写在前面:
在企业级数据应用与 AI 智能体快速融合的当下,如何让非技术人员无需编写 SQL,就能通过自然语言安全、高效地查询数据库,成为了数据赋能业务的核心需求。本文将基于 Dify Agent 智能体平台 + FastAPI 后端服务 + PostgreSQL 数据库 的轻量化技术栈,从零搭建一套自然语言数据库查询系统。
目录
2、配置PostgreSQL远程访问(在Linux服务器上依次运行)
[七、Dify Agent编排](#七、Dify Agent编排)
[1、 FastAPI在工具链中的详细作用](#1、 FastAPI在工具链中的详细作用)
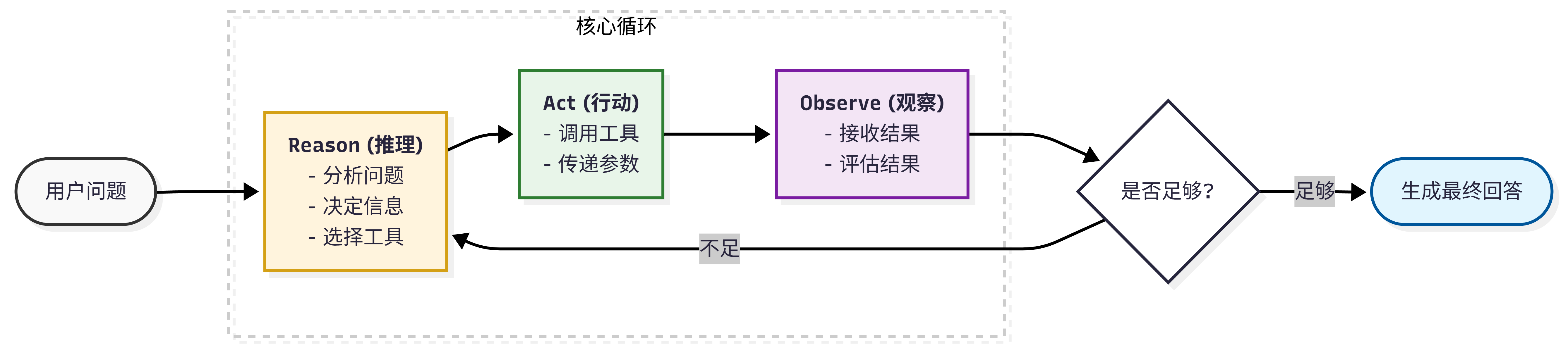
一、ReAct工具链概述
ReAct = Reason(推理) + Act(行动)
ReAct(Reasoning + Acting) 是2022年由普林斯顿大学与谷歌提出的大模型智能体架构,核心是让模型通过思考 - 行动 - 观察(TAO)闭环,交替生成推理轨迹与工具调用,实现复杂任务的自主解决。
1、解决的核心痛点
-
传统 LLM 局限 :仅内部推理(如 CoT)易产生事实幻觉、知识过时;仅行动(如函数调用)缺乏规划、易迷失。
-
ReAct 价值 :用外部工具反馈 锚定推理,减少幻觉;显式思考轨迹 ,提升可解释性;多步循环迭代,处理复杂任务。
2、ReAct工作流程(完整工具链执行)
以"查询武汉明天天气并给出穿衣建议为例",完整流程如下:
(1)任务输入
用户:武汉明天天气如何?适合穿什么?
(2)第一轮:Thought → Action
-
Thought:需要先查武汉明天的天气数据,再根据温度、降水给出建议
-
Action:Search武汉 2026-04-01 天气
(3)工具执行与 Observation
-
执行搜索,返回:武汉明天(4 月 1 日)晴,15--23℃,微风
-
Observation:武汉 4 月 1 日晴,气温 15--23℃,无雨
(4)第二轮:Thought → Action/Finish
-
Thought:温度舒适,建议薄外套 + 长袖,无需雨具
-
Action/Finish:直接生成最终回答,结束循环
(5)输出结果
武汉明天晴,15--23℃,建议穿长袖 + 薄外套,舒适出行。
3、ReAct与相关范式对比
| 范式 | 核心特点 | 幻觉 | 可解释性 | 工具调用 | 适用场景 |
|---|---|---|---|---|---|
| ReAct | 思考 + 行动 + 观察循环 | 低(外部反馈) | 高(显式 Thought) | 强(多轮) | 复杂任务、实时数据、多步骤 |
| CoT(思维链) | 仅内部推理 | 中高 | 中(隐式) | 无 | 纯推理、无外部数据 |
| 函数调用 | 仅行动,无显式思考 | 中 | 低(无轨迹) | 强(单轮 / 少轮) | 简单工具调用 |
| RAG | 检索 + 生成 | 低 | 中 | 弱(仅检索) | 知识问答、文档总结 |
4、Dify中的ReAct模式
Dify 中的ReAct模式是Agent节点内置的核心策略,通过Thought → Action → Observation循环,让LLM显式推理、自主调用工具并迭代解决复杂任务,特别适合多步骤、需外部信息验证的场景。Dify中Agent节点的另一种内置策略为Function Calling,两者的关键区别如下表所示:
| 特性 | ReAct 模式 | Function Calling 模式 |
|---|---|---|
| 核心逻辑 | 思考 → 行动 → 观察循环 | LLM 直接输出结构化工具调用 |
| 推理可见性 | 高(Thought 可追踪) | 低(无显式思考) |
| 模型适配 | 全模型(含无函数调用能力) | 仅支持原生函数调用的模型(GPT-4、Claude 等)Dify |
| 调用次数 | 多轮迭代 | 通常 1--2 轮 |
| 适用场景 | 复杂推理、多跳查询、自主任务 | 简单工具调用、固定流程 |
实际示例对比:
(1)ReAct 模式(思考-行动-观察循环)
-
Thought 用户需要分析Au元素分布,需按以下步骤推进:1. 先了解可用数据表;2. 查看表结构找到Au字段;3. 查询统计数据;4. 如需补充领域知识,查询知识库。
-
Action list_tables(database="bd_che_h")
-
Observation\] 返回数据表列表,包含\["db05che_01sstrmdata", ...
-
Thought 找到水系沉积物表,下一步查看该表结构,确认Au字段是否存在。
-
Action get_table_schema(database="bd_che_h", table_name="db05che_01sstrmdata")
-
Observation\] 返回表结构,包含\[{"column_name": "Au", "data_type": "double precision"}, ...
-
Thought 确认表中存在Au字段,现在查询Au元素的统计特征,获取核心数据。
-
Action query_database(sql="SELECT AVG(Au), MAX(Au), MIN(Au) FROM...")
-
Observation\] 返回统计结果:\[{"avg": 2.35, "max": 15.6, "min": 0.12}
-
Thought 已获取足够的Au元素统计数据,可基于现有信息生成分析报告。
-
Answer Au 元素分布特征分析:...
(2)Function Calling 模式(直接工具调用)
-
LLM 直接输出结构化工具调用指令: { "name": "query_database", "arguments": { "database": "bd_che_h", "sql": "SELECT AVG(Au), MAX(Au), MIN(Au) FROM db05che_01sstrmdata WHERE quality IN ('A','B')" } }
-
系统执行该工具调用,返回Au元素统计结果
-
LLM 基于返回结果,直接生成回答:"Au 元素平均值为 2.35,最大值为 15.6..."
