零、前置专有名词
Class-Incremental Learning (CIL, 类增量学习)
- 定义:机器学习的一种设定。模型需要在不同时间段依次学习不同的新类别(例如:先学猫和狗,再学鸟和鱼),同时必须记住之前学过的旧类别。
- 核心难点 :灾难性遗忘------模型在学习新知识时,往往会把旧知识忘得一干二净。
Pre-trained Model (预训练模型)
- 定义:指在大规模数据集(如ImageNet)上预先训练好的模型(如ViT, ResNet等)。
- 作用 :作为"底座",提供强大的特征提取能力。在增量学习中,通常为了节省计算资源和防止遗忘,会冻结(不更新)这些主干网络的参数。
Adapter (适配器)
- 定义 :一种参数高效微调技术。它是在预训练模型的层与层之间插入的极小的神经网络模块。
- 优势:训练时只需更新这些极小的模块,而不需要动庞大的预训练模型,既省显存又能针对新任务进行定制。
Task-Specific Adapter (任务特定适配器)
- 解释:专门为某一个特定任务(比如"识别动物"这个任务)训练的适配器。它像是一个"专科医生",只懂这一类知识。
Universal Adapter (通用适配器)
- 解释:这是本文提出的创新点。它将所有任务的知识融合在一起,形成一个"全科医生",掌握所有任务共有的、通用的特征,帮助模型在遇到模糊情况时也能做出正确判断。
Entropy-based Selection (基于熵的选择)
- 解释:一种决策机制。"熵"在信息论中代表不确定性。
- 原理:模型在推理时,会计算各个适配器输出的"熵"。熵越低,说明适配器对当前图片的判断越自信(越确定)。系统会选择那个"最自信"的适配器来处理这张图片。
Adapter Fusion (适配器融合)
- 解释:一种将多个已经训练好的适配器参数合并成一个适配器的技术。本文利用它来从多个"专科医生"(任务适配器)中提取共性,生成"全科医生"(通用适配器)。
Catastrophic Forgetting (灾难性遗忘)
- 通俗解释:就像你学会了骑自行车,结果一学游泳,就把骑车给忘了。这是神经网络的一个老毛病,学新东西时把旧东西覆盖掉了。
- 文中语境:这是 CIL 要解决的核心大 BOSS。
Pre-trained Models (PTMs, 预训练模型)
- 通俗解释:就是那种已经在大数据集(比如整个互联网的图片)上"读过书"、受过训练的"学霸"模型。
- 作用:因为它们底子好、见识广,所以哪怕只给它看一点点新数据,它也能很快学会,而且不容易忘本。
Visual Prompt Tuning (视觉提示微调)
- 通俗解释:这原本是自然语言处理(NLP)里的概念(比如在句子前加几个词引导 AI)。在视觉里,就是不给图片改像素,而是在模型里加几个可学习的"提示向量"(Prompt),告诉模型"注意看这里"。
- 文中语境:这是目前很流行的一类方法,但作者觉得它选提示的时候容易选错(靠 Key-Query 匹配不太靠谱)。
