一、什么是Hive
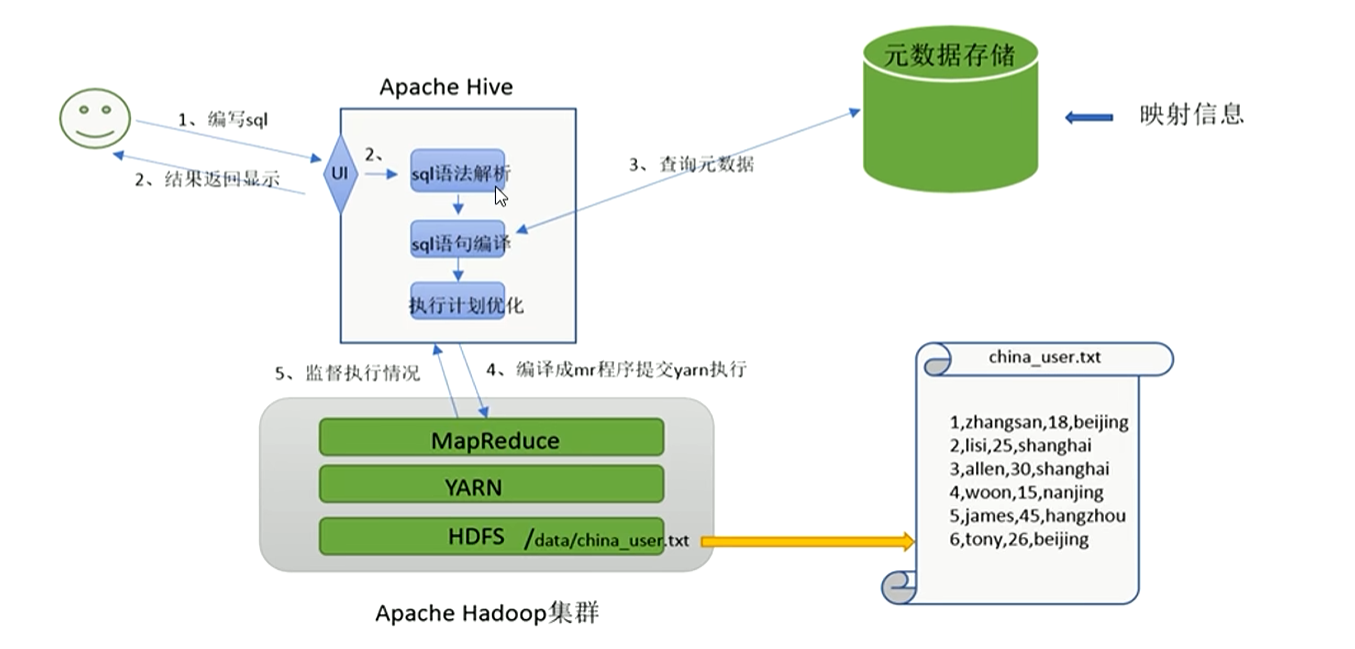
Apache Hive是一款建立在Hadoop上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似于SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop上大型数据集。
Hive的核心是将HQL转换为MapReduct程序,然后将程序提交到Hadoop集群执行。
Hive是有Fackbook实现并开源
hive的组成结构,其中Hive Driver是hive的核心部分
二、搭建Hive工具
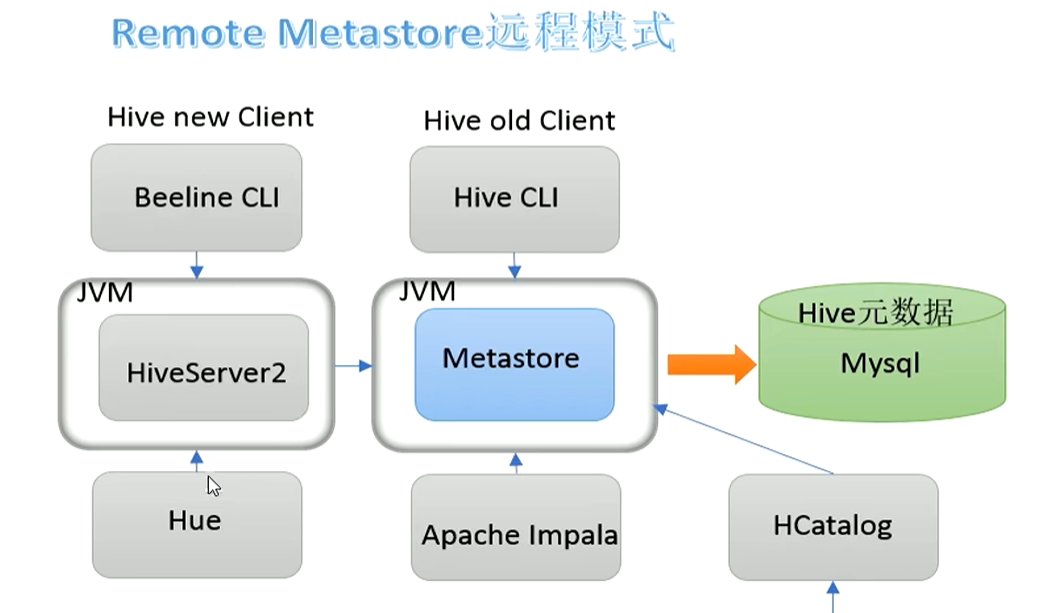
我们采用远程独立部署模式,hive的元数据存储需要依赖一个外部mysql,所以我们第一步先需要安装一个mysql ,我们在node02节点上搭建hive ,mysql安装好了后,现在开始正式搭建Hive。
1、HDFS配置修改
因为Hive需要把数据存储到HDFS上,并且通过MapReduce作为执行引擎处理数据,因此需要在Hadoop中添加相关配置,以满足hive在hadoop上运行,
我们需要修改Hadoop的core-site.xml配置
XML
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>分发配置到node02 、node03
XML
scp core-site.xml node02:$PWD
scp core-site.xml node03:$PWD重启hdfs
2、安装Hive
Hive只是个工具,我们只需要在一台集群上安装即可, 我们选择node02机器上安装使用。
2.1、复制hadoop的guava.jar包到hive的lib目录中
ssh连接上node02服务器
cd /export/server 进入软件安装目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz
XML
cd /export/server/apache-hive-3.1.2-bin/lib
rm -rf guava-19.0.jar
cp /export/server/hadoop-3.3.6/share/hadoop/common/lib/guava-27.0-jre.jar ./2.2、修改hive-env.sh配置
XML
export HADOOP_HOME=/export/server/hadoop-3.3.6
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib2.3、修改hive-site.xml配置
XML
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.31.20:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>JDBC connect string for a JDBC metastore. Added allowPublicKeyRetrieval=true for MySQL 8+ compatibility.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore. Use com.mysql.cj.jdbc.Driver for MySQL 8+.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value> </property>
<!--H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>192.168.31.20</value>
</property>
<!--远程部署模式 metastore服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.31.20:9083</value>
</property>
<!--关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>2.4、mysql驱动加载
