🧑 博主简介 :CSDN博客专家 ,「历代文学网」 (PC端可以访问:https://lidaiwenxue.com/#/?__c=1000,移动端可关注公众号 " 心海云图 " 微信小程序搜索"历代文学 ")总架构师,首席架构师,也是联合创始人!
16年工作经验,精通Java编程,高并发设计,分布式系统架构设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探索科技的边界,并将理论知识转化为实际应用。保持对新技术的好奇心,乐于分享所学,希望通过我的实践经历和见解,启发他人的创新思维。在这里,我希望能与志同道合的朋友交流探讨,共同进步,一起在技术的世界里不断学习成长。🤝商务合作 :请搜索或扫码关注微信公众号 "
心海云图"


Elasticsearch 集群、Kibana和IK分词器:最新版 9.3.2 手动安装教程
1. 前言
Elasticsearch 9.3.2 于 2026 年 3 月正式发布,作为 Elastic Stack 家族的最新成员,带来了多项性能改进与功能增强。然而,对于需要精细掌控服务器环境的运维人员而言,官方提供的包管理器安装方式往往无法满足生产环境的手动部署需求。尤其在集群模式下,节点间的通信配置、安全认证启用,以及中文搜索必须的 IK 分词器版本匹配与手动安装,均是实践中常见的痛点。
本文将手把手带你完成 Elasticsearch 9.3.2 集群 + Kibana 可视化面板 + IK 中文分词器 的全流程手动安装与配置。从环境准备、集群节点配置到插件部署,每一步均提供详尽的命令与配置文件示例,助你从零构建一套完整、稳定且支持中文搜索的日志与搜索基础架构。
1.1 Elasticsearch 简介

Elasticsearch是一个基于JSON的分布式搜索和分析引擎 ,它提供了一个分布式 、多租户能力的全文搜索引擎,具有HTTP网络接口和无模式的数据索引,不依赖于任何特定的数据库结构。
Elasticsearch的设计目标之一就是它的可扩展性 ,它被设计为能够处理大规模数据集 。此外,它还提供了近实时的搜索和分析能力 ,支持结构化 和非结构化 数据的存储 、索引 和搜索 。Elasticsearch的分布式特性使其部署能够随着数据和查询量的增长而无缝扩展。
1.2 Kibana 简介

Kibana则是一个开源的数据分析和可视化平台,作为Elastic Stack的一部分,它主要用于对Elasticsearch中的数据进行搜索 、查看 、交互操作。
Kibana提供了丰富的数据可视化选项,如柱状图 、线图 、饼图 、地图 等,帮助用户以图形化的方式理解数据。它还提供了强大的数据探索 功能,允许用户使用Elasticsearch的查询语言进行数据查询,并通过Kibana的界面进行数据筛选和排序。
此外,Kibana还集成了Elasticsearch的机器学习 功能,可以用于异常检测、预测等任务。Kibana的定制和扩展性通过丰富的API和插件系统进一步增强了其功能,使用户能够根据自己的需求定制和扩展Kibana。
1.3 Elasticsearch 和 Kibana 配合使用场景