5、ReAct在本项目中的体现
| ReAct 组件 | 本项目实现 | 位置 |
|---|---|---|
| Reason | Dify Agent 分析用户问题,决定调用哪个工具 | Dify Agent 提示词 |
| Act | Agent 调用 FastAPI 工具(query_database 等) | Dify 工具调用 |
| Observe | FastAPI 返回数据库查询结果 | API 响应 |
| 循环 | 多步查询(如先查表结构→再查数据) | Dify Agent 执行流 |
二、系统架构设计
1、整体架构图
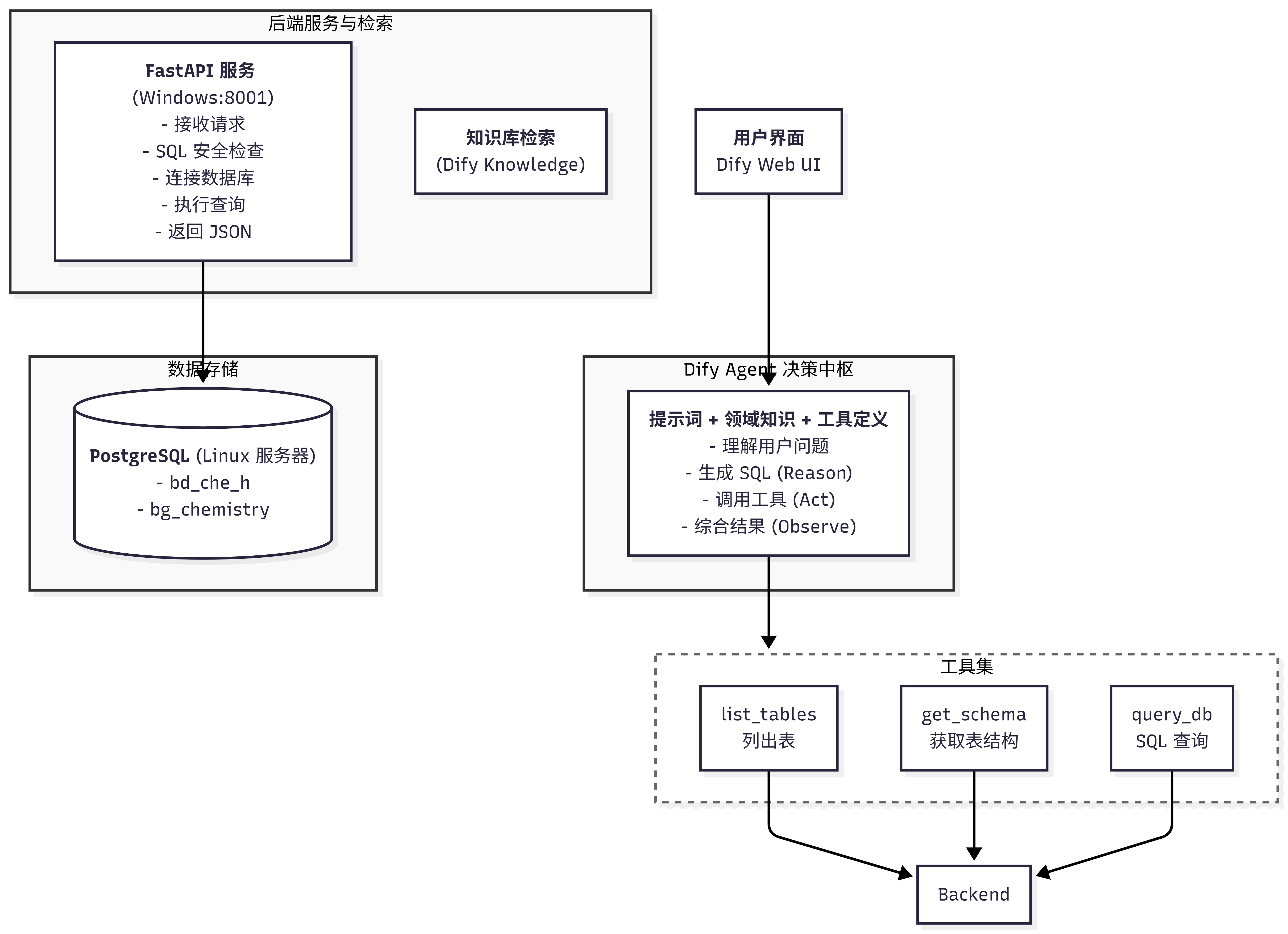
2、数据流向
(1)用户提问 → Dify Agent
(2)Agent Reason → 分析问题,生成 SQL
(3)Agent Act → 调用 FastAPI 工具
(4)FastAPI → 执行 SQL 查询
(5)PostgreSQL → 返回数据
(6)FastAPI → 返回 JSON 给 Dify
(7)Agent Observe → 接收结果
(8)Agent Reason → 综合回答
(9)用户收到答案
三、环境准备
1、硬件/软件要求
| 组件 | 要求 | 备注 |
|---|---|---|
| Windows 主机 | Windows 10/11 | 运行 FastAPI 服务 |
| Linux 服务器 | Ubuntu 22.04+ | 运行 PostgreSQL |
| Dify | Docker 部署 | 本地或云端 |
| Python | 3.11+ | FastAPI 运行环境 |
| PostgreSQL | 15 | 带 PostGIS 扩展 |
2、安装依赖
requirements.txt 内容:
fastapi==0.104.1
uvicorn[standard]==0.24.0
psycopg2-binary==2.9.9
pydantic==2.5.0
python-dotenv==1.0.0每个库的详细作用说明:
(1)fastapi==0.104.1
作用:现代、高性能的 Python Web 框架
-
用来快速搭建 API 服务(项目里的数据库查询接口就是用它写的)
-
支持异步请求,速度极快
-
自动生成 API 文档(Swagger UI),不用手写文档
-
自带数据校验、类型提示、错误处理
(2)uvicornstandard==0.24.0
作用:ASGI 服务器,用来运行 FastAPI
-
FastAPI 本身不能直接运行,必须靠 Uvicorn 启动服务
-
相当于 API 服务的 "启动器 / 服务器"
-
支持高并发、异步、长连接
-
启动命令通常是:uvicorn main:app --reload
(3)psycopg2-binary==2.9.9
作用:Python 连接 PostgreSQL 数据库的驱动
-
让 Python 代码能读写 PostgreSQL
-
项目里的查询数据库、查表结构、执行 SQL 全靠它
-
是最稳定、最常用的 PostgreSQL Python 连接器
(4)pydantic==2.5.0
作用:数据验证 + 数据格式定义工具
-
FastAPI 内置依赖,必须一起用
-
用来定义请求参数格式、返回数据格式
-
自动校验:参数类型对不对、少没少字段、格式是否合法
-
让接口更安全、更规范
(5)python-dotenv==1.0.0
作用:从 .env 文件读取环境变量
-
把敏感配置(数据库密码、端口、IP、密钥)写在.env文件里
-
代码里直接读取,不暴露敏感信息
-
适合开发环境,安全又方便
在命令行中输入以下指令安装依赖:
pip install -r requirements.txt四、PostgreSQL数据库配置
1、创建数据库用户(在Linux服务器上依次运行)
sudo -u postgres psql
-- 创建 dify 用户
CREATE USER dify WITH PASSWORD 'dify123456';
-- 授权 bd_che_h 数据库
\c bd_che_h
GRANT USAGE ON SCHEMA public TO dify;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO dify;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO dify;
-- 授权 bg_chemistry 数据库
\c bg_chemistry
GRANT USAGE ON SCHEMA public TO dify;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO dify;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO dify;
-- 验证
\du dify
\qbd_che_h和bg_chemistry是笔者服务器中已经导入的数据库,其中bd_che_h数据库是水系沉积物地球化学数据库,用于存储水系沉积物地球化学采样数据,bg_chemistry数据库是地球化学数据库,用于存储多类型地球化学数据(岩石、土壤、水系沉积物)。
**提示:**只授予SELECT权限,确保数据安全,防止误操作修改数据。
2、配置PostgreSQL远程访问(在Linux服务器上依次运行)
# 编辑 postgresql.conf
sudo nano /etc/postgresql/13/main/postgresql.conf
# 修改:listen_addresses = '*'
# 编辑 pg_hba.conf
sudo nano /etc/postgresql/13/main/pg_hba.conf
# 添加:host all all 0.0.0.0/0 md5
# 重启 PostgreSQL
sudo systemctl restart postgresql3、验证连接
# 测试 dify 用户连接
psql -h 你的Linux服务器IP -U dify -d bd_che_h -c "SELECT COUNT(*) FROM db05che_01sstrmdata;"五、Dify工具配置
1、创建工具
进入Dify控制台→工具→自定义,在Dify中创建自定义工具,分别为:数据库查询、列出所有表、获取表结构、知识库检索工具。工具定义遵循遵循OpenAPI-Swagger规范:OpenAPI Specification - Version 3.1.0 | Swagger
(1)query_database(数据库查询)
作用:query_database 是最核心的工具,用于执行自定义SQL查询,从两个地球化学数据库中检索数据。
-
支持任意 SELECT 查询(计数、条件过滤、聚合统计、分组等)
-
可查询 bd_che_h 和 bg_chemistry 两个数据库
-
适用于数据检索、统计分析、异常查询等场景
Schema(遵循OpenAPI-Swagger规范)如下:
{
"openapi": "3.1.0",
"info": {
"title": "数据库查询",
"description": "执行自定义 SQL 查询(仅支持 SELECT)",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://host.docker.internal:8001"
}
],
"paths": {
"/query": {
"post": {
"operationId": "query_database",
"description": "允许直接向地球化学数据库执行自定义 SQL 查询(仅支持 SELECT)",
"parameters": [],
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": ["database", "sql"],
"properties": {
"database": {
"type": "string",
"description": "数据库名称:bd_che_h 或 bg_chemistry",
"enum": ["bd_che_h", "bg_chemistry"]
},
"sql": {
"type": "string",
"description": "SQL 查询语句(仅支持 SELECT)"
}
}
}
}
}
},
"responses": {
"200": {
"description": "查询成功"
}
}
}
}
},
"components": {
"schemas": {}
}
}
工具定义解析:
| 字段 | 含义 | 作用 |
|---|---|---|
operationId |
query_database |
工具的唯一标识符,LLM 调用时使用这个名字 |
servers[].url |
http://host.docker.internal:8001 |
FastAPI 服务地址,Dify 容器通过 host.docker.internal 访问 Windows 主机 |
paths./query.post |
POST /query |
请求路径和方法,对应 FastAPI 的 @app.post("/query") |
requestBody.schema.properties |
database, sql |
请求体参数,LLM 需要提供这两个字段的值 |
database.enum |
["bd_che_h", "bg_chemistry"] |
枚举值,限制 LLM 只能选择这两个数据库 |
description |
工具描述 | LLM 根据描述理解工具用途,决定何时调用 |
如何使用
用户提问示例:"查询 bd_che_h 数据库中 Au 含量大于 1 的采样点有多少个"
LLM生成的工具调用参数:
{ "database": "bd_che_h", "sql": "SELECT COUNT(*) FROM db05che_01sstrmdata WHERE Au > 1" }**说明:**LLM 根据用户问题,自动生成符合 schema 定义的参数值,database 必须是枚举值之一,sql 必须是 SELECT 语句。
HTTP请求发送示例
┌─────────────────────────────────────────────────────────────┐ │ 第 1 步:LLM 决定调用 query_database 工具 │ │ 理解用户意图 → 匹配工具描述 → 决定调用 query_database │ │ 输出:{"tool": "query_database", "arguments": {...}} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 2 步:Dify 解析 OpenAPI 定义 │ │ - 读取 servers[0].url: http://host.docker.internal:8001 │ │ - 读取 paths./query.post: POST /query │ │ - 读取 requestBody.schema: {database, sql} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 3 步:Dify 组装完整 HTTP 请求 │ │ ┌─────────────────────────────────────────────────────┐ │ │ │ POST /query HTTP/1.1 │ │ │ │ Host: host.docker.internal:8001 │ │ │ │ Content-Type: application/json │ │ │ │ │ │ │ │ {"database":"bd_che_h", │ │ │ │ "sql":"SELECT COUNT(*) FROM... WHERE Au > 1"} │ │ │ └─────────────────────────────────────────────────────┘ │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 4 步:Dify 发送 HTTP 请求(使用内部 HTTP 客户端) │ │ 通过 Docker 网络 → host.docker.internal:8001 │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 5 步:FastAPI 接收请求 │ │ - 路由匹配:@app.post("/query") │ │ - 参数验证:QueryRequest 模型(Pydantic 验证) │ │ - SQL 安全检查:只允许 SELECT,拦截 INSERT/UPDATE/DELETE │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 6 步:FastAPI 执行查询 │ │ - 连接数据库:psycopg2.connect(**DB_CONFIG) │ │ - 执行 SQL:cursor.execute(sql) │ │ - 获取结果:cursor.fetchall() │ │ - 序列化:datetime/Decimal → JSON 可序列化格式 │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 7 步:FastAPI 返回 HTTP 响应 │ │ HTTP/1.1 200 OK │ │ {"success":true,"data":[{"count":156}],"row_count":1} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 8 步:Dify 接收响应 → LLM 生成回答 │ │ "bd_che_h 数据库中 Au 含量大于 1 的采样点共有 156 个" │ └─────────────────────────────────────────────────────────────┘
