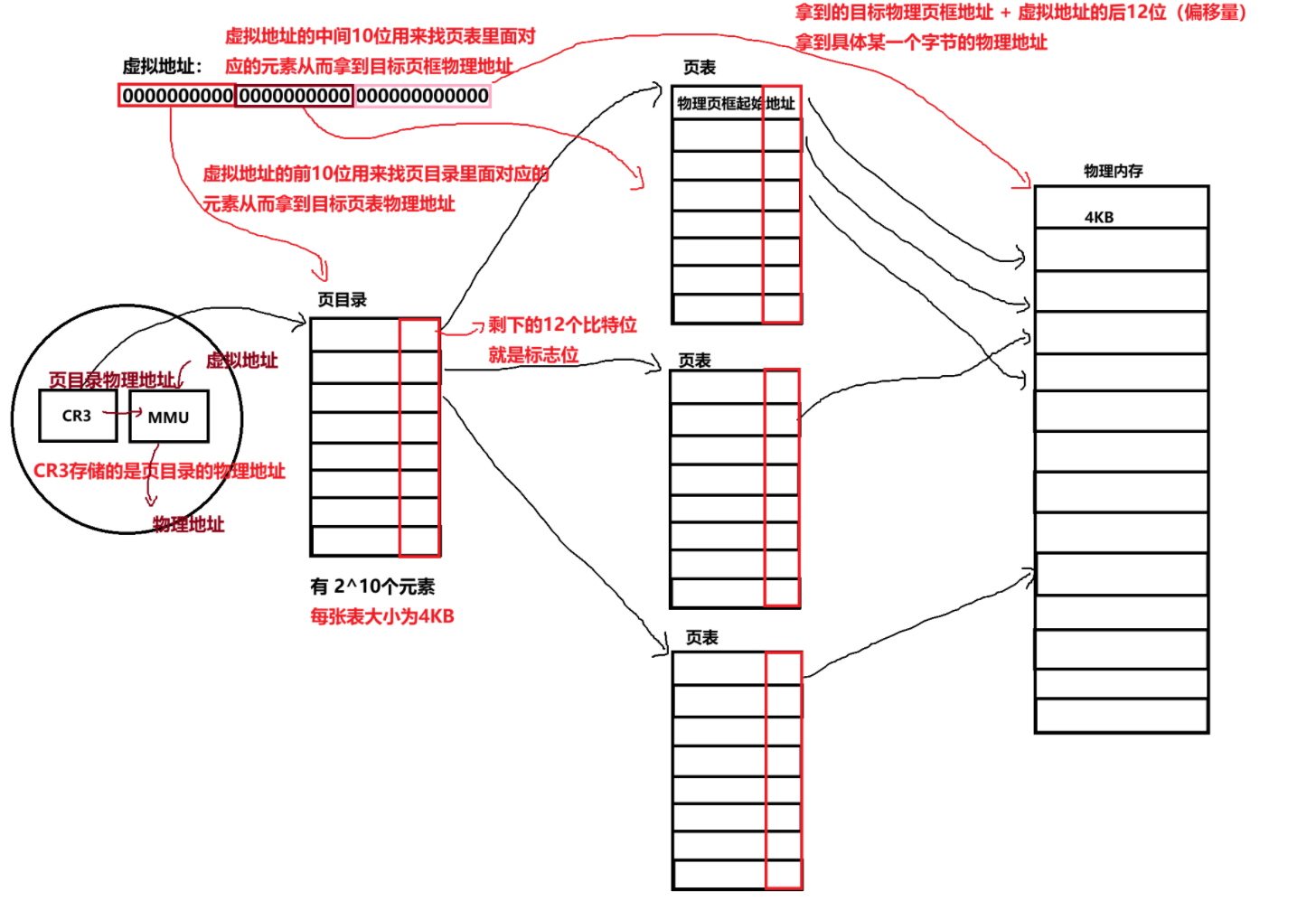
页目录和页表
-
页表采用二级分页结构,第一级是页目录表,页目录表中存放的是对应二级页表的物理页框起始地址;第二级就是普通页表,页表项中存放最终物理页框的地址。无论是页目录表还是普通页表,大小都为 4KB,与物理页框大小一致,因此一张表恰好占用一个页框。也就是说,只要知道这个页框的起始地址,就等价于得到了对应页目录或页表的物理地址。
-
页目录表和页表的本质,都可以看作是元素个数为 2¹⁰(即 1024)的无符号整型数组。
2¹⁰ × 4B = 4096B = 4KB,这也正是每张页目录表和页表的大小。
-
页目录项中存储的是对应页表的物理地址,而页表项中存储的是最终物理页框的起始地址,注意这里指向的是物理页框,而非普通内存字节地址。
为什么会用到多级页表?这是因为单级页表不仅对连续物理内存要求很高,而且会造成极大的内存浪费 。在 32 位系统下,虚拟地址共有 2³² 种取值,如果采用单级页表,就需要对应 2²⁰个页表项来完成地址映射。即便按 4KB 页面大小计算,一个进程的单级页表就需要占用 4MB 连续物理内存;而程序的虚拟地址空间往往是稀疏使用的,大部分区域并未实际使用,单级页表依然要为整个地址空间分配完整内存。如果每个进程都如此,内存会被大量无效页表占据,总不能让页表本身就把宝贵的物理空间给占满吧。当然这也是把双刃剑,依靠多级页表节省了空间,但也降低了查询效率。
