前言:最近在学习 Spring AI,发现网上关于 Spring AI 结合 RAG(检索增强生成)的中文资料比较少,而且很多都是理论介绍。经过几天的实践,我终于成功搭建了一个完整的 RAG 问答系统。本文将分享我的学习过程和代码实现,希望能帮助到正在学习 Spring AI 的 Java 开发者。
目录[什么是 Spring AI?](#什么是 Spring AI?)
[什么是 RAG?](#什么是 RAG?)
[首先获取阿里云 API Key](#首先获取阿里云 API Key)
[创建 Spring Boot 项目](#创建 Spring Boot 项目)
[pom.xml 关键依赖](#pom.xml 关键依赖)
[RAG 服务核心](#RAG 服务核心)
[REST 控制器](#REST 控制器)
[什么是 Prompt 工程?](#什么是 Prompt 工程?)
首先介绍一下概念
什么是 Spring AI?
Spring AI 是 Spring 官方推出的人工智能应用开发框架,旨在为 Java 开发者提供一套简洁、统一的工具,用于将 AI 能力(特别是大语言模型)集成到企业级应用中。
简单来说,它就像是 JDBC 统一了数据库访问一样,为 AI 模型访问提供了统一的抽象层
什么是向量数据库?
向量数据库 是一种专门用于存储、索引和检索向量数据 的数据库。它通过计算向量之间的相似度来实现快速、准确的语义搜索。
向量的本质
向量 是一组数字的数组,代表某个事物的特征。比如:
java// 文本 "Spring AI" 被转换为向量 [0.12, -0.34, 0.56, 0.78, -0.23, ...] // 1536个数字向量相似度示例
java// 文本向量化后 "Spring AI" → [0.12, -0.34, 0.56, ...] "Java框架" → [0.11, -0.33, 0.55, ...] // 相似度高 "苹果手机" → [0.89, 0.45, -0.23, ...] // 相似度低
什么是 RAG?
在开始之前,我们先理解一个概念:RAG(Retrieval-Augmented Generation,检索增强生成)。
传统的 LLM 调用是这样的:
javaString answer = chatClient.prompt(question).call().content();
这里介绍一下LLM概念:
LLM(Large Language Model,大语言模型) 是一种基于深度学习的人工智能模型,经过海量文本数据训练,能够理解和生成人类语言。
通俗的理解就是把 LLM 想象成一个读过全世界所有书籍的人:
📖 阅读了互联网上几乎所有文本(网页、书籍、论文、代码等)
🧠 学会了语言的规律、知识的关联、逻辑的推理
💬 能够理解你的问题,并给出合理的回答
注:也就是市面上常见的AI大模型,本文接下来使用的是阿里云的通义千问大模型
这么做的弊端就是:AI 完全依赖训练数据中的知识,可能出现:
❌ 知识过时(训练数据截止日期之前)
❌ 无法访问私有数据(公司内部文档)
❌ 产生幻觉(编造不存在的信息)
而RAG 的解决方案:
用户问题 → 检索相关知识 → 增强 Prompt → LLM 生成答案简单说:先查资料,再让 AI 基于资料回答。
业务上的流程图:
┌─────────────────────────────────────────────────────────────┐ │ Spring AI + RAG 系统 │ ├─────────────────────────────────────────────────────────────┤ │ │ │ 用户 → REST API → Controller → Service │ │ ↓ │ │ ┌────────────────┐ │ │ │ 1. 向量检索 │ │ │ │ VectorStore │ │ │ └────────────────┘ │ │ ↓ │ │ ┌────────────────┐ │ │ │ 2. 构建上下文 │ │ │ │ Prompt工程 │ │ │ └────────────────┘ │ │ ↓ │ │ ┌────────────────┐ │ │ │ 3. LLM 调用 │ │ │ │ 通义千问 │ │ │ └────────────────┘ │ │ ↓ │ │ 返回答案 │ └─────────────────────────────────────────────────────────────┘
本文接下来将要使用到的技术栈:
组件 技术 说明 框架 Spring Boot 3.5.13 基础框架 AI 框架 Spring AI 1.1.3 AI 应用抽象 向量存储 SimpleVectorStore 内存向量存储(开发用) LLM 阿里云通义千问 DashScope 服务 构建工具 Maven 依赖管理 Java 版本 17 LTS 版本
环境准备:
注:这里注意使用spring-AI框架需要确保JDK版本大于17,springboot版本大于3.x
首先获取阿里云 API Key
访问 阿里云 DashScope 控制台,开通服务并获取 API Key。
创建 Spring Boot 项目
使用 Spring Initializr 创建项目,选择:
Spring Web
Lombok
pom.xml 关键依赖
XML<properties> <java.version>17</java.version> <spring-ai.version>1.1.3</spring-ai.version> <spring-ai-alibaba.version>1.1.2.0</spring-ai-alibaba.version> </properties> <dependencies> <!-- Spring Boot Web --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Spring AI 核心 --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-core</artifactId> </dependency> <!-- 向量存储 --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-vector-store-core</artifactId> </dependency> <!-- 简单向量存储(内存存储) --> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-simple-vector-store</artifactId> </dependency> <!