Deepseek

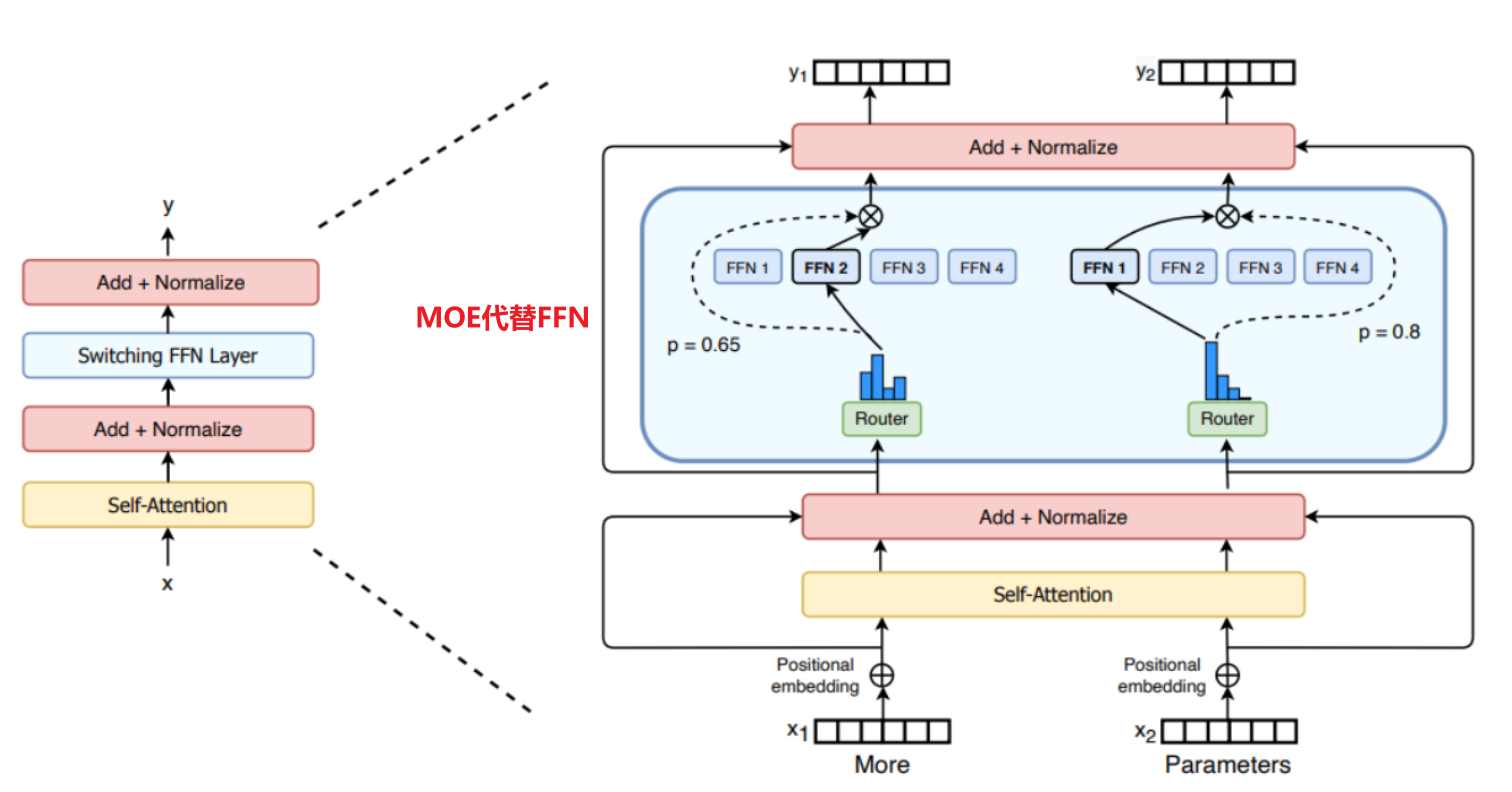
MOE(Mixture of Experts) - 混合专家模型
MOE是什么: 一种模型架构设计。它不是用一个巨大的神经网络处理所有任务,而是内置了很多个"小专家网络"(每个擅长不同领域,如编程、历史、数学等)。对于每个输入的问题,一个**"路由网络"**会判断这个问题应该交给哪几个最相关的专家来处理,然后把它们的输出组合起来
主要目的: 在保持模型能力的同时,大幅提升计算效率、降低成本和能耗。因为每次计算只动用一部分参数,而不是全部
核心优势(1)参数规模与计算量解耦 :你可以将模型的总参数量做得极大(比如万亿级别),但每次推理的计算量(FLOPs)只相当于一个小模型(只激活了K个专家),打破了"模型越大,计算越慢"的壁垒
(2)更强的模型能力与专业性 :专家们可以"分而治之",各自专注于学习数据中不同的模式和领域,从而让整体模型的知识覆盖更广、更深入
(3)更低的训练与推理成本:训练时,可以通过条件计算节省算力。推理时,内存和计算需求远小于同等能力的密集模型,部署成本更低
挑战(1)负载均衡问题 :如果路由网络总是把任务分给少数几个热门专家(如"编程专家"),其他专家就得不到训练,成为"懒专家",最终导致模型能力下降
解决方案 :在训练时引入负载均衡损失,惩罚那些分配不均的路由决策,鼓励均匀使用所有专家(2)路由网络的训练难度 :路由网络和专家网络需要协同训练。如何让路由学会做出精准的判断,本身就是一个复杂的优化问题
(3)通信开销 :在分布式训练或部署中,需要根据路由决策,将数据在不同专家所在的设备间传输,可能带来通信瓶颈。
解决方案:精心设计系统,将专家合理地分布在不同的GPU或计算节点上。
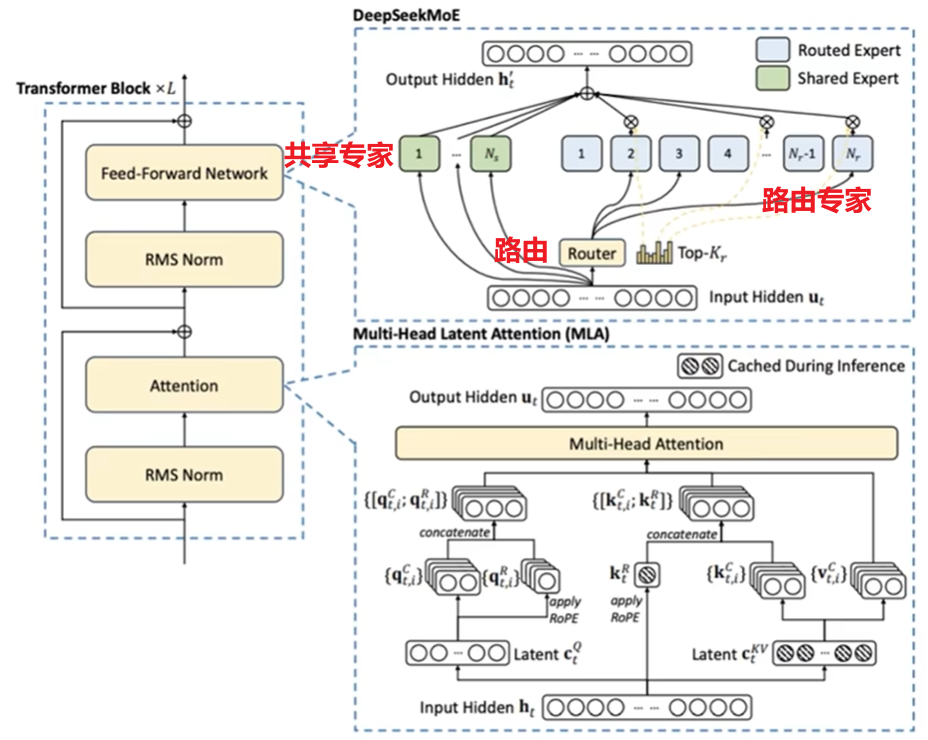

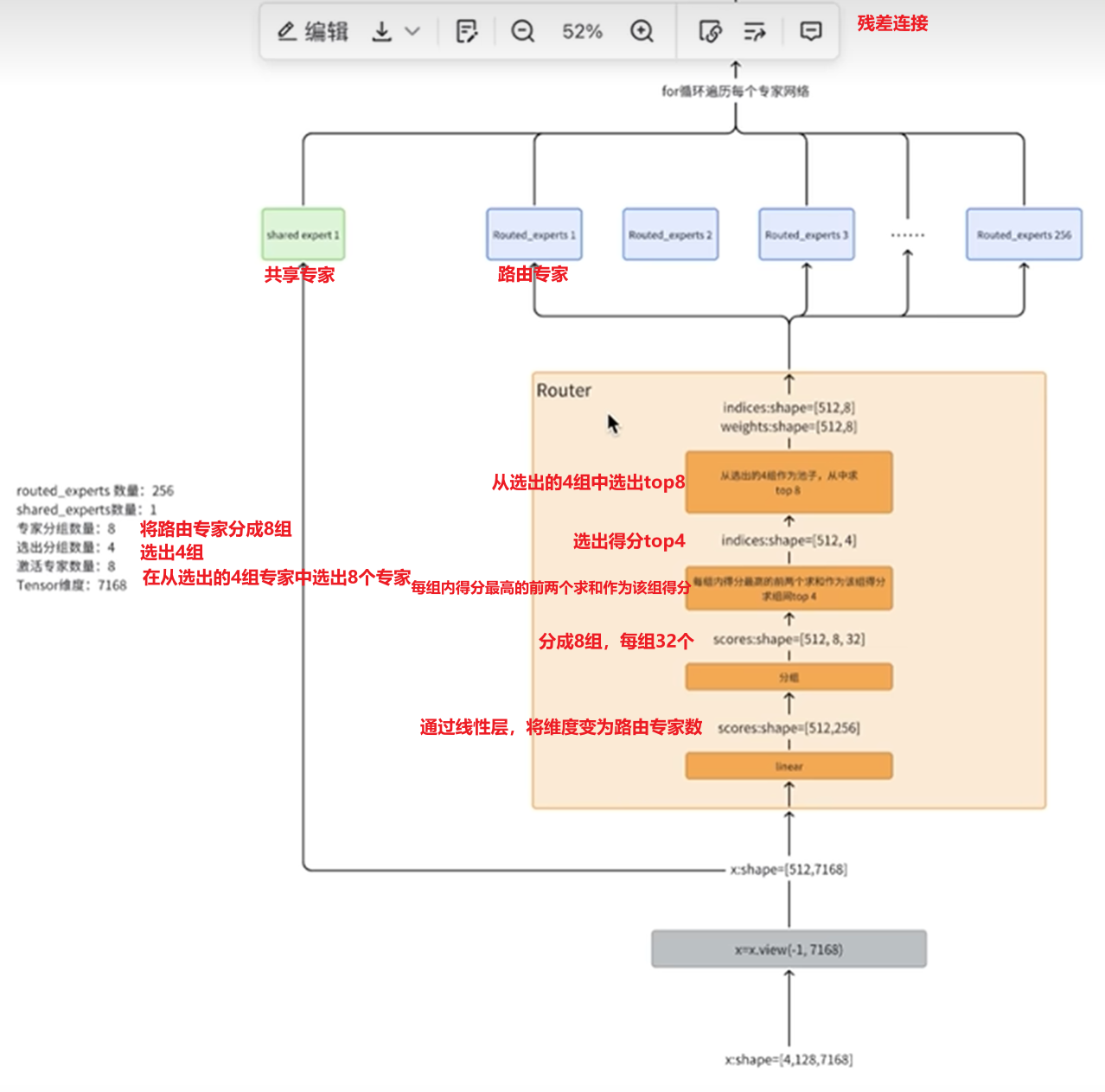
MLA (Multi-head Latent Attention) - 多头潜在注意力
MLA是什么: 一种改进的注意力机制。它是传统"多头注意力"的升级版,旨在解决处理超长文本(比如一本书)时内存和计算量爆炸性增长的问题
