1. 上架测试代码
调用/api/product/spuinfo/11/up方法,将商品上架。
通过/mall_product/_doc/1可以查询到es中有上传的商品:
bash
{
"_index": "mall_product",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"skuId": 1,
"spuId": 11,
"skuTitle": "华为 HUAWEI Mate 30 Pro 星河银 8GB+256GB麒麟990旗舰芯片OLED环幕屏双4000万徕卡电影四摄4G全网通手机",
"skuPrice": 6299.0000,
"skuImg": "https://gulimall-hello.oss-cn-beijing.aliyuncs.com/2019-11-26/60e65a44-f943-4ed5-87c8-8cf90f403018_d511faab82abb34b.jpg",
"saleCount": 0,
"hasStock": false,
"hotScore": 0,
"brandId": 9,
"brandName": "华为",
"brandImg": "https://gulimall-hello.oss-cn-beijing.aliyuncs.com/2019-11-18/de2426bd-a689-41d0-865a-d45d1afa7cde_huawei.png",
"catalogName": "手机",
"attrs": [
{
"attrId": 15,
"attrName": "CPU品牌",
"attrValue": "海思(Hisilicon)"
},
{
"attrId": 16,
"attrName": "CPU型号",
"attrValue": "HUAWEI Kirin 970"
}
]
}
}2. 关于feign的调用流程
见:feign学习
3. 商城TOC页面开发
3.1 thymeleaf
- 导入thymeleaf依赖、热部署依赖devtools使页面实时生效:mall-product/pom.xml
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>- html\首页资源\index放到achangmall-product下的static文件夹,把index.html放到templates中
- 关闭thymeleaf缓存,方便开发实时看到更新
- web开发放到web包下,原来的controller是前后分离对接手机等访问的,所以可以改成app,对接app应用
- 注意:springboot3,展示图片的时候,需要去掉/static的前缀
3.2 二三级目录编写
略
4. Nginx配置域名访问
4.1 本地dns映射
略
4.2 nginx.conf内容
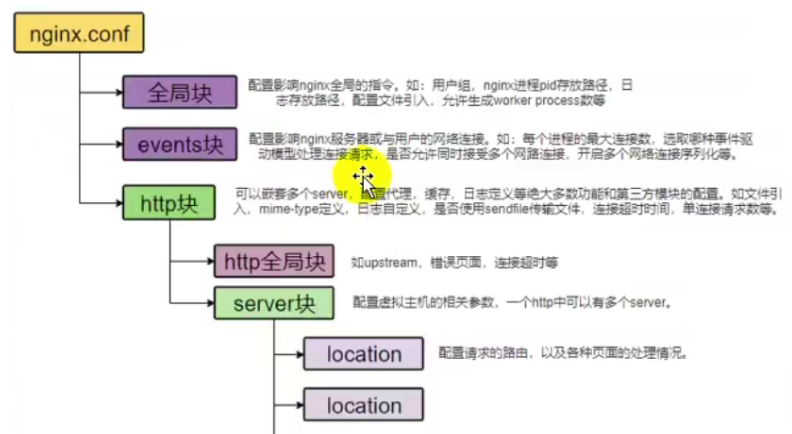
bash
# 定义 Nginx 运行使用的系统用户,保证权限安全
user nginx;
# 工作进程数,auto 表示自动根据 CPU 核心数设置(性能最优)
worker_processes auto;
# 错误日志配置
# /var/log/nginx/error.log 日志存放路径
# notice 日志级别(info/notice/warn/error/crit 等)
error_log /var/log/nginx/error.log notice;
# Nginx 主进程 PID 文件存放位置(用于重启、停止服务)
pid /run/nginx.pid;
# 事件模块:配置网络连接相关参数
events {
# 每个 worker 进程最大支持的并发连接数
worker_connections 1024;
}
# HTTP 核心模块:Web 服务、代理、缓存等都在这里配置
http {
# 引入 MIME 类型配置文件(告诉 Nginx 不同后缀文件是什么类型)
include /etc/nginx/mime.types;
# 默认文件类型(无法识别的文件按二进制流处理)
default_type application/octet-stream;
# 定义日志格式,命名为 main
# $remote_addr 客户端IP
# $remote_user 客户端用户名(一般为空)
# $time_local 访问时间
# $request 请求方法+路径+协议
# $status 响应状态码(200/404/500等)
# $body_bytes_sent 响应数据大小
# $http_referer 来源页面
# $http_user_agent 浏览器/客户端信息
# $http_x_forwarded_for 真实IP(经过代理时)
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
# 访问日志路径,使用上面定义的 main 格式
access_log /var/log/nginx/access.log main;
# 开启高效文件传输模式(静态资源服务必开)
sendfile on;
# 配合 sendfile 使用,减少网络拥塞(默认注释)
#tcp_nopush on;
# 长连接超时时间(秒),超过自动断开
keepalive_timeout 65;
# 开启 Gzip 压缩,减小传输体积(默认注释)
#gzip on;
# 引入 /etc/nginx/conf.d/ 下所有 .conf 配置
# 实际站点配置一般写在这里面,方便管理
include /etc/nginx/conf.d/*.conf;
}TODO
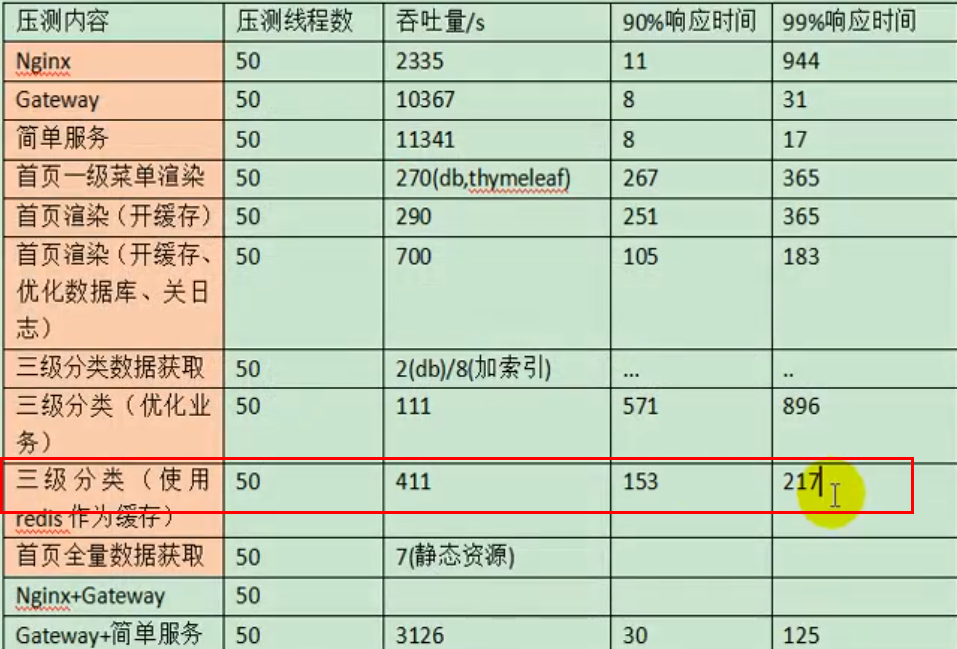
5. 压力测试
5.1 性能指标


