详细描述一条 SQL 语句在 MySQL 中的执行过程




MySQL的索引类型有哪些?





MySQL 的 Change Buffer 是什么?它有什么作用?

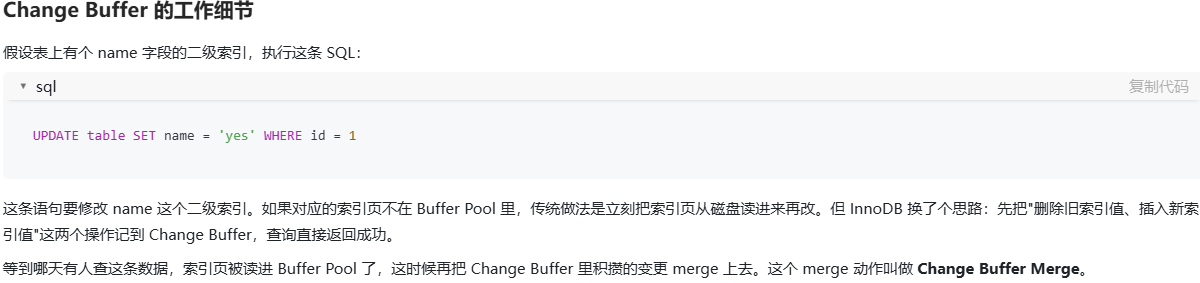




什么是数据全量同步和增量同步?它们各有什么优缺点?


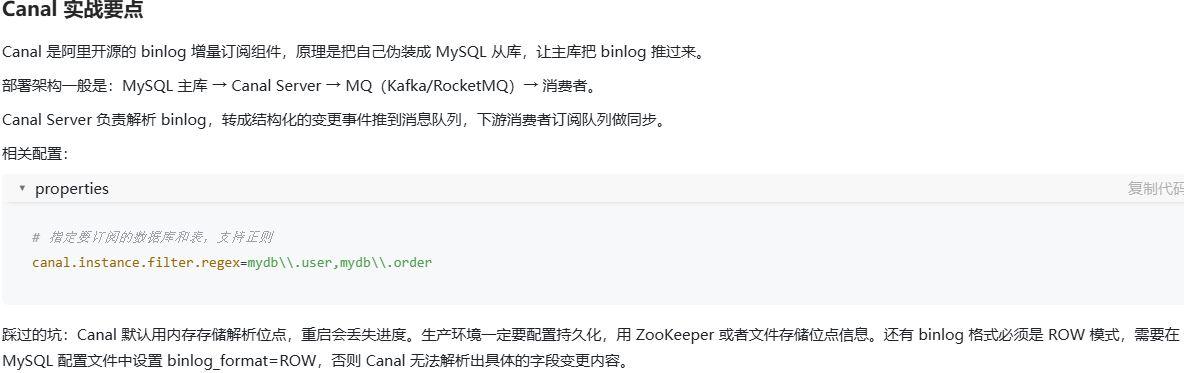



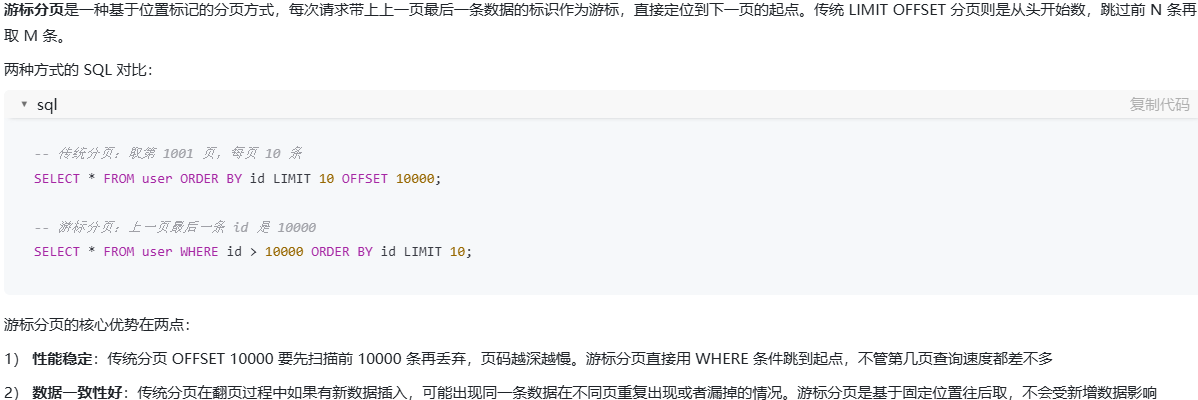
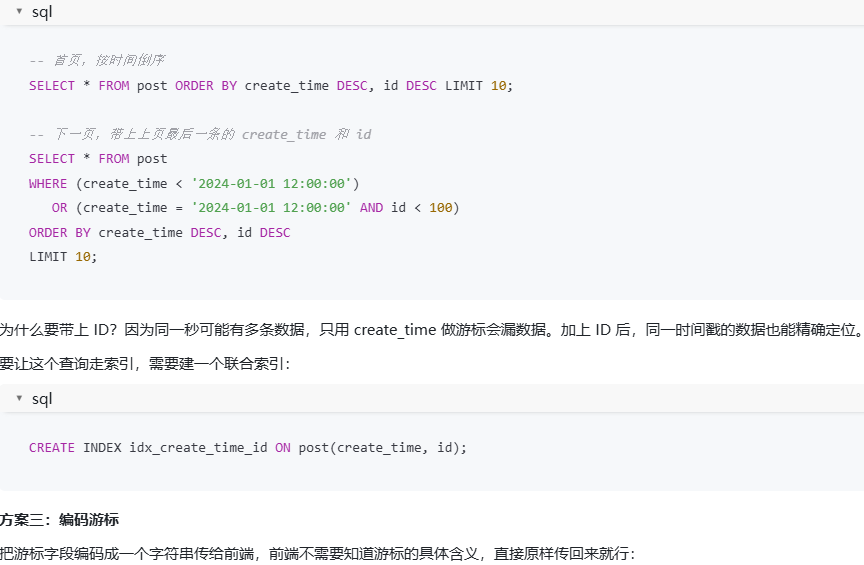
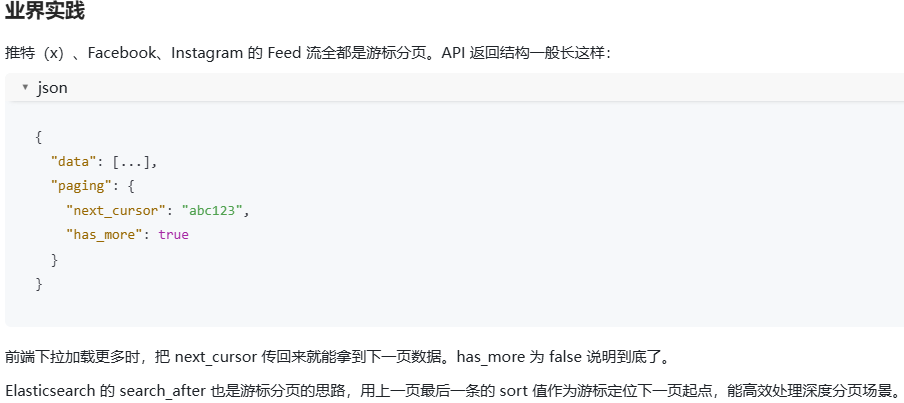
什么是游标 Cursor 分页?相比传统 LIMIT OFFSET 分页有什么优势?