下载一个mysql驱动jar包放到hive的lib目录下。
cp mysql-connector-java-8.0.20.jar /export/server/apache-hive-3.1.2-bin/lib
2.5、初始化hive元数据(mysql)表
cd /export/server/apache-hive-3.1.2-bin # 也可以将hive的bin目录配置到/etc/profile环境变量中
bin/schematool -initSchema -dbType mysql -verbos
2.6、创建hdfs对应目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /usr/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
2.7、hive客户端连接
先启动metastore服务 再启动 hiveserver2服务
nohup bin/hive --service metastore &
nohup bin/hive --service hiveserver2 &
hive的客户端连接
(1)、第一代客户端
live 进去
(2)、第二代客户端
beeline 进去
!connect jdbc:hive2://node02:10000
root
直接回车
三、hive的简单使用
drop database example;
create database example;
use example;
create table t_archer (
id int ,
name string comment '名称',
hp_max int comment '最大hp量',
mp_max int comment '最大mp值',
attach_max int comment '最大物理攻击',
defense_max int comment '最大物理防御'
)
row format delimited fields terminated by "\t";
show tables in 库名;
show formtted t_archer ; -- 查看表的元信息
hive3的表中文注释乱码问题处理
XML
ALTER TABLE COLUMNS_V2 MODIFY COLUMN COMMENT VARCHAR(256) CHARACTER SET utf8;
ALTER TABLE TABLE_PARAMS MODIFY COLUMN PARAM_VALUE VARCHAR(4000) CHARACTER SET utf8;
ALTER TABLE PARTITION_PARAMS MODIFY COLUMN PARAM_VALUE VARCHAR(4000) CHARACTER SET utf8;
ALTER TABLE PARTITION_KEYS MODIFY COLUMN PKEY_COMMENT VARCHAR(4000) CHARACTER SET utf8;
ALTER TABLE INDEX_PARAMS MODIFY COLUMN PARAM_VALUE VARCHAR(4000) CHARACTER SET utf8;load data local inpath '/xx/xx' overwrite into table table_name;
创建表
create table t_user (
id int ,
name string,
age int
) row format delimited fields terminated by ",";
insert 插入数据
insert into t_user values (1,'张三',22),(2,'李四',24),(3,'王五',25);
聚合函数
avg()
count()
max()
min()
sum()
....
CTAS 语句一步到位,将SQL查询数据结果生成一个新的表, 抽取数据
ETL 数据清洗
抽取、转换、加载
tb_msg_source
tb_msg_etl
create table t_test as
select msg_time,sender_name from tb_msg_source limit 5;