5.2 jMeter的安装与使用
略
5.3 性能监控
jvisualvm,略
5.4 结果解析:
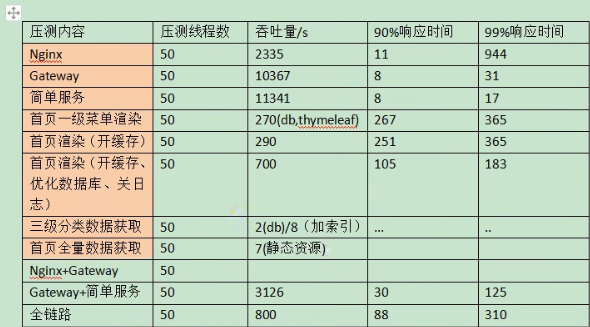
优化:
- SQL耗时越小越好,一般情况下微秒级别
- 命中率越高越好,一般情况下不能低于95%
- 锁等待次数越低越好,等待时间越短越好
- 中间件越多,性能损失越大,大多都损失在网络交互
6. 动静分离
由于动态资源和静态资源目前都处于服务端,所以为了减轻服务器压力,我们将 js、css、img等静态资源放置在Nginx端,以减轻服务器压力。
略
7. 缓存和分布式锁
哪些数据适合放入到缓存中:
- 即时性、数据一致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)
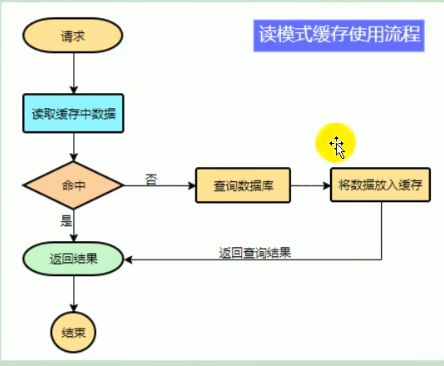
注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
7.1 springboot整合redis并测试
略
7.2 使用缓存改造三级分类
略
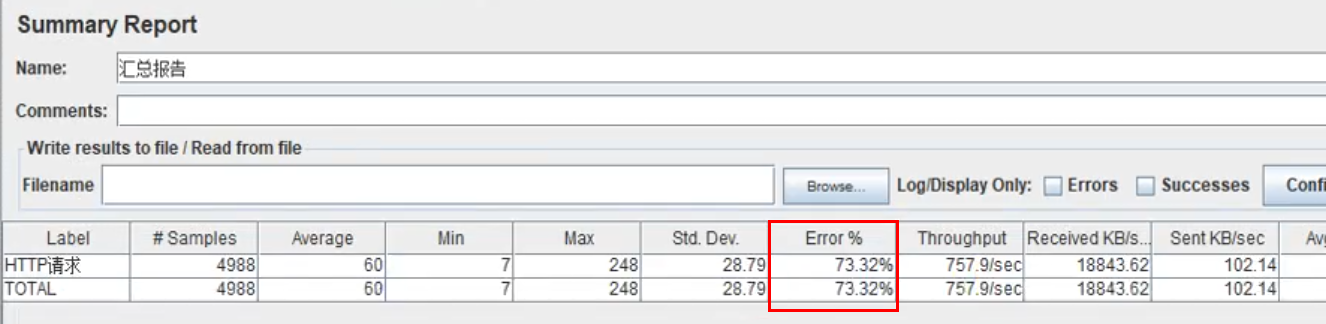
7.3 压力测试出内存泄露及解决
bash
注:此问题存在于springboot2中,springboot3已修复压测分类接口:
测试报告:
再次访问页面异常:
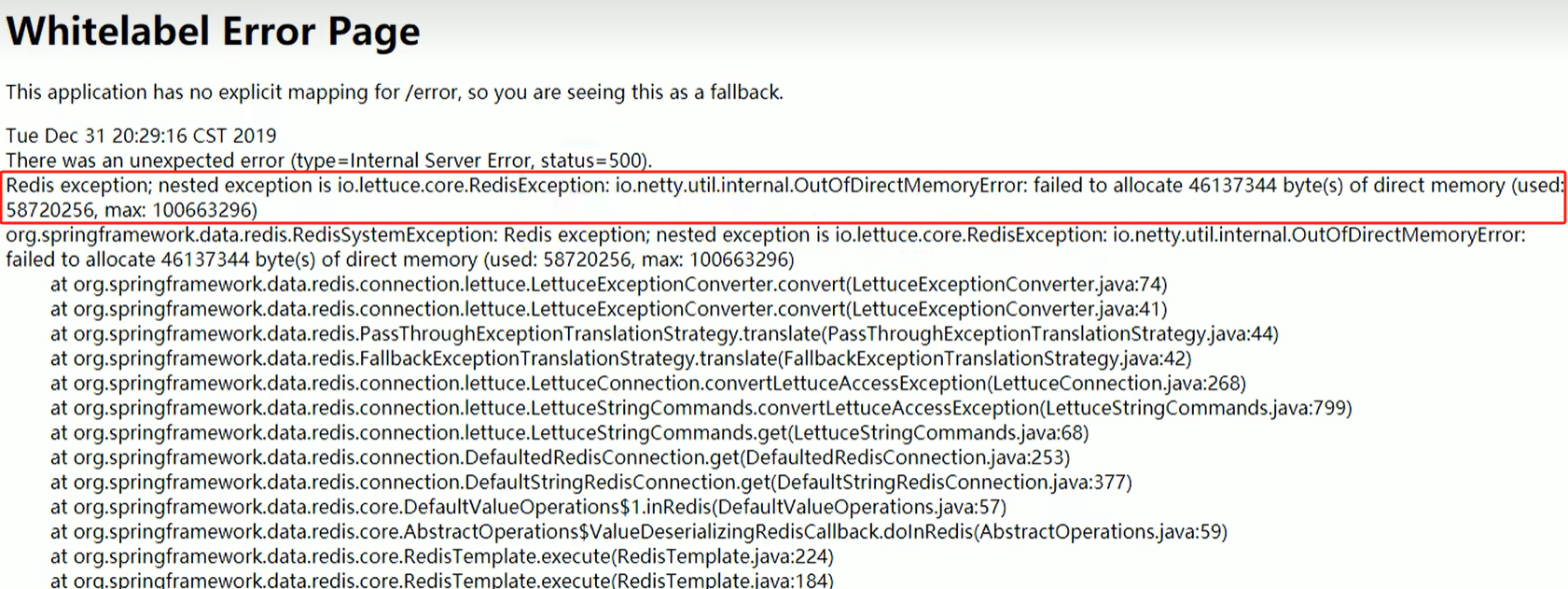
堆外内存溢出的原因:
- 产生堆外内存溢出:OutOfDirectMemoryError
- springboot2.0以后默认使用lettuce作为操作redis的客户端。使用netty进行网络通信
- lettuce的bug导致netty堆外内存溢出,Xmx300m:netty;netty如果没有指定堆外内存,默认使用-Xmx300m
可以通过-Dio.netty.maxDirectMemory进行设置
- 解决方案:不能使用-Dio.netty.maxDirectyMemory只去调大堆外内存
- 升级lettuce客户端。
- 切换使用jedis。
- redisTemplate:lettuce、jedis操作redis的底层客户端,spring再次封装redisTemplate
7.4 使用缓存测试:
使用Redis作为缓存后,吞吐量得到了很大的提升,响应时间也缩短了很多:
7.5 高并发下缓存失效问题
前面我们将查询三级分类数据的查询进行了优化,将查询结果放入到Redis中,当再次获取到相同数据的时候,直接从缓存中读取,没有则到数据库中查询,并将查询结果放入到Redis缓存中。
但是在分布式系统中,这样还是会存在问题。
7.5.1 缓存穿透:查询不存在的数据

7.5.2 缓存雪崩:key同时大面积失效

7.5.3 缓存击穿:高频的key失效

7.6 本地锁解决缓存击穿
当启用一个服务的时候,使用双检锁+jvm级别的锁可以解决问题。
但是如果在分布式的情况下,启动多个服务,每个服务拿到的本地锁是不同的。所以需要分布式锁
7.7 分布式锁
7.7.1 本地缓存面临问题
当有多个服务存在时,每个服务的缓存仅能够为本服务使用,这样每个服务都要查询一次数据库,并且当数据更新时只会更新单个服务的缓存数据,就会造成数据不一致的问题
所有的服务都到同一个redis进行获取数据,就可以避免这个问题
7.7.2 分布式锁
当分布式项目在高并发下也需要加锁,但本地锁只能锁住当前服务,这个时候就需要分布式锁。
分布式下如何加锁?
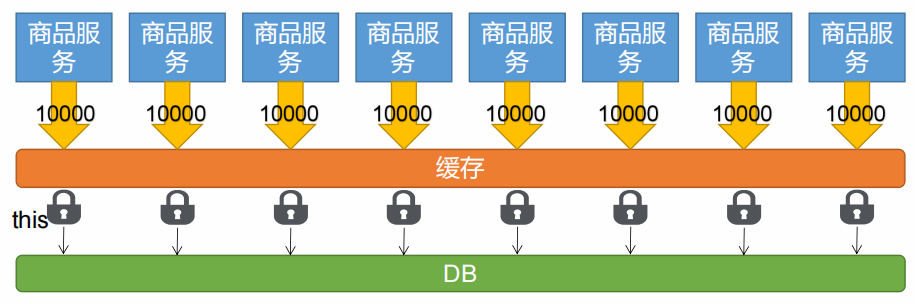
本地锁,只能锁住当前进程,所以我们需要分布式锁
7.7.3 分布式锁的演进
基本原理
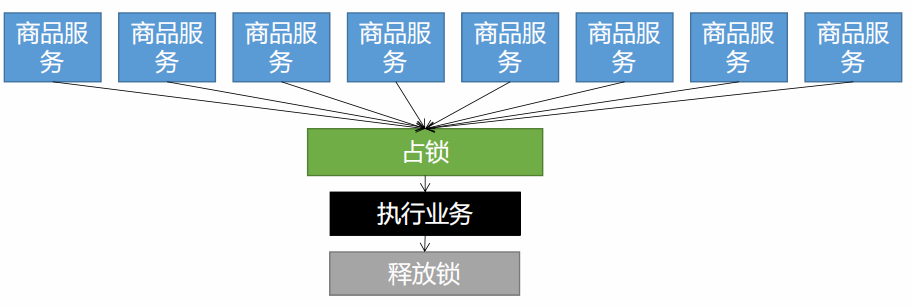
bash
我们可以同时去一个地方 " 占坑 " ,如果占到,就执行逻辑。否则就必须等待,直到释放锁。
" 占坑 " 可以去 redis ,可以去数据库,可以去任何大家都能访问的地方。
等待可以 自旋 的方式。下面使用redis来实现分布式锁,使用的是SET key value EX seconds PX milliseconds NX\|XX,http://www.redis.cn/commands/set.html
1、打开SecureCRT,创建四个Redis的redis-cli连接
2、同时执行"set loc 1 NX"观察四个窗口的输出
将命令批量发送到四个窗口的的方式:
7.7.3.1 阶段一
java
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//删除锁
return dataFromDB;
}else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}-
问题:1、setnx占好了位,业务代码异常或者程序在页面过程中宕机。没有执行删除锁逻辑,这就造成了死锁
-
解决:设置锁的自动过期,即使没有删除,会自动删除
7.7.3.2 阶段二
java
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111");
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
// 2、设置过期时间
stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//删除锁
return dataFromDB;
}else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}- 问题: 1、 setnx 设置好,正要去设置过期时间,宕机。又死锁了。
- 解决: 设置过期时间和占位必须是原子的。redis 支持使用 setnxex命令
7.7.3.3 阶段三
java
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", "111", 300, TimeUnit.SECONDS);
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
// 2、设置过期时间,必须和加锁是同步的,原子的
// stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
stringRedisTemplate.delete("lock");//删除锁
return dataFromDB;
} else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}- 问题: 1、删除锁直接删除??? 如果由于业务时间很长,锁自己过期了,我们直接删除,有可能把别人正在持有的锁删除了。
- 解决: 占锁的时候,值指定为uuid ,每个人匹配是自己的锁才删除。
7.7.3.4 阶段四
java
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
//获取到锁,执行业务
if (lock) {
//加锁成功。。。执行业务
// 2、设置过期时间,必须和加锁是同步的,原子的
// stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
String lockValue = stringRedisTemplate.opsForValue().get("lock");
if (uuid.equals(lockValue)) {
//删除我自己的锁
stringRedisTemplate.delete("lock");//删除锁
}
return dataFromDB;
} else {
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}- 问题: 1、如果正好判断是当前值,正要删除锁的时候,锁已经过期,别人已经设置到了新的值。那么我们删除的是别人的锁
- 解决: 删除锁必须保证原子性。使用redis+Lua 脚本完成
7.7.3.5 阶段五-最终形态
java
private Map<String, List<Catelog2Vo>> getCatalogJsonFromDBWithRedisLock() {
// 1、占分布式锁,去redis占坑
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
//获取到锁,执行业务
if (lock) {
System.out.println("获取分布式锁成功。。。");
//加锁成功。。。执行业务
// 2、设置过期时间,必须和加锁是同步的,原子的
// stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catelog2Vo>> dataFromDB = getDataFromDB();
// 获取值对比+对比成功删除=原子操作 Lua脚本解锁
// String lockValue = redisTemplate.opsForValue().get("lock");
// if (uuid.equals(lockValue)) {
// // 删除我自己的锁
// stringRedisTemplate.delete("lock");//删除锁
// }
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 删除锁
Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);
System.out.println("删除锁返回值:" + lock1);
return dataFromDB;
} else {
System.out.println("获取分布式锁失败,等待重试。。。");
//没获取到锁,等待100ms重试
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
return getCatalogJsonFromDBWithRedisLock();
}
}lua脚本:保证加锁【占位+过期时间】和删除锁【判断+删除】的原子性。
java
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";