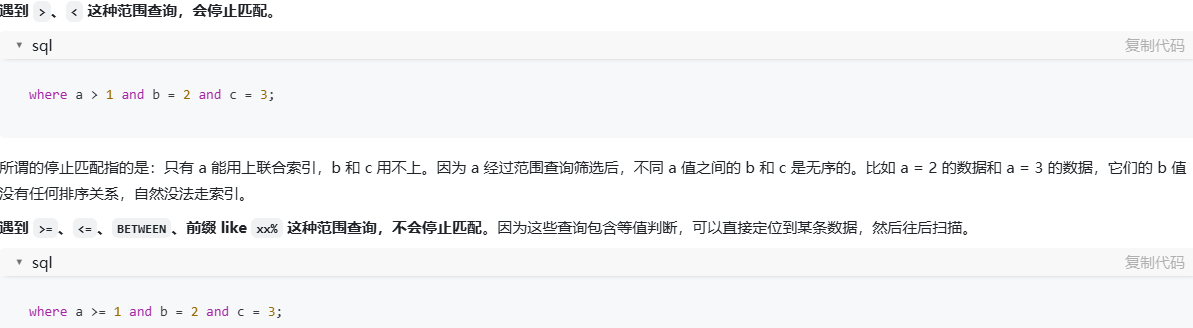
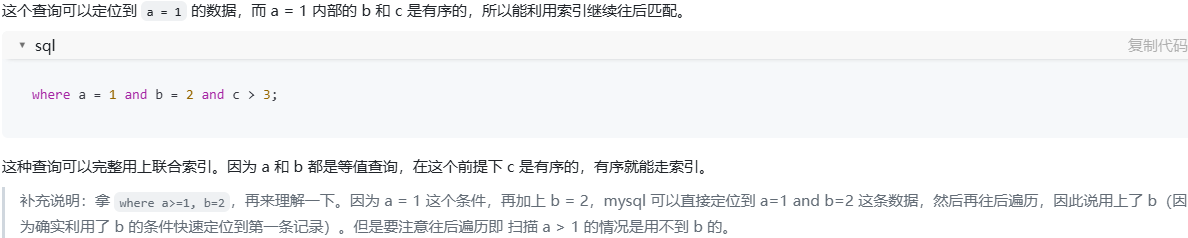
MySQL 索引的最左前缀匹配原则是什么?




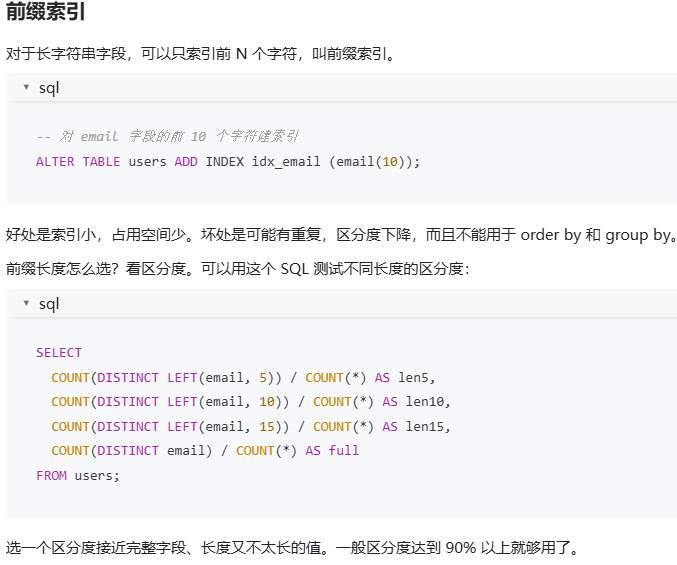
在 MySQL 中建索引时需要注意哪些事项?


-- 查询1:按用户查订单
WHERE user_id = 123
-- 查询2:按用户和状态查订单
WHERE user_id = 123 AND status = 'PAID'
-- 查询3:按用户和时间范围查订单
WHERE user_id = 123 AND create_time > '2026-01-01'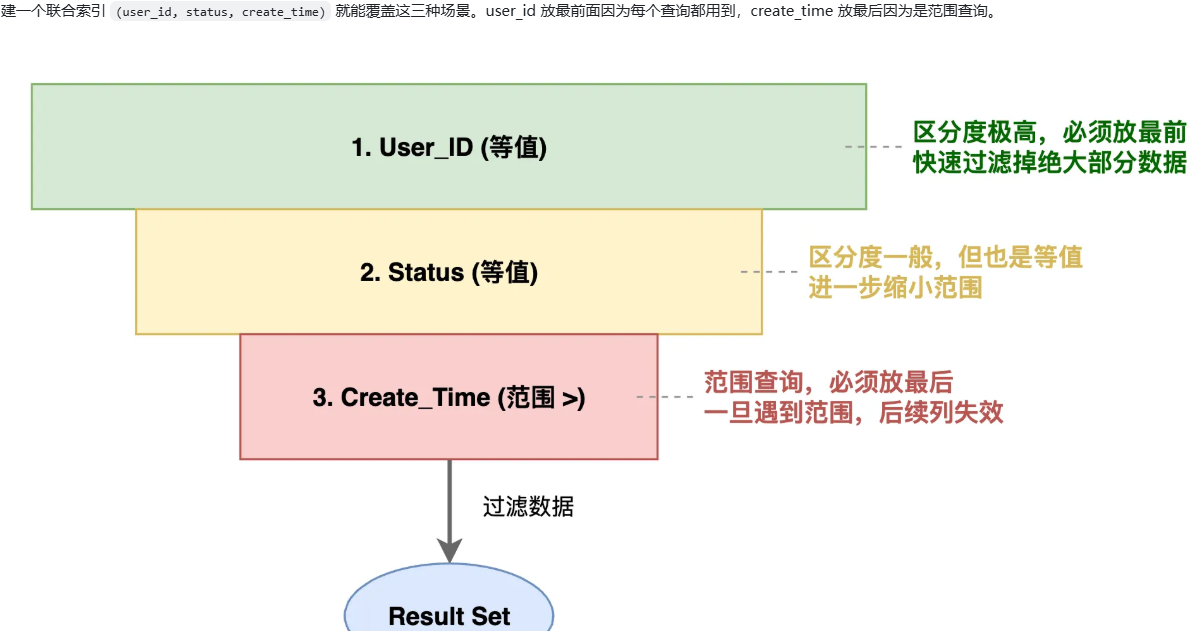


