你一定写过这样的代码:先对年龄做分箱,再对职业做 one-hot,然后把处理好的列拼起来,最后喂给模型。每一步都是散装的
fit_transform,变量名从X_binned到X_encoded到X_final,稍不留神就在测试集上用了训练集的 encoder,或者上线时漏了某一步预处理。
sklearn 提供了一套组合工具:Pipeline + ColumnTransformer ,把这些散装步骤焊成一条流水线。训练时一个 fit,预测时一个 predict,中间的特征工程全部封装在里面。
这篇文章从一个完整的信用评分建模场景出发,讲清楚这条流水线是怎么拼出来的、为什么要这样拼。
一、散装代码的问题
1.1 手动实现
先看最常见的写法,把每一步拆开手动执行:
python
from sklearn.preprocessing import KBinsDiscretizer, OneHotEncoder
from sklearn.linear_model import LogisticRegression
import numpy as np
# 第 1 步:数值特征分箱
binner = KBinsDiscretizer(n_bins=10, encode="ordinal", strategy="quantile")
X_train_binned = binner.fit_transform(X_train[numeric_features])
X_test_binned = binner.transform(X_test[numeric_features])
# 第 2 步:分箱结果 one-hot
ohe_num = OneHotEncoder(sparse_output=False, handle_unknown="ignore")
X_train_num = ohe_num.fit_transform(X_train_binned)
X_test_num = ohe_num.transform(X_test_binned)
# 第 3 步:类别特征 one-hot
ohe_cat = OneHotEncoder(sparse_output=False, handle_unknown="ignore")
X_train_cat = ohe_cat.fit_transform(X_train[categorical_features])
X_test_cat = ohe_cat.transform(X_test[categorical_features])
# 第 4 步:二值特征直接用
X_train_bin = X_train[binary_features].values
X_test_bin = X_test[binary_features].values