7.8 Redisson
Redisson 是架设在 Redis 基础上 的一个 Java 驻内存数据网格( In-Memory Data Grid )。充分的利用了 Redis 键值数据库提供的一系列优势, 基于 Java 实用工具包中常用接口 ,为使用者提供了一系列具有分布式特性的常用工具类。 使得原本作为协调单机多线程并发程序的工 具包获得了协调分布式多机多线程并发系统的能力 ,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。
官方文档
7.8.1 简单使用
- 导入依赖
xml
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>4.3.0</version>
</dependency>另外Redison也提供了一个集成到SpringBoot上的starter
- 添加config配置类
由于我们使用的单节点,所以配置了单节点的Redisson。配置方法:官方文档
java
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
//1、创建配置
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//2、根据Config创建出RedissonClient实例
//Redis url should start with redis:// or rediss://
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}- 测试使用
java
@Autowired
RedissonClient redissonClient;
@Test
public void testRedison(){
System.out.println(redissonClient);
}
7.8.2 lock锁测试
Redison分布式锁:详见:官方文档
在Redison中分布式锁的使用,和java.util.concurrent包中的所提供的锁的使用方法基本相同。
测试Redisson的Lock锁的使用:
- 在controller中添加方法:
java
@GetMapping("/hello")
@ResponseBody
public String hello(){
// 1.获取一把锁,只要名字一样,就是同一把锁
RLock lock = redisson.getLock("my-lock");
// 2.加锁和解锁
try {
lock.lock();
System.out.println("加锁成功,执行业务方法..."+Thread.currentThread().getId());
Thread.sleep(30000);
} catch (Exception e){
e.printStackTrace();
}finally {
lock.unlock();
System.out.println("释放锁..."+Thread.currentThread().getId());
}
return "hello";
}-
同时发送两个请求到:http://localhost:10000/hello

-
能够看到在加锁期间另外一个请求一直都是出于挂起状态,需要等待上一个请求处理完毕后,它才能接着执行。

-
查看Redis:

7.8.3 Redisson分布式锁实现原理
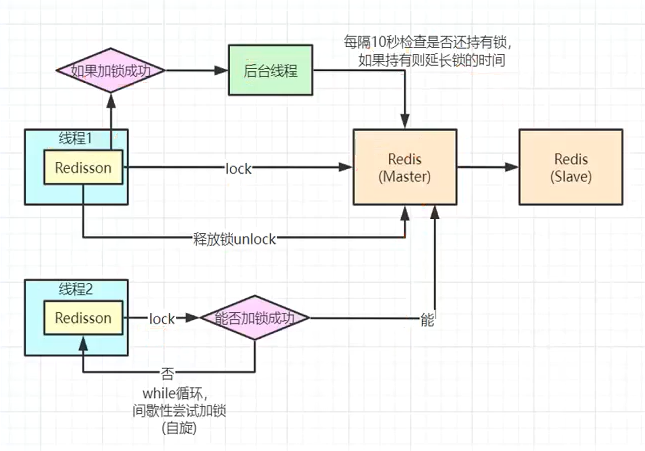
7.8.4 lock看门狗原理-redisson如何解决死锁
设想一种情况,一个请求线程在执行业务方法的时候,突然发生了中断,此时没有来得及执行释放锁操作,那么同时等待的另外一个线程是否会发生死锁。为了模拟这种情形,我们同时启动10000和10001,同时发送请求。
-
同时发送请求:
-
在10000端口上的服务在获取锁后,突然中断它的运行

-
观察Redis,能够看到这个锁仍然仍然存在:

-
此时在10001上运行的服务先是等待一会,然后成功获取到了锁:

-
观察Redis能够看大这个锁变为了针对于10001端口的了:

-
通过上面的实践能够看到,在加锁后,即便我们没有释放锁,也会自动的释放锁,这是因为在Redisson中会为每个锁加上"leaseTime",默认是30秒
java
大家都知道,如果负责储存这个分布式锁的Redisson节点宕机以后,
而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,
Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,
不断的延长锁的有效期。默认情况下,看门狗检查锁的超时时间是30秒钟,
也可以通过修改Config.lockWatchdogTimeout来另行指定。- 在Redis中,我们能够看到这一点:

7.8.4.1 小结:redisson的lock具有如下特点
- lock.lock():阻塞式等待。默认加的都是30s
- 锁的自动续期,如果业务过长,运行期间自动给锁续上30s,不用担心业务时间长,锁自动过期被删掉。
- 加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除。
- lock方法还有一个重载的方法,lock(long leaseTime, TimeUnit unit)
java
@Override
public void lock(long leaseTime, TimeUnit unit) {
try {
lock(leaseTime, unit, false);
} catch (InterruptedException e) {
throw new IllegalStateException();
}
}-
lock.lock(10, TimeUnit.SECONDS):10秒自动解锁,设置的自动解锁时间一定要大于业务的执行时间
- 问题:lock.lock(10, TimeUnit.SECONDS);在锁到期后,是否会自动续期?
- 答案:在指定了超时时间后,
不会进行自动续期,此时如果有多个线程,即便业务仍然在执行,超时时间到了后,锁也会失效,其他线程就会争抢到锁。 - 如果我们传递了锁的超时时间,就会飞redis发送执行脚本,进行占锁,默认超时就是我们指定的时间。
- 如果我们未指定锁的超时时间,就是用30*1000【lockWatchdogTimeout看门狗的默认时间】。
- 关于续期周期,只要锁占领成功,就会自动启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10s都会自动再次续期,续成30s。这个10s中是根据( internalLockLeasTime)/3得到的。
-
最佳实战 :
- 尽管相对于lock(),lock(long leaseTime, TimeUnit unit)存在到期后自动删除的问题,但是我们对于它的使用还是比较多的,通常都会评估一下业务的最大执行用时,在这个时间内,如果仍然未能执行完成,则认为出现了问题,则释放锁执行其他逻辑。
-
lock.tryLock(100, 10, TimeUnit.SECONDS)
- 尝试加锁,最多等待100秒,上锁以后10秒自动解锁
7.8.5 读写锁测试:
功能:保证一定能够读取到最新的数据,修改期间,写锁是一个排他锁(互斥锁),读锁是一个共享锁,写锁没释放读就必须等待。
- 在Redis增加一个新的key"writeValue",值为11111
- 增加write和read的controller方法
java
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock writeLock = redisson.getReadWriteLock("rw-loc");
String uuid = null;
RLock lock = writeLock.writeLock();
lock.lock();
try {
uuid = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", uuid);
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
}
return uuid;
}
@GetMapping("/read")
@ResponseBody
public String redValue(){
String uuid = null;
RReadWriteLock readLock = redisson.getReadWriteLock("rw-loc");
RLock lock = readLock.readLock();
lock.lock();
try {
uuid = redisTemplate.opsForValue().get("writeValue");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
return uuid;
}- 启动gulimall-product
- 分别访问"http://localhost:10000/read"和"http://localhost:10000/write",观察现象。
- 执行写操作时,读操作必须要等待;
- 可以同时执行多个读操作,读操作之间互不影响;
- 在写操作时查看Redis中"rw-loc"的状态

7.8.5 读写锁补充
- 修改"read"和"write"的controller方法
java
@GetMapping("/write")
@ResponseBody
public String writeValue(){
RReadWriteLock writeLock = redisson.getReadWriteLock("rw-loc");
String uuid = null;
RLock lock = writeLock.writeLock();
lock.lock();
try {
log.info("写锁加锁成功");
uuid = UUID.randomUUID().toString();
redisTemplate.opsForValue().set("writeValue", uuid);
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
log.info("写锁释放");
}
return uuid;
}
@GetMapping("/read")
@ResponseBody
public String redValue(){
String uuid = null;
RReadWriteLock readLock = redisson.getReadWriteLock("rw-loc");
RLock lock = readLock.readLock();
lock.lock();
try {
log.info("读锁加锁成功");
uuid = redisTemplate.opsForValue().get("writeValue");
Thread.sleep(30000);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
log.info("读锁释放");
}
return uuid;
}-
先发送一个写请求,然后同时发送四个读请求
-
观察现象
-
在写操作期间,四个读操作被阻塞,此时查看Redis中"rw-loc"状态,是写状态

