目录
[Serial / Serial Old](#Serial / Serial Old)
[Parallel / Parallel Old](#Parallel / Parallel Old)
[CMS(Concurrent Mark Sweep)](#CMS(Concurrent Mark Sweep))
[ZGC 简介](#ZGC 简介)
Serial / Serial Old
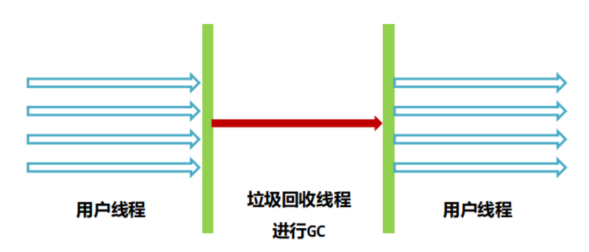
定位 :最古老、最稳定的单线程串行收集器,全程 STW。
算法:
-
新生代:复制算法
-
老年代:标记 - 压缩算法
特点:简单稳定,适合客户端 / 单核环境;停顿时间长,不适合高并发服务。
参数 :-XX:+UseSerialGC
ParNew
-
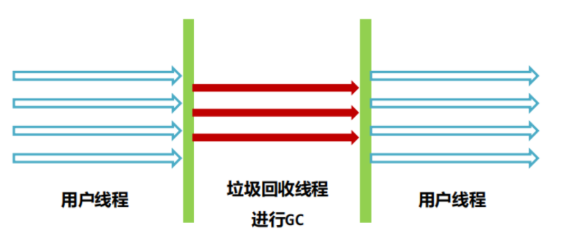
定位 :Serial 的多线程并行版本,早期配合 CMS 的新生代收集器。
-
算法:
-
新生代:复制算法(多线程并行)
-
老年代:串行(配合 Serial Old 或 CMS)、标记 - 压缩算法
-
-
特点:多线程并行回收,比 Serial 更快;仍需 STW;是 JDK 8 前唯一能与 CMS 配合的新生代收集器。
-
参数:
-
-XX:+UseParNewGC启用 ParNew -
-XX:ParallelGCThreads限制 GC 线程数
-
Parallel / Parallel Old
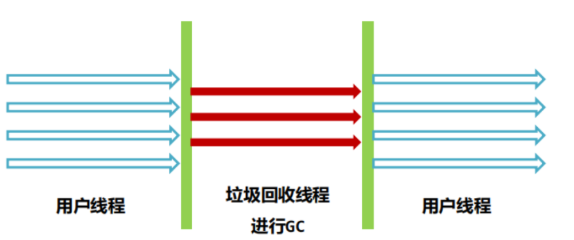
ParNew收集器的缺点是:无法自定义线程的数量,Parallel是对ParNew的改进。Parallel Old是Parallel Scavenge收集器的老年代版本。
-
定位 :注重吞吐量的并行收集器,JDK 8 默认收集器。
-
算法:
-
新生代(Parallel Scavenge):复制算法
-
老年代(Parallel Old):标记 - 压缩算法(JDK 6+ 提供)
-
-
特点:
-
多线程并行回收,追求高吞吐量;
-
支持自适应调节:动态调整 Eden/Survivor 比例、晋升年龄等;
-
适合后台计算型服务,对响应时间要求不高。
-
-
参数:
-
-XX:+UseParallelGC启用 Parallel Scavenge -
-XX:+UseParallelOldGC启用 Parallel Old
-
CMS(Concurrent Mark Sweep)
-
定位 :追求低停顿的并发收集器,适合互联网 / 响应敏感型服务。
-
核心目标:最短回收停顿时间,提升用户体验。
-
算法:标记 - 清除算法(Mark-Sweep)
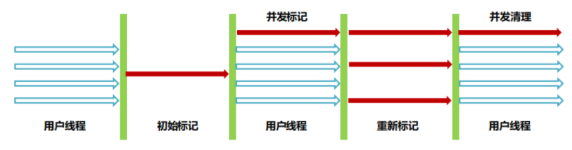
工作流程(4 阶段)
-
初始标记:STW,仅标记 GC Roots 直接关联的对象,速度极快。
-
并发标记:与用户线程并行,遍历 GC Roots 引用链,耗时最长。
-
重新标记:STW,修正并发标记期间因业务线程运行导致的标记变动,停顿比初始标记稍长。
-
并发清除:与用户线程并行,清理死亡对象。耗时第二长。
核心特点
-
STW 仅发生在初始标记和重新标记,并发阶段不影响用户线程,整体停顿极短;
-
预处理回收:需在老年代用尽前完成回收,否则会并发失败触发 Full GC。
优缺点
| 优点 | 缺点 |
|---|---|
| 并发收集、低停顿 | 产生大量内存碎片 |
| 与用户线程并行执行 | 并发阶段占用 CPU,降低吞吐量 |
| 适合响应敏感型服务 | 无法处理浮动垃圾,需预留内存空间 |
关键参数
-
-XX:+UseConcMarkSweepGC启用 CMS -
