scikit-learn Lasso回归算法详解
本文介绍 scikit-learn 中的 Lasso 回归算法 。Lasso 在线性回归的基础上引入 L1 正则化项 ,能够在拟合数据的同时将部分特征系数压缩为 0,从而同时实现 回归建模 与 特征选择。本文将结合算法原理、关键参数、代码示例与可视化分析,系统说明 Lasso 的使用方式、系数收缩机制及其适用场景。整体来看,Lasso 适合高维数据和强调解释性的任务,但对特征缩放较为敏感,在强相关特征场景下结果可能不够稳定。
1. 算法背景
在线性回归中,我们希望找到一组合适的特征系数,使模型预测值尽可能接近真实值。普通最小二乘回归虽然简单有效,但当特征数量较多、变量之间相关性较强,或者数据中包含较多噪声时,模型往往容易出现过拟合或不稳定的问题。
为了解决这类问题,正则化方法被广泛引入。Ridge 回归通过加入 L2 正则化 约束系数大小,使模型更加平滑;而 Lasso 回归采用 L1 正则化,不仅会压缩系数,还可能将部分系数直接压缩为 0。也正因为如此,Lasso 不只是一个回归模型,同时也是一种嵌入式特征选择方法。
在 scikit-learn 中,其核心实现类是 Lasso:
python
from sklearn.linear_model import LassoLasso 的优化目标可以写作:
w^=argminw{12n∣y−Xw∣22+α∣w∣1} \hat{w} = \arg\min_w \left\{ \frac{1}{2n}|y - Xw|_2^2 + \alpha |w|_1 \right\} w^=argwmin{2n1∣y−Xw∣22+α∣w∣1}
其中,XXX 表示特征矩阵,yyy 表示目标变量,www 表示模型系数,α\alphaα 表示正则化强度。
从这个目标函数可以看出,Lasso 在最小化预测误差的同时,通过 L1 正则项约束模型复杂度。因此,它尤其适合两类任务:一类是高维特征数据下的回归建模,另一类是希望自动筛选变量并增强模型解释性的场景。
2. 核心参数说明
Lasso 的常用参数形式如下:
python
Lasso(
alpha=1.0,
*,
fit_intercept=True,
precompute=False,
copy_X=True,
max_iter=1000,
tol=0.0001,
warm_start=False,
positive=False,
random_state=None,
selection='cyclic',
)其中,最重要的参数是 alpha。它控制 L1 正则化强度,也决定模型在拟合能力与稀疏性之间的平衡。alpha 越大,正则化越强,被压缩为 0 的系数越多,模型越简单;alpha 越小,模型越接近普通线性回归,特征筛选能力则会减弱。
fit_intercept 用于控制是否拟合截距项,默认值为 True。通常保持默认即可;只有在数据已经完成中心化处理时,才会考虑设置为 False。
max_iter 表示最大迭代次数。由于 Lasso 依赖迭代优化求解,当数据维度较高或 alpha 较小时,模型可能需要更多迭代轮数才能收敛。若训练过程中出现收敛警告,通常可以优先尝试增大该参数。
tol 是停止迭代的阈值,用于控制优化精度。该值越小,求解越精细,但训练时间也会相应增加。
selection 用于指定系数更新方式。默认值为 "cyclic",表示按照特征顺序循环更新;若设为 "random",则每次随机选择特征进行更新。对应地,random_state 只在 selection="random" 时才会生效。
此外,positive 用于限制系数是否必须为正;warm_start 表示是否以上一次训练结果作为初始值;precompute 和 copy_X 则主要与计算过程有关。在大多数常规任务中,这些参数保持默认设置即可。