-
写操作完毕后,查看Redis中的"rw-loc"状态,状态为读状态
- 同时会出现三个读锁的

- 同时会出现三个读锁的
-
查看控制台输出:能够看到三个读操作是同时获取到锁的。

-
另外在先执行读操作时,写操作被阻塞。
-
-
小结:
只要存在写操作,不论前面是或后面执行的是读或写操作,都会阻塞。- 读+读:相当于无锁,并发读,只会在redis中记录,所有当前的读锁,都会同时加锁成功
- 写+读:等待写锁释放;
- 写+写:阻塞方式
- 读+写:写锁等待读锁释放,才能加锁
7.8.6闭锁测试
类似juc的CountDownLatch
java
/**
* 放假,锁门
* 5个班全部走完,我们可以锁大门
*/
@GetMapping("/lockDoor")
@ResponseBody
public String lockDoor() throws InterruptedException {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.trySetCount(5);
//等待闭锁完成,此处等待调用5次countDown
door.await();
return "放假了...";
}
@GetMapping("/gogogo/{id}")
@ResponseBody
public String gogogo(@PathVariable("id") Long id) {
RCountDownLatch door = redissonClient.getCountDownLatch("door");
door.countDown();//计数减一
return id + "班级的人都走了";
}7.8.7 信号量测试
先在redis中设置park的值为3

java
/**
* 车库停车
* 3个车位
* 信号量也可以做分布式限流
*/
@GetMapping(value = "/park")
@ResponseBody
public String park() throws InterruptedException {
RSemaphore park = redisson.getSemaphore("park");
// 获取一个信号、获取一个值,占一个车位
// 如果车位不够,此处就会等待
park.acquire();
boolean flag = park.tryAcquire();
if (flag) {
//执行业务
} else {
return "error";
}
return "ok=>" + flag;
}
@GetMapping(value = "/go")
@ResponseBody
public String go() {
RSemaphore park = redisson.getSemaphore("park");
park.release(); //释放一个车位
return "ok";
}小结: 信号量可以作为分布式限流
7.8.8 缓存一致性解决
缓存一致性是为了解决数据库和缓存的数据不同步问题的。
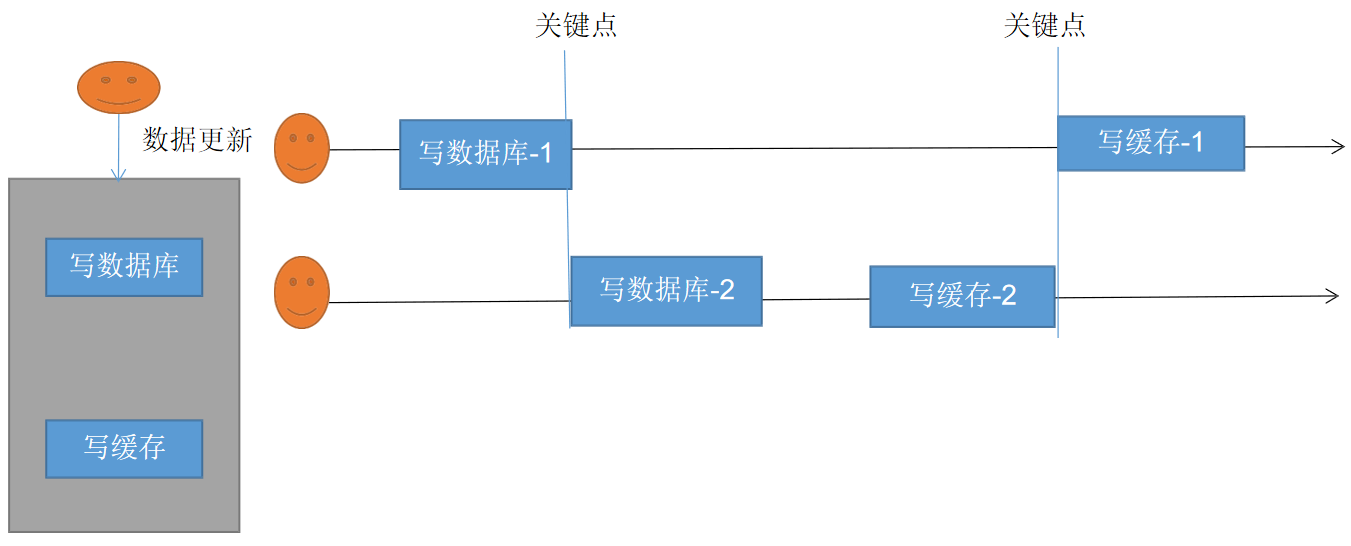
7.8.8.1 写缓存方式一:双写模式
- 由于卡顿等原因,导致写缓存2在最前,写缓存1在后面就出现了不一致脏数据问题
- 这是暂时性的脏数据问题,但是在数据稳定,缓存过期以后,又能得到最新的正确数据读到的最新数据有延迟:最终一致性
7.8.8.2 写缓存方式二:失效模式
