本节先介绍在Linux驱动程序中的并发与竞争的处理,再介绍应用层与驱动层并发与竞争的区别。
1.在Linux驱动中什么会产生竞争?
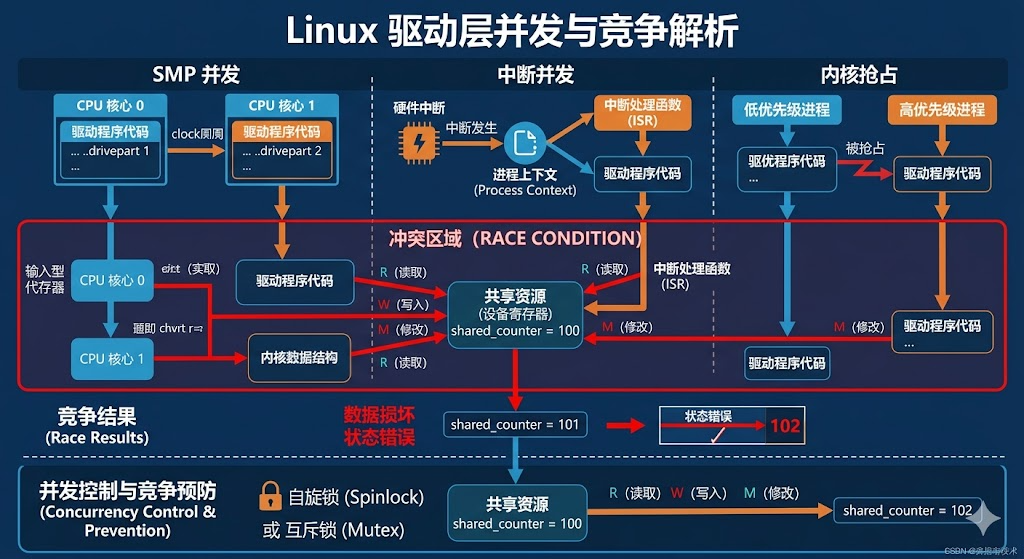
在 Linux 内核中,竞争通常源于以下四个方面:
-
多核并发 (SMP):多个物理 CPU 核同时运行不同的进程或中断。
-
内核抢占 (Preemption):高优先级的进程抢占当前正在执行的低优先级进程。
-
硬件中断 (Interrupts):硬件触发中断,强制 CPU 停止当前任务转而执行中断处理函数(ISR)。
-
软中断与 Tasklet:内核的异步延迟执行机制。
2.并发处理机制
本节将系统介绍 Linux 驱动中解决并发竞争的四种常用机制:原子变量 、自旋锁 、信号量 和 互斥锁,包括原理、适用场景及典型代码示例。
2.1原子变量(Atomic Variables)
原子变量是一种特殊的整型变量,其读写、加减、测试等操作由硬件保证在单条指令内完成,不会被中断或其它 CPU 核心打断。Linux 内核提供 atomic_t 类型以及一系列原子操作函数。
适用场景:
-
计数器:如统计设备打开的引用计数、丢包计数等。
-
标志位:仅需进行"读取-修改-写回"且不涉及复杂数据结构的场景。
常用API:
cpp
#include <linux/types.h>
atomic_t cnt = ATOMIC_INIT(0);
// 读原子变量
int val = atomic_read(&cnt);
// 加/减
atomic_inc(&cnt); // 自增 1
atomic_dec(&cnt); // 自减 1
atomic_add(2, &cnt); // 加 2
atomic_sub(1, &cnt); // 减 1
// 测试并设置(如果当前值为 0,则设置为 1 并返回 true)
if (!atomic_add_unless(&cnt, 1, 1)) {
// 已经是 1,无法设置
}
// 设置新值
atomic_set(&cnt, 10);优点:不涉及线程切换,不消耗多余 CPU,效率极高。
2.2自旋锁(spinlock)
原理:
自旋锁是一种忙等待锁。当线程尝试获取已被占用的自旋锁时,它会在一个循环中不断检测锁的状态("自旋"),直到锁被释放。自旋期间该线程不会睡眠,也不会让出 CPU。
-
在单核非抢占内核中,自旋锁退化为空操作(因为一次只能有一个线程运行,只需关中断即可)。
-
在多核系统中,自旋锁通常会在获取前禁用内核抢占,防止其他 CPU 上的进程抢占当前线程导致死锁。
核心特性 :持有自旋锁期间绝对不能睡眠 (不能调用 schedule()、copy_from_user()、mutex_lock() 等可能阻塞的函数),否则其他等待锁的 CPU 会永远自旋,系统死锁。
由于自旋锁是忙等的,所以自旋锁的临界区尽可能的短,快进快出。
适用场景:
-
临界区极短(几个内存访问、几条指令),锁持有时间远小于两次上下文切换开销。
-
保护中断上下文与进程上下文共享的数据 (需结合
spin_lock_irqsave()禁止本地中断)。 -
SMP 环境下对共享数据结构的快速更新,如链表、哈希表节点插入删除。
常用API:
cpp
#include <linux/spinlock.h>
DEFINE_SPINLOCK(my_lock); // 静态初始化
spinlock_t my_lock;
spin_lock_init(&my_lock); // 动态初始化
// 普通版本(假定不会在中断中使用)
spin_lock(&my_lock);
/* 临界区 */
spin_unlock(&my_lock);
// 禁用本地中断的版本(防止中断处理程序争用)
unsigned long flags;
