引言:算力碎片化下的"部署地狱"
在企业级 AI 视频项目落地的现实场景中,技术决策者(CTO/架构师)往往面临着严峻的算力碎片化 挑战。一方面,云端数据中心普遍采用 X86 架构配合高性能 GPU(如 NVIDIA)进行大规模并发推理;另一方面,工业现场的边缘侧则充斥着各式各样的 ARM 架构 NPU 边缘计算盒子(如瑞芯微、昇腾等)。传统的单一架构软件无法同时满足这两种环境的需求,导致企业被迫维护两套代码分支,开发和运维成本激增。
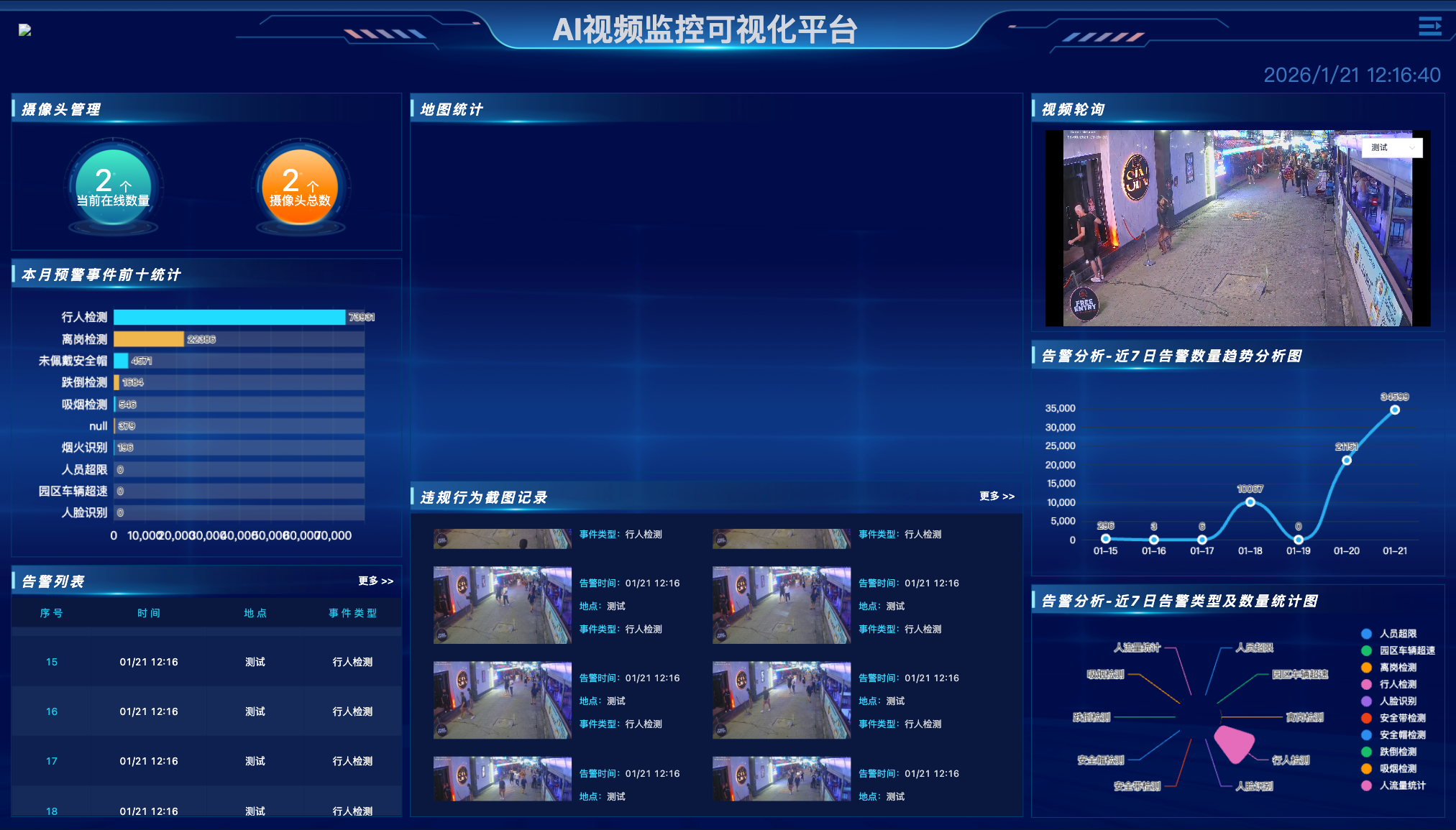
YiheCode Server 给出的解法是**"软硬解耦 + 源码交付"。这不仅是一个基于 Spring Boot 2.7 + Vue 2.6 开发的视频管理平台,更是一个支持全硬件适配**的异构计算底座。本文将深入解析其如何利用容器化与微服务架构,打通 X86 与 ARM 的壁垒,实现一套代码在不同算力芯片上的无缝迁移,从而帮助企业削减约 95% 的底层适配开发成本。
一、 核心架构:边缘-中心协同的异构计算体系
YiheCode Server 的架构设计核心在于将业务逻辑 与算力资源进行了物理隔离。系统分为中心管理平台(Server)和边缘计算节点(Edge),通过这种分层设计,实现了对异构硬件的统一调度。
1.1 边缘节点的"插件化"管理
根据 Gitee 仓库文档中的系统架构图,平台通过边缘推流 和Socket 通信,将繁重的视频解码与 AI 推理任务下沉到边缘侧。边缘节点(ZLMediaKit 或 算法盒子)负责具体的取流和计算,而中心服务器仅负责策略下发和结果汇聚。
这种设计使得边缘节点可以根据现场硬件灵活配置:
- 高性能场景:部署基于 X86 + GPU 的推理服务器集群,处理高码率、高并发的视频流。
- 低功耗场景:部署基于 ARM + NPU 的边缘盒子,直接在端侧完成算法检测,减少带宽占用。
1.2 跨平台部署矩阵
平台通过源码交付,允许开发者直接针对目标硬件编译二进制文件,完美解决了闭源软件无法跨指令集运行的痛点。
| 硬件环境 | 指令集架构 | 适用组件 | 典型应用场景 |
|---|---|---|---|
| 云端/服务器 | X86_64 | ZLMediaKit 节点、MinIO 存储、MySQL | 大型园区级联、海量视频流汇聚存储 |
| 边缘端 | ARM64/32 | 算法推理程序、轻量级 ZLM | 工厂车间、变电站、移动布控球 |
| 异构加速 | 通用 | 支持定制化 GPU/NPU 驱动接入 | 特定行业的深度学习模型加速 |