-XX:+UseCMSCompactAtFullCollectionFull GC 后进行碎片整理(会导致 STW 变长) -
-XX:CMSFullGCsBeforeCompaction设置多少次 Full GC 后进行一次碎片整理 -
-XX:ParallelCMSThreads设置 CMS 线程数(约等于 CPU 核心数)
G1收集器
-
定位 :JDK 9+ 默认收集器,目标是替代 CMS,兼顾低延迟与高吞吐量。
-
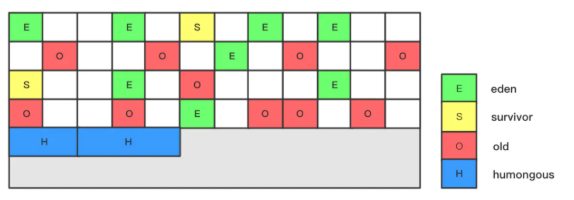
核心设计 :将堆划分为多个大小相等的 Region(1M~32M,2 的幂次方) ,新生代和老年代不再物理隔离,而是由多个 Region 组成;新增 Humongous(H) 区域存储巨型对象(超过 Region 大小 50%,直接在新的一个或多个连续region中分配,并标记为H)。
核心特点
-
并行与并发:充分利用多核 CPU 缩短 STW 时间,部分阶段可与用户线程并发执行。
-
分代收集:保留分代概念,可独立管理新生代和老年代,无需配合其他收集器。
-
空间整合 :整体基于标记 - 压缩算法,局部基于复制算法,不会产生内存碎片。
-
可预测停顿 :允许用户指定
MaxGCPauseMillis(垃圾收集上的时间不得超过N毫秒),在目标时间内优先回收垃圾最多的 Region(Garbage First)。 -
Remembered Set 优化:通过 RS 记录跨 Region 引用,避免全堆扫描,大幅提升效率。
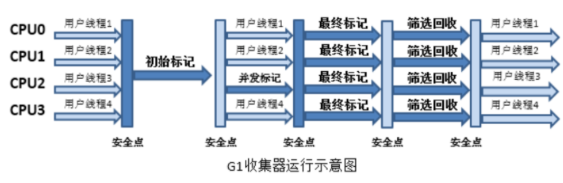
工作流程(4 阶段)
-
初始标记:STW,标记 GC Roots 直接关联的对象,速度快。
-
并发标记:与用户线程并行,进行可达性分析,遍历引用链。同时通过写屏障更新 RS。
-
最终标记 :STW,修正并发标记期间的变动,合并所有 Region 的 Remembered Set 数据,确保标记结果准确。
-
筛选回收:STW,对各 Region 按「回收价值 / 成本」排序,根据目标停顿时间选择回收区域,用复制算法清理垃圾,保证停顿可控。
关键参数
-
-XX:+UseG1GC启用 G1 -
-XX:G1HeapRegionSize指定 Region 大小(1M~32M,2 的幂次方) -
-XX:MaxGCPauseMillis设置目标最大 GC 停顿时间(毫秒) -
-XX:G1NewSizePercent设置新生代初始占比(默认 5%) -
-XX:G1MaxNewSizePercent设置新生代最大占比(默认 60%)
三色标记算法(并发标记核心)
使用可达性分析算法判断对象是否可以被回收 三色标记算法标记出来哪些对象可以被回收
基本概念
-
白色:未被访问过的对象(垃圾)
-
灰色:已被访问,但引用的对象未全部扫描
-
黑色:已被访问,且引用的对象全部扫描完毕(存活)
完整流程
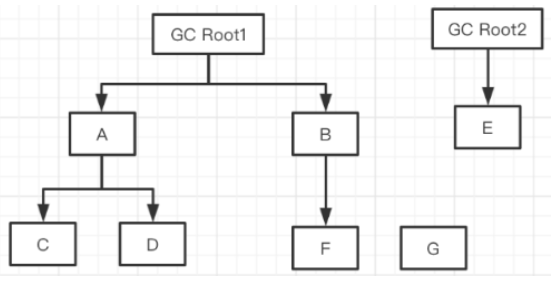
- 初始状态 :所有对象都是白色,只有 GC Roots 是根节点。
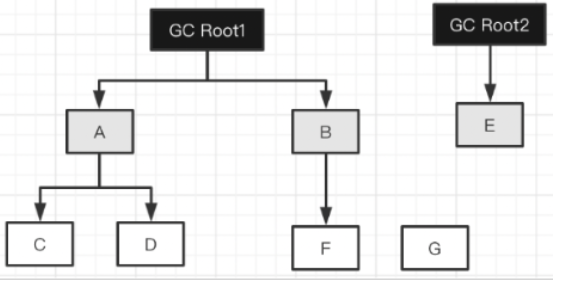
- 初始标记阶段:
-
把所有 GC Roots 直接引用的对象 (A、B、E)标记为灰色;
-
将这些灰色对象放入待处理队列;
-
GC Roots 本身标记为黑色(表示根节点已处理完成)。
- 遍历标记阶段
循环从「待扫描队列」中取出灰色对象,执行以下操作:
-
遍历当前灰色对象的所有直接引用子对象:
-
若子对象为白色 → 标记为灰色,并加入「待扫描队列」;
-
若子对象为灰色 / 黑色 → 无需处理;
-
-
当前灰色对象的所有子对象扫描完成后,将其标记为黑色;