Elasticsearch 和 Kibana 是经常被用于以下几种场景:
- 日志管理 :
Elasticsearch用于存储日志,Kibana用于查询 和可视化日志。 - 应用监控 :同样,
Elasticsearch存储监控数据,Kibana用于分析 和展示。 - 实时应用搜索 :
Elasticsearch可以对大量数据进行快速搜索。 - 数据分析 :
Kibana提供丰富的数据可视化 工具,如图表 、表格 、地图等。
2. Elasticsearch 下载到集群安装
2.1 Elasticsearch最新版 官方下载
Elasticsearch 的官方下载地址:https://www.elastic.co/cn/downloads/elasticsearch
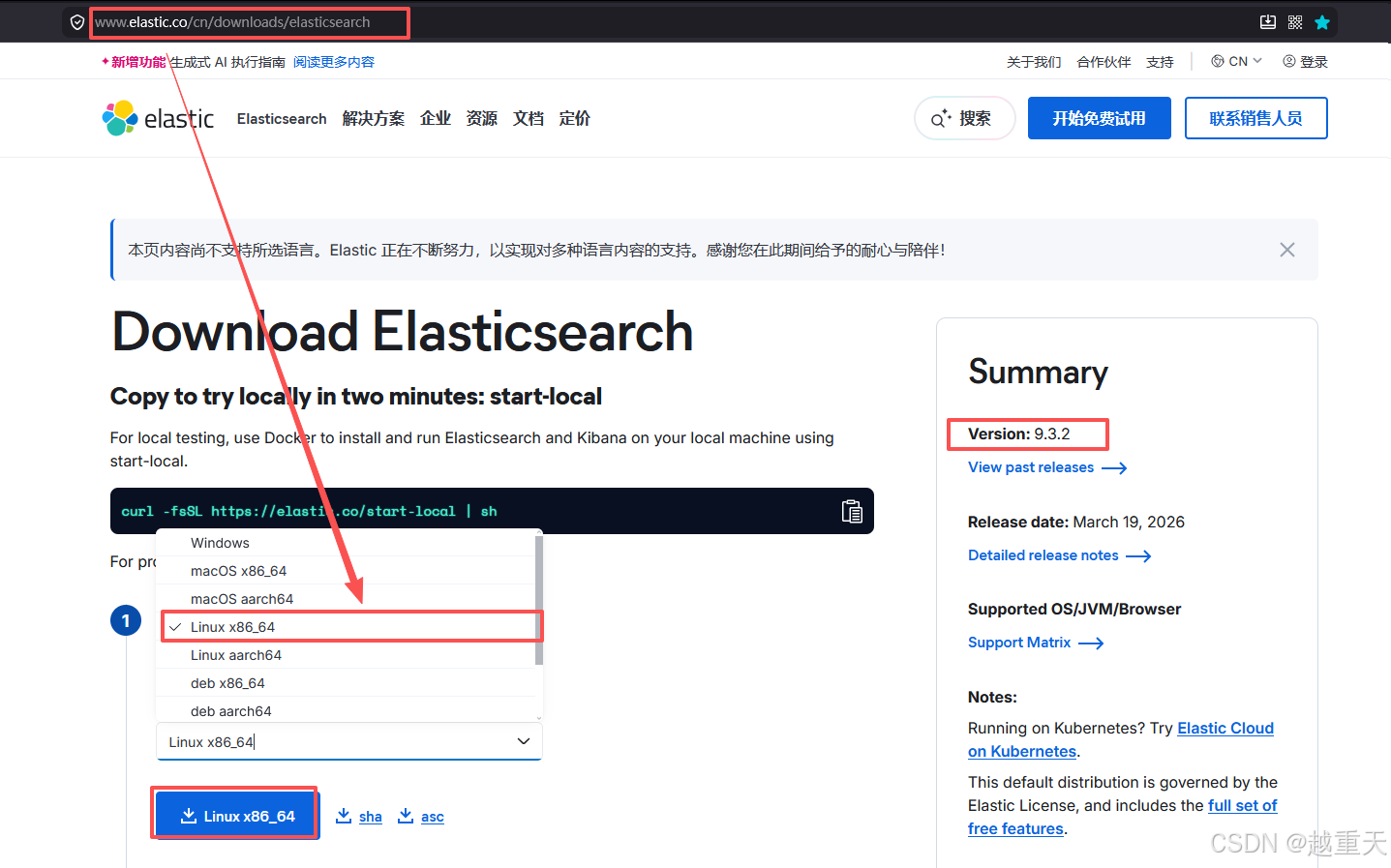
如上图,根据你服务器的架构选择对应的Linux版本,这里选择的是Linux x86_64架构版本。选好后,点下载按钮即 可完成Elasticsearch最新版本的下载。