- 所以一个进程的页表理论上最多占用 1 个页目录表 + 1024 个页表 = 1025 个页框,总大小为 1025 × 4KB ≈ 4MB。但单个进程不可能占用全部虚拟地址空间,因此实际页表占用的内存远小于 4MB;再加上操作系统采用懒加载(缺页时才建立映射),实际存在的页表项会更少。
两级页表之间的地址转换
-
一个虚拟地址共 32 位,操作系统会将其划分为三部分进行地址翻译:第一部分是高 10 位,用于在页目录表中索引,找到对应的目标页表;第二部分是中间 10 位,用于在对应页表中索引,找到最终的物理页框起始地址;第三部分是低 12 位,表示目标字节在物理页框内的偏移量。用查找到的物理页框起始地址加上页内偏移量,即可得到该字节对应的物理地址。32 位刚好被完整拆分:10 位 + 10 位 + 12 位。其中 10 位可以索引页目录、页表里 2¹⁰=1024 个任意表项,12 位可以覆盖 4096 字节,正好对应一个 4KB 页框的大小。
-
发生写时拷贝时,并不是只复制被修改的单个字节,而是以整个物理页框为单位进行拷贝。程序加载内存同样以页框为单位,往往会多加载相邻部分的数据和代码,这正是利用了局部性原理:当前执行某一行代码时,其附近的代码和数据有极大概率会被紧接着访问,提前将这些内容加载到内存中,可以大幅减少缺页异常,提升运行效率。
-
那么页表如何存储权限等信息呢?靠的就是标志位。页目录项中存储的是对应页表的物理地址,页表项中存储的是最终物理页框的起始地址,它们本质上存储的都是物理页框的起始地址。一个页框按 4KB 对齐,起始地址低 12 位恒为 0,因此完整地址并不需要 32 位,只需要用高 20 位保存页帧号即可,通过页帧号左移 12 位就能还原出物理页框的起始地址。空闲出来的低 12 位,就可以用作标志位,用来标识页面是否存在、读写权限、用户 / 内核权限、是否脏页、是否缓存等控制信息。