3. 为什么使用 Lasso 前通常要做标准化
Lasso 对特征尺度较为敏感。如果不同特征的量纲差异较大,那么相同的正则化强度作用在不同特征上时,就会产生不均衡的影响,进而改变系数收缩结果。换句话说,数值范围较大的变量可能在模型中占据不合理的优势,而数值范围较小的变量则更容易被压缩。
因此,在实际使用中,通常会先对特征做标准化处理,再输入 Lasso 模型。这样可以保证所有特征在统一尺度下参与建模,使正则化更加合理,得到的特征选择结果也更稳定。实际开发中,常见做法是使用 Pipeline 将标准化和建模过程串联起来:
python
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso
model = make_pipeline(
StandardScaler(),
Lasso(alpha=0.1)
)这种写法简洁清晰,也能够避免训练集和测试集预处理不一致的问题。
4. 代码示例:Lasso 回归
下面使用 make_regression 构造一个带噪声的回归数据集,并通过标准化与 Lasso 建立一个基础回归流程。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_error, r2_score
# 统一可视化风格
sns.set_theme(style="whitegrid", font="SimHei", rc={"axes.unicode_minus": False})
# 生成回归数据
X, y, coef_true = make_regression(
n_samples=200,
n_features=20,
n_informative=6,
noise=15,
coef=True,
random_state=42
)
feature_names = [f"X{i}" for i in range(X.shape[1])]
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 构建模型
model = make_pipeline(
StandardScaler(),
Lasso(alpha=0.2, max_iter=5000)
)
# 训练模型
model.fit(X_train, y_train)
# 模型预测
y_pred = model.predict(X_test)
# 评估指标
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("MSE:", mse)
print("R2 :", r2)
# 提取系数
lasso = model.named_steps["lasso"]
coef = lasso.coef_
coef_df = pd.DataFrame({
"特征": feature_names,
"系数": coef,
"系数绝对值": np.abs(coef)
}).sort_values("系数绝对值", ascending=False)
print("非零系数个数:", np.sum(coef != 0))
print(coef_df)MSE: 222.7948769880385
R2 : 0.9857870306930531
非零系数个数: 18
特征 系数 系数绝对值
17 X17 107.051592 107.051592
1 X1 64.004952 64.004952
11 X11 48.541786 48.541786
0 X0 44.486114 44.486114
8 X8 23.299332 23.299332
14 X14 10.359710 10.359710
10 X10 3.520441 3.520441
13 X13 3.079414 3.079414
