参考
要在现有的 Hadoop 容器中安装 Zookeeper,我们需要执行以下步骤:

📁 目录结构规划
bash
mkdir ~/hive-docker
cd ~/hive-docker
hive-docker/
├── apache-hive-3.1.3-bin.tar.gz # 本地已有的 Hive 包
├── mysql-connector-java-8.0.31.jar # 本地已有的 MySQL 驱动
├── Dockerfile # Docker 构建文件
├── hive-site.xml # Hive 配置文件
├── hive-env.sh # Hive 环境配置
├── hive-log4j2.properties # Hive 日志配置
├── beeline-log4j2.properties # Beeline 日志配置
└── start-hive.sh # hive启动脚本🛠️ 修正后的 Dockerfile
dockerfile
FROM hadoop-pseudo:3.3.0
# 设置环境变量
ENV HIVE_VERSION=3.1.3
ENV HIVE_HOME=/opt/hive
ENV PATH=$PATH:$HIVE_HOME/bin
ENV HADOOP_HOME=/usr/local/hadoop
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 安装必要的软件包
RUN apt-get update && \
apt-get install -y \
tar \
mysql-server \
mysql-client \
python3 \
python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 复制本地已下载的 Hive 和 MySQL 驱动
COPY apache-hive-${HIVE_VERSION}-bin.tar.gz /tmp/
COPY mysql-connector-java-8.0.31.jar /tmp/
# 解压并安装 Hive
RUN tar -zxvf /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz -C /opt/ && \
mv /opt/apache-hive-${HIVE_VERSION}-bin ${HIVE_HOME} && \
rm /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz
# 安装 MySQL JDBC 驱动
RUN mkdir -p ${HIVE_HOME}/lib && \
cp /tmp/mysql-connector-java-8.0.31.jar ${HIVE_HOME}/lib/ && \
rm /tmp/mysql-connector-java-8.0.31.jar
# 创建必要的目录
RUN mkdir -p ${HIVE_HOME}/logs \
&& mkdir -p ${HIVE_HOME}/tmp \
&& mkdir -p /var/lib/mysql-files \
&& chown -R root:root ${HIVE_HOME}
# 配置 MySQL 作为 Hive Metastore
RUN service mysql start && \
mysql -e "CREATE DATABASE metastore;" && \
mysql -e "CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';" && \
mysql -e "GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';" && \
mysql -e "FLUSH PRIVILEGES;" && \
service mysql stop
# 复制配置文件
COPY hive-site.xml ${HIVE_HOME}/conf/
COPY hive-env.sh ${HIVE_HOME}/conf/
COPY hive-log4j2.properties ${HIVE_HOME}/conf/
COPY beeline-log4j2.properties ${HIVE_HOME}/conf/
# 设置权限
RUN chmod +x ${HIVE_HOME}/bin/* \
&& chmod +x ${HIVE_HOME}/sbin/*
# 暴露端口
EXPOSE 10000 10002 9999 9998 9083
# 创建启动脚本
RUN echo '#!/bin/bash\n\
\n\
# 启动 MySQL 服务\n\
echo "Starting MySQL service..."\n\
service mysql start\n\
\n\
# 等待 MySQL 启动\n\
sleep 5\n\
\n\
# 检查 MySQL 是否正常启动\n\
if ! service mysql status > /dev/null 2>&1; then\n\
echo "MySQL failed to start, initializing..." \n\
mysql_install_db --user=mysql --ldata=/var/lib/mysql\n\
service mysql restart\n\
sleep 5\n\
fi\n\
\n\
# 初始化 Hive Metastore Schema\n\
echo "Initializing Hive Metastore Schema..." \n\
${HIVE_HOME}/bin/schematool -dbType mysql -initSchema --verbose\n\
\n\
# 启动 Hadoop 服务(如果需要)\n\
if [ -d "${HADOOP_HOME}" ]; then\n\
echo "Starting Hadoop services..." \n\
cd ${HADOOP_HOME}\n\
sbin/start-dfs.sh\n\
sbin/start-yarn.sh\n\
fi\n\
\n\
# 启动 Hive Metastore 服务\n\
echo "Starting Hive Metastore..." \n\
${HIVE_HOME}/bin/hive --service metastore &\n\
\n\
# 启动 HiveServer2 服务\n\
echo "Starting HiveServer2..." \n\
${HIVE_HOME}/bin/hiveserver2 &\n\
\n\
# 保持容器运行\n\
echo "All services started. Container running..." \n\
tail -f /dev/null' > /start-hive.sh
RUN chmod +x /start-hive.sh
CMD ["/start-hive.sh"]⚙️ 配置文件内容
hive-site.xml
xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- MySQL Metastore 配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<!-- 其他配置 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://0.0.0.0:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'</description>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
<description>Port for WebUI</description>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
<description>authentication for hive server2</description>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Throw an exception if there's a mismatch.
False: Wipe clean the existing schema and initialize it with new schema.
</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive/tmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive/tmp/resources</value>
<description>Where local resources will be downloaded from remote locations</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hive/tmp/querylog</value>
<description>Location for query logs</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hive/tmp/operation_logs</value>
<description>Location for HiveServer2 logs</description>
</property>
</configuration>
EOFhive-env.sh
bash
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=/opt/hive/conf
export METASTORE_PORT=9083hive-log4j2.properties
properties
status = INFO
name = HiveLog4j2
packages = org.apache.hadoop.hive.ql.log
# Property with default values
property.hive.log.level = INFO
property.hive.root.logger = DRFA
property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}/logs
property.hive.log.file = hive.log
# Console appender should be used by IT tests
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} [%t]: %p %c{2}: %m%n
appender.DRFA.type = RollingFile
appender.DRFA.name = DRFA
appender.DRFA.fileName = ${sys:hive.log.dir}/${sys:hive.log.file}
appender.DRFA.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.%i
appender.DRFA.layout.type = PatternLayout
appender.DRFA.layout.pattern = %d{ISO8601} %-5p [%t]: %c{2} (%F:%L) - %m%n
appender.DRFA.policies.type = Policies
appender.DRFA.policies.size.type = SizeBasedTriggeringPolicy
appender.DRFA.policies.size.size = 10MB
appender.DRFA.strategy.type = DefaultRolloverStrategy
appender.DRFA.strategy.max = 10
logger.basedepcopy.name = org.apache.hadoop.hive.ql.exec.CopyTask
logger.basedepcopy.level = WARN
logger.basedepcopy.additivity = false
logger.basedepcopy.appenderRef = DRFA
rootLogger.level = ${sys:hive.log.level}
rootLogger.appenderRef = ${sys:hive.root.logger}beeline-log4j2.properties
properties
status = INFO
name = BeelineLog4j2
packages = org.apache.hadoop.hive.ql.log
# Property with default values
property.beeline.log.level = INFO
property.beeline.root.logger = console
# Console appender
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} [%t]: %p %c{2}: %m%n
rootLogger.level = ${sys:beeline.log.level}
rootLogger.appenderRef = ${sys:beeline.root.logger}🚀 安装步骤
1. 准备文件
bash
# 创建构建目录
mkdir -p ~/hive-docker && cd ~/hive-docker
# 确保本地有这两个文件
ls -la ~/apache-hive-3.1.3-bin.tar.gz
ls -la ~/mysql-connector-java-8.0.31.jar
# 复制到构建目录
cp ~/apache-hive-3.1.3-bin.tar.gz ./
cp ~/mysql-connector-java-8.0.31.jar ./2. 新增:生成配置文件到构建目录和 ~/hadoop-conf 目录
bash
# 创建配置目录
mkdir -p ~/hive-confhive-site.xml
bash
# 将配置文件复制到构建目录和 ~/hadoop-conf 目录
cat > ~/hive-docker/hive-site.xml << 'EOF'
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- MySQL Metastore 配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true&useSSL=false&allowPublicKeyRetrieval=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<!-- 其他配置 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://0.0.0.0:9083</value>
<description>IP address (or fully-qualified domain name) and port of the metastore host</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'</description>
</property>
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
<description>Port for WebUI</description>
</property>
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
<description>authentication for hive server2</description>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoStartMechanism</name>
<value>SchemaTable</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Throw an exception if there's a mismatch.
False: Wipe clean the existing schema and initialize it with new schema.