二、 源码级技术实现:Docker 容器化与资源调度
YiheCode Server 基于 Java 技术栈,具备天然的跨平台特性。结合 Docker 容器化部署,进一步屏蔽了底层操作系统的差异。

2.1 容器化部署策略
根据仓库文档要求,私有化部署需安装 Docker 和 Docker-compose。平台利用容器技术实现了环境的一致性:
- 中心服务:打包为标准 Docker 镜像,可在任何支持 Docker 的 Linux 发行版(CentOS, Ubuntu, Debian)上运行。
- 边缘服务:提供针对 ARM 架构的专用镜像,或直接提供源码供客户交叉编译,确保在资源受限的边缘设备上也能高效运行。
2.2 智能负载均衡算法
为了防止某一台边缘服务器过载,平台实现了一套基于最小连接数的负载均衡策略。以下是基于文档逻辑的伪代码解析:
python
# 伪代码:边缘节点负载均衡调度器
class NodeScheduler:
def schedule_camera(self, camera_info):
# 1. 获取所有在线 ZLM 节点状态
active_nodes = self.zlm_registry.get_active_nodes()
# 2. 筛选出支持该协议(RTSP/GB28181)且负载最低的节点
target_node = min(
(node for node in active_nodes if node.support_protocol(camera_info.protocol)),
key=lambda x: x.current_connections
)
# 3. 将摄像头分配给该节点,并建立拉流任务
assignment = target_node.assign_stream(camera_info.stream_url)
# 4. 若为国标流(GB28181),利用国标服务自动穿透;若为手动拉流,则主动拉流
if camera_info.protocol == "GB28181":
self.sip_server.start_invite(target_node, camera_info)
else:
target_node.start_pull_stream()
return assignment这种架构确保了在混合部署(X86 服务器与 ARM 盒子混用)的场景下,系统能自动将任务分配给最合适的算力单元。
三、 私有化与定制化:掌握算力的主动权
