目录
[MySQL 索引](#MySQL 索引)
【MySQL | 第二篇】 MVCC的底层实现(多版本并发控制)![]() https://blog.csdn.net/h52412224/article/details/159504812【MySQL | 第一篇】 深入理解三大日志(undo Redo Bin)
https://blog.csdn.net/h52412224/article/details/159504812【MySQL | 第一篇】 深入理解三大日志(undo Redo Bin)![]() https://blog.csdn.net/h52412224/article/details/159462696?spm=1001.2014.3001.5502
https://blog.csdn.net/h52412224/article/details/159462696?spm=1001.2014.3001.5502
MySQL 索引
概念
索引是一种用于快速查询和检索 数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引的作用就相当于书的目录,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了,无需遍历全书。
优缺点
索引的优点:
-
查询速度起飞(主要目的):通过索引,数据库可以大幅减少需要扫描的数据量,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
-
保证数据唯一性:通过创建唯一索引 (Unique Index),可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
-
加速排序和分组:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
索引的缺点:
-
创建和维护耗时:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行增、删、改 (DML 操作) 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会降低这些 DML 操作的执行效率。
-
占用存储空间:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会额外占用一定的磁盘空间。索引越多、越大,占用的空间也就越多。
-
可能被误用或失效:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
索引提速的原因
索引之所以快,核心原因是它大大减少了磁盘 I/O 的次数。
它的本质是一种排好序的数据结构,就像书的目录,让我们不用一页一页地翻(全表扫描)。
在 MySQL 中,这个数据结构是B+树。B+树结构主要从两方面做了优化:
-
B+树的特点是"矮胖",一个千万数据的表,索引树的高度可能只有 3-4 层。这意味着,最多只需要3-4 次磁盘 I/O,就能精确定位到我想要的数据,而全表扫描可能需要成千上万次,所以速度极快。
-
B+树的叶子节点是用链表连起来的。找到开头后,就能顺着链表顺序读下去,这对磁盘非常友好,还能触发预读。
索引底层数据结构
回答B+树,以及它的特点。
B+树的特点
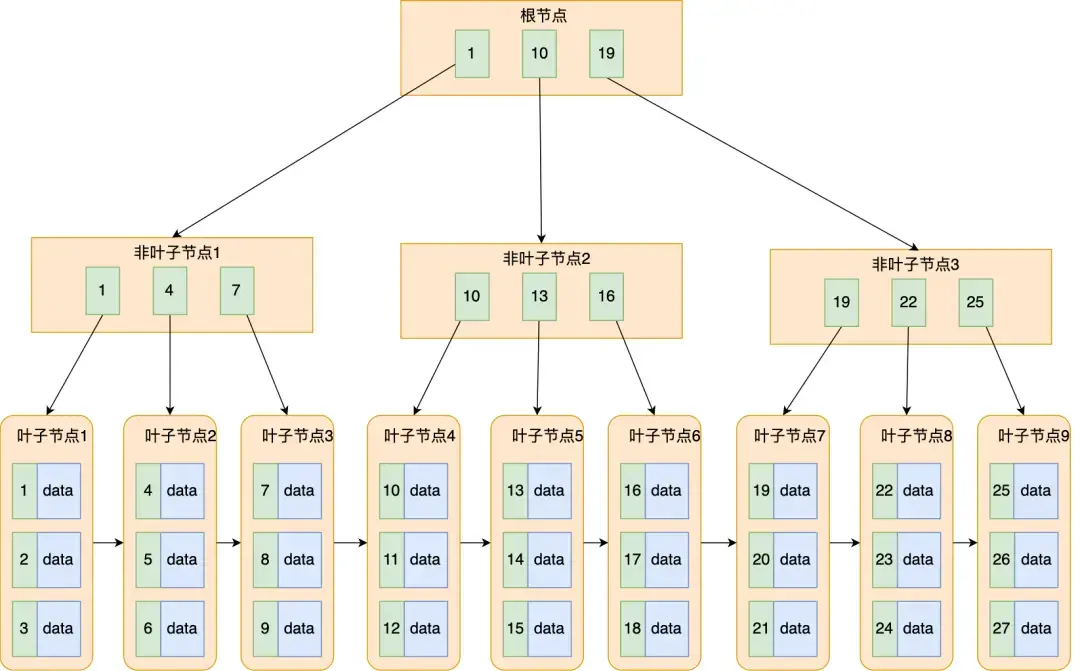
是 B-Tree(B 树)的优化变种,专为磁盘 IO 设计,结构分为「非叶子节点」和「叶子节点」:
-
非 叶子节点:仅存储「索引列的值 + 子节点指针」,不存实际数据,单个节点可容纳更多索引项(减少树的高度);
-
叶子节点 :存储「索引列的值 + 数据行的物理地址(MyISAM)/ 主键(InnoDB)」,且所有叶子节点通过双向链表连接(支持范围查询);
-
平衡性:B+Tree 是多路平衡树,保证任意叶子节点到根节点的路径长度一致,避免极端情况下的慢查询。
B+树 的优点
适配磁盘 IO 特性:磁盘「顺序 IO」速度是「随机 IO」的 100 倍以上,B+Tree 叶子节点的双向链表支持顺序读取,减少随机 IO;
树高度低:百万级数据的 B+Tree 高度仅 3-4 层,只需 3-4 次磁盘 IO 即可定位数据(对比二叉树,百万级数据高度约 20 层,IO 次数多);
查询效率稳定:无论查询哪个数据,路径长度一致,不会出现极端慢查询;
支持范围查询 :叶子节点的双向链表可快速遍历区间(如 WHERE id BETWEEN 10 AND 20),而 Hash 索引无法支持。
哈希为何未作为索引
它的优点是进行精确的等值查询时,理论上时间复杂度是 O(1) ,速度极快。
但它有几个对于通用数据库来说是致命的缺点:
-
不支持范围查询 : 这是最主要的原因。哈希函数的一个特点是它会把相邻的输入值(比如