3 X3 2.768845 2.768845
5 X5 -1.763141 1.763141
4 X4 1.193506 1.193506
15 X15 0.670071 0.670071
9 X9 -0.669645 0.669645
7 X7 0.542886 0.542886
12 X12 -0.445053 0.445053
19 X19 0.391531 0.391531
2 X2 -0.377449 0.377449
18 X18 0.163582 0.163582
6 X6 0.000000 0.000000
16 X16 -0.000000 0.000000
这段代码展示了一个典型的 Lasso 使用流程:先构造数据,再完成训练集与测试集划分,随后通过标准化与回归建模形成完整管道,最后输出误差指标和系数结果。相比只看预测性能,Lasso 的另一个重要价值在于系数本身,因为它直接反映了模型最终保留了哪些特征。
5. 可视化分析:系数分布
为了更直观地观察 Lasso 的特征选择结果,可以对系数进行可视化。下面的图将特征按系数绝对值从大到小排序,更适合用于技术博客展示。
python
plt.figure(figsize=(12, 6))
ax = sns.barplot(data=coef_df, x="特征", y="系数")
ax.axhline(0, color="black", linewidth=1.0, linestyle="--")
ax.set_title("Lasso回归系数分布", fontsize=14, pad=12)
ax.set_xlabel("特征", fontsize=11)
ax.set_ylabel("回归系数", fontsize=11)
plt.xticks(rotation=45)
non_zero_count = np.sum(coef != 0)
ax.text(
0.98, 0.95,
f"非零系数数:{non_zero_count}/{len(coef)}",
transform=ax.transAxes,
ha="right",
va="top",
fontsize=10,
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", alpha=0.85)
)
plt.tight_layout()
plt.show()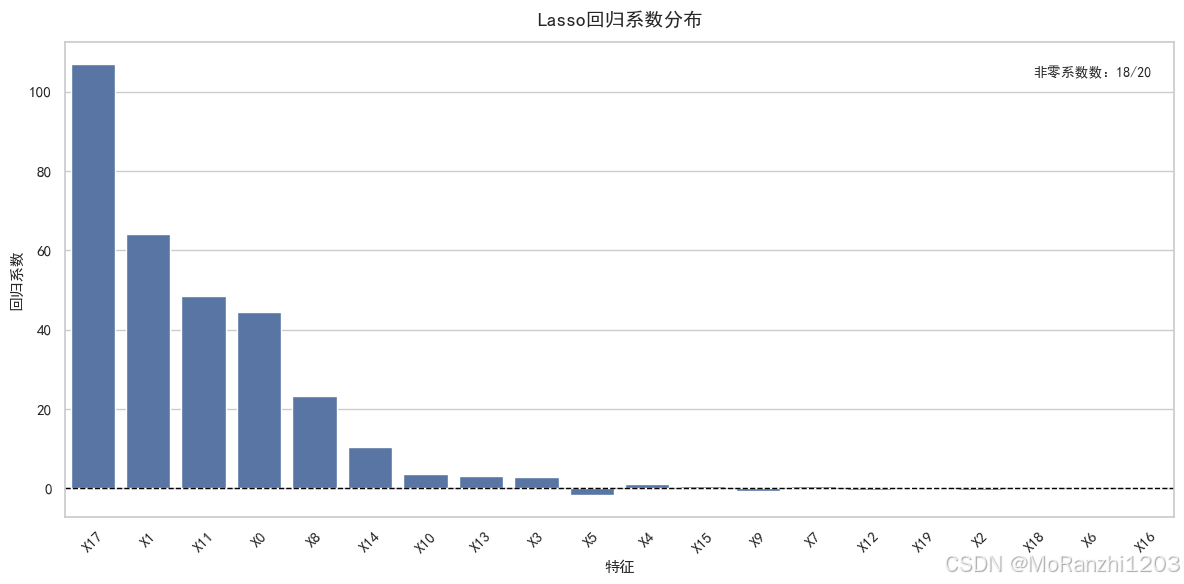
从这张图中可以直接看到,Lasso 不会为所有特征分配非零系数,而是会将一部分特征压缩到 0。也就是说,模型在进行回归预测的同时,也完成了自动特征筛选。最终保留下来的非零系数,通常对应着对目标变量更有解释力的特征,因此整个模型会更加紧凑,也更便于分析。
6. 可视化分析:预测值与真实值对比
除了观察系数分布,还可以通过真实值与预测值的散点图来评估模型拟合效果。
python
plt.figure(figsize=(7.2, 5.8))
ax = sns.scatterplot(x=y_test, y=y_pred, s=70, alpha=0.8)
min_val = min(y_test.min(), y_pred.min())
max_val = max(y_test.max(), y_pred.max())
ax.plot([min_val, max_val], [min_val, max_val], linestyle="--", linewidth=1.5)
ax.set_title("Lasso预测值与真实值对比", fontsize=14, pad=12)
ax.set_xlabel("真实值", fontsize=11)
ax.set_ylabel("预测值", fontsize=11)
