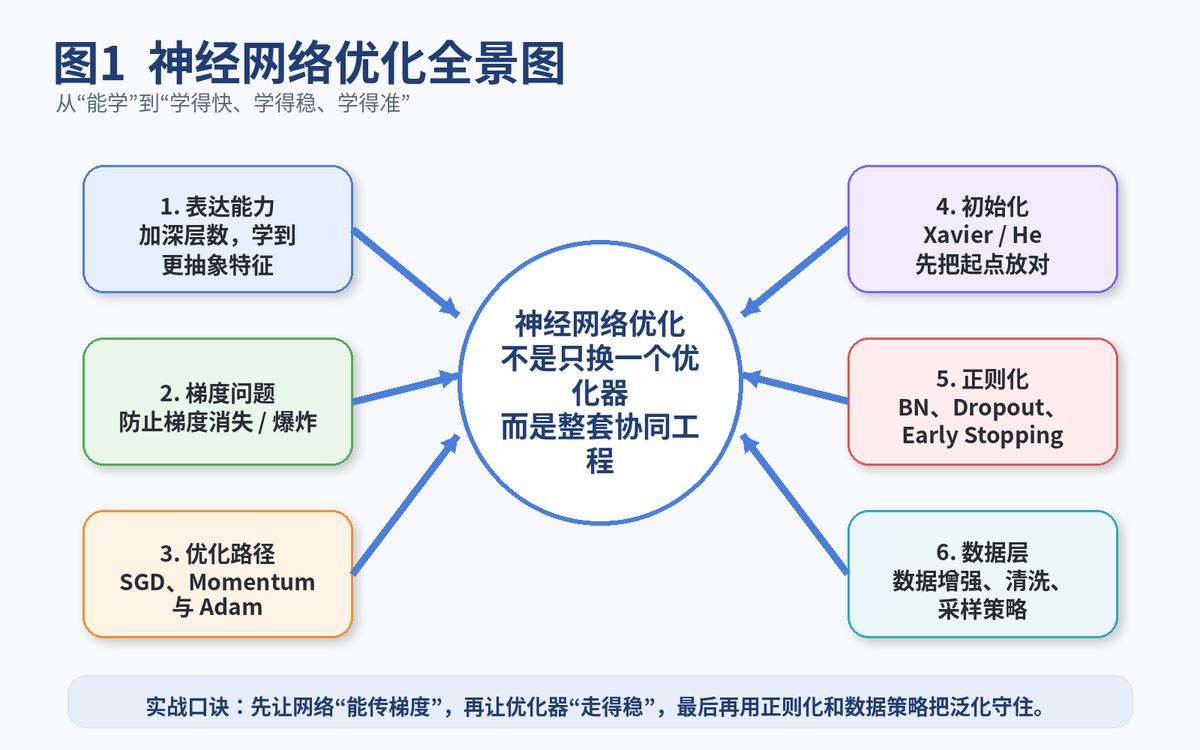
很多人一提"神经网络优化",第一反应就是:换 Adam、调学习率。这只说对了一小半。 真正的优化,是从网络结构、梯度传递、初始化、优化器、归一化、正则化到数据增强的一整套配合。
这道题在面试里特别容易被连续追问:为什么深层网络更难训练?什么是梯度消失和爆炸?Momentum 为什么能加速?Adam 和 SGD 怎么选?为什么不能把权重全初始化为 0?BatchNorm 和 Dropout 在训练与测试时分别做了什么?