-
将虚拟地址转换为物理地址的操作,是由 CPU 内部集成的硬件单元 MMU(内存管理单元) 完成的。之所以不交给软件实现,是因为地址转换的调用频率极高,如果用软件处理会严重降低运行效率;而地址转换的逻辑固定、流程统一,非常适合交给专用硬件电路直接执行。
-
在 MMU 地址翻译的流程中,还有一个用于提升转换效率的硬件缓存结构,叫做快表 TLB。它的核心作用是把近期使用过的虚拟地址与其对应的物理地址缓存起来。每次进行虚拟地址转换时,MMU 会先在 TLB 中查找;如果命中,就可以直接得到物理地址,省去查询内存页表的开销;只有当 TLB 未命中时,才会按照多级页表的流程去内存中逐级查找。
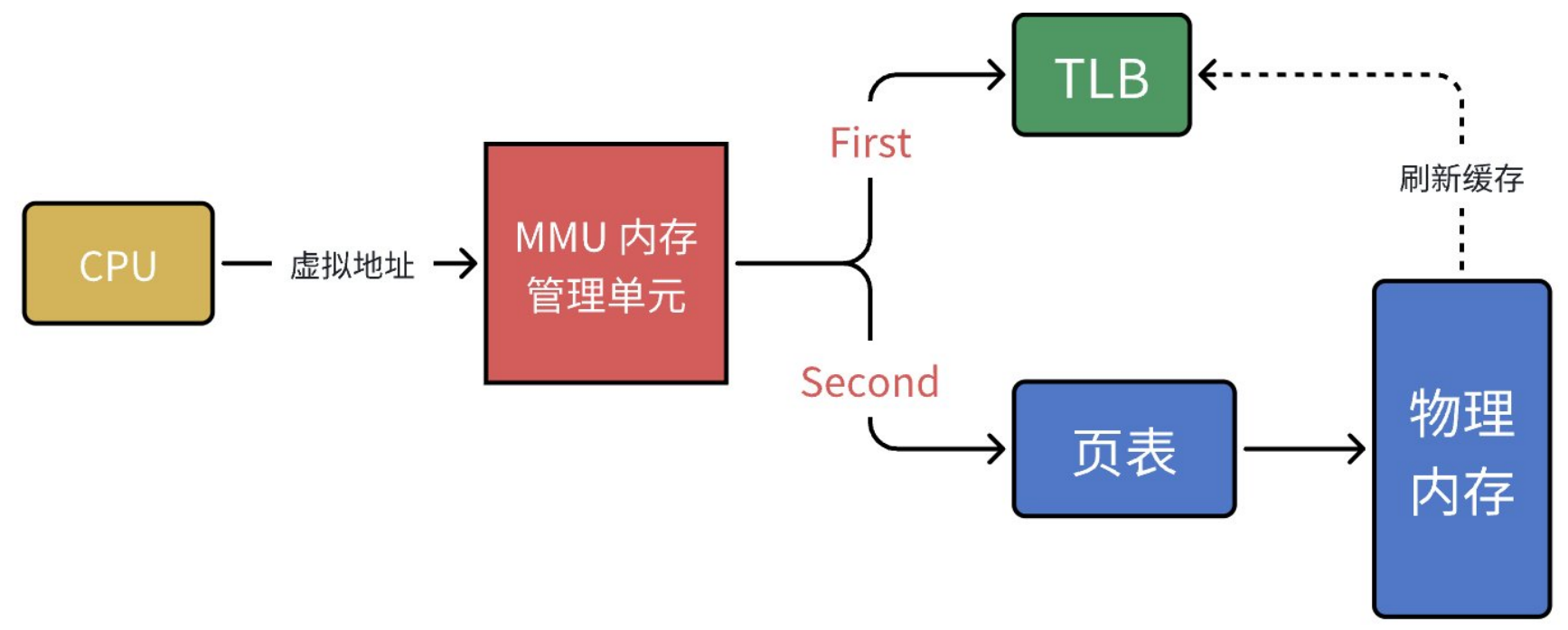
- CPU 内部有一个名为 CR3 的控制寄存器,它专门用于存放当前进程页目录的物理地址。之所以必须存放物理地址而非虚拟地址,核心原因在于:地址翻译工作本身是由 MMU 完成的,MMU 必须先从 CR3 中获取页目录地址,才能开始进行虚拟地址到物理地址的转换。如果 CR3 中存放的是页目录的虚拟地址,那么 MMU 想要使用它,就必须先对这个虚拟地址再做一次翻译,而翻译又依赖于页目录,这就陷入了典型的先有鸡还是先有蛋的死循环,地址翻译流程将永远无法启动。
缺页异常
- 如果在 TLB 和页表里都没有找到对应的物理页,就会发生缺页异常。它是一种由硬件触发、可由软件逻辑纠正的异常,并非程序执行错误。