id=100和id=101)映射到哈希表中完全不相邻的位置。这种顺序的破坏,使得我们无法处理像WHERE age > 30或BETWEEN 100 AND 200这样的范围查询。要完成这种查询,哈希索引只能退化为全表扫描。 -
不支持排序 : 同理,因为哈希值是无序的,所以我们无法利用哈希索引来优化
ORDER BY子句。 -
不支持部分索引键查询 : 对于联合索引,比如
(col1, col2),哈希索引必须使用所有索引列进行查询,它无法单独利用col1来加速查询。 -
哈希冲突问题: 当不同的键产生相同的哈希值时,需要额外的链表或开放寻址来解决,这会降低性能。
B树与B+树的对比
-
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
-
B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
-
B+ 树叶子节点之间用链表连接了起来,有利于范围查询,而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
-
B+树的查找性能更稳定,每次查找都需要查找到叶子节点;而B树的查找可能会在非叶子节点找到数据,性能相对不稳定。
|----------|------------------|-----------------------|
| 对比维度 | B 树(B-Tree) | B + 树(B+Tree) |
| 数据存储位置 | 非叶子节点 + 叶子节点都存数据 | 仅叶子节点存数据,非叶子节点仅存索引 |
| 叶子节点关联 | 无关联(孤立) | 双向链表连接(有序) |
| 索引值冗余 | 无冗余(索引值仅出现一次) | 有冗余(非叶子节点索引值是叶子节点的副本) |
| 节点存储效率 | 低(数据占空间,单节点存索引少) | 高(仅存索引,单节点存更多索引项) |
| 树高度 | 较高(百万数据约 4-5 层) | 更低(百万数据约 3-4 层) |
| 磁盘 IO 次数 | 更多(层级高 + 节点数据多) | 更少(层级低 + 节点索引多) |
| 等值查询效率 | 略快(可能在非叶子节点命中) | 稍慢(必须到叶子节点) |
| 范围查询效率 | 极低(需遍历多个子树) | 极高(叶子节点链表直接遍历) |
聚簇索引 和 主键 索引的关系
-
聚簇 / 非聚簇是按索引的物理存储特性划分(底层实现角度)