ax.text(
0.05, 0.95,
f"$R^2$ = {r2:.4f}\nMSE = {mse:.2f}",
transform=ax.transAxes,
ha="left",
va="top",
fontsize=10,
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", alpha=0.85)
)
plt.tight_layout()
plt.show()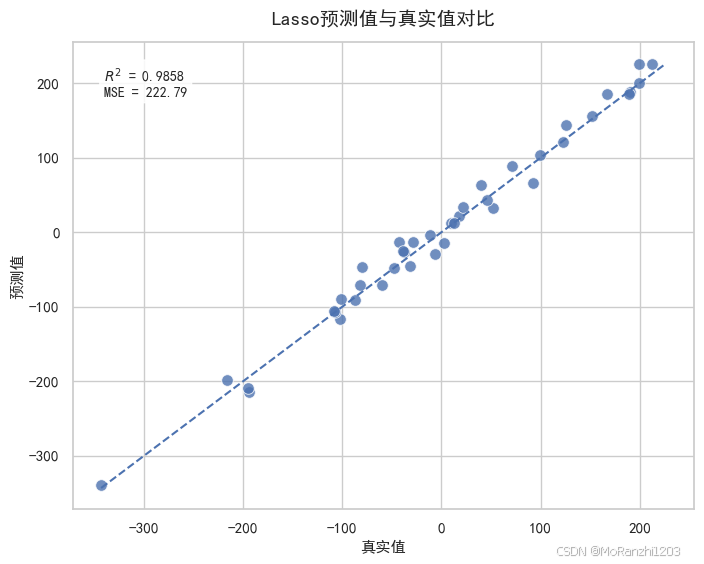
如果散点大致分布在对角线附近,说明模型整体拟合效果较好;若偏离明显,则说明预测误差较大。将这张图与系数图结合起来,可以同时展示 Lasso 的两个核心特征:一方面通过正则化控制模型复杂度,另一方面在保持一定预测能力的同时实现特征筛选。
7. 不同 alpha 对系数收缩的影响
alpha 是 Lasso 中最关键的超参数。为了更直观地展示它对模型的影响,可以观察不同 alpha 取值下的系数收缩路径。
python
from matplotlib.font_manager import FontProperties
alphas = [0.01, 0.1, 0.5, 1.0, 5.0]
coef_list = []
for a in alphas:
temp_model = make_pipeline(
StandardScaler(),
Lasso(alpha=a, max_iter=5000)
)
temp_model.fit(X_train, y_train)
coef_list.append(temp_model.named_steps["lasso"].coef_)
coef_matrix = np.array(coef_list)
# 对数坐标轴刻度字体优化
tick_fp = FontProperties(family="DejaVu Sans")
plt.figure(figsize=(8.2, 5.6))
ax = plt.gca()
for i in range(coef_matrix.shape[1]):
ax.plot(
alphas,
coef_matrix[:, i],
marker="o",
linewidth=1.8,
alpha=0.8
)
ax.set_xscale("log")
ax.axhline(0, color="black", linestyle="--", linewidth=1.0)
ax.set_title("不同 alpha 下的 Lasso 系数收缩路径", fontsize=14, pad=12)
ax.set_xlabel("alpha(对数尺度)", fontsize=11)
ax.set_ylabel("回归系数", fontsize=11)
ax.grid(True, linestyle="--", alpha=0.45)
for label in ax.get_xticklabels():
label.set_fontproperties(tick_fp)
for label in ax.get_yticklabels():
label.set_fontproperties(tick_fp)
plt.tight_layout()
plt.show()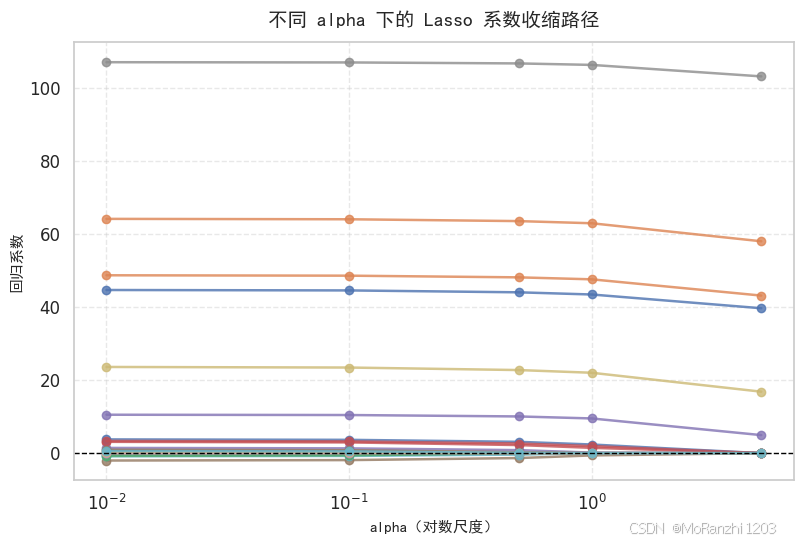
这张图更接近 Lasso 的核心机制。随着 alpha 增大,正则化不断增强,各特征系数会持续向 0 收缩。较小的 alpha 会保留更多特征,使模型更接近普通线性回归;较大的 alpha 会产生更稀疏的解,使模型更加简洁。这里横轴采用对数尺度,并单独优化了刻度字体,可以更清晰地展示不同数量级下 alpha 的变化。
8. 不同 alpha 下的非零系数数量变化