</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hive/tmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hive/tmp/resources</value>
<description>Where local resources will be downloaded from remote locations</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hive/tmp/querylog</value>
<description>Location for query logs</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hive/tmp/operation_logs</value>
<description>Location for HiveServer2 logs</description>
</property>
</configuration>
EOFhive-env.sh
bash
cat > ~/hive-docker/hive-env.sh << 'EOF'
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=/opt/hive/conf
export METASTORE_PORT=9083
EOFhive-log4j2.properties
bash
cat > ~/hive-docker/hive-log4j2.properties << 'EOF'
status = INFO
name = HiveLog4j2
packages = org.apache.hadoop.hive.ql.log
# Property with default values
property.hive.log.level = INFO
property.hive.root.logger = DRFA
property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}/logs
property.hive.log.file = hive.log
# Console appender should be used by IT tests
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} [%t]: %p %c{2}: %m%n
appender.DRFA.type = RollingFile
appender.DRFA.name = DRFA
appender.DRFA.fileName = ${sys:hive.log.dir}/${sys:hive.log.file}
appender.DRFA.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.%i
appender.DRFA.layout.type = PatternLayout
appender.DRFA.layout.pattern = %d{ISO8601} %-5p [%t]: %c{2} (%F:%L) - %m%n
appender.DRFA.policies.type = Policies
appender.DRFA.policies.size.type = SizeBasedTriggeringPolicy
appender.DRFA.policies.size.size = 10MB
appender.DRFA.strategy.type = DefaultRolloverStrategy
appender.DRFA.strategy.max = 10
logger.basedepcopy.name = org.apache.hadoop.hive.ql.exec.CopyTask
logger.basedepcopy.level = WARN
logger.basedepcopy.additivity = false
logger.basedepcopy.appenderRef = DRFA
rootLogger.level = ${sys:hive.log.level}
rootLogger.appenderRef = ${sys:hive.root.logger}
EOFbeeline-log4j2.properties
bash
cat > ~/hive-docker/beeline-log4j2.properties << 'EOF'
status = INFO
name = BeelineLog4j2
packages = org.apache.hadoop.hive.ql.log
# Property with default values
property.beeline.log.level = INFO
property.beeline.root.logger = console
# Console appender
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} [%t]: %p %c{2}: %m%n
rootLogger.level = ${sys:beeline.log.level}
rootLogger.appenderRef = ${sys:beeline.root.logger}
EOF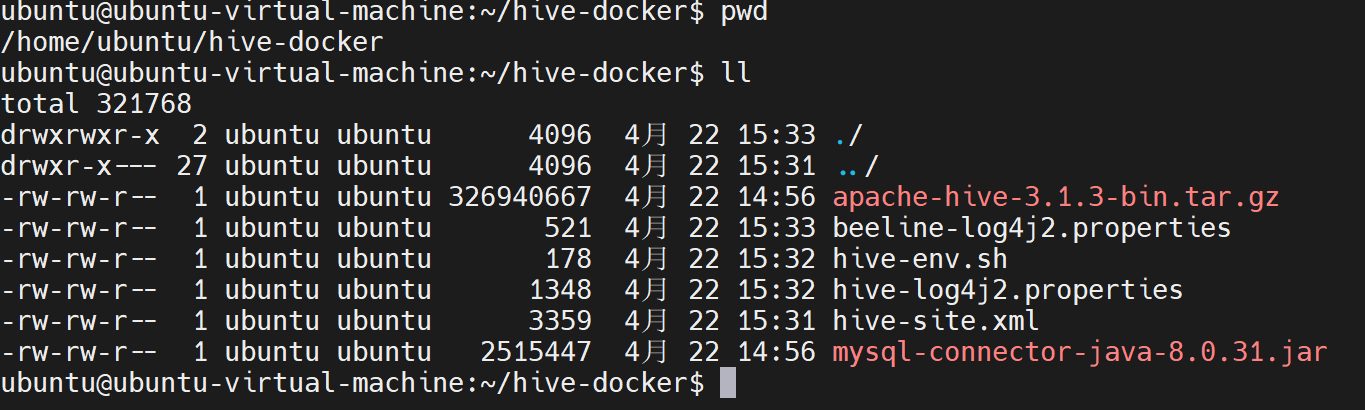
复制配置文件到~/hive-conf/
bash
# 同时复制到 ~/hadoop-conf 目录(用于可能的共享配置需求)
cp ~/hive-docker/hive-site.xml ~/hive-conf/
cp ~/hive-docker/hive-env.sh ~/hive-conf/
cp ~/hive-docker/hive-log4j2.properties ~/hive-conf/
cp ~/hive-docker/beeline-log4j2.properties ~/hive-conf/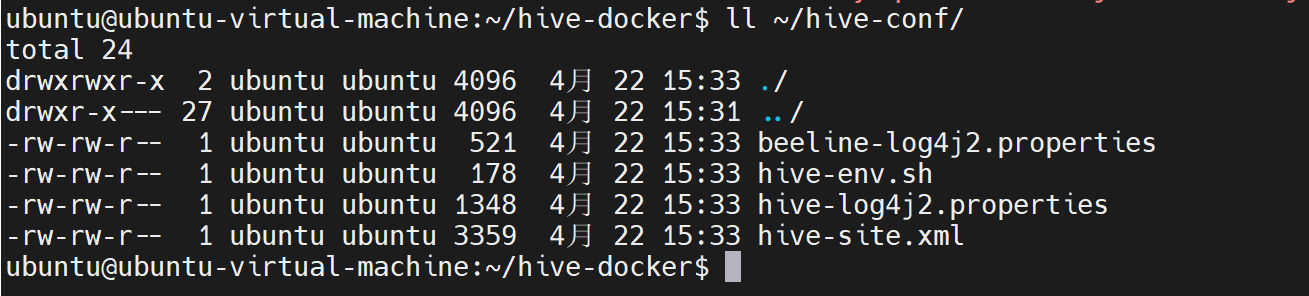
Dockerfile文件
bash
cat > ~/hive-docker/Dockerfile << 'EOF'
FROM hadoop-pseudo:3.3.0
# 设置环境变量
ENV HIVE_VERSION=3.1.3
ENV HIVE_HOME=/opt/hive
ENV PATH=$PATH:$HIVE_HOME/bin
ENV HADOOP_HOME=/usr/local/hadoop
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 安装必要的软件包
RUN apt-get update && \
apt-get install -y \
tar \
mysql-server \
mysql-client \
python3 \
python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 复制本地已下载的 Hive 和 MySQL 驱动
COPY apache-hive-${HIVE_VERSION}-bin.tar.gz /tmp/
COPY mysql-connector-java-8.0.31.jar /tmp/
# 解压并安装 Hive
RUN tar -zxvf /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz -C /opt/ && \