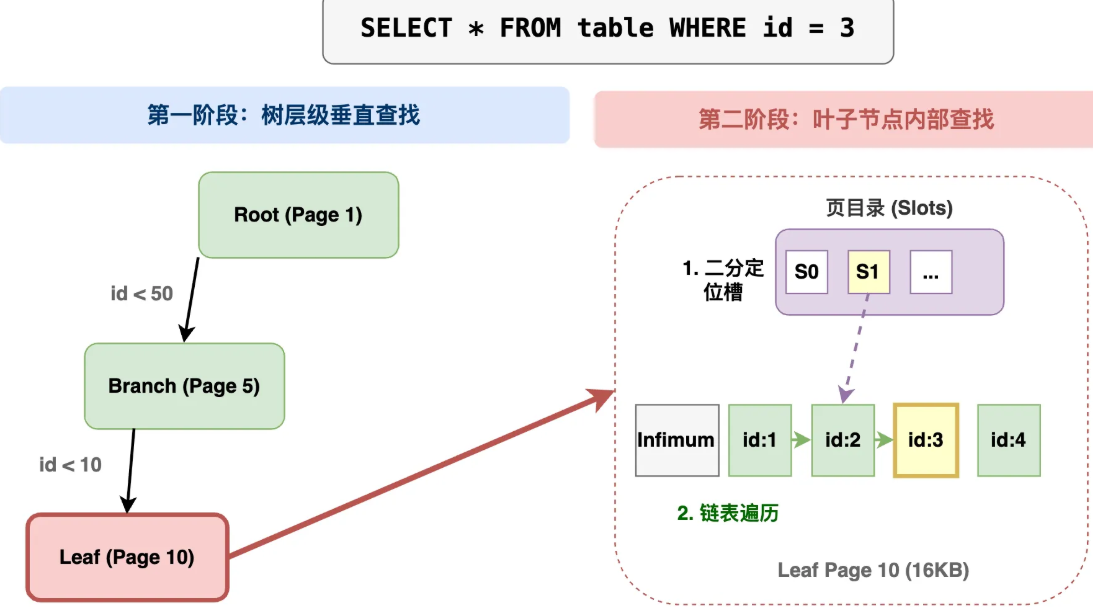
MySQL 的 B+ 树中查询数据的全过程


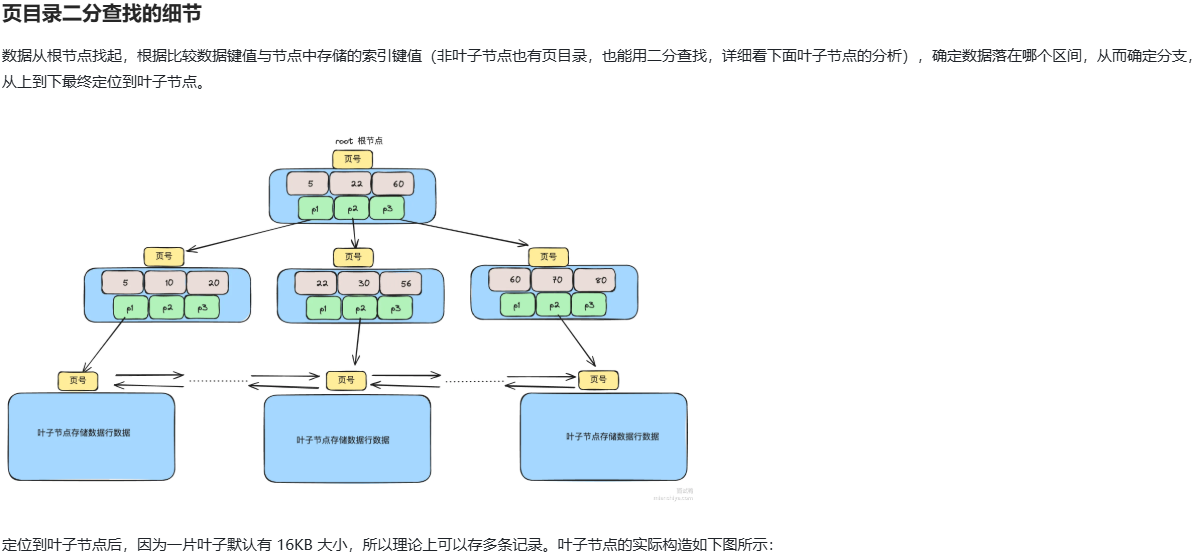
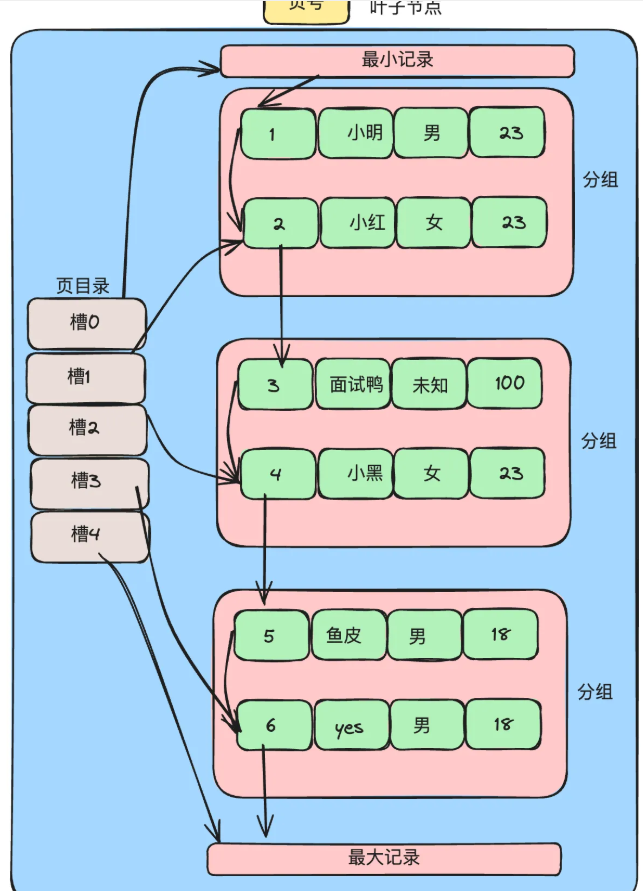



为什么 MySQL 选择使用 B+ 树作为索引结构?