这篇文章不走公式堆砌路线,而是把这些知识点拆成"能听懂、能记住、能复述"的版本。你看完之后,既能写文章,也能直接拿去回答面试。
1. 什么叫神经网络的优化
先把"优化"这两个字掰开看。它至少包含三层意思。
第一层:让模型真的学到东西,也就是 loss 能往下掉。
第二层:让模型学得稳,不要今天降、明天炸,甚至一会儿出现 NaN。
第三层:让模型学出来的东西能泛化,不只是把训练集背下来。
所以,优化从来不只是"找一个更厉害的 optimizer"。优化的本质,是让参数更新这件事既能推进,又不失控,还能兼顾泛化。
面试里如果你上来就说"我一般用 Adam",会显得太窄。更稳的答法是:神经网络优化是一个系统工程,核心包括结构设计、梯度传播、参数初始化、优化器、正则化和数据策略。
1.1 为什么要加深神经网络的层数
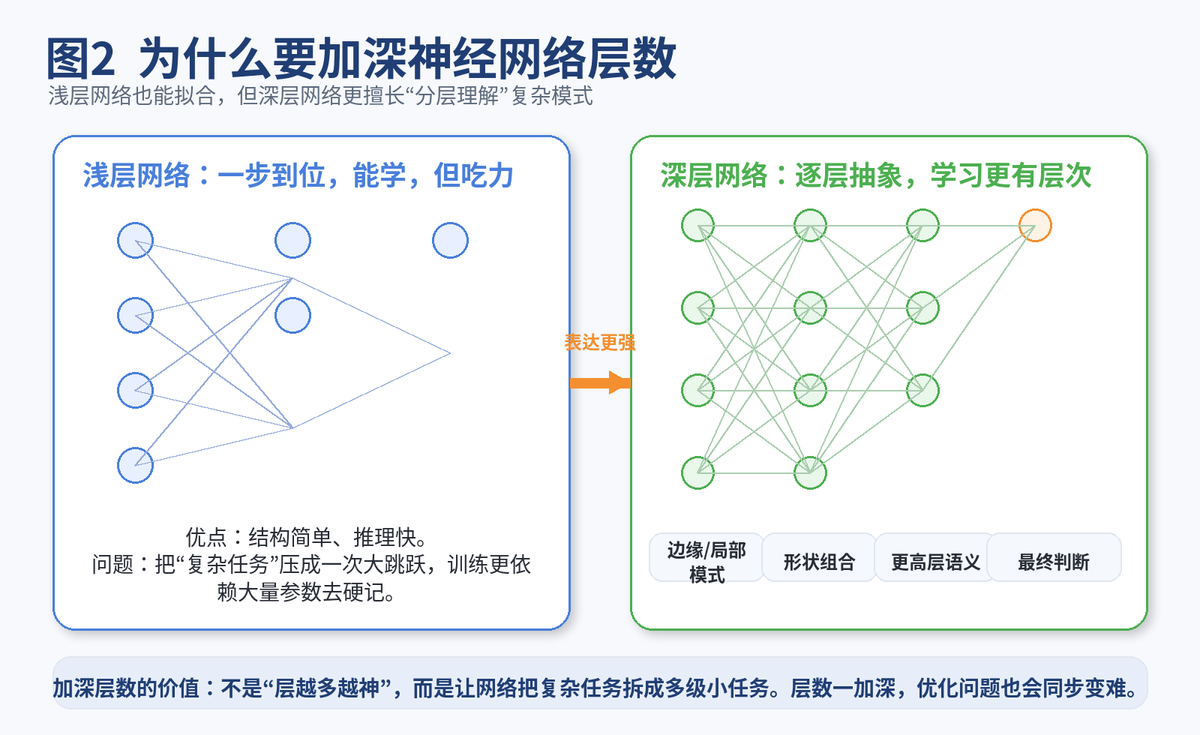
浅层网络不是不能做事,而是它更像"用一层大力出奇迹"。碰到复杂任务时,它往往要靠很多参数硬凑。
深层网络的价值,在于它会"逐层抽象"。前面几层先学局部模式,中间几层把局部模式拼成更复杂结构,后面几层再做高层语义判断。
这就是为什么在图像里,前层可能学边缘,中层学纹理和形状,后层学物体;在文本里,前层可能感知词法和局部搭配,后层再组合成句义和任务相关表示。
一句话概括:
加深层数的意义,不是为了"堆层数",而是为了让复杂任务被拆成多级特征加工。
1.2 为什么层数一深,训练就容易出问题
原因很简单:网络一深,反向传播的梯度要穿过很多层。每穿一层,梯度都要乘上一些导数和权重。乘的次数多了,就容易出现两种极端:
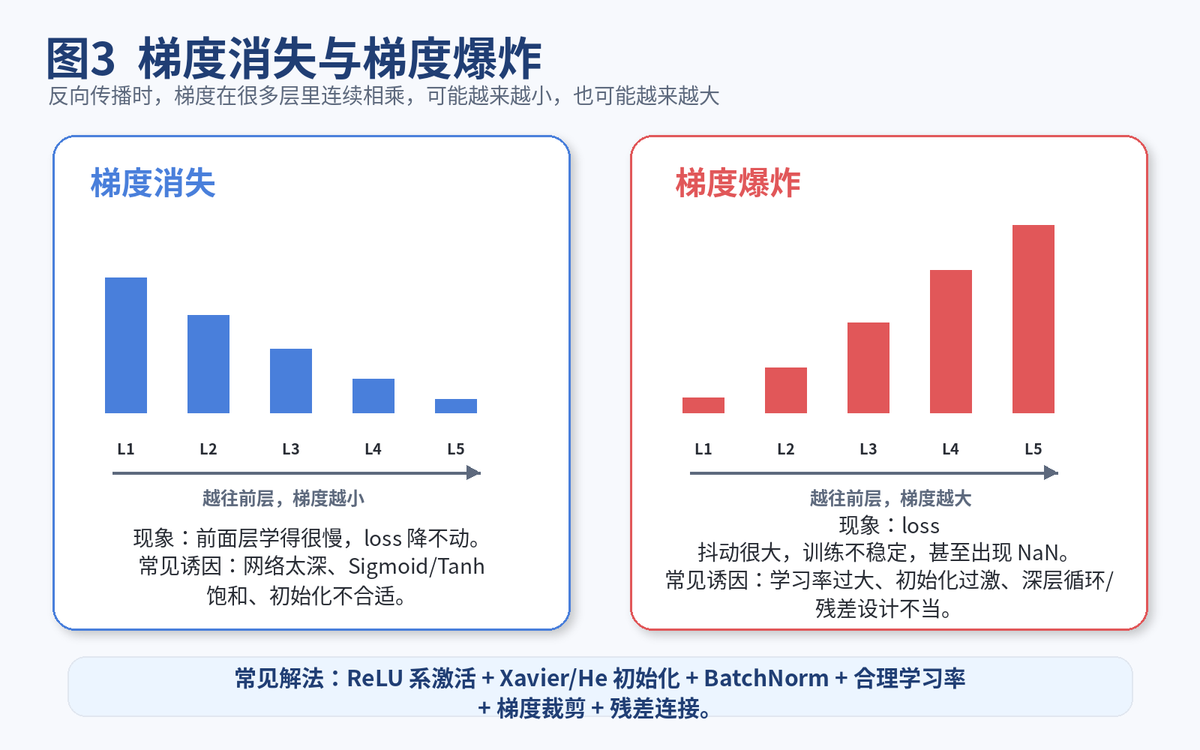
越来越小,最后小到几乎传不回去,这叫梯度消失。