mv /opt/apache-hive-${HIVE_VERSION}-bin ${HIVE_HOME} && \
rm /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz
# 安装 MySQL JDBC 驱动
RUN mkdir -p ${HIVE_HOME}/lib && \
cp /tmp/mysql-connector-java-8.0.31.jar ${HIVE_HOME}/lib/ && \
rm /tmp/mysql-connector-java-8.0.31.jar
# 创建必要的目录
RUN mkdir -p ${HIVE_HOME}/logs \
&& mkdir -p ${HIVE_HOME}/tmp \
&& mkdir -p /var/lib/mysql-files \
&& chown -R root:root ${HIVE_HOME}
# 配置 MySQL 作为 Hive Metastore
RUN service mysql start && \
mysql -e "CREATE DATABASE metastore;" && \
mysql -e "CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';" && \
mysql -e "GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';" && \
mysql -e "FLUSH PRIVILEGES;" && \
service mysql stop
# 复制配置文件
COPY hive-site.xml ${HIVE_HOME}/conf/
COPY hive-env.sh ${HIVE_HOME}/conf/
COPY hive-log4j2.properties ${HIVE_HOME}/conf/
COPY beeline-log4j2.properties ${HIVE_HOME}/conf/
# 设置权限
RUN chmod +x ${HIVE_HOME}/bin/* \
&& chmod +x ${HIVE_HOME}/sbin/*
# 暴露端口
EXPOSE 10000 10002 9999 9998 9083
# 创建启动脚本
RUN echo '#!/bin/bash\n\
\n\
# 启动 MySQL 服务\n\
echo "Starting MySQL service..."\n\
service mysql start\n\
\n\
# 等待 MySQL 启动\n\
sleep 5\n\
\n\
# 检查 MySQL 是否正常启动\n\
if ! service mysql status > /dev/null 2>&1; then\n\
echo "MySQL failed to start, initializing..." \n\
mysql_install_db --user=mysql --ldata=/var/lib/mysql\n\
service mysql restart\n\
sleep 5\n\
fi\n\
\n\
# 初始化 Hive Metastore Schema\n\
echo "Initializing Hive Metastore Schema..." \n\
${HIVE_HOME}/bin/schematool -dbType mysql -initSchema --verbose\n\
\n\
# 启动 Hadoop 服务(如果需要)\n\
if [ -d "${HADOOP_HOME}" ]; then\n\
echo "Starting Hadoop services..." \n\
cd ${HADOOP_HOME}\n\
sbin/start-dfs.sh\n\
sbin/start-yarn.sh\n\
fi\n\
\n\
# 启动 Hive Metastore 服务\n\
echo "Starting Hive Metastore..." \n\
${HIVE_HOME}/bin/hive --service metastore &\n\
\n\
# 启动 HiveServer2 服务\n\
echo "Starting HiveServer2..." \n\
${HIVE_HOME}/bin/hiveserver2 &\n\
\n\
# 保持容器运行\n\
echo "All services started. Container running..." \n\
tail -f /dev/null' > /start-hive.sh
RUN chmod +x /start-hive.sh
CMD ["/start-hive.sh"]
EOF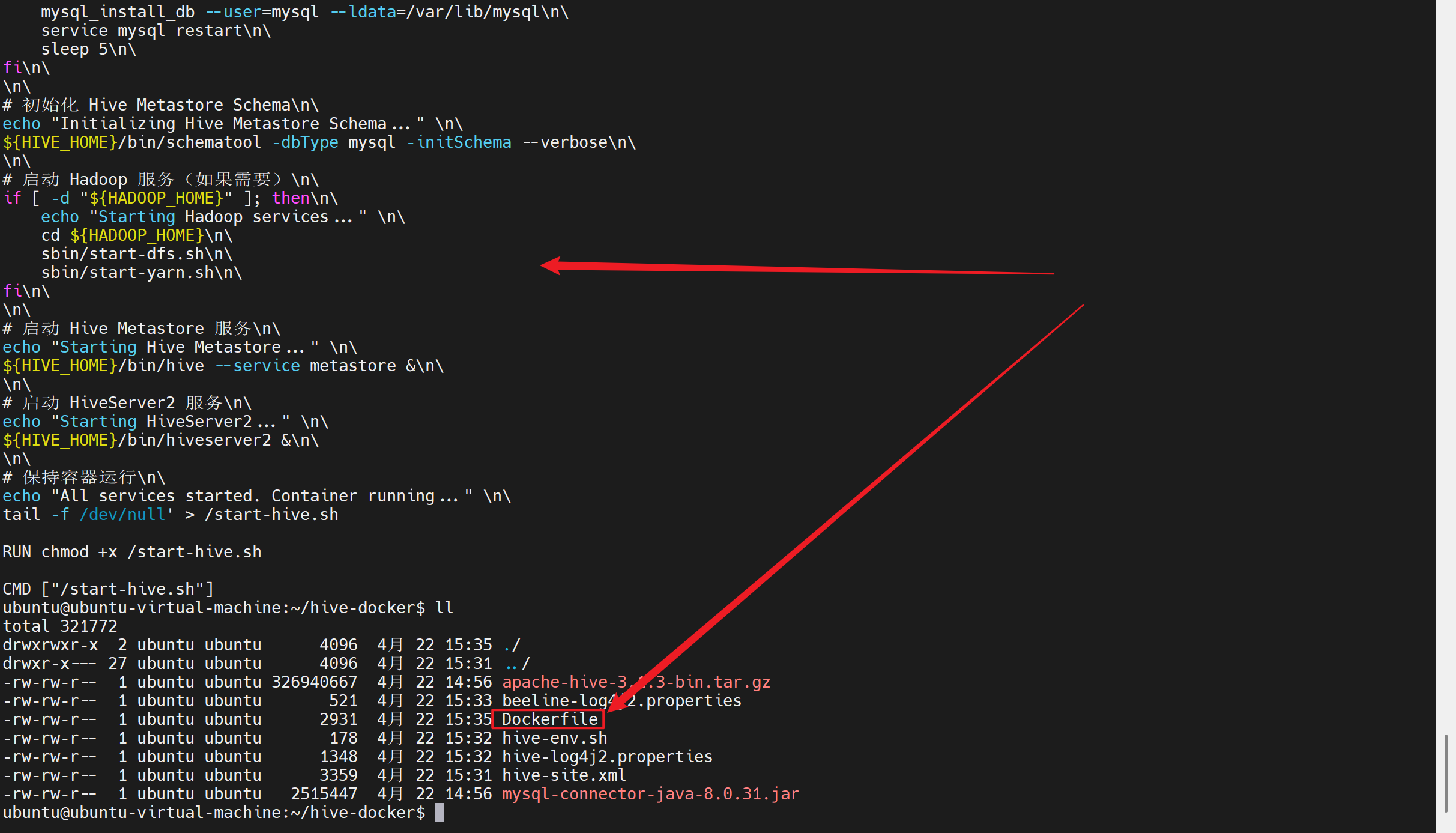
3. 验证文件完整性
bash
# 检查所有必需文件
ls -la
# 应该看到:
# apache-hive-3.1.3-bin.tar.gz
# mysql-connector-java-8.0.31.jar
# Dockerfile
# hive-site.xml
# hive-env.sh
# hive-log4j2.properties
# beeline-log4j2.properties4. 构建镜像
bash
# 构建镜像
docker build -t hadoop-pseudo-hive:3.3.0 .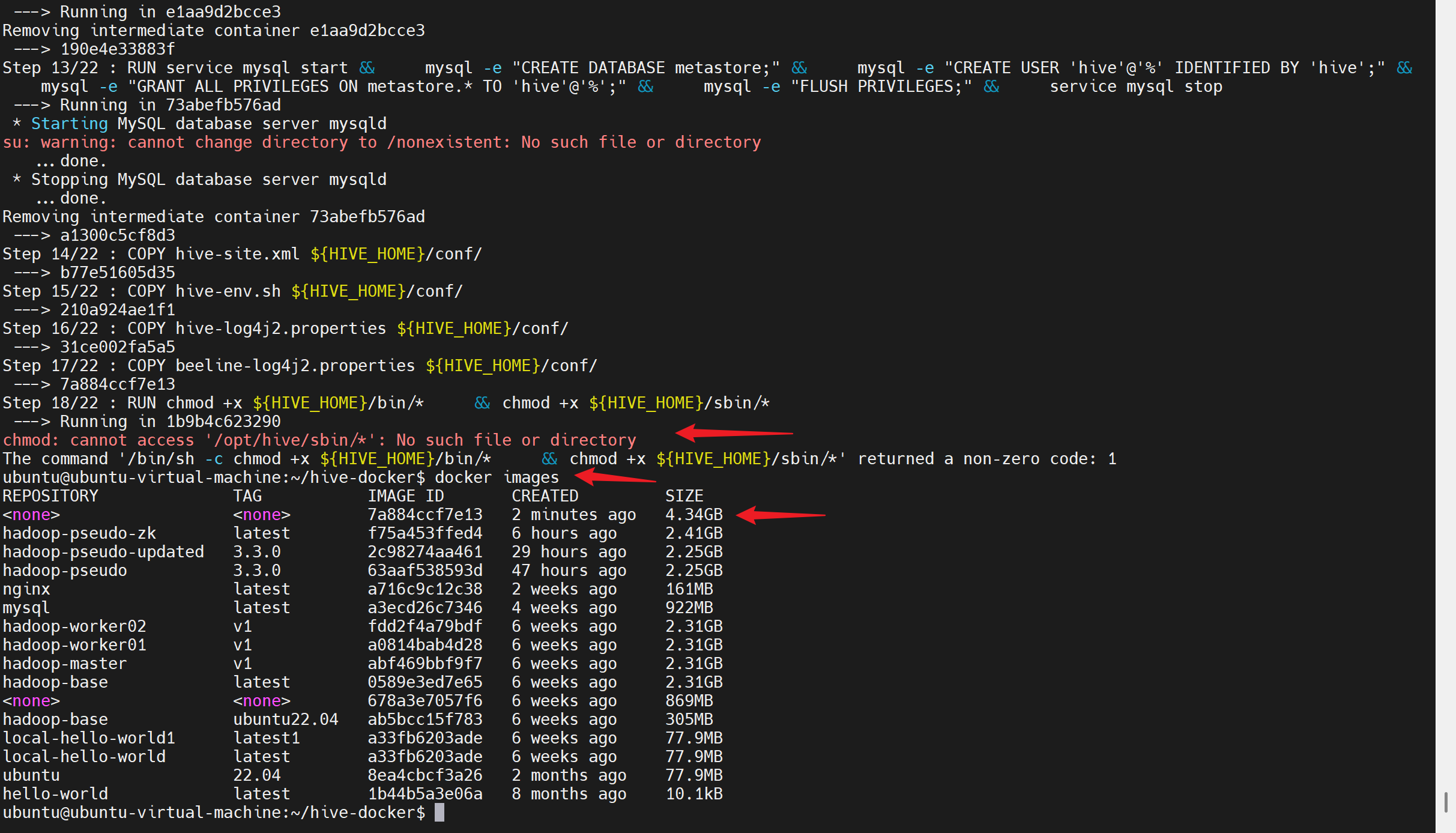
能看出来构建失败了,删除镜像,根据具体id配置
bash
# 删除未完成的中间镜像 会有临时容器 需要强制删除-f
docker rmi -f 7a884ccf7e13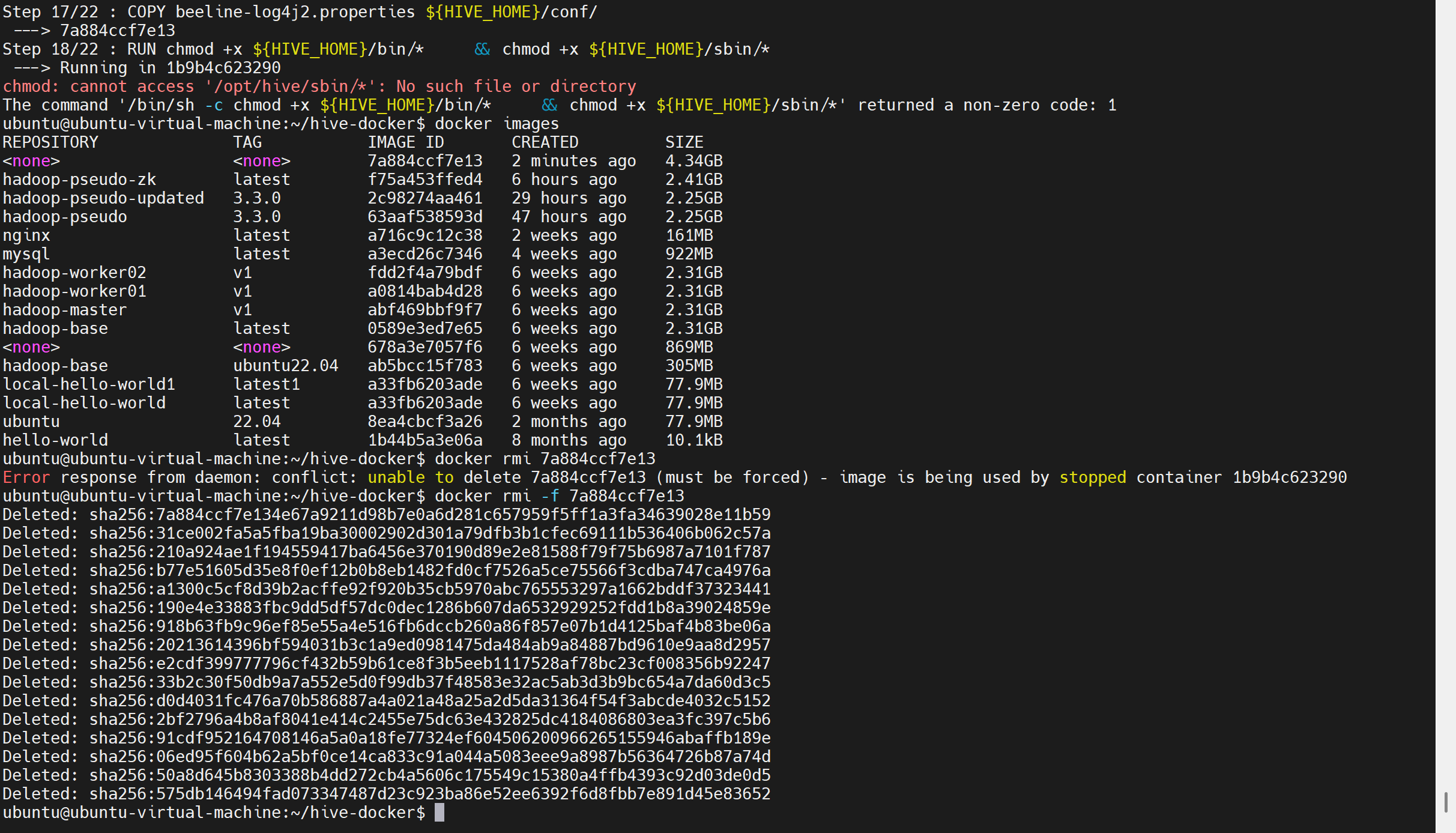
bash
# 清理所有停止的容器
docker container prune -f
# 清理所有悬空镜像(<none> 标签的镜像)
docker image prune -f
# 或者清理所有未使用的资源
docker system prune -f5.重新修改Dockerfile并构建-解决hive/sbin问题
bash
# 确保 Dockerfile 已经更新(这是最关键的一步)
cat > ~/hive-docker/Dockerfile << 'EOF'
FROM hadoop-pseudo:3.3.0
# 设置环境变量
ENV HIVE_VERSION=3.1.3
ENV HIVE_HOME=/opt/hive
ENV PATH=$PATH:$HIVE_HOME/bin
ENV HADOOP_HOME=/usr/local/hadoop
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 安装必要的软件包
RUN apt-get update && \
apt-get install -y \
tar \
mysql-server \
mysql-client \
python3 \
python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 复制本地已下载的 Hive 和 MySQL 驱动
COPY apache-hive-${HIVE_VERSION}-bin.tar.gz /tmp/
COPY mysql-connector-java-8.0.31.jar /tmp/
# 解压并安装 Hive
RUN tar -zxvf /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz -C /opt/ && \