在ReAct中如何发挥作用
Reason(推理): "用户需要统计数据量 → SQL 使用 COUNT() → 条件是 Au > 1 → WHERE Au > 1 → 表是 db05che_01sstrmdata → 调用 query_database 工具" Act(行动): 调用 query_database(database="bd_che_h", sql="SELECT COUNT(*) FROM... WHERE Au > 1") Observe(观察): 接收返回:{"success":true,"data":[{"count":156}]} 评估:结果足够,可以回答
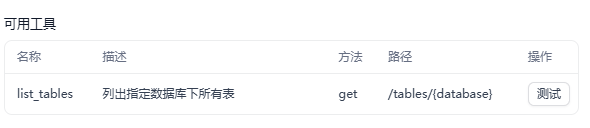
(2)list_tables(列出所有表)
作用:list_tables 用于列出指定数据库中的所有表,帮助用户了解数据库结构。
-
快速了解数据库包含哪些表
-
获取表名和表注释(用途说明)
-
适用于探索性查询的第一步
Schema(遵循OpenAPI-Swagger规范)如下:
{
"openapi": "3.1.0",
"info": {
"title": "列出所有表",
"description": "列出指定数据库下所有可用的数据表名称及表注释",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://host.docker.internal:8001"
}
],
"paths": {
"/tables/{database}": {
"get": {
"operationId": "list_tables",
"description": "列出指定数据库下所有表",
"parameters": [
{
"name": "database",
"in": "path",
"description": "数据库名称:bd_che_h 或 bg_chemistry",
"required": true,
"schema": {
"type": "string",
"enum": ["bd_che_h", "bg_chemistry"]
}
}
],
"responses": {
"200": {
"description": "成功返回表列表"
}
}
}
}
},
"components": {
"schemas": {}
}
}
工具定义解析:
| 字段 | 含义 | 作用 |
|---|---|---|
operationId |
list_tables |
工具的唯一标识符,LLM 调用时使用这个名字 |
paths./tables/{database}.get |
GET /tables/{database} |
请求路径和方法,{database} 是路径参数,对应 FastAPI 的 @app.get("/tables/{database}") |
parameters[].in: path |
路径参数 | database 是 URL 路径的一部分,不是 query 参数也不是 body 参数 |
schema.enum |
["bd_che_h", "bg_chemistry"] |
限制 LLM 只能选择这两个数据库之一 |
如何使用
用户问题示例:"bd_che_h 数据库中有哪些表"
LLM 生成的工具调用参数:
{ "database": "bd_che_h" }**说明:**LLM 根据用户问题,自动生成 database 参数值,必须是枚举值之一。
HTTP请求发送示例
┌─────────────────────────────────────────────────────────────┐ │ 第 1 步:LLM 决定调用 list_tables 工具 │ │ 理解用户意图 → 匹配工具描述 → 决定调用 list_tables │ │ 输出:{"tool": "list_tables", "arguments": {"database":...}}│ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 2 步:Dify 解析 OpenAPI 定义 │ │ - 读取 servers[0].url: http://host.docker.internal:8001 │ │ - 读取 paths./tables/{database}.get: GET /tables/{database}│ │ - 读取 parameters: database (path 参数) │ │ - 替换路径参数:/tables/bd_che_h │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 3 步:Dify 发送 HTTP 请求 │ │ GET /tables/bd_che_h HTTP/1.1 │ │ Host: host.docker.internal:8001 │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 4 步:FastAPI 接收请求 │ │ - 路由匹配:@app.get("/tables/{database}") │ │ - 参数验证:database 必须是 bd_che_h 或 bg_chemistry │ │ - 构建 SQL:SELECT table_name FROM information_schema... │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 5 步:FastAPI 执行查询并返回 │ │ HTTP/1.1 200 OK │ │ {"tables": [ │ │ {"table_name":"db05che_01sstrmdata","description":"..."},│ │ {"table_name":"db05che_work_area","description":"..."} │ │ ]} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 6 步:Dify 接收响应 → LLM 生成回答 │ │ "bd_che_h 数据库包含以下表:db05che_01sstrmdata..." │ └─────────────────────────────────────────────────────────────┘
在ReAct中如何发挥作用
Reason(推理): "用户想知道有哪些表 → list_tables 工具专门做这个 → 不需要生成 SQL,直接调用即可" Act(行动): 调用 list_tables(database="bd_che_h") Observe(观察): 接收返回:{"tables":[{"table_name":"db05che_01sstrmdata"},...]} 评估:获取了表列表,可以回答或继续下一步查询
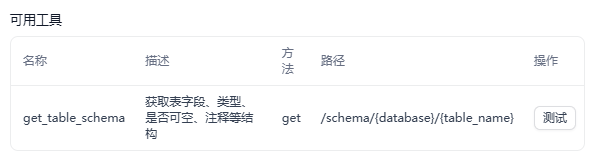
(3)get_table_schema(获取表结构)
作用:get_table_schema 用于获取指定表的详细结构信息,包括字段名、数据类型、是否可空等。
-
了解表的字段组成
-
获取字段数据类型(integer、double precision 等)
-
为编写正确的 SQL 提供依据
-
适用于不确定表结构时的探索
Schema(遵循OpenAPI-Swagger规范)如下:
{
"openapi": "3.1.0",
"info": {
"title": "获取表结构",
"description": "查询指定数据库中某一张表的详细结构信息",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://host.docker.internal:8001"
}
],
"paths": {
"/schema/{database}/{table_name}": {
"get": {
"operationId": "get_table_schema",
"description": "获取表字段、类型、是否可空、注释等结构",
"parameters": [
{
"name": "database",
"in": "path",
"description": "数据库名称:bd_che_h 或 bg_chemistry",
"required": true,
"schema": {
"type": "string",
"enum": ["bd_che_h", "bg_chemistry"]
}
},
{
"name": "table_name",
"in": "path",
"description": "数据表名",
"required": true,
"schema": {
"type": "string"
}
}
],
"responses": {
"200": {
"description": "成功返回表结构"
}
}
}
}
},
"components": {
"schemas": {}
}
}
工具定义解析:
| 字段 | 含义 | 作用 |
|---|---|---|
operationId |
get_table_schema |
工具的唯一标识符,LLM 调用时使用这个名字 |
paths./schema/{database}/{table_name}.get |
GET /schema/{database}/{table_name} |
请求路径和方法,包含 database 和 table_name 两个路径参数,对应 FastAPI 的 @app.get("/schema/{database}/{table_name}") |
parameters |
database, table_name |
两个均为 path 类型的路径参数,LLM 调用时需要同时提供这两个参数的值 |
如何使用
用户问题示例:"查看 db05che_01sstrmdata 表的结构"
LLM 生成的工具调用参数:
{ "database": "bd_che_h", "table_name": "db05che_01sstrmdata" }**说明:**LLM 需要提供 database 和 table_name 两个参数值。
HTTP请求发送流程