Task-Specific vs. Universal (任务特定 vs. 通用)
- Task-Specific:专才。比如专门认车的,专门认鸟的。
- Universal:通才。既懂车又懂鸟,还能看出它们都是"物体"的共同点。
- 文中语境:以前的方法只顾着培养专才,忽略了通才的作用,导致遇到长得像的"跨界"东西(比如不同任务里的相似动物)就懵了。
Distribution Shifts (分布偏移)
- 通俗解释:训练时的数据和实际用的数据长得不一样。比如你拿白天的照片训练模型,结果晚上拿去用,效果就不好了,因为光线变了,这就是分布偏移。
- 文中语境:在这种情况下,旧的"键-查询"匹配机制更容易失效。
Data Rehearsal (数据排练/回放)
- 通俗解释:这就是"温故知新"。为了防止学了新的忘了旧的,模型会存一部分旧数据的照片(叫 Exemplars),每次学新课的时候,把旧照片拿出来复习一遍。
- 缺点:需要存数据,占内存,有时候还涉及隐私问题。
Knowledge Distillation (知识蒸馏)
- 通俗解释:把旧模型当成"老师",新模型当成"学生"。学生在学习新知识时,老师会在旁边盯着说:"哎,这道旧题你以前是这么做的,现在也得这么做,别跑偏了。"
- 核心:强迫新模型的输出尽量模仿旧模型在旧数据上的表现。
Inductive Bias (归纳偏差)
- 通俗解释:模型的一种"先入为主"的倾向。比如模型看多了猫,可能就会觉得"有毛茸茸耳朵的就是猫"。在增量学习中,这种偏见会导致模型对新来的类别不公平,或者对旧的类别判断失误。
- 文中语境:基于模型校正的方法就是要纠正这种偏见,让预测更客观。
Parameter Regularization (参数正则化)
- 通俗解释:给模型参数戴上"镣铐"。对于旧任务特别重要的参数,不让它们随便变动。如果新任务非要改这些参数,就罚它(加惩罚项)。
- 代表算法:像 EWC 就是这类的经典。
基于预训练模型的新兴方法
Parameter-Efficient Fine-Tuning (PEFT, 参数高效微调)
- 通俗解释:预训练模型太大了,全量微调太贵且容易忘。PEFT 就是把大模型冻住不动,只训练插在里面的几个小零件(比如 Adapter 或 Prompt)。
- 优势:省钱、省显存、还能利用大模型的强大能力。
Prompt Pool (提示池)
通俗解释:这是一个"工具箱"。L2P 方法准备了很多不同的"提示"(Prompt),遇到新图片时,先去池子里捞几个最合适的提示出来用。
Random Projection (随机投影)
- 通俗解释:RanPAC 用的招数。简单说就是把数据扔到一个高维的随机空间里去。
- 作用:在这个高维空间里,原本纠缠不清的数据可能会变得更容易分开(线性可分),这样分类器就更好做了。
Logits
通俗解释:神经网络最后一层输出的原始数值,还没经过 Softmax 变成概率的那个数。它代表了模型对某个类别的"信心打分"。