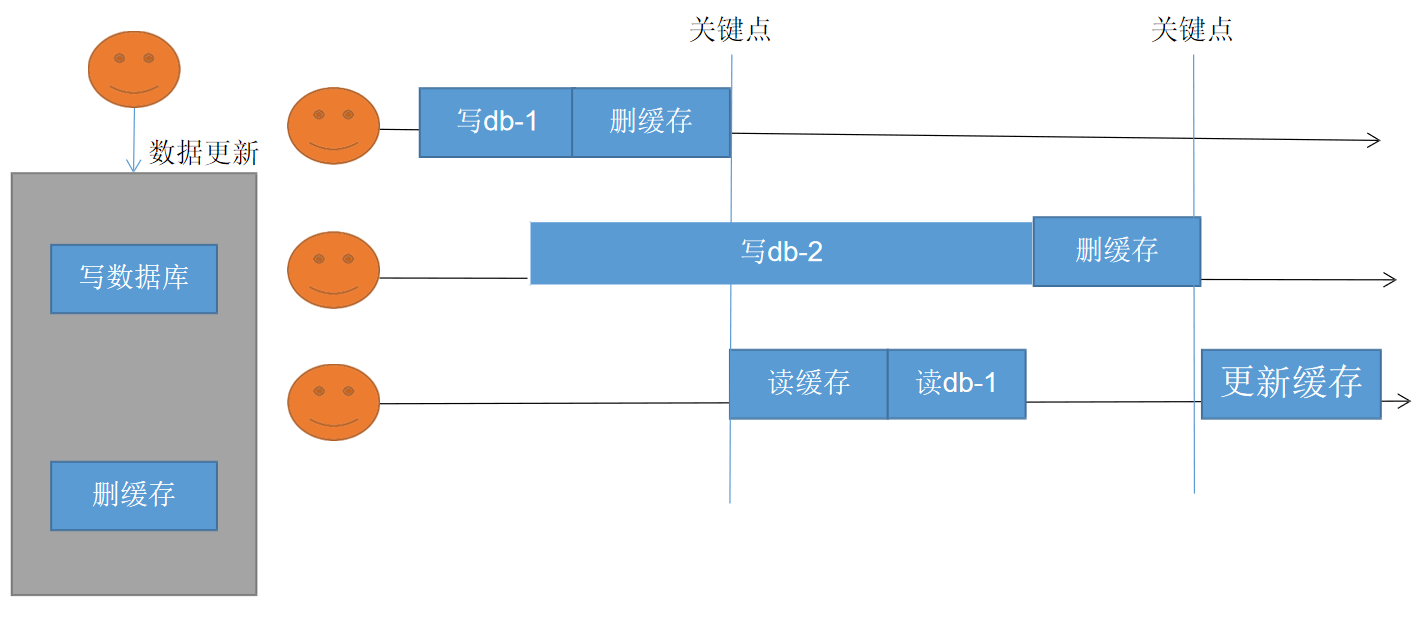
7.8.8.3 解决方案:
- 无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
- 如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式。
- 缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
- 总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
7.8.8.4 解决方案:Canal
通过binlog日志,在写入数据库的同时,监听binlong日志,同步写入到缓存中
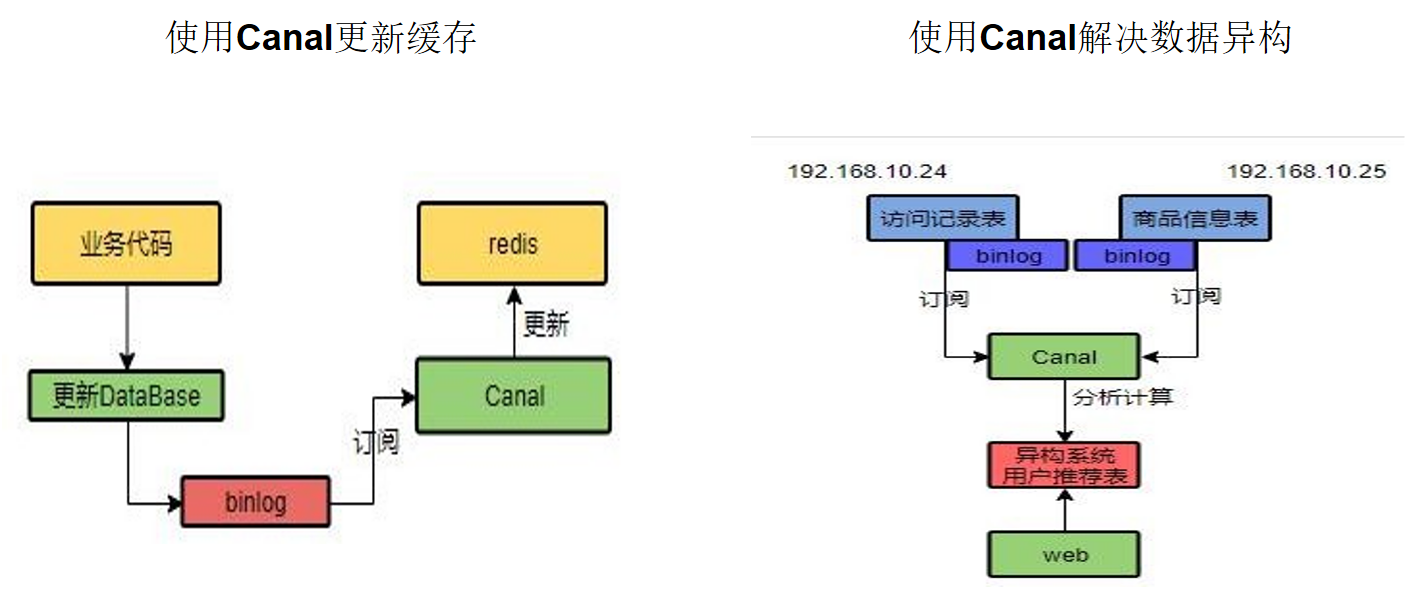
7.8.8.5 我们系统的最佳解决方案:
- 缓存的所有数据都有过期时间,数据过期下一次查询触发主动更新
- 读写数据的时候,加上分布式的读写锁。
- 在更新分类数据的时候,删除缓存中的旧数据。
7.9 SpringCache
这个了解下即可,学习下来觉得只是简化一部分redis获取和设置的代码,本质上是方法添加了Aop,用处不大,不如自己配置直接可控。
7.9.1 简介
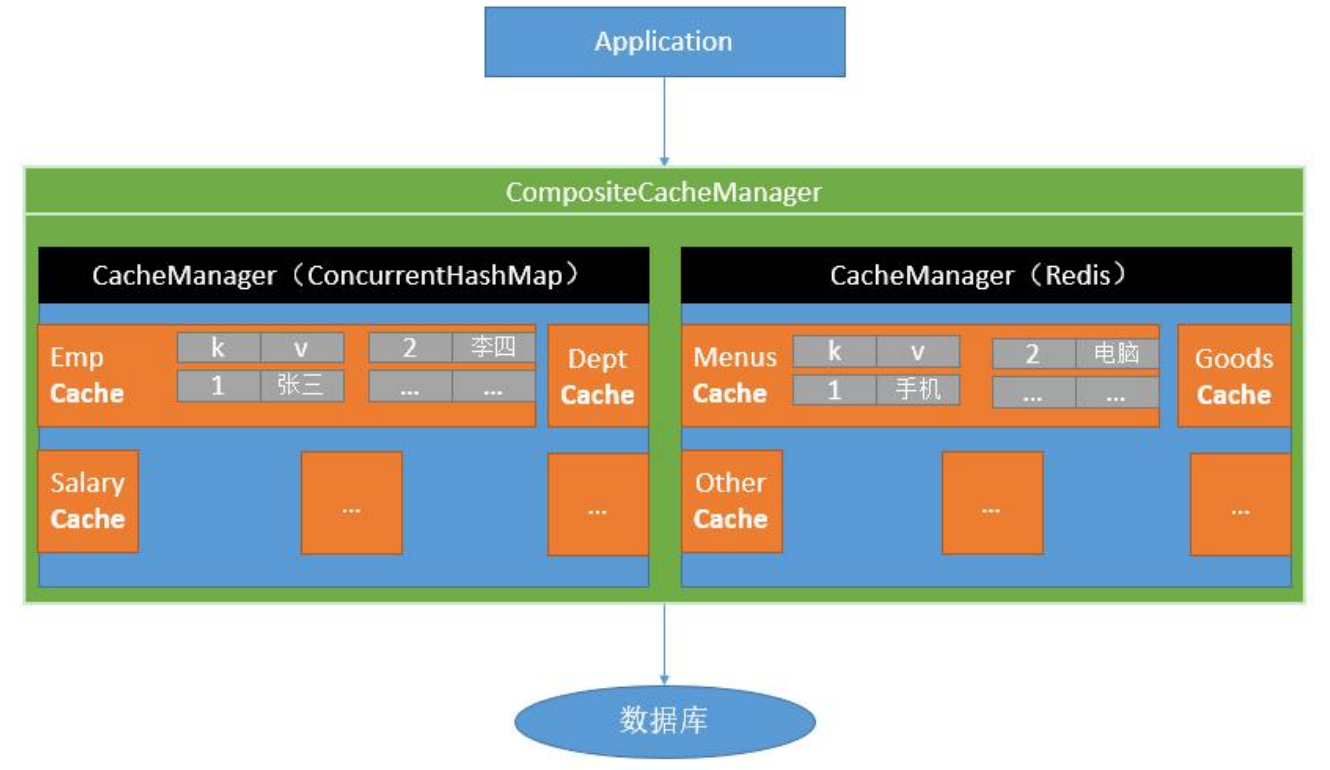
- Spring 从 3.1 开始定义了 org.springframework.cache.Cache和 org.springframework.cache.CacheManager 接口来统一不同的缓存技术;并支持使用 JCache(JSR-107)注解简化我们开发;
- Cache 接口为缓存的组件规范定义,包含缓存的各种操作集合;Cache 接 口 下 Spring 提 供 了 各 种 xxxCache 的 实 现 ; 如 RedisCache , EhCacheCache , ConcurrentMapCache 等;
- 每次调用需要缓存功能的方法时,Spring 会检查检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
- 使用 Spring 缓存抽象时我们需要关注以下两点;
- 确定方法需要被缓存以及他们的缓存策略
- 从缓存中读取之前缓存存储的数据
- SpringCache的文档:https://docs.spring.io/spring-framework/docs/5.3.34/reference/html/integration.html#cache
7.9.2 基础概念
7.9.3 SpringCache-整合。体验@Cacheable
7.9.3.1 引入依赖
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>7.9.3.2 编写配置
- 缓存的自动配置了哪些?
- CacheAutoConfiguration,会导入RedisCacheConfiguration
- 自动配置了缓存管理器RedisCacheManager
- 配置使用Redis作为缓存
- 修改"application.properties"文件,指定使用redis作为缓存,spring.cache.type=redis
java
spring.cache.type=redis7.9.3.3 和缓存有关的注解
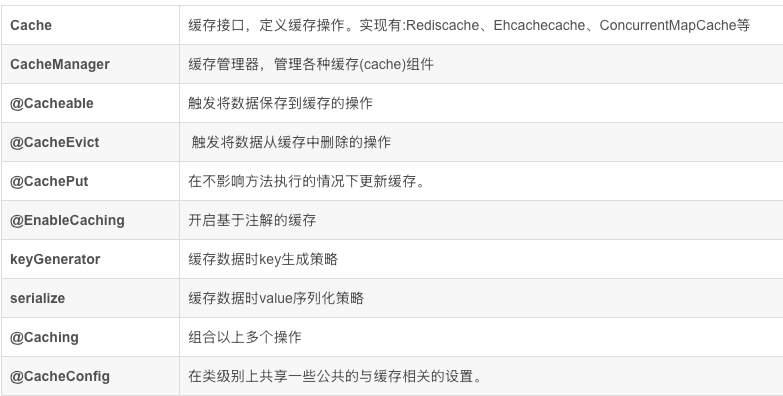