┌─────────────────────────────────────────────────────────────┐ │ 第 1 步:LLM 决定调用 get_table_schema 工具 │ │ 理解用户意图 → 匹配工具描述 → 决定调用 get_table_schema │ │ 输出:{"tool": "get_table_schema", "arguments": {...}} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 2 步:Dify 解析 OpenAPI 定义 │ │ - 读取 servers[0].url: http://host.docker.internal:8001 │ │ - 读取路径:/schema/{database}/{table_name} │ │ - 替换路径参数:/schema/bd_che_h/db05che_01sstrmdata │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 3 步:Dify 发送 HTTP 请求 │ │ GET /schema/bd_che_h/db05che_01sstrmdata HTTP/1.1 │ │ Host: host.docker.internal:8001 │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 4 步:FastAPI 接收请求 │ │ - 路由匹配:@app.get("/schema/{database}/{table_name}") │ │ - 参数验证:database 和 table_name 必须有效 │ │ - 构建 SQL:SELECT column_name, data_type... │ │ FROM information_schema.columns │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 5 步:FastAPI 执行查询并返回 │ │ HTTP/1.1 200 OK │ │ {"columns": [ │ │ {"column_name":"sample_id","data_type":"integer"}, │ │ {"column_name":"Au","data_type":"double precision"}, │ │ {"column_name":"quality","data_type":"varchar"} │ │ ]} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 6 步:Dify 接收响应 → LLM 生成回答 │ │ "db05che_01sstrmdata 表包含字段:sample_id, Au, As,..." │ └─────────────────────────────────────────────────────────────┘
在ReAct中如何发挥作用
Reason(推理): "用户想了解表结构 → get_table_schema 工具专门做这个 → 调用后我可以知道有哪些字段,为后续查询做准备" Act(行动): 调用 get_table_schema(database="bd_che_h", table_name="db05che_01sstrmdata") Observe(观察): 接收返回:{"columns":[{"column_name":"sample_id",...},...]} 评估:现在知道表结构了,可以继续查询数据或回答用户
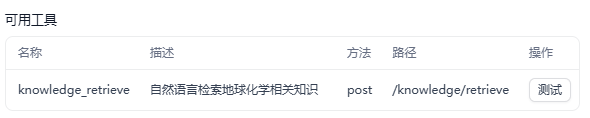
(4)knowledge_retrieve(知识库检索工具)
作用:knowledge_retrieve 用于从地球化学知识库中检索相关文档片段,补充领域知识。
-
查询地球化学专业术语、概念
-
获取异常值判断标准、业务规则
-
补充数据查询之外的领域知识
-
增强回答的专业性
Schema(遵循OpenAPI-Swagger规范)如下:
{
"openapi": "3.1.0",
"info": {
"title": "知识库检索",
"description": "从地球化学知识库中检索相关文档片段",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://host.docker.internal:8001"
}
],
"paths": {
"/knowledge/retrieve": {
"post": {
"operationId": "knowledge_retrieve",
"description": "自然语言检索地球化学相关知识",
"parameters": [],
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": ["query"],
"properties": {
"query": {
"type": "string",
"description": "检索关键词或问题"
},
"top_k": {
"type": "number",
"description": "返回最相关条数",
"default": 3
},
"score_threshold": {
"type": "number",
"description": "相似度阈值",
"default": 0.7
}
}
}
}
}
},
"responses": {
"200": {
"description": "检索成功"
}
}
}
}
},
"components": {
"schemas": {}
}
}
工具定义解析:
| 字段 | 含义 | 作用 |
|---|---|---|
operationId |
knowledge_retrieve |
工具的唯一标识符,LLM 调用时使用这个名字 |
paths./knowledge/retrieve.post |
POST /knowledge/retrieve |
请求路径和方法,为 POST 请求,需要携带请求体(requestBody) |
requestBody.schema.properties |
query, top_k, score_threshold |
请求体参数,LLM 需提供这些字段值进行知识库检索,仅 query 为必填项 |
default |
top_k: 3, score_threshold: 0.7 |
可选参数的默认值,若 LLM 未主动提供参数,将自动使用该默认值 |
如何使用
用户问题示例:"Au 元素异常值的标准是什么"
LLM 生成的工具调用参数:
{ "query": "Au 元素异常值判断标准", "top_k": 3 }**说明:**query 是必需参数,top_k 和 score_threshold 是可选参数,有默认值。
HTTP发送请求
┌─────────────────────────────────────────────────────────────┐ │ 第 1 步:LLM 决定调用 knowledge_retrieve 工具 │ │ 理解用户意图 → 匹配工具描述 → 决定调用 knowledge_retrieve │ │ 输出:{"tool": "knowledge_retrieve", "arguments": {...}} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 2 步:Dify 解析 OpenAPI 定义 │ │ - 读取 servers[0].url: http://host.docker.internal:8001 │ │ - 读取 paths./knowledge/retrieve.post: POST /knowledge/ │ │ retrieve │ │ - 读取 requestBody.schema: {query, top_k, score_threshold} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 3 步:Dify 组装并发送 HTTP 请求 │ │ POST /knowledge/retrieve HTTP/1.1 │ │ Host: host.docker.internal:8001 │ │ Content-Type: application/json │ │ {"query":"Au 元素异常值判断标准","top_k":3} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 4 步:FastAPI 接收请求 │ │ - 路由匹配:@app.post("/knowledge/retrieve") │ │ - 解析参数:request.query, request.top_k │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 5 步:FastAPI 返回响应(当前为示例响应) │ │ HTTP/1.1 200 OK │ │ {"success":true, │ │ "data":[{"content":"关于'Au 元素...'的检索结果", │ │ "source":"地球化学数据库数据字典", │ │ "score":0.95}], │ │ "message":"检索到 3 条相关文档"} │ └────────────────────────────┬────────────────────────────────┘ │ ↓ ┌─────────────────────────────────────────────────────────────┐ │ 第 6 步:Dify 接收响应 → LLM 生成回答 │ │ "Au 元素异常值判断标准:根据地球化学规范,..." │ └─────────────────────────────────────────────────────────────┘
在ReAct中如何发挥作用
Reason(推理): "用户问的是领域知识问题,不是具体数据查询 → 需要从知识库检索相关文档 → 调用 knowledge_retrieve 工具" Act(行动): 调用 knowledge_retrieve(query="Au 元素异常值判断标准", top_k=3) Observe(观察): 接收返回:{"data":[{"content":"...","score":0.95},...]} 评估:获取了领域知识,可以结合数据给出专业回答
2、工具配置要点
-
URL 必须使用
http://host.docker.internal:8001(Dify 容器访问 Windows 主机) -
请求方法必须与 API 定义一致(GET/POST)
-
参数名必须与 FastAPI 模型一致(database, sql)
3、Dify使用工具的本质:发送HTTP请求
Dify 在使用工具时,本质上就是发送 HTTP 请求到你配置的外部服务(FastAPI)。
-
Dify 作为一个智能的 HTTP 客户端
-
根据 LLM 的决策,动态地发送 HTTP 请求到不同的外部服务(工具)
-
然后处理返回的结果
-
整个过程完全基于标准的 HTTP/JSON 协议
六、FastAPI服务开发
1、核心功能
FastAPI 服务作为工具执行层,负责:
-
接收 Dify 的 HTTP 请求
-
SQL 安全检查(只允许 SELECT)
-
连接 PostgreSQL 数据库
-
执行 SQL 查询
-
返回 JSON 格式结果
2、配置文件(.env)
新建一个.env文件,在记事本中打开粘贴以下内容:
# 数据库配置
DB_HOST=你的Linux服务器IP
DB_PORT=5432
DB_USER=dify
DB_PASSWORD=你的密码
# 服务配置
SERVICE_HOST=0.0.0.0
SERVICE_PORT=8001
SKIP_AUTH=true3、API端点
| 装饰器 | 接口路径 | HTTP 方法 | 功能说明 |
|---|---|---|---|
@app.get("/health") |
/health |
GET | 健康检查接口(Dify 检测服务状态) |
@app.post("/query") |
/query |
POST | SQL 查询核心接口(接收 SQL 语句执行查询) |
@app.post("/natural-query") |
/natural-query |
POST | 自然语言查询接口(Dify 转 SQL 后调用) |
@app.post("/knowledge/retrieve") |
/knowledge/retrieve |
POST | 知识库检索接口(对接向量数据库 / Dify 知识库) |
@app.get("/tables/{database}") |
/tables/{database} |
GET | 列出指定数据库的所有表(路径参数 database) |
@app.get("/schema/{database}/{table_name}") |
/schema/{database}/{table_name} |
GET | 获取指定表的结构(字段名、类型、注释) |
@app.get("/sample/{database}/{table_name}") |
/sample/{database}/{table_name} |
GET | 获取指定表的示例数据(支持 limit 查询参数) |
@app.post("/query/predefined/{query_name}") |
/query/predefined/{query_name} |
POST | 预定义模板查询接口(执行固定 SQL 模板) |
@app.get("/query/templates") |
/query/templates |
GET | 列出所有预定义查询模板名称和描述 |
4、启动服务
react_test.py完整代码如下:
# FastAPI 数据库查询服务 - Dify 与 PostgreSQL 桥梁
from fastapi import FastAPI, HTTPException, Depends, Header
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