无样本设置( Exemplar-free Setting**)**
- 在持续学习过程中,当模型开始学习新任务时,旧任务的数据不可用(既不存储也不回放)。这是比"回放法"更具挑战性的设定。
经验风险( Empirical Risk**)**
- 在统计学习理论中,指模型在训练数据上的平均损失。最小化经验风险是机器学习模型训练的基本目标。
假设空间( Hypothesis Space**)**
- 学习算法在解决问题时所能选择的所有可能模型(或函数)的集合。
视觉变换器(VIT)
- 一种基于 Transformer 架构的深度学习模型,专门用于处理图像数据,将图像分割成序列块进行处理。
特征提取器(Feature Extractor)
- 神经网络中负责从原始输入数据(如图片)中提取高级抽象特征的部分,通常位于网络的底层和中间层。
分类器(Classifier)
- 神经网络的最后一部分,通常是一个线性层,负责接收特征并输出具体的类别预测结果。
参数高效微调( Parameter-Efficient Fine-Tuning (PEFT))
- 一类技术,旨在通过只训练模型中极少量的参数(如偏置项或新增的适配器),来适应新任务,从而大幅降低计算成本并防止遗忘。
提示池( Prompt Pool**)**
- 在提示学习中,预先定义的一组可学习的向量集合。模型在推理时会根据输入从中挑选最合适的提示来辅助任务。
查询-键匹配机制( Query-Key Matching Mechanism**)**
- 一种检索机制。输入数据生成一个"查询",与池中每个提示对应的"键"计算相似度,从而选出最相关的提示。
余弦距离( Cosine Distance**)**
- 用于衡量两个向量在方向上差异的指标。在这里用于计算查询向量和键向量之间的相似度。
正交约束( Orthogonal Constraint**)**
- 一种数学约束,要求两个向量相互垂直,在机器学习中常用于去相关性。
符号匹配( Sign Matching**)**
- 一种模型融合技术,通过比较参数符号的一致性来合并模型。
预测熵( Predictive Entropy**)**
- 信息论概念,用于衡量概率分布的不确定性,熵越低表示模型越自信。
集成学习( Ensemble Learning**)**
- 通过构建并结合多个学习器来完成学习任务,通常比单一学习器效果更好。
一、摘要
类增量学习(CIL)要求学习系统在不遗忘旧知识的前提下,持续不断地学习新类别。现有的基于预训练模型的 CIL 方法通常会冻结预训练网络,并使用适配器(Adapters)等额外的轻量级模块来适应增量任务。
然而,这些方法存在两个主要问题:
- 推理过程中的模块选择错误会损害模型性能;
- 仅针对特定任务的模块往往忽视了共享的通用知识,导致在区分跨任务的相似类别时容易出错。
为了解决上述挑战,本文提出了**集成任务特定适配器与通用适配器(TUNA)**的方法。具体而言:
- 我们训练任务特定适配器 以捕捉各自任务中最关键的特征,并引入一种基于熵的选择机制来挑选最合适的适配器。