越来越大,最后大到更新失控,这叫梯度爆炸。
所以,深层网络带来更强表达能力的同时,也把优化难度一起抬高了。这就是深度学习里最经典的矛盾之一:网络越深,潜力越大;但网络越深,也越难训。
2. 什么是梯度消失和梯度爆炸?怎么解决
先讲最通俗的版本。梯度可以理解为"下一步该往哪里走、走多大"的信号。
如果这个信号在往前层传的时候越来越弱,前面的层就几乎收不到学习指令;如果这个信号越传越大,参数更新就会过猛,训练曲线会剧烈震荡。
它们的典型表现如下:
梯度消失:loss 降得很慢,前层几乎学不动,深层网络越深越明显。
梯度爆炸:loss 大幅波动,参数更新很猛,严重时会直接出现 inf 或 NaN。
2.1 梯度消失/爆炸为什么会出现
最常见的根源有四类。
激活函数问题:像 Sigmoid、Tanh 在饱和区导数很小,深层叠加后更容易把梯度压没。
初始化问题:如果初始权重尺度不合适,信号一开始就在层间不断缩小或放大。
学习率问题:学习率太大,更新会失控,更容易放大训练震荡。
网络本身太深或结构设计不合理:层数多、残差设计不足、循环链太长时,问题会更明显。
2.2 常见解决方案
解决思路可以概括成一句话:
让梯度"传得回去",而且"别传炸"。
优先使用 ReLU 家族激活。它在正半轴不容易像 Sigmoid 那样进入饱和区。
用合适的初始化。ReLU 网络常配 He 初始化;更传统的对称场景常见 Xavier。
用 BatchNorm 或其他归一化手段,稳定中间层分布。
把学习率设得合理,并配合学习率衰减。
必要时使用梯度裁剪,尤其是在 RNN、大模型或训练明显不稳定时。
更深的网络中加入残差连接,让信息和梯度拥有更短路径。
3. 神经网络为什么不太怕"局部最小值",却很怕"鞍点和平台区"
很多面试题会问:深度学习是不是容易陷入局部最小值?