对于寻求私有化部署的企业而言,源码交付不仅仅是拥有代码,更是拥有了对算力资源的绝对控制权。
3.1 自定义算力适配
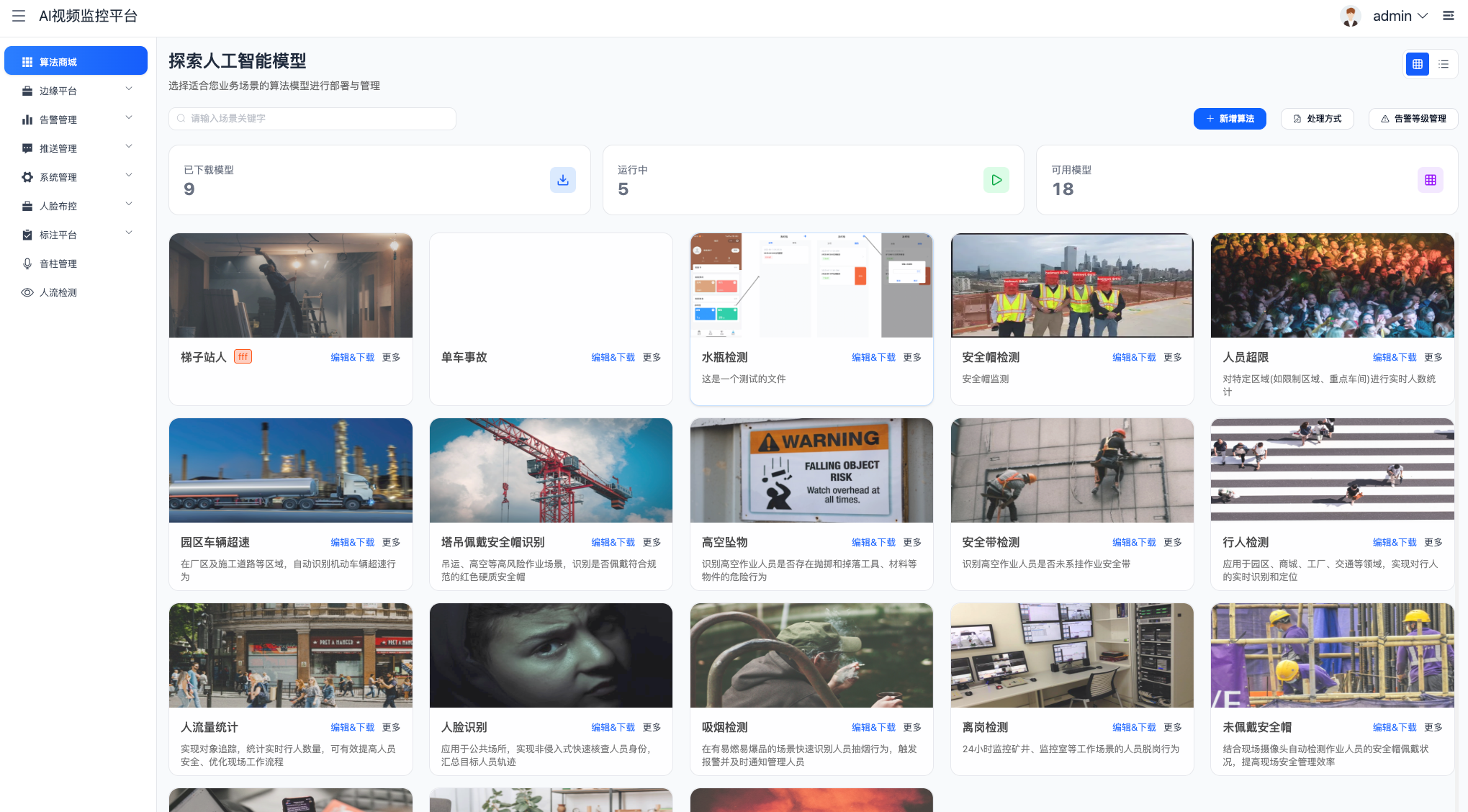
文档中提到平台支持"客户定制化 GPU 品牌"。由于提供了算法推理层的源码,开发者可以:
- 修改底层推理引擎(如替换为 TensorRT、ONNX Runtime 或特定 NPU 的 SDK)。
- 针对特定芯片(如华为昇腾、寒武纪)进行算子优化,提升推理 FPS。
- 移除不必要的功能模块,裁剪出仅占用 50MB 内存的极简边缘版。
3.2 录像与存储的资源优化
基于异构架构,平台对存储策略进行了精细化设计,以适应不同硬件的 I/O 性能:
json
// 录像控制策略配置 (Record Interface Logic)
{
"record_mode": "intelligent", // 智能模式:仅在告警时或手动开启时录制
"check_interval": "5m", // 定时器每5分钟检查一次状态
"storage_policy": {
"edge_cache": "local_nvr", // 边缘侧:先存本地(ARM盒子SD卡或硬盘)
"cloud_sync": "minio" // 中心侧:告警片段自动上传至 MinIO 对象存储
},
"cleanup_rule": "cron 0 0 * * *", // 每日清理非告警原图,节省磁盘空间
"hardware_adaptation": {
"x86_gpu": "enable_h265_full_fps", // X86开启 H.265 全帧率解码
"arm_npu": "enable_h264_low_latency" // ARM开启 H.264 低延迟模式
}
}四、 总结
YiheCode Server 通过源码级开放 和微服务架构 ,成功构建了一个硬件无关的 AI 视频中台。
对于技术决策者而言,这套系统最大的价值在于:它将"适配 10 种不同芯片"的复杂性封装在了边缘节点层,向上层业务提供了统一的 HTTP/WebSocket 接口。无论是基于 X86 的云端大脑,还是基于 ARM 的边缘触角,都能通过这套系统实现统一管理。这种架构,正是实现"减少 95% 开发成本"并应对复杂算力环境的关键基础设施。
架构师建议 :
在混合部署时,建议将中心管理服务(Spring Boot)部署在 X86 服务器上以保证数据库性能,而将 ZLMediaKit 和 AI 推理服务根据物理位置分散部署在 ARM 边缘盒子上,以降低网络延迟。