如果希望从数量角度进一步观察稀疏化过程,也可以统计不同 alpha 下非零系数的数量。
python
non_zero_counts = [np.sum(c != 0) for c in coef_matrix]
plt.figure(figsize=(7.5, 5.2))
ax = sns.lineplot(
x=alphas,
y=non_zero_counts,
marker="o",
linewidth=2.2,
markersize=7
)
ax.set_xscale("log")
ax.set_title("不同 alpha 下的非零系数数量变化", fontsize=14, pad=12)
ax.set_xlabel("alpha(对数尺度)", fontsize=11)
ax.set_ylabel("非零系数数量", fontsize=11)
ax.grid(True, linestyle="--", alpha=0.45)
for x, y in zip(alphas, non_zero_counts):
ax.text(x, y + 0.2, str(y), ha="center", va="bottom", fontsize=10)
for label in ax.get_xticklabels():
label.set_fontproperties(tick_fp)
for label in ax.get_yticklabels():
label.set_fontproperties(tick_fp)
plt.tight_layout()
plt.show()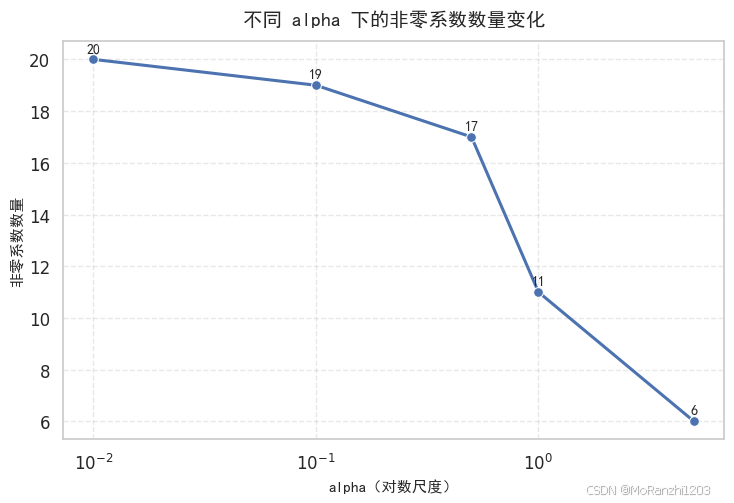
从这张图中可以更清晰地看出:随着 alpha 增大,模型会逐步变得更加稀疏。这也是 Lasso 能够完成特征选择的直接体现。相比系数路径图,这种表达方式更直观,也更便于快速理解正则化强度与特征数量之间的关系。
9. 使用 LassoCV 自动选择 alpha
在实际项目中,手动试探 alpha 往往比较繁琐,而且不同数据集对应的最佳正则化强度差异较大。为此,scikit-learn 提供了 LassoCV ,可以通过交叉验证自动选择最优的 alpha。
python
from sklearn.linear_model import LassoCV
model_cv = make_pipeline(
StandardScaler(),
LassoCV(cv=5, max_iter=5000, random_state=42)
)
model_cv.fit(X_train, y_train)
lasso_cv = model_cv.named_steps["lassocv"]
print("最优 alpha:", lasso_cv.alpha_)
print("非零系数个数:", np.sum(lasso_cv.coef_ != 0))最优 alpha: 0.6826617663085435
非零系数个数: 14
这种方式在实际建模中更常见,因为它能够通过交叉验证在不同参数之间进行比较,从而自动找到一个在泛化性能与模型稀疏性之间更平衡的解。
10. 可视化分析:LassoCV 交叉验证误差曲线
如果希望进一步展示 LassoCV 的选参过程,可以绘制交叉验证误差曲线。
python
mse_path_mean = lasso_cv.mse_path_.mean(axis=1)
alphas_cv = lasso_cv.alphas_
plt.figure(figsize=(7.8, 5.2))
ax = sns.lineplot(
x=alphas_cv,
y=mse_path_mean,
marker="o",
linewidth=2.2,
markersize=6