更实战的回答是:
现代深层网络里,真正最麻烦的往往不是"掉进一个很差的局部最小值",而是鞍点、平坦区域、狭长谷地,以及由此带来的优化停滞和震荡。
因为参数空间维度非常高,很多地方看起来像"最低点",其实只是某些方向低、某些方向高。模型在这里会表现为:梯度很小、下降很慢、训练像卡住一样。
为什么 mini-batch SGD、Momentum、Adam 这些方法有用?因为它们不是"死板地一步一步往前挪",而是在噪声、惯性、历史统计的帮助下,更容易摆脱这种停滞状态。
面试里说到这里,会比只背"局部最优不重要"要高级得多。
4. 梯度下降有哪些常见形式?区别是什么
这部分是基础题,但也是后面讲 Momentum 和 Adam 的前提。
|--------|-------------|------------------|--------------------|
| 方法 | 每次用多少样本 | 优点 | 缺点 |
| BGD | 全量样本 | 方向最稳定 | 每次更新太慢,数据大时成本高 |
| SGD | 1 个样本 | 更新快,有噪声,能帮助跳出停滞区 | 震荡大,不够稳 |
| MBGD | 一小批样本 | 速度和稳定性折中,深度学习最常用 | batch 太小或太大都可能有副作用 |
真正训练神经网络时,最常见的是小批量梯度下降,也就是 Mini-Batch。因为它兼顾了计算效率、GPU 并行能力和训练稳定性。
4.1 Momentum 为什么能加速收敛
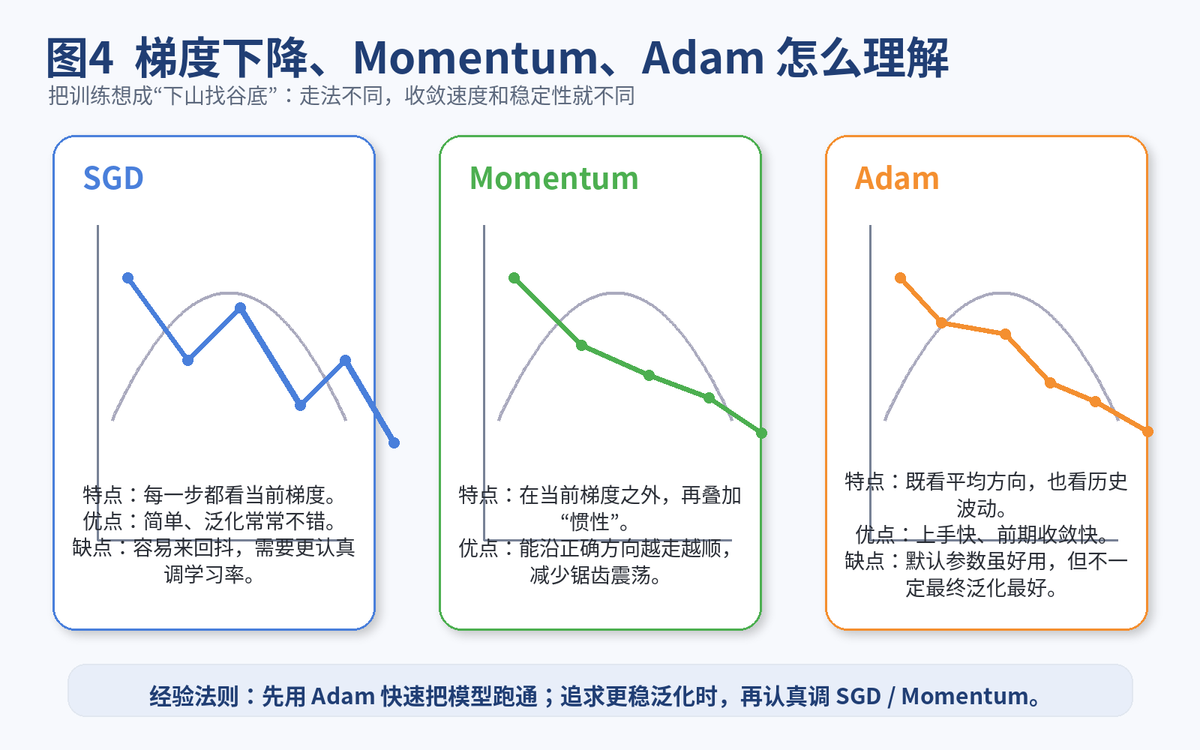
SGD 的典型问题,是在狭长谷地里左右来回摆,明明大方向对了,却总在局部抖。