-
主键 / 二级是按索引的关联字段 / 业务用途划分(使用角度)
-
简单说:在 InnoDB 中, 主键 索引就是 聚簇索引 ,二级索引就是 非聚簇索引;
聚簇索引和非聚簇索引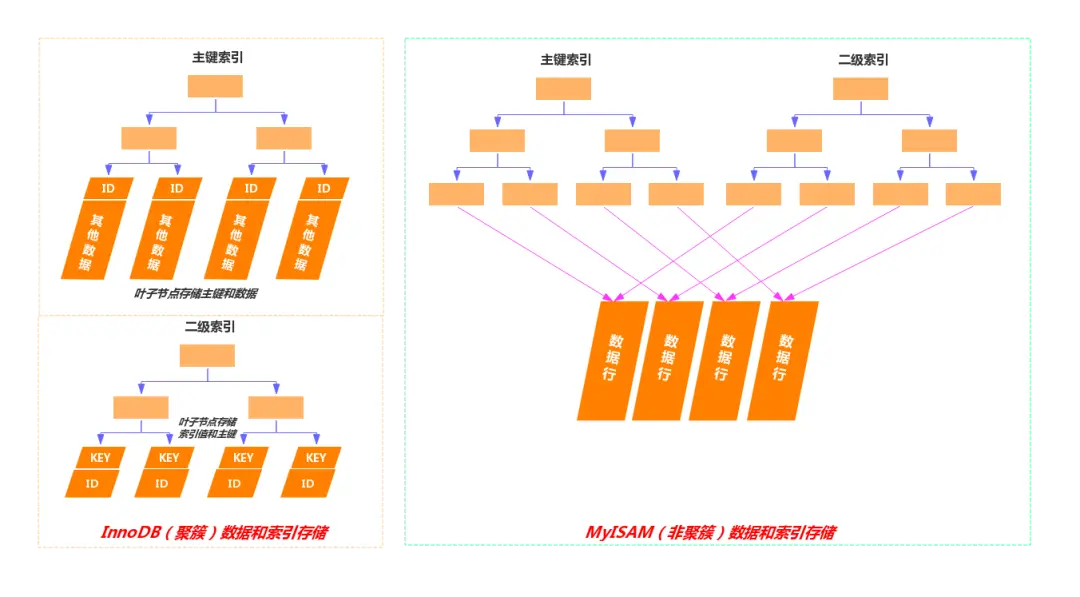
一、核心定义
-
聚簇索引
聚簇索引的索引 叶子节点 直接存储整行数据 ,且数据行的物理存储顺序与索引的逻辑排序完全一致,相当于索引本身就是数据的物理存储结构。
-
一个表只能有一个聚簇索引(因为数据物理顺序只能有一种);
-
InnoDB 中,主键默认是聚簇索引;若无主键,会选唯一非空索引;若都没有,数据库会隐式生成一个行号作为聚簇索引。
-
-
非聚簇索引
非聚簇索引的索引 叶子节点 仅存储索引键值 + 聚簇索引 键值(也叫"书签"),不存储整行数据,数据行的物理存储顺序与索引逻辑顺序无关。
-
一个表可以有多个非聚簇索引(仅索引结构独立存储,不影响数据物理顺序);
-
MyISAM 中所有索引都是非聚簇索引,InnoDB 中普通索引、唯一索引(非主键)均为非聚簇索引。
-
二、区别
|-------------|-------------------------------|--------------------------------|
| 对比维度 | 聚簇索引 | 非聚簇索引 |
| 数据存储关系 | 索引叶子节点=整行数据 | 索引叶子节点=键值+书签 |
| 物理顺序 | 数据物理顺序=索引逻辑顺序 | 数据与索引物理顺序无关 |
| 数量限制 | 一个表仅一个 | 一个表可多个 |
| 查询效率 | 单条/范围查询效率极高,无需回表 | 普通查询需回表(通过书签查聚簇索引取数据),效率略低 |
| 插入/更新代价 | 插入需保证物理顺序,频繁插入无序数据易产生页分裂,代价较高 | 仅维护索引结构,页分裂影响小,代价较低 |
| 空间占用 | 无需额外存储数据,空间占用小 | 需独立存储索引结构,空间占用更大 |
三、使用场景
聚簇索引
-
主键查询、高频范围查询的场景(如订单表按订单ID范围查询、用户表按用户ID查询);
-
适合作为表的核心标识字段索引,是所有非聚簇索引的基础。
非聚簇索引
-
高频等值查询的非主键字段(如用户表按手机号查用户、商品表按商品名称查商品);
-
多条件查询的联合索引(如订单表按"用户ID+订单时间"查询,建联合非聚簇索引);
-