- 此外,我们利用适配器融合策略 构建一个通用适配器,用于编码跨任务共享的最具判别力的特征。
- 在推理阶段,我们结合任务特定适配器和通用适配器的预测结果,从而同时利用专业化知识和通用知识。
在多个基准数据集上的广泛实验证明了该方法的最先进(SOTA)性能。
代码仓库
二、引言
背景与挑战
深度学习虽已广泛应用,但现实世界的数据是持续流动的。这就要求模型具备类增量学习(CIL) 的能力,即在不断学习新类别的同时,不能忘记旧知识。然而,这面临着灾难性遗忘 的巨大挑战。为了解决这个问题,学术界开始利用在大数据上训练好的预训练模型(PTMs),因为它们本身就具备强大的泛化能力,不容易"忘本"。
️ 现有方法的不足
目前的主流做法是冻结预训练模型的主体,只通过添加轻量级的视觉提示(Visual Prompt) 来适应新任务。但这存在两个明显缺陷:
-
选择机制脆弱 :推理时依赖"键-查询"匹配来选择对应的提示模块。一旦匹配错误(比如在任务模糊或数据分布变化时),性能就会大幅下降。
-
忽视通用知识:过于关注每个任务的"个性"(特定知识),忽略了不同任务之间的"共性"(通用知识)。这导致模型在区分跨任务的相似类别时容易出错。
TUNA 的解决方案
为了克服上述问题,作者提出了 TUNA 方法,核心思想是将"专才"与"通才"结合:
-
双组件设计 :将学习过程分解为两部分------提取任务独有特征的任务特定适配器 ,和整合跨任务共享知识的通用适配器 。
-
改进选择机制 :不再使用脆弱的键值匹配,而是引入基于熵的选择策略 。简单来说,就是看哪个适配器对当前输入的预测最确定(熵最低),就选谁来处理。
-
知识融合:利用适配器融合技术,将所有"专才"的知识合并成一个"通才",既保留了共性,又减少了冗余。
最终,在推理阶段,TUNA 会协同使用这两个组件,从而在多个基准数据集上取得了最先进的性能。
三、相关方法
传统类增量学习 (CIL) 方法
这部分主要盘点了解决"灾难性遗忘"问题的几种经典思路:
- 基于数据排练的方法:核心是"温故知新"。通过保存一部分旧类别的样本,在学习新类别时拿出来复习,以巩固旧记忆。
- 基于知识蒸馏的方法:把旧模型当作"老师",让它指导新模型的学习,确保新模型在处理旧任务时的表现与老模型保持一致。
- 基于模型校正的方法:旨在修正模型在增量更新过程中产生的预测偏差,确保对所有类别(无论新旧)的公平性。
- 基于参数正则化的方法:给模型的关键参数戴上"镣铐",限制它们在适应新任务时发生剧烈变化,从而保护已学到的旧知识。
- 可扩展网络:一种更直接的方法,为每个新任务开辟新的网络分支,保留旧任务的完整网络,最后将所有分支的特征合并起来进行判断。
基于预训练模型 (PTM) 的 CIL 方法
这是当前的研究热点,其核心思想是利用强大的预训练模型作为基础,并通过参数高效微调 (PEFT) 技术来适应新任务,避免了对庞大模型的全面修改。主要流派包括:
- 提示学习 (Prompt-based):这是主流方向。代表工作如 L2P、DualPrompt、CODA-Prompt 等,它们不改动预训练模型的主体,而是通过学习一系列可插入的"提示"(Prompts)来引导模型处理不同任务。DAP 则更进一步,直接生成针对特定样本的提示。
- 其他创新路径 :
- SLCA:通过对特征分布建模并重放,来校准分类器。
- APER:融合了原始预训练模型和微调后模型的特征来构建更强的分类器。
- EASE:类似于可扩展网络,拼接多个任务主干的特征来增强能力。
- RanPAC:利用随机投影技术,在高维空间中构建鲁棒的特征来进行学习。
四、前言
这一部分作为论文的"预备知识",其实是在完成一个"先立后破"的过程:先定义游戏规则,再把当前主流方法(靶子)立起来,最后指出其缺陷,从而引出你自己的新方法。
以下是分层级的深度总结:
核心任务设定
这部分定义了本文要解决的"战场"环境:
- 任务类型 :类增量学习 ,且严格遵循无样本设置 。
- 这意味着: 模型不仅要面对源源不断的新类别,而且一旦学完旧类别,旧数据就会被销毁,无法回头查看。
- 数学目标:学习一个函数 f(x),使其在所有见过的类别上都能保持最低的预测错误率(最小化经验风险)。
模型架构视角
为了在预训练模型(PTM)的基础上进行增量学习,作者采用了组件化视角:
- 冻结主干 :将预训练模型视为一个固定的特征提取器 ϕ(⋅)。
- 适配头部 :在其之上添加或调整分类器 W 。
- 意义: 这种视角将复杂的深度学习问题简化为如何在固定特征空间中设计更好的分类边界或提示机制。
现有主流方法分析
作者重点剖析了当前最流行的基于提示学习的方法(如 L2P):
- 核心机制 :查询-键匹配 。
- 模型维护一个"提示池"。
- 推理时,根据输入图像的特征(查询),去池子里找最匹配的提示(键)。
- 优化目标:通过最小化交叉熵损失和正则化项来训练这些提示。
现有方法的致命缺陷
这是本段最关键的部分,作者指出了现有方法"为什么不行",为提出自己的方法铺路:
- 缺陷一:推理极其脆弱 。
- 严重依赖"匹配"的准确性。一旦输入数据具有迷惑性导致匹配错误,整个模型的预测就会崩盘。
- 缺陷二:知识孤岛效应 。
- 过于强调"任务特定知识"(即每个任务各学各的),忽略了"任务间共享知识"。
- 后果: 无法有效区分跨任务的相似类别(例如:任务1里的狗和任务2里的猫,如果长得像,模型容易混淆)。
一句话总结:
这段内容首先确立了无样本类增量学习 的严峻挑战,然后指出当前主流的基于提示匹配 的方法虽然流行,但因匹配机制脆弱 且缺乏跨任务知识共享,导致在处理相似类别时表现不佳,从而论证了提出新方法的必要性。
五、方法
核心组件:特定任务适配器
对应章节:4.1 Learning Orthogonal Task-Specific Adapters
设计思路:
模型不直接修改庞大的预训练模型主干,而是为每一个新来的任务训练一个轻量级的"插件",即适配器。
具体实现:
- 结构: 适配器是一个"瓶颈结构",插入到预训练模型的每个 Transformer 块的 MLP 层中。它包含一个降维层和一个升维层。
- 正交约束: 这是关键创新点。为了防止新任务的适配器与旧任务的适配器"长得太像"而导致混淆,作者引入了一个正交损失函数。它强制要求当前任务的适配器参数(主要是升维层权重)与之前所有任务的适配器参数保持正交(即互不相关)。
- 目的: 确保每个适配器都学到该任务独一无二的特征,减少冗余和干扰。
知识融合:通用适配器
对应章节:4.2 Multi-Stage Adapter Fusion
设计思路:
只有特定任务适配器是不够的,因为它们太"专一",缺乏跨任务的通用知识(比如不同任务里都有"轮子"这个概念)。因此,模型需要把所有特定任务适配器的知识"提炼"出来,合成一个通用适配器。
具体实现(基于符号匹配):
- 展平: 把所有训练好的适配器权重展平成向量。
- 符号投票: 计算所有适配器权重的符号(正或负)。如果大多数适配器在某个参数位置上都是正的,那么通用适配器在该位置也是正的。这代表了跨任务的共识。
- 幅值选择: 在确定了符号后,选择那些符合该符号的适配器中,绝对值最大的那个数值。这保留了最强的特征响应。
- 目的: 创建一个能够捕捉所有任务共享特征的通用模型,作为背景知识。
推理策略:基于熵的选择
对应章节:4.3 Adapter Selection via Prediction Uncertainty
设计思路:
当模型面对一张新图片时,它不知道该用哪个"特定任务适配器"来处理。模型通过计算预测熵来解决这个问题。
具体实现:
- 熵作为指标: 模型会尝试用所有的特定任务适配器去预测这张图。
- 选择逻辑: 哪个适配器给出的预测结果熵最低(即最自信、概率分布最尖锐),就认为这张图属于那个适配器对应的任务。
- 目的: 自动识别输入图像所属的任务域,从而调用最合适的专家(适配器)。
最终预测:双重集成
对应章节:4.4 Task-Specific and Universal Model Ensemble
设计思路:
仅仅用"特定任务适配器"容易忽略通用特征,仅仅用"通用适配器"又不够精细。TUNA 采用集成学习的策略。
具体实现:
- 公式: 最终预测 = 选出的最佳特定任务适配器 + 通用适配器。
- 逻辑: 在推理阶段,模型同时利用"专家知识"(选出的特定适配器)和"通识知识"(通用适配器)来共同决定分类结果。
- 目的: 兼顾判别性 和鲁棒性,既利用了特定任务的细节,又利用了跨任务的共享特征,从而在区分相似类别时表现更好。
总结:TUNA 模型的工作流
这张图(Figure 1)完整展示了 TUNA 模型 从训练到推理的全生命周期。它被清晰地划分为三个阶段:训练阶段 、融合阶段 和 推理阶段。
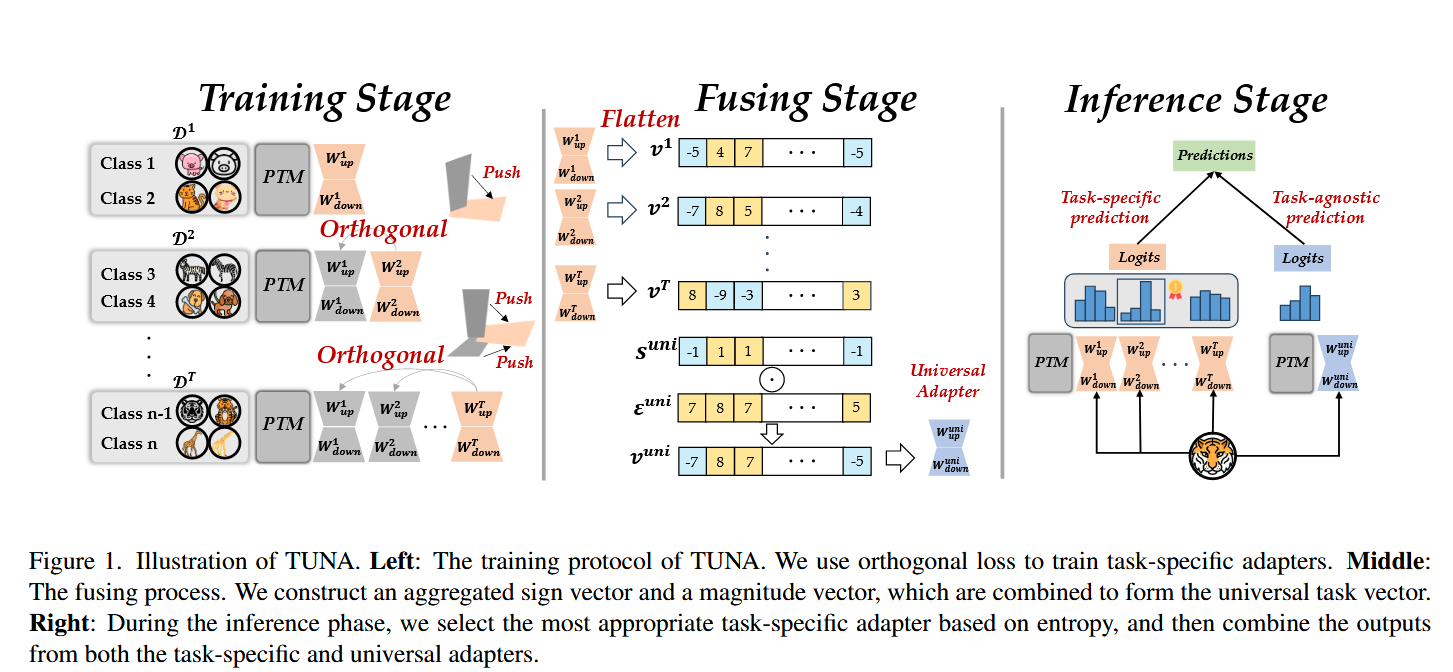
第一阶段:训练阶段
- 训练阶段: 来一个新任务 -> 训练一个正交的特定适配器 -> 训练完所有任务后 -> 把所有适配器融合成一个通用适配器。

第二阶段:融合阶段