spin_lock_irqsave(&my_lock, flags);
/* 临界区 */
spin_unlock_irqrestore(&my_lock, flags);自旋锁不允许持有者睡眠的原因:
典型的死锁场景 (The Deadlock Trap):假设你在 CPU A 上持有了自旋锁,然后调用了 msleep() 睡着了:
- CPU A 进入睡眠,调度器被迫切换到了 进程 B。
- 进程 B 恰好也需要访问被这个自旋锁保护的资源,于是它也调用了 spin_lock()。
- 由于自旋锁是"忙等"锁,进程 B 会在 CPU A 上疯狂原地打转(自旋),等待锁释放。
- 关键点 :持有锁的那个进程还在睡眠队列里躺着呢!它需要 CPU A 重新调度它才能继续运行并释放锁。但此时 CPU A 正在被 进程 B 的自旋动作 100% 占用。
- 结果 :进程 B 永远等不到锁,持有锁的进程永远回不来。CPU A 彻底锁死。
2.3信号量
我们讲自旋锁不允许休眠,是忙等的,信号量是一种可以引起休眠的锁。它通常包含一个计数器,允许 N 个执行单元同时进入临界区(如果 N=1,则等同于互斥锁)。信号量就相当于钥匙,如果有5把钥匙就是可以同时有五个人可以访问。
-
行为:拿不到锁时,进程会进入休眠状态,释放 CPU 给其他任务。
-
适用场景:临界区执行时间较长,涉及磁盘 IO 或大量内存拷贝。
-
限制 :严禁在中断上下文使用。因为中断不能休眠。
常用API:
cpp
#include <linux/semaphore.h>
struct semaphore sem;
sema_init(&sem, 1); // 初始值 1,互斥信号量(类似于互斥锁)
sema_init(&sem, 5); // 初始值 5,允许 5 个并发
// 获取信号量(可被信号中断,返回 -EINTR)
if (down_interruptible(&sem)) {
return -ERESTARTSYS;
}
/* 临界区 */
up(&sem); // 释放信号量
// 不可中断版本(较少用,因为难以终止进程)
down(&sem);2.4互斥锁(Mutex)
互斥锁(mutex)是信号量的一种特例(计数值为 1),但它有更严格的约束和更优的性能。互斥锁也导致进程睡眠,但比信号量更轻量,且增加了调试检查(例如不能在中段上下文使用、不能递归获取、持有者必须由同一线程释放)
适用场景:
-
标准的互斥访问(一次只有一个线程进入临界区)。
-
临界区可能较长,但不需要计数功能。
-
进程上下文中保护共享资源。
常用API:
cpp
#include <linux/mutex.h>
DEFINE_MUTEX(my_mutex); // 静态初始化
struct mutex my_mutex;
mutex_init(&my_mutex); // 动态初始化
mutex_lock(&my_mutex);
/* 临界区 */
mutex_unlock(&my_mutex);
// 可被信号中断的版本
if (mutex_lock_interruptible(&my_mutex)) {
return -ERESTARTSYS;
}2.5对比
| 需求场景 | 推荐方案 | 理由 |
|---|---|---|
| 仅保护一个简单的整数 | 原子变量 | 效率最高,无锁开销 |
| 临界区极短,且可能在中断中使用 | 自旋锁 | 中断不能休眠,自旋锁是唯一选择 |
| 临界区很长,涉及 IO 操作 | 互斥锁 | 避免长时间占用 CPU,允许系统调度 |
| 允许多个读者同时访问,仅写者互斥 | 读写锁/RCU | 优化高频读取场景的性能 |
3.驱动并发与应用并发的区别