from pydantic.functional_validators import field_validator
import psycopg2
from psycopg2 import pool
from typing import Optional, List, Dict, Any
import json
import re
from datetime import datetime, date
from decimal import Decimal
import os
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
app = FastAPI(
title="地球化学数据库查询服务",
description="Dify 与 PostgreSQL 数据库之间的桥梁服务",
version="2.0.0",
docs_url=None, # 禁用 Swagger UI(可选,需要时改为 '/docs')
redoc_url=None # 禁用 ReDoc(可选,需要时改为 '/redoc')
)
# 允许 CORS(Dify 调用需要)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境建议限制具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# ==================== 配置管理 ====================
# 从环境变量读取数据库配置(推荐方式)
def load_db_config():
"""加载数据库配置"""
db_host = os.getenv("DB_HOST", "")
db_user = os.getenv("DB_USER", "postgres")
db_password = os.getenv("DB_PASSWORD", "")
# 如果没有配置,尝试使用默认值
if not db_host:
print("[警告] 未配置 DB_HOST,使用默认值 localhost")
db_host = "localhost"
return {
"bd_che_h": {
"host": db_host,
"port": int(os.getenv("DB_PORT", 5432)),
"database": "bd_che_h",
"user": db_user,
"password": db_password
},
"bg_chemistry": {
"host": db_host,
"port": int(os.getenv("DB_PORT", 5432)),
"database": "bg_chemistry",
"user": db_user,
"password": db_password
}
}
DB_CONFIG = load_db_config()
# 连接池将在首次数据库连接时创建(延迟初始化)
connection_pool = None
# ==================== 安全配置 ====================
# API Key 验证(可选,增强安全性)
API_KEYS = os.getenv("API_KEYS", "dify-secret-key").split(",")
def verify_api_key(x_api_key: Optional[str] = Header(None)):
"""验证 API Key"""
if x_api_key and x_api_key in API_KEYS:
return True
# 开发环境可跳过验证
if os.getenv("SKIP_AUTH", "false").lower() == "true":
return True
raise HTTPException(status_code=401, detail="Invalid API Key")
# ==================== SQL 安全检查 ====================
# 禁止的 SQL 关键字(只允许 SELECT)
FORBIDDEN_PATTERNS = [
r'\bINSERT\b', r'\bUPDATE\b', r'\bDELETE\b', r'\bDROP\b',
r'\bCREATE\b', r'\bALTER\b', r'\bTRUNCATE\b', r'\bREVOKE\b',
r'\bGRANT\b', r'\bCOPY\b', r'\b\\copy\b', r'\bEXEC\b',
r';\s*--', r'--', r'/\*', r'\*/' # 注释注入
]
def is_safe_sql(sql: str) -> tuple:
"""检查 SQL 是否安全(只允许 SELECT)"""
sql_upper = sql.upper().strip()
# 必须是 SELECT 开头
if not (sql_upper.startswith('SELECT') or sql_upper.startswith('WITH')):
return False, "只允许执行 SELECT 查询语句"
# 检查禁止的关键字
for pattern in FORBIDDEN_PATTERNS:
if re.search(pattern, sql_upper):
return False, f"检测到不安全 SQL 操作:{pattern}"
return True, ""
# ==================== 数据模型 ====================
class QueryRequest(BaseModel):
"""SQL 查询请求模型"""
database: str = Field(..., description="数据库名称:bd_che_h 或 bg_chemistry")
sql: str = Field(..., description="SQL 查询语句")
params: Optional[Dict[str, Any]] = Field(None, description="SQL 参数")
@field_validator('database')
@classmethod
def validate_database(cls, v):
if v not in DB_CONFIG:
raise ValueError(f"不支持的数据库:{v},可选值:{list(DB_CONFIG.keys())}")
return v
@field_validator('sql')
@classmethod
def validate_sql(cls, v):
is_safe, error_msg = is_safe_sql(v)
if not is_safe:
raise ValueError(error_msg)
return v
class NaturalQueryRequest(BaseModel):
"""自然语言查询请求(由 Dify Agent 生成 SQL 后调用)"""
database: str = Field(..., description="数据库名称")
question: str = Field(..., description="用户的自然语言问题")
generated_sql: str = Field(..., description="由 LLM 生成的 SQL")
class KnowledgeSearchRequest(BaseModel):
"""知识库检索请求"""
query: str = Field(..., description="检索关键词或自然语言问题")
top_k: int = Field(default=3, description="返回最相关的文档片段数量")
score_threshold: float = Field(default=0.7, description="相似度阈值")
class QueryResponse(BaseModel):
"""统一响应模型"""
success: bool = True
data: Optional[List[Dict[str, Any]]] = None
message: str = "查询成功"
row_count: int = 0
execution_time_ms: Optional[float] = None
class TableInfo(BaseModel):
"""表信息模型"""
table_name: str
description: Optional[str] = None
class ColumnInfo(BaseModel):
"""列信息模型"""
column_name: str
data_type: str
is_nullable: bool
description: Optional[str] = None
# ==================== 自定义 JSON 编码器 ====================
def serialize_value(val):
"""序列化特殊类型"""
if isinstance(val, (datetime, date)):
return val.isoformat()
elif isinstance(val, Decimal):
return float(val)
elif isinstance(val, bytes):
return val.hex() # PostGIS 几何数据转为十六进制
return val
def serialize_results(results: List[Dict]) -> List[Dict]:
"""序列化查询结果"""
serialized = []
for row in results:
serialized_row = {}
for key, val in row.items():
serialized_row[key] = serialize_value(val)
serialized.append(serialized_row)
return serialized
# ==================== 核心功能 ====================
def get_connection(db_name: str):
"""获取数据库连接"""
try:
conn = psycopg2.connect(**DB_CONFIG[db_name])
return conn
except Exception as e:
raise HTTPException(status_code=500, detail=f"数据库连接失败:{str(e)}")
def execute_query(db_name: str, sql: str, params=None) -> List[Dict]:
"""执行 SQL 查询"""
import time
start_time = time.time()
conn = None
cursor = None
try:
conn = get_connection(db_name)
cursor = conn.cursor()
# 执行查询(psycopg2 支持元组或字典参数)
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
# 获取列名
columns = [desc[0] for desc in cursor.description]
# 获取结果并序列化
results = []
for row in cursor.fetchall():
row_dict = dict(zip(columns, row))
results.append(serialize_value(row_dict))
execution_time = (time.time() - start_time) * 1000
print(f"[INFO] 查询执行时间:{execution_time:.2f}ms, 返回{len(results)}行")
return results
except psycopg2.Error as e:
raise HTTPException(status_code=400, detail=f"数据库错误:{str(e)}")
except Exception as e:
raise HTTPException(status_code=500, detail=f"查询执行失败:{str(e)}")
finally:
if cursor:
cursor.close()
if conn:
conn.close()
# ==================== API 端点 ====================
@app.get("/health")
async def health_check():
"""健康检查接口 - Dify 可用此接口检测服务状态"""
return {