mv /opt/apache-hive-${HIVE_VERSION}-bin ${HIVE_HOME} && \
rm /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz
# 安装 MySQL JDBC 驱动
RUN mkdir -p ${HIVE_HOME}/lib && \
cp /tmp/mysql-connector-java-8.0.31.jar ${HIVE_HOME}/lib/ && \
rm /tmp/mysql-connector-java-8.0.31.jar
# 创建必要的目录
RUN mkdir -p ${HIVE_HOME}/logs \
&& mkdir -p ${HIVE_HOME}/tmp \
&& mkdir -p /var/lib/mysql-files \
&& chown -R root:root ${HIVE_HOME}
# 配置 MySQL 作为 Hive Metastore
RUN service mysql start && \
mysql -e "CREATE DATABASE metastore;" && \
mysql -e "CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';" && \
mysql -e "GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';" && \
mysql -e "FLUSH PRIVILEGES;" && \
service mysql stop
# 复制配置文件
COPY hive-site.xml ${HIVE_HOME}/conf/
COPY hive-env.sh ${HIVE_HOME}/conf/
COPY hive-log4j2.properties ${HIVE_HOME}/conf/
COPY beeline-log4j2.properties ${HIVE_HOME}/conf/
# 设置权限 - 仅设置 bin 目录,因为 Hive 没有 sbin 目录
RUN chmod +x ${HIVE_HOME}/bin/*
# 暴露端口
EXPOSE 10000 10002 9999 9998 9083
# 创建启动脚本
RUN echo '#!/bin/bash\n\
\n\
# 启动 MySQL 服务\n\
echo "Starting MySQL service..."\n\
service mysql start\n\
\n\
# 等待 MySQL 启动\n\
sleep 5\n\
\n\
# 检查 MySQL 是否正常启动\n\
if ! service mysql status > /dev/null 2>&1; then\n\
echo "MySQL failed to start, initializing..." \n\
mysql_install_db --user=mysql --ldata=/var/lib/mysql\n\
service mysql restart\n\
sleep 5\n\
fi\n\
\n\
# 初始化 Hive Metastore Schema\n\
echo "Initializing Hive Metastore Schema..." \n\
${HIVE_HOME}/bin/schematool -dbType mysql -initSchema --verbose\n\
\n\
# 启动 Hadoop 服务(如果需要)\n\
if [ -d "${HADOOP_HOME}" ]; then\n\
echo "Starting Hadoop services..." \n\
cd ${HADOOP_HOME}\n\
sbin/start-dfs.sh\n\
sbin/start-yarn.sh\n\
fi\n\
\n\
# 启动 Hive Metastore 服务\n\
echo "Starting Hive Metastore..." \n\
${HIVE_HOME}/bin/hive --service metastore &\n\
\n\
# 启动 HiveServer2 服务\n\
echo "Starting HiveServer2..." \n\
${HIVE_HOME}/bin/hiveserver2 &\n\
\n\
# 保持容器运行\n\
echo "All services started. Container running..." \n\
tail -f /dev/null' > /start-hive.sh
RUN chmod +x /start-hive.sh
CMD ["/start-hive.sh"]
EOF
bash
# 重新构建镜像
cd ~/hive-docker
docker build -t hadoop-pseudo-hive:3.3.0 .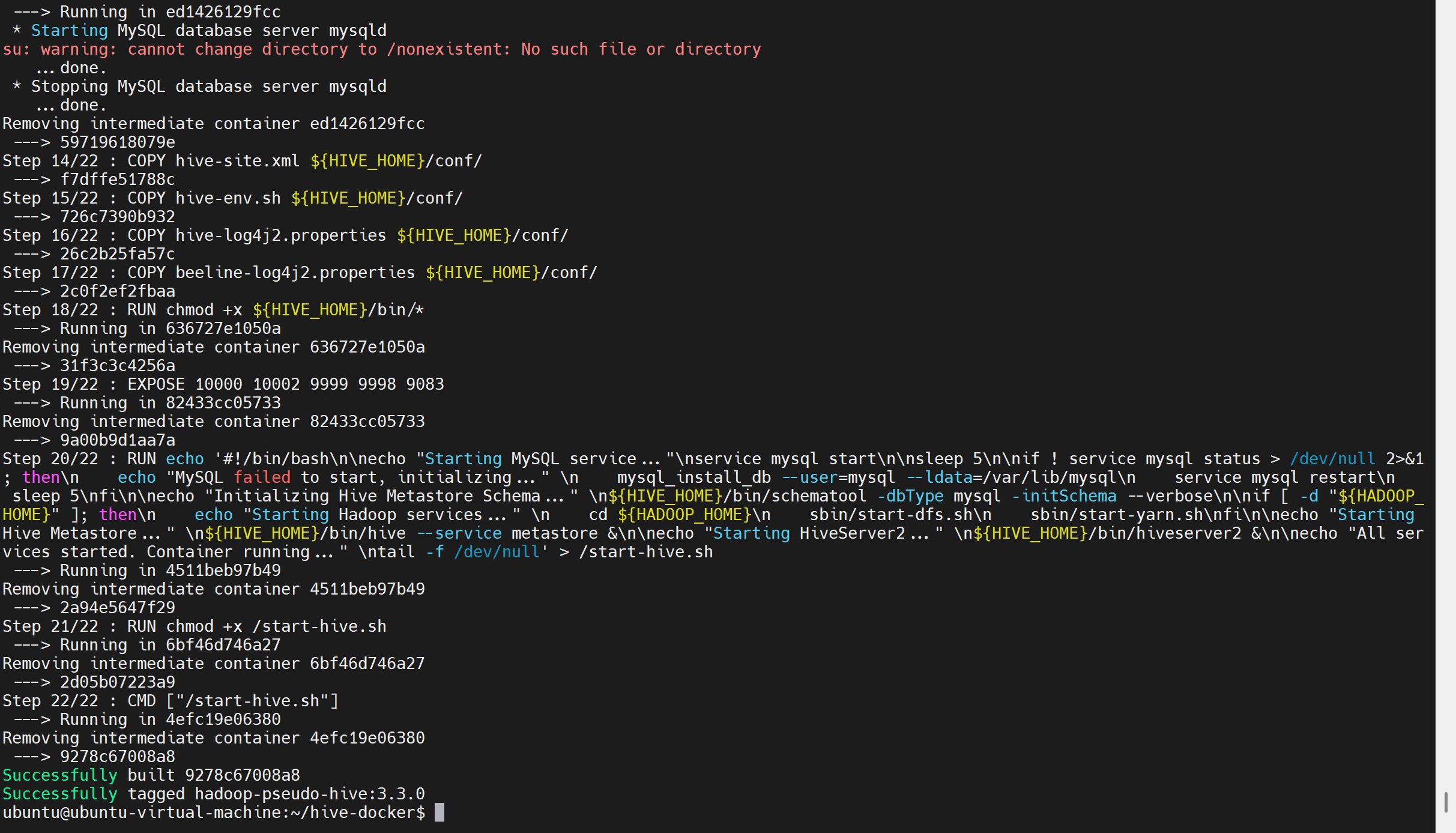
bash
docker run --rm hadoop-pseudo-hive:3.3.0 ls -la /opt/hive/bin/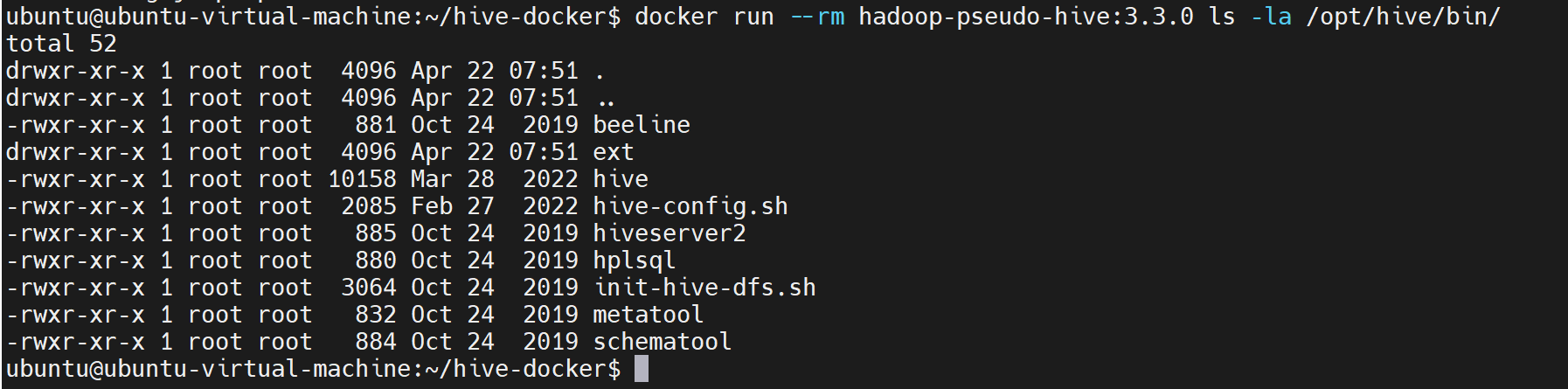
6. 运行容器
bash
docker run -d \
--name hadoop-pseudo-hive \
--hostname hadoop-pseudo-hive \
--network custom-network \
--ip 172.20.240.12 \
-p 9870:9870 \
-p 8088:8088 \
-p 8042:8042 \
-p 9000:9000 \
-p 10000:10000 \
-p 10002:10002 \
-p 9083:9083 \
-v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop \
-v ~/hive-conf:/opt/hive/conf \
-v hive-metastore:/var/lib/mysql \
-v pseudo-hadoop-namenode:/hadoop-data/namenode \
-v pseudo-hadoop-datanode:/hadoop-data/datanode \
-v pseudo-hadoop-tmp:/hadoop-data/tmp \
--privileged \
hadoop-pseudo-hive:3.3.0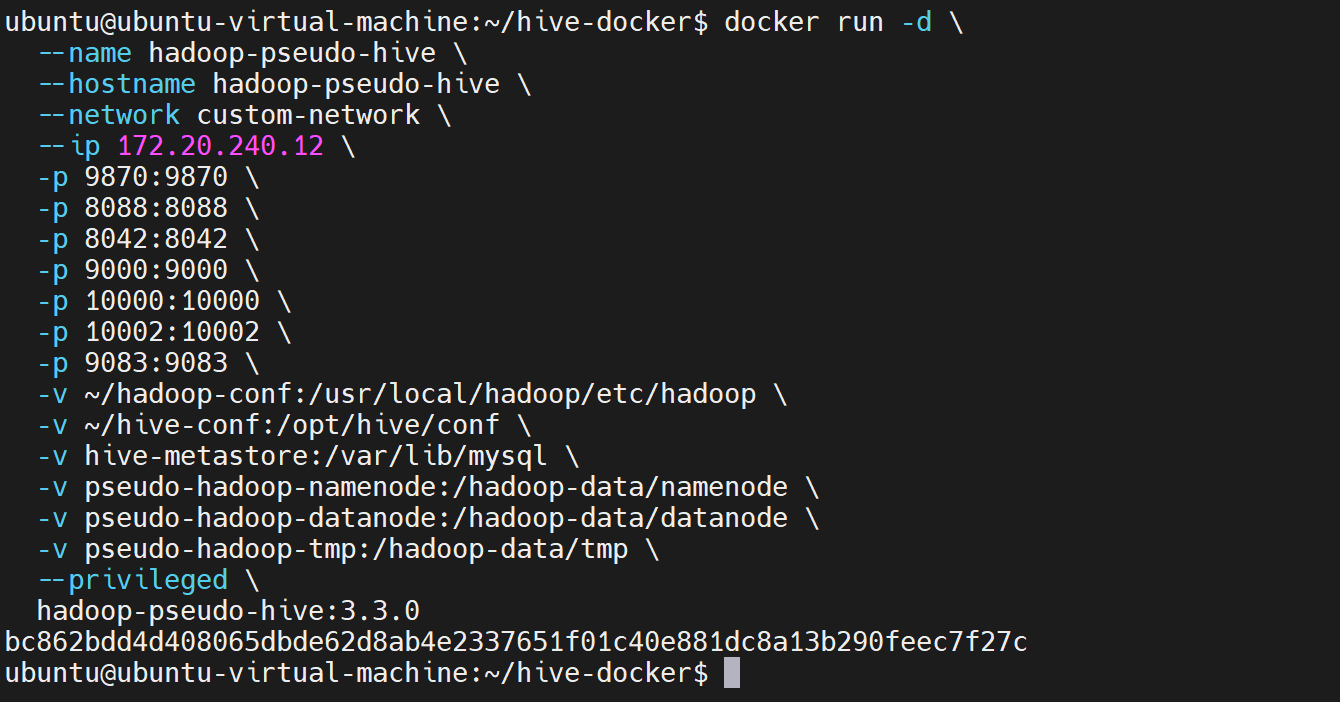
7. 验证安装
bash
# 等待容器启动
sleep 90
# 查看容器日志
docker logs -f hadoop-pseudo-hive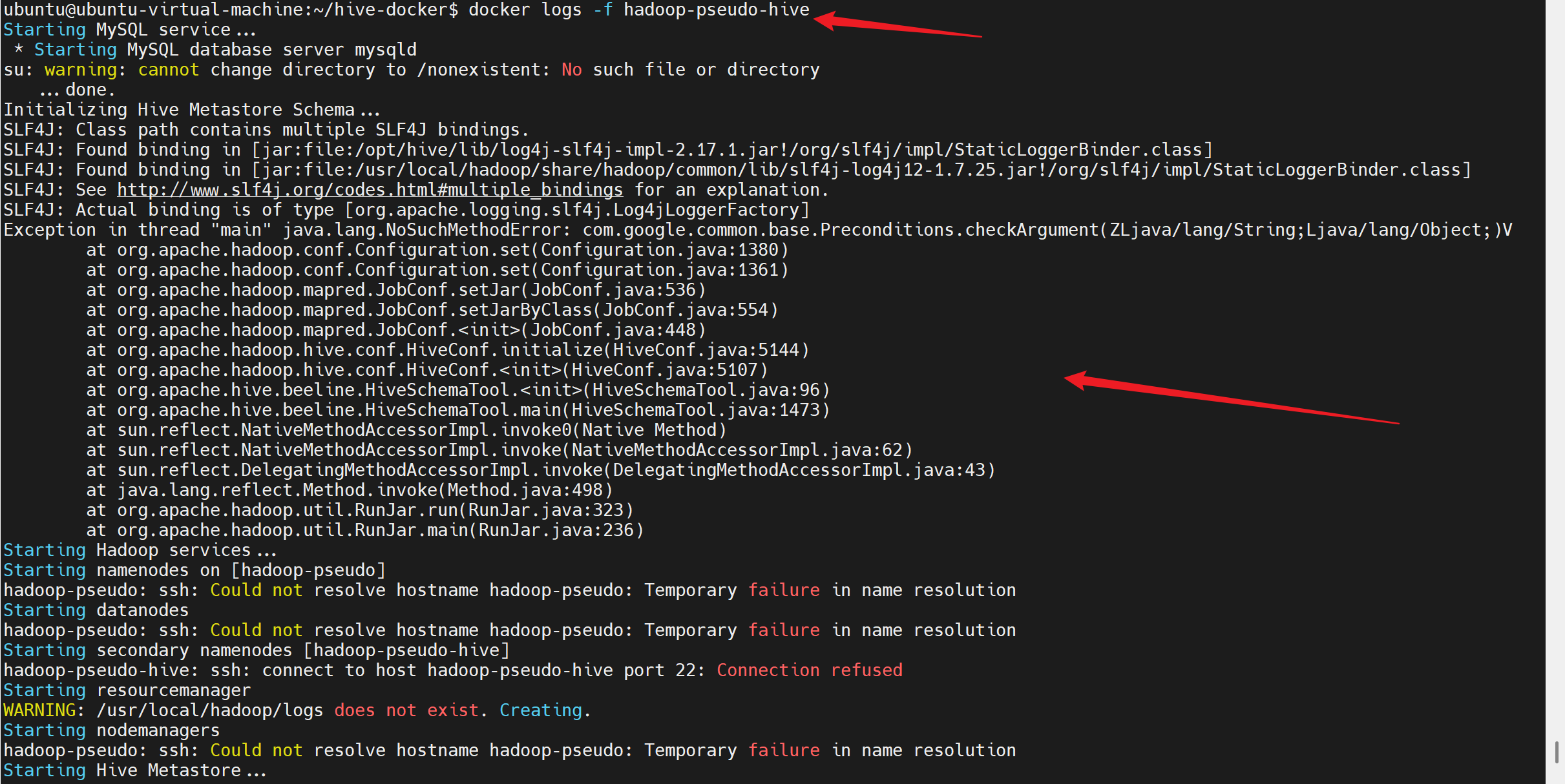
这个问题是hive与hadoop的guava版本兼容问题
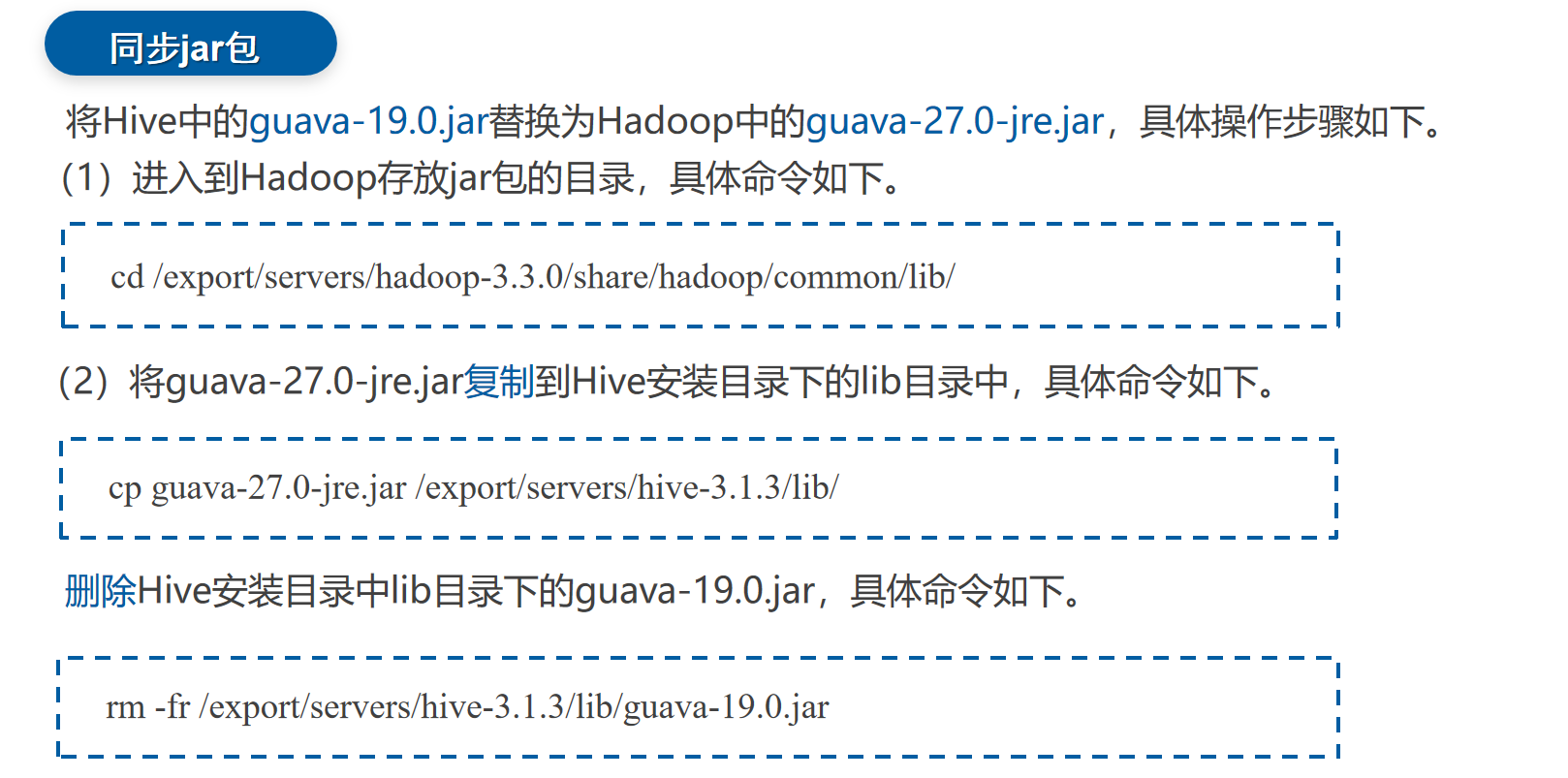
8.重新修改Dockerfile并构建-解决guava版本
bash
# 更新 Dockerfile,使用更清晰的步骤
cat > ~/hive-docker/Dockerfile << 'EOF'
FROM hadoop-pseudo:3.3.0
# 设置环境变量
ENV HIVE_VERSION=3.1.3
ENV HIVE_HOME=/opt/hive
ENV PATH=$PATH:$HIVE_HOME/bin
ENV HADOOP_HOME=/usr/local/hadoop