MySQL 为什么不使用跳表作为索引的数据结构?
磁盘 I/O 效率
B + 树:B + 树的高度较低,通常只有 3 - 4 层,就能存储海量数据。它的节点大小设计适配磁盘页大小,一次磁盘 I/O 操作就能读取一个节点的数据,这使得查询时尽量减少磁盘 I/O 次数。比如,在千万级数据量下,通过几次磁盘 I/O 就能定位到目标数据。
跳表:跳表是基于链表实现的多层索引结构,虽然也能加速查找,但链表的随机访问特性差,在磁盘存储场景下,定位数据可能需要多次随机 I/O,这比 B + 树的顺序 I/O 效率低得多,因为磁盘顺序读写的速度远高于随机读写。
数据存储与范围查询
B + 树:B + 树的叶子节点形成有序链表,所有数据记录都保存在叶子节点上,这种结构天然适合做范围查询。执行诸如SELECT * FROM table WHERE column BETWEEN value1 AND value2这样的 SQL 语句时,只需沿着叶子节点链表顺序遍历就可以,效率很高。
跳表:跳表虽然也支持范围查询,但实现起来相对复杂。由于其多层链表的结构,在范围查询时遍历节点不如 B + 树叶子节点链表那样直接、高效,额外开销较大。
内存占用
B + 树:B + 树节点紧凑,内部节点只存储索引项,叶子节点才存储实际数据,相同数据量下,内存占用相对少。这对于数据库系统这种内存资源宝贵的场景很关键,能缓存更多的索引节点,减少磁盘 I/O。
跳表:跳表是链表结构,每个节点除了数据,还需要额外指针来构建多层索引,这使得内存占用量较大,同样的数据量,跳表耗费的内存可能远超 B + 树。
索引更新维护成本
B + 树:B + 树在插入、删除节点时,有成熟且高效的算法来平衡树结构,确保整体性能稳定。例如删除一个节点后,能通过旋转、合并临近节点等方式快速恢复树的平衡,更新操作的开销可控。
跳表:跳表的插入和删除操作涉及多层链表的调整,维护跳表的结构复杂度较高,尤其是频繁增删数据时,维持各层索引一致性的成本较大,容易出现性能波动。
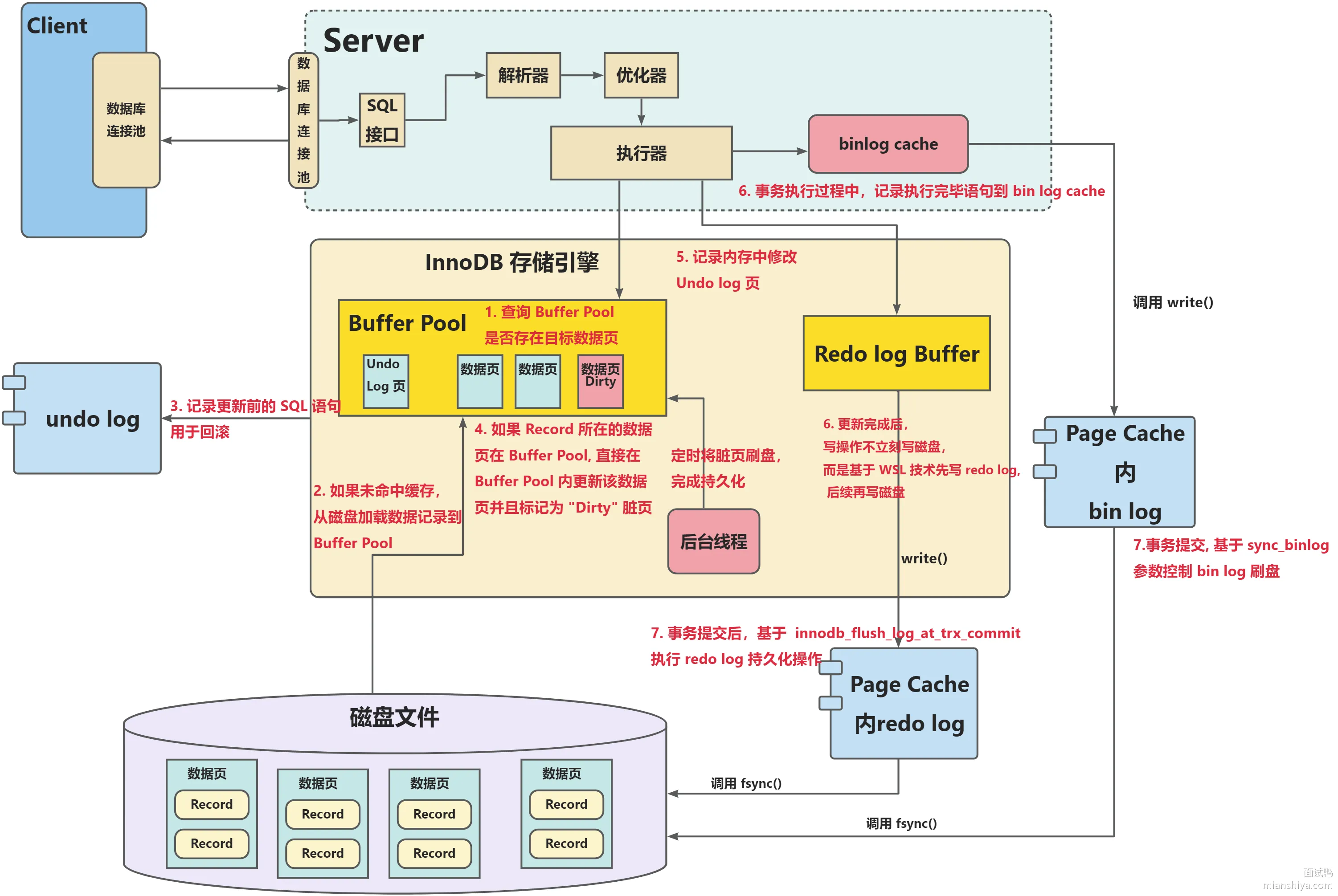
MySQL 中的日志类型有哪些?binlog、redo log 和 undo log 的作用和区别是什么?