第三阶段:推理阶段
- 推理阶段: 来一张图 -> 算一下哪个特定适配器最自信 -> 选出该适配器 -> 与通用适配器结合 -> 输出最终结果。

总结
这个架构的精妙之处在于 "分而治之,合而用之":
- 训练时(分) :用 正交约束 强制模型把不同任务的知识隔离开,防止打架。
- 融合时(合) :用 符号匹配 把所有任务的知识提纯,得到一个包含共性知识的"底座"。
- 推理时(用) :用 熵 快速判断"这是谁的主场",同时结合"底座"的常识,做出最准确的判断。
六、实验
这部分主要交代了实验是在什么环境下跑的,用了什么数据,以及跟谁在比。
数据集
作者选择了四个非常有代表性的数据集,涵盖了不同的难度和场景:
- CIFAR100:经典的入门级数据集,包含100个类别。
- ImageNet-R:包含ImageNet中物体的"艺术化"版本(如素描、玩具),测试模型的泛化能力。
- ImageNet-A:包含ImageNet中模型最难识别的自然对抗样本,测试模型的鲁棒性。
- ObjectNet:物体拍摄角度非常刁钻的数据集,测试域偏移下的性能。
- 设定:使用"B-m Inc-n"的格式。例如"B0 Inc20"意味着从0个基类开始,每次增量增加20个类。
对比方法
作者将TUNA与三类最先进的方法进行了对比:
- 基于提示的方法:如L2P, DualPrompt(通过调整提示词来适应新任务)。
- 全模型微调方法:如SLCA(调整整个模型参数)。
- 基于适配器的方法:如SSiAT, MOS(和TUNA类似,但在设计上不同)。
- 基于回放的方法:如iCaRL, DER(这些方法会存储旧数据的图片来防止遗忘,通常效果很好但有存储成本)。
实现细节
- 主干网络:主要使用ViT-B/16(视觉Transformer)。
- 训练参数:使用SGD优化器,学习率余弦退火,投影维度 r=16r=16 。
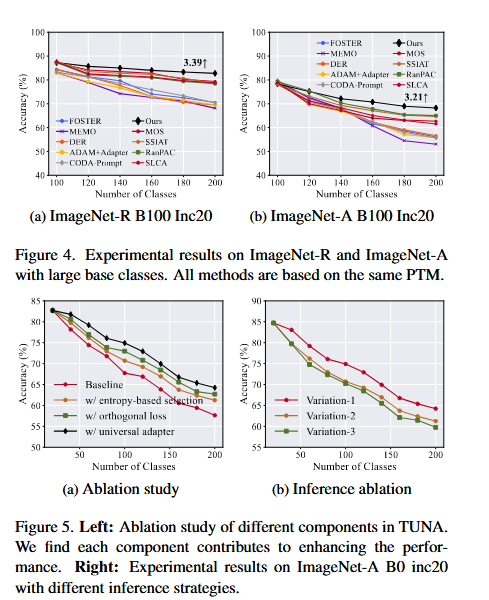
消融实验详解
这部分是为了证明 TUNA 模型的每一个组件都是不可或缺的。作者通过"控制变量法"来做实验。
组件贡献分析
- 实验设置:在 ImageNet-A B0 Inc20 设置下进行。
- 对比配置 :
- Baseline:仅训练特定任务的适配器,预测时使用所有适配器并取最大logit。
- w/ entropy-based adapter selection:使用基于熵的选择策略来选择适配器。
- w/ orthogonality loss:引入正交损失来增强特定任务的知识学习。
- w/ universal adapter:集成一个通用适配器的输出。
- 结果 :
- Baseline 性能最差。
- w/ entropy-based adapter selection 性能有所提升,证明了选择策略的有效性。
- w/ orthogonality loss 性能进一步提升,证明了正交约束的重要性。