ENV JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# 安装必要的软件包
RUN apt-get update && \
apt-get install -y \
tar \
mysql-server \
mysql-client \
python3 \
python3-pip \
&& rm -rf /var/lib/apt/lists/*
# 复制本地已下载的 Hive 和 MySQL 驱动
COPY apache-hive-${HIVE_VERSION}-bin.tar.gz /tmp/
COPY mysql-connector-java-8.0.31.jar /tmp/
# 解压并安装 Hive
RUN tar -zxvf /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz -C /opt/ && \
mv /opt/apache-hive-${HIVE_VERSION}-bin ${HIVE_HOME} && \
rm /tmp/apache-hive-${HIVE_VERSION}-bin.tar.gz
# 安装 MySQL JDBC 驱动
RUN mkdir -p ${HIVE_HOME}/lib && \
cp /tmp/mysql-connector-java-8.0.31.jar ${HIVE_HOME}/lib/ && \
rm /tmp/mysql-connector-java-8.0.31.jar
# 解决 Guava 版本冲突:先删除 Hive 的旧版本,再复制 Hadoop 的新版本
RUN rm -f ${HIVE_HOME}/lib/guava-*.jar && \
cp /usr/local/hadoop/share/hadoop/common/lib/guava-*.jar ${HIVE_HOME}/lib/
# 创建必要的目录
RUN mkdir -p ${HIVE_HOME}/logs \
&& mkdir -p ${HIVE_HOME}/tmp \
&& mkdir -p /var/lib/mysql-files \
&& chown -R root:root ${HIVE_HOME}
# 配置 MySQL 作为 Hive Metastore
RUN service mysql start && \
mysql -e "CREATE DATABASE metastore;" && \
mysql -e "CREATE USER 'hive'@'%' IDENTIFIED WITH mysql_native_password BY 'hive';" && \
mysql -e "GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'%';" && \
mysql -e "FLUSH PRIVILEGES;" && \
service mysql stop
# 复制配置文件
COPY hive-site.xml ${HIVE_HOME}/conf/
COPY hive-env.sh ${HIVE_HOME}/conf/
COPY hive-log4j2.properties ${HIVE_HOME}/conf/
COPY beeline-log4j2.properties ${HIVE_HOME}/conf/
# 添加主机名映射以解决 UnknownHostException
RUN echo "127.0.0.1 hadoop-pseudo" >> /etc/hosts
# 设置权限
RUN chmod +x ${HIVE_HOME}/bin/*
# 暴露端口
EXPOSE 10000 10002 9999 9998 9083
# 创建启动脚本,只启动 SSH、MySQL 和 Hadoop/Hive 服务
RUN echo '#!/bin/bash\n\
\n\
# 启动 SSH 服务\n\
echo "Starting SSH service..."\n\
service ssh start\n\
\n\
# 启动 MySQL 服务\n\
echo "Starting MySQL service..."\n\
service mysql start\n\
\n\
# 等待 MySQL 启动\n\
sleep 5\n\
\n\
# 检查 MySQL 是否正常启动\n\
if ! service mysql status > /dev/null 2>&1; then\n\
echo "MySQL failed to start, initializing..." \n\
mysql_install_db --user=mysql --ldata=/var/lib/mysql\n\
service mysql restart\n\
sleep 5\n\
fi\n\
\n\
# 检查 Hive Metastore Schema 是否已存在,如果不存在则初始化\n\
echo "Checking Hive Metastore Schema..."\n\
export HADOOP_HOME=/usr/local/hadoop\n\
export HIVE_HOME=/opt/hive\n\
\n\
# 尝试连接并检查表是否存在\n\
if mysql -u hive -phive -e "USE metastore; SELECT 1 FROM VERSION LIMIT 1;" 2>/dev/null; then\n\
echo "Hive Metastore Schema already exists."\n\
else\n\
echo "Initializing Hive Metastore Schema..." \n\
${HIVE_HOME}/bin/schematool -dbType mysql -initSchema --verbose\n\
fi\n\
\n\
# 启动 Hadoop 服务(如果需要)\n\
if [ -d "${HADOOP_HOME}" ]; then\n\
echo "Starting Hadoop services..." \n\
cd ${HADOOP_HOME}\n\
sbin/start-dfs.sh\n\
sbin/start-yarn.sh\n\
fi\n\
\n\
# 启动 Hive Metastore 服务\n\
echo "Starting Hive Metastore..." \n\
${HIVE_HOME}/bin/hive --service metastore &\n\
\n\
# 等待几秒让 Metastore 启动\n\
sleep 10\n\
\n\
# 启动 HiveServer2 服务\n\
echo "Starting HiveServer2..." \n\
${HIVE_HOME}/bin/hiveserver2 &\n\
\n\
# 保持容器运行\n\
echo "All services started. Container running..." \n\
tail -f /dev/null' > /start-hive.sh
RUN chmod +x /start-hive.sh
CMD ["/start-hive.sh"]
EOF
bash
# 停止并删除当前的容器
docker stop hadoop-pseudo-hive || true
docker rm hadoop-pseudo-hive || true
# 删除当前的镜像
docker rmi hadoop-pseudo-hive:3.3.0 || true
# 重新构建镜像
cd ~/hive-docker
docker build -t hadoop-pseudo-hive:3.3.0 .