- 发生缺页时,CPU 无法获取数据会暂停执行,进而触发缺页中断,进程从用户态切换为内核态,再由内核的中断处理程序处理缺页。
- CPU 内部还有一个名为 CR2 的控制寄存器,当 CPU 触发页错误异常(如缺页异常 )时,这个寄存器会自动保存触发异常的虚拟地址,该地址通常就是导致程序出现段错误、非法内存访问乃至程序崩溃的关键地址。
- 申请内存的本质,本质上就是为指定的虚拟地址,在对应的页表项中填写好映射的物理页框起始地址。更准确地说:我们平时调用 malloc/new 申请内存时,通常只是先分配虚拟地址空间、建立页表结构,并不会立刻分配物理内存;只有当程序真正访问这块虚拟地址、触发缺页异常时,操作系统才会分配物理页框,并把物理地址写入页表项,完成最终的地址映射。
- 页表本质是进程看到内存资源的窗口,拥有的虚拟地址越多,那么能映射的物理地址也就越多,划分区域分配资源,其实就是划分虚拟地址。而让不同的 PCB(轻量级进程 / LWP)去执行代码的不同部分,就是让它们执行不同的函数,访问各自对应的虚拟地址。
- main 函数是单线程程序的唯一入口,而多线程的本质,就是一个进程内存在多个独立的执行入口(线程入口函数)。
三、进程 vs 线程
3.1 线程加深了解

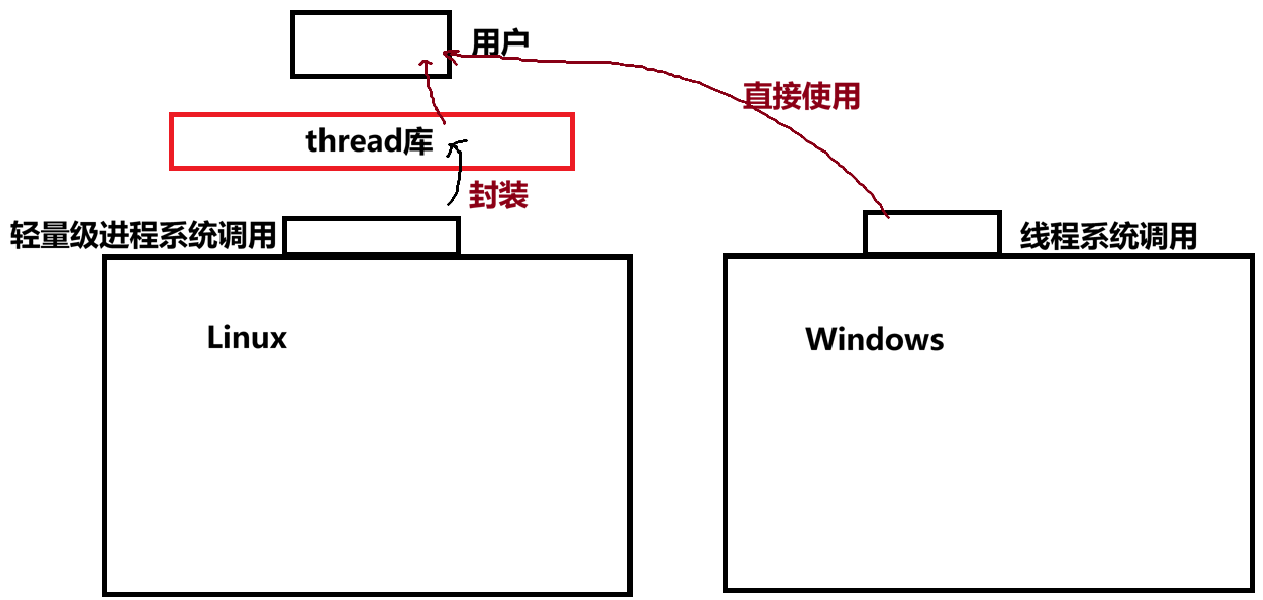
- 对于 Linux 系统,内核层面不存在传统意义上的 "线程" 实体,只实现了轻量级进程(LWP),因此内核仅提供操作轻量级进程的系统调用,如 clone()。