-- 阿里云 DashScope --> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-starter-dashscope</artifactId> </dependency> <!-- Lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-bom</artifactId> <version>${spring-ai.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud.ai</groupId> <artifactId>spring-ai-alibaba-bom</artifactId> <version>${spring-ai-alibaba.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <repositories> <repository> <id>spring-milestones</id> <name>Spring Milestones</name> <url>https://repo.spring.io/milestone</url> </repository> </repositories>application.yml
XMLspring: ai: dashscope: api-key: ${DASHSCOPE_API_KEY} # 阿里云通义千问中的appkey chat: options: model: qwen-turbo temperature: 0.7 max-tokens: 2000 embedding: enabled: true model: text-embedding-v2 vectorstore: type: simple # 使用内存向量存储 server: port: 8989 logging: level: com.smoky.ai: DEBUG
首先需要理解一下怎么调用AI大模型:
大家可以自己调用一下感受一下,本文就不放输出结果了,实际上就是把你的问题通过springai调用通义千问然后生成回答返回,此示例很简单,注意自己的token使用。
要点:感受流式调用和普通调用及主题调用
javapackage com.smoky.ai.springai.controller; import org.springframework.ai.chat.client.ChatClient; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/api/ai") public class AiController { @Autowired private ChatClient chatClient; @GetMapping("/ask") public String ask(@RequestParam String question) { return chatClient.prompt() .system("你是一个专业的Java助手,请用中文回答") .user(question) .call() .content(); } /** * 流式输出示例 * GET /api/ai/stream?message=讲个故事 */ @GetMapping(value = "/stream", produces = "text/plain;charset=UTF-8") public String stream(@RequestParam String message) { StringBuilder result = new StringBuilder(); chatClient.prompt() .user(message) .stream() .content() .subscribe(chunk -> { result.append(chunk); System.out.print(chunk); // 实时输出 }); // 注意:这里需要等待流式输出完成,实际使用中可能需要异步处理 try { Thread.sleep(3000); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } return result.toString(); } /** * 带参数的对话(使用系统提示模板) * GET /api/ai/role-play?role=老师&topic=数学 */ @GetMapping("/role-play") public String rolePlay(@RequestParam String role, @RequestParam String topic) { String systemTemplate = "你是一个{role},请用{role}的身份回答关于{topic}的问题"; // 方法内 return chatClient.prompt() .system(spec -> spec .text(systemTemplate) .param("role", role) .param("topic", topic)) .user("请介绍一下这个主题") .call() .content(); } }
其次我们需要在这个过程中引入向量数据库+RAG的概念,以达到增强检索的目的
注:增强检索不是微调模型,增强检索的意义在于让我们的AI基于向量数据库已经加载的文档及数据来进行回答,从而避免了AI大模型在不知道问题的答案的时候胡乱回答,从而造成幻觉问题,也就是问一答二
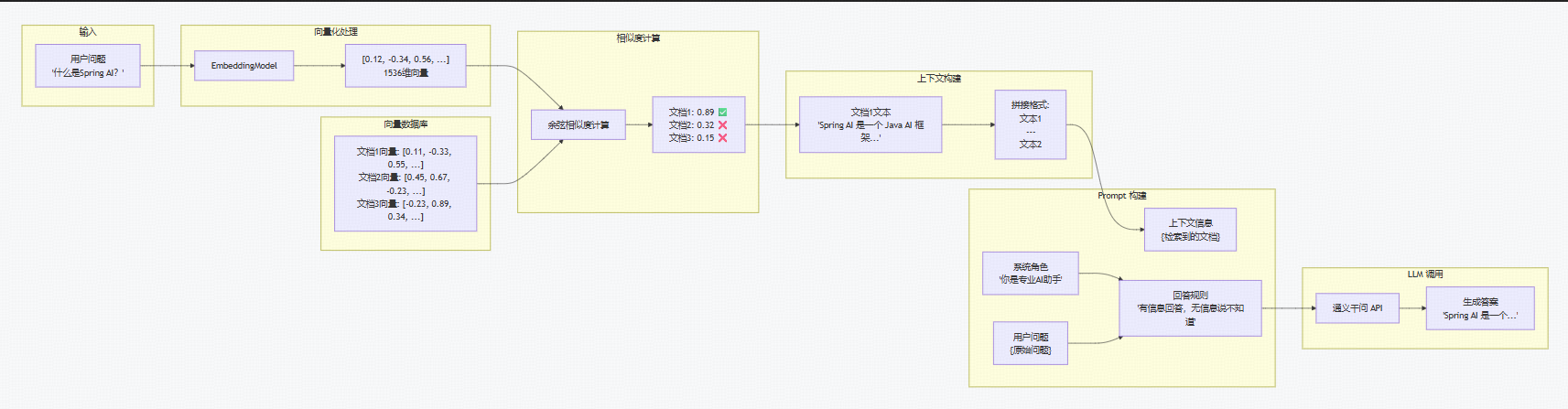
内部数据流转流程图为(需要好好理解一下流程):
接下来是核心代码实现
向量存储配置:
javapackage com.smoky.ai.config; import org.springframework.ai.embedding.EmbeddingModel; import org.springframework.ai.vectorstore.SimpleVectorStore; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class VectorStoreConfig { @Bean public VectorStore vectorStore(EmbeddingModel embeddingModel) { // 使用内存向量存储,开发测试用 return SimpleVectorStore.builder(embeddingModel).build(); } }RAG 服务核心