在 Linux 系统中,应用层(User Space)与驱动层(Kernel Space)在处理并发(Concurrency)与竞争(Race Condition)时,虽然目标一致(都是保护共享资源),但其实现机制、约束条件和底层逻辑有着天壤之别。
以下从五个维度对两者的差异进行详细拆解:
1. 竞争对手的"身份"差异
这是理解两者区别的根基。在应用层,你面对的干扰相对单一;而在驱动层,干扰无处不在。
-
应用层(竞争对手:进程/线程)
-
多线程:同一个进程内的线程抢夺全局变量。
-
多进程:不同进程通过共享内存或文件进行竞争。
-
特点:所有的竞争者都受操作系统调度器(Scheduler)管辖,行为可预测。
-
-
驱动层(竞争对手:上下文/中断/硬件)
-
进程上下文:不同应用进程通过系统调用进入内核,同时操作同一个驱动。
-
中断上下文:正在执行驱动代码时,硬件突然触发中断,中断处理函数(ISR)强行插入并修改数据。
-
多核抢占(SMP):在多核 CPU 上,核 A 在运行驱动,核 B 也在运行同样的驱动代码,两者物理并行。
-
软中断/Tasklet:内核的异步延迟执行机制。
-
2. 同步机制的"工具箱"对比
A. 互斥锁(Mutex)与信号量(Semaphore)
-
应用层 :调用
pthread_mutex_lock。如果拿不到锁,线程会被操作系统挂起(休眠),直到锁释放。 -
驱动层 :也存在
struct mutex。但关键区别在于:驱动层互斥锁绝对不能在中断上下文中使用。因为中断上下文没有进程实体,一旦进入休眠(调度),内核就无法再切回中断现场,导致系统"挂死"。
B. 自旋锁(Spinlock)------驱动层的"核心杀手锏"
-
应用层 :极少使用(虽然有
pthread_spin_lock)。因为应用层无法关抢占,如果持锁线程被切走,其他线程会白白空转 CPU。 -
驱动层 :必选方案。
-
逻辑:拿不到锁时不睡觉,而是原地打转(自旋)。
-
进阶版 :
spin_lock_irqsave。它在加锁的同时关闭本地 CPU 中断。这是为了防止:进程拿到锁后被中断抢占,而中断里也想拿这个锁,导致"原地自旋死锁"。
-
C. RCU (Read-Copy-Update) ------驱动层的"黑科技"
-
应用层:很难实现,通常需要复杂的库支持。
-
驱动层 :广泛使用。它的核心思想是"读者不加锁,写者先拷贝"。在读取路由表、设备列表等读多写少的场景下,性能几乎是无损的。
3. "睡眠"的权限差异
这是开发者最容易犯错的地方。
-
应用层 :几乎任何时候都可以睡眠。不管是等 IO、等锁还是手动
sleep,OS 会帮你处理好上下文切换。 -
驱动层 :严禁随意睡眠。
-
持有自旋锁时:严禁睡眠(因为别人正在原地等你,你一睡,大家一起死)。
-
处于中断上下文时:严禁睡眠(没有进程实体,无法被调度器唤醒)。
-
而在应用层,你永远不需要关心自己是否处于"中断上下文"。
-
4. 硬件层面的控制力
-
应用层:完全没有硬件控制权。你无法告诉 CPU"现在不要响应键盘中断"。
-
驱动层:拥有最高权限。
-
关中断(Local IRQ Disable):驱动可以暂时关闭当前 CPU 的中断响应,从而在物理上消灭"被中断打断"的可能性。
-
关抢占(Preemption Disable):可以告诉内核,"在我这段代码跑完前,不要把我切走"。
-
5. 内存顺序与屏障(Memory Barriers)
在现代多核处理器中,为了性能,CPU 会对指令进行重排。
-
应用层 :通常不需要担心。编译器和高级语言(如 C++11 的
std::atomic)已经帮你封装好了内存模型。 -
驱动层:必须手动处理。
-
当你操作硬件寄存器时顺序至关重要。比如:必须先给硬件写数据,再发"启动"指令。
-
驱动开发者必须显式使用
wmb()(写屏障)、rmb()(读屏障)来强制 CPU 按照代码顺序执行,否则硬件会因为指令重排而行为异常。
-