)
ax.set_xscale("log")
ax.axvline(
lasso_cv.alpha_,
linestyle="--",
linewidth=1.5,
label=f"最优 alpha = {lasso_cv.alpha_:.4g}"
)
ax.set_title("LassoCV交叉验证误差曲线", fontsize=14, pad=12)
ax.set_xlabel("alpha(对数尺度)", fontsize=11)
ax.set_ylabel("平均MSE", fontsize=11)
ax.grid(True, linestyle="--", alpha=0.45)
ax.legend(frameon=True, fontsize=10)
for label in ax.get_xticklabels():
label.set_fontproperties(tick_fp)
for label in ax.get_yticklabels():
label.set_fontproperties(tick_fp)
plt.tight_layout()
plt.show()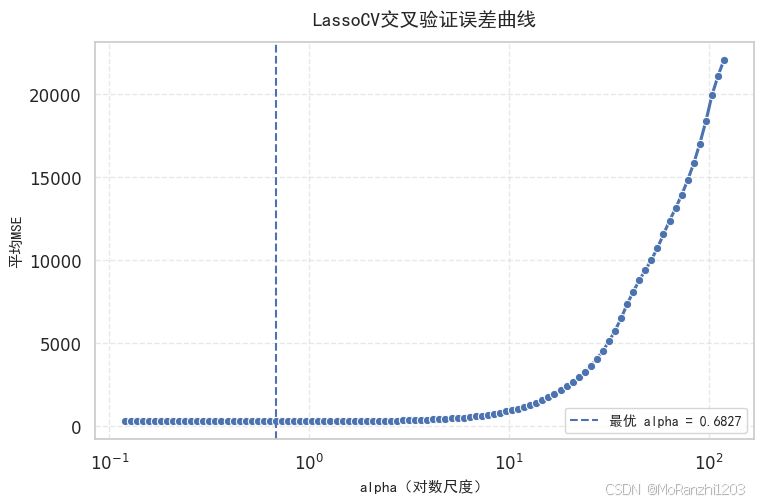
通过这张图,读者不仅能够看到最优 alpha 的数值,还能直观看到它是如何通过交叉验证被选出来的。对于需要稳定结果的实验或项目,LassoCV 往往比手动调参更高效,也更可靠。
11. Lasso 的特点、适用场景与局限
Lasso 与 Ridge 都属于正则化线性模型,但两者的作用机制并不相同。Ridge 使用 L2 正则化,它会让所有系数整体缩小,却通常不会将系数直接压缩为 0;Lasso 使用 L1 正则化,它既能够压缩系数,也能够将部分系数彻底消除。因此,Ridge 更偏向于"保留全部特征,但减弱它们的影响",而 Lasso 更偏向于"直接筛除一部分特征,使模型更稀疏"。
这也决定了 Lasso 的核心优势。对于高维数据或解释性要求较强的任务,Lasso 往往更有价值。通过将不重要特征的系数压缩为 0,模型不仅更加简洁,也更容易分析哪些变量真正发挥了作用。同时,正则化项的加入还能在一定程度上缓解过拟合,使模型在测试集上具备更好的泛化能力。
不过,Lasso 并非在所有场景下都占优。首先,它对特征缩放较为敏感,因此通常需要先进行标准化处理。其次,当多个特征高度相关时,Lasso 往往只会从中挑选出一部分,而不会稳定地保留全部相关特征,这会导致结果在某些数据集上不够稳定。此外,alpha 的设置会显著影响模型表现:正则化过强时容易欠拟合,正则化过弱时又难以体现特征选择优势。
因此,在实际任务中可以这样理解:如果重点在于降低过拟合并保持模型稳定性,Ridge 往往是更稳妥的选择;如果除了预测结果之外,还希望自动完成特征选择,那么 Lasso 通常更合适;如果数据中存在较强的特征相关性,同时又希望兼顾稀疏性和稳定性,则可以进一步考虑 Elastic Net。
12. 总结
Lasso 是 scikit-learn 中非常经典的线性回归算法。它通过引入 L1 正则化项 ,在控制模型复杂度的同时,将部分特征系数压缩为 0,从而实现 回归预测 与 特征选择 的统一。相较于普通线性回归,Lasso 得到的模型通常更加稀疏,解释性也更强,因此在高维数据分析、变量筛选和可解释建模任务中具有很高的实用价值。
总体来看,Lasso 特别适合那些既希望获得预测结果,又希望回答"哪些变量真正重要"这一问题的场景。在实际使用中,通常建议先对特征进行标准化,并优先结合 LassoCV 自动选择合适的正则化参数。若数据中存在较强的特征相关性,或者任务更强调模型稳定性,则可以进一步考虑 Ridge 或 Elastic Net。通过这些方法的配合使用,可以更有针对性地完成不同类型的回归建模任务。