9.运行并验证容器
运行容器
bash
docker run -d \
--name hadoop-pseudo-hive \
--hostname hadoop-pseudo \
--network custom-network \
--ip 172.20.240.12 \
-p 9870:9870 \
-p 8088:8088 \
-p 8042:8042 \
-p 9000:9000 \
-p 10000:10000 \
-p 10002:10002 \
-p 9083:9083 \
-v ~/hadoop-conf:/usr/local/hadoop/etc/hadoop \
-v ~/hive-conf:/opt/hive/conf \
-v hive-metastore:/var/lib/mysql \
-v pseudo-hadoop-namenode:/hadoop-data/namenode \
-v pseudo-hadoop-datanode:/hadoop-data/datanode \
-v pseudo-hadoop-tmp:/hadoop-data/tmp \
--privileged \
hadoop-pseudo-hive:3.3.0验证容器
bash
# 等待容器启动
sleep 90
# 查看容器日志
docker logs -f hadoop-pseudo-hive
# 进入容器验证
docker exec -it hadoop-pseudo-hive bash
# 检查安装
ls -la /opt/hive/lib/mysql-connector-java-8.0.31.jar
hive --version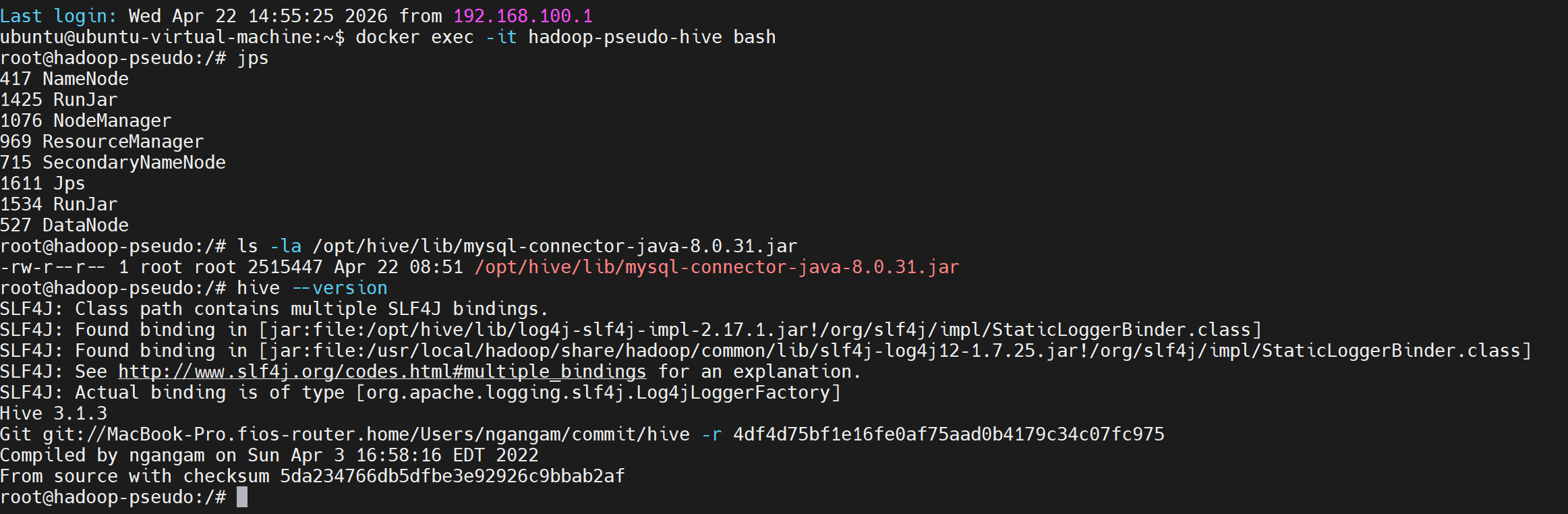
10. 测试连接
链接hive shell并进行操作
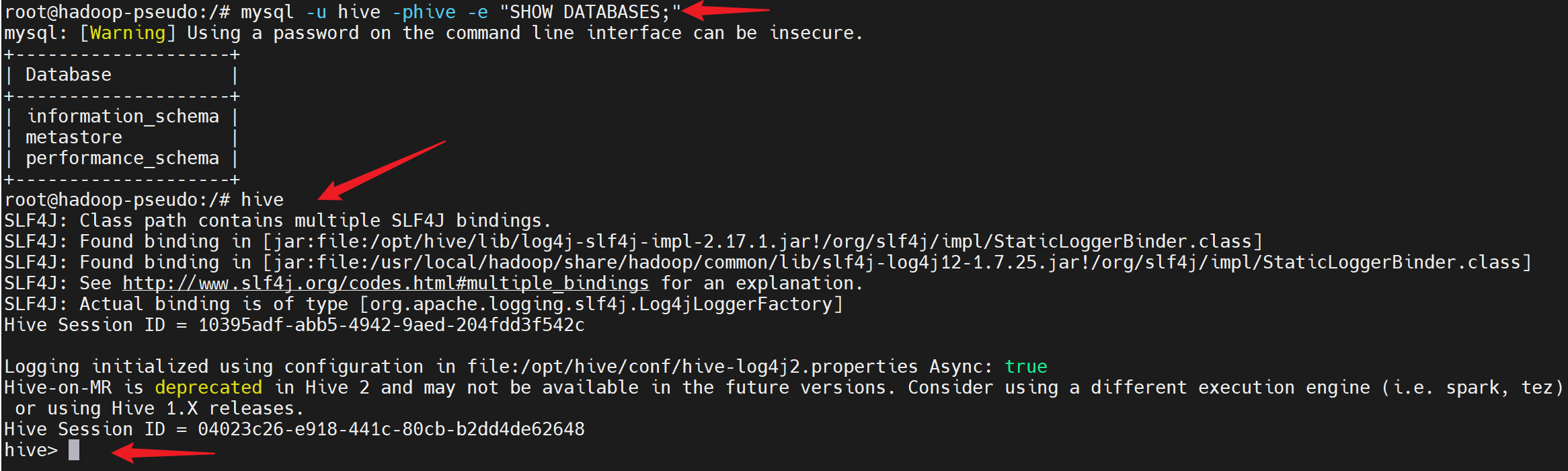
好的!既然 Hive CLI 可以正常使用,让我们测试一些基本的 Hive 操作。以下是常用的 Hive Shell 测试语句:
sql
-- 显示当前数据库
SHOW DATABASES;
-- 使用默认数据库
USE default;
-- 显示当前数据库中的表
SHOW TABLES;
-- 创建一个简单的测试表
CREATE TABLE IF NOT EXISTS test_table (
id INT,
name STRING,
age INT,
salary DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 查看表结构
DESCRIBE test_table;
-- 插入一些测试数据
INSERT INTO TABLE test_table VALUES
(1, 'Alice', 25, 50000.0),
(2, 'Bob', 30, 60000.0),
(3, 'Charlie', 35, 70000.0);
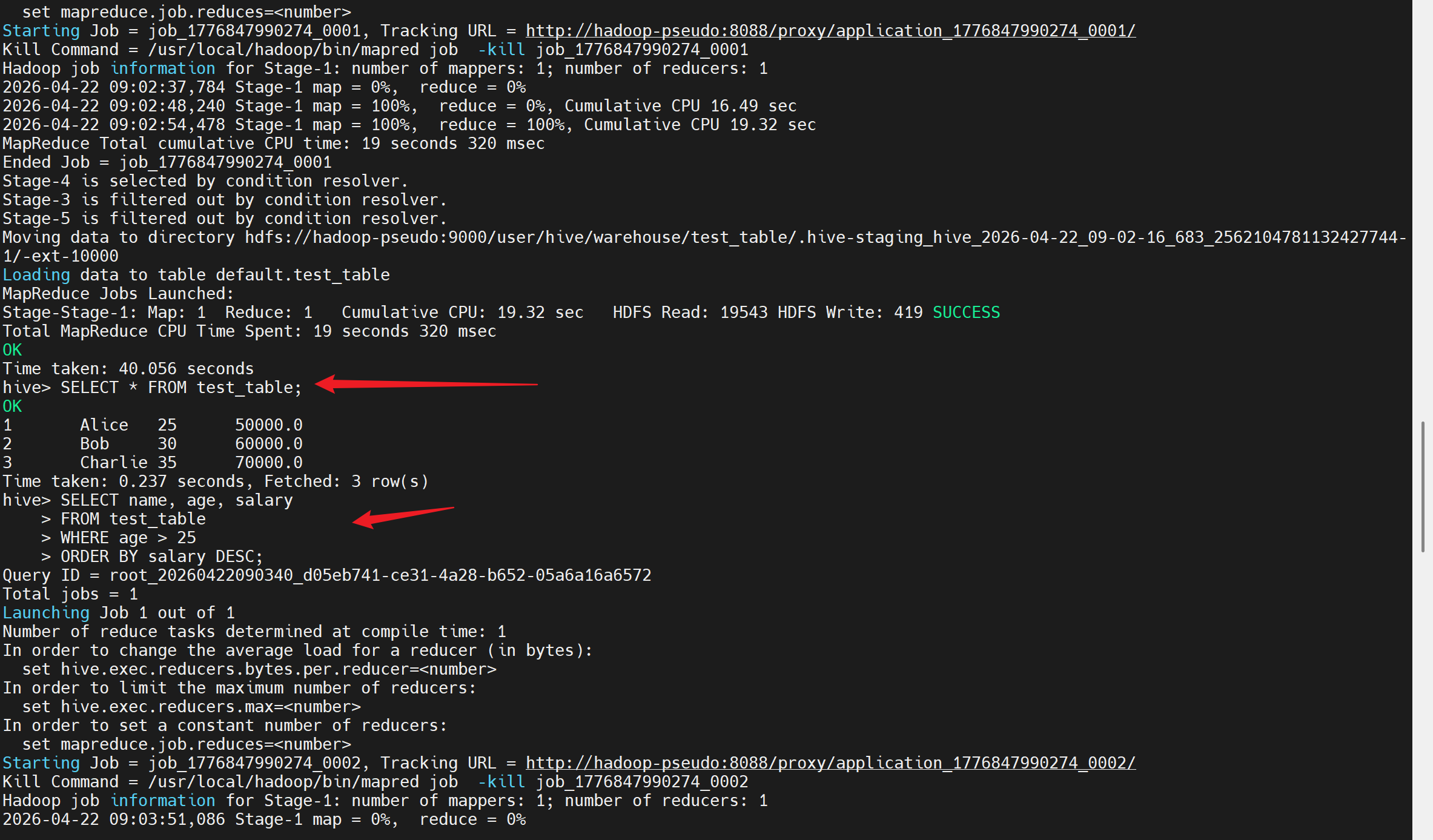