- 表达式语法
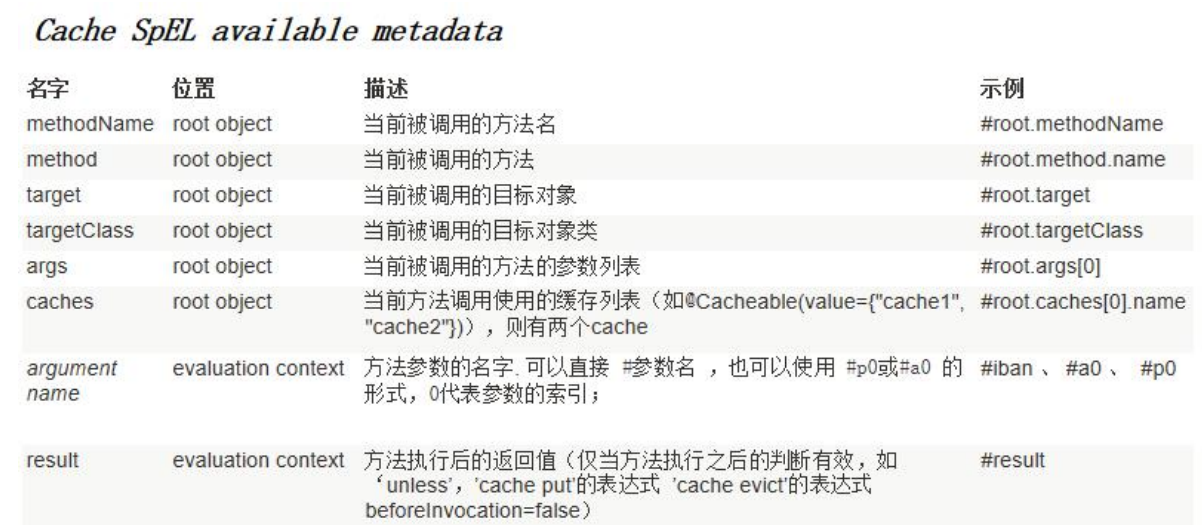
7.9.3.4 测试使用缓存
- 开启缓存功能,在主启动类上,添加注解@EnableCaching
- 只需要使用注解,就可以完成缓存操作
- 在业务方法的头部标上@Cacheable,加上该注解后,表示当前方法需要将进行缓存,如果缓存中有,方法无效调用,如果缓存中没有,则会调用方法,最后将方法的结果放入到缓存中。
- 指定缓存分区。每一个需要缓存的数据,我们都需要来指定要放到哪个名字的缓存中。通常按照业务类型进行划分。
如:我们将一级分类数据放入到缓存中,指定缓存名字为"category"
java
@Cacheable({"category"})//代表当前方法的结果需要缓存,如果缓存中有,方法不用调用。如果缓存中没有,最后将方法放入缓存。
@Override
public List<CategoryEntity> getLevel1Categories() {
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0));
return categoryEntities;
}- 访问:http://localhost:10000/
- 查看Redis:能够看到一级分类信息,已经被放入到缓存中了,而且再次访问的时候,没有查询数据库,而是直接从缓存中获取。