javapackage com.smoky.ai.service; import lombok.extern.slf4j.Slf4j; import org.springframework.ai.chat.client.ChatClient; import org.springframework.ai.document.Document; import org.springframework.ai.vectorstore.SearchRequest; import org.springframework.ai.vectorstore.VectorStore; import org.springframework.stereotype.Service; import java.util.List; import java.util.Map; import java.util.stream.Collectors; @Slf4j @Service public class RagService { private final VectorStore vectorStore; private final ChatClient chatClient; public RagService(VectorStore vectorStore, ChatClient.Builder chatClientBuilder) { this.vectorStore = vectorStore; this.chatClient = chatClientBuilder.build(); log.info("RagService 初始化完成"); } /** * RAG 问答核心方法 */ public String askQuestion(String question) { log.info("用户问题: {}", question); // 1. 检索相关文档 List<Document> relevantDocs = vectorStore.similaritySearch( SearchRequest.builder() .query(question) .topK(3) .similarityThreshold(0.5) .build() ); // 2. 构建上下文 String context = relevantDocs.stream() .map(Document::getText) .collect(Collectors.joining("\n\n---\n\n")); // 3. 构建 Prompt String prompt = buildPrompt(question, context); // 4. 调用 LLM 生成答案 String answer = chatClient.prompt(prompt).call().content(); return answer; } /** * 添加示例文档 */ public void addDocuments() { log.info("添加示例文档到向量存储..."); List<Document> documents = List.of( new Document("Spring AI 是一个用于构建 AI 应用的 Java 框架,它提供了统一的 API 来集成各种 AI 模型。", Map.of("source", "official", "topic", "spring-ai")), new Document("RAG(检索增强生成)是一种技术,通过从外部知识库检索相关信息来增强大模型的回答能力。", Map.of("source", "tutorial", "topic", "rag")), new Document("向量数据库用于存储和检索文档的向量表示,Chroma、Pinecone、Weaviate 等都是常用的向量数据库。", Map.of("source", "article", "topic", "vector-db")), new Document("DashScope 是阿里云提供的模型服务平台,支持通义千问等多种大语言模型和向量化模型。", Map.of("source", "official", "topic", "dashscope")), new Document("Spring AI 1.1.x 版本支持多种向量数据库,包括 Chroma、Pinecone、Qdrant 等。", Map.of("source", "docs", "topic", "spring-ai")) ); vectorStore.add(documents); log.info("成功添加 {} 个文档", documents.size()); } /** * 语义搜索 */ public List<Document> search(String query, int topK) { SearchRequest searchRequest = SearchRequest.builder() .query(query) .topK(topK) .similarityThreshold(0.5) .build(); return vectorStore.similaritySearch(searchRequest); } /** * 构建 Prompt */ private String buildPrompt(String question, String context) { return """ 你是一个专业的 AI 助手,请基于以下上下文信息回答用户的问题。 要求: 1. 如果上下文中包含相关信息,请基于上下文准确回答 2. 如果上下文中没有相关信息,请明确说"根据现有知识库,我无法回答这个问题" 3. 回答要简洁、准确、有条理 ===== 上下文信息 ===== %s ===================== 用户问题:%s 请回答: """.formatted(context, question); } }REST 控制器