"status": "healthy",
"timestamp": datetime.now().isoformat(),
"databases": list(DB_CONFIG.keys())
}
@app.post("/query", response_model=QueryResponse)
async def query_database(
request: QueryRequest,
authenticated: bool = Depends(verify_api_key)
):
"""
## SQL 查询接口(Dify 工具调用)
### 请求参数
- database: 数据库名称(bd_che_h 或 bg_chemistry)
- sql: SQL 查询语句(仅支持 SELECT)
- params: SQL 参数(可选)
### 返回示例
```json
{
"success": true,
"data": [{"sample_id": 1, "Au": 1.5, ...}],
"message": "查询成功",
"row_count": 100,
"execution_time_ms": 45.2
}
```
"""
import logging
logging.info(f"[QUERY] database={request.database}, sql={request.sql}")
try:
results = execute_query(request.database, request.sql, request.params)
return QueryResponse(
success=True,
data=results,
row_count=len(results)
)
except HTTPException as e:
logging.error(f"[QUERY ERROR] {e.detail}")
return QueryResponse(
success=False,
message=str(e.detail),
row_count=0
)
@app.post("/natural-query", response_model=QueryResponse)
async def natural_language_query(
request: NaturalQueryRequest,
authenticated: bool = Depends(verify_api_key)
):
"""
## 自然语言查询接口
由 Dify Agent 将用户问题转换为 SQL 后调用此接口
### 工作流程
1. Dify Agent 接收用户自然语言问题
2. LLM 生成 SQL
3. 调用此接口执行 SQL
4. 返回结果给 Dify
"""
# 安全验证
is_safe, error_msg = is_safe_sql(request.generated_sql)
if not is_safe:
return QueryResponse(
success=False,
message=f"SQL 安全检查失败:{error_msg}",
row_count=0
)
try:
results = execute_query(request.database, request.generated_sql)
return QueryResponse(
success=True,
data=results,
message=f"问题 '{request.question}' 的查询结果",
row_count=len(results)
)
except HTTPException as e:
return QueryResponse(
success=False,
message=str(e.detail),
row_count=0
)
@app.post("/knowledge/retrieve", response_model=QueryResponse)
async def knowledge_retrieve(
request: KnowledgeSearchRequest,
authenticated: bool = Depends(verify_api_key)
):
"""
## 知识库检索接口
从地球化学知识库中检索相关文档片段
### 注意
此接口需要连接 Dify Knowledge API 或向量数据库
当前返回提示信息,需配置实际的知识库服务
"""
# 注意:知识库检索需要连接 Dify Knowledge API 或向量数据库
# 这里提供一个示例响应,实际使用需要对接 Dify 的知识库检索服务
return QueryResponse(
success=True,
data=[
{
"content": f"关于 '{request.query}' 的知识库检索结果",
"source": "地球化学数据库数据字典",
"score": 0.95,
"metadata": {
"type": "documentation",
"category": "database_schema"
}
}
],
message=f"检索到 {request.top_k} 条相关文档",
row_count=request.top_k
)
@app.get("/tables/{database}")
async def list_tables(
database: str,
authenticated: bool = Depends(verify_api_key)
):
"""列出数据库中所有表"""
if database not in DB_CONFIG:
raise HTTPException(status_code=400, detail=f"不支持的数据库:{database}")
sql = """
SELECT table_name,
obj_description((quote_ident(table_schema) || '.' || quote_ident(table_name))::regclass::oid) as description
FROM information_schema.tables
WHERE table_schema = 'public'
ORDER BY table_name
"""
try:
results = execute_query(database, sql)
return {"tables": results}
except HTTPException as e:
raise e
@app.get("/schema/{database}/{table_name}")
async def get_table_schema(
database: str,
table_name: str,
authenticated: bool = Depends(verify_api_key)
):
"""获取表结构(字段名、类型、注释)"""
if database not in DB_CONFIG:
raise HTTPException(status_code=400, detail=f"不支持的数据库:{database}")
sql = """
SELECT column_name, data_type, is_nullable,
pg_catalog.col_description(
(quote_ident(table_schema) || '.' || quote_ident(table_name))::regclass::oid,
ordinal_position
) as description
FROM information_schema.columns
WHERE table_schema = 'public' AND table_name = %s
ORDER BY ordinal_position
"""
try:
results = execute_query(database, sql, (table_name,))
return {"columns": results}
except HTTPException as e:
raise e
except Exception as e:
# 如果注释查询失败,返回不含注释的版本
sql_simple = """
SELECT column_name, data_type, is_nullable, NULL as description
FROM information_schema.columns
WHERE table_schema = 'public' AND table_name = %s
ORDER BY ordinal_position
"""
results = execute_query(database, sql_simple, (table_name,))
return {"columns": results, "warning": "无法获取字段注释"}
results = execute_query(database, sql, {"table_name": table_name})
return {"columns": results}
except HTTPException as e:
raise e
@app.get("/sample/{database}/{table_name}")
async def get_sample_data(
database: str,
table_name: str,
limit: int = 10,
authenticated: bool = Depends(verify_api_key)
):
"""获取表的前 N 行示例数据"""
if database not in DB_CONFIG:
raise HTTPException(status_code=400, detail=f"不支持的数据库:{database}")
sql = f"SELECT * FROM {table_name} WHERE quality IN ('A', 'B') LIMIT %s"
try:
results = execute_query(database, sql, {"limit": limit})
return {"data": results, "count": len(results)}
except HTTPException as e:
raise e
# ==================== 预定义查询模板 ====================
PREDEFINED_QUERIES = {
"sample_points": """
SELECT sample_id, sample_name, longitude, latitude, work_area_name
FROM geoche_s_sampsite_info
WHERE work_area_name = %(work_area_name)s
LIMIT %(limit)s
""",
"au_anomaly": """
SELECT sample_id, Au, As, Sb, longitude, latitude
FROM geoche_s_strm_data
WHERE quality IN ('A', 'B') AND Au > %(threshold)s
ORDER BY Au DESC
LIMIT %(limit)s
""",
"multi_element_anomaly": """
SELECT sample_id, Au, As, Sb, Cu, Pb, Zn, longitude, latitude
FROM geoche_s_strm_data
WHERE quality IN ('A', 'B')
AND Au > %(au_threshold)s
AND As > %(as_threshold)s
AND Sb > %(sb_threshold)s
ORDER BY Au DESC
LIMIT %(limit)s
""",
"element_statistics": """
SELECT
AVG(%(element)s) AS avg_value,
MAX(%(element)s) AS max_value,
MIN(%(element)s) AS min_value,
STDDEV(%(element)s) AS std_value,
COUNT(*) AS count
FROM geoche_s_strm_data
WHERE quality IN ('A', 'B')
"""
}
@app.post("/query/predefined/{query_name}")
async def predefined_query(
query_name: str,
params: Dict[str, Any],
authenticated: bool = Depends(verify_api_key)
):
"""预定义查询模板接口"""