# 第 5 步:拼接
X_train_final = np.hstack([X_train_num, X_train_cat, X_train_bin])
X_test_final = np.hstack([X_test_num, X_test_cat, X_test_bin])
# 第 6 步:训练模型
model = LogisticRegression(max_iter=1000, C=0.1)
model.fit(X_train_final, y_train)1.2 踩坑点
上述代码本身没有错,但有三个容易踩的坑:
(1) 训练/测试不一致。
你必须记住每个 transformer 只在训练集上 fit,测试集只能 transform。步骤一多,手滑调反一次就是数据泄露。
(2)上线时要复现全部步骤。
部署时你需要保存 binner、ohe_num、ohe_cat 三个对象,还要记住拼接顺序。漏一个就会出错。
(3) 调参时代码膨胀
想试试 n_bins=5 和 n_bins=20 的效果?你得手动改值、重新跑全部六步。想做交叉验证?每一折都要重复这套流程。
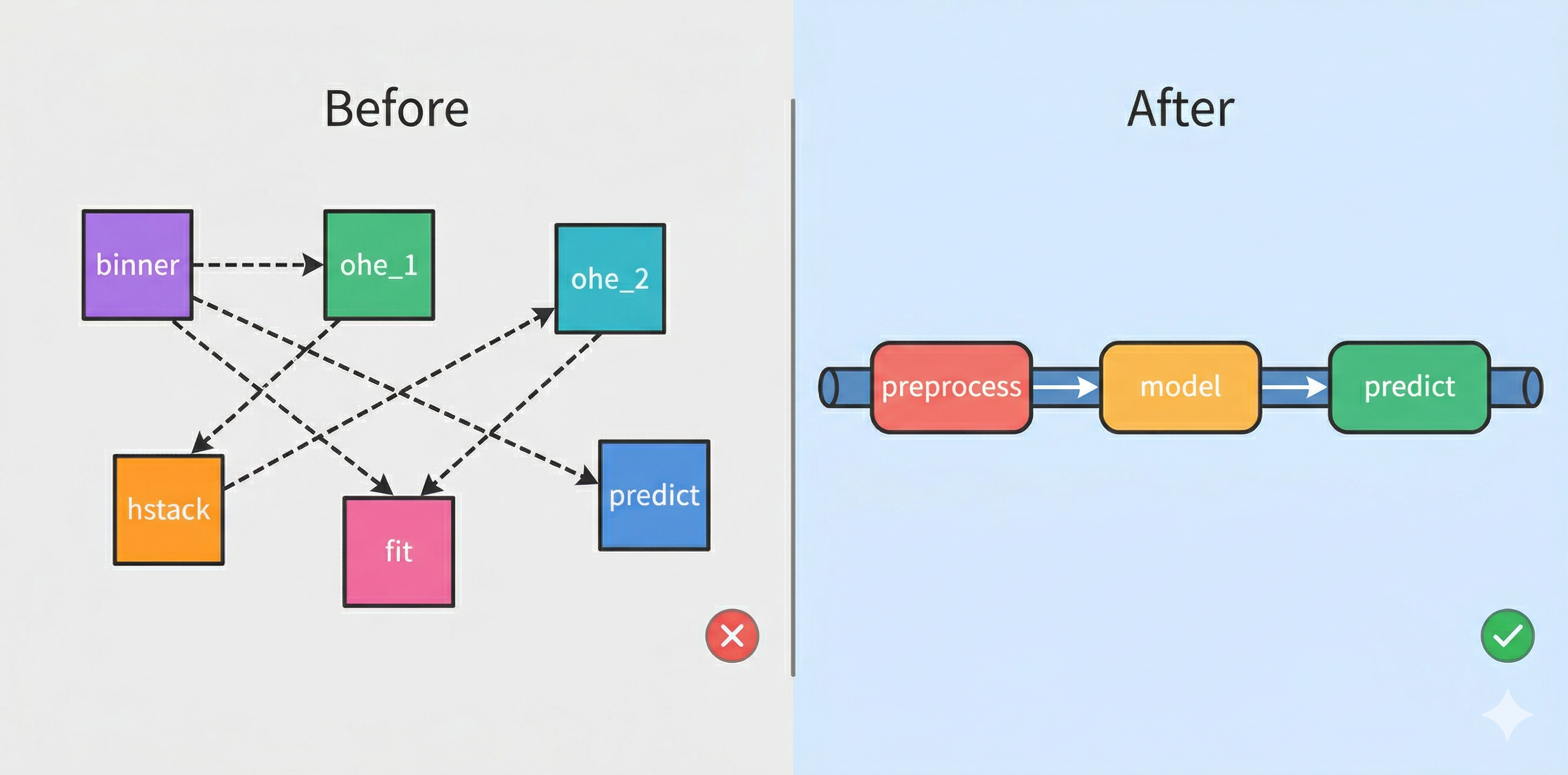
这些问题的根源是同一个:预处理和模型是分开的,你得自己保证它们步调一致。
二、Pipeline:把多步串成一步
Pipeline 把多个处理步骤串联成一个对象。调用这个对象的 fit,它会按顺序依次 fit_transform 每一步,最后一步只 fit;调用 predict,它会依次 transform,最后一步 predict。
2.1 简单示例
先看一个最简单的例子,数值特征的"分箱 → one-hot"两步操作:
python
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import KBinsDiscretizer, OneHotEncoder
numeric_transformer = Pipeline([
("binning", KBinsDiscretizer(n_bins=10, encode="ordinal", strategy="quantile")),
("onehot", OneHotEncoder(sparse_output=False, handle_unknown="ignore")),
]) Pipeline 接收一个列表,每个元素是 (名字, 转换器) 的二元组。名字随便起,但后面调参时会用到。
2.2 逻辑说明
这两步的执行逻辑是:
输入矩阵
│
▼
KBinsDiscretizer ── fit_transform ──▶ 分箱编号矩阵(0,1,2,...,9)
│
▼
OneHotEncoder ── fit_transform ──▶ one-hot 矩阵-
为什么分箱用
encode="ordinal"而不是直接encode="onehot"?
