在日常的后端开发和架构设计中,跨系统获取数据是一个基础需求。比如,订单系统需要读取用户系统的会员等级,或者 BI 报表系统需要汇总各个业务线的流水。
面对"把 A 系统的数据给 B 系统用"这个需求,业界通常有三种实现路径:ETL 定时跑批、基于日志的 CDC(变更数据捕获)数据同步,以及暴露实时 API 接口。
不同的方案在延迟、系统侵入性、开发维护成本上差异很大。本文将对这三种方案的原理和适用边界进行梳理。

一、 ETL 定时跑批
ETL(Extract, Transform, Load)是最传统的数据流转方式。通常利用定时任务(如 Crontab、Airflow),在业务低谷期(如凌晨),通过脚本或同步工具(如 DataX、Kettle)将源数据库的数据批量抽取、清洗后写入目标库(如数仓 Hive、ClickHouse 或统计用 MySQL)。
技术特点:
-
吞吐量极大: 适合 GB/TB 级别的数据搬运。
-
计算后置: 可以在 Transform 阶段做很复杂的多表 Join、聚合计算。
-
对源库有集中压力: 跑批时会对源库产生较大的 Select 压力,甚至占用全表锁,因此只能在凌晨执行。
核心痛点:
-
高延迟: 数据通常是 T+1(隔天生效),最快也是小时级,无法满足实时业务需求。
-
维护成本高: 随着业务增长,跑批任务之间容易产生复杂的依赖(DAG),一旦某个上游节点失败,会导致下游级联报错,需要人工介入重跑。
适用场景:
- 离线 BI 报表、T+1 财务对账、跨系统历史数据归档。
二、 基于 CDC 的数据同步
近几年,基于日志的 CDC(Change Data Capture)同步越来越普及。它的核心原理是伪装成源数据库的从节点(Slave),实时读取并解析数据库的事务日志(如 MySQL 的 Binlog、PostgreSQL 的 WAL),将数据变更(Insert/Update/Delete)解析为消息,推送到 Kafka 等消息队列,再由下游消费方写入目标库或搜索引擎。典型的开源工具包括 Canal、Debezium、Flink CDC。
技术特点:
-
低延迟: 延迟通常在秒级或毫秒级。
-
对源库侵入性极小: 相比于频繁的 Select 查询,解析 Binlog 对源库本身的 QPS/TPS 影响可以忽略不计。
-
解耦: 源系统不需要关心谁在消费数据,下游系统可以随时接入 Kafka 消费同一份数据。
核心痛点:
-
基础设施复杂度高: 引入了 ZooKeeper、Kafka、同步组件等一系列中间件,运维排障门槛较高。