核心思想 :不直接对海量的原始文本token(词元)进行两两计算注意力,而是先通过压缩,生成一组数量固定、高度抽象的"潜在表示"(可以理解为"摘要"或"关键概念")。注意力主要在这些"潜在表示"之间计算,从而极大地降低了计算复杂度(标准注意力 1.54 亿,MLA 仅 1660 万,少了 90% 参数)
主要目的: 突破模型上下文窗口的长度限制,使其能够高效处理数十万甚至百万token的超长文本。
典型代表: DeepSeek-V2 中首次提出并应用了MLA

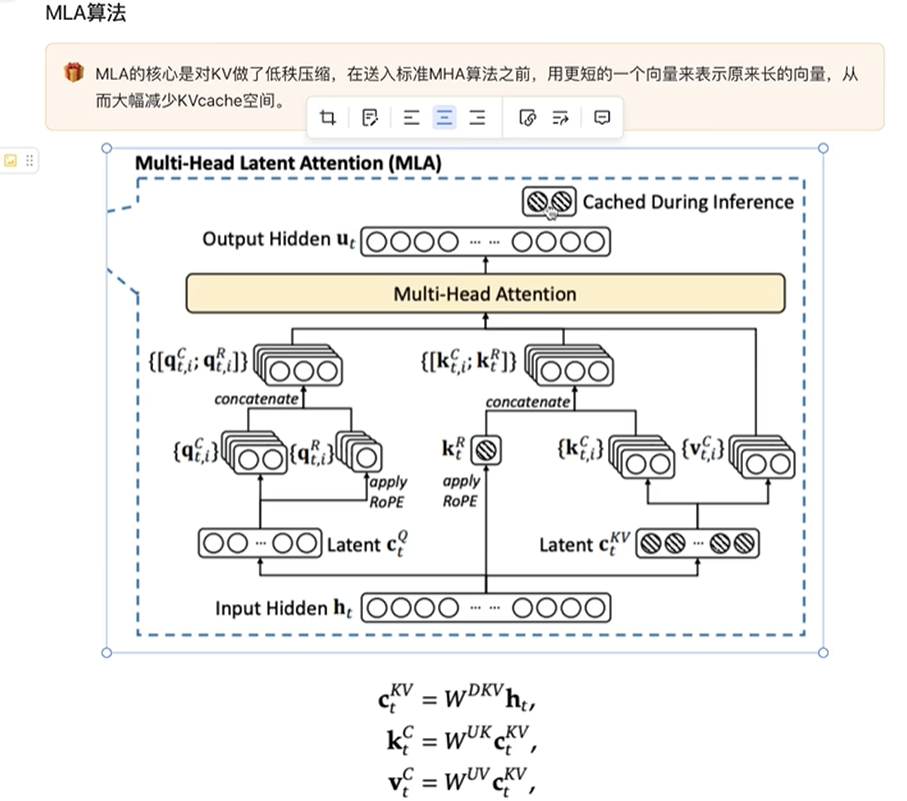
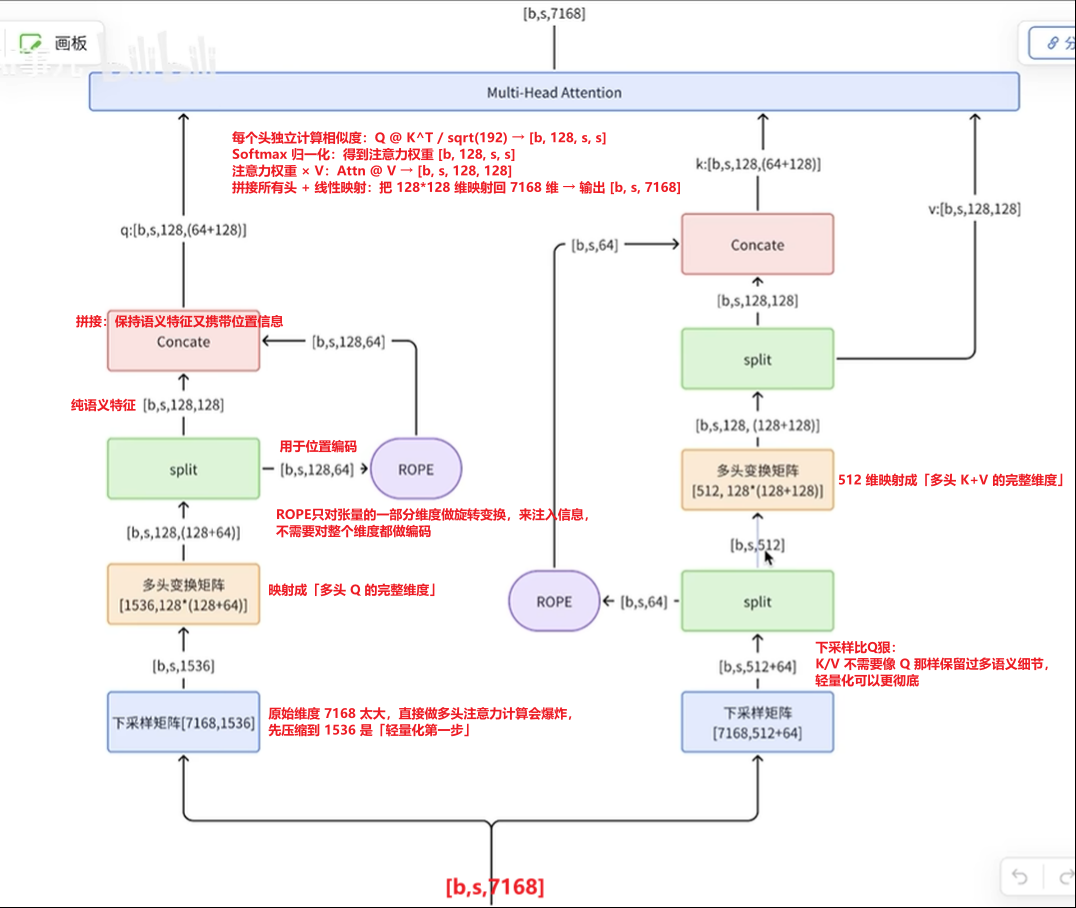
🌱语义与位置解耦,互不干扰:语义特征(Q 的 128 维、K/V 的 128 维)全程不做任何变换,只参与线性映射和注意力计算,保证语义信息完整传递。位置信息只在 64 维上做 ROPE,不会污染语义特征,也不会丢失位置信号
🌱下采样是「线性可逆」的 :下采样矩阵是可学习的线性层,只要维度足够(Q 到 1536,K/V 到 576),就能在训练中学习到「高维输入到低维特征」的最优映射,不会丢失关键信息。最后注意力输出时,会再线性映射回 7168 维,相当于「先压缩再解压」,信息在压缩阶段被保留,解压后恢复
🌱embedding 的高维是容量,不是信息量,有效语义天然低秩(有效秩通常只有几百) ,可以安全压缩 MLA🌱用可学习投影(
自动学习一个最优投影,只保留语义信息,丢掉冗余) + 注意力聚合 + 重建升维,完美保留所有语义
🌱注意力机制本身是「信息聚合」的标准多头注意力是「信息分散」到多个头,而 MLA 是「信息压缩(提取有效信息)后再聚合」。因为 K/V 维度更小,注意力计算更高效,同时每个头都能捕捉到完整的语义 + 位置信息,最终聚合时能把分散的信息重新组合成原始维度的特征,不会丢失
🎯MLA 就是 「先把高维输入做不对称下采样,再拆分出语义和位置维度,给位置维度单独进行ROPE,最后拼回去做轻量多头注意力」,既减少了计算量,又通过「语义位置解耦 + 线性可逆下采样 + 注意力聚合」保证了信息不会丢失
KVCache
1.传统KVCache
假设我们要生成句子:"The cat sat on the"
python
没有KVCache的情况:
步骤1: 输入"The" → 计算"The"的K,V → 输出"cat"