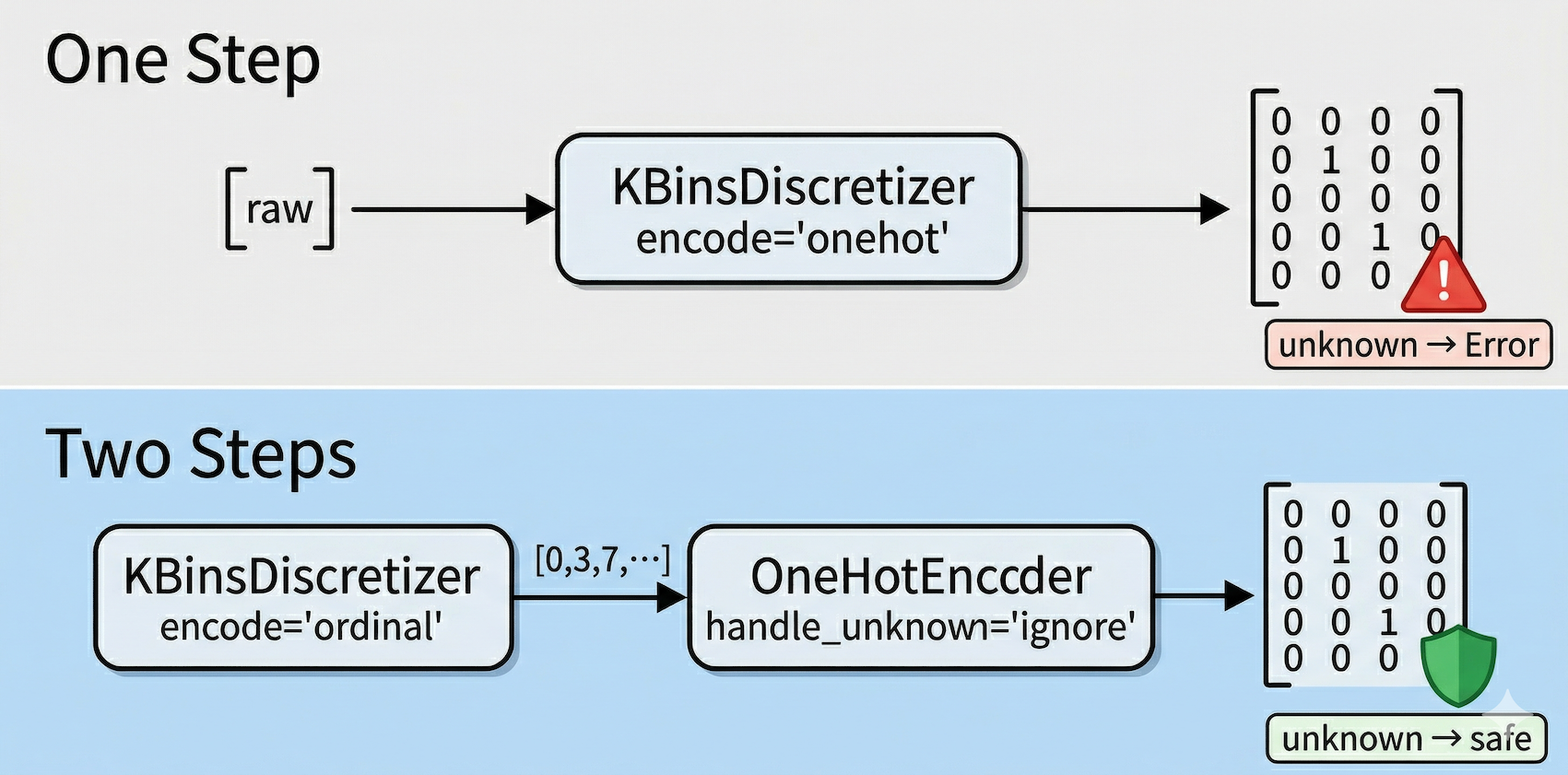
上面是一步到位的方案:
KBinsDiscretizer直接输出 one-hot,但它不认识训练时没见过的分箱编号,遇到就报错。下面是拆成两步的方案:第一步只输出整数编号,第二步交给OneHotEncoder,它的handle_unknown="ignore"能安全地把未知类别编码为全零向量,不会中断推理流程。生产环境中数据分布漂移是常态,两步写法多一层防护。
三、ColumnTransformer:不同列用不同管道
现实中,一张表里的特征不会都是同一种类型。数值特征要分箱,类别特征要 one-hot,二值特征什么都不用做。ColumnTransformer 解决的就是"不同列走不同处理路径,最后自动拼回来"这个问题。
3.1 简单示例
python
from sklearn.compose import ColumnTransformer
NUMERIC_FEATURES = ["age", "income", "debt_ratio"]
CATEGORICAL_FEATURES = ["education", "occupation"]
BINARY_FEATURES = ["has_house", "has_car"]
preprocessor = ColumnTransformer([
("num", numeric_transformer, NUMERIC_FEATURES),
("cat", OneHotEncoder(sparse_output=False, handle_unknown="ignore"), CATEGORICAL_FEATURES),
("bin", "passthrough", BINARY_FEATURES),
])3.2 参数说明
三个参数的含义:
| 参数位置 | 含义 | 示例 |
|---|---|---|
| 第 1 个 | 名字(用于调参和调试) | "num" |
| 第 2 个 | 转换器(可以是 Pipeline、单个 transformer,或 "passthrough") |
numeric_transformer |
| 第 3 个 | 要处理的列名列表 | NUMERIC_FEATURES |