javapackage com.smoky.ai.controller; import com.smoky.ai.service.RagService; import lombok.AllArgsConstructor; import lombok.Data; import lombok.RequiredArgsConstructor; import lombok.extern.slf4j.Slf4j; import org.springframework.ai.document.Document; import org.springframework.web.bind.annotation.*; import java.util.List; import java.util.Map; @Slf4j @RestController @RequestMapping("/api/rag") @RequiredArgsConstructor public class RagController { private final RagService ragService; @PostMapping("/ask") public AnswerResponse ask(@RequestBody QuestionRequest request) { String answer = ragService.askQuestion(request.getQuestion()); return new AnswerResponse(answer); } @PostMapping("/ask-with-filter") public AnswerResponse askWithFilter(@RequestBody FilteredQuestionRequest request) { String answer = ragService.askQuestionWithFilter( request.getQuestion(), request.getTopic() ); return new AnswerResponse(answer); } @PostMapping("/load-documents") public Map<String, String> loadDocuments() { ragService.addDocuments(); return Map.of("status", "success", "message", "文档已加载"); } @GetMapping("/search") public List<Document> search( @RequestParam String q, @RequestParam(defaultValue = "3") int topK) { return ragService.search(q, topK); } @Data public static class QuestionRequest { private String question; } @Data public static class FilteredQuestionRequest { private String question; private String topic; } @Data @AllArgsConstructor public static class AnswerResponse { private String answer; } }启动类
javapackage com.smoky.ai; import com.smoky.ai.service.RagService; import lombok.extern.slf4j.Slf4j; import org.springframework.boot.CommandLineRunner; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.context.annotation.Bean; @Slf4j @SpringBootApplication public class SpringaiApplication { public static void main(String[] args) { SpringApplication.run(SpringaiApplication.class, args); } @Bean public CommandLineRunner initDocuments(RagService ragService) { return args -> { log.info("初始化知识库..."); ragService.addDocuments(); log.info("知识库初始化完成!"); }; } }
测试接口:
bash# 1. 基础问答 curl -X POST http://localhost:8989/api/rag/ask \ -H "Content-Type: application/json" \ -d '{"question": "什么是Spring AI?"}' # 2. 语义搜索 curl "http://localhost:8989/api/rag/search?q=向量数据库&topK=2" # 3. 主题过滤问答 curl -X POST http://localhost:8989/api/rag/ask-with-filter \ -H "Content-Type: application/json" \ -d '{"question": "支持哪些数据库?", "topic": "spring-ai"}'输出:
bash{ "answer": "根据知识库信息,Spring AI 是一个用于构建 AI 应用的 Java 框架,它提供了统一的 API 来集成各种 AI 模型。Spring AI 1.1.x 版本支持多种向量数据库,包括 Chroma、Pinecone、Qdrant 等。" }
核心概念解析
传统搜索是关键词匹配,向量检索是语义理解:
sql// 传统搜索(只能匹配"汽车") SELECT * FROM docs WHERE text LIKE '%汽车%' // 向量检索(也能匹配"轿车"、"车辆") vectorStore.similaritySearch("汽车")什么是 Prompt 工程?
Prompt 是给 AI 的指令,好的 Prompt 能显著提升回答质量:
javaString prompt = """ 请基于以下上下文回答问题: 上下文:%s 问题:%s 要求: 1. 如果上下文有信息,准确回答 2. 如果没信息,明确说不知道 3. 回答简洁有条理 """;注:上述代码使用了java15的新特性文本块模式,这个可以自行了解
写在最后:
简单来说:Spring AI 提供统一接口,让 Java 应用通过向量数据库检索私有知识,增强大模型回答,实现精准的 RAG 智能问答。
类比理解:
传统 LLM = 靠记忆回答的专家(可能记错) Spring AI + 向量数据库 + RAG = 带图书馆的专家(先查书再回答)Spring AI = 图书馆管理系统(统一接口)
向量数据库 = 智能书架(语义检索)
RAG = 查书→回答的工作流程
通过本文,你应该已经掌握了:
✅ RAG 的核心概念
✅ Spring AI 的基本使用
✅ 向量检索的实现
✅ Prompt 工程的方法
✅ 完整的 RAG 问答系统
RAG 是解决大模型幻觉问题的有效方案,也是企业落地 AI 应用的重要技术。希望本文能帮助你快速入门 Spring AI 和 RAG!
如果有任何问题,欢迎在评论区交流讨论。