7.9.4 @Cacheable细节设置
上面我们将一级分类数据的信息缓存到Redis中了,缓存到Redis中数据具有如下的特点:
- 如果缓存中有,方法不会被调用;
- key默认自动生成;形式为"缓存的名字::SimpleKey(自动生成的key值)";
- 缓存的value值,默认使用jdk序列化机制,将序列化后的数据缓存到redis;
- 默认ttl时间为-1,表示永不过期
然而这些并不能够满足我们的需要,我们希望:
- 能够指定生成缓存所使用的key;
- 指定缓存的数据的存活时间;
- 将缓存的数据保存为json形式;
- 针对于第一点,我们使用@Cacheable注解的时候,设置key属性,接受一个SpEL
java
@Cacheable(value = {"category"},key = "'level1Categorys'")- 针对于第二点,在配置文件中指定ttl:
java
spring.cache.redis.time-to-live=3600000 #这里指定存活时间为1小时清空redis,再次进行访问:http://localhost:10000/
查看Redis
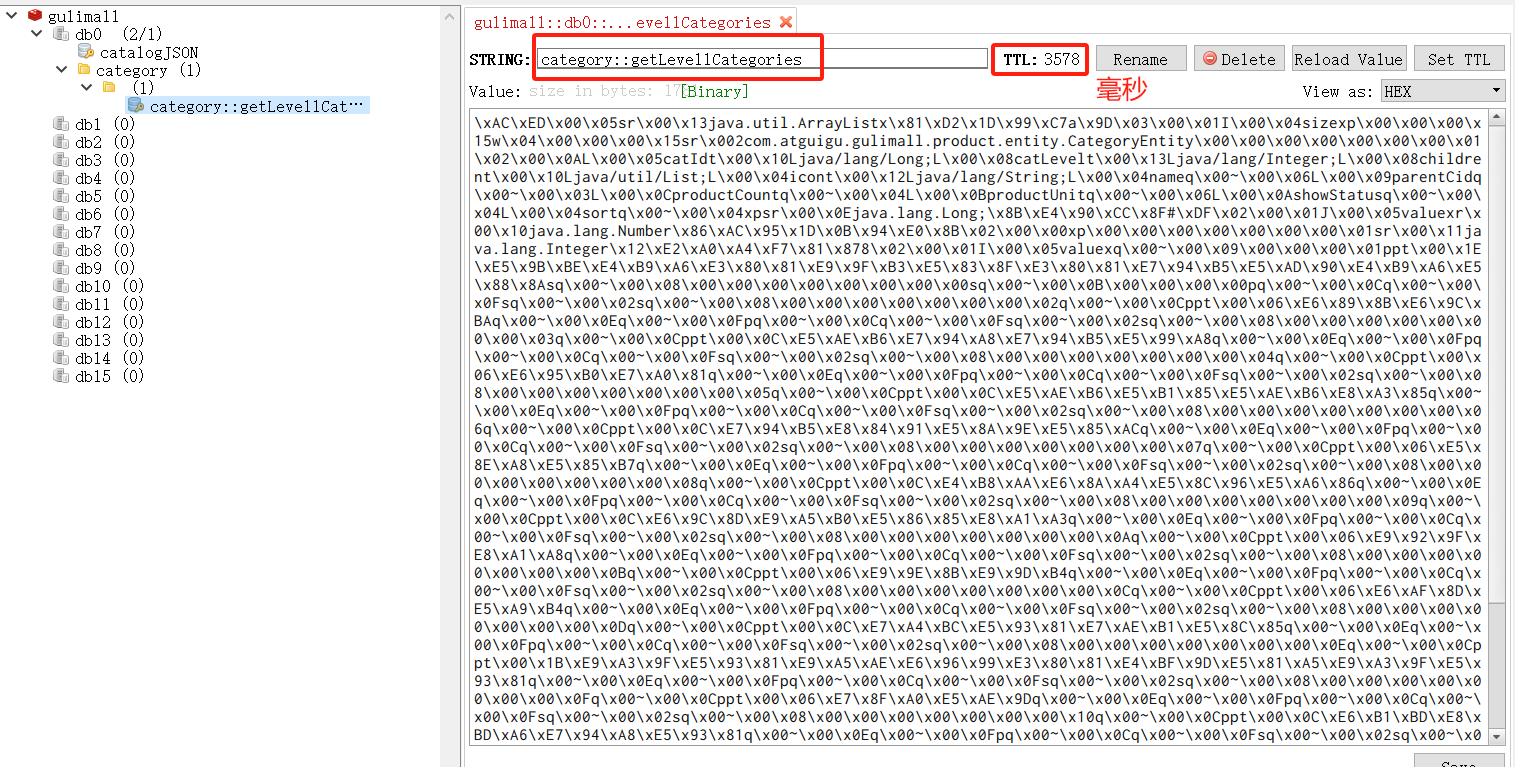
更多关于key的设置,在文档中给予了详细的说明:springcache文档
7.9.5 自定义缓存配置(存储json)
上面我们解决了第一个命名问题和第二个设置存活时间问题,但是如何将数据以JSON的形式缓存到Redis呢?
这涉及到修改缓存管理器的设置,CacheAutoConfiguration导入了RedisCacheConfiguration,而RedisCacheConfiguration中自动配置了缓存管理器RedisCacheManager,而RedisCacheManager要初始化所有的缓存,每个缓存决定使用什么样的配置,如果RedisCacheConfiguration有就用已有的,没有就用默认配置。
想要修改缓存的配置,只需要给容器中放一个"redisCacheConfiguration"即可,这样就会应用到当前RedisCacheManager管理的所有缓存分区中。
java
private org.springframework.data.redis.cache.RedisCacheConfiguration createConfiguration(
CacheProperties cacheProperties, ClassLoader classLoader) {
Redis redisProperties = cacheProperties.getRedis();
org.springframework.data.redis.cache.RedisCacheConfiguration config = org.springframework.data.redis.cache.RedisCacheConfiguration
.defaultCacheConfig();
config = config.serializeValuesWith(
SerializationPair.fromSerializer(new JdkSerializationRedisSerializer(classLoader)));
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}Redis中的序列化器:org.springframework.data.redis.serializer.RedisSerializer
在Redis中放入自动配置类,设置JSON序列化机制
java
@EnableConfigurationProperties(CacheProperties.class)
@Configuration
@EnableCaching
public class MyCacheConfig {
/**
* 配置文件中的东西没有用到
*
* 1、原来和配置文件绑定的配置类是这样的
* @ConfigurationProperties(prefix="spring.cache")
* public class CacheProperties
* 2、让他生效
* @EnableConfigurationProperties(CacheProperties.class)
* @return
*/
@Bean
RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//将配置文件中的所有配置都生效
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//设置配置文件中的各项配置,如过期时间
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
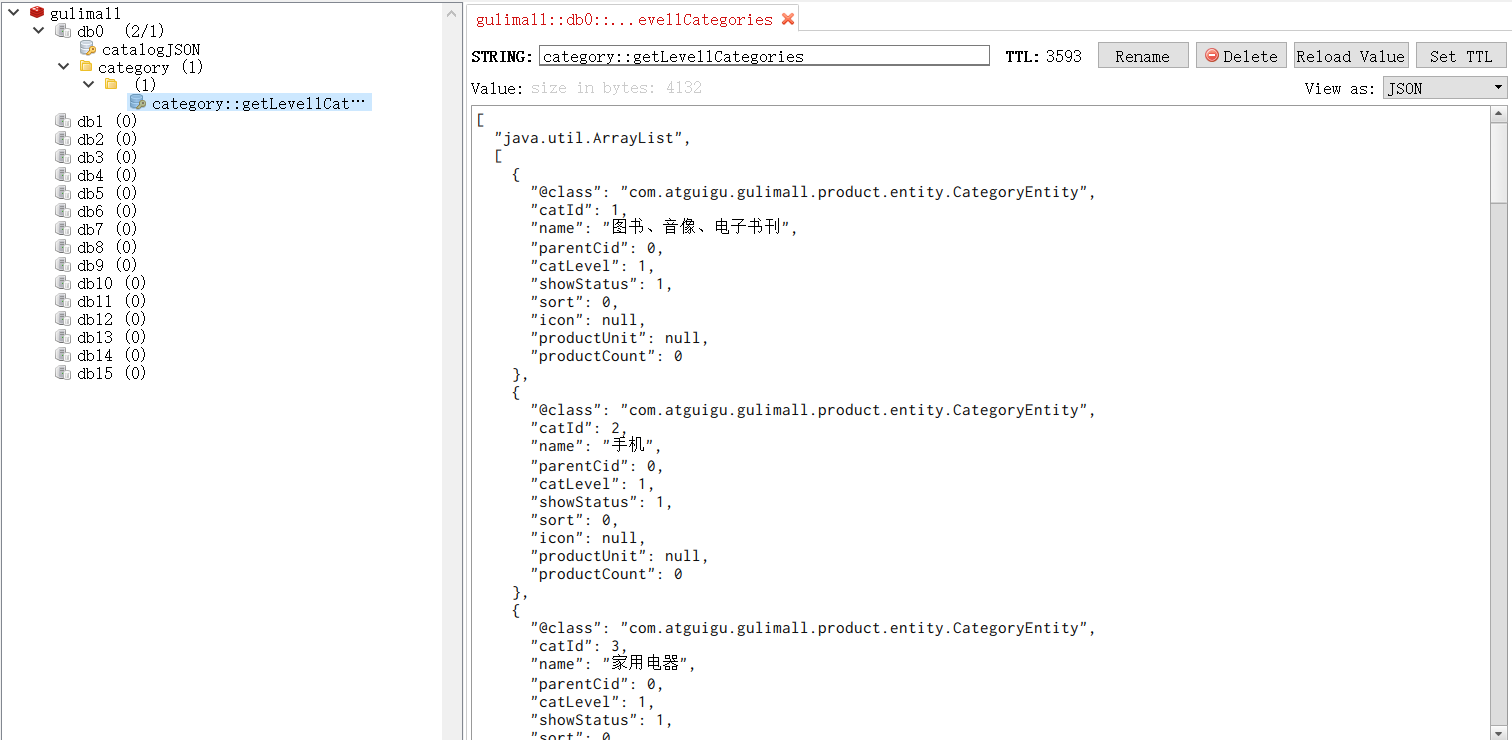
}查看Redis能够看到以JSON的形式,将数据缓存下来了:
bash
spring.cache.type=redis
#设置超时时间,默认是毫秒
spring.cache.redis.time-to-live=3600000
#设置Key的前缀,如果指定了前缀,则使用我们定义的前缀,否则使用缓存的名字作为前缀
spring.cache.redis.key-prefix=CACHE_
spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
spring.cache.redis.cache-null-values=true基于这个配置,在如果出现了null值,也会被保存到redis中:

如果配置"spring.cache.redis.use-key-prefix=false",则生成的key没有前缀:
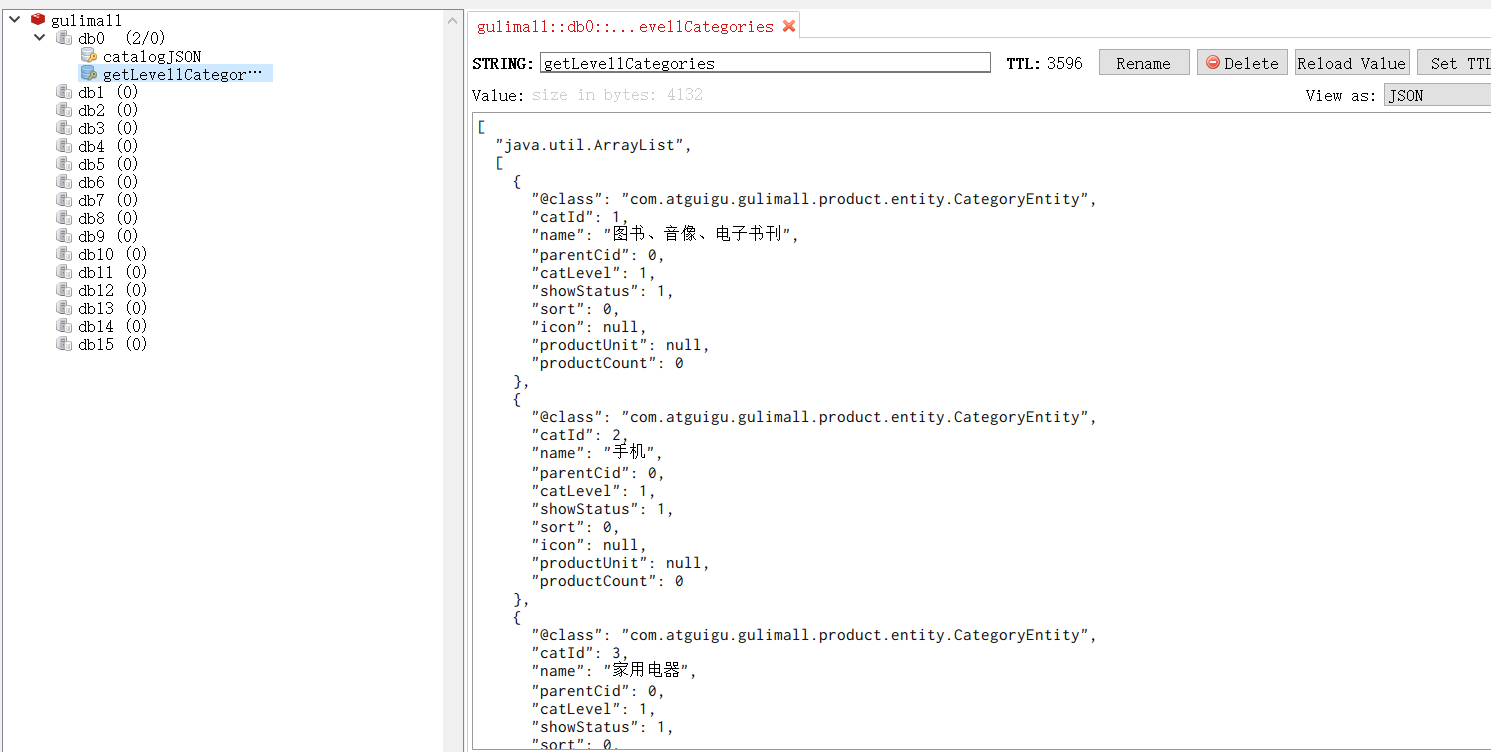
7.9.6 @CacheEvict
在上面实例中,在读模式中,我们将一级分类信息缓存到redis中,当请求再次获取数据时,直接从缓存中进行获取,但是如果执行的是写模式呢?
在写模式下,有两种方式来解决缓存一致性问题,双写模式和失效模式,在SpringCache中可以通过@CachePut来实现双写模式,使用@CacheEvict来实现失效模式。
实例:使用缓存失效机制实现更新数据库中值的是,使得缓存中的数据失效
- 修改updateCascade方法,添加@CacheEvict注解,指明要删除哪个分类下的数据,并且确定key
修改"com.atguigu.gulimall.product.service.impl.CategoryServiceImpl"类,代码如下:
java
@CacheEvict(value = {"category"}, key = "getLevel1Categories")
@Transactional
@Override
public void updateCascade(CategoryEntity category) {
this.updateById(category);
categoryBrandRelationService.updateCategory(category.getCatId(), category.getName());
// 同时修改缓存中的数据
// redis.del("catalogJSON");等待下一次主动查询进行更新
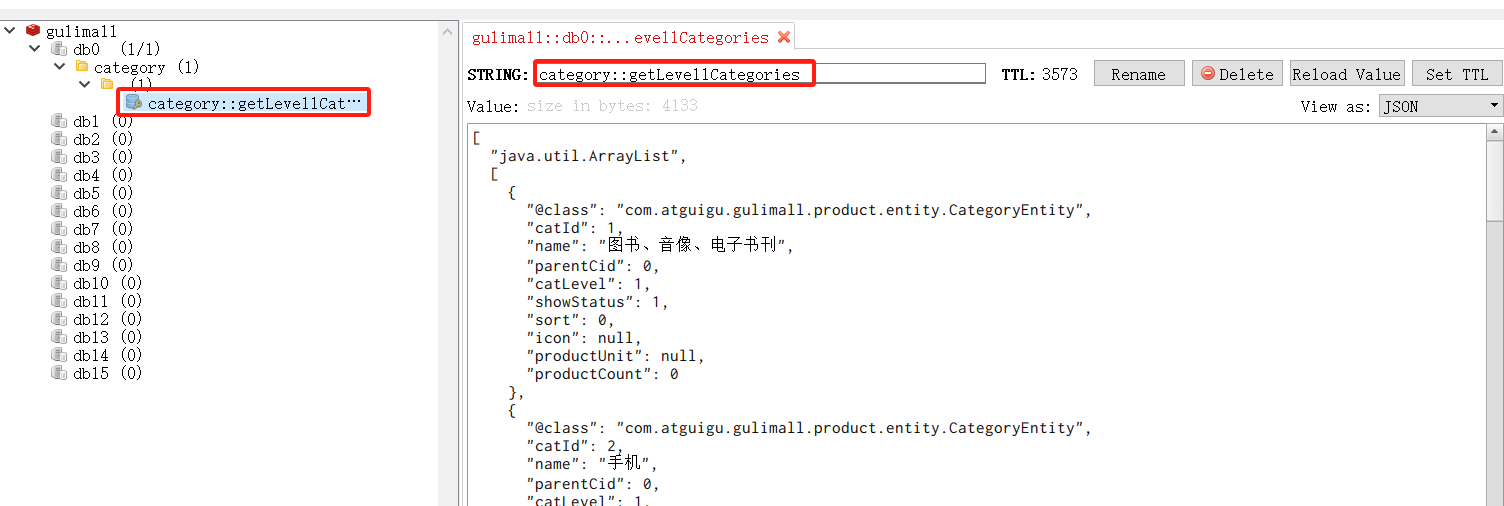
}- 启动gulimall-product,启动renren-fast,启动gulimall-gateway,启动项目的前端页面
- 检查redis中是否有"category"命名空间下的数据,没有则访http://localhost:10000/,生成数据
- 修改数据:
- 检查Redis中对应数据是否还存在
检查后发现数据没了,说明缓存失效策略是有效的。
另外在修改了一级缓存时,对应的二级缓存也需要更新,需要修改原来二级分类的执行逻辑。
将"getCatalogJson"恢复成为原来的逻辑,但是设置@Cacheable,非侵入的方式将查询结果缓存到redis中:
修改"CategoryServiceImpl"类,代码如下:
java
@Cacheable(value = {"category"}, key = "#root.methodName")
@Override
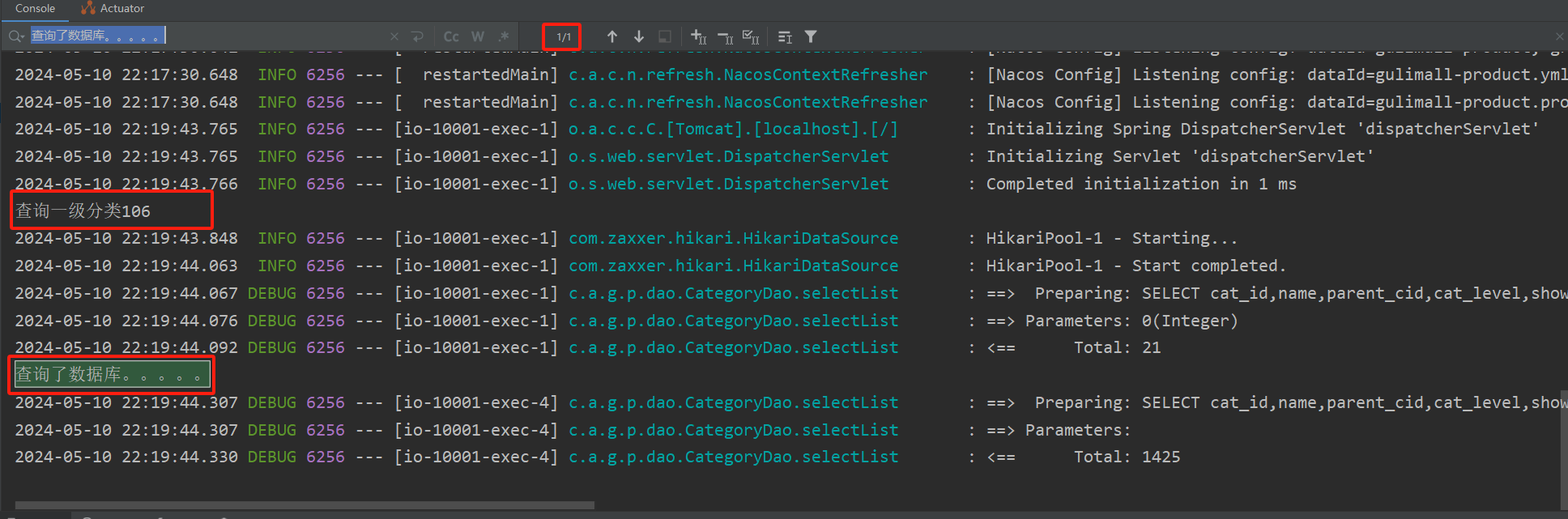
public Map<String, List<Catelog2Vo>> getCatalogJson() {
System.out.println("查询了数据库。。。。。");
List<CategoryEntity> selectList = baseMapper.selectList(null);
// 1、查出所有1级分类
List<CategoryEntity> level1Category = getParent_cid(selectList, 0L);
// 2、封装数据
Map<String, List<Catelog2Vo>> parent_cid = level1Category.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 2.1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
// 2.2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
// 2.2.1、找当前二级分类的三级分类封装vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Catalog3Vo> collect = level3Catelog.stream().map(l3 -> {
// 2.2.2、封装成指定格式
Catelog2Vo.Catalog3Vo catelog3Vo = new Catelog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(collect);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}再次访问,发现控制台数据未更新,还是第一次访问时的输出:
查看Redis中缓存的数据:
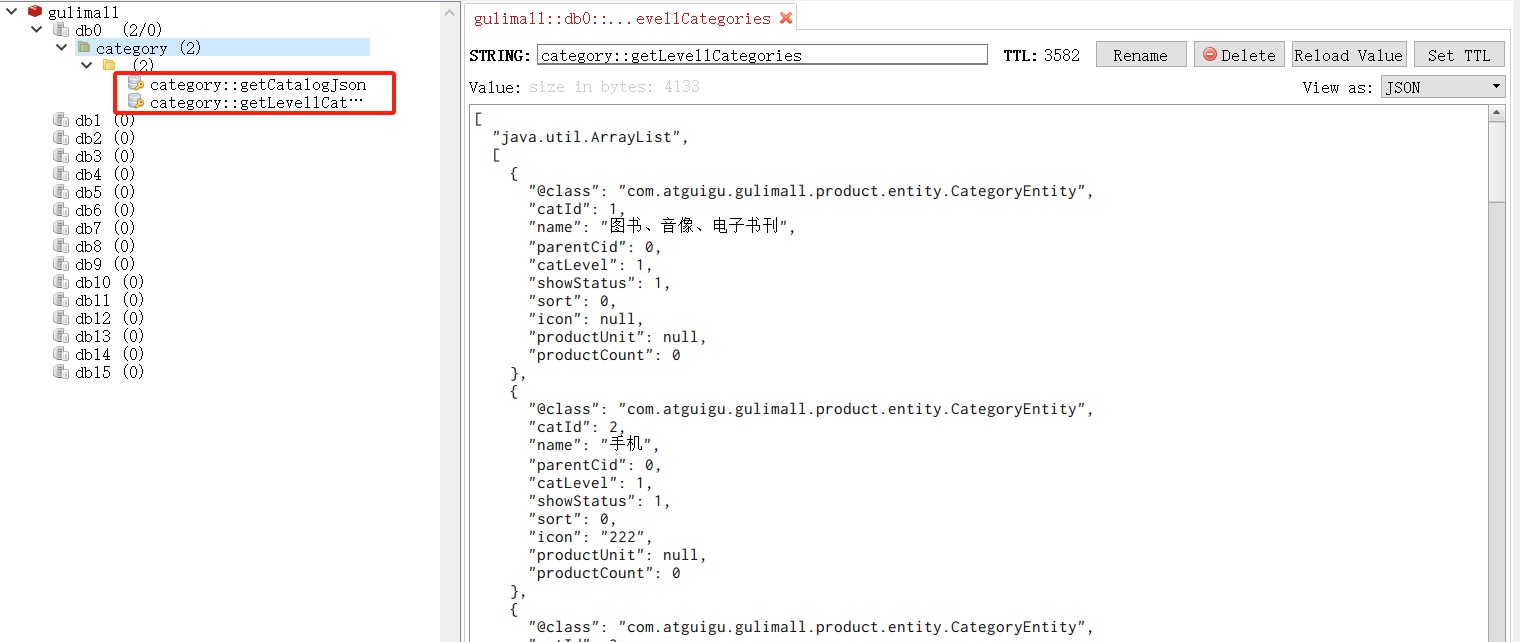
上面我们将一级和三级分类信息都缓存到了redis中,现在我们想要实现一种场景是,更新分类数据的时候,将缓存到redis中的一级和三级分类数据都清空。
借助于"@Caching"来完成
修改"CategoryServiceImpl"类,代码如下:
java
@Caching(evict={
@CacheEvict(value = {"category"},key = "'level1Categorys'"),
@CacheEvict(value = {"category"},key = "'getCatalogJson'")
})
@Override
@Transactional
public void updateCascade(CategoryEntity category) {
this.updateById(category);
relationService.updateCategory(category.getCatId(),category.getName());
}查询redis,一级和三级分类数据已经被删除。
除了可以使用@Cache外,还可以使用@CacheEvict来完成:
java
@CacheEvict(value = {"category"},allEntries = true)
@Override
@Transactional
public void updateCascade(CategoryEntity category) {
this.updateById(category);
relationService.updateCategory(category.getCatId(),category.getName());
}它表示要删除"category"分区下的所有数据。
可以看到存储同一类型的数据,都可以指定未同一个分区,可以批量删除这个分区下的数据。以后建议不使用分区前缀,而是使用默认的分区前缀。
- 小结:CacheEvict:失效模式
- 同时进行多种缓存操作 @Caching
- 指定删除某个分区下的所有数据
- 存储同一类型的数据,都可以指定成同一个分区。分区名默认就是缓存的前缀
7.9.7 SpringCache-原理与不足
- 读模式
- 缓存穿透:查询一个null值。解决,缓存空数据;cache-null-value=true;
- 缓存击穿:大量并发进来同时查询一个正好过期的数据。
- 解决方法,是进行加锁,默认是没有加锁的,
- 查询时设置Cacheable的
sync=true即可解决缓存击穿。
- 缓存雪崩:大量的key同时过期。解决方法:加上随机时间;加上过期时间。"spring.cache.redis.time-to-live=3600000"
- 写模式(缓存与数据一致)
- 读写加锁;
- 引入canal,感知到mysql的更新去更新数据库;
- 读多写少,直接去数据库查询就行;
- 总结
- 常规数据(读多写少,即时性,一致性要求不高的数据):完全可以使用spring-cache;
- 写模式:只要缓存的数据有过期时间就足够了;
- 特殊数据:特殊设计;