- 与 Windows 不同,Linux 内核没有专门的 TCB(线程控制块)结构体,而是复用 task_struct(进程控制块 PCB)来统一管理进程与轻量级进程。
- 但用户层只认知 "线程" 这一抽象概念,因此为了让用户以线程的方式使用轻量级进程,Linux 提供了 lpthread 库,它里面的函数是对内核轻量级进程接口的封装,如pthread_create。
- fork 其实就是对 clone 的封装,它会创建新进程,还会拷贝页表和建立独立的虚拟地址空间。除此之外,还有一个函数叫 vfork,它也是对 clone 函数的封装,只不过它只会创建 task_struct,不会拷贝页表和虚拟地址空间,父子进程临时共享同一地址空间。它们两个创建的都是进程,都有自己的pid。clone 函数的 flags 参数就是代表是否复制虚拟地址空间、页表等资源。
3.2 资源的共享与独占
- 进程之间相互独立,而线程共享所属进程的地址空间与各类资源。Linux线程在进程内部运行,本质就是在进程的地址空间内运行。
- 进程是资源分配的最小单位,线程是 CPU 调度的最小单位。线程虽然共享进程的大部分数据,但也拥有自身的私有数据,即线程独有资源。
- 这部分私有数据包括线程 ID、线程的寄存器集合(硬件上下文)------ 系统进行线程切换调度时,这些上下文会保存在 task_struct 中;此外栈也是线程私有的,不同线程创建临时变量、构建函数栈帧都需要使用各自独立的栈空间。
3.3 线程的优缺点
优点
-