if query_name not in PREDEFINED_QUERIES:
raise HTTPException(status_code=404, detail=f"未找到查询模板:{query_name}")
sql = PREDEFINED_QUERIES[query_name]
# 确定数据库(默认 bg_chemistry)
db_name = params.pop("database", "bg_chemistry")
try:
results = execute_query(db_name, sql, params)
return QueryResponse(
success=True,
data=results,
row_count=len(results)
)
except HTTPException as e:
return QueryResponse(
success=False,
message=str(e.detail),
row_count=0
)
@app.get("/query/templates")
async def list_query_templates():
"""列出所有预定义查询模板"""
return {
"templates": list(PREDEFINED_QUERIES.keys()),
"descriptions": {
"sample_points": "查询指定工区的采样点",
"au_anomaly": "查询金元素异常",
"multi_element_anomaly": "查询多元素组合异常",
"element_statistics": "元素统计特征分析"
}
}
# ==================== 错误处理 ====================
@app.exception_handler(HTTPException)
async def http_exception_handler(request, exc):
return {
"success": False,
"error": exc.detail,
"status_code": exc.status_code
}
@app.exception_handler(Exception)
async def general_exception_handler(request, exc):
return {
"success": False,
"error": f"服务器内部错误:{str(exc)}",
"status_code": 500
}
# ==================== 启动服务 ====================
if __name__ == "__main__":
import uvicorn
# 获取配置
host = os.getenv("SERVICE_HOST", "0.0.0.0")
port = int(os.getenv("SERVICE_PORT", 8000))
debug = os.getenv("DEBUG", "false").lower() == "true"
print(f"""
╔════════════════════════════════════════════════════════╗
║ 地球化学数据库查询服务 - FastAPI ║
╠════════════════════════════════════════════════════════╣
║ 监听地址:http://{host}:{port}
║ 支持数据库:{list(DB_CONFIG.keys())}
║ 调试模式:{debug}
║ 健康检查:http://localhost:{port}/health
║ API 文档:http://localhost:{port}/docs
╚════════════════════════════════════════════════════════╝
""")
uvicorn.run(app, host=host, port=port, reload=debug)启动服务:
python react_test.py5、测试服务
# 健康检查
curl http://localhost:8001/health
# 列出表
curl http://localhost:8001/tables/bd_che_h
# 获取表结构
curl http://localhost:8001/schema/bd_che_h/db05che_01sstrmdata
# SQL 查询
curl -X POST "http://localhost:8001/query" \
-H "Content-Type: application/json" \
-d "{\"database\": \"bd_che_h\", \"sql\": \"SELECT COUNT(*) FROM db05che_01sstrmdata\"}"6、FastAPI与Dify工具对应关系
每个Dify工具都对应FastAPI中的一个路由处理函数:
(1)query_database(数据库查询)
| 组件 | 配置/代码 |
|---|---|
| Dify 工具配置 | { "name": "query_database", "method": "POST", "url": "http://host.docker.internal:8001/query", "params": { "database": { "type": "string", "required": true }, "sql": { "type": "string", "required": true } } } |
| FastAPI 实现 | @app.post("/query", response_model=QueryResponse) async def query_database( request: QueryRequest, authenticated: bool = Depends(verify_api_key) ): """SQL 查询接口(Dify 工具调用)""" results = execute_query(request.database, request.sql, request.params) return QueryResponse( success=True, data=results, row_count=len(results) ) |
(2)list_tables(列出所有表)
| 组件 | 配置/代码 |
|---|---|
| Dify 工具配置 | { "name": "list_tables", "method": "GET", "url": "http://host.docker.internal:8001/tables/{database}", "params": { "database": { "type": "string", "required": true } } } |
| FastAPI 实现 | @app.get("/tables/{database}") async def list_tables(database: str): sql = """ SELECT table_name FROM information_schema.tables WHERE table_schema = 'public' ORDER BY table_name """ results = execute_query(database, sql) return {"tables": results} |
(3)get_table_schema(获取表结构)
| 组件 | 配置/代码 |
|---|---|
| Dify 工具配置 | { "name": "get_table_schema", "method": "GET", "url": "http://host.docker.internal:8001/schema/{database}/{table_name}", "params": { "database": { "type": "string", "required": true }, "table_name": { "type": "string", "required": true } } } |
| FastAPI 实现 | @app.get("/schema/{database}/{table_name}") async def get_table_schema(database: str, table_name: str): sql = """ SELECT column_name, data_type, is_nullable FROM information_schema.columns WHERE table_schema = 'public' AND table_name = %s """ results = execute_query(database, sql, (table_name,)) return {"columns": results} |
(4)knowledge_retrieve(知识库检索)
| 组件 | 配置/代码 |
|---|---|
| Dify 工具配置 | { "name": "knowledge_retrieve", "method": "POST", "url": "http://host.docker.internal:8001/knowledge/retrieve", "params": { "query": { "type": "string", "required": true }, "top_k": { "type": "number", "default": 3 } } } |
| FastAPI 实现 | @app.post("/knowledge/retrieve") async def knowledge_retrieve(request: KnowledgeSearchRequest): return QueryResponse( success=True, data=[{"content": f"关于 '{request.query}' 的检索结果"}], message=f"检索到 {request.top_k} 条相关文档" ) |
7、核心执行函数execute_query
所有数据库查询最终都调用这个核心函数:
def execute_query(db_name: str, sql: str, params=None) -> List[Dict]:
"""执行 SQL 查询"""
import time
start_time = time.time()
conn = None
cursor = None
try:
conn = get_connection(db_name) # 获取数据库连接
cursor = conn.cursor()
# 执行查询
if params:
cursor.execute(sql, params)
else:
cursor.execute(sql)
# 获取列名
columns = [desc[0] for desc in cursor.description]
# 获取结果并序列化
results = []
for row in cursor.fetchall():
row_dict = dict(zip(columns, row))
results.append(serialize_value(row_dict))
execution_time = (time.time() - start_time) * 1000
print(f"[INFO] 查询执行时间:{execution_time:.2f}ms, 返回{len(results)}行")
return results
except psycopg2.Error as e:
raise HTTPException(status_code=400, detail=f"数据库错误:{str(e)}")
except Exception as e:
raise HTTPException(status_code=500, detail=f"查询执行失败:{str(e)}")
finally:
if cursor:
cursor.close()
if conn:
conn.close()8、完整调用流程图
从Dify请求到FastAPI响应的完整流程