-- 查询数据
SELECT * FROM test_table;
-- 更复杂的查询示例
SELECT name, age, salary
FROM test_table
WHERE age > 25
ORDER BY salary DESC;
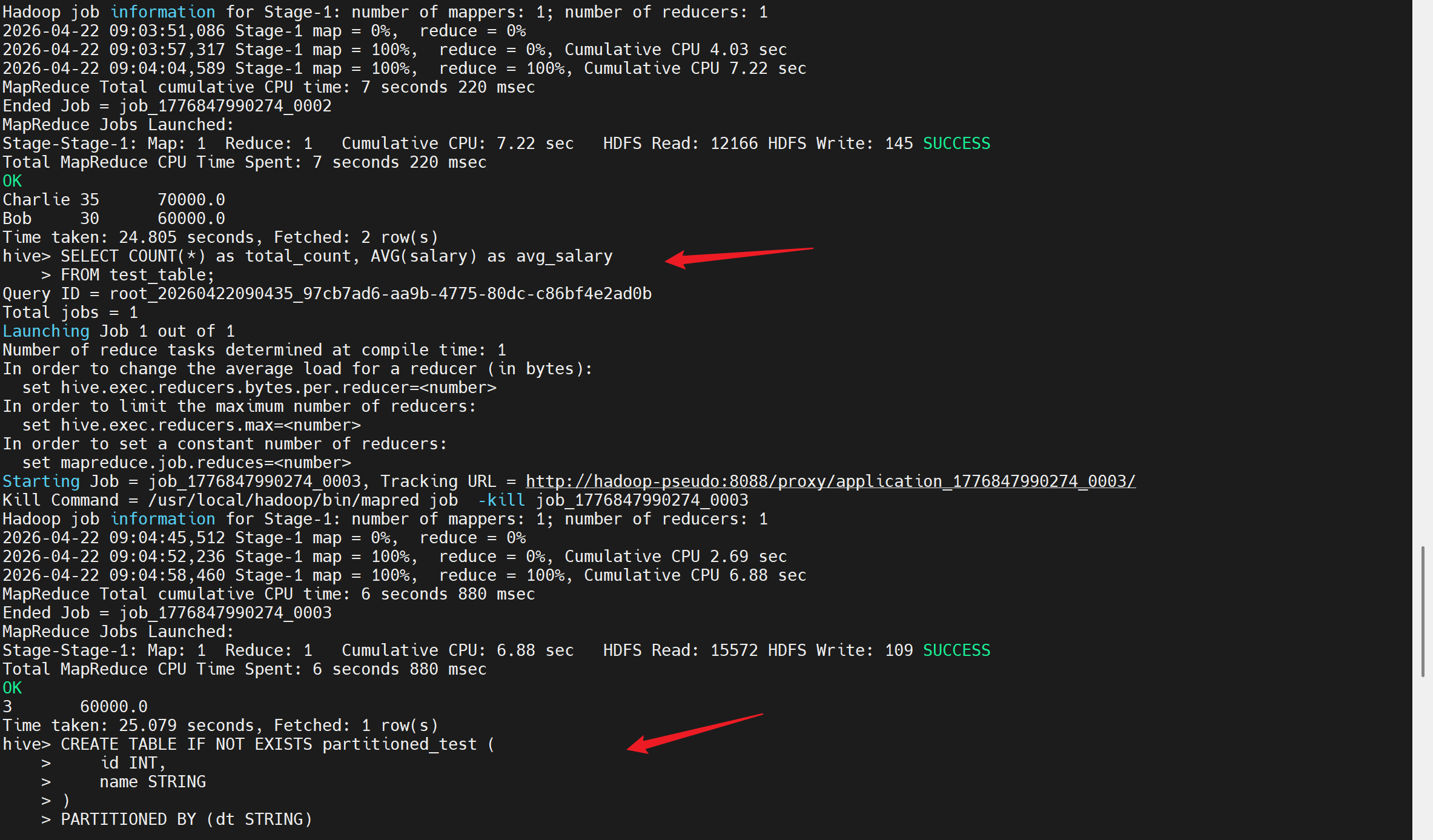
-- 统计信息
SELECT COUNT(*) as total_count, AVG(salary) as avg_salary
FROM test_table;
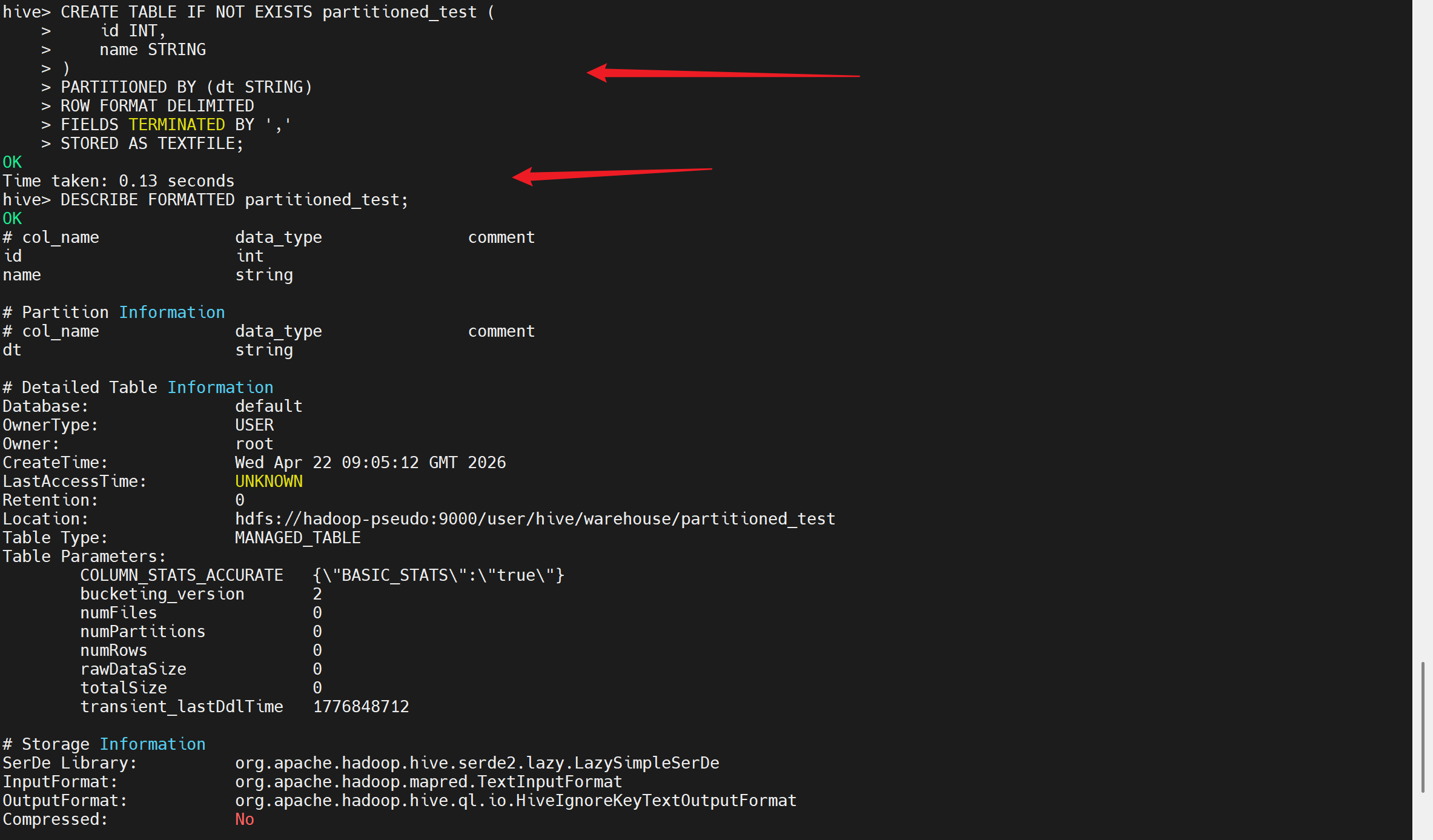
-- 创建分区表(高级功能测试)
CREATE TABLE IF NOT EXISTS partitioned_test (
id INT,
name STRING
)
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
-- 查看分区表结构
DESCRIBE FORMATTED partitioned_test;
-- 退出 Hive
EXIT;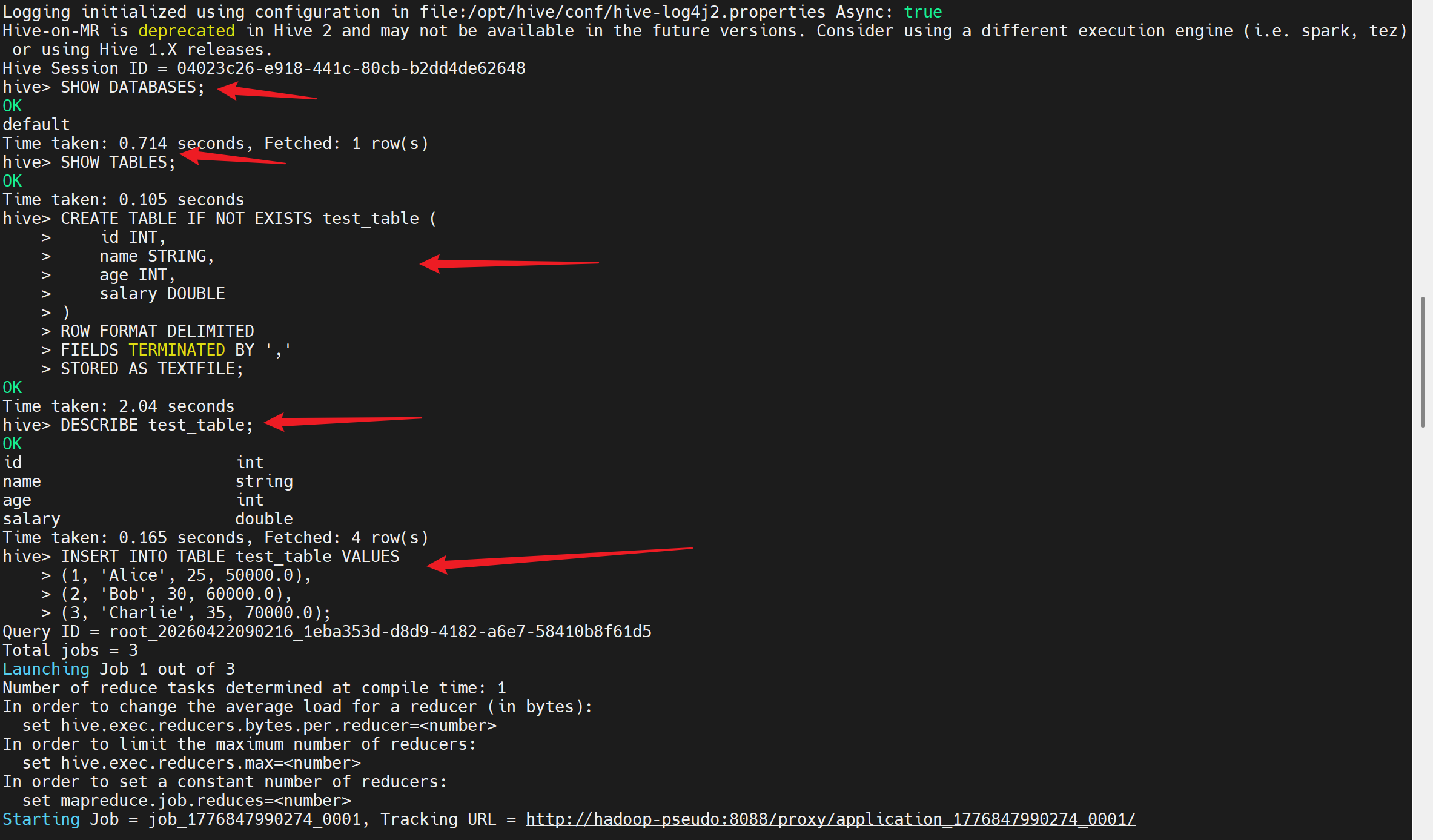
查看hdfs中对应的数据
当然!以下是与 Hive 操作相对应的 HDFS 文件查看命令:
bash
# 1. 查看 HDFS 根目录
hdfs dfs -ls /
# 2. 查看 Hive 数据存储目录(通常在 HDFS 上)
hdfs dfs -ls /user/hive/
hdfs dfs -ls /user/hive/warehouse/
# 3. 查看特定表的数据文件(假设表名为 test_table)
hdfs dfs -ls /user/hive/warehouse/test_table
# 4. 查看表中的实际数据文件内容
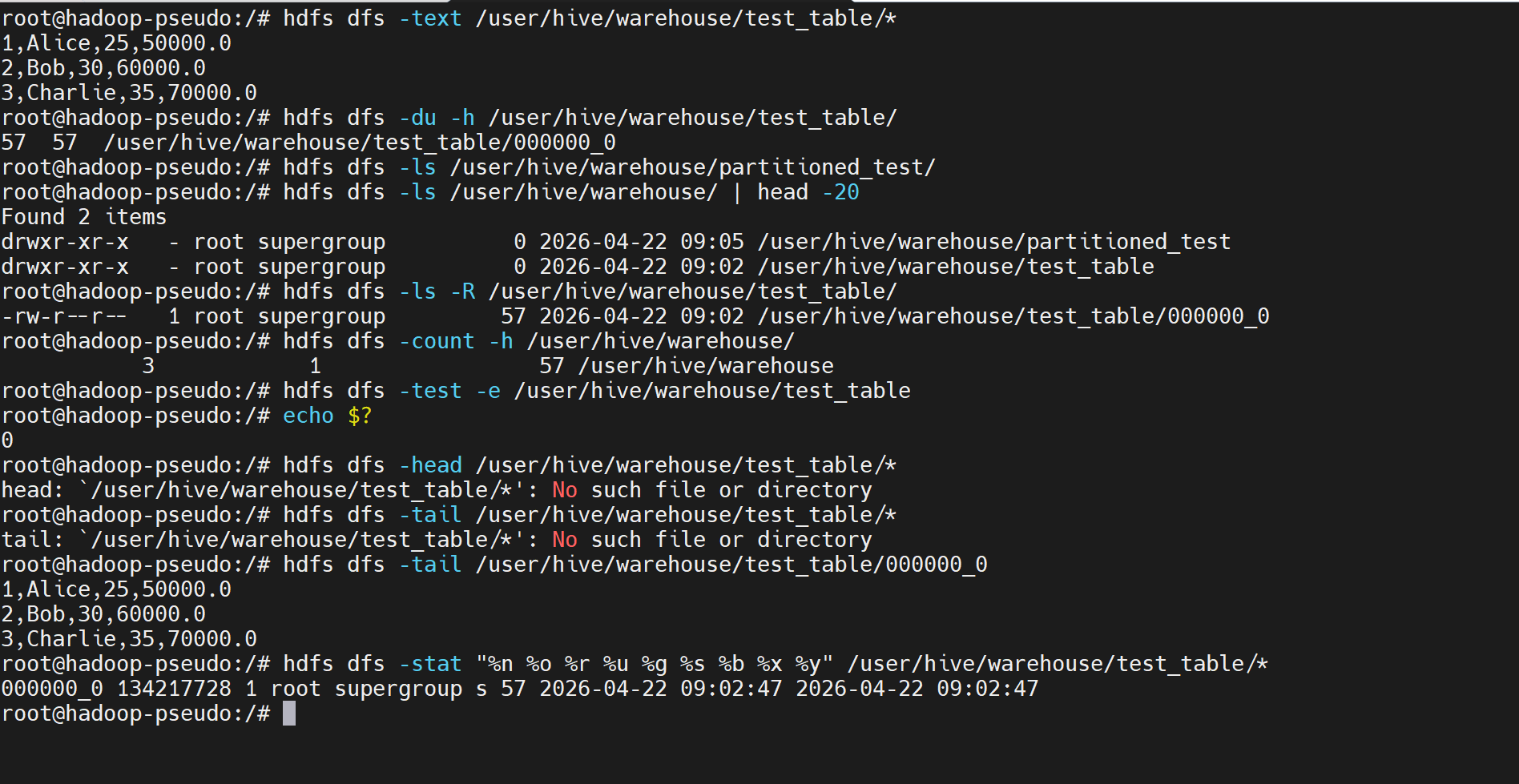
hdfs dfs -cat /user/hive/warehouse/test_table/*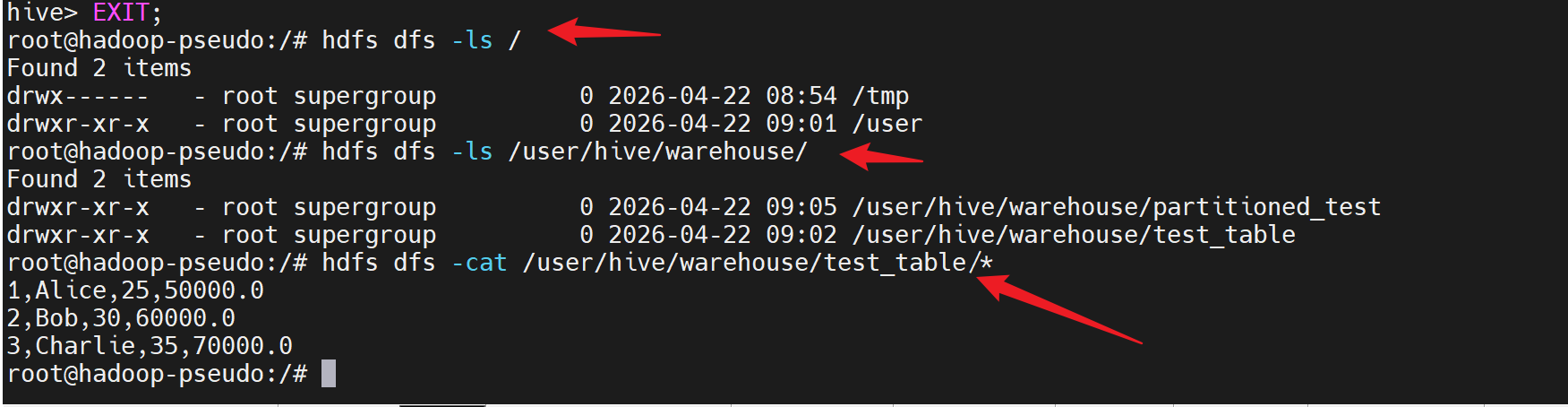
bash
# 或者使用 -text 查看文本格式的内容
hdfs dfs -text /user/hive/warehouse/test_table/*
# 5. 查看文件大小和详细信息
hdfs dfs -du -h /user/hive/warehouse/test_table/
# 6. 查看分区表的目录结构(如果创建了分区表)
hdfs dfs -ls /user/hive/warehouse/partitioned_test/
# 7. 查看所有 Hive 相关的目录
hdfs dfs -ls /user/hive/warehouse/ | head -20
# 8. 查看文件的详细信息(包括副本数、权限等)
hdfs dfs -ls -R /user/hive/warehouse/test_table/