-
Schema 演进处理麻烦: 如果源库执行了 DDL(如修改列名、删除字段),同步链路容易中断,需要较强的容错和数据格式转换机制。
-
数据一致性保障难: 在网络抖动或组件重启时,需要处理消息的 Exactly-Once(精确一次)语义,防止下游数据重复或乱序。
适用场景:
- 异构存储同步(如 MySQL 同步到 ES 做全文搜索、同步到 Redis 做缓存刷新)、构建实时数仓、微服务间的异步事件通知。
三、 实时 API 调用
当目标系统需要源系统的某条具体数据,且要求绝对实时时,最直接的做法是源系统提供一个 HTTP (RESTful) 或 RPC (如 gRPC、Dubbo) 接口。目标系统在处理业务逻辑时,同步发起网络请求获取数据。
技术特点:
-
绝对实时: 拿到的永远是源系统当前时刻的最准确数据。
-
数据不冗余: 坚持了"单一数据源(Single Source of Truth)"原则,业务数据不用在多个系统间复制,避免了状态不一致。
核心痛点:
-
系统强耦合: A 系统强依赖 B 系统的接口可用性。B 系统如果宕机或网络超时,A 系统的业务也会直接被阻塞。
-
放大源库压力: 如果目标系统并发量大,所有的 API 请求最终都会透传为源数据库的 Select 语句,容易把源库的连接池打满。
-
重复的开发工作: 每增加一个取数需求,往往需要源系统的后端开发人员编写对应的 Entity、Mapper 和 Controller 代码,联调成本高。
适用场景:
- 交易链路中的强一致性校验(如:下单前实时查询商品库存、支付前实时校验用户余额)、前端大屏直接拉取特定指标。
四、 选型总结
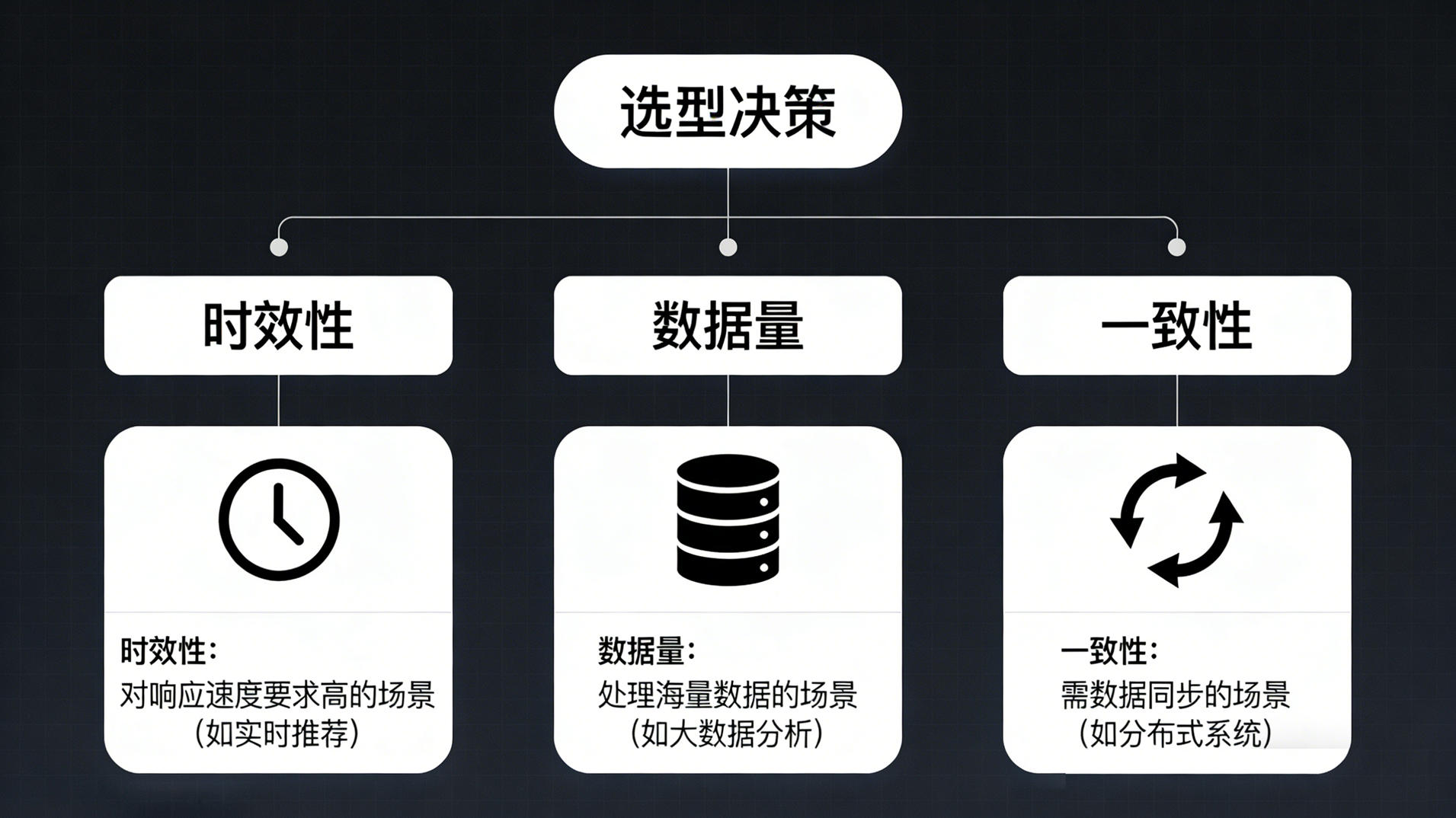
在实际的架构设计中,没有一种方案可以包打天下。可以参考以下判断逻辑:
-
看时效性要求: 如果业务能接受昨天的数据,首选 ETL 跑批,架构最简单。
-
看数据量与读写比: 如果需要同步几张大表用于复杂的检索或分析,且需要准实时,选择 CDC 同步 到专用存储(如 ES/ClickHouse)。
-
看一致性与频次: 如果只需要单条或少量数据的精准状态,且逻辑简单,直接走 API 调用。
在微服务架构下,大量跨部门的轻量级数据共享需求实际上落在了 API 调用 上。然而,传统手写 API 的模式正在成为后端研发效能的瓶颈。如何在保证数据库安全的前提下,更高效地暴露和管理底层数据接口,是下一阶段架构演进需要重点解决的问题。