创建、销毁、切换开销极低:创建一个新线程的代价远小于创建新进程,因为线程只需创建 task_struct,而进程还需要申请并复制大量独立资源。
-
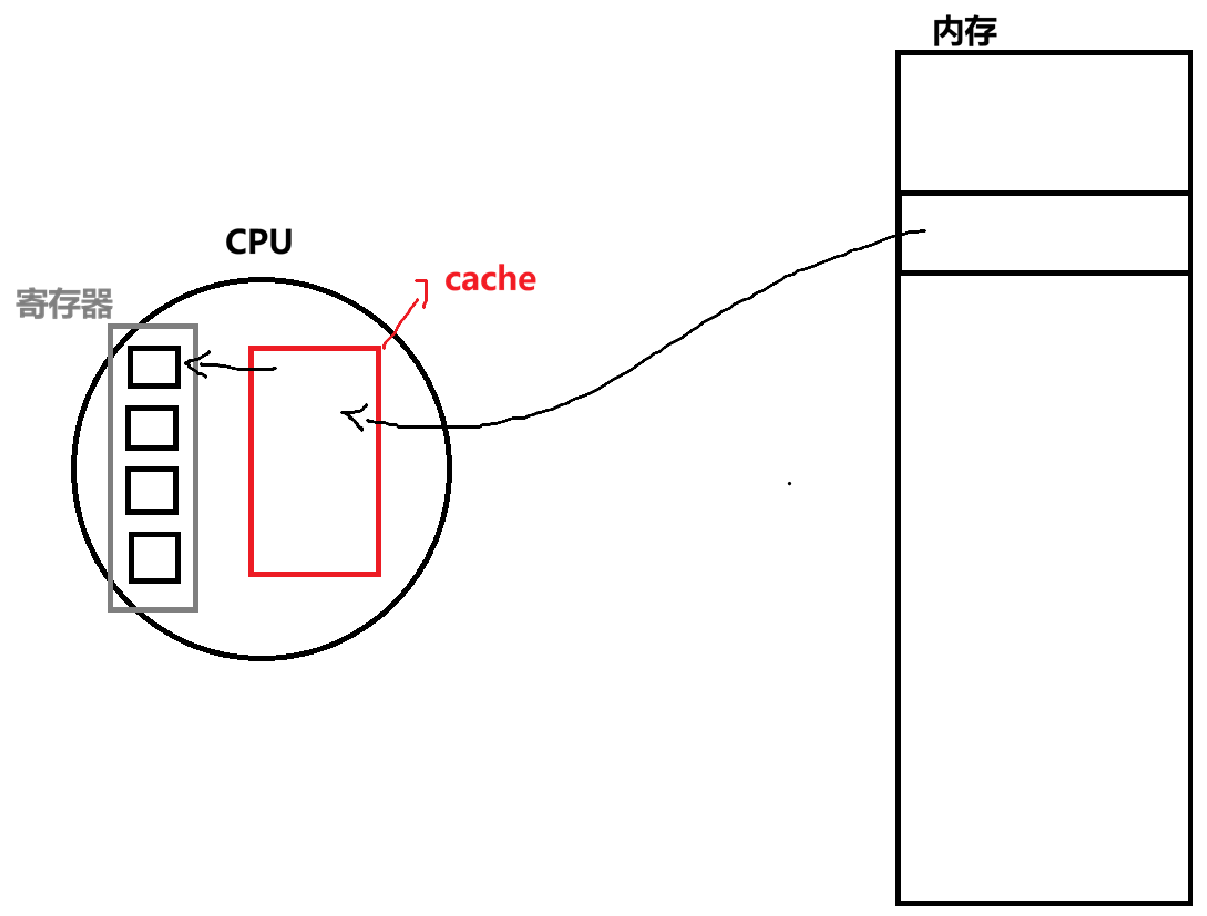
线程切换的开销远小于进程切换,一方面是无需切换进程级上下文(共享同一地址空间,CR3 中的页表地址不变,TLB 也不用刷新),另一方面是硬件高速缓存 cache 可以大部分复用,避免重新缓存数据 。
-
我们知道 CPU 访问内存时效率较低,又由于局部性原理,为了提高效率通常会从内存中读取一块连续的代码和数据到 cache 中缓存。CPU 需要时直接从 cache 读取,远比从内存读取快得多。线程切换时不需要清空 cache,而进程切换会因地址空间变化导致 cache 失效、需要重新加载数据,因此效率会慢很多。
-
线程间通信简单高效:共享进程的虚拟地址空间、全局变量、堆、文件描述符等资源,无需管道、消息队列等 IPC 机制,直接读写共享数据即可。
-
充分利用多核 CPU,并发能力强:同一进程内多个线程可并行运行在不同核心,提升程序执行效率。
缺点
- 缺乏进程级的隔离性:线程共享地址空间,一个线程异常崩溃(段错误、除零等),会导致整个进程所有线程全部终止。
- 存在线程安全问题:同一进程内的线程共享虚拟地址空间与各类资源,可直接互相访问共享数据,若未合理同步,极易出现数据竞争、结果错乱等问题,资源安全性无法保证,需通过互斥锁、原子操作等同步机制保障安全。
今天的分享就到此结束啦,如果对读者朋友们有所帮助的话,可否留下宝贵的三连呢~~
让我们共同努力, 一起走下去!