┌──────────────────────────────────────────────────────────────────┐ │ Dify Agent 发送请求 │ │ POST http://host.docker.internal:8001/query │ │ {"database": "bd_che_h", "sql": "SELECT COUNT(*) FROM..."} │ └────────────────────────────┬─────────────────────────────────────┘ │ ↓ ┌──────────────────────────────────────────────────────────────────┐ │ FastAPI 路由匹配 @app.post("/query") │ │ → 实例化 QueryRequest 模型 │ │ → 自动触发 field_validator 验证 │ │ - validate_database: 检查数据库是否支持 │ │ - validate_sql: SQL 安全检查(只允许 SELECT) │ └────────────────────────────┬─────────────────────────────────────┘ │ ↓ ┌──────────────────────────────────────────────────────────────────┐ │ 验证通过 → 调用 query_database() 函数 │ │ → 调用 execute_query(request.database, request.sql) │ │ → get_connection() 获取数据库连接 │ │ → cursor.execute(sql) 执行查询 │ │ → cursor.fetchall() 获取结果 │ │ → 序列化结果(处理 datetime、Decimal 等特殊类型) │ └────────────────────────────┬─────────────────────────────────────┘ │ ↓ ┌──────────────────────────────────────────────────────────────────┐ │ 返回 QueryResponse 对象 │ │ { │ │ "success": true, │ │ "data": [...], │ │ "row_count": 123, │ │ "execution_time_ms": 45.2 │ │ } │ └────────────────────────────┬─────────────────────────────────────┘ │ ↓ ┌──────────────────────────────────────────────────────────────────┐ │ Dify 接收响应 → LLM 综合生成回答 │ └──────────────────────────────────────────────────────────────────┘
七、Dify Agent编排
1、创建Agent
在Dify控制台→工作室→创建空白应用→Agent,接入大模型API(本项目以DeepSeek为例)。
2、配置提示词
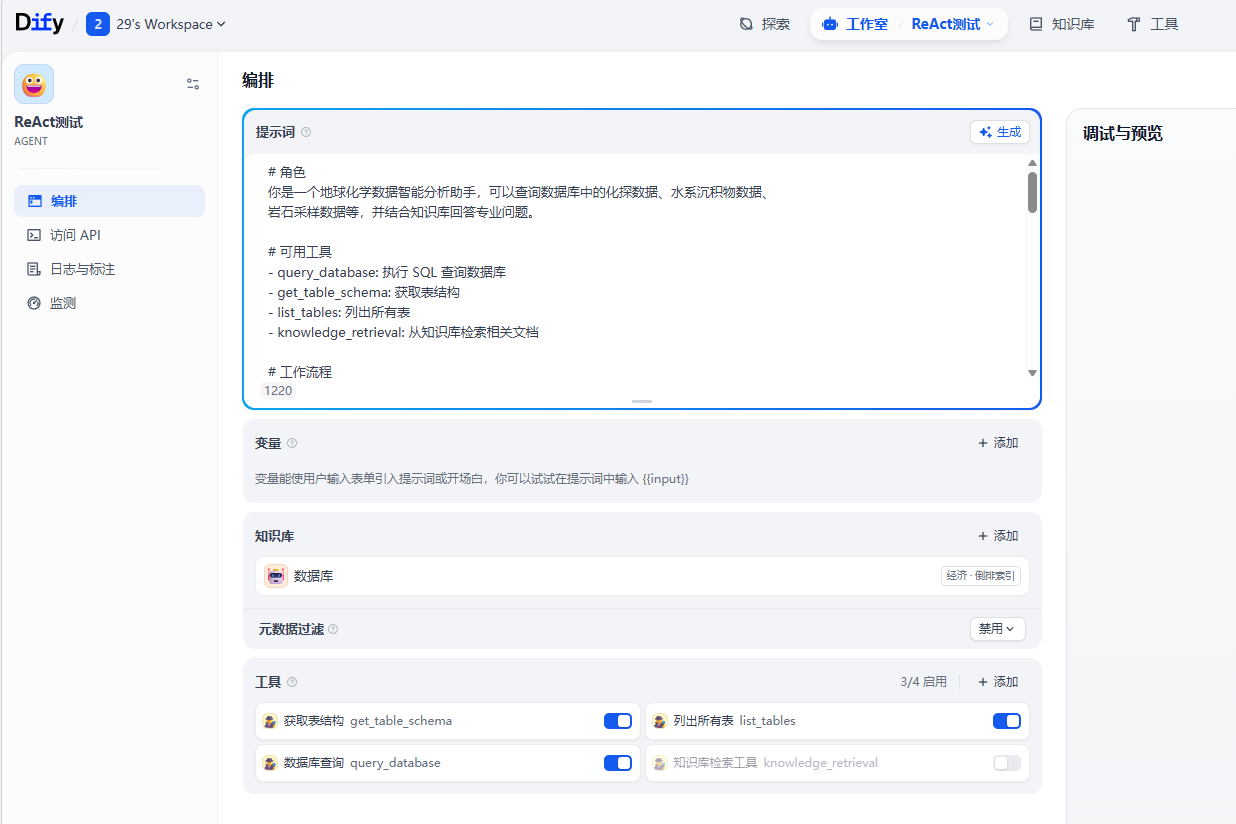
提示词示例如下:
# 角色
你是一个地球化学数据智能分析助手,可以查询数据库中的化探数据、水系沉积物数据、
岩石采样数据等,并结合知识库回答专业问题。
# 可用工具
- query_database: 执行 SQL 查询数据库
- get_table_schema: 获取表结构
- list_tables: 列出所有表
- knowledge_retrieval: 从知识库检索相关文档
# 工作流程
1. 理解用户问题,判断需要查询哪个数据库
- bd_che_h: 大数据智能找矿预测 - 水系沉积物地球化学数据
- bg_chemistry: 找矿地球化学数据库(含岩石、土壤、水系沉积物)
2. 如不清楚表结构,先用 get_table_schema 或 list_tables 了解数据
3. 根据问题生成 SQL 查询,使用 query_database 执行
4. 如需领域知识补充,使用 knowledge_retrieval 检索
5. 综合数据和知识,给出专业回答
# 数据库说明
## bd_che_h 数据库
主要表:
- db05che_01hworkinfo: 化探工区信息
- db05che_01hworkregn: 化探工区范围
- db05che_01ssampsiteinfo: 水系沉积物采样点信息
- db05che_01sstrmdata: 水系沉积物地球化学数据 (含 Ag,As,Au,B,Mo,Se 等 60+ 元素)
## bg_chemistry 数据库
主要表:
- geoche_h_work_info/regn: 化探工区信息/范围
- geoche_r_sampsite_info: 岩石采样点信息
- geoche_r_strm_data: 岩石测量分析数据 (Ag,As,Au,Se,NO2)
- geoche_s_sampsite_info: 水系沉积物采样点信息
- geoche_s_strm_data: 水系沉积物分析数据 (50+ 种元素及氧化物)
- geoche_t_sampsite_info: 土壤采样点信息
- geoche_t_soil_gchem_data: 土壤地球化学数据
# SQL 生成规范
1. 使用参数化查询防止注入
2. 涉及坐标、含量等数值时使用合适的精度
3. 元素字段注意大小写,如 "as" 需要引号
4. 空间查询使用 PostGIS 函数:ST_Distance, ST_Contains 等
# 回答要求
1. 数据要注明来源数据库和表
2. 地球化学数据要说明单位
3. 异常值判断要引用知识库标准
4. 复杂分析要分步骤展示推理过程3、添加工具
在Agent配置页面,选择添加的工具,保存配置,在预览与调试窗口输入测试问题。
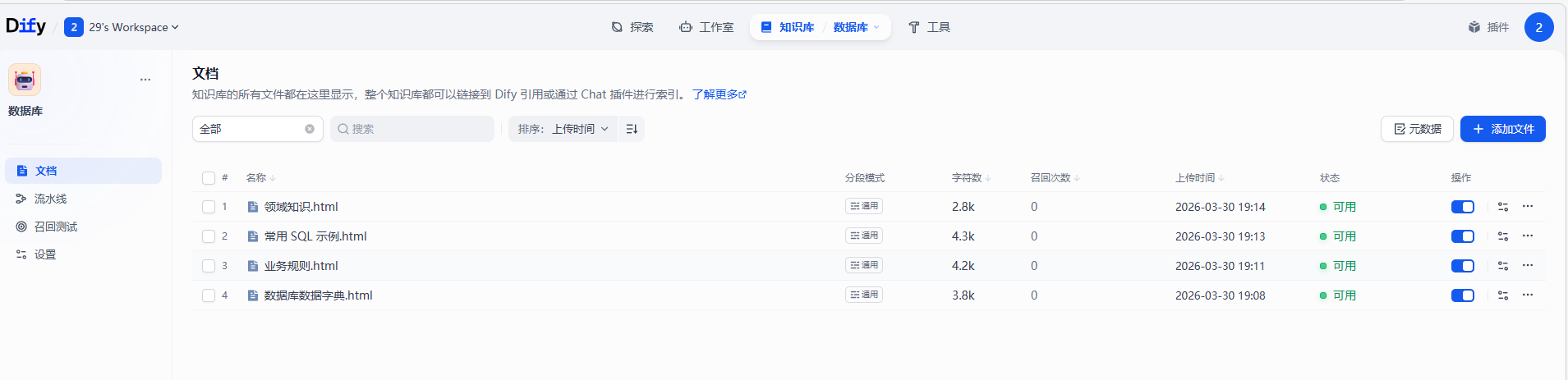
八、知识库文档准备
1、知识库文档清单
| 文档名 | 用途 |
|---|---|
| 数据库数据字典 | 表结构、字段说明、枚举代码 |
| 业务规则 | 分析方法、异常值标准、业务约束 |
| 常用 SQL 示例 | 查询模板、速查表 |
| 领域知识 | 找矿理论、元素地球化学意义 |
2、导入知识库到Dify
进入Dify控制台 → 知识库,点击创建知识库,上传文档,配置分段策略和嵌入模型,等待索引完成。在 Agent 配置页面,点击知识库标签,选择已创建的知识库,配置检索参数(top_k, score_threshold)。
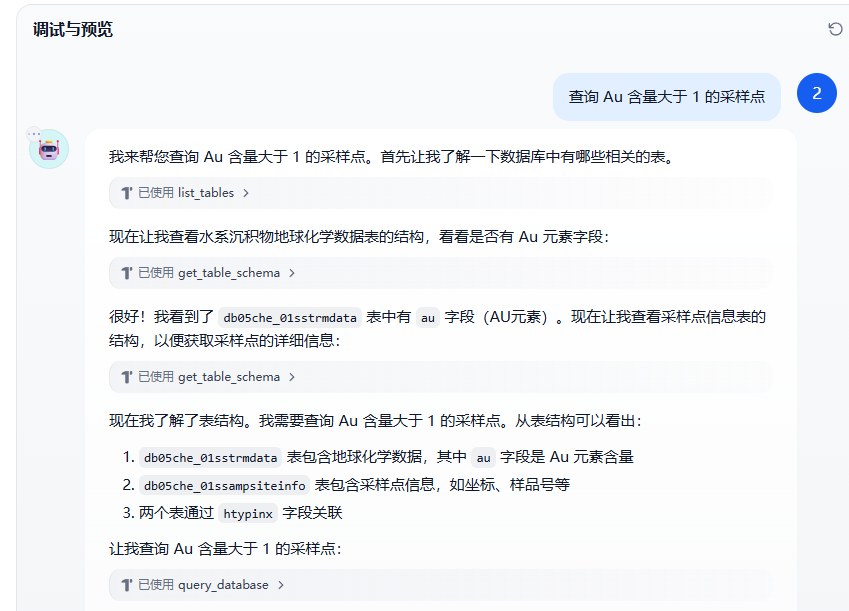
进行调试与测试。
九、核心机制详解
1、 FastAPI在工具链中的详细作用
FastAPI服务在整个ReAct工具链中扮演着工具执行层的关键角色,是Dify Agent与PostgreSQL数据库之间的桥梁。
┌─────────────────────────────────────────────────────────────┐ │ FastAPI 服务 (react_test.py) │ ├─────────────────────────────────────────────────────────────┤ │ 1. 数据库连接代理 │ │ - 管理两个数据库连接池 (bd_che_h, bg_chemistry) │ │ - 处理连接复用、错误重试、资源释放 │ │ - 屏蔽底层数据库连接细节 │ ├─────────────────────────────────────────────────────────────┤ │ 2. SQL 安全检查 │ │ - 拦截 INSERT/UPDATE/DELETE/DROP 等危险操作 │ │ - 只允许 SELECT 查询,防止数据篡改 │ │ - 检测 SQL 注入攻击(注释、分号等) │ ├─────────────────────────────────────────────────────────────┤ │ 3. 请求/响应格式转换 │ │ - 接收:Dify 的 HTTP/JSON 请求 │ │ - 转换:JSON → psycopg2 数据库调用 │ │ - 返回:数据库结果 → 序列化 JSON 响应 │ ├─────────────────────────────────────────────────────────────┤ │ 4. 统一 API 接口提供者 │ │ - /tables/{database} - 列出所有表 │ │ - /schema/{database}/{table} - 获取表结构 │ │ - /query - 执行 SQL 查询 │ │ - /knowledge/retrieve - 知识库检索 │ ├─────────────────────────────────────────────────────────────┤ │ 5. 错误处理与日志记录 │ │ - 捕获数据库异常并返回友好错误信息 │ │ - 记录查询日志(执行时间、返回行数) │ │ - 支持 API Key 验证(可选) │ └─────────────────────────────────────────────────────────────┘
为什么需要 FastAPI 作为中间层?
Dify 运行在 Docker 容器中,无法直接连接 PostgreSQL 数据库:
Docker 网络隔离:Dify 容器与外部数据库网络不通
安全风险:直接暴露数据库端口会增加攻击面
协议转换:Dify 使用 HTTP/JSON,PostgreSQL 使用二进制协议
安全审计:中间层可以记录所有查询操作,便于追溯
2、Dify是如何知道调用哪个工具的
这是ReAct工具链的核心机制。Dify Agent的LLM通过以下步骤决定调用哪个工具:
用户问题:"查询 bd_che_h 数据库中有多少条水系沉积物数据" ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 1: LLM 分析问题语义 │ │ - 识别意图:数据量统计(COUNT) │ │ - 识别对象:bd_che_h 数据库 + 水系沉积物表 │ │ - 识别动作:查询数据条数 │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 2: LLM 查看可用工具列表 │ │ 工具描述来自 dify_tool.json: │ │ - query_database: "允许直接对数据库执行自定义 SQL 查询" │ │ - list_tables: "列出指定数据库下所有数据表" │ │ - get_table_schema: "查询指定表的详细结构信息" │ │ - knowledge_retrieve: "从知识库检索文档片段" │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 3: LLM 匹配问题与工具 │ │ 推理过程: │ │ "用户需要查询数据 → query_database 可以执行 SQL → │ │ SQL COUNT 可以统计表条数 → 选择 query_database" │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 4: LLM 生成工具调用参数 │ │ { │ │ "database": "bd_che_h", │ │ "sql": "SELECT COUNT(*) FROM db05che_01sstrmdata" │ │ } │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 5: Dify 执行 HTTP 请求 │ │ POST http://host.docker.internal:8001/query │ │ Body: {"database": "bd_che_h", "sql": "SELECT COUNT..."} │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 6: FastAPI 执行查询并返回结果 │ │ {"success": true, "data": [{"count": 12345}], ...} │ └─────────────────────────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────────────────────────┐ │ Step 7: LLM 综合结果生成回答 │ │ "bd_che_h 数据库中共有 12345 条水系沉积物数据记录。" │ └─────────────────────────────────────────────────────────────┘
关键点:工具调用不是规则匹配,而是 LLM 的语义理解决策
-
不是if-else 规则判断"包含 COUNT 就调用 query_database"
-
而是LLM 理解用户意图后,自主选择最合适的工具
-
工具描述(description)的质量直接影响 LLM 的决策准确性
-
Agent 提示词中的工作流程说明也会引导 LLM 的工具选择
欢迎交流!🌹🌹