步骤2: 输入"The cat" → 重新计算"The"和"cat"的K,V → 输出"sat"
步骤3: 输入"The cat sat" → 重新计算所有token的K,V → 输出"on"
步骤4: 输入"The cat sat on" → 重新计算所有token的K,V → 输出"the"
python
有KVCache的情况:
步骤1: 输入"The" → 计算"The"的K,V → 缓存K1,V1 → 输出"cat"
步骤2: 输入"cat" → 计算"cat"的K,V → 缓存K2,V2 → 注意力计算使用[K1,K2]和[V1,V2] → 输出"sat"
步骤3: 输入"sat" → 计算"sat"的K,V → 缓存K3,V3 → 注意力计算使用[K1,K2,K3]和[V1,V2,V3] → 输出"on"
步骤4: 输入"on" → 计算"on"的K,V → 缓存K4,V4 → 注意力计算使用[K1,K2,K3,K4]和[V1,V2,V3,V4] → 输出"the"
python
import torch
import torch.nn as nn
class AttentionWithKVCache(nn.Module):
def __init__(self, d_model=512, n_heads=8):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.head_dim = d_model // n_heads
# 投影矩阵
self.Wq = nn.Linear(d_model, d_model)
self.Wk = nn.Linear(d_model, d_model)
self.Wv = nn.Linear(d_model, d_model)
self.Wo = nn.Linear(d_model, d_model)
def forward(self, x, past_kv_cache=None):
"""
x: 当前输入token [batch_size, seq_len=1, d_model]
past_kv_cache: 之前的K,V缓存 [2, batch, n_heads, past_len, head_dim]
K,V缓存分别存在两个数组中,past_len为之前缓存的k,v个数
"""
batch_size = x.shape[0]