# 9. 统计目录下的文件数量和大小
hdfs dfs -count -h /user/hive/warehouse/
# 10. 检查文件是否存在
hdfs dfs -test -e /user/hive/warehouse/test_table
echo $? # 如果输出0表示文件存在,1表示不存在
# 11. 查看文件的前几行(类似 head 命令)
hdfs dfs -head /user/hive/warehouse/test_table/*
# 12. 查看文件的最后几行(类似 tail 命令)
hdfs dfs -tail /user/hive/warehouse/test_table/*
# 13. 获取文件的详细统计信息
hdfs dfs -stat "%n %o %r %u %g %s %b %x %y" /user/hive/warehouse/test_table/*当你在 Hive 中执行:
sql
INSERT INTO TABLE test_table VALUES (1, 'Alice', 25, 50000.0);这个操作会在 HDFS 上创建相应的数据文件,你可以使用上述 HDFS 命令来查看这些文件。
特别注意:
- Hive 表的数据默认存储在 HDFS 的
/user/hive/warehouse/目录下 - 每个表对应一个子目录
- 分区表会有额外的子目录表示不同的分区
- 文件通常是文本格式,可以用 HDFS 命令直接查看
11.远程测试
另外,如果你想要测试 HiveServer2 的连接(通过 Beeline),可以尝试启动 HiveServer2:
bash
# 进入容器验证
docker exec -it hadoop-pseudo-hive bash
# 停止所有 HiveServer2 进程
pkill -f hiveserver2
# 清空日志
> /tmp/hiveserver2.log
# 启动 HiveServer2 并在后台运行
nohup /opt/hive/bin/hiveserver2 >> /tmp/hiveserver2.log 2>&1 &
# 实时查看日志直到看到启动完成信息
timeout 30 tail -f /tmp/hiveserver2.log
# 在另一个终端中启动 HiveServer2
nohup /opt/hive/bin/hiveserver2 > /tmp/hiveserver2.log 2>&1 &
# 检查进程
jps
# 查看日志
tail -f /tmp/hiveserver2.log
# 然后在另一个终端中用 Beeline 测试连接
beeline -u jdbc:hive2://localhost:10000这些测试语句可以帮助验证 Hive 的基本功能是否正常工作,包括 DDL(数据定义语言)、DML(数据操作语言)和查询功能。
bash
# 在容器内测试
beeline -u jdbc:hive2://localhost:10000
# 外部测试
beeline -u jdbc:hive2://172.20.240.12:10000