Momentum 的思路,就是把"上一步、上上步"的趋势也记下来。你可以把它理解成给小球加了惯性:
如果连续几步方向差不多,Momentum 会越滚越顺,前进更快。
如果当前梯度只是局部抖动,惯性会帮你把无效摆动压下去。
所以 Keras 官方文档会直接把 momentum 描述为:能沿相关方向加速梯度下降,并抑制震荡。
4.2 Adam 在实际中常用吗?与 SGD 相比有什么优势
很常用。尤其是在你还没完全摸透任务时,Adam 往往是一个非常友好的起点。
Adam 的核心思想,不是只看"当前梯度往哪走",而是同时记两件事:
第一,平均方向是什么,也就是一阶动量。
第二,最近波动有多大,也就是二阶统计。
这样做的好处是:不同参数可以自动得到不同尺度的更新,训练前期通常更容易收敛。
但这不等于 Adam 永远最好。很多视觉任务、很多追求极致最终精度的场景里,认真调过学习率和衰减策略的 SGD / Momentum,最终泛化可能更强。
所以实战里常见的经验是:
先用 Adam 快速验证模型和数据流程能不能跑通。
再视任务目标,决定是否切换到 SGD / Momentum 去"打磨最后一截性能"。

5. 权重初始化为什么重要?为什么不能全初始化为 0
这是面试非常爱问的一题。
如果把所有权重都初始化为 0,会出现一个核心问题:
对称性。 也就是说,同一层的神经元从初始状态到后续更新,都会做出完全一样的反应。
结果就是:这一层虽然看起来有很多神经元,但它们没有真正"分工",等于白搭。
所以,权重初始化至少要做到两件事:
打破对称,让不同神经元学到不同东西。
控制尺度,让信号和梯度在层间传播时别过大也别过小。
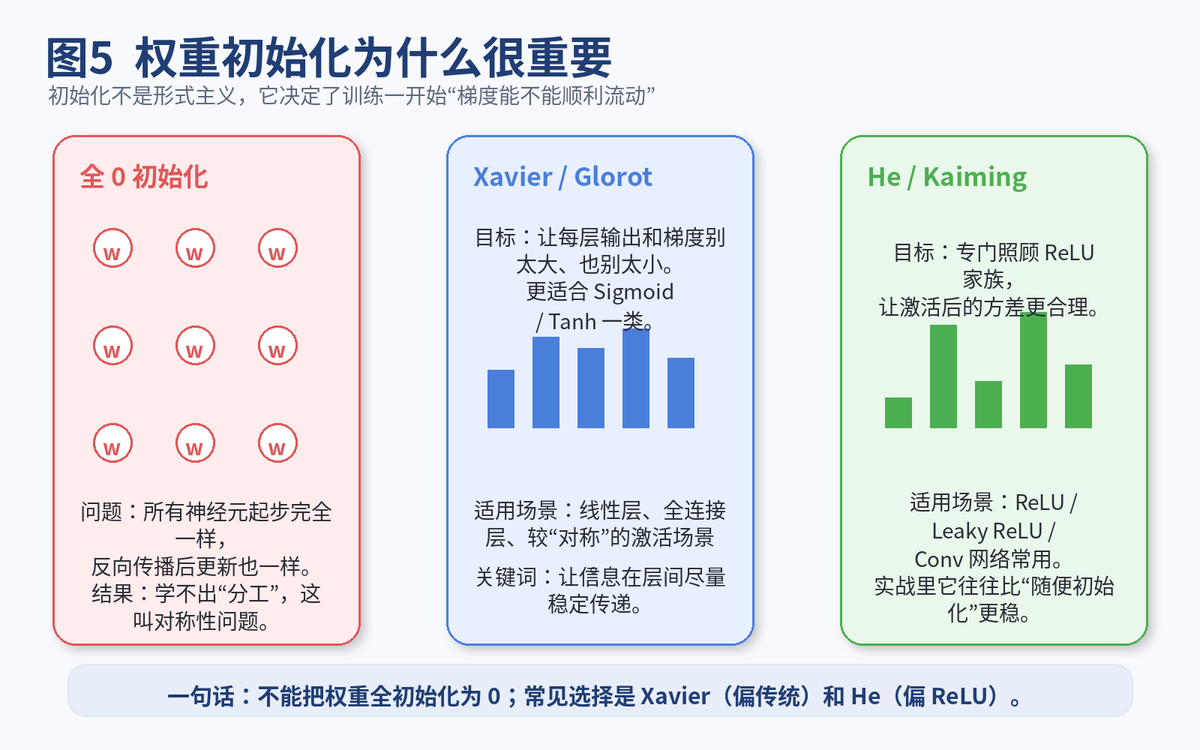