# 计算当前token的Q,K,V
Q = self.Wq(x) # [batch, 1, d_model]
K = self.Wk(x) # [batch, 1, d_model]
V = self.Wv(x) # [batch, 1, d_model]
# 重塑为多头
Q = Q.view(batch_size, 1, self.n_heads, self.head_dim).transpose(1, 2)
K = K.view(batch_size, 1, self.n_heads, self.head_dim).transpose(1, 2)
V = V.view(batch_size, 1, self.n_heads, self.head_dim).transpose(1, 2)
# 如果有缓存,拼接
if past_kv_cache is not None:
past_K, past_V = past_kv_cache
K = torch.cat([past_K, K], dim=2) # 沿序列维度拼接
V = torch.cat([past_V, V], dim=2)
# 计算注意力
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn = torch.softmax(scores, dim=-1)
output = torch.matmul(attn, V)
# 重塑输出
output = output.transpose(1, 2).contiguous().view(batch_size, 1, self.d_model)
output = self.Wo(output)
# 更新缓存(包含所有K,V)
new_kv_cache = (K, V)
return output, new_kv_cache
# 使用示例
attn = AttentionWithKVCache()
x = torch.randn(1, 1, 512) # batch=1, seq_len=1, d_model=5122.MLA中的KVCache
🌱 MLA KVCache在存储完整K/V向量的同时,额外存储一个
低维的L向量作为"语义摘要",在计算注意力时先用低维L快速筛选相关历史token,再用筛选结果压缩完整K/V进行精确计算,从而大幅减少计算量