Elasticsearch 集群的手动部署搭建相对比较麻烦,喜欢的朋友一定要有耐心看完,缺少任何一个细节都会导致启动失败!
2.2 Elasticsearch 节点环境准备
Elasticsearch集群搭建至少需要3个节点 。这是因为Elasticsearch集群的稳定性 和可用性 在很大程度上依赖于节点的数量 和配置 。具体来说,至少需要3个master节点是为了防止脑裂现象的发 生。脑裂是指在分布式系统中,由于网络分区导致多个节点认为自己成为了集群的主节点,从而引发数据不一致和其他问题。通过设置最少可工作的候选主节点个数(即discovery.zen.minimum_master_nodes)为(候选主节点数/2)+1,可以确保在大多数情况下,没有足够的master候选节点进行选举,从而避免脑裂的可能性。此外,至少需要3个节点也是基于集群选举算法 的奇数法则,这是为了保证在集群中任一节点故障时,仍然能够通过多数决策来维持集群的正常运作。
在Elasticsearch集群中,节点可以承担不同的角色,包括master(主节点) 、data(数据节点) 、client(客户端节点)等。主节点负责处理集群的管理任务,如节点发现 、故障检测 等;数据节点则负责数据的存储和处理;客户端节点则处理来自外部的请求。通过合理配置这些节点的角色和数量,可以提高集群的性能 和可用性。例如,为了实现高可用性和容错性,一般建议每个角色使用独立的节点,但在资源有限的情况下,也可以通过配置节点的不同角色(如在一台机器上同时运行master和data节点)来模拟多节点环境,这种做法通常被称为搭建伪集群。
在本教程中,准备了三台ES节点:
es-node-a:172.16.10.50es-node-b:172.16.10.51es-node-c:172.16.10.52
2.3 节点禁用防火墙
请将ES所有节点全部禁用防火墙 ,避免集群节点间出现通信故障 ,以及造成应用程序无法访问的问题,分别执行如下命令:
bash
systemctl stop firewalld
systemctl disable firewalld2.4 创建elasticsearch用户和用户组
Elasticsearch需要单独创建用户 和用户组 主要是出于安全性 和管理的考虑。
首先,Elasticsearch作为一个强大的搜索引擎,能够独立接受用户输入的脚本,因此,为了系统的安全性,需要单独建立一个用户来运行Elasticsearch,以避免潜在的安全风险。使用专门的运行用户可以限制Elasticsearch的访问权限,减少被恶意利用的可能性。
执行以下命令即可完成Elasticsearch用户和用户组的创建:
bash
groupadd -r elasticsearch \
&& useradd -r -g elasticsearch elasticsearch2.5 目录权限设置
假设安装目录是/usr/share/elasticsearch/,Elasticsearch安装目录权限的设置,分为两个场景:
- es应用安装目录 和索引存放目录 部署在同一个根目录下。
用root账户登录,并执行如下命令
bash
# es安装目录权限设置
chown -R elasticsearch /usr/share/elasticsearch
chgrp -R elasticsearch /usr/share/elasticsearch- es应用安装目录 和索引存放目录部署在不同一个根目录下。
bash
# es安装目录权限设置
chown -R elasticsearch /usr/share/elasticsearch
chgrp -R elasticsearch /usr/share/elasticsearch
# es 数据索引目录权限设置
chgrp -R elasticsearch /data
chown -R elasticsearch /data2.6 修改节点句柄数
Elasticsearch 需要大量的文件句柄主要是因为Elasticsearch是一个基于Lucene的搜索引擎,它使用倒排索引 来提供快速的全文搜索功能。在Lucene中,每个文档都被分割成多个段,并且每个段都会被存储在一个单独的文件中。因此,随着索引的增长,Elasticsearch 需要打开和操作的文件数量会急剧增加。此外,Elasticsearch还涉及到大量的并发读写操作,每个操作都需要一个文件句柄。
但是Linux系统默认提供的文件句柄是1024个。
为了解决这个问题,可以通过配置:ml-search`limits.conf`文件来增加文件句柄的数量限制。limits.conf是一个配置文件,用于设置Linux系统中用户和进程的资源限制,包括文件描述符的数量。
将如下配置添加到/etc/security/limits.conf末尾即可:
bash
elasticsearch - nofile 655350添加好后,如下图所示:

2.7 提升vm.max_map_count配置
Elasticsearch需要修改vm.max_map_count是因为这个参数限制了一个进程可以拥有的VMA(虚拟内存区域)的数量 ,而Elasticsearch等存储系统使用MMAP(内存映射)技术来提高文件读取效率。如果vm.max_map_count的值设置得太低,可能会导致内存溢出错误,从而影响Elasticsearch的正常运行。因此,为了确保Elasticsearch能够高效运行,需要调整vm.max_map_count的值。
Elasticsearch使用MMAP技术来减少用户态 与内核态 之间的数据拷贝 ,用内存读取取代I/O读取 ,从而提高文件读取效率 。这种技术要求系统能够创建大量的虚拟内存区域 ,因此需要相应的vm.max_map_count值来支持。默认情况下,vm.max_map_count的值可能不足以满足Elasticsearch的需求,因此需要进行调整。
具体来说,部署Elasticsearch时,需要将vm.max_map_count的值调整到至少262144,以确保Elasticsearch能够正确运行。
进入/etc/sysctl.conf文件中,将配置vm.max_map_count=262144添加到文件末端即可:
bash
vm.max_map_count=262144如下图所示:

2.8 关闭 SELinux
如果不关闭SELinux,由于SELinux 开启了安全模式,会导致Elasticsearch通过注册的服务开机启动可能报(code=exited, status=203/EXEC)错误。
临时关闭:
bash
[root@localhost bin]# getenforce #查看selinux状态
Enforcing
[root@localhost bin]# setenforce 0 #临时关闭selinux
[root@localhost bin]# getenforce
Permissive永久关闭:
bash
[root@localhost bin]# vi /etc/selinux/config
SELINUX=enforcing 修改为 SELINUX=disabled
#重启服务器生效2.9 解压安装包到/usr/share/elasticsearch目录下
如果是ES应用 和索引数据 分开部署,建议将ES应用部署到/usr/share/elasticsearch目录下。

2.10 ES配置修改
主要是对JVM内存 以及集群相关的配置进行修改。
- JVM内存修改
直接修改/usr/share/elasticsearch/config/jvm.options配置文件:
yml
-Xms8g
-Xmx8g注意:-Xms和-Xmx必须设置成一样,否则集群启动会报错。因为ES要考虑性能,设置成一样,是为了避免JVM内存频繁伸缩,导致不必要的性能开销。
- ES集群配置
直接修改/usr/share/elasticsearch/config/elasticsearch.yml配置文件。
三台节点,除了node.name和network.host不一样,其它配置完全一样!如下代码所示,是节点es-node-a的配置:
yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: sinhy-cloud-es-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: "es-node-a"
# 注意至少有两个具有选举master资格的节点
node.roles: [master, data]
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
#允许连接IP
network.host: 172.16.10.50
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
# 网页访问端口
http.port: 9200
#集群间通信端口号,在同一机器下必须不一样,不同的机器,一般是9300
transport.port: 9300
xpack.security.enabled: false
xpack.security.transport.ssl.enabled: false
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
# 集群成员
discovery.seed_hosts: ["172.16.10.50:9300", "172.16.10.51:9300", "172.16.10.52:9300"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["es-node-a", "es-node-b", "es-node-c"]
http.cors.enabled: true
http.cors.allow-origin: "*"
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Allow wildcard deletion of indices:
#
#action.destructive_requires_name: false2.11 ES节点以服务注册方式启动
这个简单了,三台节点都分别这样操作即可:直接到目录/etc/systemd/system下,创建一个名为elasticsearch.service的服务文件,如下图所示:
 编辑
编辑elasticsearch.service内容:
bash
[Unit]
Description=Elasticsearch
After=network.target
[Service]
User=elasticsearch
Group=elasticsearch
ExecStart=/usr/share/elasticsearch/bin/elasticsearch
[Install]
WantedBy=multi-user.target注册服务开机启动:
bash
systemctl enable elasticsearch.service手动启动服务:
bash
systemctl start elasticsearch.service查看ES服务状态:
bash
systemctl status elasticsearch.service如果启动成功,状态会显示成如下图所示:

2.12 启动完成后进入展示界面
可用elasticsearch-head-master进行测试,也可以用Kibana进行测试,见本文下面 ,以下是带有kibana的数据索引:
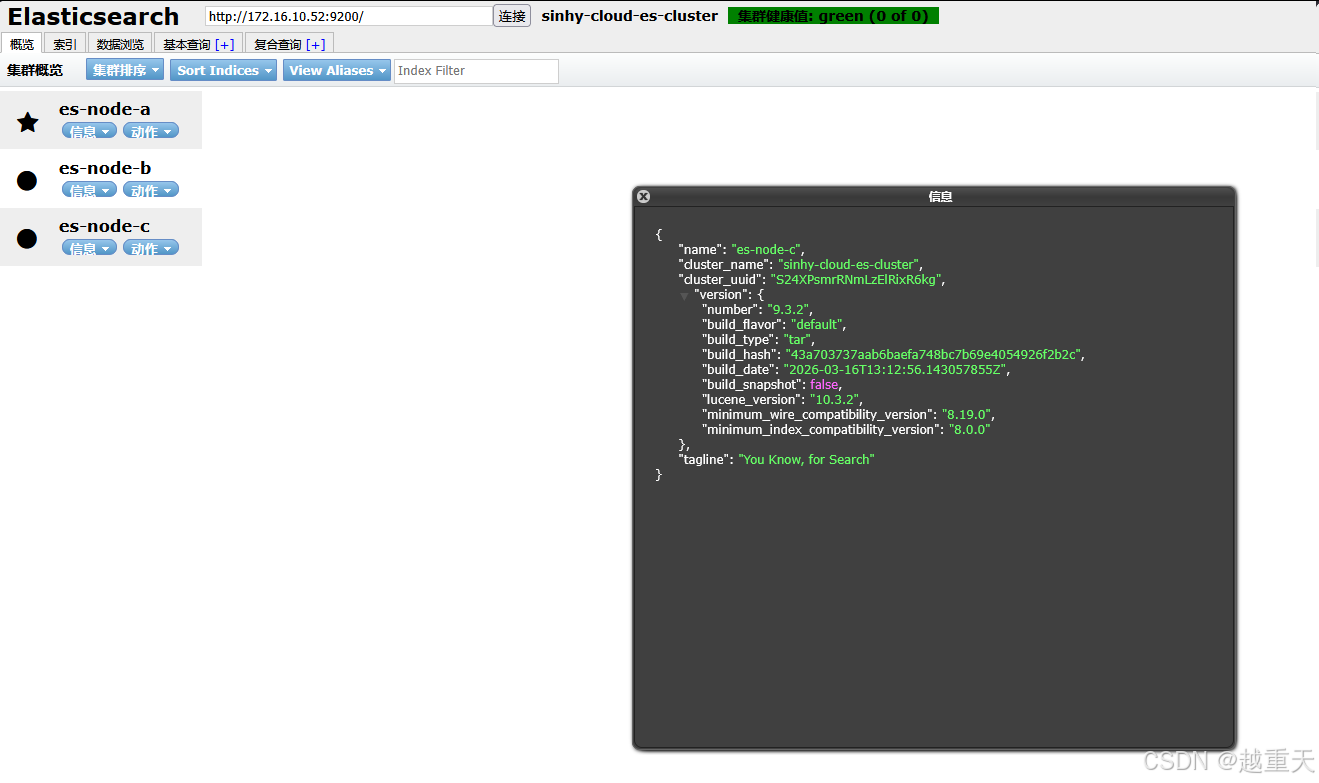