"passthrough" 是特殊值,表示"这些列原样保留,不做任何转换"。二值特征已经是 0/1,直接用就行。
3.3 使用说明
执行时,ColumnTransformer 把输入 DataFrame 按列名拆成三组,分别送进各自的转换器,最后把输出水平拼接成一个矩阵:
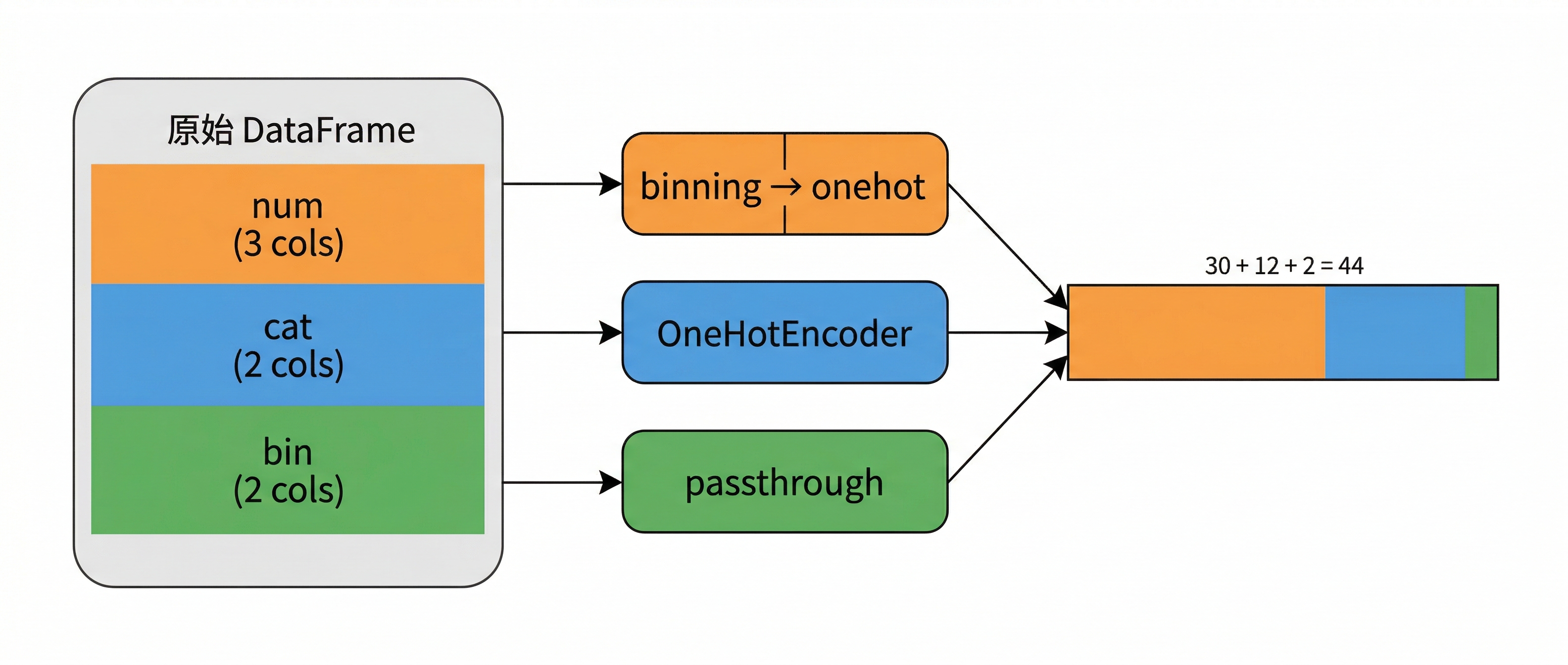
一张表进来,按列类型拆成三路:数值特征走"分箱→独热"两步管道,类别特征直接独热编码,二值特征原样通过。三路输出水平拼接成一个 44 列的矩阵,3 个数值特征各10 箱独热得 30 列,类别特征展开 12 列,二值特征 2 列。这个拆-处理-拼的过程就是 ColumnTransformer 自动完成的。
四、完整流水线:预处理 + 模型一体化
把 ColumnTransformer 和模型再套一层 Pipeline,就得到了一个从原始 DataFrame 到预测结果的完整对象:
python
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import KBinsDiscretizer, OneHotEncoder
from sklearn.linear_model import LogisticRegression
NUMERIC_FEATURES = ["age", "income", "debt_ratio"]
CATEGORICAL_FEATURES = ["education", "occupation"]
BINARY_FEATURES = ["has_house", "has_car"]
def build_pipeline(n_bins=10, strategy="quantile", C=0.1):
numeric_transformer = Pipeline([
("binning", KBinsDiscretizer(n_bins=n_bins, encode="ordinal", strategy=strategy)),
("onehot", OneHotEncoder(sparse_output=False, handle_unknown="ignore")),
])