5.1 常见初始化方法有哪些
如果你只记两种,面试就够用了。
Xavier / Glorot:目标是让信号在层间传播时相对稳定,传统全连接网络里很常见。
He / Kaiming:更偏向 ReLU 家族,通常更适合现代 CNN / MLP 中常见的 ReLU 激活。
PyTorch 官方初始化工具里就直接提供了 Xavier 和 Kaiming 这两大家族。
你在面试里可以这样答:如果隐藏层主要是 ReLU,我更优先考虑 He 初始化;如果是更传统的对称激活场景,Xavier 也很常见。
6. Batch Normalization(BN)是什么?为什么有用
BatchNorm 可以理解为:在训练过程中,把某一层的输出先拉回到更稳定的分布,再交给下一层。
它最直观的价值有三个。
第一,训练更稳。
第二,允许你用相对更积极的学习率。
第三,在一定程度上减轻初始化和梯度传播带来的压力。
注意,BN 不是"万能加速器"。它更像一个让训练流程更顺手的稳定器。
6.1 BN 在训练和测试时有什么区别
这是高频追问。回答一定要清楚:
训练时:BN 用当前 mini-batch 的均值和方差做归一化,并同步更新滑动统计量。
推理时:BN 不再依赖当前 batch,而是使用训练阶段累计下来的 running mean 和 running variance。
所以 BN 在训练和测试阶段的行为并不一样。Keras 官方文档也专门强调了这一点。
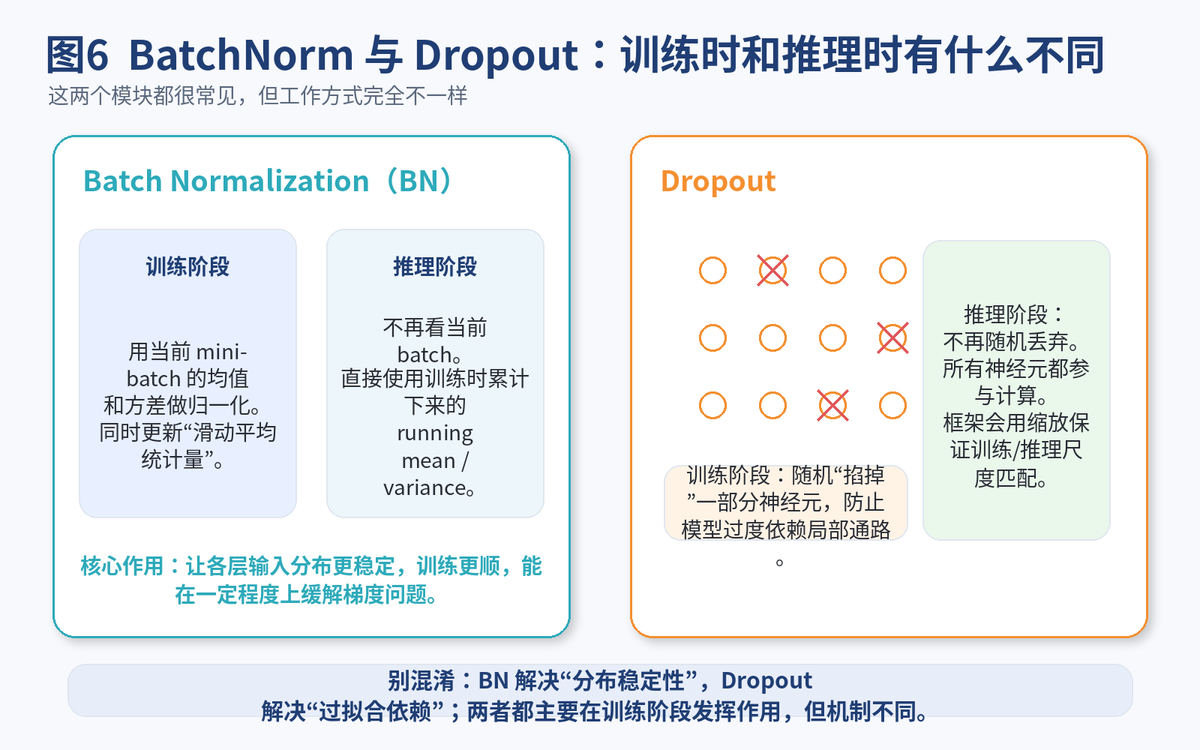
7. Dropout 的原理是什么?训练和测试时有何区别
Dropout 的思路特别好记:训练时,随机让一部分神经元临时下线。