| 日志 | binlog | redo log | undo log |
|---|---|---|---|
| 作用层级 | Server 层 | InnoDB 存储引擎层 | InnoDB 存储引擎层 |
| 作用 | 支持 备份恢复 和 主从复制,记录所有数据变更操作。 | 保证事务的 持久性(Crash-Safe),支持故障恢复。 | 支持事务的 原子性 和 多版本并发控制(MVCC)。 |
| 记录内容 | 记录 逻辑操作 (如 SQL 语句或行数据的变化) | 记录 物理修改 (数据页的具体更改) | 记录事务修改前的数据,用于 回滚 和 MVCC |
| 写入方式 | 追加写入:文件写满后创建新文件,不覆盖旧日志。 | 循环写入:固定大小,写满后从头开始覆盖。 | 随事务变化按需生成,形成 版本链。 |
| 主要用途 | 数据恢复到指定时间点;主从复制同步。 | 宕机后恢复已提交的事务,保证数据一致性。 | 支持事务回滚;基于 MVCC 实现快照读和隔离性。 |
三大日志的详细说明
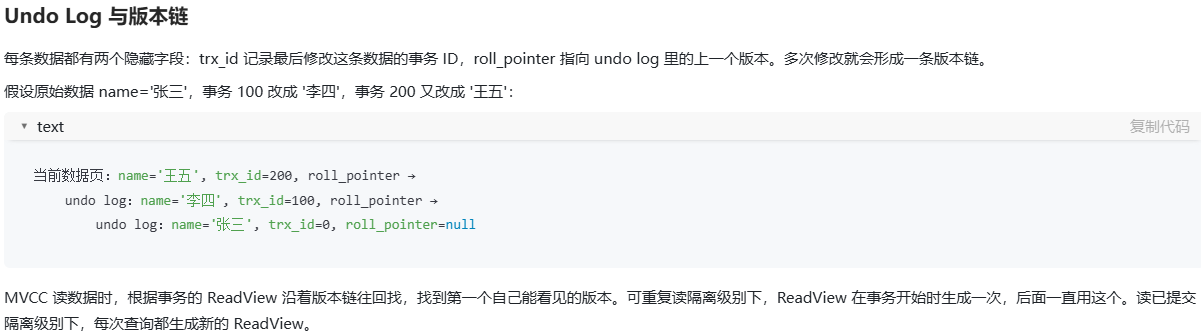
Undo Log(回滚日志)
- 作用 :
- 事务回滚:记录修改前的数据,用于回滚操作,保证事务的原子性。
- MVCC 支持:通过版本链实现多版本并发控制。
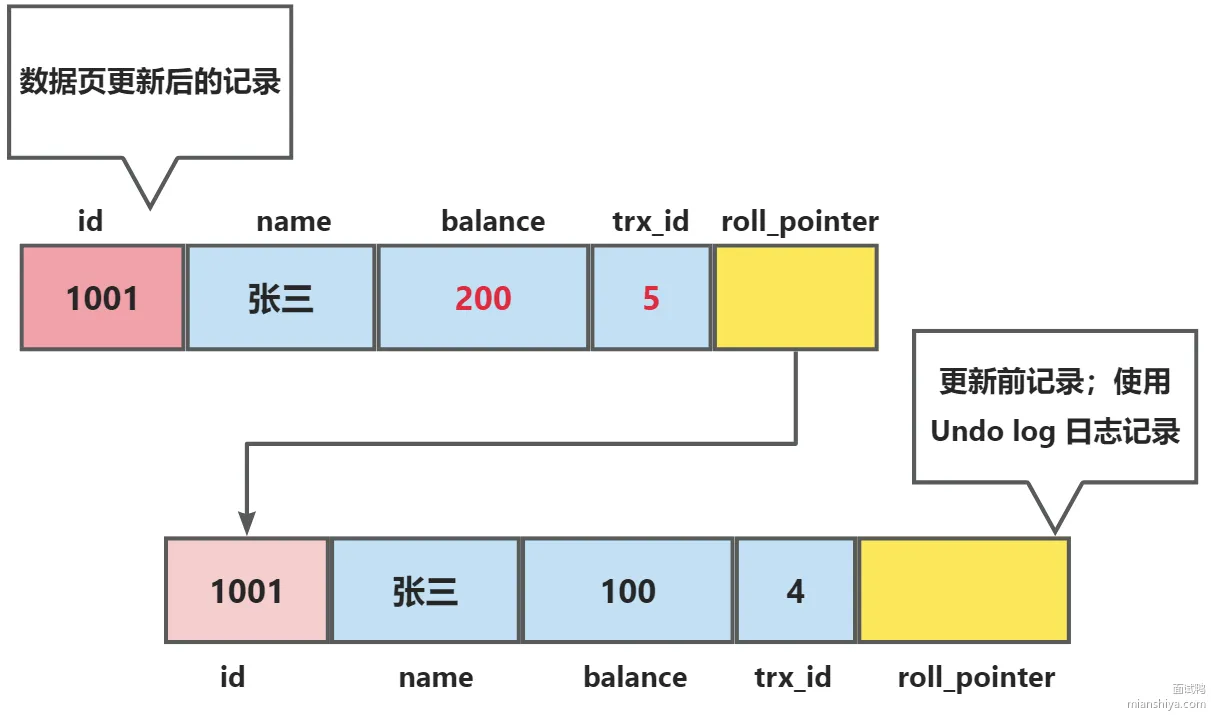
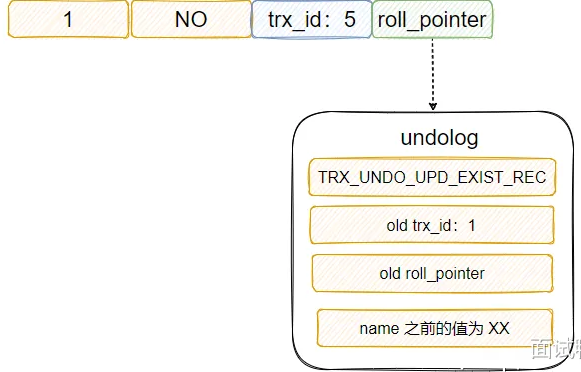
- 工作机制 :
- 每次修改数据前,记录旧值到 Undo Log。
- 形成版本链(通过
trx_id和roll_pointer),配合 Read View 实现 MVCC 快照读。