- w/ universal adapter 性能最好,证明了通用适配器能够捕捉跨任务的共享知识。
推理策略分析
- 实验设置:在 ImageNet-A B0 Inc20 设置下进行。
- 对比策略 :
- Variation-1:TUNA 的推理策略。
- Variation-2:仅基于熵选择特定任务的适配器。
- Variation-3:仅依赖通用适配器。
- 结果 :
- Variation-1 性能最好,证明了 TUNA 的推理策略能够充分利用特定任务和通用适配器的优势。
- Variation-2 性能较差,因为无法利用跨任务的共享知识。
- Variation-3 性能最差,因为缺乏特定任务的细粒度信息。
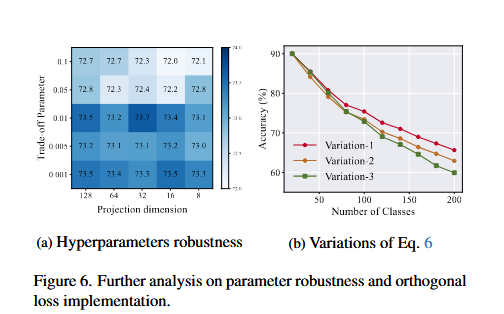
超参数鲁棒性分析
- 实验设置:在 ImageNet-A B0 Inc20 设置下进行。
- 对比参数 :
- 投影维度 r:在 {8, 16, 32, 64, 128} 中选择。
- 权衡参数 λ:在 {0.001, 0.005, 0.01, 0.05, 0.1} 中选择。
- 结果 :
- TUNA 的性能在不同的超参数设置下都保持稳定,证明了其鲁棒性。
正交损失变体分析
- 实验设置:在 ObjectNet B0 Inc20 设置下进行。
- 对比变体 :
- Variation-1:仅对当前适配器的上投影权重施加正交约束。
- Variation-2:仅对当前适配器的下投影权重施加正交约束。
- Variation-3:同时对上投影和下投影权重施加正交约束。
- 结果 :
- Variation-1 性能最好,证明了对上投影权重施加正交约束是最有效的。
- Variation-2 性能较差,因为下投影权重主要负责投影输入特征,施加正交约束可能会阻碍模型学习任务特定信息。
- Variation-3 性能最差,因为同时对上投影和下投影权重施加正交约束可能会引入过多的刚性,降低模型的灵活性。
实验图表分析
表一
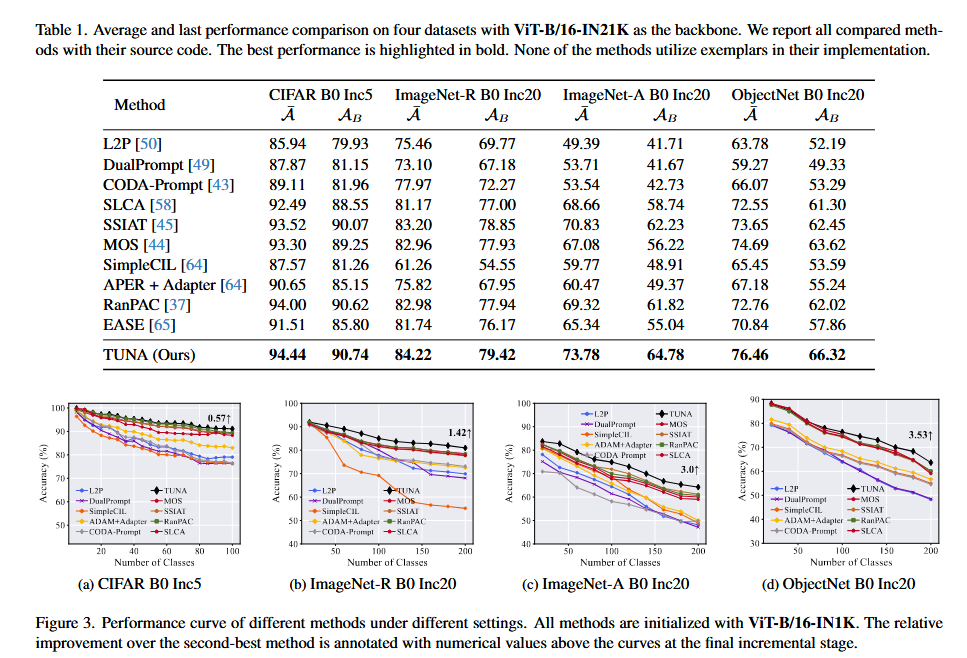

图三

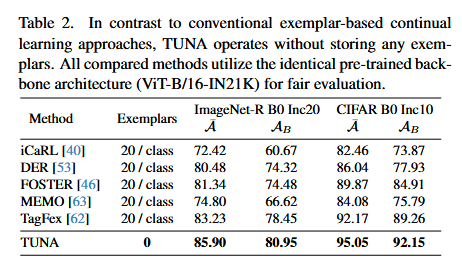
表二

图四和图五


 图六
图六

 无序列表
无序列表
图七


总结
通过这一系列的实验,作者不仅证明了 TUNA 模型的有效性,还深入分析了每个组件的作用和模型的鲁棒性。这些实验结果为 TUNA 模型的优势提供了有力的证据。
七、结论
该段落是论文的结论部分,主要内容包括:
- 提出方法 :作者提出了名为 TUNA 的新方法,结合了"任务特定适配器"和"通用适配器",用于解决类增量学习(CIL)问题。
- 核心机制 :
- 训练特定适配器来捕捉独特特征。
- 通过融合机制创建通用适配器以保留共享知识。
- 推理时使用基于熵的选择策略来组合两者的预测。
- 实验结论:实验证明了该方法的有效性。
- 不足与展望:目前的缺点是推理速度较慢(因为需要多次前向传播来选择适配器),未来的目标是优化算法速度。