3. IK分词器安装
到IK分词器官网下载地址去下载与ES安装程序 相对应的版本:IK分词器下载
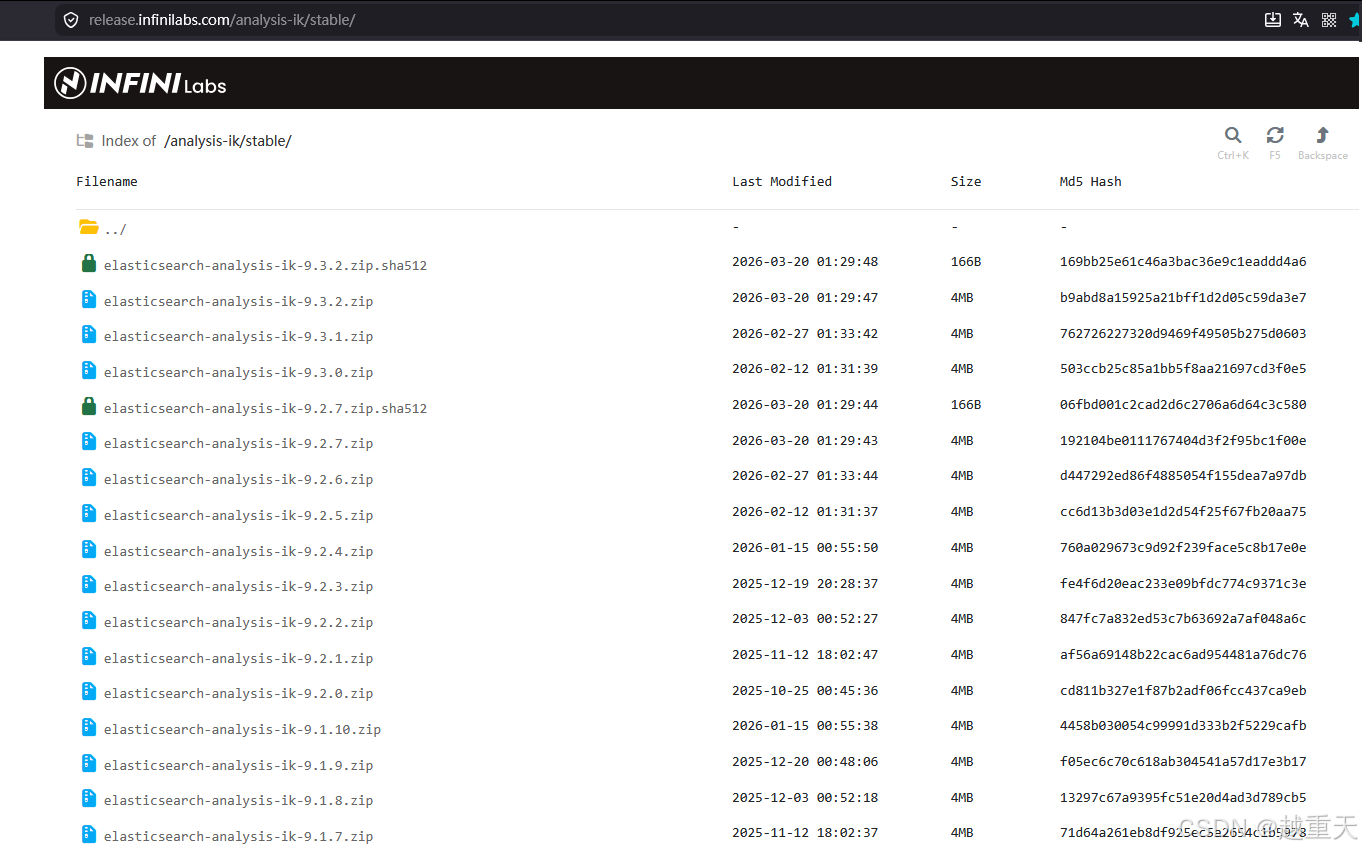
3.1 安装ik分词器
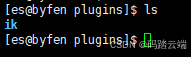
-
将下载好的zip包解压,生成一个
ik文件夹 -
将ik文件夹移动到
ES安装目录下的plugins文件夹下(每台ES节点都要执行相同的操作)
-
重启ES集群
3.2 自定义分词库
-
用vim在ik中的config目录中新建词库文件
my_word.dic输入你定义的词保存。 -
修改ik中的config目录下面的
IKAnalyzer.cfg.xml文件。
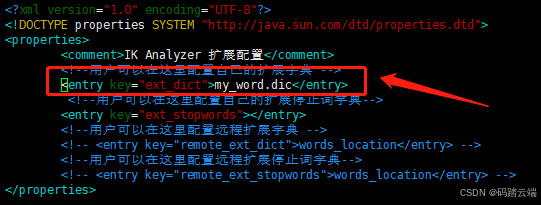
-
添加自定义分词需要重启ES。
4. kibana 的下载和安装
Kibana的官方下载地址:https://www.elastic.co/cn/downloads/kibana
这里以Linus版本安装部署为例,如下图:

4.1 Kibana配置文件修改
这个很简单,直接看代码吧:
yml
server.port: 5601
server.host: "0.0.0.0"
# 配置ES集群节点
elasticsearch.hosts: ["http://172.16.10.50:9200", "http://172.16.10.51:9200", "http://172.16.10.52:9200"]
# 配置中文界面
# Supported languages are the following: English (default) "en", Chinese "zh-CN", Japanese "ja-JP", French "fr-FR".
i18n.locale: "zh-CN"4.2 docker 简化部署
这里为了快速方便部署kibana,直接采用docker部署,如下docker启动脚本所示:
bash
# 拉取镜像
docker pull docker.elastic.co/kibana/kibana:9.3.2
# 删除日志目录
rm -rf /data/docker-containers/kibana/logs
# 创建日志目录
mkdir -p /data/docker-containers/kibana/logs
chmod 777 -R /data/*
docker run -d \
--name kibana-9.3.2 \
--restart=always \
--privileged=true \
-p 5601:5601 \
-e TZ="Asia/Shanghai" \
-v /data/docker-containers/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
-v /data/docker-containers/kibana/logs:/usr/share/kibana/logs \
kibana:9.3.24.3 进入Kibana界面

5. 总结
以上就是关于Elasticsearch 集群 和 Kibana 最新版 (9.3.2) 的手动安装教程,怎么样?是不是很简单?看完后,你学会了吗?是否一次性成功!如果是,恭喜你,你认真阅读了本文!