categorical_transformer = OneHotEncoder(sparse_output=False, handle_unknown="ignore")
preprocessor = ColumnTransformer([
("num", numeric_transformer, NUMERIC_FEATURES),
("cat", categorical_transformer, CATEGORICAL_FEATURES),
("bin", "passthrough", BINARY_FEATURES),
])
return Pipeline([
("preprocess", preprocessor),
("model", LogisticRegression(max_iter=1000, random_state=42, C=C)),
]) 整个结构是嵌套的:
Pipeline(最外层)
├── preprocess: ColumnTransformer
│ ├── num: Pipeline
│ │ ├── binning: KBinsDiscretizer
│ │ └── onehot: OneHotEncoder
│ ├── cat: OneHotEncoder
│ └── bin: passthrough
└── model: LogisticRegression 写成函数的好处是参数化。 n_bins、strategy、C 都是函数参数,换一组超参数就是换一次函数调用,不用改任何内部代码。
五、用起来有多简单
5.1 训练和预测
python
pipe = build_pipeline(n_bins=10, C=0.1)
pipe.fit(X_train, y_train) # 一行完成所有预处理 + 模型训练
y_pred = pipe.predict(X_test) # 一行完成所有预处理 + 预测
y_prob = pipe.predict_proba(X_test) # 概率输出也一样 不需要手动管理任何中间变量。pipe 内部会自动保证训练集 fit、测试集只 transform。
5.2 交叉验证
python
from sklearn.model_selection import cross_val_score