🌱 低维L向量是通过一个专门的线性投影层(通常称为 W l W_l Wl)将原始的K向量压缩得到的,这个投影层将高维的键向量(如64维)映射到低维的潜在空间(如8维),保留了最关键的语义和语法特征用于快速相似度计算
python
每个token缓存三样东西:
1. K: 完整的键向量 [head_dim维]
2. V: 完整的值向量 [head_dim维]
3. L: 对K进行压缩的潜在向量 [latent_size维,通常更小]
python
for 每个新token:
# 步骤1:计算当前token的Q, K, V, L
Q_new = 计算当前查询
K_new, V_new = 计算键值
L_new = compress(K_new) # 压缩到低维
# 步骤2:更新缓存
K_cache.append(K_new)
V_cache.append(V_new)
L_cache.append(L_new)
# 步骤3:MLA注意力计算
# a) 用L_cache快速计算注意力权重
Q_proj = compress(Q_new) # 投影到L空间
weights = softmax(Q_proj @ L_cache^T) # 低维计算
# b) 用权重压缩K_cache和V_cache
compressed_K = Σ(weights_i × K_cache[i])
compressed_V = Σ(weights_i × V_cache[i])
# c) 最终计算(高维但只计算一次)
attn_score = Q_new @ compressed_K^T
output = attn_score × compressed_V
python
例如当前Q3 = [0.0, 0.0, 0.3, 0.7]
Q3_proj = Q3 @ W_l.T = [0.0, 0.5]
历史L_cache = [[0.9, 0.0], # "The"
[0.1, 0.5], # "cat"
[0.0, 0.5]] # "sat"
# 计算相似度:
sim1 = Q3_proj · L1 = 0.0×0.9 + 0.5×0.0 = 0.0
sim2 = Q3_proj · L2 = 0.0×0.1 + 0.5×0.5 = 0.25
sim3 = Q3_proj · L3 = 0.0×0.0 + 0.5×0.5 = 0.25