这么做的目的,是不让模型过度依赖某几条固定通路,从而减轻过拟合。
它的核心机制有两个。
训练时:按设定概率随机置零一部分单元。
推理时:不再丢弃神经元,全部正常参与计算。
Keras 文档里明确写到,Dropout 只会在 training=True 的时候生效,推理阶段不会再随机丢弃。
面试时你还可以补一句:Dropout 更像在"打散依赖关系",BN 更像在"稳定分布";两者目标不同,不要混为一谈。
8. 什么是数据增强?为什么它也属于优化技巧
很多人把数据增强只看成"数据处理"。其实从训练角度看,它也是非常重要的优化工具。
原因在于:模型过拟合,本质上 often 是训练样本覆盖不够。TensorFlow 官方教程也反复强调,数据更完整、更能覆盖真实输入分布,模型自然更容易泛化。
当你没有更多真数据时,数据增强就是在"现有数据上造多样性"。
图像里常见:翻转、裁剪、旋转、缩放、颜色扰动、随机擦除。
文本里常见:噪声注入、同义改写、回译、样本混合。
语音里常见:加噪、时间偏移、变速。
它的核心目标不是"把数据改花哨",而是让模型见到更丰富但仍合理的样本变化。
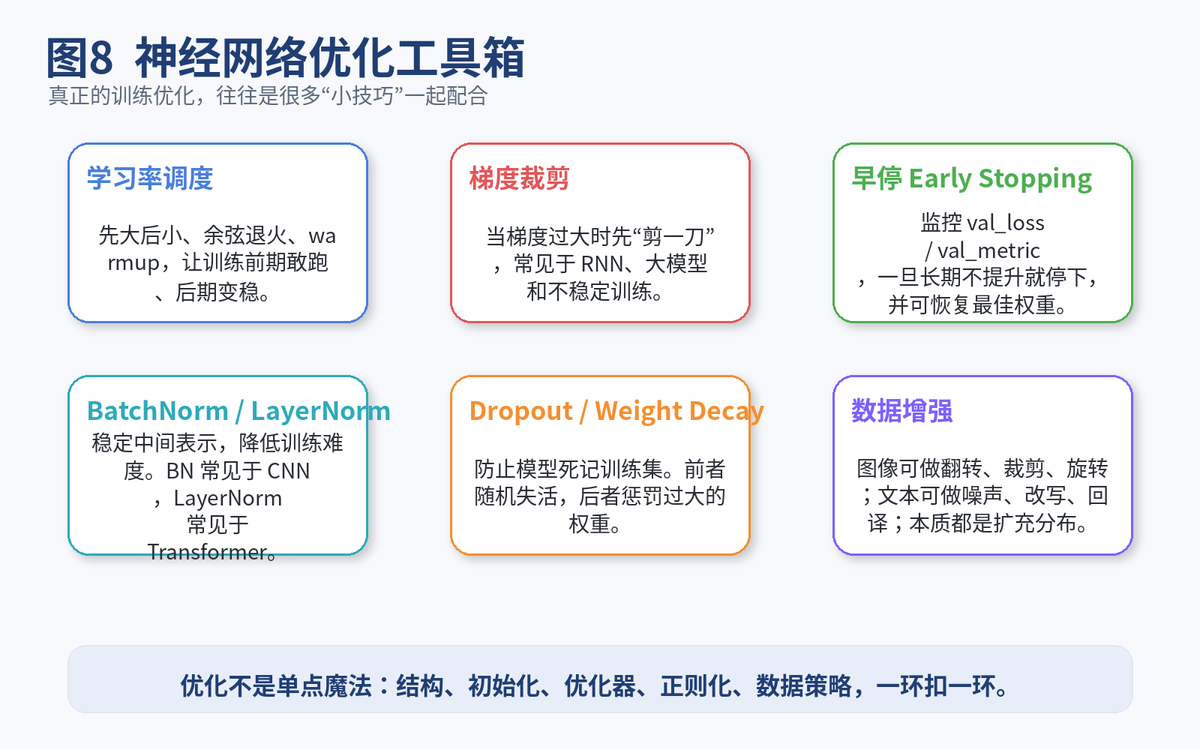
9. 神经网络中还有哪些常见优化技巧
如果你想把这题答得更完整,可以再补上下面这些关键词。
学习率调度:比如 step decay、cosine decay、warmup。前期敢跑,后期变稳。
Early Stopping:监控验证集指标,一旦长期不提升就停止训练,必要时恢复最佳权重。
梯度裁剪:当梯度过大时,先把它截住,避免更新失控。
Weight Decay:限制权重无限变大,是常见正则化手段。
残差连接:给梯度更短的通路,深层网络尤其受益。