pipe = build_pipeline(n_bins=10, C=0.1)
scores = cross_val_score(pipe, X_train, y_train, cv=5, scoring="roc_auc")
print(f"AUC: {scores.mean():.4f} ± {scores.std():.4f}") 如果预处理和模型是分开的,交叉验证时你要么手动在每一折里跑全套预处理(写起来极其繁琐),要么在交叉验证之前就把整个训练集预处理好,后者会导致数据泄露:分箱的边界、one-hot 的类别列表,都应该只从当前折的训练部分学到,不应该看到验证部分的数据。
Pipeline 自动解决了这个问题:每一折的 fit 只看训练部分,transform 应用到验证部分。
5.3 网格搜索
python
from sklearn.model_selection import GridSearchCV
param_grid = {
"preprocess__num__binning__n_bins": [5, 10, 20],
"preprocess__num__binning__strategy": ["quantile", "uniform"],
"model__C": [0.01, 0.1, 1.0],
}
search = GridSearchCV(
build_pipeline(),
param_grid,
cv=5,
scoring="roc_auc",
n_jobs=-1,
)
search.fit(X_train, y_train)
print(search.best_params_) 注意,参数名用双下划线连接层级 :preprocess__num__binning__n_bins 的意思是"Pipeline 的 preprocess 步骤 → ColumnTransformer 的 num 转换器 → Pipeline 的 binning 步骤 → n_bins 参数"。
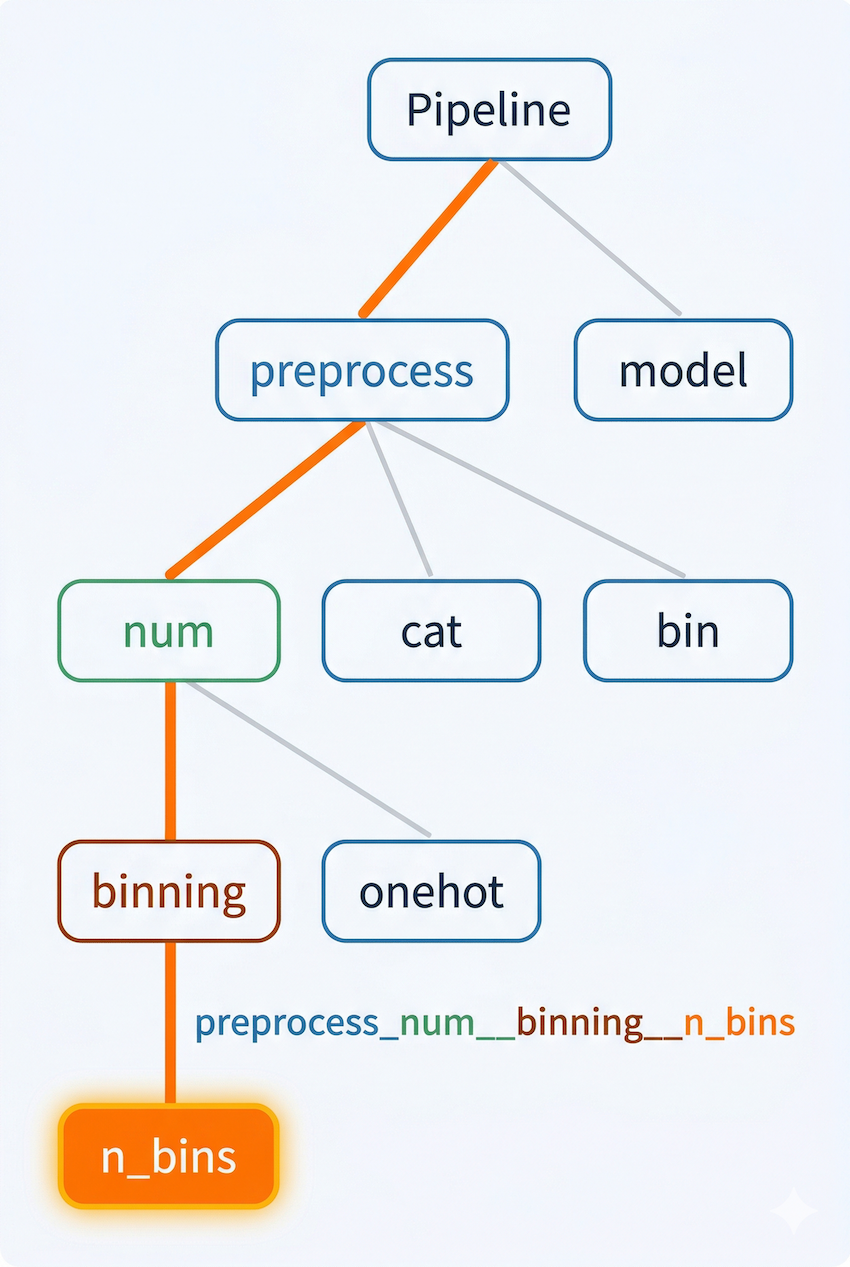
双下划线就是树的路径分隔符。preprocess__num__binning__n_bins 从根节点出发,经过四层嵌套定位到最底层的 n_bins 参数。这就是前面给每一步起名字的意义,名字是网格搜索的寻址路径。