- MVCC 隔离级别 :
- 读已提交(Read Committed):每次查询生成新的 Read View,可能导致多次查询结果不一致。
- 可重复读(Repeatable Read):事务启动时生成 Read View,保证整个事务中查询结果一致。
工作流程示意
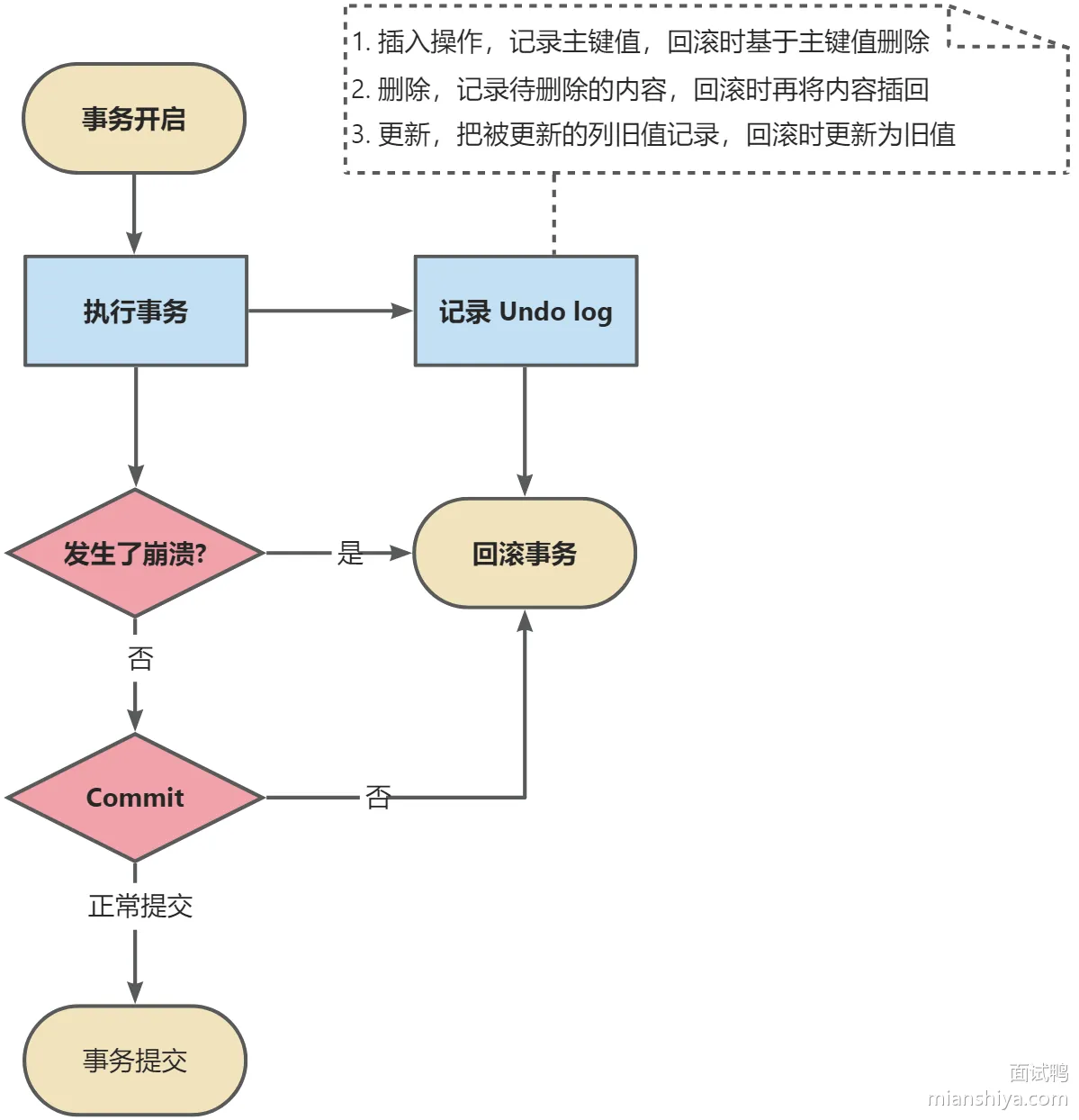
版本链示意
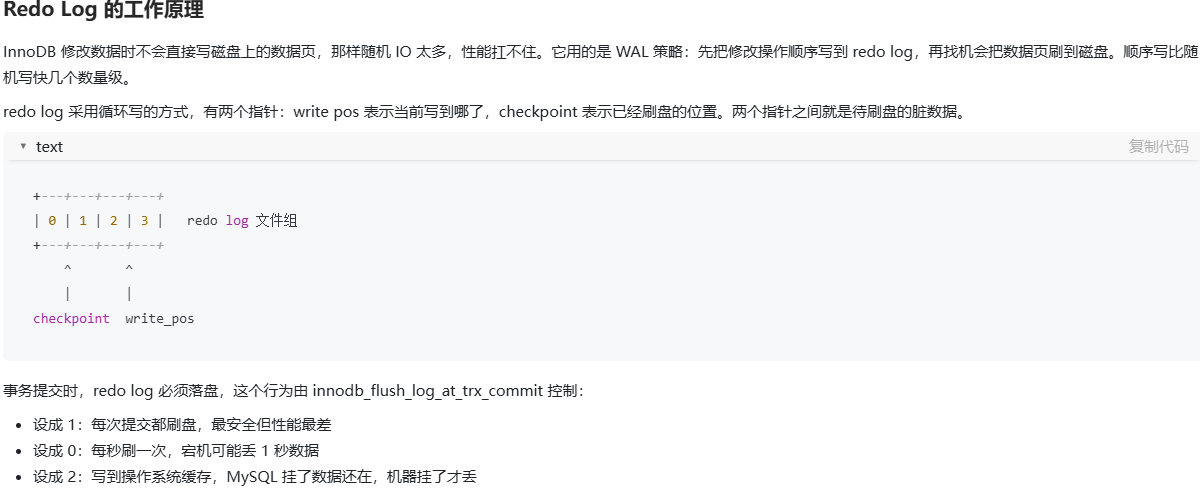
Redo Log(重做日志)
- 作用 :
- 保证事务的 持久性,即使宕机也能恢复提交的数据。
- 提升写性能:利用 WAL(Write-Ahead Logging) 技术,将随机写转化为顺序写。
- 工作机制 :
- 更新操作先写内存(Buffer Pool),同时记录 Redo Log,标记为脏页。
- 后台线程在合适时机将脏页刷入磁盘。
- 若发生宕机,可通过 Redo Log 恢复未刷盘的修改。
- 刷盘时机 :
- 事务提交时写入磁盘(由
innodb_flush_log_at_trx_commit参数控制)。 - 后台线程每秒刷盘一次。
- 事务提交时写入磁盘(由
innodb_flush_log_at_trx_commit 参数控制:
| 值 | 含义 | 适用场景 |
|---|---|---|
| 0 | Redo Log 保存在内存,每秒刷盘一次,可能丢失最近 1 秒数据。 | 性能优先的开发、测试环境。 |
| 1 | 事务提交时立刻刷盘,保证数据可靠性。 | 数据要求极高可靠性的核心生产环境。 |