需多个索引支持不同查询维度的场景(如商品表需按名称、分类、价格分别建索引)。
主键索引和二级索引
一、核心定义
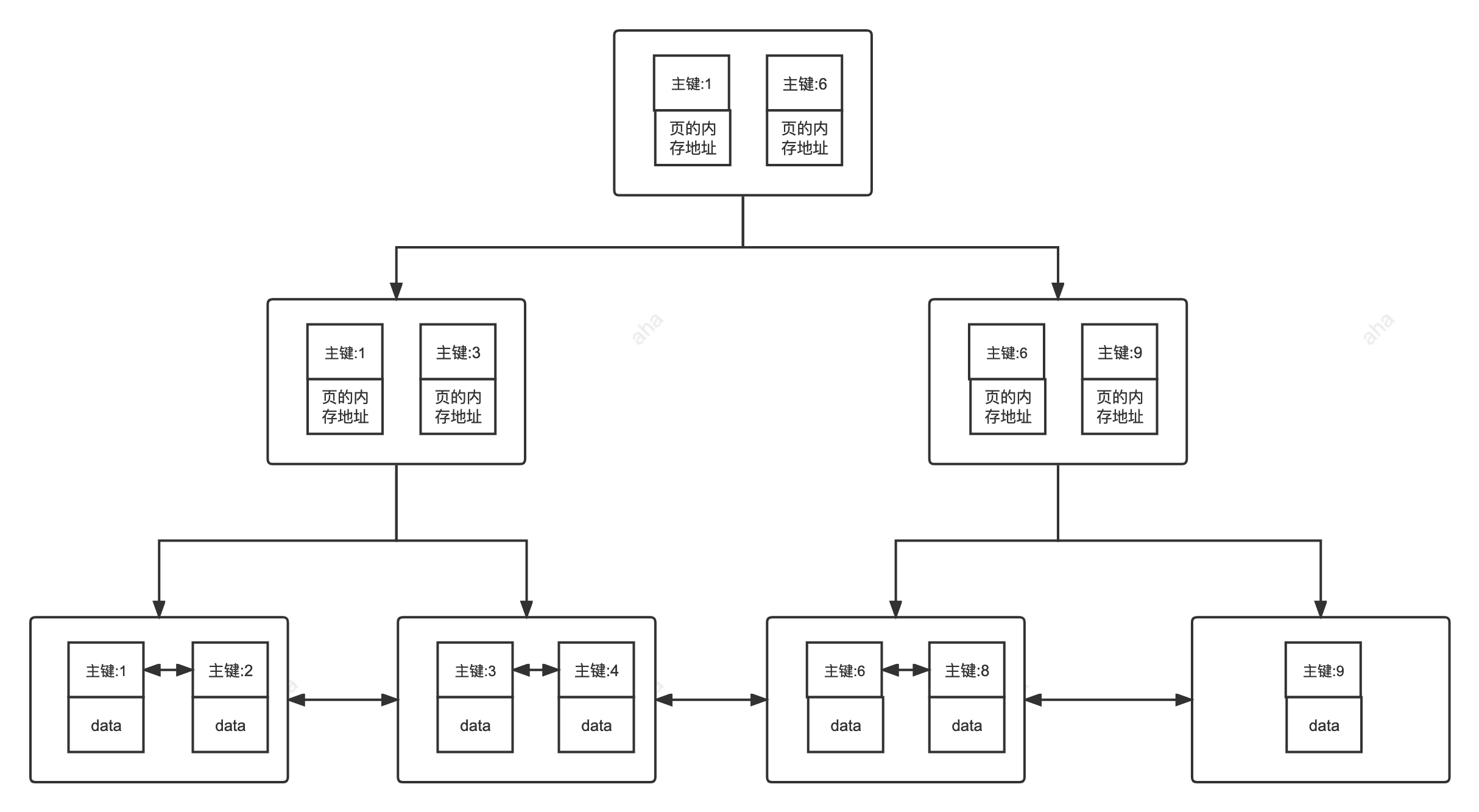
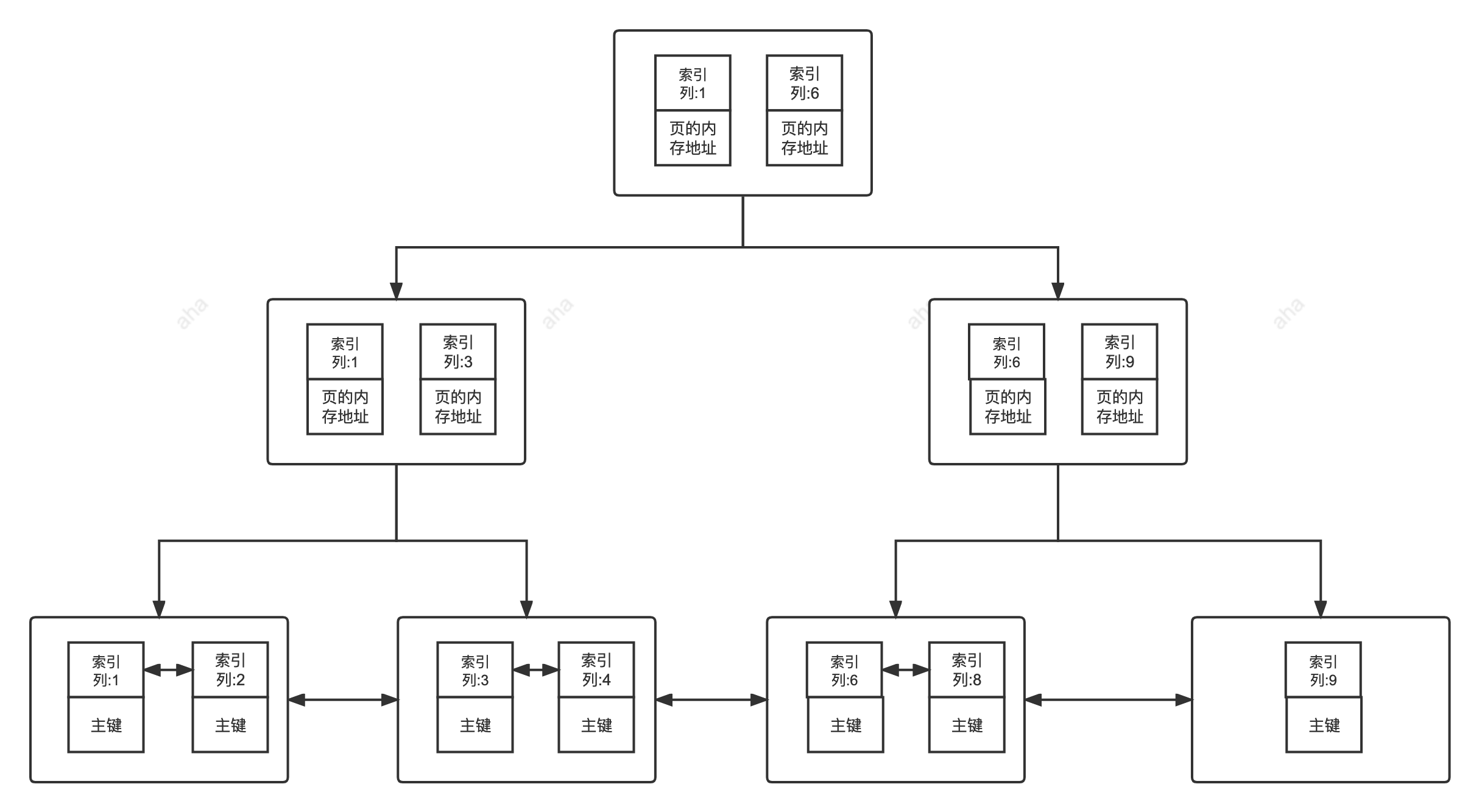
1. 主键 索引
主键索引是基于表的主键字段创建的 聚簇索引 ,是InnoDB表的默认聚簇索引,也是表的核心索引,用于唯一标识表中的每一行数据。
-
表只能有一个主键索引;
-
若未显式指定主键,InnoDB会先选择唯一非空索引作为主键索引;若无此索引,会隐式生成一个6字节的自增行号(row_id)作为隐藏主键,构建主键索引。
2. 二级索引
二级索引也叫辅助索引 ,是基于非 主键 字段创建的 非聚簇索引,包括普通索引、唯一索引(非主键)、联合索引等,用于优化非主键字段的查询效率。
-
表可以有多个二级索引,满足不同维度的查询需求;
-
二级索引不直接存储整行数据,是依赖主键索引完成最终数据查询的"过渡索引"。
二、区别
|------------------|------------------|---------------------------|
| 对比维度 | 主键 索引 | 二级索引 |
| 索引类型 | 聚簇索引 | 非聚簇索引(辅助索引) |
| 关联字段 | 仅能基于主键字段创建 | 基于任意非主键字段创建 |
| 数量限制 | 单表仅1个 | 单表可多个 |
| B+树 叶子节点 | 存储整行数据 | 存储索引键值+主键值 |
| 查询是否回表 | 直接取数,无需回表 | 普通查询需回表,覆盖索引除外 |
| 数据存储关系 | 索引与数据物理融合(索引即数据) | 索引与数据物理分离,依赖主键索引 |
| 构建前提 | 表的核心索引,无依赖 | 必须基于主键索引构建,无主键则依赖隐藏row_id |
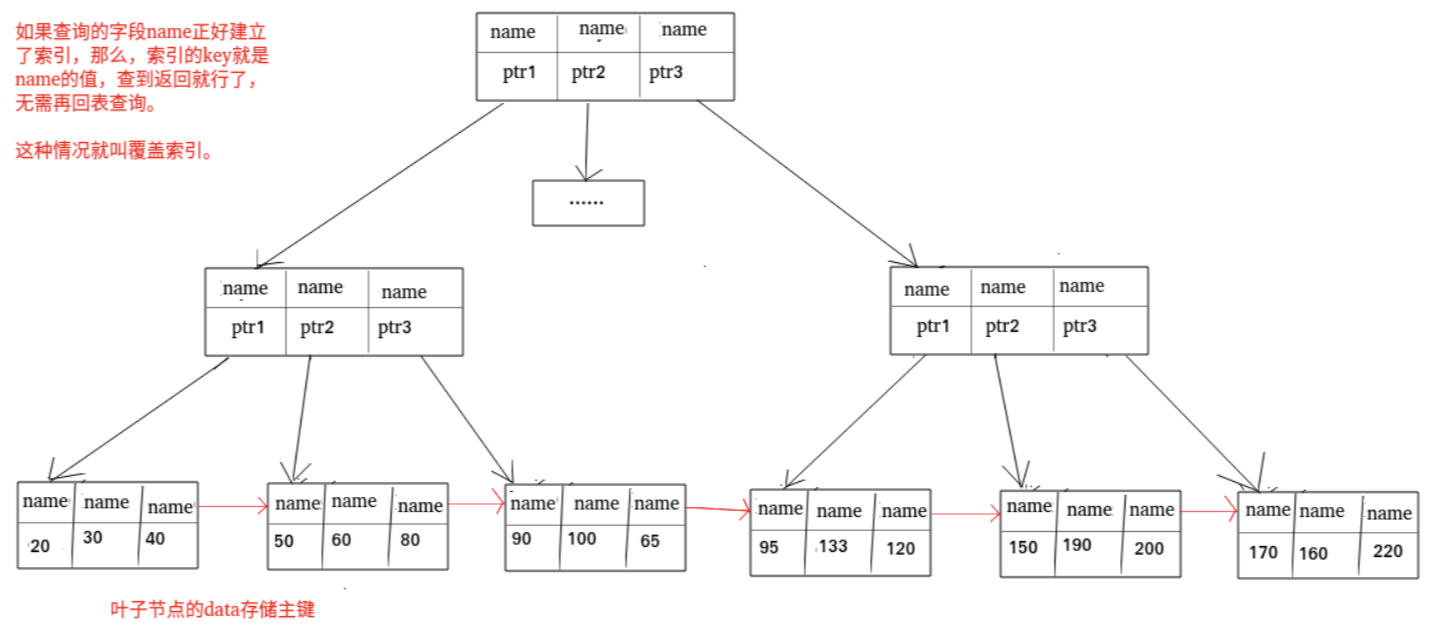
覆盖索引
一、核心定义
覆盖索引(Covering Index)是指索引的 叶子节点 中,包含了查询语句所需的所有字段 ,查询时仅通过遍历该索引即可获取全部结果,无需回表查询 聚簇 / 主键 索引的一种索引使用方式
示例
用户表user:主键id(聚簇索引),二级索引idx_phone (phone)(叶子节点存phone+id)
-
普通查询(需回表):