如果面试官继续追问,你甚至可以给出一条典型训练闭环:
先用合适的初始化把起点放对。
用 ReLU 家族激活和 BN 保证梯度更容易传递。
用 Mini-Batch + Adam 先把模型快速跑通。
观察训练/验证曲线,再配合学习率调度、Dropout、数据增强、Early Stopping 做泛化优化。
如果追求更强最终效果,再试 SGD / Momentum 细调。
10. 面试里怎么把这题答得像"会做事的人"
下面给你一个可直接复述的高分模板。
神经网络优化不是只换一个优化器,而是一个系统工程。加深层数能提升表达能力,但也会带来梯度消失和爆炸,所以需要用 ReLU、合适的初始化、BatchNorm、残差连接等手段保证梯度稳定。训练时通常采用 Mini-Batch 梯度下降;如果想更快跑通模型,常先用 Adam;如果追求更强泛化和最终精度,再认真调 SGD / Momentum。除此之外,还要结合 Dropout、Weight Decay、Early Stopping、数据增强和学习率调度,整体提升训练稳定性和泛化能力。
这段话的好处是:覆盖了结构、梯度、初始化、优化器、正则化和数据策略六个维度,面试官很容易感受到你不是只会背名词。
11. 总结
把整篇文章压缩成四句话。
第一,神经网络之所以要加深层数,是为了做层级特征抽象。
第二,网络一深,训练就容易遇到梯度消失、梯度爆炸、鞍点和震荡。
第三,优化的核心不只是 Adam 或 SGD,而是初始化、结构、归一化、正则化、学习率和数据策略的联动。
第四,真正的训练技巧不是"记一个神招",而是根据任务阶段,用合适的组合拳。
一句话收尾:神经网络优化,拼的不是某一个参数,而是整套训练系统是否协同。