| 2 | 提交时写入文件系统缓存,每秒刷盘一次,可能丢失操作系统崩溃前的数据。 | 性能与可靠性折中的业务场景。 |
安全性来说: 1 > 2 > 0 写入性能来说: 0 > 2 > 1
redo + undo log 工作示意图
Binlog(二进制日志)
- 作用 :
- 备份与恢复:支持通过 Binlog 恢复到指定时间点。
- 主从复制:主库把 Binlog 传输给从库,从库重放 Binlog 更新自身数据。
- 记录方式(三种格式) :
- STATEMENT:记录 SQL 语句(逻辑日志),但动态函数可能导致主从不一致。
- ROW:记录行数据的变化(物理日志),避免动态函数问题,但日志量大。
- MIXED:根据情况选择 STATEMENT 或 ROW 模式。
刷盘控制 :通过 sync_binlog 参数控制刷盘频率:
| 值 | 含义 | 适用场景 |
|---|---|---|
sync_binlog = 0 |
事务提交时只写入缓存,由操作系统决定刷盘。 | 性能优先的开发、测试环境。 |
sync_binlog = 1 |
每次事务提交都会立刻刷盘,保证数据可靠性。 | 数据要求极高可靠性的核心生产环境。 |
sync_binlog = N |
每提交 N 个事务后刷盘,性能和可靠性折中。 | 性能优先但需一定可靠性的业务场景。 |
三大日志工作简示图
其中
redo log的刷盘机制由于innodb_flush_log_at_trx_commit设置的值存在不同bin log的刷盘机制由于sync_binlog设置的值存在不同
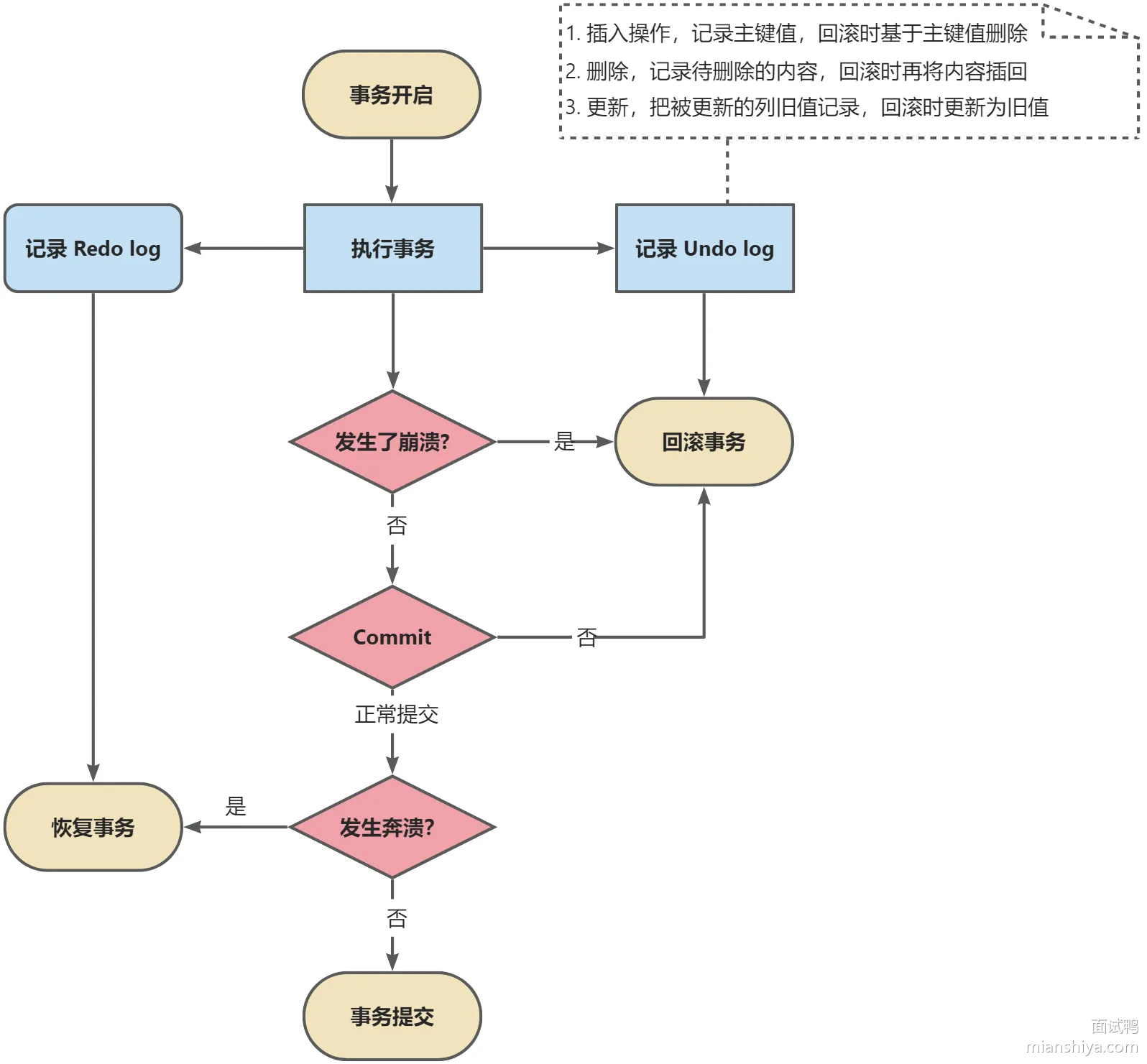
MySQL 是如何实现事务的?