-
重复上述步骤,直到「待扫描队列」为空。
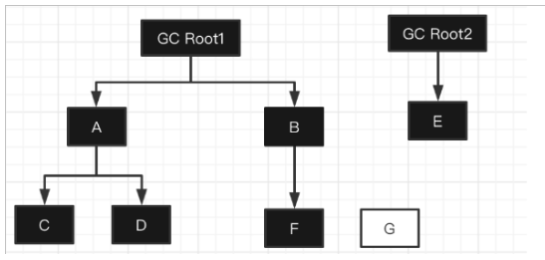
- 最终结果:
-
仍为白色 的对象(G):无法被 GC Roots 访问到 → 判定为垃圾对象,可以被回收。
-
标记为黑色的对象:可被 GC Roots 访问到 → 存活对象,保留。
并发标记问题与解决方案
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 浮动垃圾 | 已标记为存活的对象,在并发标记期间变为垃圾,本次 GC 不会清理,留待下次处理 | 无需处理,下次 GC 自动回收 |
| 漏标(错杀) | 仍被引用的对象被误判为垃圾,导致空指针异常 | 打破两个条件之一:1. 增量更新(CMS) :写屏障记录黑色对象新增的白色引用,重新标记时重新扫描2. 原始快照(SATB,G1):写屏障记录灰色对象断开的白色引用,将其标记为黑色,当作浮动垃圾留待下次处理 |
ZGC 简介
-
版本:JDK 11 引入,JDK 15+ 正式转正。
-
定位 :超低延迟 垃圾收集器,目标是将停顿时间控制在 亚毫秒级(<10ms),支持 TB 级大内存。
-
核心技术:染色指针(Colored Pointers),将标记信息存在对象指针中,无需修改对象头,实现并发标记与整理。
-
适用场景:对延迟极度敏感的服务(如金融、实时通信),否则优先选择 G1。
垃圾收集器对比与选择
回收器搭配与版本变化
-
新生代收集器:Serial、ParNew、Parallel Scavenge
-
老年代收集器:Serial Old、Parallel Old、CMS
-
整堆收集器:G1(独立管理新生代 + 老年代)
-
版本废弃:
-
JDK 9:废弃 ParNew
-
JDK 14:废弃 CMS
-
可搭配组合
| 新生代收集器 | 可搭配的老年代收集器 |
|---|---|
| Serial | Serial Old / CMS |
| ParNew | Serial Old / CMS |
| Parallel Scavenge | Serial Old / Parallel Old |
核心回收器对比表
| 收集器组合 | 关注点 | 核心优化 | 适用场景 |
|---|---|---|---|
| Serial/Serial Old | 简单稳定 | 单线程串行 | 客户端、单核环境 |
| Parallel/Parallel Old | 吞吐量 | 自适应调节、多线程并行 | 后台计算型服务、JDK 8 默认 |
| ParNew + CMS | 低停顿 | 并发标记(仅初始标记 / 重新标记 STW) | 互联网 / 响应敏感型服务(JDK 8 前) |
| G1 | 平衡低延迟与吞吐量 | Region 划分 + Remembered Set + 可预测停顿 | JDK 9+ 默认,通用型服务 |
| ZGC | 超低延迟 | 染色指针(标记存于指针) | 对延迟要求极高、超大内存场景 |
选择策略
Serial 单线程,Parallel 重吞吐,CMS 求低停,G1 靠 Region+RS 控停顿,ZGC 极致低延迟。
-
客户端程序 :
Serial + Serial Old(简单稳定,适合单核 / 桌面应用) -
吞吐量优先 :
Parallel Scavenge + Parallel Old(追求 CPU 利用率,适合后台计算、大数据场景) -
响应时间优先(JDK 8 前) :
ParNew + CMS(低停顿,适合互联网网站、B/S 服务) -
通用场景(JDK 9+) :
G1(平衡延迟与吞吐量,无内存碎片,可控制停顿时间) -
极致低延迟 :
ZGC(亚毫秒级停顿,适合金融、实时通信等超敏感场景)