weights = softmax([0.0, 0.25, 0.25]) ≈ [0.2, 0.4, 0.4]
#compressed_V步骤相同
compressed_K = 0.2×K1 + 0.4×K2 + 0.4×K3
= [0.2×1.0 + 0.4×0.0 + 0.4×0.0, # 0.2
0.2×0.0 + 0.4×1.0 + 0.4×0.0, # 0.4
0.2×0.0 + 0.4×0.8 + 0.4×0.3, # 0.44
0.2×0.0 + 0.4×0.2 + 0.4×0.7] # 0.36
= [0.2, 0.4, 0.44, 0.36]MTP(Multi Token Prediction) - 多词元预测


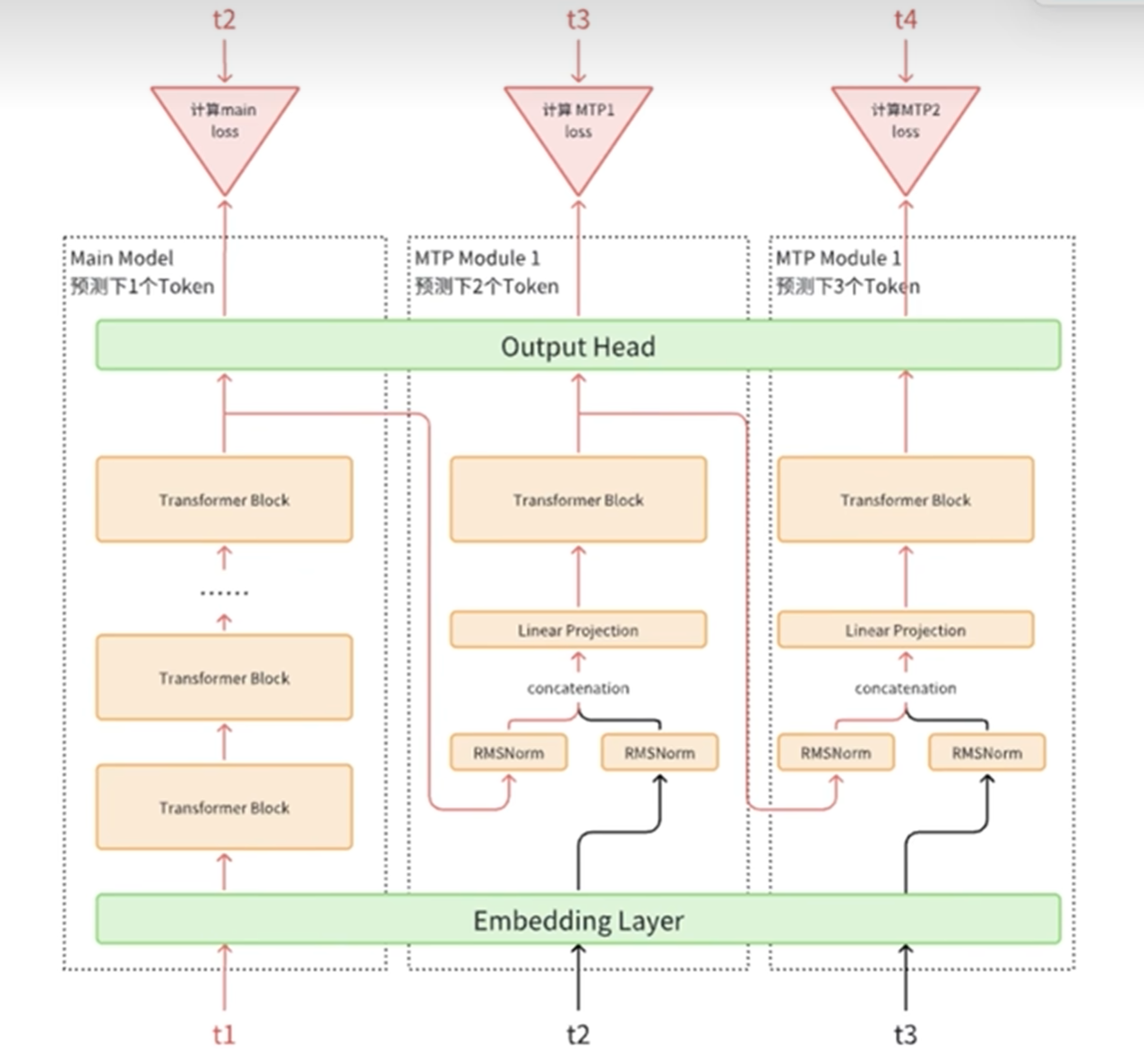
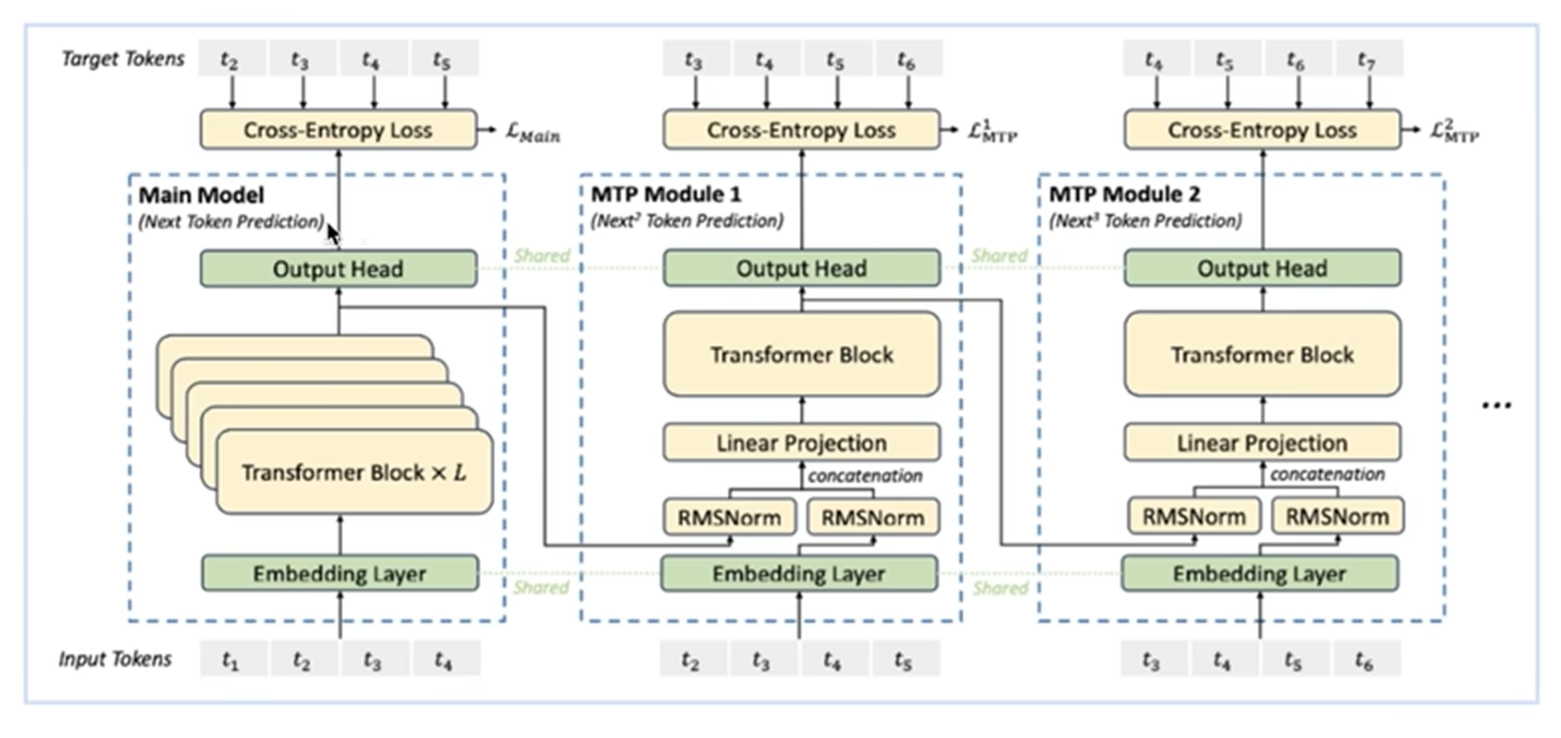
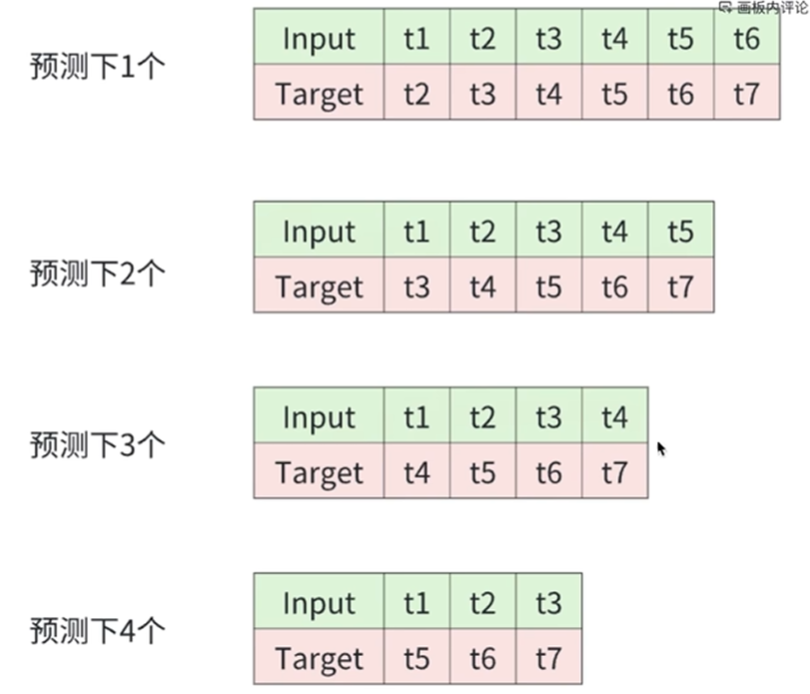

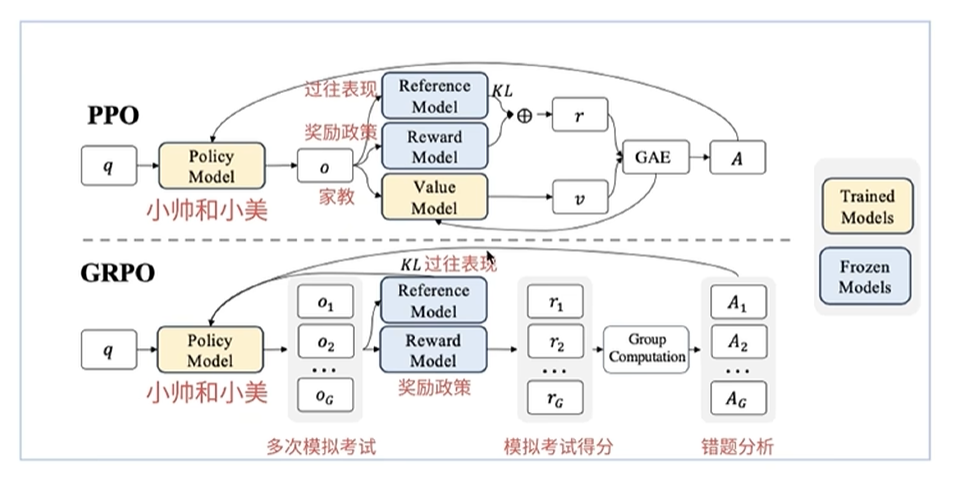
GRPO(Group Relative Policy Optimization) - 分组相对策略优化
GRPO是什么: 一种模型对齐和微调的方法,属于"基于人类反馈的强化学习" 范畴的简化版
核心思想 :对于一个提示词(问题),让模型生成一组(多个)不同的回答。不依赖复杂的人工标注或奖励模型打分,而是根据一个简单的、可自动计算的规则(例如:回答是否遵循了指令?是否更简洁?是否包含了关键词?)对这组回答进行两两比较和排序。根据这个组内的相对排名,来更新模型参数,鼓励模型生成排名更高的回答。
主要目的 : 以更低成本(节省训练Critic模型) 、更高效的方式让模型的行为与人类偏好对齐,使其回答更有用、更真实、更无害
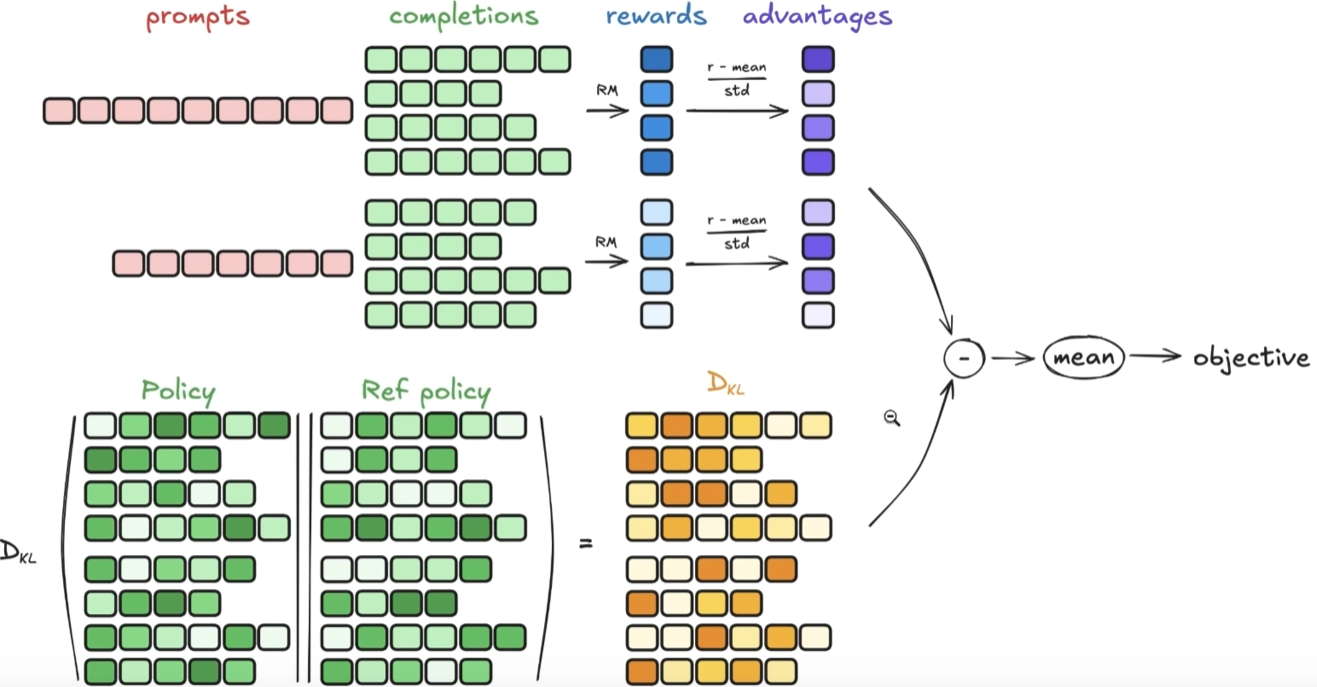
对于上图,一个answer的KL散度 = ∑每个token的KL散度值
问了deepseek,相较于"先减去KL散度,再标准化原始奖励"来说"
先标准化原始奖励,再减去KL惩罚"数值稳定性、训练稳定性、最终效果都更好
1. 模型定义
策略模型 : π p o l i c y π_{policy} πpolicy 正在训练的目标模型,用于生成回答并优化, 可训练,参数不断更新