select id, phone, name from user where phone = '13800138000'原因:二级索引idx_phone仅包含phone+id,缺少name,需回表查聚簇索引获取name。 -
覆盖索引查询(无需回表):
select id, phone from user where phone = '13800138000'原因:查询的id+phone均在二级索引idx_phone的叶子节点中,直接遍历索引即可取数。 -
改造为覆盖索引:创建联合索引
idx_phone_name (phone, name),此时叶子节点存phone+name+id,执行上述普通查询也会触发覆盖索引,无需回表。
二、判定条件
查询语句触发覆盖索引,需同时满足2 个核心条件,缺一不可:
-
查询的所有字段 (select 后的列)都包含在同一个索引的叶子节点中;
-
查询的筛选条件 (where 后的条件)是该索引的前缀字段 (遵循联合索引的最左匹配原则)。
如果不符合最左匹配时,但是索引 叶子节点 包含查询所有字段,确实物理上不用回表,但数据库优化器不会将其判定为「覆盖索引」
联合索引及其最左前缀原则
使用表中的多个字段创建索引,就是 联合索引。
最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。
创建索引的原则
1. 只为高频查询字段建索引
2. 区分适合 / 不适合建索引的字段类型
✅ 适合建索引的字段
-
主键字段(必须建,InnoDB 默认聚簇索引);
-
唯一度高的字段(如手机号、身份证号,索引定位效率高);
-
多条件查询的组合字段(建联合索引,而非多个单字段索引)。
❌ 不适合建索引的字段
-
低基数字段(如性别、状态(仅 0/1)、删除标记,唯一度极低,索引扫描效率不如全表扫描);
-
大字段(如 text、longtext、blob,索引体积过大,磁盘 IO 效率低);
-
频繁更新的字段(每次更新需同步维护索引,易引发页分裂,降低性能)。
3. 联合索引 遵循 「等值优先、范围次之、查询最后」 排序
-
第一顺位:高频等值筛选字段 (
=/in),作为最左前缀,保证快速定位; -
第二顺位:高频范围筛选字段 (
>/</between); -
最后顺位:查询 / 排序 / 分组字段(
select/order by/group by)
4. 避免索引冗余,利用 联合索引 的最左前缀特性
-
联合索引