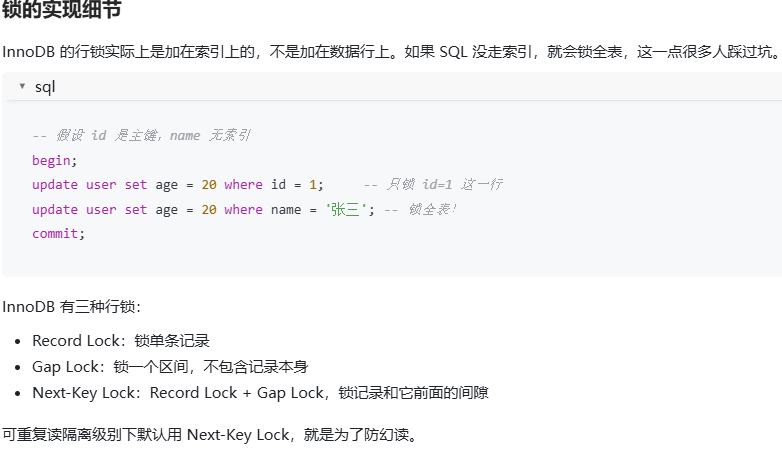


MySQL 中的 MVCC 是什么?

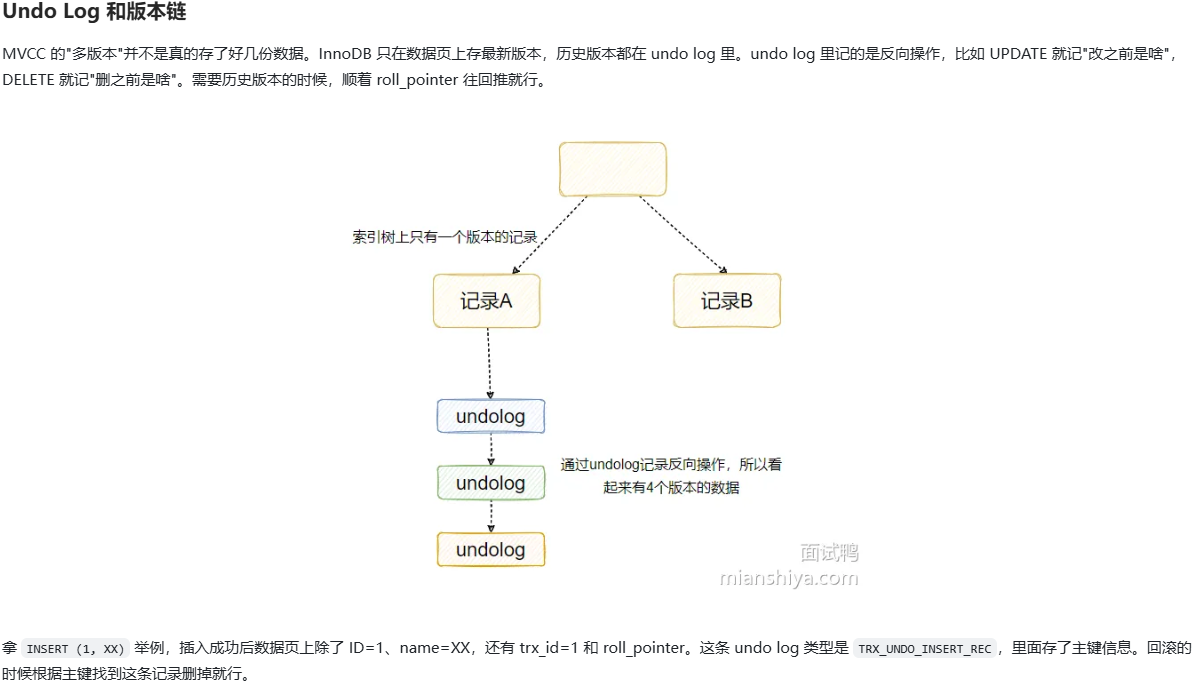
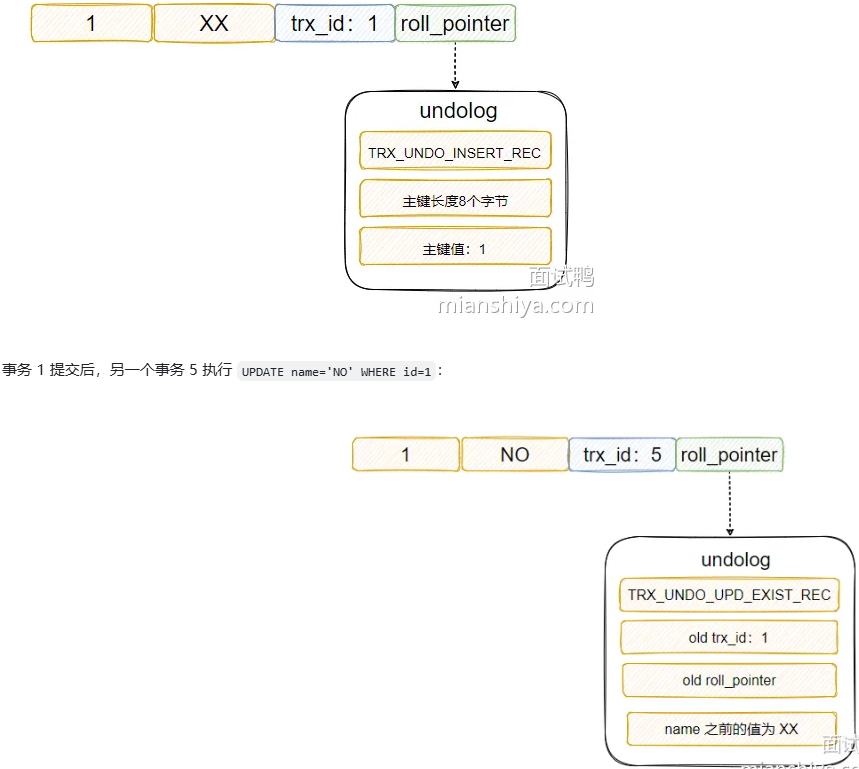



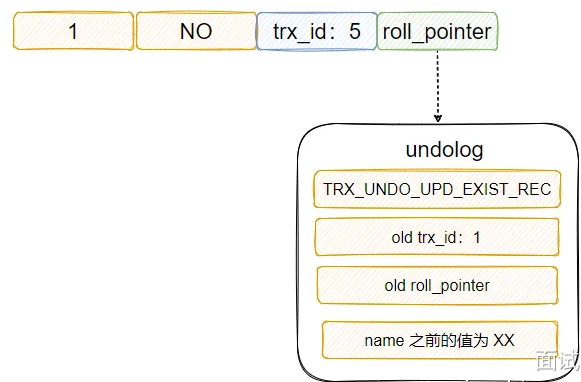



什么是分库分表?分库分表有哪些类型(或策略)?