参考模型 : π r e f π_{ref} πref 提供稳定的概率基线,用于计算 KL 散度, 模型参数永久冻结
奖励模型 : π r m π_{rm} πrm 为回答打分,输出标量质量分数,模型参数永久冻结,奖励模型为预训练模型或为规则函数
2.采样与分组
python
#对于每个prompt x,采样多个响应
#每个prompt作为一个独立的"组"
#组内响应相互比较,而不是跨prompt比较
prompt = "解释量子力学"
responses = [
y1 = "量子力学是...", # 响应1
y2 = "量子力学描述...", # 响应2
y3 = "在量子力学中...", # 响应3
... # 通常采样4-8个响应
]
#计算每个响应的原始奖励
rewards_raw = [R(x, y1), R(x, y2), R(x, y3), ...]3. 计算KL散度惩罚项
粒度转换:KL散度本质上是token级别的计算,需要聚合为序列级别
逐token计算:对于answer中的每个token位置,计算当前策略模型与参考模型在该位置预测分布的KL散度
序列聚合:将所有token位置的KL散度求和,得到整个answer序列的总KL散度
4.计算相对奖励(组内排名)
将绝对奖励通过标准化方法转换为组内相对奖励:对组内所有绝对奖励值进行标准化(减均值 μ μ μ,除标准差 σ σ σ)
相对奖励 R r e l a t i v e = ( 𝑅 − μ ) / σ R_{relative}= (𝑅 - μ)/σ Rrelative=(R−μ)/σ
5.奖励修正(KL散度融入)
将KL散度惩罚直接融入奖励计算中,得到优势函数:
A t = 𝑅 r e l a t i v e − 𝛽 ⋅ 𝐷 K L ( 𝜋 p o l i c y ( 𝑦 ∣ 𝑥 ) ∥ 𝜋 r e f ( 𝑦 ∣ 𝑥 ) ) A_t =𝑅_{relative}−𝛽⋅𝐷_{KL}(𝜋_{policy}(𝑦∣𝑥)∥𝜋_{ref}(𝑦∣𝑥)) At=Rrelative−𝛽⋅DKL(𝜋policy(y∣x)∥𝜋ref(y∣x))
𝑅 r e l a t i v e 𝑅_{relative} Rrelative:标准化后的相对奖励值𝛽:KL惩罚系数,控制约束强度,较大的β具有强约束,防止策略过度偏离参考模型;较小的β具有弱约束,更注重奖励最大化