idx_a_b_c天然包含所有左前缀索引 (a、a-b、a-b-c),无需再为a、a-b单独建单字段 / 组合索引; -
示例:已建
idx_age_name,再建idx_age就是冗余索引,需直接删除,减少维护成本。
5. 主键 索引优先选择自增整型,拒绝 UUID / 字符串
-
自增整型(int/bigint):插入时按顺序追加在 B + 树末尾,无页分裂,插入效率高;且占用空间小,能减少二级索引的书签体积(二级索引存主键值);
-
UUID / 字符串:无序值,插入时频繁调整 B + 树结构引发页分裂,产生磁盘碎片;且占用空间大,导致二级索引体积膨胀,查询 IO 增加。
6. 长字符串字段建前缀索引,减少索引体积
-
对 varchar (100)/char 等长字符串字段,无需对全字段建索引,取前 N 个唯一字符 建前缀索引(如
idx_name(name(10))); -
核心:保证前 N 个字符的唯一性足够(如用户名前 10 位基本不重复),在减少索引体积的同时,不影响定位效率。
防止索引失效的原则
-
严格遵循 联合索引 最左前缀原则,跳过最左前缀会导致索引失效
-
索引字段禁止做函数 / 运算 / 类型转换,否则索引失效
-
模糊查询like %xxx 会导致索引失效,仅like xxx% 有效
-
like '%张三'/like '%张三%':模糊匹配从开头开始,破坏索引 B + 树的排序特性,索引失效; -
like '张三%':从最左开始匹配,能利用索引的前缀定位,索引有效;
-
-
or连接非索引字段,会导致索引失效- 替代方案:为非索引字段也建索引,或拆分查询用
union all拼接。
- 替代方案:为非索引字段也建索引,或拆分查询用
-
not in/not exists大概率导致索引失效,谨慎使用- 替代方案:用
<>``not between替代(如where age <>20 and age <>30),或结合业务用范围查询规避。
- 替代方案:用
-
避免select *,按需查询字段,配合 覆盖索引 优化
-
小表查询无需建索引,索引效率不如 全表扫描
上述内容也同步在我的飞书,欢迎访问
https://my.feishu.cn/wiki/QLauws6lWif1pnkhB8IcAvkhncc?from=from_copylink
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,你们的支持就是我坚持下去的动力!