5.4 持久化
python
import joblib
joblib.dump(pipe, "credit_model.pkl")
# 部署时
pipe = joblib.load("credit_model.pkl")
score = pipe.predict_proba(new_customer_df)[:, 1] 一个文件,包含全部预处理逻辑和模型权重。不会再出现"上线时忘了带 encoder"的问题。
六、和散装代码的对比
| 维度 | 散装代码 | Pipeline |
|---|---|---|
| 训练/测试一致性 | 手动保证,容易出错 | 自动保证 |
| 交叉验证 | 需要手写循环或冒数据泄露风险 | 直接传给 cross_val_score |
| 超参数搜索 | 手动改值 + 重跑 | GridSearchCV 一行搞定 |
| 部署 | 保存多个对象 + 拼接逻辑 | joblib.dump 一个对象 |
| 可读性 | 六步散装操作 | 嵌套结构一目了然 |
| 新增特征类型 | 改多处代码 | 在 ColumnTransformer 里加一行 |
七、总结
- Pipeline 串联步骤 :多个 transformer 串成一条链,
fit/transform/predict一个接一个自动执行 - ColumnTransformer 分列路由:不同类型的特征走不同的处理路径,最后自动拼接
- 嵌套组合:Pipeline 里可以放 ColumnTransformer,ColumnTransformer 里可以放 Pipeline,任意嵌套
- 双下划线寻址 :
步骤名__子步骤名__参数名的命名规则让网格搜索能直接触达任意层级的超参数 - 核心价值不是少写几行代码,而是消除训练和推理之间的不一致。预处理逻辑和模型绑在一起,不可能漏步骤、不可能用错 encoder
如果你正在做评分卡、风控模型、或者任何需要"分箱 + 编码 + 线性模型"的场景,Pipeline 几乎是标配写法。下次写建模代码时,试试从 build_pipeline() 函数开始,而不是从第一个 fit_transform 开始。