𝐷 K L 𝐷_{KL} DKL:序列级KL散度
6.策略优化
计算优势函数 :
相对奖励可作为优势函数的估计
策略梯度更新 :使用PPO风格的裁剪机制更新策略参数
目标函数:最大化相对奖励,同时通过KL惩罚保持与参考模型的接近
r a t i o t = π n e w ( a t ∣ s t ) / π o l d ( a t ∣ s t ) = 训练后 p o l i c y 模型生成的 t o k e n 概率 / 训练前 p o l i c y 模型生成的 t o k e n 概率 ratio_t = π_{new}(a_t|s_t) /π_{old}(a_t|s_t) = 训练后policy模型生成的token概率/训练前policy模型生成的token概率 ratiot=πnew(at∣st)/πold(at∣st)=训练后policy模型生成的token概率/训练前policy模型生成的token概率
L G R P O = m i n ( r a t i o t × A t , c l i p ( r a t i o t , 1 − ε , 1 + ε ) × A t ) = m i n ( 概率比值 × 优势函数 , c l i p ( 概率比值 , 1 − ε , 1 + ε ) × 优势函数 ) L_{GRPO} = min(ratio_t × A_t, clip(ratio_t, 1-ε, 1+ε) × A_t) = min(概率比值 × 优势函数, clip(概率比值, 1-ε, 1+ε) × 优势函数) LGRPO=min(ratiot×At,clip(ratiot,1−ε,1+ε)×At)=min(概率比值×优势函数,clip(概率比值,1−ε,1+ε)×优势函数)
7. 迭代流程
整个训练过程按以下循环进行:
- 更新模型:当前轮训练结束后,将当前策略模型的参数复制给旧模型成为下一轮训练的起点
- 采样:使用更新后的旧模型,为每个提示词生成一组回答,存储数据
- 多次策略更新(通常 3~10 个 epoch):对于缓冲区中的数据,每次使用当前的策略模型计算概率,并根据存储的旧模型概率和参考模型概率计算 KL散度、修正奖励、优势,最后通过剪切目标更新策略模型
- 检查收敛